

In dieser Studie wollte ich untersuchen, welche Leistungsverbesserungen erzielt werden können, wenn man ClickHouse als Datenquelle anstelle von PostgreSQL verwendet. Ich kenne die Leistungsvorteile, die ich bei Nutzung von ClickHouse erhalte. Werden diese Vorteile auch erhalten, wenn ich über ein Foreign Data Wrapper (FDW) aus PostgreSQL auf ClickHouse zugreife?
Die untersuchten Datenbankumgebungen sind PostgreSQL v11, clickhousedb_fdw und die ClickHouse-Datenbank. Letztendlich werden wir von PostgreSQL v11 verschiedene SQL-Abfragen durchführen, die über unser clickhousedb_fdw zur ClickHouse-Datenbank geleitet werden. Dann werden wir sehen, wie die Leistung von FDW im Vergleich zu den gleichen Abfragen ausschaut, die in nativem PostgreSQL und nativem ClickHouse ausgeführt werden.
ClickHouse-Datenbank
ClickHouse ist ein Open-Source-Spaltenorientiertes Datenbankmanagementsystem, das 100 bis 1000 Mal schneller als traditionelle Datenbankansätze sein kann und mehr als eine Milliarde Zeilen in weniger als einer Sekunde verarbeiten kann.
clickhousedb_fdw
clickhousedb_fdw — die FDW-Schnittstelle für die ClickHouse-Datenbank ist ein Open-Source-Projekt von Percona. .
.
Wie Sie sehen werden, bietet es FDW für ClickHouse, das es ermöglicht, FROM zu SELECT und INTO zu INSERT in die ClickHouse-Datenbank von einem PostgreSQL-Server v11.
FDW unterstützt erweiterte Funktionen wie Aggregation und Joins. Dies erhöht die Leistung erheblich, indem die Ressourcen des entfernten Servers für diese ressourcenintensiven Operationen genutzt werden.
Benchmark-Umgebung
- Supermicro-Server:
- Intel® Xeon® CPU E5-2683 v3 @ 2.00GHz
- 2 Sockel / 28 Kerne / 56 Threads
- Speicher: 256 GB RAM
- Speicher: Samsung SM863 1,9 TB Enterprise SSD
- Dateisystem: ext4/xfs
- Betriebssystem: Linux smblade01 4.15.0-42-generic #45~16.04.1-Ubuntu
- PostgreSQL: Version 11
Benchmark-Tests
Anstelle eines maschinell generierten Datensatzes für diesen Test haben wir Daten zur "Leistung über die Zeit, gemeldete Betriebszeiten des Betreibers" von 1987 bis 2018 verwendet. Sie können auf die Daten zugreifen .
Die Größe der Datenbank beträgt 85 GB und bietet eine Tabelle mit 109 Spalten.
Benchmark-Abfragen
Hier sind die Abfragen, die ich zum Vergleich von ClickHouse, clickhousedb_fdw und PostgreSQL verwendet habe.
Q#
Abfrage enthält Aggregationen und GROUP BY
Q1
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q2
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q3
SELECT Origin, count(*) AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10;
Q4
SELECT Carrier, count() FROM ontime WHERE DepDelay > 10 AND Year = 2007 GROUP BY Carrier ORDER BY count() DESC;
Q5
SELECT a.Carrier, c, c2, c1000 / c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay > 10 AND Year = 2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year = 2007 GROUP BY Carrier ) b ON a.Carrier = b.Carrier ORDER BY c3 DESC;
Q6
SELECT a.Carrier, c, c2, c1000 / c2 as c3 FROM ( SELECT Carrier, count() AS c FROM ontime WHERE DepDelay > 10 AND Year >= 2000 AND Year = 2000 AND Year <= 2008 GROUP BY Carrier ) b ON a.Carrier = b.Carrier ORDER BY c3 DESC;
Q7
SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier;
Q8
SELECT Year, avg(DepDelay) FROM ontime GROUP BY Year;
Q9
SELECT Year, count(*) AS c1 FROM ontime GROUP BY Year;
Q10
SELECT avg(cnt) FROM (SELECT Year, Month, count(*) AS cnt FROM ontime WHERE DepDel15 = 1 GROUP BY Year, Month) a;
Q11
SELECT avg(c1) FROM (SELECT Year, Month, count(*) AS c1 FROM ontime GROUP BY Year, Month) a;
Q12
SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10;
Q13
SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10;
Abfrage enthält Joins
Q14
WÄHLEN Sie a.Jahr, c1/c2 AUS (Wählen Sie Jahr, Anzahl()1000 als c1 von ontime WO DepDelay>10 GRUPPIEREN NACH Jahr) a INNER JOIN (Wählen Sie Jahr, Anzahl(*) als c2 von ontime GRUPPIEREN NACH Jahr) b ON a.Jahr=b.Jahr BESTELLEN NACH a.Jahr;
Q15
WÄHLEN Sie a.”Jahr”, c1/c2 AUS (Wählen Sie “Jahr”, Anzahl()1000 als c1 VON fontime WO “DepDelay”>10 GRUPPIEREN NACH “Jahr”) a INNER JOIN (Wählen Sie “Jahr”, Anzahl(*) als c2 VON fontime GRUPPIEREN NACH “Jahr”) b ON a.”Jahr”=b.”Jahr”;
Tabelle-1: Abfragen, die im Benchmark verwendet wurden
Abfrageausführungen
Hier sind die Ergebnisse jeder Abfrage bei Ausführung in verschiedenen Datenbankeinstellungen: PostgreSQL mit und ohne Indizes, eigenes ClickHouse und clickhousedb_fdw. Die Zeit wird in Millisekunden angezeigt.
Q#
PostgreSQL
PostgreSQL (Indiziert)
ClickHouse
clickhousedb_fdw
Q1
27920
19634
23
57
Q2
35124
17301
50
80
Q3
34046
15618
67
115
Q4
31632
7667
25
37
Q5
47220
8976
27
60
Q6
58233
24368
55
153
Q7
30566
13256
52
91
Q8
38309
60511
112
179
Q9
20674
37979
31
81
Q10
34990
20102
56
148
Q11
30489
51658
37
155
Q12
39357
33742
186
1333
Q13
29912
30709
101
384
Q14
54126
39913
124
1364212
Q15
97258
30211
245
259
Tabelle-1: Zeit, die benötigt wird, um die im Benchmark verwendeten Abfragen auszuführen
Ergebnisse anzeigen
Das Diagramm zeigt die Ausführungszeit der Abfrage in Millisekunden, die X-Achse zeigt die Abfragenummer aus den obigen Tabellen, und die Y-Achse zeigt die Ausführungszeit in Millisekunden. Die Ergebnisse von ClickHouse und die aus Postgres mit clickhousedb_fdw erhaltenen Daten werden angezeigt. Aus der Tabelle geht hervor, dass es einen enormen Unterschied zwischen PostgreSQL und ClickHouse gibt, jedoch nur einen minimalen Unterschied zwischen ClickHouse und clickhousedb_fdw.
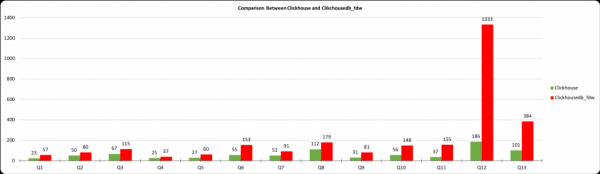
Dieses Diagramm zeigt den Unterschied zwischen ClickhouseDB und clickhousedb_fdw. In den meisten Abfragen sind die Overheads von FDW nicht so groß und kaum spürbar, außer bei Q12. Diese Abfrage enthält Joins und eine ORDER BY-Klausel. Aufgrund der ORDER BY GROUP/BY und ORDER BY wird nicht auf ClickHouse verwiesen.
In Tabelle 2 sehen wir einen Anstieg der Zeit bei den Abfragen Q12 und Q13. Ich wiederhole, dies liegt an der ORDER BY-Klausel. Um dies zu bestätigen, habe ich die Abfragen Q-14 und Q-15 mit und ohne ORDER BY-Klausel ausgeführt. Ohne ORDER BY beträgt die Ausführungszeit 259 ms, mit ORDER BY hingegen 1364212. Zur Fehlersuche dieser Abfrage erkläre ich beide Abfragen, und hier sind die Erklärungsergebnisse.
Q15: Ohne ORDER BY-Klausel
bm=# EXPLAIN VERBOS SELECT a."Year", c1/c2
FROM (SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) AS c2 FROM fontime GROUP BY "Year") b ON a."Year"=b."Year";Q15: Abfrage ohne ORDER BY-Klausel
ABFRAGEPLAN
Hash Join (Kosten=2250,00..128516,06 Zeilen=50000000 Breite=12)
Ausgabe: fontime."Jahr", (((count(*) * 1000)) / b.c2)
Innere Einzigartigkeit: wahr Hash-Bedingung: (fontime."Jahr" = b."Jahr")
-> Foreign Scan (Kosten=1,00..-1,00 Zeilen=100000 Breite=12)
Ausgabe: fontime."Jahr", ((count(*) * 1000))
Beziehungen: Aggregat auf (fontime)
Remote SQL: SELECT "Jahr", (count(*) * 1000) FROM "default".ontime WHERE (("DepDelay" > 10)) GROUP BY "Jahr"
-> Hash (Kosten=999,00..999,00 Zeilen=100000 Breite=12)
Ausgabe: b.c2, b."Jahr"
-> Subquery Scan auf b (Kosten=1,00..999,00 Zeilen=100000 Breite=12)
Ausgabe: b.c2, b."Jahr"
-> Foreign Scan (Kosten=1,00..-1,00 Zeilen=100000 Breite=12)
Ausgabe: fontime_1."Jahr", (count(*))
Beziehungen: Aggregat auf (fontime)
Remote SQL: SELECT "Jahr", count(*) FROM "default".ontime GROUP BY "Jahr"(16 Zeilen)Q14: Abfrage mit ORDER BY-Klausel
bm=# ERKLÄREN VERBOSSEN SELECT a."Jahr", c1/c2 FROM(SELECT "Jahr", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Jahr") a
INNER JOIN(SELECT "Jahr", count(*) as c2 FROM fontime GROUP BY "Jahr") b ON a."Jahr"= b."Jahr"
ORDER BY a."Jahr";Q14: Abfrageplan mit ORDER BY-Klausel
ABFRAGEPLAN
Merge Join (Kosten=2,00..628498,02 Zeilen=50000000 Breite=12)
Ausgabe: fontime."Jahr", (((count(*) * 1000)) / (count(*)))
Innere Eindeutigkeit: wahr Merge-Bedingung: (fontime."Jahr" = fontime_1."Jahr")
-> GroupAggregate (Kosten=1,00..499,01 Zeilen=1 Breite=12)
Ausgabe: fontime."Jahr", (count(*) * 1000)
Gruppenschlüssel: fontime."Jahr"
-> Foreign Scan on public.fontime (Kosten=1,00..-1,00 Zeilen=100000 Breite=4)
Remote SQL: SELECT "Jahr" FROM "default".ontime WHERE (("DepDelay" > 10))
ORDER BY "Jahr" ASC
-> GroupAggregate (Kosten=1,00..499,01 Zeilen=1 Breite=12)
Ausgabe: fontime_1."Jahr", count(*) Gruppenschlüssel: fontime_1."Jahr"
-> Foreign Scan on public.fontime fontime_1 (Kosten=1,00..-1,00 Zeilen=100000 Breite=4)
Remote SQL: SELECT "Jahr" FROM "default".ontime ORDER BY "Jahr" ASC(16 Zeilen)Fazit
Die Ergebnisse dieser Experimente zeigen, dass ClickHouse tatsächlich eine hervorragende Leistung bietet, während clickhousedb_fdw die Leistungsgewinne von ClickHouse in PostgreSQL zugänglich macht. Obwohl bei der Verwendung von clickhousedb_fdw einige Overheadkosten anfallen, sind diese gering und vergleichbar mit der Leistung, die bei einem nativen Einsatz in der ClickHouse-Datenbank erreicht wird. Das bestätigt zudem, dass fdw in PostgreSQL bemerkenswerte Ergebnisse liefert.
Telegram-Chat zu ClickHouse
Telegram-Chat zu PostgreSQL
Quelle: habr.com
