

In Tscheljabinsk finden Sysadminka-Systemadministratortreffen statt, und beim letzten habe ich über unsere Lösung zum Ausführen von Anwendungen auf 1C-Bitrix in Kubernetes berichtet.
Bitrix, Kubernetes, Ceph – eine tolle Mischung?
Ich erzähle Ihnen, wie wir daraus eine funktionierende Lösung zusammengestellt haben.
Lassen Sie uns gehen!

Das Treffen fand am 18. April in Tscheljabinsk statt. Über unsere Meetups könnt ihr hier lesen und anschauen .
Wenn Sie mit einem Bericht oder als Zuhörer zu uns kommen möchten, schreiben Sie an vadim.isakanov@gmail.com und im Telegramm an t.me/vadimisakanov.
Mein Bericht
Lösung „Bitrix in Kubernetes, Version Southbridge 1.0“
Ich werde über unsere Lösung im Format „für Dummies in Kubernetes“ sprechen, wie es beim Treffen geschehen ist. Ich gehe aber davon aus, dass Sie die Wörter Bitrix, Docker, Kubernetes, Ceph zumindest auf der Ebene von Artikeln auf Wikipedia kennen.
Was bietet Bitrix in Kubernetes?
Über den Betrieb von Bitrix-Anwendungen in Kubernetes gibt es im gesamten Internet nur sehr wenige Informationen.
Ich habe nur diese Materialien gefunden:
Bericht von Alexander Serbul, 1C-Bitrix und Anton Tuzlukov von Qsoft:

Ich empfehle, es anzuhören.
Entwickeln Sie Ihre eigene Lösung aus dem Benutzer heraus .
Mehr gefunden .
Uuuund... eigentlich ist das alles.
Ich warne Sie, wir haben die Qualität der Lösungen in den obigen Links nicht überprüft :)
Übrigens habe ich bei der Vorbereitung unserer Lösung mit Alexander Serbul gesprochen, damals war sein Bericht noch nicht erschienen, daher gibt es in meinen Folien den Punkt „Bitrix verwendet kein Kubernetes“.
Es gibt aber bereits viele vorgefertigte Docker-Images für den Betrieb von Bitrix in Docker:
Reicht das aus, um eine Komplettlösung für Bitrix in Kubernetes zu erstellen?
Nein. Es gibt eine Vielzahl von Problemen, die gelöst werden müssen.
Welche Probleme gibt es mit Bitrix in Kubernetes?
Erstens sind vorgefertigte Images von Dockerhub nicht für Kubernetes geeignet
Wenn wir eine Microservices-Architektur aufbauen wollen (und das tun wir normalerweise bei Kubernetes), müssen wir unsere Kubernetes-Anwendung in Container aufteilen und jeden Container eine kleine Funktion ausführen lassen (und zwar gut). Warum nur einer? Kurz gesagt: Je einfacher, desto zuverlässiger.
Um genauer zu sein, schauen Sie sich bitte diesen Artikel und das Video an:
Docker-Images in Dockerhub basieren hauptsächlich auf dem All-in-One-Prinzip, sodass wir immer noch unser eigenes Fahrrad erstellen und sogar Images von Grund auf erstellen mussten.
Zweitens: Der Site-Code wird über das Admin-Panel bearbeitet
Wir haben einen neuen Abschnitt auf der Website erstellt – der Code wurde aktualisiert (ein Verzeichnis mit dem Namen des neuen Abschnitts wurde hinzugefügt).
Wenn Sie die Eigenschaften einer Komponente über das Admin-Panel geändert haben, hat sich auch der Code geändert.
Damit kann Kubernetes „standardmäßig“ nicht arbeiten; Container müssen zustandslos sein.
Grund: Jeder Container (Pod) im Cluster verarbeitet nur einen Teil des Datenverkehrs. Wenn Sie den Code nur in einem Container (Pod) ändern, ist der Code in verschiedenen Pods unterschiedlich, die Site funktioniert anders und verschiedene Benutzer werden unterschiedliche Versionen der Site angezeigt. So kann man nicht leben.
Drittens müssen Sie das Problem mit der Bereitstellung lösen
Wenn wir einen Monolithen und einen „klassischen“ Server haben, ist alles ganz einfach: Wir stellen eine neue Codebasis bereit, migrieren die Datenbank, schalten den Datenverkehr auf die neue Version des Codes um. Die Umschaltung erfolgt sofort.
Wenn wir eine Site in Kubernetes haben, die in Microservices unterteilt ist, gibt es viele Container mit Code – oh. Sie müssen Container mit einer neuen Version des Codes sammeln, diese anstelle der alten ausrollen, die Datenbank korrekt migrieren und dies im Idealfall unbemerkt für die Besucher tun. Glücklicherweise hilft uns Kubernetes dabei, indem es eine ganze Reihe verschiedener Arten von Bereitstellungen unterstützt.
Viertens: Sie müssen das Problem der Speicherung statischer Daten lösen
Wenn Ihre Site „nur“ 10 Gigabyte groß ist und Sie sie vollständig in Containern bereitstellen, erhalten Sie am Ende 10-Gigabyte-Container, deren Bereitstellung ewig dauert.
Sie müssen die „schwersten“ Teile des Geländes außerhalb von Containern lagern, und es stellt sich die Frage, wie dies richtig gemacht wird
Was fehlt in unserer Lösung?
Der gesamte Bitrix-Code ist nicht in Mikrofunktionen/Mikrodienste unterteilt (so dass die Registrierung separat ist, das Online-Shop-Modul separat ist usw.). Wir speichern die gesamte Codebasis in jedem Container.
Wir speichern die Datenbank auch nicht in Kubernetes (ich habe immer noch Lösungen mit einer Datenbank in Kubernetes für Entwicklungsumgebungen implementiert, aber nicht für die Produktion).
Für Site-Administratoren wird weiterhin erkennbar sein, dass die Site auf Kubernetes läuft. Die Funktion „Systemprüfung“ funktioniert nicht ordnungsgemäß. Um den Site-Code über das Admin-Panel zu bearbeiten, müssen Sie zunächst auf die Schaltfläche „Ich möchte den Code bearbeiten“ klicken.
Die Probleme wurden identifiziert, die Notwendigkeit der Implementierung von Microservices wurde ermittelt, das Ziel ist klar – ein funktionierendes System zum Ausführen von Anwendungen auf Bitrix in Kubernetes zu erhalten, wobei sowohl die Fähigkeiten von Bitrix als auch die Vorteile von Kubernetes erhalten bleiben. Beginnen wir mit der Umsetzung.
Architektur
Es gibt viele „funktionierende“ Pods mit einem Webserver (Worker).
Eine davon mit Cron-Aufgaben (nur eine ist erforderlich).
Ein Upgrade zum Bearbeiten des Site-Codes über das Admin-Panel (auch nur eines ist erforderlich).
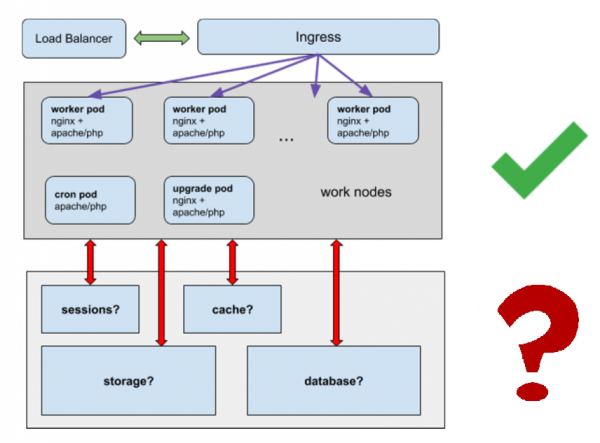
Wir lösen Fragen:
- Wo werden Sitzungen gespeichert?
- Wo soll der Cache gespeichert werden?
- Wo soll ich die statischen Daten speichern und nicht Gigabytes an statischen Daten in einer Reihe von Containern unterbringen?
- Wie wird die Datenbank funktionieren?
Docker-Image
Wir beginnen mit der Erstellung eines Docker-Images.
Die ideale Option ist, dass wir ein universelles Image haben, auf dessen Grundlage wir Worker-Pods, Pods mit Crontasks und Upgrade-Pods erhalten.
.
Es umfasst Nginx, Apache/php-fpm (kann während des Builds ausgewählt werden), msmtp zum Senden von E-Mails und Cron.
Beim Zusammenstellen des Bildes wird die gesamte Codebasis der Site in das Verzeichnis /app kopiert (mit Ausnahme der Teile, die wir in einen separaten gemeinsam genutzten Speicher verschieben).
Microservices, Dienste
Arbeiter-Pods:
- Container mit Nginx + Container Apache/php-fpm + msmtp
- Es hat nicht geklappt, msmtp in einen separaten Microservice zu verschieben, Bitrix beginnt sich darüber zu ärgern, dass es keine E-Mails direkt versenden kann
- Jeder Container verfügt über eine vollständige Codebasis.
- Verbot der Codeänderung in Containern.
Cron unter:
- Container mit Apache, PHP, Cron
- komplette Codebasis enthalten
- Verbot der Codeänderung in Containern
Upgrade unter:
- Nginx-Container + Apache/php-fpm-Container + msmtp
- Es gibt kein Verbot, Code in Containern zu ändern
Sitzungsspeicherung
Bitrix-Cache-Speicher
Eine weitere wichtige Sache: Wir speichern Passwörter für die Verbindung zu allem, von der Datenbank bis zur E-Mail, in Kubernetes-Geheimnissen. Wir erhalten einen Bonus: Passwörter sind nur für diejenigen sichtbar, denen wir Zugang zu den Geheimnissen gewähren, und nicht für jeden, der Zugriff auf die Codebasis des Projekts hat.
Lagerung für Statik
Sie können alles verwenden: Ceph, NFS (wir empfehlen NFS jedoch nicht für die Produktion), Netzwerkspeicher von Cloud-Anbietern usw.
Der Speicher muss in Containern mit dem /upload/-Verzeichnis der Site und anderen Verzeichnissen mit statischem Inhalt verbunden werden.
Datenbank
Der Einfachheit halber empfehlen wir, die Datenbank außerhalb von Kubernetes zu verschieben. Die Basis in Kubernetes ist eine separate komplexe Aufgabe; sie wird das Schema um eine Größenordnung komplexer machen.
Sitzungsspeicher
Wir verwenden Memcached :)
Es verwaltet die Sitzungsspeicherung gut, ist geclustert und wird „nativ“ als session.save_path in PHP unterstützt. Ein solches System wurde viele Male in der klassischen monolithischen Architektur getestet, als wir Cluster mit einer großen Anzahl von Webservern bauten. Für den Einsatz nutzen wir helm.
$ helm install stable/memcached --name sessionphp.ini – hier enthält das Bild Einstellungen zum Speichern von Sitzungen im Memcached
Wir haben Umgebungsvariablen verwendet, um Daten über Hosts mit Memcached zu übergeben .
Dadurch können Sie denselben Code in den Entwicklungs-, Bühnen-, Test- und Produktionsumgebungen verwenden (die darin zwischengespeicherten Hostnamen sind unterschiedlich, daher müssen wir für Sitzungen an jede Umgebung einen eindeutigen Hostnamen übergeben).
Bitrix-Cache-Speicher
Wir benötigen einen fehlertoleranten Speicher, auf den alle Pods schreiben und von dem sie lesen können.
Wir verwenden auch Memcached.
Diese Lösung wird von Bitrix selbst empfohlen.
$ helm install stable/memcached --name cachebitrix/.settings_extra.php – hier wird in Bitrix angegeben, wo der Cache gespeichert wird
Wir verwenden auch Umgebungsvariablen.
Krontaski
Es gibt verschiedene Ansätze, Crontasks in Kubernetes auszuführen.
- separate Bereitstellung mit einem Pod zum Ausführen von Crontasks
- Cronjob zum Ausführen von Crontasks (wenn es sich um eine Web-App handelt – mit wget , oder kubectl exec in einem der Worker-Pods usw.)
- usw.
Über die richtige Lösung kann man streiten, aber in diesem Fall haben wir die Option „separate Bereitstellung mit Pods für Crontasks“ gewählt.
Wie es gemacht wird:
- Fügen Sie Cron-Aufgaben über ConfigMap oder über die Datei config/addcron hinzu
- In einem Fall starten wir einen Container, der mit dem Worker-Pod identisch ist, und ermöglichen die Ausführung von Kronenaufgaben darin
- Es wird die gleiche Codebasis verwendet, dank der Vereinheitlichung ist die Containermontage einfach
Was Gutes bekommen wir:
- Wir haben funktionierende Crontasks in einer Umgebung, die mit der Entwicklerumgebung (Docker) identisch ist.
- Crontasks müssen für Kubernetes nicht „umgeschrieben“ werden, sie funktionieren in der gleichen Form und in der gleichen Codebasis wie zuvor
- Cron-Aufgaben können von allen Teammitgliedern mit Commit-Rechten für den Produktionszweig hinzugefügt werden, nicht nur von Administratoren
Southbridge K8SDeploy-Modul und Codebearbeitung über das Admin-Panel
Wir haben unten über ein Upgrade gesprochen?
Wie lenke ich den Verkehr dorthin?
Hurra, wir haben dafür ein Modul in PHP geschrieben :) Dies ist ein kleines klassisches Modul für Bitrix. Es ist noch nicht öffentlich verfügbar, aber wir planen, es zu öffnen.
Das Modul wird wie ein reguläres Modul in Bitrix installiert:
Und es sieht so aus:
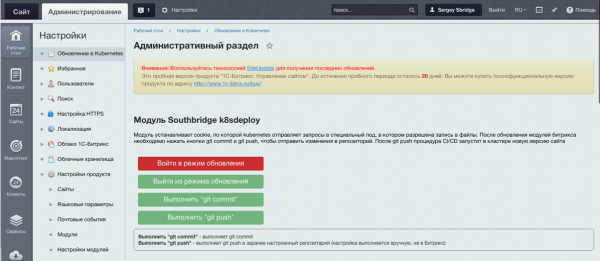
Sie können damit ein Cookie setzen, das den Site-Administrator identifiziert und es Kubernetes ermöglicht, Datenverkehr an den Upgrade-Pod zu senden.
Wenn die Änderungen abgeschlossen sind, müssen Sie auf „Git Push“ klicken. Die Codeänderungen werden an Git gesendet. Anschließend erstellt das System ein Image mit einer neuen Version des Codes und „rollt“ es im gesamten Cluster aus, wobei die alten Pods ersetzt werden .
Ja, es ist ein bisschen eine Krücke, aber gleichzeitig behalten wir die Microservice-Architektur bei und nehmen Bitrix-Benutzern nicht ihre Lieblingsmöglichkeit, den Code über das Admin-Panel zu korrigieren. Letztendlich ist dies eine Option; Sie können das Problem der Codebearbeitung auf andere Weise lösen.
Helmkarte
Um Anwendungen auf Kubernetes zu erstellen, verwenden wir normalerweise den Helm-Paketmanager.
Für unsere Bitrix-Lösung in Kubernetes hat Sergey Bondarev, unser führender Systemadministrator, ein spezielles Helm-Diagramm geschrieben.
Es erstellt Worker-, Ugrade- und Cron-Pods, konfiguriert Ingresses, Dienste und überträgt Variablen von Kubernetes-Geheimnissen an Pods.
Wir speichern den Code in Gitlab und führen auch den Helm-Build von Gitlab aus.
Kurz gesagt, es sieht so aus
$ helm upgrade --install project .helm --set image=registrygitlab.local/k8s/bitrix -f .helm/values.yaml --wait --timeout 300 --debug --tiller-namespace=productionHelm ermöglicht Ihnen auch ein „nahtloses“ Rollback, wenn während der Bereitstellung plötzlich etwas schief geht. Es ist schön, wenn Sie nicht in Panik geraten und „den Code per FTP reparieren, weil das Produkt ausgefallen ist“, sondern Kubernetes dies automatisch und ohne Ausfallzeiten erledigt.
Einsetzen
Ja, wir sind Fans von Gitlab & Gitlab CI, wir nutzen es :)
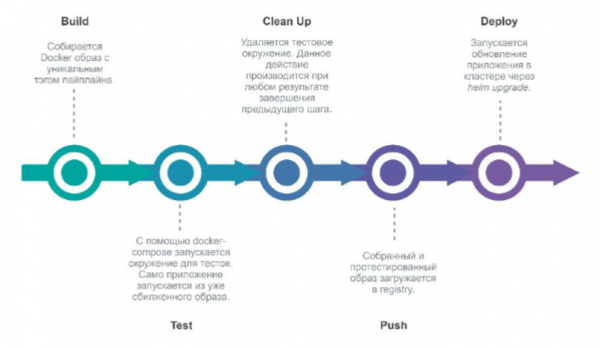
Beim Commit in Gitlab in das Projekt-Repository startet Gitlab eine Pipeline, die eine neue Version der Umgebung bereitstellt.
Steps:
- build (Erstellen eines neuen Docker-Images)
- testen (testen)
- Aufräumen (Entfernen der Testumgebung)
- push (wir senden es an die Docker-Registrierung)
- Bereitstellen (wir stellen die Anwendung über Helm auf Kubernetes bereit).
Hurra, es ist fertig, lasst es uns umsetzen!
Nun ja, oder stellen Sie Fragen, falls es welche gibt.
Was haben wir also gemacht?
Aus technischer Sicht:
- dockerisiertes Bitrix;
- Bitrix in Container „schneiden“, von denen jeder ein Minimum an Funktionen ausführt;
- Zustandslosigkeit der Container erreicht;
- das Problem mit der Aktualisierung von Bitrix in Kubernetes wurde gelöst;
- alle Bitrix-Funktionen funktionierten weiterhin (fast alle);
- Wir haben an der Bereitstellung auf Kubernetes und dem Rollback zwischen Versionen gearbeitet.
Aus betriebswirtschaftlicher Sicht:
- Fehlertoleranz;
- Kubernetes-Tools (einfache Integration mit Gitlab CI, nahtlose Bereitstellung usw.);
- geheime Passwörter (nur sichtbar für diejenigen, denen direkt Zugriff auf die Passwörter gewährt wird);
- Es ist bequem, zusätzliche Umgebungen (für Entwicklung, Tests usw.) innerhalb einer einzigen Infrastruktur zu erstellen.
Source: habr.com
