


Der Kube-Scheduler ist ein wesentlicher Bestandteil von Kubernetes, der für die Zuordnung von Pods zu Knoten gemäß festgelegten Richtlinien verantwortlich ist. Oft denken wir beim Betrieb eines Kubernetes-Clusters nicht darüber nach, nach welchen genauen Richtlinien die Pods zugeteilt werden, da die Standardrichtlinien des Kube-Schedulers für die meisten täglichen Aufgaben geeignet sind. Dennoch gibt es Situationen, in denen es wichtig ist, den Prozess der Pod-Zuweisung fein zu steuern, wofür es zwei Lösungsansätze gibt:
- Einen Kube-Scheduler mit einem benutzerdefinierten Regelwerk erstellen
- Einen eigenen Scheduler schreiben und ihn mit dem API-Server interagieren lassen
In diesem Artikel werde ich die Umsetzung des ersten Ansatzes zur Lösung des Problems der ungleichmäßigen Pod-Zuweisung in einem unserer Projekte beschreiben.
Eine kurze Einführung in die Funktionsweise des Kube-Schedulers
Es ist besonders zu beachten, dass der kube-scheduler nicht für die direkte Planung von Pods zuständig ist – er bestimmt lediglich, auf welchem Knoten der Pod platziert werden soll. Anders gesagt, das Ergebnis der Arbeit des kube-schedulers ist der Name des Knotens, den er dem API-Server auf die Anfrage zur Planung zurückgibt, und damit endet seine Aufgabe.
Zuerst erstellt der kube-scheduler eine Liste von Knoten, auf denen ein Pod gemäß den Predicate-Richtlinien geplant werden kann. Dann erhält jeder Knoten in dieser Liste eine bestimmte Anzahl von Punkten gemäß den Priority-Richtlinien. Das Ergebnis ist der Knoten, der die maximale Punktzahl erreicht hat. Wenn mehrere Knoten die gleiche maximale Punktzahl erreichen, wird zufällig einer ausgewählt. Eine Liste und Beschreibung der Predicate- (Filtering) und Priority- (Scoring) Richtlinien sind zu finden in .
Beschreibung des Problems
Trotz der Vielzahl an unterschiedlichen Kubernetes-Clustern, die von Nixys betreut werden, sind wir erstmals auf das Problem der Pods-Planung gestoßen, als wir für eines unserer Projekte eine große Anzahl von regelmäßigen Aufgaben (~100 CronJob-Entitäten) starten mussten. Um das Problem bestmöglich zu veranschaulichen, nehmen wir als Beispiel einen Mikroservice, bei dem einmal pro Minute eine Cron-Aufgabe gestartet wird, die eine gewisse CPU-Last erzeugt. Für den Betrieb der Cron-Aufgabe wurden drei absolut identische Nodes (jeweils 24 vCPU) zugewiesen.
Es lässt sich jedoch nicht genau vorhersagen, wie lange die CronJob-Ausführung dauern wird, da das Volumen der Eingangsdaten ständig variiert. Durchschnittlich, bei normalem Betrieb des kube-schedulers, laufen auf jeder Node 3-4 Instanzen der Aufgabe, die etwa 20-30 % der CPU-Last jeder Node erzeugen:
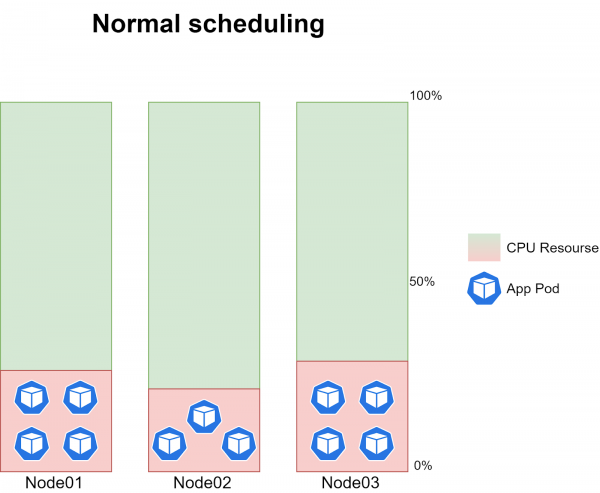
Das eigentliche Problem besteht darin, dass manchmal die Cron-Jobs auf einem der drei Knoten nicht geplant wurden. Das bedeutet, dass zu einem bestimmten Zeitpunkt auf einem der Knoten keine Pods geplant waren, während auf den anderen beiden Knoten jeweils 6-8 Instanzen der Aufgabe liefen, was etwa 40-60% CPU-Auslastung erzeugte.
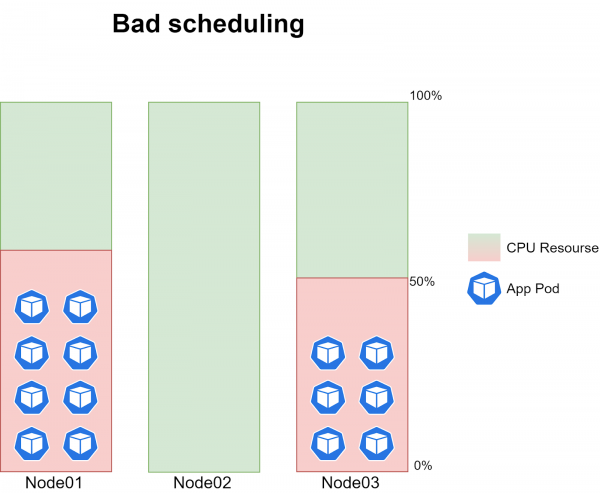
Das Problem trat mit absolut zufälliger Periodizität auf und korrelierte gelegentlich mit dem Moment der Bereitstellung einer neuen Codeversion.
Durch die Erhöhung des Protokollierungsniveaus des Kube-Schedulers auf Stufe 10 (-v=10) begannen wir zu protokollieren, wie viele Punkte jeder der Knoten im Bewertungsprozess erhält. Bei normalem Planungsverhalten konnte man in den Protokollen folgende Informationen sehen:
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: Ausgewogene Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1387 Milli-Core 4161694720 Byte Arbeitsspeicher, Punktzahl 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: Ausgewogene Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1347 Milli-Core 4444810240 Byte Arbeitsspeicher, Punktzahl 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: Minimale Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1387 Milli-Core 4161694720 Byte Arbeitsspeicher, Punktzahl 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: Ausgewogene Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1687 Milli-Core 4790840320 Byte Arbeitsspeicher, Punktzahl 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: Minimale Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1347 Milli-Core 4444810240 Byte Arbeitsspeicher, Punktzahl 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: Minimale Ressourcenallokation, Kapazität 23900 Milli-Core 67167186944 Byte Arbeitsspeicher, Gesamtanforderung 1687 Milli-Core 4790840320 Byte Arbeitsspeicher, Punktzahl 9
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: Node-Affinitäts-Priorität, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: Node-Affinitäts-Priorität, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: Node-Affinitäts-Priorität, Punktzahl: (0)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node01: InterPod-Affinitäts-Priorität, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: Taint-Toleranz-Priorität, Punktzahl: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node02: InterPod-Affinitäts-Priorität, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: Taint-Toleranz-Priorität, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node01: Selektorverteilung-Priorität, Punktzahl: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node03: InterPod-Affinitäts-Priorität, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: Taint-Toleranz-Priorität, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node02: Selektorverteilung-Priorität, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node03: Selektorverteilung-Priorität, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: Selektorverteilung-Priorität, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: Selektorverteilung-Priorität, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: Selektorverteilung-Priorität, Punktzahl: (10)
generic_scheduler.go:781] Host Node01 -> Punktzahl 100043
generic_scheduler.go:781] Host Node02 -> Punktzahl 100043
generic_scheduler.go:781] Host Node03 -> Punktzahl 100043Das bedeutet, dass gemäß den Informationen aus den Logs jede der Knoten eine gleiche Anzahl an Gesamtpunkten erreicht hat und zufällig ausgewählt wurde. Zum Zeitpunkt der problematischen Planung sahen die Logs folgendermaßen aus:
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: BalancedResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 1587 millicores 4581125120 Speicherbytes, Punktzahl 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: BalancedResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 1087 millicores 3532549120 Speicherbytes, Punktzahl 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: LeastResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 1587 millicores 4581125120 Speicherbytes, Punktzahl 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: BalancedResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 987 millicores 3322833920 Speicherbytes, Punktzahl 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: LeastResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 987 millicores 3322833920 Speicherbytes, Punktzahl 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: LeastResourceAllocation, Kapazität 23900 millicores 67167186944 Speicherbytes, Gesamtanfrage 1087 millicores 3532549120 Speicherbytes, Punktzahl 9
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node03: InterPodAffinityPriority, Punktzahl: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node02: InterPodAffinityPriority, Punktzahl: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node01: InterPodAffinityPriority, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: TaintTolerationPriority, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node03: SelectorSpreadPriority, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node02: SelectorSpreadPriority, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: TaintTolerationPriority, Punktzahl: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node01: SelectorSpreadPriority, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: NodeAffinityPriority, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: SelectorSpreadPriority, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: SelectorSpreadPriority, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: TaintTolerationPriority, Punktzahl: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: NodeAffinityPriority, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: NodeAffinityPriority, Punktzahl: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: SelectorSpreadPriority, Punktzahl: (10)
generic_scheduler.go:781] Host Node03 => Punktzahl 100041
generic_scheduler.go:781] Host Node02 => Punktzahl 100041
generic_scheduler.go:781] Host Node01 => Punktzahl 100038Es war ersichtlich, dass einer der Knoten weniger Gesamtpunkte als die anderen erzielt hat, weshalb die Planung nur auf die beiden Knoten mit der höchsten Punktzahl ausgeführt wurde. So konnten wir sicherstellen, dass das Problem tatsächlich in der Planung der Pods liegt.
Der nächste Schritt zur Problemlösung war für uns klar — die Protokolle zu analysieren, herauszufinden, aus welchem Grund der Knoten nicht genügend Punkte erreicht hat, und gegebenenfalls die Standardrichtlinien des kube-schedulers anzupassen. Doch hier sahen wir uns mit zwei wesentlichen Herausforderungen konfrontiert:
- Auf der höchsten Protokollierungsebene (10) werden Punkte nur für einige Prioritäten angezeigt. Im obigen Auszug aus den Protokollen wird deutlich, dass die Knoten in einer normalen und problematischen Planung bei allen im Protokoll dargestellten Prioritäten die gleiche Punktzahl erreichen, jedoch das Endergebnis bei problematischer Planung abweicht. Daraus lässt sich schließen, dass für bestimmte Prioritäten die Punkte 'hinter den Kulissen' gezählt werden, und wir keine Möglichkeit haben zu verstehen, nach welcher spezifischen Priorität der Knoten nicht genug Punkte gesammelt hat. Wir haben dieses Problem ausführlich in dem Kubernetes-Repository auf Github beschrieben. Zum Zeitpunkt der Erstellung des Artikels erhielten wir von den Entwicklern die Rückmeldung, dass die Unterstützung der Protokollierung in den Updates von Kubernetes v1.15, 1.16 und 1.17 hinzugefügt wird.
- Es gibt keinen einfachen Weg zu verstehen, mit welchem spezifischen Satz von Richtlinien der kube-scheduler derzeit arbeitet. Ja, diese Liste ist aufgeführt, aber sie enthält keine Informationen darüber, welche spezifischen Gewichte jeder der Prioritätsrichtlinien zugewiesen sind. Die Gewichte zu sehen oder die Richtlinien des Standard-kube-schedulers zu bearbeiten, kann man nur in den Quellcodes. .
Es ist erwähnenswert, dass wir einmal festgestellt haben, dass ein Knoten keine Punkte gemäß der ImageLocalityPriority-Politik sammelte, die Punkte für Knoten vergibt, wenn bereits ein Abbild vorhanden ist, das zum Starten der Anwendung benötigt wird. Das bedeutet, dass zum Zeitpunkt des Rollouts einer neuen Version der Cron-Job es schaffte, auf zwei Knoten zu starten und dabei das neue Abbild aus dem Docker-Registry herunterzuladen, sodass diese beiden Knoten eine höhere Gesamtbewertung im Vergleich zum dritten Knoten erhielten.
Wie bereits erwähnt, sehen wir in den Logs keine Informationen zur Bewertung der ImageLocalityPriority-Politik. Um meine Annahme zu überprüfen, haben wir das Abbild mit der neuen Version der Anwendung auf den dritten Knoten übertragen, wonach die Planung korrekt zu funktionieren begann. Aufgrund der ImageLocalityPriority-Politik trat das Planungsproblem relativ selten auf; es war meist mit etwas anderem verbunden. Da wir nicht in der Lage waren, jede der Politiken in der Prioritätenliste des Standard-Kube-Schedulers umfassend zu debuggen, wurde der Bedarf an flexibler Verwaltung der Pod-Planungspolitiken offensichtlich.
Problemstellung
Wir wollten, dass die Problemlösung so punktgenau wie möglich ist, das heißt, die wichtigsten Komponenten von Kubernetes (hier ist der Standard-kube-scheduler gemeint) sollten unverändert bleiben. Wir wollten das Problem nicht an einer Stelle lösen und an einer anderen neu schaffen. Daher haben wir zwei Lösungsansätze entwickelt, die im Einführungsteil des Artikels angesprochen wurden – die Erstellung eines zusätzlichen Schemas oder die Entwicklung eines eigenen. Die Hauptanforderung an die Planung von Cron-Jobs ist eine gleichmäßige Lastverteilung über drei Knoten. Dieses Kriterium kann bereits mit den vorhandenen Richtlinien des kube-schedulers erfüllt werden, weshalb es keinen Sinn macht, einen eigenen Scheduler zu schreiben.
Die Anleitung zur Erstellung und Bereitstellung eines zusätzlichen kube-schedulers ist in . Wir kamen jedoch zu dem Schluss, dass die Deployment-Entitäten nicht ausreichen, um die Fehlertoleranz eines so kritischen Dienstes wie kube-scheduler zu gewährleisten. Daher haben wir uns entschieden, einen neuen kube-scheduler als Static Pod bereitzustellen, der direkt von Kubelet überwacht wird. Somit ergeben sich folgende Anforderungen an den neuen kube-scheduler:
- Der Dienst muss als Static Pod auf allen Master-Knoten des Clusters bereitgestellt werden.
- Für den Fall einer Nichtverfügbarkeit des aktiven Pods mit dem kube-scheduler sollte Redundanz eingeplant werden.
- Bei der Planung sollte die Verfügbarkeit der Ressourcen auf dem Node (LeastRequestedPriority) oberste Priorität haben.
Implementierung der Lösung.
Es sollte erwähnt werden, dass alle Arbeiten in Kubernetes v1.14.7 durchgeführt werden, da genau diese Version im Projekt verwendet wurde. Lassen Sie uns mit dem Schreiben des Manifests für unseren neuen kube-scheduler beginnen. Wir orientieren uns am Manifest des Default (/etc/kubernetes/manifests/kube-scheduler.yaml) und passen es wie folgt an:
kind: Pod
metadata:
labels:
component: scheduler
tier: control-plane
name: kube-scheduler-cron
namespace: kube-system
spec:
containers:
- command:
- /usr/local/bin/kube-scheduler
- --address=0.0.0.0
- --port=10151
- --secure-port=10159
- --config=/etc/kubernetes/scheduler-custom.conf
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --v=2
image: gcr.io/google-containers/kube-scheduler:v1.14.7
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10151
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler-cron-container
resources:
requests:
cpu: '0.1'
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kube-config
readOnly: true
- mountPath: /etc/localtime
name: localtime
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom.conf
name: scheduler-config
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom-policy-config.json
name: policy-config
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kube-config
- hostPath:
path: /etc/localtime
name: localtime
- hostPath:
path: /etc/kubernetes/scheduler-custom.conf
type: FileOrCreate
name: scheduler-config
- hostPath:
path: /etc/kubernetes/scheduler-custom-policy-config.json
type: FileOrCreate
name: policy-configKurzübersicht der wichtigsten Änderungen:
- Wir haben den Namen des Pods und des Containers auf kube-scheduler-cron geändert.
- Wir haben die Verwendung der Ports 10151 und 10159 festgelegt, da eine Option definiert wurde.
hostNetwork: trueund wir können nicht dieselben Ports wie der standardmäßige kube-scheduler (10251 und 10259) verwenden. - Mit dem Parameter —config haben wir die Konfigurationsdatei angegeben, mit der der Dienst gestartet werden soll.
- Wir haben das Einbinden der Konfigurationsdatei (scheduler-custom.conf) und der Planungsrichtliniendatei (scheduler-custom-policy-config.json) vom Host konfiguriert.
Vergessen wir nicht, dass unser kube-scheduler die gleichen Berechtigungen wie der Standard benötigt. Wir bearbeiten seine Clusterrolle:
kubectl edit clusterrole system:kube-scheduler...
resourceNames:
- kube-scheduler
- kube-scheduler-cron
...Jetzt sprechen wir darüber, was in der Konfigurationsdatei und der Datei mit den Planungsrichtlinien enthalten sein sollte:
- Konfigurationsdatei (scheduler-custom.conf)
Um die Konfiguration des Standard-kube-schedulers zu erhalten, muss der Parameter verwendet werden:--write-config-tovon . Die erhaltene Konfiguration wird in der Datei /etc/kubernetes/scheduler-custom.conf abgelegt und wie folgt formatiert:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: kube-scheduler-cron
bindTimeoutSeconds: 600
clientConnection:
acceptContentTypes: ""
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/scheduler.conf
qps: 50
disablePreemption: false
enableContentionProfiling: false
enableProfiling: false
failureDomains: kubernetes.io/hostname,failure-domain.beta.kubernetes.io/zone,failure-domain.beta.kubernetes.io/region
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 0.0.0.0:10151
leaderElection:
leaderElect: true
leaseDuration: 15s
lockObjectName: kube-scheduler-cron
lockObjectNamespace: kube-system
renewDeadline: 10s
resourceLock: endpoints
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10151
percentageOfNodesToScore: 0
algorithmSource:
policy:
file:
path: "/etc/kubernetes/scheduler-custom-policy-config.json"Kurzübersicht der wichtigsten Änderungen:
- Im schedulerName haben wir den Namen unseres Services kube-scheduler-cron festgelegt.
- Im Parameter
lockObjectNamemuss ebenfalls der Name unseres Services angegeben werden und sichergestellt werden, dass der ParameterleaderElectauf true gesetzt ist (wenn Sie nur einen Master-Knoten haben, kann dieser auf false gesetzt werden). - Wir haben den Pfad zur Datei mit der Beschreibung der Planungsrichtlinien im Parameter
algorithmSource.
Es ist wichtig, näher auf den zweiten Punkt einzugehen, wo wir die Parameter für den Schlüssel leaderElection. Um die Ausfallsicherheit zu gewährleisten, haben wir den Prozess der Wahl des Leaders (Masters) zwischen den Pods unseres kube-schedulers aktiviert (leaderElect) durch die Verwendung eines gemeinsamen Endpunkts (resourceLock) mit dem Namen kube-scheduler-cron (lockObjectName) im Namensraum kube-system (lockObjectNamespace). Informationen zur Sicherstellung der Hochverfügbarkeit wichtiger Komponenten (einschließlich kube-scheduler) in Kubernetes finden Sie in .
- Datei für die Planungsrichtlinien (scheduler-custom-policy-config.json)
Wie bereits erwähnt, können wir nur durch die Analyse des Codes herausfinden, mit welchen spezifischen Richtlinien der Standard-kube-scheduler arbeitet. Das bedeutet, dass wir die Datei mit den Planungsrichtlinien des Standard-kube-schedulers nicht im Vergleich zur Konfigurationsdatei erhalten können. Wir werden die für uns interessanten Planungsrichtlinien in der Datei /etc/kubernetes/scheduler-custom-policy-config.json wie folgt beschreiben:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "GeneralPredicates"
}
],
"priorities": [
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"name": "EqualPriority",
"weight": 1
},
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "NodePreferAvoidPodsPriority",
"weight": 10000
},
{
"name": "NodeAffinityPriority",
"weight": 1
}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}Der kube-scheduler erstellt zunächst eine Liste von Knoten, auf denen ein Pod gemäß der GeneralPredicates-Politik geplant werden kann (die eine Reihe von Politiken wie PodFitsResources, PodFitsHostPorts, HostName und MatchNodeSelector umfasst). Anschließend wird jede Knoten gemäß der Prioritäten im Prioritäten-Array bewertet. Um die Anforderungen unserer Aufgabe zu erfüllen, haben wir entschieden, dass dieser Satz von Politiken die optimale Lösung darstellt. Ich erinnere daran, dass der Satz von Politiken mit detaillierten Beschreibungen verfügbar ist in . Um Ihre Aufgabe zu erfüllen, können Sie einfach den verwendeten Politikensatz ändern und ihnen die entsprechenden Gewichtungen zuweisen.
Das Manifest des neuen kube-schedulers, das wir zu Beginn des Kapitels erstellt haben, nennen wir kube-scheduler-custom.yaml und speichern es unter dem folgenden Pfad /etc/kubernetes/manifests auf drei Master-Knoten. Wenn alles korrekt ausgeführt wurde, wird Kubelet auf jedem Knoten einen Pod starten, und in den Logs unseres neuen kube-schedulers werden wir Informationen sehen, dass unsere Politiken erfolgreich angewendet wurden:
Scheduler wird aus der Konfiguration erstellt: {{ } [{GeneralPredicates }] [{ServiceSpreadingPriority 1 } {EqualPriority 1 } {LeastRequestedPriority 1 } {NodePreferAvoidPodsPriority 10000 } {NodeAffinityPriority 1 } ] [] 10 false}
Registrierung des Prädikats: GeneralPredicates
Prädikatstyp GeneralPredicates ist bereits registriert, wird wiederverwendet.
Registrierung der Priorität: ServiceSpreadingPriority
Prioritätstyp ServiceSpreadingPriority ist bereits registriert, wird wiederverwendet.
Registrierung der Priorität: EqualPriority
Prioritätstyp EqualPriority ist bereits registriert, wird wiederverwendet.
Registrierung der Priorität: LeastRequestedPriority
Prioritätstyp LeastRequestedPriority ist bereits registriert, wird wiederverwendet.
Registrierung der Priorität: NodePreferAvoidPodsPriority
Prioritätstyp NodePreferAvoidPodsPriority ist bereits registriert, wird wiederverwendet.
Registrierung der Priorität: NodeAffinityPriority
Prioritätstyp NodeAffinityPriority ist bereits registriert, wird wiederverwendet.
Scheduler wird mit passenden Prädikaten 'map[GeneralPredicates:{}]' und Prioritätsfunktionen 'map[EqualPriority:{} LeastRequestedPriority:{} NodeAffinityPriority:{} NodePreferAvoidPodsPriority:{} ServiceSpreadingPriority:{}]' erstellt.Jetzt muss nur noch in der Spezifikation unserer CronJob-Definition angegeben werden, dass alle Anfragen zur Planung ihrer Pods von unserem neuen kube-scheduler verarbeitet werden sollen:
...
jobTemplate:
spec:
template:
spec:
schedulerName: kube-scheduler-cron
...Fazit
Schließlich haben wir einen zusätzlichen kube-scheduler mit einem einzigartigen Satz von Scheduling-Richtlinien eingerichtet, dessen Arbeit direkt von kubelet überwacht wird. Darüber hinaus haben wir die Wahl eines neuen Leaders zwischen den Pods unseres kube-schedulers konfiguriert, falls der alte Leader aus irgendwelchen Gründen nicht mehr verfügbar ist.
Reguläre Anwendungen und Dienste werden weiterhin über den Standard-kube-scheduler geplant, während alle Cron-Jobs vollständig auf den neuen umgestellt wurden. Die von Cron-Jobs erzeugte Last wird jetzt gleichmäßig auf alle Knoten verteilt. Da die meisten Cron-Jobs auf denselben Knoten ausgeführt werden wie die Hauptanwendungen des Projekts, konnte das Risiko der Migration von Pods aufgrund von Ressourcenmangel erheblich verringert werden. Nach der Implementierung des zusätzlichen kube-schedulers traten keine Probleme mit der ungleichen Planung von Cron-Jobs mehr auf.
Lesen Sie auch andere Artikel in unserem Blog:
Quelle: habr.com
