

Guten Tag! Mein Name ist Danil Lipovoy. Unser Team bei Sbertech hat begonnen, HBase als Speichersystem für operative Daten zu nutzen. Im Laufe unserer Untersuchungen haben wir Erfahrungen gesammelt, die wir systematisieren und dokumentieren wollten (wir hoffen, dass viele davon profitieren können). Alle nachfolgend aufgeführten Experimente wurden mit den HBase-Versionen 1.2.0-cdh5.14.2 und 2.0.0-cdh6.0.0-beta1 durchgeführt.
- Allgemeine Architektur
- Datenschreibung in HBase
- Datenlesen aus HBase
- Daten-Caching
- Batchverarbeitung von Daten MultiGet/MultiPut
- Tabelle-Regionen-Split-Strategie
- Fehlertoleranz, Kompaktierung und Datenlokalität
- Einstellungen und Leistung
- Lasttest
- Fazit
1. Allgemeine Architektur
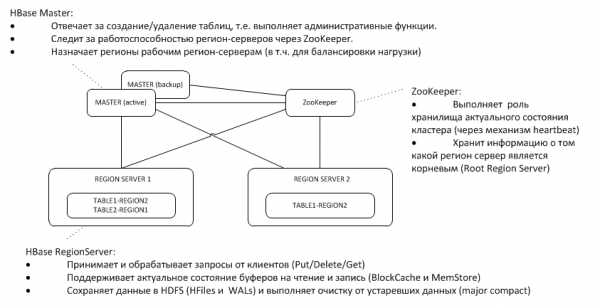
Der Backup-Master überwacht das Heartbeat des aktiven Masters auf dem ZooKeeper-Knoten und übernimmt im Falle eines Ausfalls die Funktionen des Masters.
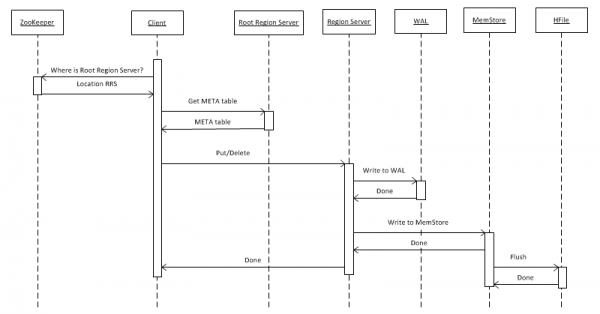
2. Datenschreibung in HBase
Zuerst betrachten wir den einfachsten Fall – das Schreiben eines Schlüssel-Wert-Objekts in eine Tabelle mithilfe von put(rowkey). Der Client muss zuerst herausfinden, wo sich der Root Region Server (RRS) befindet, der die Tabelle hbase:meta speichert. Diese Informationen erhält er von ZooKeeper. Anschließend wendet er sich an den RRS und liest die Tabelle hbase:meta, aus der er die Informationen darüber entnimmt, welcher RegionServer (RS) für die Speicherung der Daten für den angegebenen Schlüssel rowkey in der von ihm interessierten Tabelle verantwortlich ist. Zur weiteren Verwendung wird die Metatabelle vom Client zwischengespeichert, sodass nachfolgende Zugriffe schneller direkt zum RS erfolgen.
Danach schreibt RS, nachdem es die Anfrage erhalten hat, zunächst in das WriteAheadLog (WAL), was für die Wiederherstellung im Falle eines Ausfalls erforderlich ist. Danach werden die Daten im MemStore gespeichert. Dies ist ein Speicherpuffer, der eine sortierte Menge von Schlüsseln für diese Region enthält. Die Tabelle kann in Regionen (Partitionen) unterteilt werden, von denen jede eine nicht überschneidende Menge von Schlüsseln enthält. Dadurch kann durch die Verteilung der Regionen auf verschiedene Server eine höhere Leistung erzielt werden. Trotz der offensichtlichen Natur dieser Aussage werden wir jedoch sehen, dass dies nicht in allen Fällen funktioniert.
Nach dem Ablegen des Eintrags im MemStore erhält der Kunde eine Rückmeldung, dass der Eintrag erfolgreich gespeichert wurde. Tatsächlich wird er jedoch nur im Puffer gespeichert und gelangt erst auf die Festplatte, nachdem ein gewisser Zeitraum vergangen ist oder wenn er mit neuen Daten gefüllt wird.
Bei der Ausführung der «Delete»-Operation erfolgt keine physische Löschung der Daten. Sie werden lediglich als gelöscht markiert, und die tatsächliche Zerstörung findet zum Zeitpunkt des Aufrufs der Funktion major compact statt, die in Punkt 7 näher erläutert wird.
HFile-Dateien sammeln sich im HDFS und gelegentlich wird ein Minor Compact-Prozess gestartet, der einfach kleine Dateien zu größeren zusammenführt, ohne etwas zu löschen. Im Laufe der Zeit führt dies zu einem Problem, das sich nur beim Lesen von Daten bemerkbar macht (darauf kommen wir später zurück).
Neben dem oben beschriebenen Upload-Prozess gibt es ein viel effizienteres Verfahren, das wohl die stärkste Seite dieser Datenbank ist – BulkLoad. Dabei erstellen wir HFiles selbst und legen sie auf die Festplatte, was eine hervorragende Skalierbarkeit und durchaus respektable Geschwindigkeiten ermöglicht. Letztlich ist hier nicht HBase die Grenze, sondern die Möglichkeiten der Hardware. Nachfolgend sind die Ergebnisse des Uploads in einem Cluster mit 16 RegionServern und 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2,40 GHz * 64 Threads), Version HBase 1.2.0-cdh5.14.2, aufgeführt.
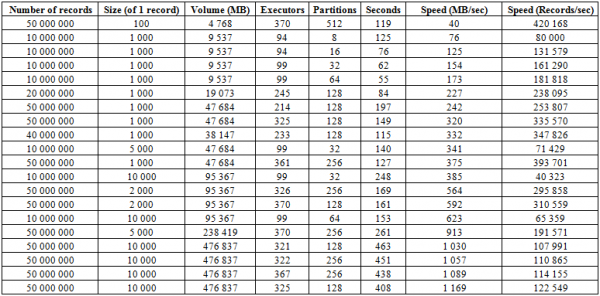
Hier ist zu erkennen, dass die Erhöhung der Anzahl der Partitionen (Regionen) in der Tabelle sowie der Spark-Executors die Upload-Geschwindigkeit steigert. Zudem hängt die Geschwindigkeit vom Volumen der Schreibvorgänge ab. Große Blöcke führen zu einem Anstieg in MB/s, kleine hingegen erhöhen die Anzahl der eingefügten Datensätze pro Zeiteinheit, unter ansonsten gleichen Bedingungen.
Es ist auch möglich, den Download in zwei Tabellen gleichzeitig zu starten und die Geschwindigkeit zu verdoppeln. Unten ist zu sehen, dass das gleichzeitige Schreiben von 10-KB-Blöcken in zwei Tabellen mit einer Geschwindigkeit von etwa 600 MB/s pro Tabelle (insgesamt 1275 MB/s) erfolgt, was mit der Schreibgeschwindigkeit in eine Tabelle von 623 MB/s übereinstimmt (siehe Nr. 11 oben).

Der zweite Durchlauf mit 50-KB-Einträgen zeigt, dass die Ladegeschwindigkeit nur geringfügig steigt, was auf annähernde Grenzwerte hinweist. Dabei sollte berücksichtigt werden, dass die Belastung für HBASE praktisch nicht entsteht; alles, was von ihm gefordert wird, besteht darin, zuerst die Daten aus hbase:meta bereitzustellen und nach der Ablage von HFiles die Daten im BlockCache zurückzusetzen und den MemStore-Puffer auf die Festplatte zu speichern, sofern dieser nicht leer ist.
3. Daten aus HBASE lesen
Wenn man davon ausgeht, dass der Kunde bereits alle Informationen aus hbase:meta hat (siehe Punkt 2), wird die Anfrage sofort an den RS gesendet, wo der benötigte Schlüssel gespeichert ist. Zunächst erfolgt die Suche in MemCache. Unabhängig davon, ob dort Daten vorhanden sind oder nicht, wird auch im BlockCache und bei Bedarf in HFiles gesucht. Wenn die Daten in der Datei gefunden werden, werden sie in den BlockCache gelegt und bei der nächsten Anfrage schneller zurückgegeben. Die Suche in HFile erfolgt relativ schnell dank der Verwendung des Bloom Filters, d.h. nachdem eine kleine Datenmenge gelesen wurde, kann sofort festgestellt werden, ob diese Datei den benötigten Schlüssel enthält. Falls nicht, wird zur nächsten gewechselt.
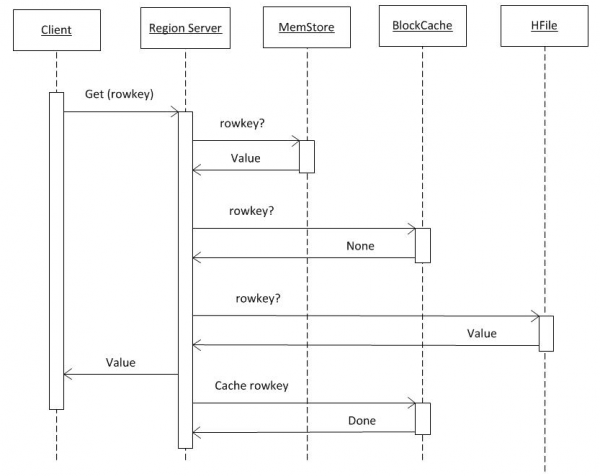
Nachdem Daten aus diesen drei Quellen erhalten wurden, formt der RS die Antwort. Insbesondere kann er mehrere gefundene Versionen des Objekts gleichzeitig übermitteln, wenn der Kunde nach Versionsverwaltung gefragt hat.
4. Daten-Caching
Die MemStore- und BlockCache-Puffer nehmen bis zu 80 % des zugewiesenen on-heap Speichers des RS ein (der Rest ist für die Dienstaufgaben des RS reserviert). Wenn der typische Nutzungsmodus so ist, dass Prozesse diese Daten schreiben und sofort wieder lesen, macht es Sinn, den BlockCache zu reduzieren und den MemStore zu erhöhen, da beim Schreiben die Daten nicht in den Lesekernel gelangen und der BlockCache seltener verwendet wird. Der BlockCache besteht aus zwei Teilen: LruBlockCache (immer on-heap) und BucketCache (in der Regel off-heap oder auf SSD). Den BucketCache sollte man verwenden, wenn es viele Leseanfragen gibt, die nicht im LruBlockCache Platz finden, was zu einer aktiven Arbeit des Garbage Collectors führt. Dabei sollte man jedoch keine radikalen Leistungssteigerungen durch die Verwendung des Lesekerns erwarten; darauf kommen wir in Punkt 8 zurück.
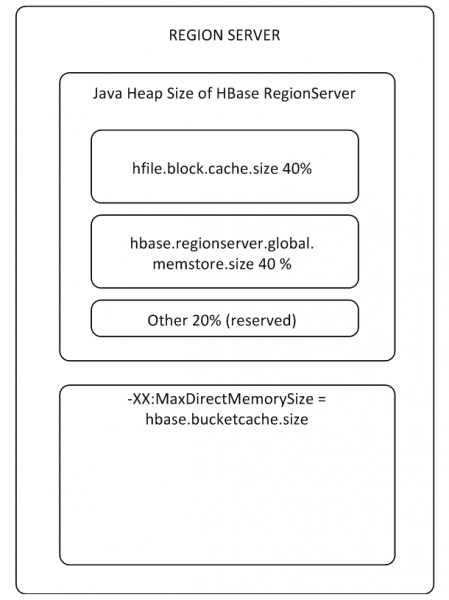
Der BlockCache ist für den gesamten RS einheitlich, während der MemStore für jede Tabelle individuell ist (je einer für jede Spaltenfamilie).
Wie In der Theorie gelangen Daten beim Schreiben nicht in den Cache, und tatsächlich sind die Parameter CACHE_DATA_ON_WRITE für die Tabelle und „Cache DATA on Write“ für RS auf false gesetzt. In der Praxis jedoch, wenn Daten in den MemStore geschrieben und dann auf die Festplatte zurückgespült werden (somit gelöscht), erhalten wir beim Ausführen einer Abrufanfrage dennoch erfolgreich die Daten. Selbst wenn wir den BlockCache komplett deaktivieren und die Tabelle mit neuen Daten füllen, dann den MemStore auf die Festplatte zurückspülen, sie löschen und aus einer anderen Sitzung anfordern, werden sie trotzdem irgendwoher abgerufen. HBase speichert also nicht nur Daten, sondern auch geheimnisvolle Rätsel.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Der Parameter „Cache DATA on Read“ ist auf false gesetzt. Wenn es Ideen gibt, sind Sie herzlich eingeladen, dies in den Kommentaren zu besprechen.
5. Batch-Datenverarbeitung MultiGet/MultiPut
Die Verarbeitung einzelner Anfragen (Get/Put/Delete) ist eine recht kostspielige Operation, daher sollten sie nach Möglichkeit in einer Liste zusammengefasst werden, um eine beträchtliche Leistungssteigerung zu erzielen. Dies gilt insbesondere für Schreiboperationen, während beim Lesen ein weiterer Stolperstein zu beachten ist. Im unteren Diagramm ist die Lesezeit von 50.000 Datensätzen aus MemStore dargestellt. Das Lesen erfolgte in einem einzigen Thread, und auf der horizontalen Achse ist die Anzahl der Schlüssel in der Anfrage angezeigt. Hier ist zu sehen, dass bei einer Erhöhung auf bis zu tausend Schlüssel in einer Anfrage die Ausführungszeit sinkt, d.h. die Geschwindigkeit steigt. Allerdings tritt beim standardmäßig aktivierten MSLAB-Modus nach diesem Schwellenwert ein drastischer Leistungsabfall auf, und je größer das Datenvolumen im Datensatz ist, desto länger dauert die Verarbeitung.
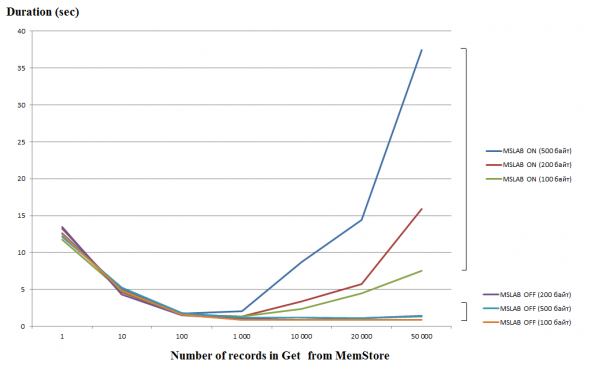
Die Tests wurden auf einer virtuellen Maschine mit 8 Kernen, Version HBase 2.0.0-cdh6.0.0-beta1, durchgeführt.
Der MSLAB-Modus wurde entwickelt, um die Fragmentierung des Heaps zu reduzieren, die durch das Mischen von Daten neuer und alter Generationen entsteht. Um dieses Problem zu lösen, werden beim Aktivieren von MSLAB die Daten in relativ kleine Einheiten (Chunks) eingeordnet und in Portionen verarbeitet. Dadurch sinkt die Leistung erheblich, wenn die Größe des angeforderten Datenpakets den zugewiesenen Speicher überschreitet. Andererseits ist das Deaktivieren dieses Modus ebenfalls unerwünscht, da dies zu Stopps durch GC während intensiver Datenverarbeitung führt. Eine gute Lösung ist die Erhöhung der Chunk-Größe, wenn gleichzeitig Daten durch Put geschrieben und gelesen werden. Es ist erwähnenswert, dass das Problem nicht auftritt, wenn nach dem Schreiben der Befehl Flush ausgeführt wird, der den MemStore auf die Festplatte zurückschreibt, oder wenn der Upload mithilfe von BulkLoad erfolgt. Die folgende Tabelle zeigt, dass Anfragen aus dem MemStore mit größerem Volumen (und der gleichen Anzahl) zu einer Verlangsamung führen. Allerdings wird die Verarbeitungszeit durch Erhöhung der Chunk-Größe wieder auf das Normalniveau zurückgebracht.
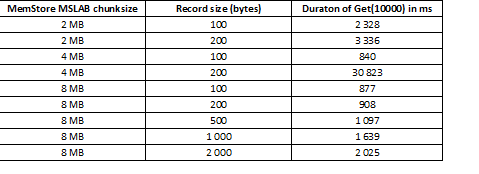
Zusätzlich zur Erhöhung der Chunkgröße hilft die Aufteilung der Daten nach Regionen, also dem Splitten von Tabellen. Dadurch erhält jede Region weniger Anfragen, und wenn sie in eine Zelle passen, bleibt die Antwortzeit gut.
6. Strategie zur Aufteilung von Tabellen auf Regionen (Splitting)
Da HBase ein Key-Value-Speicher ist und die Partitionierung nach dem Schlüssel erfolgt, ist es entscheidend, die Daten gleichmäßig auf alle Regionen zu verteilen. Beispielsweise führt die Partitionierung einer solchen Tabelle in drei Teile dazu, dass die Daten auf drei Regionen aufgeteilt werden:
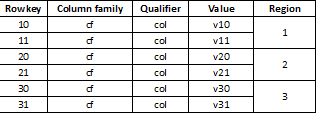
Es kann passieren, dass dies zu einer erheblichen Verlangsamung führt, wenn die anschließend geladenen Daten beispielsweise lange Werte enthalten, die größtenteils mit derselben Ziffer beginnen, zum Beispiel:
1000001
1000002
…
1100003
Da die Schlüssel als Byte-Arrays gespeichert werden, werden sie alle gleich anfangen und zu einer Region #1 gehören, die diesen Schlüsselbereich speichert. Es gibt mehrere Strategien für die Aufteilung:
HexStringSplit – Wandelt den Schlüssel in eine Zeichenfolge mit hexadezimaler Kodierung im Bereich von „00000000“ bis „FFFFFFFF“ um und füllt links mit Nullen auf.
UniformSplit – Wandelt einen Schlüssel in ein Byte-Array mit einer hexadezimalen Kodierung im Bereich von «00» bis «FF» um und füllt ihn rechts mit Nullen auf.
Darüber hinaus kann ein beliebiger Bereich oder eine Gruppe von Schlüsseln für die Aufteilung angegeben und das Autoplenning konfiguriert werden. Eine der einfachsten und effektivsten Methoden ist jedoch UniformSplit und die Verwendung der Hash-Konkatenation, etwa des vorderen Byte-Paares aus der Anwendung der Funktion CRC32(rowkey) auf den Schlüssel und dem eigentlichen rowkey:
hash + rowkey
Dann werden alle Daten gleichmäßig auf die Regionen verteilt. Beim Lesen werden die ersten beiden Bytes einfach verworfen und der ursprüngliche Schlüssel bleibt erhalten. Außerdem überwacht RS die Menge der Daten und Schlüssel in der Region und teilt sie automatisch in Teile auf, wenn die Limits überschritten werden.
7. Fehlertoleranz und Datenlokalität
Da jedes Region nur für einen Satz von Schlüsseln verantwortlich ist, besteht die Lösung für Probleme im Zusammenhang mit dem Ausfall von RS oder Stilllegungen darin, alle erforderlichen Daten in HDFS zu speichern. Wenn ein RS ausfällt, erkennt der Master dies durch das Fehlen eines Heartbeats am ZooKeeper-Knoten. Er weist den betroffenen Region einem anderen RS zu, und da die HFiles in einem verteilten Dateisystem gespeichert sind, kann der neue Besitzer sie auslesen und die Daten weiterhin bereitstellen. Allerdings kann es sein, dass ein Teil der Daten im MemStore verbleibt und noch nicht in HFiles überführt wurde. Zur Wiederherstellung der Operationshistorie wird das WAL verwendet, das ebenfalls in HDFS gespeichert ist. Nach dem Aufspielen der Änderungen kann der RS wieder auf Anfragen reagieren, jedoch führt der Umzug dazu, dass einige Daten und die Prozesse, die deren Verwaltung übernehmen, sich auf verschiedenen Knoten befinden, was die Lokalität verringert.
Die Lösung des Problems ist die major compaction – ein Verfahren, das die Dateien auf die Knoten verschiebt, die für sie verantwortlich sind (dort, wo sich ihre Regionen befinden). Dadurch steigt während dieses Prozesses die Belastung des Netzwerks und der Festplatten signifikant. Allerdings wird der Zugriff auf die Daten danach deutlich beschleunigt. Darüber hinaus führt die major_compaction die Zusammenführung aller HFiles in eine Datei innerhalb der Region durch und bereinigt die Daten basierend auf den Tabelleneinstellungen. So kann beispielsweise die Anzahl der Versionen des Objekts festgelegt werden, die aufbewahrt werden sollen, oder die Lebensdauer, nach deren Ablauf das Objekt physisch gelöscht wird.
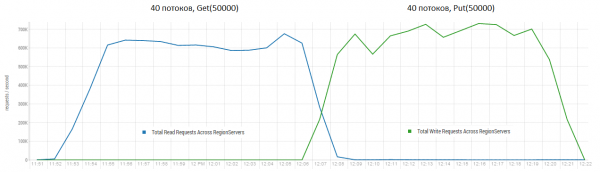
Dieses Verfahren kann sich sehr positiv auf die Leistung von HBase auswirken. Das Bild unten zeigt, wie die Leistung durch aktives Schreiben von Daten degradiert wurde. Hier sieht man, wie 40 Threads in eine Tabelle schreiben und 40 Threads gleichzeitig Daten lesen. Die schreibenden Threads erzeugen immer mehr HFiles, die von anderen Threads gelesen werden. Infolgedessen müssen immer mehr Daten aus dem Speicher entfernt werden, und schließlich beginnt der Garbage Collector zu arbeiten, was die gesamte Arbeit praktisch lähmt. Der Start einer Major Compaction führte zur Bereinigung der entstandenen Rückstände und zur Wiederherstellung der Leistung.
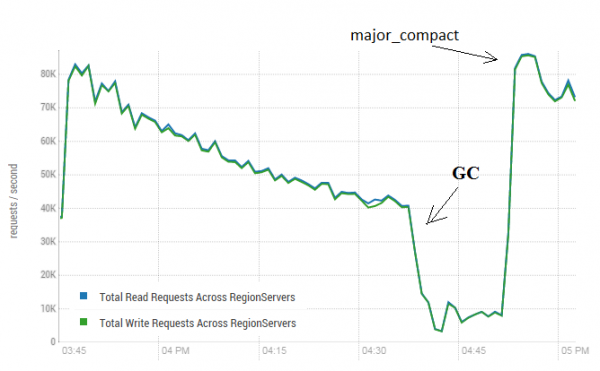
Der Test wurde auf 3 DataNodes und 4 RegionServern (CPU Xeon E5-2680 v4 @ 2,40 GHz * 64 Threads) durchgeführt. HBase Version 1.2.0-cdh5.14.2
Es ist anzumerken, dass die Durchführung einer major compaction auf einer "lebenden" Tabelle stattfand, in die aktiv Daten geschrieben und gelesen wurden. In der Community wurde behauptet, dass dies zu inkorrekten Antworten beim Lesen von Daten führen könnte. Zur Überprüfung wurde ein Prozess gestartet, der neue Daten generierte und in die Tabelle schrieb. Anschließend wurden diese sofort gelesen und mit den gespeicherten Werten abgeglichen. Während dieses Prozesses wurde die major compaction etwa 200 Mal durchgeführt, und es wurden keine Fehler festgestellt. Möglicherweise tritt das Problem selten und nur bei hoher Auslastung auf, weshalb es sicherer ist, die Schreib- und Leseprozesse programmatisch zu stoppen und die Bereinigung durchzuführen, um solche GC-Einbrüche zu vermeiden.
Außerdem hat die major compaction keinen Einfluss auf den Zustand des MemStore; um ihn auf die Festplatte zu leeren und zu kompaktiifizieren, muss flush verwendet werden (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Einstellungen und Leistung
Wie bereits erwähnt, zeigt HBase den größten Erfolg, wenn es nichts tun muss, während es BulkLoad ausführt. Dies gilt jedoch für die meisten Systeme und Menschen. Dieses Tool eignet sich besser für die Massenablage von Daten in großen Blöcken. Wenn der Prozess jedoch viele konkurrierende Lese- und Schreibanfragen erfordert, werden die oben beschriebenen Befehle Get und Put verwendet. Um die optimalen Parameter zu bestimmen, wurden mehrere Läufe mit unterschiedlichen Kombinationen von Tabelleneinstellungen und Konfigurationen durchgeführt.
- Es wurden 10 Threads gleichzeitig dreimal hintereinander gestartet (nennen wir dies einen Threadblock).
- Die Laufzeit aller Threads im Block wurde gemittelt und war das Endergebnis der Blockausführung.
- Alle Threads arbeiteten mit derselben Tabelle.
- Vor jedem Start des Threadblocks wurde eine Major-Compaction durchgeführt.
- Jeder Block führte nur eine der folgenden Operationen aus:
— Put
— Get
— Get+Put
- Jeder Block führte 50.000 Wiederholungen seiner Operation aus.
- Die Größe eines Eintrags im Block betrug 100 Byte, 1000 Byte oder 10000 Byte (zufällig).
- Blöcke wurden mit einer unterschiedlichen Anzahl angeforderter Schlüssel gestartet (entweder ein Schlüssel oder 10).
- Die Blöcke wurden mit verschiedenen Tabelleneinstellungen gestartet. Die Parameter wurden geändert:
— BlockCache = ein- oder ausgeschaltet
— BlockSize = 65 KB oder 16 KB
— Partitionen = 1, 5 oder 30
— MSLAB = ein- oder ausgeschaltet
So sieht der Block aus:
a. Der MSLAB-Modus wurde ein- bzw. ausgeschaltet.
b. Eine Tabelle wurde erstellt, für die folgende Parameter festgelegt wurden: BlockCache = true/none, BlockSize = 65/16 KB, Partitionen = 1/5/30.
c. GZ-Kompression wurde aktiviert.
d. Es wurden gleichzeitig 10 Threads gestartet, die 1/10 Put/Get/Get+Put-Operationen in dieser Tabelle mit Datensätzen von 100/1000/10000 Bytes durchführten, wobei 50.000 Anfragen hintereinander ausgeführt wurden (Zufallszahlen).
e. Punkt d wurde dreimal wiederholt.
f. Die Laufzeit aller Threads wurde im Durchschnitt berechnet.
Alle möglichen Kombinationen wurden getestet. Vorhersehbar war, dass die Geschwindigkeit sinkt, wenn die Datensatzgröße erhöht wird, oder dass das Deaktivieren des Caching zu einer Verlangsamung führt. Das Ziel war jedoch, das Ausmaß und die Bedeutung des Einflusses jedes Parameters zu verstehen. Daher wurden die gesammelten Daten in eine lineare Regressionsfunktion eingespeist, was eine Bewertung der Verlässlichkeit mithilfe von t-Statistiken ermöglicht. Im Folgenden sind die Ergebnisse der Blöcke aufgeführt, die die Put-Operationen ausführen. Die vollständige Kombination von 2*2*3*2*3 ergibt 144 Varianten + 72, da einige zweimal durchgeführt wurden. Insgesamt also 216 Ausführungen:
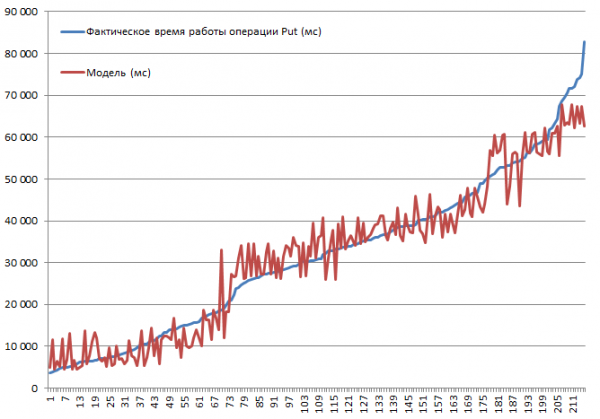
Die Tests wurden auf einem Mini-Cluster durchgeführt, das aus 3 DataNodes und 4 RS (CPU Xeon E5-2680 v4 @ 2,40 GHz * 64 Threads) bestand. Version HBase 1.2.0-cdh5.14.2.
Die höchste Einfügegeschwindigkeit von 3,7 Sekunden wurde im ausgeschalteten MSLAB-Modus auf einer Tabelle mit einer Partition erreicht, mit aktiviertem BlockCache, BlockSize = 16, mit 100-Byte-Datensätzen in 10er-Packs.
Die niedrigste Einfügegeschwindigkeit von 82,8 Sekunden wurde im aktivierten MSLAB-Modus auf einer Tabelle mit einer Partition erreicht, mit aktiviertem BlockCache, BlockSize = 16, mit 10.000-Byte-Datensätzen von je 1 Stück.
Jetzt schauen wir uns das Modell an. Wir sehen eine gute Modellqualität gemäß R², aber es ist völlig klar, dass eine Extrapolation hier nicht angebracht ist. Das tatsächliche Verhalten des Systems bei Änderung der Parameter wird nicht linear sein; dieses Modell dient nicht zur Prognose, sondern zum Verständnis dessen, was innerhalb der gegebenen Parameter passiert ist. Zum Beispiel sehen wir hier anhand des Student-Kriteriums, dass die Parameter BlockSize und BlockCache für die Put-Operation irrelevant sind (was im Allgemeinen ziemlich vorhersehbar ist):

Dass jedoch eine Erhöhung der Anzahl von Partitionen zu einer Verringerung der Leistung führt, ist etwas unerwartet (wir haben bereits einen positiven Einfluss der Erhöhung der Partitionen bei BulkLoad gesehen), obwohl es erklärbar ist. Erstens muss für die Verarbeitung Anfragen an 30 Regionen anstatt an eine einzige gestellt werden, und das Datenvolumen reicht nicht aus, um daraus einen Vorteil zu ziehen. Zweitens wird die Gesamtarbeitszeit durch den langsamsten RS bestimmt, und da die Anzahl der DataNodes geringer ist als die Anzahl der RS, haben einige Regionen eine null Lokalisierung. Schauen wir uns die Top 5 an:

Jetzt bewerten wir die Ergebnisse der Ausführung der Get-Blocks:

Die Anzahl der Partitionen hat an Bedeutung verloren, was wahrscheinlich daran liegt, dass die Daten gut zwischengespeichert werden und der Lesecache das statistisch bedeutendste Merkmal darstellt. Natürlich ist auch eine Erhöhung der Anzahl an Anfragen im Request sehr nützlich für die Leistung. Die besten Ergebnisse:

Und schließlich schauen wir uns das Blockmodell an, das zuerst get und dann put ausgeführt hat:

Hier sind alle Parameter signifikant. Und die Ergebnisse der Besten:

9. Lasttests
Und schließlich lassen Sie uns eine halbwegs anständige Last ausprobieren, aber es ist immer interessanter, wenn man einen Vergleich hat. Auf der DataStax-Website – dem wichtigsten Entwickler von Cassandra – gibt es NHT einer Reihe von NoSQL-Datenbanken, einschließlich HBase Version 0.98.6-1. Der Test wurde mit 40 Threads durchgeführt, die Datengröße betrug 100 Byte, SSDs wurden verwendet. Das Testergebnis für die Operationen Read-Modify-Write ergab folgende Resultate.
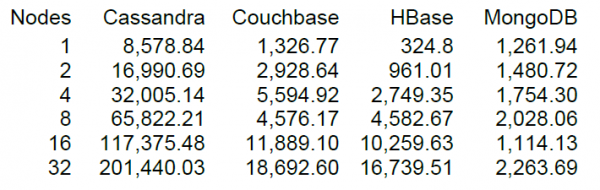
Soweit ich verstanden habe, wurde das Lesen in Blöcken von 100 Einträgen durchgeführt, und für 16 Nodes zeigte der DataStax-Test für HBase eine Leistung von 10.000 Operationen pro Sekunde.
Es ist günstig, dass auch in unserem Cluster 16 Knoten installiert sind, allerdings ist es weniger erfreulich, dass jeder über 64 Kerne (Threads) verfügt, während im DataStax-Test lediglich 4 pro Knoten genutzt werden. Auf der anderen Seite haben sie SSDs, während wir HDDs verwenden und eine neuere Version von HBase haben. Die CPU-Auslastung während der Last war jedoch kaum signifikant angestiegen (visuell um 5-10 Prozent). Dennoch werden wir versuchen, auf dieser Konfiguration zu starten. Die Tabelleneinstellungen sind standardmäßig, das Lesen erfolgt zufällig im Schlüsselbereich von 0 bis 50 Millionen (d.h. praktisch jedes Mal neu). In der Tabelle sind 50 Millionen Datensätze, aufgeteilt in 64 Partitionen. Die Schlüssel sind nach crc32 gehasht. Die Tabelleneinstellungen sind standardmäßig, MSLAB ist aktiviert. Es werden 40 Threads gestartet, jeder Thread liest ein Set aus 100 zufälligen Schlüsseln und schreibt sofort 100 generierte Bytes zurück zu diesen Schlüsseln.
Stand: 16 DataNodes und 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 Threads). HBase-Version 1.2.0-cdh5.14.2.
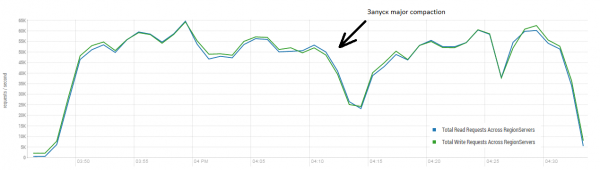
Das durchschnittliche Ergebnis liegt näher bei 40.000 Operationen pro Sekunde, was deutlich besser ist als im DataStax-Test. Für das Experiment können die Bedingungen jedoch leicht angepasst werden. Es ist ziemlich unwahrscheinlich, dass alle Arbeiten ausschließlich mit einer Tabelle und nur mit einzigartigen Schlüsseln durchgeführt werden. Angenommen, es gibt einen 'heißen' Schlüsselbereich, der die Hauptlast erzeugt. Daher versuchen wir, eine Last mit größeren Datensätzen (10 KB), ebenfalls in Stapeln zu 100, auf 4 verschiedenen Tabellen zu erstellen und den Bereich der angeforderten Schlüssel auf 50.000 zu begrenzen. Im folgenden Diagramm wird der Start von 40 Threads gezeigt, wobei jeder Thread eine Gruppe von 100 Schlüsseln liest und sofort zufällige 10 KB zu diesen Schlüsseln zurückschreibt.
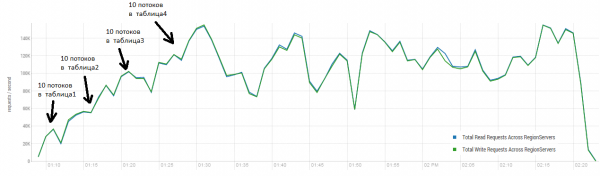
Stand: 16 DataNodes und 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 Threads). HBase-Version 1.2.0-cdh5.14.2.
Während der Last wurde mehrfach eine Major Compaction gestartet, wie oben gezeigt, und ohne diese Prozedur würde die Leistung allmählich abnehmen, jedoch entsteht während der Ausführung auch zusätzliche Last. Die Einbrüche wurden durch verschiedene Gründe verursacht. Manchmal beendeten die Threads ihre Arbeit, und während sie neu gestartet wurden, gab es eine Pause. Manchmal erzeugten Drittanwendungen zusätzliche Last auf dem Cluster.
Das gleichzeitige Lesen und Schreiben gehört zu den herausforderndsten Szenarien für HBase. Wenn nur kleine Put-Anfragen von beispielsweise 100 Bytes gemacht werden, können diese in Batches von 10.000 bis 50.000 zusammengefasst werden, um mehrere Hunderttausend Operationen pro Sekunde zu erreichen. Ähnlich verhält es sich mit reinen Leseanfragen. Es ist zu beachten, dass die Ergebnisse deutlich besser sind als die von DataStax, hauptsächlich dank der Batches von 50.000 Anfragen.
Stand: 16 DataNodes und 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 Threads). HBase-Version 1.2.0-cdh5.14.2.
10. Fazit
Dieses System lässt sich flexibel konfigurieren, jedoch bleibt der Einfluss zahlreicher Parameter weitgehend unbekannt. Einige davon wurden getestet, fanden aber keinen Eingang in die Ergebnisreihe der Tests. Vorläufige Experimente zeigten beispielsweise eine geringe Signifikanz des Parameters DATA_BLOCK_ENCODING, der Informationen unter Verwendung von Werten aus benachbarten Zellen kodiert, was für zufällig generierte Daten vollständig verständlich ist. Bei der Verwendung einer großen Anzahl sich wiederholender Objekte kann der Gewinn erheblich sein. Insgesamt macht HBase den Eindruck einer ernsthaften und gut durchdachten Datenbank, die bei Operationen mit großen Datenblöcken durchaus leistungsfähig sein kann. Besonders wenn die Möglichkeit besteht, Lese- und Schreibprozesse zeitlich zu trennen.
Wenn meiner Meinung nach etwas nicht ausreichend behandelt wurde, bin ich bereit, detaillierter zu berichten. Wir laden Sie ein, Ihre Erfahrungen zu teilen oder zu diskutieren, wenn Sie mit etwas nicht einverstanden sind.
Quelle: habr.com
