


Obwohl es heute fast überall viele Daten gibt, sind analytische Datenbanken weiterhin recht exotisch. Sie sind schlecht bekannt und noch schlechter effektiv nutzbar. Viele nutzen weiterhin MySQL oder PostgreSQL, die für andere Szenarien ausgelegt sind, kämpfen mit NoSQL oder zahlen überteuerte Preise für kommerzielle Lösungen. ClickHouse verändert die Spielregeln und senkt den Eintrittswiderstand in die Welt der analytischen DBMS erheblich.
Der Vortrag von der BackEnd Conf 2018 ist veröffentlicht worden mit Genehmigung des Referenten.


Wer bin ich und warum spreche ich über ClickHouse? Ich bin der Entwicklungsleiter bei LifeStreet, einem Unternehmen, das ClickHouse einsetzt. Außerdem bin ich der Gründer von Altinity. Das ist ein Partner von Yandex, der ClickHouse fördert und hilft, ClickHouse erfolgreicher zu machen. Ich freue mich auch, mein Wissen über ClickHouse zu teilen.

Und ich bin nicht der Bruder von Petja Zajtsev. Das wird mich oft gefragt. Nein, wir sind keine Brüder.

„Jeder weiß“, dass ClickHouse:
- Sehr schnell ist,
- Sehr benutzerfreundlich ist,
- In Yandex verwendet wird.
Etwas weniger bekannt ist, in welchen Unternehmen und wie es eingesetzt wird.

Ich werde Ihnen erzählen, wofür, wo und wie ClickHouse neben Yandex verwendet wird.
Ich werde erklären, wie spezifische Aufgaben bei verschiedenen Unternehmen mit ClickHouse gelöst werden, welche Werkzeuge ClickHouse Sie für Ihre Anforderungen nutzen können und wie sie in unterschiedlichen Unternehmen eingesetzt wurden.
Ich habe drei Beispiele ausgewählt, die ClickHouse aus verschiedenen Perspektiven zeigen. Ich denke, das wird interessant sein.

Die erste Frage lautet: „Warum benötigen Sie ClickHouse?“. Es scheint eine recht offensichtliche Frage zu sein, aber die Antworten darauf sind zahlreich.

- Die erste Antwort ist – aufgrund der Leistung. ClickHouse ist sehr schnell. Analysen mit ClickHouse sind ebenfalls sehr zügig. Oft kann es dort eingesetzt werden, wo andere Lösungen sehr langsam oder ineffizient arbeiten.
- Die zweite Antwort betrifft die Kosten. Insbesondere die Kosten für das Skalieren. Zum Beispiel ist Vertica eine ausgezeichnete Datenbank. Sie funktioniert sehr gut, wenn Sie nicht allzu viele Terabyte Daten haben. Doch wenn es um Hunderte von Terabyte oder sogar Petabyte geht, steigen die Lizenz- und Supportkosten erheblich. Das kann teuer werden. ClickHouse hingegen ist kostenlos.
- Die dritte Antwort betrifft die Betriebskosten. Dies ist ein etwas anderer Ansatz. RedShift ist eine hervorragende Alternative. Mit RedShift lassen sich sehr schnell Lösungen erstellen. Diese werden gut funktionieren, jedoch müssen Sie stündlich, täglich und monatlich erhebliche Gebühren an Amazon zahlen, da dieser Service recht kostspielig ist. Das gilt auch für Google BigQuery. Wer es genutzt hat, weiß, dass man dort mehrere Abfragen starten und plötzlich Rechnungen in Höhe von mehreren Hundert Dollar erhalten kann.
Diese Probleme gibt es bei ClickHouse nicht.

Wo wird ClickHouse aktuell eingesetzt? Neben Yandex wird ClickHouse in vielen verschiedenen Unternehmen eingesetzt.
- In erster Linie geht es um die Analyse von Webanwendungen, d. h. um einen Anwendungsfall, der von Yandex stammt.
- Viele AdTech-Unternehmen nutzen ClickHouse.
- Zahlreiche Unternehmen, die betriebliche Protokolle aus verschiedenen Quellen analysieren müssen.
- Einige Unternehmen verwenden ClickHouse zur Überwachung von Sicherheitsprotokollen. Sie laden diese in ClickHouse hoch, erstellen Berichte und erhalten die benötigten Ergebnisse.
- Unternehmen beginnen, es in der Finanzanalyse zu nutzen, d. h. allmählich wenden sich auch größere Unternehmen ClickHouse zu.
- CloudFlare. Wer ClickHouse verfolgt, hat sicherlich den Namen dieses Unternehmens gehört. Es ist einer der bedeutendsten Mitwirkenden aus der Community. Zudem haben sie eine sehr umfangreiche ClickHouse-Installation. Zum Beispiel haben sie die Kafka-Engine für ClickHouse entwickelt.
- Telekommunikationsunternehmen haben begonnen, ClickHouse zu nutzen. Einige Firmen verwenden ClickHouse entweder als Proof of Concept oder bereits in der Produktionsumgebung.
- Ein Unternehmen nutzt ClickHouse zur Überwachung von Produktionsprozessen. Sie testen Chips, erfassen zahlreiche Parameter, insgesamt etwa 2.000 Merkmale. Anschließend analysieren sie, ob es sich um eine gute oder schlechte Charge handelt.
- Blockchain-Analytik. Es gibt ein russisches Unternehmen namens Bloxy.info, das die Ethereum-Blockchain analysiert. Auch das haben sie mit ClickHouse realisiert.

Dabei spielt die Größe keine Rolle. Viele Unternehmen nutzen lediglich einen kleinen Server, der ihnen hilft, ihre Probleme zu lösen. Und noch mehr Unternehmen verwenden große Cluster aus vielen Server oder sogar Dutzenden von Servern.
Und wenn wir uns die Rekorde ansehen:
- Yandex: über 500 Server, die täglich 25 Milliarden Datensätze speichern.
- LifeStreet: 60 Server, etwa 75 Milliarden Datensätze pro Tag. Weniger Server, aber mehr Datensätze als bei Yandex.
- CloudFlare: 36 Server, sie speichern 200 Milliarden Datensätze pro Tag. Sie haben noch weniger Server und speichern noch mehr Daten.
- Bloomberg: 102 Server, etwa eine Billion Datensätze pro Tag. Rekordhalter in der Datenspeicherung.
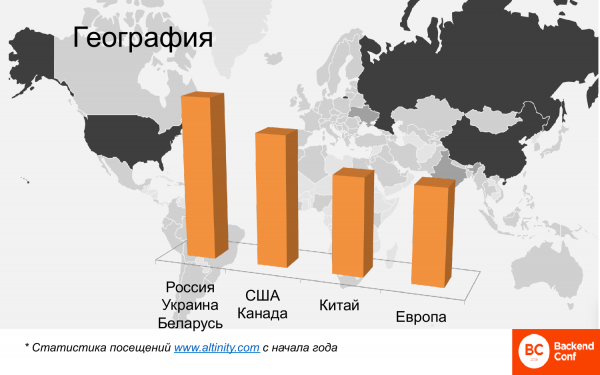
Geografisch ist das ebenfalls viel. Diese Karte zeigt die Heatmap, wo ClickHouse weltweit genutzt wird. Russland, China und Amerika heben sich deutlich hervor. Wenige europäische Länder sind zu sehen. Es lassen sich vier Cluster identifizieren.
Dies ist eine vergleichende Analyse, hier müssen keine absoluten Zahlen gesucht werden. Es handelt sich um die Analyse von Besuchern, die englischsprachige Inhalte auf der Altinity-Website lesen, da es dort keine russischsprachigen Inhalte gibt. Die russischsprachigen Nutzer aus Russland, der Ukraine und Weißrussland gehören zu den zahlreichsten. Anschließend folgen die USA und Kanada. China holt sehr stark auf. Vor einem halben Jahr war China fast nicht vertreten, jetzt hat China Europa bereits überholt und wächst weiter. Auch das alte Europa bleibt nicht zurück, wobei Frankreich überraschenderweise der führende Nutzer von ClickHouse ist.

Warum erzähle ich das alles? Um zu zeigen, dass ClickHouse zu einer Standardlösung für die Analyse großer Datenmengen wird und bereits an vielen Orten eingesetzt wird. Wenn Sie es verwenden, sind Sie auf dem richtigen Weg. Wenn Sie es noch nicht verwenden, brauchen Sie sich keine Sorgen machen, dass Sie allein bleiben und niemand Ihnen hilft, denn bereits viele Unternehmen nutzen es.

Das sind Beispiele für die tatsächliche Nutzung von ClickHouse in verschiedenen Unternehmen.
- Das erste Beispiel ist ein Werbenetzwerk: Der Umstieg von Vertica auf ClickHouse. Ich kenne mehrere Unternehmen, die von Vertica gewechselt sind oder sich im Wechselprozess befinden.
- Das zweite Beispiel ist ein transaktionales Lager auf ClickHouse. Dieses Beispiel basiert auf Anti-Pattern. Alles, was man in ClickHouse laut den Entwicklern vermeiden sollte, wurde hier umgesetzt. Und trotzdem ist es so effektiv, dass es funktioniert – und zwar viel besser als eine typische transaktionale Lösung.
- Das dritte Beispiel sind verteilte Berechnungen auf ClickHouse. Es gab Fragen dazu, wie man ClickHouse in das Hadoop-Ökosystem integrieren kann. Ich werde ein Beispiel zeigen, wie ein Unternehmen auf ClickHouse eine Art Map-Reduce-Container erstellt hat, wobei die Datenlokalisierung usw. beachtet wurde, um eine sehr komplexe Aufgabe zu lösen.

- LifeStreet – Ein Ad-Tech-Unternehmen, das über alle Technologien verfügt, die für ein Werbenetzwerk erforderlich sind.
- Sie beschäftigt sich mit der Optimierung von Anzeigen und programmatic Bidding.
- Es fallen viele Daten an: etwa 10 Milliarden Ereignisse pro Tag. Dabei können diese Ereignisse in mehrere Unterereignisse aufgeteilt werden.
- Es gibt viele Kunden für diese Daten, und es sind nicht nur Menschen, sondern in viel größerem Maße verschiedene Algorithmen, die mit programmatic Bidding arbeiten.

Das Unternehmen hat einen langen und mühsamen Weg hinter sich. Ich habe darüber auf der HighLoad gesprochen. Zuerst wechselte LifeStreet von MySQL (mit einem kurzen Intermezzo bei Oracle) zu Vertica. Dazu gibt es auch einen Erfahrungsbericht.
Und alles lief sehr gut, doch schnell wurde klar, dass die Daten wachsen und Vertica teuer ist. Daher wurden verschiedene Alternativen gesucht. Einige davon sind hier aufgeführt. Tatsächlich haben wir Proof of Concept oder manchmal Performance-Tests für fast alle Datenbanken durchgeführt, die von 2013 bis 2016 auf dem Markt erhältlich waren und in etwa funktional passten. Über einen Teil von ihnen habe ich auch auf der HighLoad gesprochen.

Die Aufgabe bestand darin, zunächst von Vertica zu migrieren, da die Datenmengen stetig wuchsen. Sie wuchsen über mehrere Jahre exponentiell. Danach kamen sie zwar ins Stocken, dennoch war das Wachstum klar abzusehen. Mit der Prognose dieses Wachstums und den geschäftlichen Anforderungen an die Datenmenge für Analysen war abzusehen, dass bald das Thema Petabytes zur Sprache kommen würde. Für Petabytes zu zahlen ist jedoch sehr teuer, weshalb nach einer Alternative gesucht wurde.
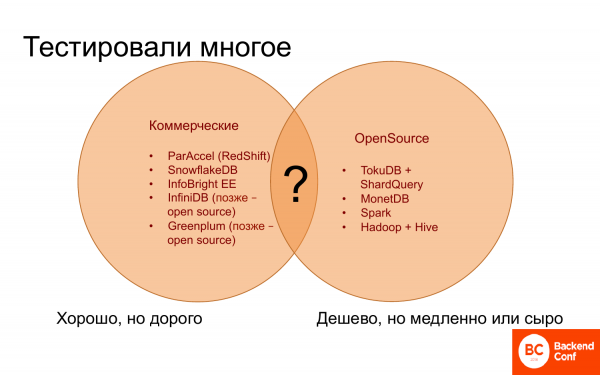
Wohin gehen? Lange Zeit war nicht klar, wohin die Reise gehen sollte, denn einerseits gibt es kommerzielle Datenbanken, die scheinbar gut funktionieren. Einige arbeiten fast so gut wie Vertica, andere weniger gut. Aber sie sind alle teuer, und etwas Besseres und Günstigeres zu finden, war nicht möglich.
Andererseits gibt es Open-Source-Lösungen, von denen es nicht viele gibt. Für analytische Zwecke kann man sie an einer Hand abzählen. Sie sind kostenlos oder günstig, aber sie arbeiten langsam. Oft fehlt es ihnen an der notwendigen und nützlichen Funktionalität.
Um die guten Eigenschaften kommerzieller Datenbanken mit den kostenlosen Funktionen von Open Source zu kombinieren, gab es bisher keine Option.

Bis zu diesem Moment war alles ruhig, bis Yandex plötzlich ClickHouse wie ein Zauberer aus dem Hut zauberte. Es war eine überraschende Lösung, und man fragt sich bis heute: „Warum?“ Dennoch.
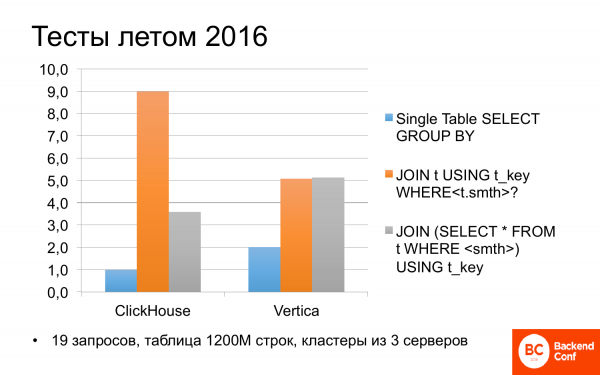
Im Sommer 2016 begannen wir sofort zu erkunden, was ClickHouse eigentlich ist. Dabei stellte sich heraus, dass es manchmal schneller ist als Vertica. Wir testeten verschiedene Szenarien mit unterschiedlichen Anfragen. Wenn die Anfrage nur eine Tabelle verwendete, also ohne Joins, war ClickHouse zweimal schneller als Vertica.
Ich habe nicht gescheut und mir kürzlich auch die Tests von Yandex angeschaut. Das gleiche Ergebnis: ClickHouse ist doppelt so schnell wie Vertica, weshalb sie oft darüber sprechen.
Wenn jedoch Joins in den Anfragen verwendet werden, ist die Situation nicht ganz klar. Dann kann ClickHouse bis zu zweimal langsamer als Vertica sein. Wenn man die Anfrage leicht anpasst und umschreibt, sind die Ergebnisse etwa gleich. Ganz ordentlich. Und kostenlos.

Nachdem wir die Testergebnisse erhalten und aus verschiedenen Perspektiven darauf geschaut hatten, hat LifeStreet auf ClickHouse umgestellt.

Das war 2016, ich erinnere daran. Es war wie der Witz über die Mäuse, die weinten und sich stachen, aber trotzdem den Kaktus weiter aßen. Darüber wurde ausführlich berichtet, es gibt ein Video dazu usw.

Daher werde ich nicht ins Detail gehen, sondern nur die Ergebnisse und einige interessante Aspekte vorstellen, die ich damals nicht erwähnt habe.
Die Ergebnisse sind:
- Erfolgreiche Migration und das System läuft nun seit über einem Jahr produktiv.
- Die Leistung und Flexibilität haben zugenommen. Während wir anfangs 10 Milliarden Datensätze pro Tag speichern konnten, verwaltet LifeStreet jetzt 75 Milliarden Datensätze pro Tag und kann dies über einen Zeitraum von 3 Monaten und mehr tun. In Spitzenzeiten werden bis zu eine Million Ereignisse pro Sekunde aufgezeichnet. Täglich erreichen mehr als eine Million SQL-Anfragen dieses System, hauptsächlich von verschiedenen Bots.
- Obwohl ClickHouse mehr Server verwendet als Vertica, ergaben sich Kosteneinsparungen bei der Hardware, da Vertica teure SAS-Festplatten nutzte. Bei ClickHouse wurden SATA-Festplatten verwendet. Warum? Weil der Insert in Vertica synchron ist. Die Synchronisierung erfordert, dass die Festplatten nicht zu langsam sind und das Netzwerk ebenfalls, was zu hohen Betriebskosten führt. Bei ClickHouse hingegen ist der Insert asynchron. Darüber hinaus können die Daten lokal ohne zusätzliche Kosten geschrieben werden, weshalb Daten in ClickHouse viel schneller eingefügt werden können als in Vertica, selbst auf weniger schnellen Festplatten. Bei der Lesegeschwindigkeit sind sie ungefähr gleich. Das Lesen von SATA-Festplatten, wenn sie im RAID betrieben werden, erfolgt ebenfalls recht schnell.
- Keine Lizenzbeschränkungen, d. h. bis zu 3 Petabyte Daten auf 60 Servern (20 Server sind eine Replik). 6 Billionen Datensätze in Fakten und Aggregaten sind ebenfalls möglich. So etwas konnten wir uns bei Vertica nicht leisten.

Jetzt komme ich zu praktischen Aspekten in diesem Beispiel.
- Erstens – das effiziente Schema. Von dem Schema hängt sehr viel ab.
- Zweitens – die Generierung effizienter SQL-Abfragen.
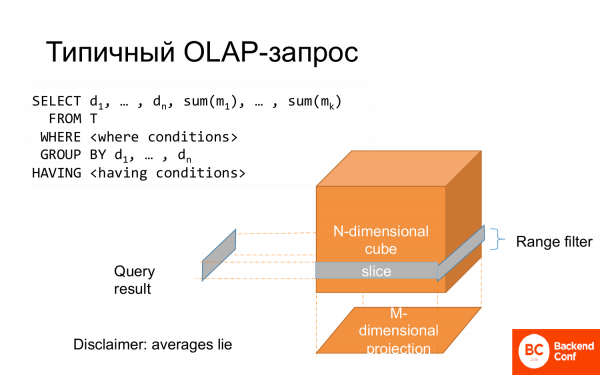
Ein typischer OLAP-Abfrage ist ein SELECT. Einige Spalten kommen in die GROUP BY-Klausel, andere in aggregierte Funktionen. Es gibt eine WHERE-Klausel, die man sich als einen Ausschnitt des Würfels vorstellen kann. Die gesamte GROUP BY-Klausel kann als Projektion angesehen werden. Das wird als multidimensionale Datenanalyse bezeichnet.

Häufig wird dies in Form eines Star-Schemas modelliert, wobei ein zentraler Fakt und die Merkmale dieses Faktors an den Seiten, entlang der Strahlen, dargestellt werden.

In Bezug auf das physische Design, wie es auf eine Tabelle angewendet wird, wird normalerweise eine normalisierte Darstellung verwendet. Man kann sie denormalisieren, aber das ist diskplatzintensiv und nicht besonders effizient in Bezug auf Abfragen. Daher wird in der Regel eine normalisierte Darstellung erstellt, d. h. eine Faktentabelle und viele Dimensionstabellen.
Aber in ClickHouse funktioniert das schlecht. Es gibt zwei Gründe dafür:
- Erstens – weil ClickHouse nicht besonders gute Joins bietet, d. h. Joins sind vorhanden, aber sie sind schlecht. Bisher schlecht.
- Zweitens – weil die Tabellen nicht aktualisiert werden. In der Regel müssen in diesen Tabellen, die um das Star-Schema herum angeordnet sind, Änderungen vorgenommen werden. Zum Beispiel der Name des Kunden, der Name des Unternehmens usw. Und das funktioniert nicht.
Es gibt jedoch einen Ausweg in ClickHouse, sogar gleich zwei:
- Der erste Punkt ist die Verwendung von Wörterbüchern. Externe Wörterbücher helfen zu 99 %, das Problem mit der Star-Schema, Updates und anderem zu lösen.
- Der zweite Punkt ist die Nutzung von Arrays. Arrays helfen ebenfalls, Joins zu vermeiden und Probleme mit der Normalisierung zu beseitigen.

- Joins werden nicht benötigt.
- Aktualisierbar. Seit März 2018 gibt es eine undocumented Möglichkeit (die Sie in der Dokumentation nicht finden werden), um Wörterbücher teilweise zu aktualisieren, d. h. die Einträge, die sich geändert haben. Praktisch betrachtet ist es wie bei einer Tabelle.
- Immer im Speicher, sodass Joins mit dem Wörterbuch schneller arbeiten als bei einer Tabelle, die auf der Festplatte liegt und möglicherweise nicht im Cache ist, was höchstwahrscheinlich der Fall ist.

- Auch Joins sind nicht nötig.
- Dies ist eine kompakte Darstellung von Eins zu Viele.
- Meiner Meinung nach sind Arrays für Geeks gemacht. Es handelt sich um Lambda-Funktionen und Ähnliches.
Das ist nicht nur Geschwätz. Es handelt sich um eine sehr leistungsstarke Funktionalität, die es ermöglicht, viele Dinge sehr einfach und elegant zu tun.

Typische Beispiele, die durch Arrays gelöst werden können. Diese Beispiele sind einfach und sehr anschaulich:
- Suche nach Tags. Wenn Sie dort Hashtags haben und Sie möchten Einträge nach einem Hashtag finden.
- Suche nach key-value-Paaren. Es gibt auch einige Attribute mit Werten.
- Speicherung von Schlüssellisten, die Sie in etwas anderes übersetzen müssen.
All diese Aufgaben können ohne Arrays gelöst werden. Tags können in eine Zeile gepackt und mit regulären Ausdrücken ausgewählt oder in eine separate Tabelle eingefügt werden, aber dann müssen Joins durchgeführt werden.

In ClickHouse ist das nicht nötig, man muss lediglich ein String-Array für Hashtags beschreiben oder eine verschachtelte Struktur für key-value-ähnliche Systeme erstellen.
Verschachtelte Struktur ist vielleicht nicht der beste Begriff. Es handelt sich um zwei Arrays, die einen gemeinsamen Teil im Namen haben und einige verwandte Eigenschaften.
Die Suche nach Tags ist sehr einfach. Es gibt eine Funktion has, die überprüft, ob ein Element im Array vorhanden ist. Damit finden wir alle Einträge, die zu unserer Konferenz gehören.
Die Suche nach subid ist etwas komplizierter. Zuerst müssen wir den Index des Schlüssels finden und dann das Element mit diesem Index abrufen und überprüfen, ob der Wert dem entspricht, was wir brauchen. Aber dennoch ist es sehr einfach und kompakt.
Ein regulärer Ausdruck, den Sie schreiben würden, wenn Sie alles in einer Zeile speichern würden, wäre erstens ungeschickt und zweitens würde er viel länger dauern als zwei Arrays.

Ein weiteres Beispiel. Sie haben ein Array, in dem Sie IDs speichern. Und Sie können diese in Namen umwandeln. Die Funktion arrayMap. Dies ist eine typische Lambda-Funktion. Sie übergeben Lambda-Ausdrücke. Und sie extrahiert den Namen aus dem Wörterbuch für jede ID.
Ähnlich kann die Suche durchgeführt werden. Eine Prädikatfunktion wird übergeben, die überprüft, wonach die Elemente passen.

Diese Dinge vereinfachen das Schema erheblich und lösen viele Probleme.
Aber das nächste Problem, dem wir begegnet sind und über das ich sprechen möchte, sind effiziente Abfragen.
- In ClickHouse gibt es keinen Abfrageplaner. Überhaupt nicht.
- Dennoch müssen komplexe Abfragen trotzdem geplant werden. In welchen Fällen?
- Wenn in der Abfrage mehrere Joins (join) vorhanden sind, die Sie in Unterabfragen verpacken. Und die Reihenfolge, in der sie ausgeführt werden, ist wichtig.
- Und zweitens – wenn die Abfrage verteilt ist. Denn bei einer verteilten Abfrage wird nur der innerste Subquery verteilt ausgeführt, während alles andere an einen Server übergeben wird, mit dem Sie verbunden sind, und dort ausgeführt wird. Daher ist es wichtig, die Reihenfolge zu wählen, wenn Sie verteilte Abfragen mit vielen Joins (join) haben.
Selbst in einfachen Fällen sollte der Abfrageplaner manchmal die Arbeit leisten und die Abfragen leicht umschreiben.

Hier ein Beispiel. Auf der linken Seite eine Abfrage, die die Top 5 Länder zeigt. Sie dauert etwa 2,5 Sekunden. Auf der rechten Seite dieselbe Abfrage, jedoch leicht umformuliert. Anstatt nach Zeilen zu gruppieren, haben wir nach Schlüssel (int) gruppiert. Und das ist schneller. Danach haben wir das Ergebnis mit einem Dictionary verbunden. Statt 2,5 Sekunden benötigt die Abfrage jetzt nur noch 1,5 Sekunden. Das ist gut.

Ein ähnliches Beispiel für das Umschreiben von Filtern. Hier eine Abfrage für Russland. Sie dauert 5 Sekunden. Wenn wir sie so umschreiben, dass wir nicht wieder mit Zeichenfolgen, sondern mit Zahlen aus einem Set von Schlüsseln, die zu Russland gehören, vergleichen, wird es viel schneller.

Es gibt viele solcher Tricks. Sie ermöglichen es, Anfragen, die bereits schnell erscheinen, noch weiter zu beschleunigen oder umgekehrt, solche, die langsam erscheinen, schneller zu machen.

- Maximaler Arbeitseinsatz im verteilten Modus.
- Sortierung nach minimalen Typen, so wie ich es mit den Intents gemacht habe.
- Wenn es irgendwelche Joins oder Dictionaries gibt, ist es besser, diese erst ganz am Ende zu implementieren, wenn die Daten wenigstens teilweise gruppiert sind. Dann werden die Join-Operationen oder Dictionary-Abfragen seltener benötigt, was die Geschwindigkeit erhöht.
- Austausch von Filtern.
Es gibt noch weitere Techniken, nicht nur die, die ich demonstriert habe. Alles zusammen kann manchmal die Ausführung von Anfragen erheblich beschleunigen.

Kommen wir zum nächsten Beispiel. Unternehmen X aus den USA. Was macht es?
Die Aufgabe lautete:
- Offline-Verknüpfung von Werbetransaktionen.
- Modellierung unterschiedlicher Verknüpfungsmodelle.

Worin besteht das Szenario?
Ein typischer Besucher besucht die Website etwa 20 Mal im Monat, sei es durch verschiedene Anzeigen oder einfach nur so, weil er sich an die Seite erinnert. Er schaut sich Produkte an, legt sie in den Warenkorb und nimmt sie wieder heraus. Schließlich kauft er etwas.
Wichtige Fragen sind: "Wer muss für die Werbung bezahlen, wenn es nötig ist?" und "Welche Werbung hat ihn beeinflusst, falls es eine gab?" Das heißt, warum hat er gekauft und wie können wir dafür sorgen, dass auch andere ähnliche Personen kaufen?
Um dieses Ziel zu erreichen, müssen die Ereignisse auf der Website auf die richtige Weise miteinander verknüpft werden, das heißt, es sollte eine Verbindung zwischen ihnen hergestellt werden. Diese Informationen werden dann zur Analyse an ein DWH übermittelt. Basierend auf dieser Analyse werden Modelle entwickelt, um zu entscheiden, welche Werbung wem gezeigt werden sollte.

Eine Werbetransaktion ist eine Reihe miteinander verbundener Benutzerereignisse, die mit der Anzeige einer Werbung beginnt, gefolgt von weiteren Aktionen, eventuell einem Kauf, und möglicherweise weiteren Käufen. Zum Beispiel, wenn es sich um eine mobile Anwendung oder ein mobiles Spiel handelt, erfolgt in der Regel die Installation der Anwendung kostenlos; wenn im Anschluss jedoch weitere Aktionen durchgeführt werden, können dafür Kosten anfallen. Je mehr eine Person in der Anwendung ausgibt, desto wertvoller wird sie. Aber dafür müssen alle Aktionen miteinander verknüpft werden.

Es gibt viele Modelle zur Verknüpfung.
Die beliebtesten sind:
- Last Interaction, wobei Interaction entweder ein Klick oder eine Anzeige ist.
- First Interaction, d. h. das erste Ereignis, das den Benutzer auf die Webseite führte.
- Lineare Kombination – alle gleich.
- Abschwächung.
- Und weitere.
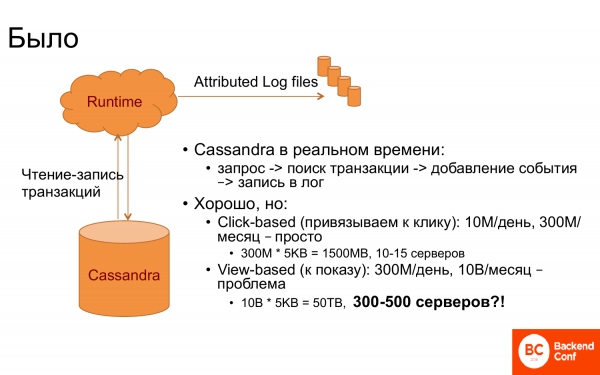
Und wie hat das ursprünglich funktioniert? Es gab Runtime und Cassandra. Cassandra wurde als Transaktionsspeicher verwendet, d. h. alle verbundenen Transaktionen wurden dort gespeichert. Wenn ein Ereignis in Runtime eintritt, wie z. B. die Anzeige einer bestimmten Seite oder ähnliches, wird eine Anfrage an Cassandra gestellt – gibt es diesen Benutzer oder nicht. Dann werden die Transaktionen abgerufen, die ihm zugeordnet sind, und die Verknüpfung wird durchgeführt.
Wenn es Glück gibt und die Anfrage eine Transaktions-ID enthält, ist das kein Problem. Aber normalerweise hat man nicht so viel Glück. Daher musste man die letzte Transaktion oder die Transaktion mit dem letzten Klick finden, und so weiter.
Das hat gut funktioniert, solange die Bindung an den letzten Klick geknüpft war. Denn sagen wir, es gab 10 Millionen Klicks pro Tag, also 300 Millionen pro Monat, wenn man das Monat als Zeitraum betrachtet. Und da in Cassandra alles im Speicher sein muss, damit es schnell funktioniert und die Runtime schnell antworten kann, benötigte man etwa 10-15 Server.
Doch als man begann, die Transaktion an die Anzeigen zu binden, wurde es sofort komplizierter. Warum? Man musste nun 30 Mal mehr Ereignisse speichern. Das bedeutet, man braucht auch 30 Mal mehr Server. Und das ergibt eine astronomische Zahl. Bis zu 500 Server zu halten, nur um eine Bindung herzustellen, während es in der Runtime deutlich weniger Server gibt, ist einfach nicht nachhaltig. Also überlegten wir, was zu tun ist.

Schließlich entschieden wir uns für ClickHouse. Aber wie geht man das mit ClickHouse an? Auf den ersten Blick scheint es, als handele es sich um eine Sammlung von Anti-Patterns.
- Die Transaktion wächst, wir binden immer neue Events ein, das heißt, sie ist veränderbar, und ClickHouse funktioniert nicht besonders gut mit veränderbaren Objekten.
- Wenn ein Besucher zu uns kommt, müssen wir seine Transaktionen über den Schlüssel, also seine Besuchs-ID, abrufen. Auch dies ist eine Punktabfrage, die in ClickHouse nicht üblich ist. Normalerweise gibt es in ClickHouse große … Scans, doch hier müssen wir nur einige Datensätze abrufen. Auch das ist ein Antipattern.
- Darüber hinaus war die Transaktion im JSON-Format, aber wir wollten sie nicht umschreiben, daher wollten wir das JSON unstrukturiert speichern und bei Bedarf etwas daraus extrahieren. Auch das ist ein Antipattern.
Das heißt, eine Menge von Antipatterns.
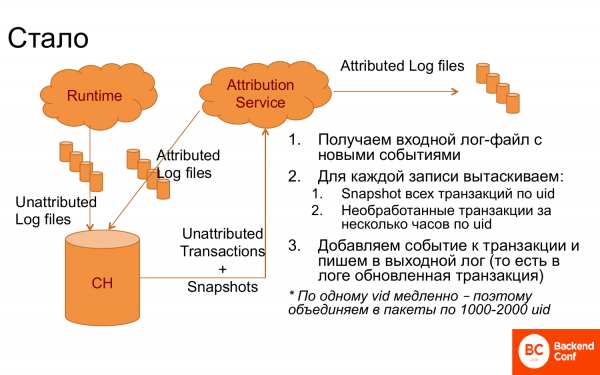
Trotzdem gelang es uns, ein System zu erstellen, das sehr gut funktionierte.
Was wurde getan? ClickHouse wurde implementiert, in den Logs, die nach Einträgen unterteilt sind, werden Daten eingepflegt. Es wurde ein Attributed-Service eingeführt, der die Logs aus ClickHouse bezieht. Anschließend wurden für jede Aufzeichnung anhand der Visit-ID die Transaktionen abgerufen, die eventuell noch nicht verarbeitet waren, sowie Snapshots, d.h. bereits verbundene Transaktionen, die das Ergebnis der vorherigen Arbeit darstellten. Daraus wurde die Logik erstellt, die korrekte Transaktion ausgewählt und neue Ereignisse angebunden. Diese Informationen wurden erneut in das Log geschrieben. Das Log wurde zurück an ClickHouse gesendet, sodass es sich um ein kontinuierliches, kreisförmiges System handelt. Darüber hinaus wurde es ins DWH gesendet, um dort analysiert zu werden.
In dieser Form funktionierte es nicht allzu gut. Um es ClickHouse zu erleichtern, wurden die Abfragen nach Visit-ID in Blöcke von 1.000 bis 2.000 Visit-IDs gruppiert, und alle Transaktionen für 1.000 bis 2.000 Personen wurden abgerufen. Danach lief alles reibungslos.
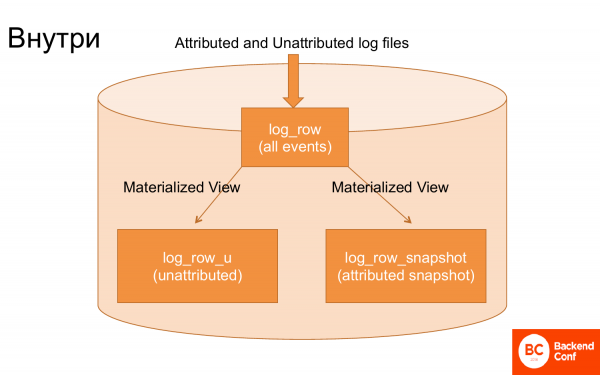
Wenn man in ClickHouse reinschaut, gibt es nur drei Haupttabellen, die alles verwalten.
Die erste Tabelle, in die die Logs geladen werden, empfängt die Daten praktisch ohne Verarbeitung.
Die zweite Tabelle. Über die materialisierte Sicht wurden aus diesen Logs nicht attribuierte Events herausgefiltert, die nicht miteinander verknüpft waren. Und über die materialisierte Sicht wurden Transaktionen zum Erstellen eines Snapshots extrahiert. Das heißt, eine spezielle materialisierte Sicht hat den Snapshot erstellt, nämlich den letzten akkumulierten Zustand der Transaktion.
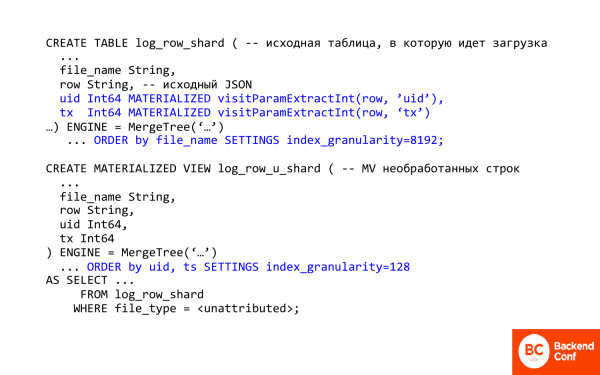
Hier steht ein Text in SQL. Ich möchte einige wichtige Punkte dazu kommentieren.
Der erste wichtige Punkt ist die Möglichkeit, in ClickHouse Spalten und Felder aus JSON zu extrahieren. Das heißt, ClickHouse bietet einige Methoden zur Arbeit mit JSON. Diese sind sehr, sehr primitiv.
visitParamExtractInt ermöglicht es, Attribute aus JSON zu extrahieren, das heißt, die erste Übereinstimmung wird aktiviert. So kann man die Transaction-ID oder die Visit-ID herausziehen. Das ist Punkt eins.
Zweitens – hier wird ein raffiniertes materialisiertes Feld verwendet. Was bedeutet das? Das bedeutet, dass Sie es nicht in die Tabelle einfügen können, das heißt, es wird nicht eingetragen, sondern berechnet und bei der Einfügung gespeichert. Bei der Einfügung erledigt ClickHouse die Arbeit für Sie. Und das, was Sie später benötigen, wird bereits aus dem JSON extrahiert.
In diesem Fall ist die materialisierte Sicht für unverarbeitete Zeilen gedacht. Dabei wird die erste Tabelle mit nahezu Roh-Logs verwendet. Was bewirkt sie? Zunächst einmal ändert sie die Sortierung, d. h. die Sortierung erfolgt jetzt nach der Visit-ID, weil wir schnell die Transaktionen einer bestimmten Person abrufen müssen.
Eine weitere wichtige Sache ist die index_granularity. Wenn Sie MergeTree gesehen haben, beträgt die index_granularity standardmäßig normalerweise 8.192. Was bedeutet das? Es handelt sich um einen Parameter für die Indexpersistenz. In ClickHouse ist der Index spärlich, das heißt, er indiziert niemals jeden einzelnen Datensatz. Er macht das alle 8.192 Einträge. Das ist vorteilhaft, wenn viele Daten berechnet werden müssen, aber nachteilig, wenn es nur wenige sind, weil es einen hohen Overhead schafft. Wenn wir die index_granularity verringern, reduzieren wir den Overhead. Eine Reduzierung auf eins ist nicht möglich, da es möglicherweise nicht genügend Speicher gibt. Der Index wird immer im Speicher gehalten.

Snapshots nutzen zudem einige interessante Funktionen von ClickHouse.
Zunächst haben wir den AggregatingMergeTree. In diesem AggregatingMergeTree wird argMax gespeichert, was dem Zustand der Transaktion entspricht, der mit dem letzten Zeitstempel verbunden ist. Für jeden Besucher werden kontinuierlich neue Transaktionen generiert. Und in den letzten Zustand dieser Transaktion haben wir ein Ereignis hinzugefügt, wodurch ein neuer Zustand entstand. Dieser wurde erneut in ClickHouse gespeichert. Über argMax in dieser materialisierten Sicht können wir immer den aktuellen Zustand abrufen.

- Die Bindung ist von Runtime „gelöst“.
- Es werden bis zu 3 Milliarden Transaktionen pro Monat gespeichert und verarbeitet. Das ist um ein Vielfaches mehr als in Cassandra, das heißt in einem typischen Transaktionssystem.
- Cluster aus 2x5 ClickHouse-Servern. 5 Server und jeder Server hat eine Replik. Das ist sogar weniger als in Cassandra, um eine klickbasierte Attribution zu ermöglichen, während wir hier eine impressionsbasierte haben. Das heißt, anstatt die Anzahl der Server um das 30-Fache zu erhöhen, konnten wir diese Anzahl reduzieren.

Ein letztes Beispiel ist das Finanzunternehmen Y, das die Korrelationen von Aktienkursänderungen analysierte.
Die Aufgabe lautete:
- Es gibt etwa 5.000 Aktien.
- Die Kurse sind alle 100 Millisekunden bekannt.
- Die Daten haben sich über 10 Jahre angesammelt. Offensichtlich haben einige Unternehmen mehr, andere weniger.
- Insgesamt etwa 100 Milliarden Datensätze.
Und es war notwendig, die Korrelation der Veränderungen zu berechnen.
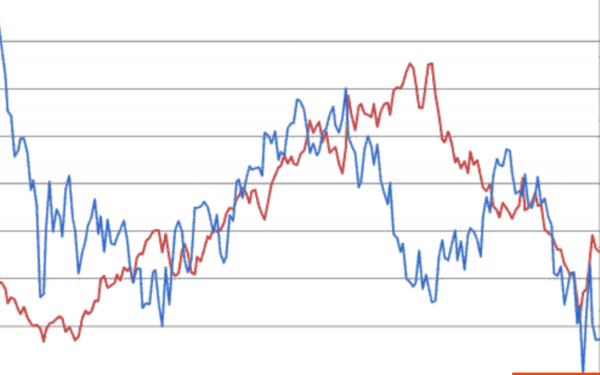
Hier gibt es zwei Aktien und deren Kursentwicklungen. Wenn eine steigt und die andere ebenfalls, dann ist das eine positive Korrelation, d.h. beide wachsen. Wenn eine am Ende des Diagramms steigt und die andere fällt, dann ist das eine negative Korrelation, d.h. wenn eine wächst, sinkt die andere.
Durch die Analyse dieser gegenseitigen Änderungen können Vorhersagen für den Finanzmarkt getroffen werden.

Aber die Aufgabe ist komplex. Was wird dafür gemacht? Wir haben 100 Milliarden Datensätze, die Folgendes enthalten: Zeit, Aktie und Preis. Zuerst müssen wir 100 Milliarden Mal die runningDifference der Preisalgorithmen berechnen. RunningDifference ist eine Funktion in ClickHouse, die die Differenz zwischen zwei aufeinanderfolgenden Zeilen berechnet.
Und danach muss die Korrelation berechnet werden, wobei die Korrelation für jedes Paar ermittelt werden muss. Bei 5.000 Aktien ergeben sich 12,5 Millionen Paare. Das ist viel, d.h. diese Korrelation muss 12,5 Mal berechnet werden.
Und falls jemand es vergessen hat, x und y sind das mathematische Erwartungswert einer Stichprobe. Das bedeutet, dass wir nicht nur die Wurzeln und Summen berechnen müssen, sondern dass innerhalb dieser Summen auch wieder Summen berechnet werden müssen. Eine Menge von Berechnungen muss 12,5 Millionen Mal durchgeführt und nach Stunden gruppiert werden. Und wir haben auch nicht gerade wenig Stunden. Das alles muss in 60 Sekunden geschehen. Das ist ein Scherz.

Wir mussten irgendwie einen Weg finden, denn alles lief sehr, sehr langsam, bevor ClickHouse kam.

Sie haben es mit Hadoop, mit Spark und mit Greenplum versucht. Und all das war sehr langsam oder teuer. Man konnte es irgendwie berechnen, aber es war dann teuer.
Doch dann kam ClickHouse und alles wurde viel besser.
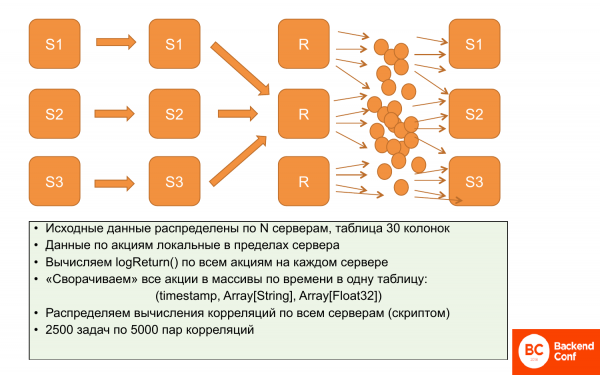
Ich erinnere daran, dass wir das Problem mit der Lokalisierung der Daten haben, denn Korrelationen können nicht lokalisiert werden. Wir können nicht einen Teil der Daten auf einem Server und einen Teil auf einem anderen zusammenfassen; wir müssen alle Daten überall haben.
Was haben sie gemacht? Ursprünglich waren die Daten lokalisiert. Auf jedem der Server befinden sich Daten zur Preisgestaltung eines bestimmten Satzes von Aktien. Diese überlappen sich nicht. Daher kann logReturn parallel und unabhängig berechnet werden, alles geschieht parallel und verteilt.
Wir haben entschieden, diese Daten zu komprimieren, ohne ihre Ausdruckskraft zu verlieren. Dazu verwenden wir Arrays, d.h. für jeden Zeitabschnitt erstellen wir ein Array von Aktien und ein Array von Preisen. So beanspruchen die Daten viel weniger Speicherplatz und lassen sich einfacher bearbeiten. Diese Vorgänge laufen nahezu parallel ab, das heißt, wir berechnen teilweise gleichzeitig und schreiben dann auf den Server.
Danach können wir diese replizieren. Der Buchstabe „r“ bedeutet, dass wir diese Daten repliziert haben. Das heißt, dass wir auf allen drei Servern identische Daten haben – nämlich diese Arrays.
Mit einem speziellen Skript können wir aus diesem Satz von 12,5 Millionen Korrelationen, die berechnet werden müssen, Pakete erstellen. Das bedeutet 2.500 Aufgaben mit 5.000 Paaren von Korrelationen. Diese Aufgabe wird auf einem bestimmten ClickHouse-Server ausgeführt. Alle Daten sind dort vorhanden, da die Daten identisch sind und er sie nacheinander berechnen kann.
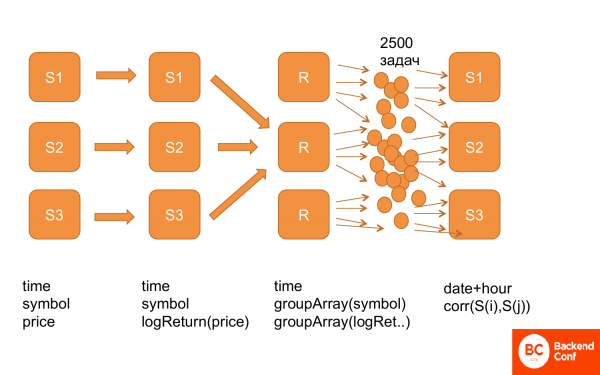
So sieht es aus. Zunächst haben wir alle Daten in folgender Struktur: Zeit, Aktien, Preis. Danach haben wir den logReturn berechnet, das heißt, die gleiche Struktur, nur dass wir anstelle des Preises den logReturn haben. Anschließend haben wir die Daten umformatiert, sodass wir Zeit und eine Gruppierung nach Aktien und Preisen erhalten haben. Danach haben wir sie zusammengeführt. Schließlich haben wir viele Aufgaben generiert und ClickHouse gefüttert, damit es diese berechnen kann. Und das funktioniert.

Bei dem Proof of Concept war die Aufgabe eine Teilaufgabe, d.h. es wurden weniger Daten verwendet. Und das Ganze lief auf drei Servern.
Die ersten beiden Schritte: Berechnung des Log_Return und Umwandlung in Arrays haben jeweils etwa eine Stunde gedauert.
Die Berechnung der Korrelation hat etwa 50 Stunden in Anspruch genommen. Aber 50 Stunden sind wenig, denn vorher hat es Wochen gedauert. Das war ein großer Erfolg. Wenn man es genau betrachtet, wurden 70 Berechnungen pro Sekunde in diesem Cluster durchgeführt.
Am wichtigsten ist jedoch, dass dieses System praktisch ohne Engpässe funktioniert, d.h. es lässt sich nahezu linear skalieren. Und das haben sie überprüft. Erfolgreich haben sie es skaliert.

- Das richtige Schema ist die halbe Miete. Und das richtige Schema bedeutet, alle notwendigen Technologien von ClickHouse zu nutzen.
- Summing/Aggregating Merge Trees sind Technologien, die es ermöglichen, Snapshots der Zustände als Ausnahme zu aggregieren oder zu zählen. Das vereinfacht viele Dinge erheblich.
- Materialisierte Ansichten ermöglichen es, die Einschränkung auf einen Index zu umgehen. Vielleicht habe ich das nicht sehr klar ausgedrückt, aber als wir die Protokolle geladen haben, lagen die Rohprotokolle in einer Tabelle mit einem einzigen Index, während die Attributlogdaten in einer anderen Tabelle gespeichert waren. Es handelt sich also um dieselben Daten, nur gefiltert, aber der Index war völlig unterschiedlich. Es scheinen zwar die gleichen Daten zu sein, jedoch mit unterschiedlicher Sortierung. Materialisierte Ansichten ermöglichen es, diese Einschränkung von ClickHouse zu umgehen, wenn dies erforderlich ist.
- Reduzieren Sie die Granularität des Index für punktuelle Abfragen.
- Verteilen Sie die Daten intelligent, versuchen Sie, die Daten innerhalb des Servers so lokal wie möglich zu halten. Achten Sie darauf, dass auch die Abfragen, wo immer möglich, diese Lokalisierung nutzen.
Zusammenfassend kann man sagen, dass ClickHouse derzeit sowohl im Bereich der kommerziellen als auch der Open-Source-Datenbanken, insbesondere für analytische Zwecke, fest etabliert ist. Es fügt sich hervorragend in dieses Umfeld ein. Darüber hinaus beginnt es allmählich, andere zu verdrängen, denn wenn Sie ClickHouse haben, benötigen Sie InfiniDB nicht. Vertica könnte bald obsolet sein, wenn sie eine ordentliche SQL-Unterstützung bieten. Nutzen Sie es!

—Vielen Dank für den Vortrag! Sehr interessant! Gab es Vergleiche mit Apache Phoenix?
- Nein, ich habe nicht gehört, dass jemand vergleicht. Wir bei Yandex bemühen uns, alle Vergleiche von ClickHouse mit verschiedenen Datenbanken zu verfolgen. Denn wenn plötzlich etwas schneller als ClickHouse ist, kann Alexey Milovidov nachts nicht schlafen und beginnt, es schnell zu optimieren. Ich habe von einem solchen Vergleich nichts gehört.
(Алексей Миловидов) Apache Phoenix – ist eine SQL-Engine auf Hbase. Hbase ist hauptsächlich für key-value-basierte Arbeitsabläufe konzipiert. In jeder Zeile kann es eine beliebige Anzahl von Spalten mit beliebigen Namen geben. Das gilt auch für Systeme wie Hbase und Cassandra. Auf diesen Systemen werden jedoch komplexe analytische Abfragen nicht gut funktionieren. Oder Sie könnten annehmen, dass sie gut funktionieren, wenn Sie keine Erfahrung mit ClickHouse haben.
Danke
Guten Tag! Ich beschäftige mich bereits ziemlich lange mit diesem Thema, da ich ein analytisches Subsystem habe. Aber wenn ich mir ClickHouse ansehe, habe ich das Gefühl, dass ClickHouse sehr gut für die Analyse von Events und veränderlichen Daten geeignet ist. Wenn ich jedoch viele Geschäftsdaten mit einer Vielzahl großer Tabellen analysieren muss, ist ClickHouse, soweit ich das verstehe, nicht die beste Wahl für mich. Besonders wenn sich diese Daten ändern. Ist das richtig, oder gibt es Beispiele, die das widerlegen können?
Das ist richtig. Das gilt für die meisten spezialisierten analytischen Datenbanken. Sie sind darauf ausgelegt, dass es eine oder mehrere große, veränderbare Tabellen gibt und viele kleine, die sich langsam ändern. Das heißt, ClickHouse ist nicht wie Oracle, wo man alles ablegen und sehr komplexe Abfragen erstellen kann. Um ClickHouse effektiv zu nutzen, muss man das Schema auf eine Weise gestalten, die gut mit ClickHouse funktioniert. Das bedeutet, übermäßige Normalisierung zu vermeiden, Nachschlagetabellen zu verwenden und weniger lange Beziehungen zu schaffen. Wenn das Schema so gestaltet ist, können ähnliche Geschäftsaufgaben in ClickHouse viel effizienter gelöst werden als in einer traditionellen relationalen Datenbank.
Vielen Dank für den Vortrag! Ich habe eine Frage zum letzten finanziellen Fall. Es gab Analysen. Man musste vergleichen, wie es aufwärts und abwärts geht. Ich verstehe, dass Sie das System genau für diese Analysen aufgebaut haben? Wenn sie morgen zum Beispiel einen anderen Bericht über diese Daten benötigen, müssen sie das Schema neu erstellen und die Daten erneut laden? Das heißt, es ist eine Art Vorverarbeitung erforderlich, um die Abfrage zu erhalten?
Natürlich wird ClickHouse für eine ganz bestimmte Aufgabe verwendet. Diese hätte traditionell auch mit Hadoop gelöst werden können. Für Hadoop ist das eine ideale Aufgabe, aber die Bearbeitung erfolgt dort sehr langsam. Mein Ziel ist es zu demonstrieren, dass mit ClickHouse Aufgaben gelöst werden können, die normalerweise mit ganz anderen Mitteln angegangen werden, und dabei deutlich effizienter sind. Es ist speziell auf diese Aufgabe zugeschnitten. Natürlich kann eine ähnliche Aufgabe auch auf ähnliche Weise gelöst werden.
Verstanden. Sie sagten, dass die Verarbeitung 50 Stunden gedauert hat. Bezieht sich das auf den gesamten Zeitraum, vom ersten Laden der Daten bis zum Erhalt der Ergebnisse?
Ja, ja.
Gut, vielen Dank.
Das ist auf einem 3-Server-Cluster.
Hallo! Vielen Dank für den Vortrag! Alles sehr interessant. Ich möchte nicht so sehr nach der Funktionalität fragen, sondern nach der Verwendung von ClickHouse in Bezug auf Stabilität. Gab es bei Ihnen Ausfälle, musste etwas wiederhergestellt werden? Wie verhält sich ClickHouse in solchen Fällen? Und kam es vor, dass auch die Replikation ausgefallen ist? Wir haben beispielsweise mit ClickHouse das Problem erfahren, dass es doch über seine Grenzen hinausgeht und abstürzt.
Natürlich gibt es keine perfekten Systeme, und auch ClickHouse hat seine Herausforderungen. Aber haben Sie jemals gehört, dass Yandex.Metrica längere Zeit nicht funktioniert hat? Wahrscheinlich nicht. Seit 2012-2013 arbeitet es zuverlässig auf ClickHouse. Auch aus meiner Erfahrung kann ich sagen, dass wir nie vollständige Ausfälle hatten. Irgendwelche partiellen Probleme konnten auftreten, aber diese waren nie so kritisch, dass sie ernsthafte Auswirkungen auf das Geschäft hatten. So etwas gab es nie. ClickHouse ist ziemlich zuverlässig und fällt nicht willkürlich aus. Darüber kann man sich keine Sorgen machen. Es ist kein ungetestetes Produkt. Das haben viele Unternehmen bewiesen.
Hallo! Sie haben gesagt, dass man von Anfang an gut über das Datenmodell nachdenken muss. Was ist, wenn das nicht passiert ist? Bei mir fließen die Daten und fließen. Nach sechs Monaten merke ich, dass das nicht so weitergehen kann, ich muss die Daten neu hochladen und etwas damit machen.
Das hängt natürlich von Ihrer Systemarchitektur ab. Es gibt mehrere Möglichkeiten, dies nahezu ohne Unterbrechung zu erreichen. Sie könnten zum Beispiel ein Materialized View erstellen, das eine andere Datenstruktur hat, wenn sie eindeutig zuordnungsfähig ist. Das bedeutet, wenn eine Zuordnung mittels ClickHouse möglich ist, also bestimmte Dinge extrahiert werden können, der Primary Key geändert wird und die Partitionierung angepasst wird, dann kann man ein Materialized View erstellen. Ihre alten Daten können dort übertragen werden, während neue automatisch geschrieben werden. Danach wechseln Sie einfach zur Verwendung des Materialized View, schalten die Schreibvorgänge um, und löschen die alte Tabelle. Das ist ein Ansatz, der völlig ohne Unterbrechung funktioniert.
Danke.
Quelle: habr.com
