

Es stellt sich regelmäßig die Aufgabe, verwandte Daten anhand einer Reihe von Schlüsseln zu finden, bis wir die benötigte Gesamtanzahl an Datensätzen erreicht haben..
Das gängigste Beispiel ist, die 20 ältesten Aufgaben anzuzeigen,die auf der Liste der Mitarbeiter stehen, (zum Beispiel innerhalb einer Abteilung). Für verschiedene Management-Dashboards mit kurzen Zusammenfassungen zu den Arbeitsbereichen ist ein solches Thema häufig erforderlich. In diesem Artikel betrachten wir die Implementierung einer „naiven“ Lösung für eine solche Aufgabe in PostgreSQL sowie eine „intelligentere“ und ganz komplexe Algorithmus-„Schleife“ in SQL mit einem Ausstiegsbedingung basierend auf gefundenen Daten,

die sowohl für die allgemeine Weiterbildung als auch für die Anwendung in anderen ähnlichen Fällen nützlich sein kann. Lassen Sie uns einen Beispieldatensatz ausdem vorherigen Artikel nehmen. Um sicherzustellen, dass die ausgegebenen Datensätze bei Übereinstimmung der sortierten Werte nicht von Mal zu Mal „hüpfen“,
erweitern wir den Index, indem wir den Primärschlüssel hinzufügen. . Um sicherzustellen, dass die ausgegebenen Einträge bei gleichen sortierten Werten nicht "springen", erweitern wir den Index durch die Hinzufügung des Primärschlüssels.Das verleiht ihm zudem sofortige Einzigartigkeit und garantiert uns eine eindeutige Sortierreihenfolge:
INDEX FÜR task(owner_id, task_date, id) ERSTELLEN;
-- und entfernen wir den alten
INDEX task_owner_id_task_date_idx HEBEN;So wie es klingt, so wird es geschrieben
Zunächst entwerfen wir die einfachste Anfrage, indem wir die IDs der Ausführer übergeben :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
Es ist etwas enttäuschend – wir haben nur 20 Datensätze angefordert, aber der Index-Scan hat uns 960 Zeilen zurückgegeben, die wir dann auch noch sortieren mussten… Lassen Sie uns versuchen, weniger zu lesen.
unnest + ARRAY
Der erste Gedanke, der uns helfen wird – wenn wir nur 20 sortierte Datensätze brauchen, reicht es, nicht mehr als 20 sortierte in derselben Reihenfolge pro Schlüssel zu lesen. Glücklicherweise haben wir einen geeigneten Index (owner_id, task_date, id). Wir nutzen dasselbe Extraktions- und „Spaltenumwandlungs“-Mechanismus
der vollständigen Tabelle , wie auch in. Zudem wenden wir die Aggregation in ein Array mit der Funktion ARRAY() WITH T AS ( SELECT unnest(ARRAY( SELECT t FROM task t WHERE owner_id = unnest ORDER BY task_date, id LIMIT 20 -- hier begrenzen wir... )) r FROM unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[]) ) SELECT (r).* FROM T ORDER BY (r).task_date, (r).id LIMIT 20; -- ... und hier auch - ebenfalls:
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- hier begrenzen wir...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... und hier ebenfalls - 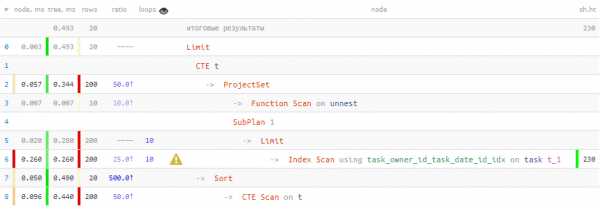
Oh, das ist schon viel besser! 40 % schneller und 4,5 Mal weniger Daten musste gelesen werden.
Materialisierung von Tabelleneinträgen über CTEIch möchte darauf hinweisen, dass in einigen Fällen der Versuch, sofort mit den Feldern des Datensatzes nach dessen Suche im Unterabfrage zu arbeiten, ohne in CTE zu „verpacken“, zu „Vervielfachung“ des InitPlans proportional zur Anzahl dieser Felder führen kann:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Ergebnis (Kosten=4.77..4.78 Zeilen=1 Breite=16) (tatsächliche Zeit=0.063..0.063 Zeilen=1 Schleifen=1)
Puffer: Shared Hit=16
InitPlan 1 (gibt $0 zurück)
-> Limit (Kosten=0.42..1.19 Zeilen=1 Breite=48) (tatsächliche Zeit=0.031..0.032 Zeilen=1 Schleifen=1)
Puffer: Shared Hit=4
-> Index-Scan mithilfe von task_owner_id_task_date_id_idx auf Aufgabe t (Kosten=0.42..387.57 Zeilen=500 Breite=48) (tatsächliche Zeit=0.030..0.030 Zeilen=1 Schleifen=1)
Index-Bedingung: (owner_id = 1)
Puffer: Shared Hit=4
InitPlan 2 (gibt $1 zurück)
-> Limit (Kosten=0.42..1.19 Zeilen=1 Breite=48) (tatsächliche Zeit=0.008..0.009 Zeilen=1 Schleifen=1)
Puffer: Shared Hit=4
-> Index-Scan mithilfe von task_owner_id_task_date_id_idx auf Aufgabe t_1 (Kosten=0.42..387.57 Zeilen=500 Breite=48) (tatsächliche Zeit=0.008..0.008 Zeilen=1 Schleifen=1)
Index-Bedingung: (owner_id = 1)
Puffer: Shared Hit=4
InitPlan 3 (gibt $2 zurück)
-> Limit (Kosten=0.42..1.19 Zeilen=1 Breite=48) (tatsächliche Zeit=0.008..0.008 Zeilen=1 Schleifen=1)
Puffer: Shared Hit=4
-> Index-Scan mithilfe von task_owner_id_task_date_id_idx auf Aufgabe t_2 (Kosten=0.42..387.57 Zeilen=500 Breite=48) (tatsächliche Zeit=0.008..0.008 Zeilen=1 Schleifen=1)
Index-Bedingung: (owner_id = 1)
Puffer: Shared Hit=4
InitPlan 4 (gibt $3 zurück)
-> Limit (Kosten=0.42..1.19 Zeilen=1 Breite=48) (tatsächliche Zeit=0.009..0.009 Zeilen=1 Schleifen=1)
Puffer: Shared Hit=4
-> Index-Scan mithilfe von task_owner_id_task_date_id_idx auf Aufgabe t_3 (Kosten=0.42..387.57 Zeilen=500 Breite=48) (tatsächliche Zeit=0.009..0.009 Zeilen=1 Schleifen=1)
Index-Bedingung: (owner_id = 1)
Puffer: Shared Hit=4
Die gleiche Datensatz wurde viermal „abgefragt“... Bis PostgreSQL 11 war dieses Verhalten regelmäßig anzutreffen, und die Lösung besteht darin, sie in ein CTE zu „wickeln“, was in diesen Versionen eine eindeutige Grenze für den Optimierer darstellt.
Rekursiver Akkumulator
In der vorherigen Version haben wir insgesamt gelesen 200 Zeilen für die benötigten 20. Nicht mehr 960, aber noch weniger – ist das möglich?
Lassen Sie uns das Wissen nutzen, dass wir benötigen insgesamt 20 Datensätze. Das heißt, wir werden die Datenauslesung nur bis zur Erreichung der benötigten Menge iterieren.
Schritt 1: Startliste
Offensichtlich sollte unsere „Ziel“-Liste aus 20 Datensätzen mit den „ersten“ Datensätzen eines unserer owner_id-Schlüssel beginnen. Daher finden wir zuerst solche „allerersten“ für jeden der Schlüssel und tragen sie in die Liste ein, sortiert nach der Reihenfolge, die wir wollen – (task_date, id).
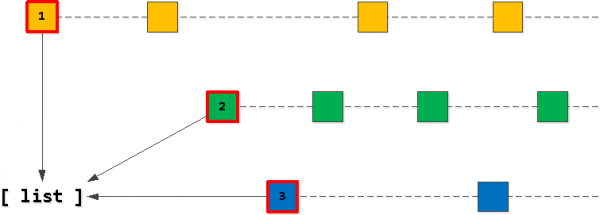
Schritt 2: Finden der „nächsten“ Datensätze
Nun, wenn wir den ersten Datensatz aus unserer Liste nehmen und anfangen, weiter im Index zu „gehen“, während wir den owner_id-Schlüssel beibehalten, dann sind alle gefundenen Datensätze genau die nächsten in der resultierenden Auswahl. Natürlich nur, bis wir den Anwendungskey des zweiten Datensatzes in der Liste überschreiten.
Wenn es so aussieht, dass wir den zweiten Eintrag "überschritten" haben, dann sollte der letzte gelesene Eintrag anstelle des ersten in die Liste aufgenommen werden (mit derselben owner_id), danach sortieren wir die Liste erneut.
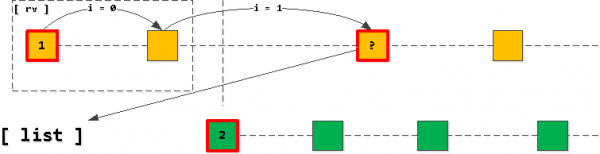
Das bedeutet, dass wir immer nur einen Eintrag pro Schlüssel in der Liste haben (wenn die Einträge aufgebraucht sind und wir die "Grenze" nicht überschritten haben, wird der erste Eintrag einfach entfernt und es wird nichts hinzugefügt), und diese sind immer nach dem aufsteigenden Anwendungs-Schlüssel (task_date, id) sortiert.
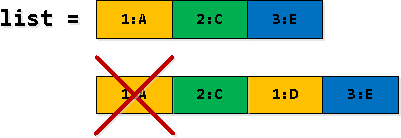
Schritt 3: Wir filtern und "entfalten" die Einträge
In einigen Zeilen unserer rekursiven Auswahl rv werden Einträge dupliziert – zuerst finden wir solche, die "die Grenze des zweiten Eintrags der Liste überschreiten", und setzen sie dann als den ersten in der Liste ein. Das erste Auftreten muss gefiltert werden.
Schrecklicher endgültiger Anfragesatz
MIT REKURSIVE T AS (
-- #1 : Fügen wir die "ersten" Einträge für jeden Schlüssel in die Liste ein
MIT wrap AS ( -- "materialisieren" wir die Datensätze, damit der Zugriff auf die Felder keine Multiplikation von InitPlan/SubPlan erzeugt
MIT T AS (
AUSWÄHLEN
(
AUSWÄHLEN
r
VON
task r
WO
owner_id = unnest
BESTELLEN NACH
task_date, id
LIMIT 1
) r
VON
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
AUSWÄHLEN
array_agg(r BESTELLEN NACH (r).task_date, (r).id) list -- sortieren die Liste in der gewünschten Reihenfolge
VON
T
)
AUSWÄHLEN
list
, list[1] rv
, FALSE not_cross
, 0 size
VON
wrap
UNION ALL
-- #2 : Lesen wir die Einträge des ersten Schlüssels, bis wir über den zweiten Schlüssel hinausgehen
AUSWÄHLEN
FALL
-- wenn nichts für den ersten Eintrag gefunden wurde
WENN X._r IST NICHT UNTERSCHIEDLICH VON NULL DANN
T.list[2:] -- entfernen wir ihn aus der Liste
-- wenn wir den zweiten Schlüssel nicht überschritten haben
WENN X.not_cross THEN
T.list -- ziehen wir einfach die gleiche Liste ohne Modifikationen weiter
-- wenn der zweite Eintrag nicht mehr in der Liste ist
WENN T.list[2] IST NULL DANN
-- einfach eine leere Liste zurückgeben
'{}'
-- sortieren das Dictionary um, entfernen den ersten Eintrag und fügen den letzten der gefundenen hinzu
SONST (
AUSWÄHLEN
coalesce(T.list[2] || array_agg(r BESTELLEN NACH (r).task_date, (r).id), '{}')
VON
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
VON
T
, LATERAL(
MIT wrap AS ( -- "materialisieren" wir die Datensätze
AUSWÄHLEN
FALL
-- wenn wir trotzdem über den zweiten Eintrag hinausgegangen sind
WENN NICHT T.not_cross
-- dann ist der benötigte Datensatz der erste aus der Liste
DANN T.list[1]
SONST ( -- wenn wir ihn nicht überschritten haben, ist der Schlüssel wie im vorherigen Eintrag geblieben - orientieren wir uns daran
AUSWÄHLEN
_r
VON
task _r
WO
owner_id = (rv).owner_id UND
(task_date, id) > ((rv).task_date, (rv).id)
BESTELLEN NACH
task_date, id
LIMIT 1
)
END _r
)
AUSWÄHLEN
_r
, FALL
-- wenn der zweite Eintrag nicht mehr in der Liste ist, aber wir wenigstens etwas gefunden haben
WENN list[2] IST NULL UND _r IST NICHT UNTERSCHIEDLICH VON NULL DANN
TRUE
SONST -- nichts gefunden oder "überschritten"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
VON
wrap
) X
WO
T.size < 20 UND -- begrenzen wir hier die Anzahl
T.list IST NICHT UNTERSCHIEDLICH VON '{}' -- oder bis die Liste nicht mehr existiert
)
-- #3 : "entfalten" wir die Einträge - die Reihenfolge ist durch die Erstellung garantiert
AUSWÄHLEN
(rv).*
VON
T
WO
not_cross; -- nehmen wir nur die "nicht überschreitenden" Einträge 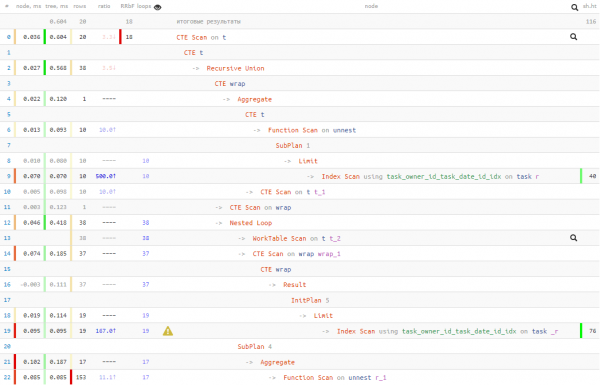
So haben wir 50% Lesevorgänge gegen 20% Laufzeit eingetauscht. Das bedeutet, wenn Sie Grund zur Annahme haben, dass das Lesen lange dauern könnte (z.B. wenn die Daten oft nicht im Cache sind und von der Festplatte abgerufen werden müssen), kann man durch diesen Ansatz weniger auf das Lesen angewiesen sein.
In jedem Fall hat sich die Laufzeit besser ergeben als im „naiven“ ersten Ansatz. Welche dieser 3 Varianten Sie verwenden möchten, liegt an Ihnen.
Quelle: habr.com
