

Tägliche Ideen und Gespräche darüber, welche weiteren Prozesse Unternehmen unterschiedlicher Größen automatisieren können, entstehen ständig. Neben der Zeit, die für die Erstellung eines Modells aufgewendet wird, ist es wichtig, Zeit für die Bewertung und Überprüfung zu investieren, um sicherzustellen, dass das Ergebnis nicht zufällig ist. Nach der Implementierung muss jedes Modell überwacht und regelmäßig geprüft werden.
All diese Schritte müssen in jedem Unternehmen durchlaufen werden, unabhängig von seiner Größe. Wenn wir über den Maßstab und das Erbe der Sberbank sprechen, steigt die Anzahl der feinen Anpassungen um ein Vielfaches. Ende 2019 wurden in Sber bereits über 2000 Modelle verwendet. Es reicht nicht aus, nur ein Modell zu entwickeln; es ist notwendig, sich in industrielle Systeme zu integrieren, Datenschaufenster für den Aufbau von Modellen zu entwickeln und die Kontrolle über die Funktionalität im Cluster zu gewährleisten.
Unser Team arbeitet an der Plattform Sber.DS. Sie ermöglicht die Lösung von Aufgaben im Bereich maschinelles Lernen, beschleunigt den Prozess der Hypothesenprüfung, vereinfacht grundsätzlich den Prozess der Entwicklung und Validierung von Modellen und überwacht zudem die Leistung des Modells in der PRO-M.
Um Ihren Erwartungen nicht gerecht zu werden, möchte ich vorab sagen, dass dieser Post eine Einführung ist und unten zunächst erklärt wird, was im Grunde unter der Haube der Sber.DS-Plattform steckt. Die Geschichte des Lebenszyklusmodells von der Erstellung bis zur Implementierung werden wir separat erläutern.
Sber.DS besteht aus mehreren Komponenten, wobei die wichtigsten die Bibliothek, das Entwicklungsystem und das Ausführungssystem von Modellen sind.

Die Bibliothek steuert den Lebenszyklus des Modells von dem Zeitpunkt an, an dem die Idee zur Entwicklung entsteht, bis hin zur Implementierung in PROK, der Überwachung und der Außerkraftsetzung. Viele Funktionen der Bibliothek sind durch die Vorgaben der Regulierungsbehörden diktiert, wie zum Beispiel die Berichterstattung und die Speicherung der Trainings- und Validierungsdatensätze. Tatsächlich handelt es sich um ein Register all unserer Modelle.
Das Entwicklungssystem ist für die visuelle Entwicklung von Modellen und Validierungsmethoden vorgesehen. Die entwickelten Modelle durchlaufen eine erste Validierung und werden an das Ausführungssystem übergeben, um ihre Geschäfts-funktionen zu erfüllen. Außerdem kann das Modell im Ausführungssystem überwacht werden, um regelmäßig Validierungsmethoden zur Kontrolle seiner Funktionsweise auszuführen.
Im System gibt es mehrere Knotentypen. Einige sind für die Verbindung zu verschiedenen Datenquellen gedacht, während andere zur Transformation von Rohdaten und deren Anreicherung (Markup) dienen. Es gibt viele Knoten zum Aufbau verschiedener Modelle sowie Knoten zur Validierung. Der Entwickler kann Daten aus beliebigen Quellen laden, sie transformieren, filtern, Zwischenresultate visualisieren und sie in Teile aufteilen.
Die Plattform enthält auch fertige Module, die per Drag-and-Drop in den Arbeitsbereich gezogen werden können. Alle Aktionen erfolgen über eine visualisierte Benutzeroberfläche. Tatsächlich kann die Aufgabe ohne eine einzige Codezeile gelöst werden.
Wenn die integrierten Funktionen nicht ausreichen, bietet das System die Möglichkeit, eigene Module schnell zu erstellen. Wir haben einen integrierten Entwicklungsmodus auf Basis von für diejenigen, die neue Module "von Grund auf" erstellen.
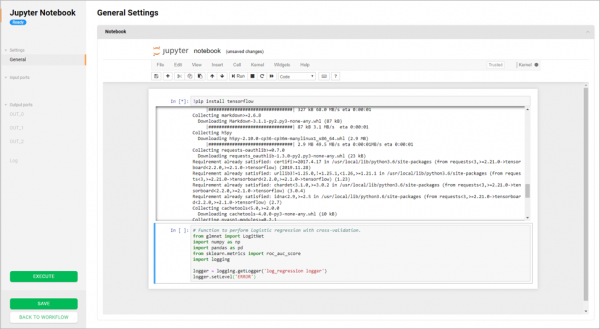
Die Architektur von Sber.DS basiert auf Mikrodiensten. Es gibt viele Meinungen darüber, was Mikrodienste sind. Einige glauben, dass es ausreicht, monolithischen Code in Teile zu zerlegen, während sie dennoch auf dasselbe Datenbankmanagementsystem zugreifen. Bei uns muss ein Mikrodienst nur über REST API mit einem anderen Mikrodienst kommunizieren. Direkter Datenbankzugriff ist nicht erlaubt.
Wir bemühen uns, dass unsere Dienste nicht zu groß und unflexibel werden: Eine Instanz sollte nicht mehr als 4-8 Gigabyte RAM verbrauchen und die Möglichkeit bieten, die Anfrage horizontal zu skalieren, indem neue Instanzen gestartet werden. Jeder Dienst kommuniziert nur über REST API (). Das Team, das für den Dienst verantwortlich ist, ist verpflichtet, die API-Rückwärtskompatibilität für den letzten Kunden aufrechtzuerhalten, der sie nutzt.
Der Kern der Anwendung ist in Java unter Verwendung des Spring Framework geschrieben. Die Lösung wurde ursprünglich für eine schnelle Bereitstellung in cloudbasierten Infrastrukturen entworfen, weshalb die Anwendung mit einem Containerisierungssystem aufgebaut wurde. (). Die Plattform entwickelt sich ständig weiter, sowohl in Bezug auf die Erweiterung der Geschäftsfunktionalität (neue Konnektoren, AutoML) als auch hinsichtlich technologischer Effizienz.
Eine der „Besonderheiten“ unserer Plattform ist, dass wir Code, der in der visuellen Benutzeroberfläche entwickelt wurde, auf jedem Ausführungssystem der Sberbank-Modelle ausführen können. Aktuell gibt es bereits zwei: eine auf Hadoop, die andere auf OpenShift (Docker). Damit geben wir uns jedoch nicht zufrieden und entwickeln Integrationsmodule, um Code auf jeder Infrastruktur auszuführen, sowohl vor Ort als auch in der Cloud. In Bezug auf die Möglichkeiten für eine effektive Integration in das Ökosystem der Sberbank planen wir zudem, die Kompatibilität mit bestehenden Ausführungsumgebungen zu unterstützen. Zukünftig kann die Lösung flexibel „out of the box“ in jede Infrastruktur jeder Organisation integriert werden.
Diejenigen, die jemals versucht haben, eine Lösung zu unterstützen, die Python auf Hadoop in PROD ausführt, wissen, dass es nicht ausreicht, die Python-Umgebung auf jedem Datenknoten vorzubereiten und bereitzustellen. Eine riesige Menge an C/C++-Bibliotheken für maschinelles Lernen, die Python-Module verwenden, erlaubt es Ihnen nicht, ruhig zu schlafen. Sie müssen daran denken, die Pakete bei der Hinzufügung neuer Bibliotheken oder Server zu aktualisieren, während Sie die Abwärtskompatibilität mit bereits implementiertem Modellcode bewahren.
Es gibt mehrere Ansätze, um dies zu tun. Zum Beispiel können Sie einige häufig verwendete Bibliotheken im Voraus vorbereiten und in PROD einfügen. Im Hadoop-Distributionspaket von Cloudera wird dies normalerweise verwendet, um zu integrieren. Außerdem ermöglicht Hadoop mittlerweile die Ausführung von -Containern. In einigen einfachen Fällen kann der Code zusammen mit dem Paket geliefert werden, .
Die Bank nimmt die Sicherheit der Ausführung von Drittanbieter-Code sehr ernst, weshalb wir die neuen Funktionen des Linux-Kernels maximal nutzen, wo der Prozess, der in einer isolierten Umgebung ausgeführt wird, , um beispielsweise den Zugang zum Netzwerk und zur lokalen Festplatte einzuschränken, wodurch die Möglichkeiten von Malware erheblich reduziert werden. Die Datenbereiche jeder Abteilung sind geschützt und nur für die Eigentümer dieser Daten zugänglich. Die Plattform garantiert, dass Daten aus einem Bereich nur über einen Datenveröffentlichungsprozess in einen anderen Bereich gelangen können, wobei alle Schritte von den Zugriffsquellen bis zur Bereitstellung der Daten im Zielbereich kontrolliert werden.
In diesem Jahr planen wir, den MVP-Start von Modellen, die in Python/R/Java auf Hadoop geschrieben sind, abzuschließen. Wir haben uns das ehrgeizige Ziel gesetzt, zu lernen, wie man jede benutzerdefinierte Umgebung auf Hadoop ausführt, um unseren Plattforumnutzern keine Einschränkungen aufzuerlegen.
Darüber hinaus haben viele DS-Spezialisten, wie sich herausstellte, ausgezeichnete Kenntnisse in Mathematik und Statistik, erstellen tolle Modelle, verstehen jedoch nicht sehr gut die Transformation großer Daten und benötigen die Hilfe unserer Data-Engineers zur Vorbereitung der Trainingsdatensätze. Wir haben beschlossen, unseren Kollegen zu helfen und benutzerfreundliche Module für die standardisierte Transformation und die Feature-Vorbereitung für Modelle auf der Spark-Engine zu entwickeln. So können sie mehr Zeit der Modellentwicklung widmen und müssen nicht warten, bis die Data-Engineers einen neuen Datensatz vorbereiten.
Bei uns arbeiten Menschen mit Wissen in verschiedenen Bereichen: Linux und DevOps, Hadoop und Spark, Java und Spring, Scala und Akka, OpenShift und Kubernetes. Beim nächsten Mal werden wir über die Modellsammlung berichten, darüber, wie ein Modell den Lebenszyklus innerhalb des Unternehmens durchläuft, wie die Validierung und Implementierung erfolgt.
Quelle: habr.com
