

Dieser Artikel ist der zweite in der Reihe zum Thema der schnellen Datenkompression. Im ersten Artikel wurde ein Kompressor beschrieben, der mit einer Geschwindigkeit von 10 GB/s pro Prozessorkern arbeitet (minimale Kompression, RTT-Min).
Dieser Kompressor ist bereits in die Ausrüstung von forensischen Duplikatoren integriert, um Dumps von Speichermedien schnell zu komprimieren und die Widerstandsfähigkeit der Kryptografie zu erhöhen. Zudem kann er zur Kompression von virtuellen Maschinen-Images und Swap-Dateien des Arbeitsspeichers verwendet werden, während diese auf schnellem SSD-Speicher abgelegt werden.
Im ersten Artikel wurde auch die Entwicklung eines Kompressionsalgorithmus zur Kompression von Backups für HDD- und SSD-Laufwerke (mittlere Kompression, RTT-Mid) mit erheblich verbesserten Kompressionsparametern angekündigt. Dieser Kompressor ist inzwischen vollständig bereit, und dieser Artikel behandelt genau ihn.
Der Kompressor, der den RTT-Mid-Algorithmus implementiert, bietet ein Kompressionsniveau, das mit Standardarchivierungssoftware wie WinRar und 7-Zip vergleichbar ist, die im Hochgeschwindigkeitsmodus arbeiten. Dabei ist seine Arbeitsgeschwindigkeit mindestens um eine Größenordnung höher.
Die Geschwindigkeit der Datenkompression/-dekompression ist ein entscheidender Parameter, der den Anwendungsbereich der Kompressionstechnologien bestimmt. Kaum jemand würde auf die Idee kommen, ein Terabyte Daten mit einer Geschwindigkeit von 10-15 Megabyte pro Sekunde zu komprimieren (genau so schnell arbeiten Komprimierungsprogramme im Standardmodus), denn das würde bei voller CPU-Auslastung fast zwanzig Stunden dauern...
Andererseits kann dasselbe Terabyte mit Geschwindigkeiten von etwa 2-3 Gigabyte pro Sekunde innerhalb von zehn Minuten kopiert werden.
Daher ist die Kompression von großen Datenmengen relevant, wenn sie mit einer Geschwindigkeit von nicht weniger als der Geschwindigkeit des realen Ein-/Ausgabeprozesses durchgeführt wird. Für moderne Systeme bedeutet das mindestens 100 Megabyte pro Sekunde.
Solche Geschwindigkeiten können moderne Kompressoren nur im ‚Fast‘-Modus erreichen. In diesem relevanten Modus werden wir den Algorithmus RTT-Mid mit traditionellen Kompressoren vergleichen.
Vergleichende Tests des neuen Kompressionsalgorithmus
Der RTT-Mid Kompressor arbeitete im Rahmen eines Testprogramms. In einer realen Anwendung arbeitet er deutlich schneller, dort wird die Multithreadfähigkeit sinnvoll genutzt und ein "normaler" Compiler verwendet, nicht C#.
Da die verwendeten Kompressoren im Vergleichstest auf unterschiedlichen Prinzipien basieren und verschiedene Datentypen unterschiedlich komprimieren, wurde zur Objektivität des Tests die Methode der "durchschnittlichen Temperatur im Krankenhaus" angewandt...
Es wurde eine Sektor-Dump-Datei des logischen Laufwerks mit dem Betriebssystem Windows 10 erstellt, dies ist die natürlichste Mischung aus verschiedenen Datenstrukturen, wie sie auf jedem Computer anzutreffen sind. Die Kompression dieser Datei ermöglicht es, die Geschwindigkeit und den Kompressionsgrad des neuen Algorithmus mit den fortschrittlichsten Kompressoren zu vergleichen, die in modernen Archivierern verwendet werden.
Hier ist die Dump-Datei:
Die Dump-Datei wurde mit den Kompressoren RTT-Mid, 7-zip, WinRar komprimiert. Der Kompressor WinRar und 7-zip wurden auf maximale Geschwindigkeit eingestellt.
Kompressor läuft 7-zip:
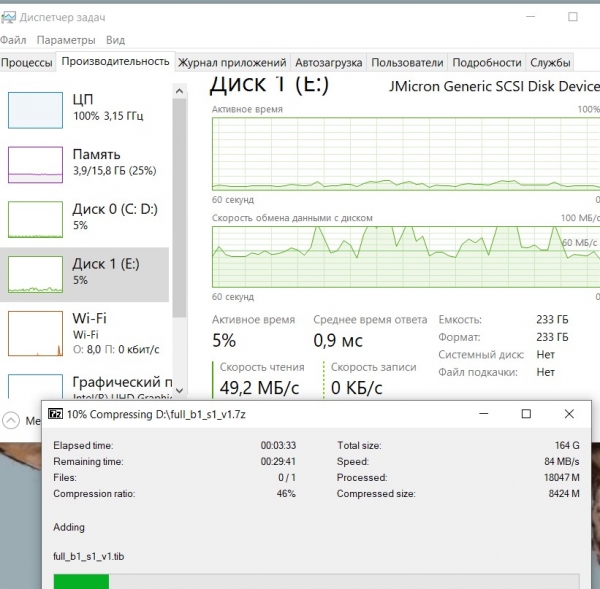
Er belastet die CPU zu 100%, während die durchschnittliche Lesegeschwindigkeit des ursprünglichen Dumps etwa 60 Megabyte/Sekunde beträgt.
Kompressor läuft WinRar:
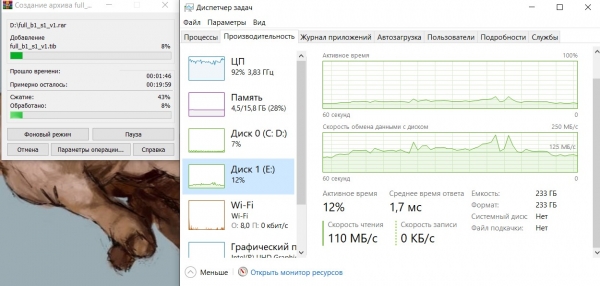
Die Situation ist ähnlich, die CPU-Auslastung liegt bei nahezu 100 %, die durchschnittliche Lesegeschwindigkeit des Dumps beträgt etwa 125 Megabyte/Sekunde.
Wie im vorherigen Fall ist die Geschwindigkeit des Archivators durch die Möglichkeiten der CPU begrenzt.
Jetzt funktioniert das Testprogramm des Kompressors. RTT-Mid:
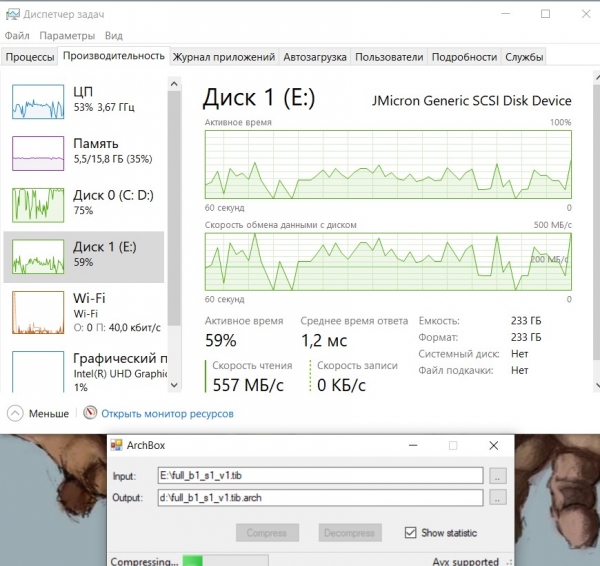
Der Screenshot zeigt, dass die CPU zu 50 % ausgelastet ist und die restliche Zeit untätig bleibt, da keine komprimierten Daten entladen werden können. Die Ablagedisk (Disk 0) ist nahezu vollständig ausgelastet. Die Lesegeschwindigkeit der Daten (Disk 1) schwankt stark, liegt aber im Durchschnitt über 200 Megabyte/Sekunde.
Die Arbeitsgeschwindigkeit des Kompressors wird in diesem Fall durch die Schreibfähigkeit komprimierter Daten auf Disk 0 begrenzt.
Jetzt der Kompressionsgrad der erhaltenen Archive:



Es ist zu sehen, dass der Kompressor RTT-Mid am besten mit der Kompression zurechtgekommen ist; das von ihm erstellte Archiv ist 1,3 Gigabyte kleiner als das WinRar-Archiv und 2,1 Gigabyte kleiner als das 7z-Archiv.
Die für die Erstellung des Archivs benötigte Zeit:
- 7-zip – 26 Minuten 10 Sekunden;
- WinRar – 17 Minuten 40 Sekunden;
- RTT-Mid – 7 Minuten 30 Sekunden.
So konnte selbst ein Testprogramm, das nicht optimiert ist und den RTT-Mid-Algorithmus verwendet, das Archiv mehr als zweieinhalbmal schneller erstellen, und das Archiv war dabei wesentlich kleiner als das der Wettbewerber...
Diejenigen, die den Screenshots nicht glauben, können ihre Richtigkeit selbst überprüfen. Das Testprogramm ist verfügbar unter , laden Sie es herunter und überprüfen Sie es.
Aber nur auf Prozessoren mit AVX-2-Unterstützung; ohne Unterstützung für diese Instruktionen funktioniert der Kompressor nicht, und testen Sie den Algorithmus nicht auf alten AMD-Prozessoren, da diese bei der Ausführung von AVX-Befehlen langsam sind...
Das verwendete Kompressionsverfahren
Der Algorithmus verwendet eine Methode zur Indizierung wiederholter Textfragmente in Bytegranularität. Diese Kompressionsmethode ist schon lange bekannt, wurde jedoch nicht verwendet, da die Übereinstimmungssuche sehr ressourcenintensiv war und deutlich mehr Zeit in Anspruch nahm als der Aufbau eines Wörterbuchs. Der RTT-Mid-Algorithmus ist also ein klassisches Beispiel für eine Rückkehr in die Zukunft...
Im RTT-Kompressor wird ein einzigartiger Hochgeschwindigkeit-Matching-Scanner eingesetzt, der den Komprimierungsprozess erheblich beschleunigt hat. Dieser selbst entwickelte Scanner ist „mein Schatz…“, „der Preis ist nicht gering, da er vollständig handgefertigt ist“ (in Assembler geschrieben).
Der Matching-Scanner basiert auf einem zweistufigen Wahrscheinlichkeitsansatz: Zuerst wird nach dem Vorhandensein eines „Merkmals“ für eine Übereinstimmung gesucht, und erst nach Identifizierung dieses „Merkmals“ wird der Prozess zur Erkennung der tatsächlichen Übereinstimmung gestartet.
Das Suchfenster für Übereinstimmungen hat eine unvorhersehbare Größe, die von der Entropiestufe im verarbeiteten Datenblock abhängt. Bei vollständig zufälligen (nicht komprimierbaren) Daten hat es die Größe von Megabyte, während es bei Daten mit Wiederholungen immer größer als ein Megabyte ist.
Viele moderne Datenformate sind jedoch nicht komprimierbar, und somit ist es ineffizient und verschwenderisch, einen ressourcenintensiven Scanner durch sie hindurch zu betreiben. Daher verwendet der Scanner zwei Betriebsmodi. Zuerst werden Abschnitte des Quelltexts mit möglichen Wiederholungen gesucht. Dieser Vorgang wird ebenfalls probabilistisch durchgeführt und geschieht sehr schnell (mit Geschwindigkeiten von 4-6 Gigabyte/Sekunde). Danach werden die Abschnitte mit möglichen Übereinstimmungen vom Hauptscanner verarbeitet.
Die Indexkompression ist nicht sehr effektiv. Es müssen wiederholte Fragmente durch Indizes ersetzt werden, und das Indexarray reduziert erheblich das Kompressionsverhältnis.
Um den Kompressionsgrad zu erhöhen, werden nicht nur vollständige Übereinstimmungen von Bytefolgen indexiert, sondern auch partielle, bei denen sowohl übereinstimmende als auch nicht übereinstimmende Bytes in der Reihe vorhanden sind. Zu diesem Zweck enthält das Indexformat ein Übereinstimmungsmaske-Feld, das auf die übereinstimmenden Bytes der beiden Blöcke verweist. Für eine noch höhere Kompression wird eine Indizierung mit Überlappung mehrerer teilweise übereinstimmender Blöcke auf dem aktuellen Block verwendet.
All dies ermöglichte es, im RTT-Mid-Kompressor ein Kompressionsverhältnis zu erzielen, das mit dem von Kompressoren, die nach dem Wörterbuchverfahren hergestellt werden, vergleichbar ist, wobei er jedoch deutlich schneller arbeitet.
Geschwindigkeit des neuen Kompressionsalgorithmus
Wenn der Kompressor mit exklusivem Einsatz des Speichercaches arbeitet (4 Megabyte pro Thread erforderlich), schwankt die Geschwindigkeit zwischen 700 und 2000 Megabyte/Sekunde pro CPU-Kern, abhängig von der Art der komprimierten Daten und hängt nur geringfügig von der Prozessortaktfrequenz ab.
Bei der Multithread-Implementierung des Kompressors wird die effektive Skalierbarkeit durch den Cache-Speicher der dritten Ebene bestimmt. Zum Beispiel macht es mit 9 Megabyte Cache keinen Sinn, mehr als zwei Kompressionsstränge zu starten, die Geschwindigkeit würde dadurch nicht steigen. Mit einem Cache von 20 Megabyte können jedoch bereits fünf Kompressionsstränge gestartet werden.
Ein weiterer wesentlicher Parameter, der die Arbeitsgeschwindigkeit des Kompressors bestimmt, ist die Latenz des Arbeitsspeichers. Der Algorithmus verwendet zufällige Zugriffe auf den RAM, von denen ein Teil nicht im Cache gespeichert wird (etwa 10 %), sodass er warten muss, bis die Daten aus dem RAM bereitgestellt werden, was die Geschwindigkeit verringert.
Die Geschwindigkeit des Kompressors wird auch durch die Funktionsweise des Ein- und Ausgabesystems beeinflusst. Anfragen an den RAM vom Ein-/Ausgang blockieren Datenabfragen des CPUs, was ebenfalls die Kompressionsgeschwindigkeit verringert. Dieses Problem ist insbesondere bei Laptops und Desktops erheblich, Server da es aufgrund des fortschrittlicheren Zugriffssteuerungsblocks zur Systembus und des Mehrkanal-RAMs weniger relevant ist.
Im gesamten Artikel wird über Kompression gesprochen, während die Dekompression in diesem Artikel nicht behandelt wird, da dort «alles in Ordnung ist». Die Dekompression erfolgt erheblich schneller und wird durch die Geschwindigkeit von Ein- und Ausgabe begrenzt. Ein physischer Kern in einem Thread kann problemlos Entpackungsgeschwindigkeiten von 3-4 Gigabyte/Sekunde erreichen.
Dies liegt daran, dass beim Entpacken der Suchvorgang nach Übereinstimmungen fehlt, der die Hauptressourcen der CPU und den Cache während der Kompression „aufzehrt“.
Zuverlässigkeit der Speicherung komprimierter Daten
Wie der Name der gesamten Klasse von Softwaretools zur Datenspeicherung (Komprimierungssoftware) bereits andeutet, sind sie für die langfristige Speicherung von Informationen gedacht, nicht für Jahre, sondern für Jahrhunderte und Jahrtausende…
Im Laufe der Speicherung verlieren Speichermedien einen Teil der Daten, hier ein Beispiel:

Dieses „analoge“ Speichermedium ist tausend Jahre alt; einige Fragmente sind verloren gegangen, aber insgesamt ist die Information „lesbar“…
Kein verantwortlicher Hersteller moderner digitaler Datenspeichersysteme und digitaler Medien bietet Garantien für die vollständige Datensicherung von mehr als 75 Jahren an.
Und das ist ein Problem, aber ein aufgeschobenes Problem, das unsere Nachkommen lösen werden…
Digitale Datenspeichersysteme können Daten nicht nur nach 75 Jahren verlieren, sondern Datenfehler können jederzeit auftreten, sogar während der Aufzeichnung. Diese Verzerrungen versuchen, durch Redundanz und Korrektur mit Fehlerkorrektursystemen zu minimieren. Redundanz und Korrektursysteme können verlorene Informationen nicht immer wiederherstellen und selbst wenn, gibt es keine Garantie, dass der Wiederherstellungsprozess korrekt durchgeführt wurde.
Und das ist auch ein großes Problem, jedoch nicht in der Zukunft, sondern ein aktuelles.
Moderne Kompressoren, die für die Archivierung digitaler Daten verwendet werden, basieren auf verschiedenen Modifikationen der Wörterbuchmethode. Für solche Archive wird der Verlust eines Informationsfragments ein fatales Ereignis sein; es gibt sogar einen feststehenden Begriff für eine solche Situation — ein „beschädigtes“ Archiv...
Die geringe Zuverlässigkeit der Informationsspeicherung in Archiven mit Wörterbuchkompression hängt mit der Struktur der komprimierten Daten zusammen. Informationen in einem solchen Archiv enthalten nicht den ursprünglichen Text; stattdessen werden die Indizes der Einträge im Wörterbuch gespeichert, während das Wörterbuch dynamisch mit dem aktuell komprimierten Text modifiziert wird. Bei Verlust oder Verfälschung eines Archivteils können alle nachfolgenden Einträge weder nach Inhalt noch nach Länge des Wörterbucheintrags identifiziert werden, da unklar bleibt, welchem Wörterbucheintrag die Indizes entsprechen.
Es ist unmöglich, Informationen aus einem solchen „beschädigten“ Archiv wiederherzustellen.
Der RTT-Algorithmus basiert auf einer zuverlässigeren Methode zur Speicherung komprimierter Daten. Hierbei kommt eine Indexpolitik zur Erfassung wiederholender Fragmente zur Anwendung. Dieser Ansatz zur Kompression minimiert die Auswirkungen von Informationsverzerrungen auf dem Träger und kann in vielen Fällen Verzerrungen, die beim Speichern der Informationen aufgetreten sind, automatisch korrigieren.
Dies liegt daran, dass die Archivdatei im Fall der indexierten Kompression zwei Felder enthält:
- ein Feld mit dem ursprünglichen Text, aus dem die Wiederholungsabschnitte entfernt wurden;
- ein Indexfeld.
Ein kritisches Feld für die Wiederherstellung von Informationen ist zwar klein, kann jedoch zur Datenspeicherung dupliziert werden. Daher kann auch, wenn ein Teil des ursprünglichen Textes oder des Index-Arrays verloren geht, alle übrige Informationen problemlos wiederhergestellt werden, wie auf dem Bild mit einem "analogen" Speichermedium.
Nachteile des Algorithmus
Es gibt keine Vorteile ohne Nachteile. Die indizierte Komprimierungsmethode komprimiert keine sich wiederholenden, kurzen Sequenzen. Dies liegt an den Einschränkungen der indizierten Methode. Indizes haben eine Größe von mindestens 3 Bytes und können bis zu 12 Bytes groß sein. Wenn ein Wiederholungsmuster kleiner ist als der beschreibende Index, wird es nicht berücksichtigt, egal wie oft solche Wiederholungen in der komprimierten Datei auftreten.
Das traditionelle, lexikalische Kompressionsverfahren komprimiert effektiv zahlreiche kurze Wiederholungen und erreicht daher eine höhere Kompressionsrate als die Indexkompression. Dies geschieht jedoch zulasten einer hohen CPU-Auslastung, denn um die Daten effizienter zu komprimieren als die Indexmethode, muss die lexikalische Methode die Datenverarbeitungsgeschwindigkeit auf 10-20 Megabyte pro Sekunde in realen Recheneinheiten bei voller CPU-Auslastung reduzieren.
Solche niedrigen Geschwindigkeiten sind für moderne Datenspeichersysteme inakzeptabel und stellen mehr ein "akademisches" Interesse dar als ein praktisches.
Der Grad der Informationskompression wird in der nächsten Modifikation des RTT-Algorithmus (RTT-Max) erheblich erhöht, die sich bereits in der Entwicklung befindet.
Also, wie immer, es folgt eine Fortsetzung…
Quelle: habr.com
