

Hallo zusammen, ich bin Alexander, ein Data Quality Engineer, der sich mit der Überprüfung der Datenqualität beschäftigt. In diesem Artikel werde ich darüber sprechen, wie ich dazu gekommen bin und warum dieses Testfeld im Jahr 2020 im Aufwind war.

Globaler Trend
Die heutige Welt erlebt eine weitere technologische Revolution, in deren Rahmen verschiedene Unternehmen gesammelte Daten nutzen, um ihren Verkaufsrhythmus, Gewinne und PR voranzutreiben. Es scheint, dass die Verfügbarkeit von guten (qualitativen) Daten sowie fähigen Köpfen, die diese in Geld verwandeln können (richtig verarbeiten, visualisieren, Machine Learning-Modelle erstellen usw.), heute der Schlüssel zum Erfolg für viele ist. Während vor 15-20 Jahren vor allem große Unternehmen intensiv mit Datensammlung und -monetarisierung beschäftigt waren, ist dies heute eine Aufgabe für fast alle rational denkenden Unternehmen.
Vor einigen Jahren haben alle weltweit auf Beschäftigung spezialisierten Portale begonnen, sich mit Stellenanzeigen für Data Scientists zu überfluten, da viele überzeugt waren, dass man mit einem solchen Spezialisten im Team ein Supermodell für maschinelles Lernen entwickeln, die Zukunft vorhersagen und einen "quantensprung" für das Unternehmen erzielen könnte. Mit der Zeit wurde jedoch klar, dass dieser Ansatz nahezu überall nicht funktioniert, da nicht alle Daten, die diesen Fachleuten zur Verfügung stehen, für das Training von Modellen geeignet sind.
Die Anfragen von Data Scientists beginnen: "Lass uns mehr Daten von diesen und jenen kaufen...", "Uns fehlen die Daten...", "Wir brauchen noch etwas mehr Daten und idealerweise hochwertige...". Basierend auf diesen Anfragen entwickelten sich zahlreiche Interaktionen zwischen Unternehmen, die über bestimmte Datensätze verfügen. Natürlich erforderte dies eine technische Organisation des Prozesses – sich mit der Datenquelle zu verbinden, die Daten herunterzuladen, zu überprüfen, dass sie vollständig geladen sind, usw. Die Anzahl solcher Prozesse nahm zu, und mittlerweile sehen wir einen enormen Bedarf an einer anderen Art von Spezialisten – Data Quality Engineers – die den Datenfluss im System (Data Pipelines), die Datenqualität am Eingang und Ausgang überwachen und Rückschlüsse auf deren Angemessenheit, Integrität und andere Eigenschaften ziehen.
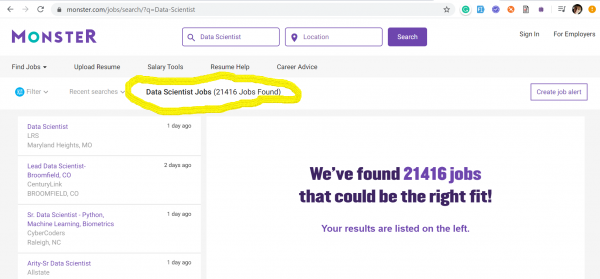
Der Trend zu Data Quality Engineers kam zu uns aus den USA, wo im Höhepunkt des kapitalistischen Booms niemand bereit ist, die Schlacht um Daten zu verlieren. Unten habe ich Screenshots von zwei der beliebtesten Jobportale in den USA eingefügt: und — auf denen die Daten zum Stand am 17. März 2020 über die Anzahl der veröffentlichten Stellenangebote für die Schlüsselwörter: Data Quality und Data Scientist angezeigt werden.
Data Scientists – 21.416 Stellenangebote
Data Quality – 41.104 Stellenangebote
Data Scientists – 404 Stellenangebote
Data Quality – 2.020 Stellenangebote
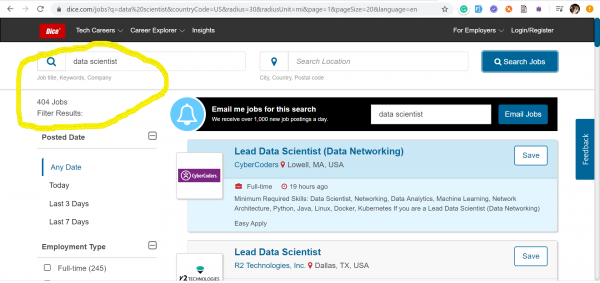
Es ist offensichtlich, dass diese Berufe in keiner Weise miteinander konkurrieren. Mit Screenshots wollte ich einfach die aktuelle Situation auf dem Arbeitsmarkt in Bezug auf die Nachfrage nach Data Quality-Ingenieuren illustrieren, die derzeit deutlich höher ist als die nach Data Scientists.
Im Juni 2019 hat EPAM, um auf die Bedürfnisse des modernen IT-Marktes zu reagieren, den Bereich Data Quality als separate Praxis ausgegliedert. Data Quality-Ingenieure verwalten im Rahmen ihrer täglichen Arbeit Daten, prüfen ihr Verhalten in neuen Bedingungen und Systemen und überwachen die Relevanz, Angemessenheit und Aktualität der Daten. Dabei widmen Data Quality-Ingenieure in der praktischen Umsetzung tatsächlich etwas Zeit dem klassischen funktionalen Testing, ABER was stark vom Projekt abhängt (ein Beispiel werde ich gleich anführen).
Die Aufgaben eines Data Quality Ingenieurs beschränken sich nicht nur auf routinemäßige manuelle/automatische Überprüfungen von «Nullwerten, Zählungen und Summen» in Datenbanktabellen, sondern erfordern ein tiefes Verständnis der geschäftlichen Bedürfnisse des Kunden und die Fähigkeit, die vorhandenen Daten in verwertbare Geschäftsinformationen zu transformieren.
Theorie der Datenqualität

Um die Rolle eines solchen Ingenieurs vollständig zu verstehen, lassen Sie uns klären, was Data Quality theoretisch bedeutet.
Datenqualität ist ein Teilbereich des Data Managements (eine gesamte Welt, die wir Ihnen zur eigenständigen Erforschung überlassen) und befasst sich mit der Analyse von Daten anhand der folgenden Kriterien:
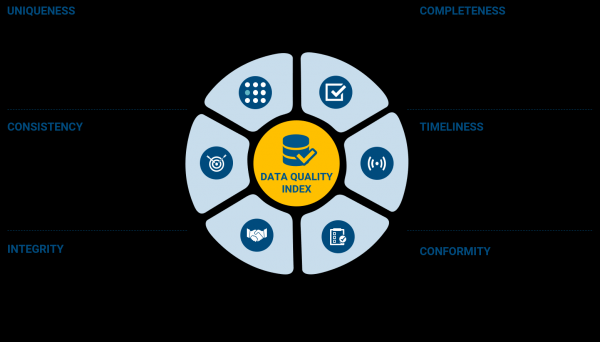
Ich denke, es ist nicht notwendig, jeden Punkt auszuleuchten (in der Theorie werden sie als «Daten-Dimensionen» bezeichnet), da sie auf dem Bild gut beschrieben sind. Der Testprozess selbst sieht jedoch nicht vor, diese Merkmale eins zu eins in Testfällen zu kopieren und zu überprüfen. In der Datenqualität, wie in jeder anderen Art des Testens, muss zunächst von den Qualitätsanforderungen ausgegangen werden, die mit den Projektbeteiligten, die geschäftliche Entscheidungen treffen, abgestimmt wurden.
Je nach Projekt kann ein Data Quality Engineer unterschiedliche Funktionen übernehmen: vom einfachen Testautomatisierer mit einer oberflächlichen Bewertung der Datenqualität bis hin zu jemandem, der eine tiefgreifende Profilierung anhand der oben genannten Merkmale durchführt.
Eine sehr ausführliche Beschreibung der Prozesse im Bereich Data Management, Data Quality und verwandter Themen ist in einem Buch mit dem Titel „DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition“. Ich empfehle dieses Buch als Einführung in dieses Thema (den Link dazu finden Sie am Ende des Artikels).
Meine Geschichte
In der IT-Branche habe ich den Weg vom Junior Tester in Produktunternehmen bis zum Lead Data Quality Engineer bei EPAM zurückgelegt. Nach etwa zwei Jahren als Tester hatte ich die feste Überzeugung, dass ich alle Arten von Tests durchgeführt hatte: Regression, Funktionalität, Stress, Stabilität, Sicherheit, UI usw. — und ich habe eine Vielzahl von Testtools ausprobiert, während ich an drei Programmiersprachen gearbeitet habe: Java, Scala, Python.
Wenn ich zurückblicke, verstehe ich, warum mein berufliches Skillset so vielfältig ist – ich war an Projekten beteiligt, die sich mit Daten in großem und kleinem Maßstab beschäftigten. Dies führte mich in die Welt zahlreicher Werkzeuge und Wachstumschancen.
Um die Vielfalt der Werkzeuge und Möglichkeiten zur Erlangung neuer Kenntnisse und Fähigkeiten zu schätzen, genügt ein Blick auf das Bild unten, das die populärsten darunter im Bereich „Data & AI“ zeigt.

Solche Illustrationen erstellt jährlich einer der bekannten Risikokapitalgeber, Matt Turck, ein ehemaliger Softwareentwickler. Hier finden Sie seinen Blog und , in der er als Partner tätig ist.
Besonders schnell wuchs ich beruflich, als ich der einzige Tester in einem Projekt war, oder zumindest am Anfang des Projekts. In solchen Momenten ist man für den gesamten Testprozess verantwortlich, und man hat keine Möglichkeit, zurückzutreten, nur voranzuschreiten. Zunächst machte mir das Angst, doch jetzt sind mir alle Vorteile dieser Herausforderung offensichtlich:
- Du kommunizierst mit dem gesamten Team wie nie zuvor, da es keinen Proxy für die Kommunikation gibt: weder einen Testmanager noch Kollegen aus der Testabteilung.
- Das Eintauchen in das Projekt wird unglaublich tief, und du hast Informationen über alle Komponenten sowohl im Gesamtbild als auch in den Details.
- Die Entwickler sehen dich nicht mehr als 'den Typen aus dem Testing, der nicht wirklich etwas macht', sondern eher als gleichwertigen Partner, der durch automatisierte Tests und das frühzeitige Erkennen von Bugs einen unglaublichen Nutzen für das Team bringt.
- Das Ergebnis ist — du bist effizienter, qualifizierter und gefragter.
Im Verlauf des Projekts wurde ich in 100 % der Fälle zum Mentor für die neu hinzugekommenen Tester, schulte sie und gab das Wissen weiter, das ich selbst erworben hatte. Allerdings erhielt ich je nach Projekt nicht immer die Experten für automatisiertes Testen von der Leitung, weshalb es notwendig war, entweder sie in der Automatisierung auszubilden (für diejenigen, die es wollten) oder Werkzeuge zu entwickeln, die sie in ihrem Alltag nutzen konnten (z. B. Daten-Generierungstools und deren Ladefunktionen in das System, Werkzeuge für Lasttests/stabilitätstests "schnell und einfach" usw.).
Beispiel eines konkreten Projekts
Leider kann ich aufgrund von Geheimhaltungsverpflichtungen nicht detailliert über die Projekte sprechen, an denen ich gearbeitet habe, jedoch werde ich Beispiele typischer Aufgaben eines Data Quality Engineers in einem der Projekte nennen.
Das Ziel des Projekts war es, eine Plattform zur Aufbereitung von Daten zu schaffen, um darauf basierende Modelle für maschinelles Lernen zu trainieren. Der Auftraggeber war ein großes Pharmaunternehmen aus den USA. Technisch handelte es sich um einen Cluster , der auf Instanzen mit mehreren Mikrodiensten und dem zugrunde liegenden Open-Source-Projekt von EPAM – , das auf die Bedürfnisse des spezifischen Kunden angepasst wurde (das Projekt hat sich mittlerweile zu weiterentwickelt). Die ETL-Prozesse wurden mit Hilfe von organisiert und übertrugen Daten aus des Kunden in Buckets. Anschließend wurde ein Docker-Image des maschinellen Lernmodells auf der Plattform bereitgestellt, das mit aktuellen Daten trainiert wurde und über eine REST-API-Schnittstelle Vorhersagen lieferte, die für das Geschäft von Interesse waren und spezifische Aufgaben lösten.
Visuell sah das etwa so aus:
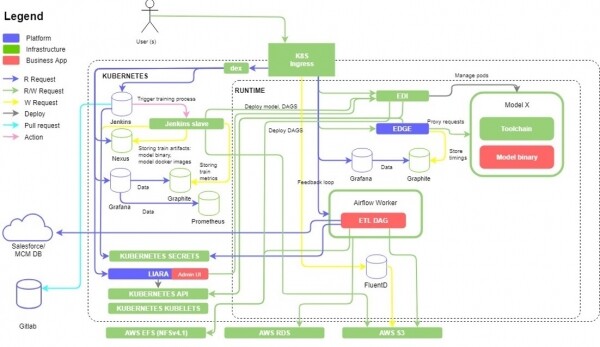
Es gab ausreichend funktionale Tests für dieses Projekt, und angesichts der Geschwindigkeit, mit der neue Funktionen entwickelt wurden, und der Notwendigkeit, das Release-Zyklus-Tempo (zweiwöchige Sprints) aufrechtzuerhalten, musste bereits frühzeitig über die Automatisierung der Tests der kritischsten Systemkomponenten nachgedacht werden. Der größte Teil der Plattform, die auf Kubernetes basierte, wurde durch Tests automatisiert, die mit + Python, aber es war auch notwendig, sie zu unterstützen und zu erweitern. Darüber hinaus wurde zum Komfort des Kunden ein GUI zur Verwaltung der auf dem Cluster bereitgestellten Modelle des maschinellen Lernens erstellt, sowie die Möglichkeit, anzugeben, woher und wohin die Daten für das Training der Modelle übertragen werden müssen. Diese umfangreiche Ergänzung führte zu einer Erweiterung der automatisierten funktionalen Tests, die überwiegend über REST-API-Aufrufe und eine geringe Anzahl von End-to-End-UI-Tests durchgeführt wurden. Ungefähr zur Mitte dieses Prozesses schloss sich uns ein manueller Tester an, der ausgezeichnete Arbeit beim Abnahmetesting der Produktversionen und bei der Kommunikation mit dem Kunden hinsichtlich der Abnahme des nächsten Releases leistete. Außerdem konnten wir durch den neuen Spezialisten unsere Arbeit dokumentieren und einige sehr wichtige manuelle Prüfungen hinzufügen, die zunächst schwer zu automatisieren waren.
Und schließlich, nachdem wir Stabilität von der Plattform und der GUI-Erweiterung erreicht hatten, begannen wir mit dem Aufbau von ETL-Pipelines mithilfe von Apache Airflow DAGs. Die automatisierte Datenqualitätsprüfung wurde durch das Schreiben spezieller Airflow DAGs durchgeführt, die die Daten gemäß den Ergebnissen des ETL-Prozesses überprüften. In diesem Projekt hatten wir das Glück, dass der Kunde uns Zugang zu anonymisierten Datensätzen gewährte, auf denen wir getestet wurden. Wir überprüften die Daten zeilenweise auf Typübereinstimmung, das Vorhandensein fehlerhafter Daten, die Gesamtanzahl der Datensätze vor und nach der Verarbeitung sowie den Vergleich der durch den ETL-Prozess vorgenommenen Transformationen hinsichtlich Aggregation, Änderung der Spaltennamen und mehr. Darüber hinaus wurden diese Prüfungen auf verschiedene Datenquellen ausgeweitet, beispielsweise auf MySQL neben SalesForce.
Die Prüfungen der endgültigen Datenqualität wurden bereits auf der S3-Ebene durchgeführt, wo sie gespeichert und im ready-to-use-Zustand für das Training von Maschinenlernmodellen waren. Um die Daten aus der finalen CSV-Datei, die im S3-Bucket gespeichert war, abzurufen und zu validieren, wurde ein Code unter Verwendung von .
Es gab auch die Anforderung des Kunden, einen Teil der Daten in einem S3-Bucket und einen anderen Teil in einem anderen S3-Bucket zu speichern. Dafür mussten zusätzliche Prüfungen implementiert werden, die die Richtigkeit dieser Sortierung überwachten.
Zusammengefasste Erfahrungen aus anderen Projekten
Ein Beispiel für die allgemeinsten Aktivitäten eines Data Quality Ingenieurs:
- Testdaten (gültige, ungültige, große und kleine) über ein automatisiertes Tool vorbereiten.
- Den vorbereiteten Datensatz in die Ausgangsquelle hochladen und dessen Einsatzbereitschaft überprüfen.
- ETL-Prozesse zur Verarbeitung des Datensatzes von der Ausgangsspeicherquelle in das endgültige oder Zwischenziel starten, wobei ein bestimmter Satz von Einstellungen angewendet wird (sofern konfigurierbare Parameter für die ETL-Aufgabe festgelegt werden können).
- Die durch den ETL-Prozess verarbeiteten Daten auf ihre Qualität und Übereinstimmung mit den Geschäftsanforderungen überprüfen.
Der Hauptfokus der Prüfungen sollte nicht nur darauf liegen, dass der Datenstrom im System grundsätzlich verarbeitet wurde und bis zum Ende gelangt ist (was Teil der funktionalen Tests ist), sondern vielmehr auf der Überprüfung und Validierung der Daten hinsichtlich ihrer Übereinstimmung mit den erwarteten Anforderungen, der Erkennung von Anomalien und anderen Aspekten.
Werkzeuge
Eine der Techniken zur Kontrolle dieser Daten könnte die Organisation von Kettenprüfungen in jeder Phase der Datenverarbeitung sein, das sogenannte „data chain“ – die Kontrolle der Daten vom Ursprung bis zum Endnutzungspunkt. Solche Prüfungen werden häufig durch das Erstellen von SQL-Abfragen realisiert, die sicherstellen, dass diese Abfragen so leichtgewichtig wie möglich sind und spezifische Aspekte der Datenqualität überprüfen (Tabellenmetadaten, leere Zeilen, NULL-Werte, Syntaxfehler – andere erforderliche Überprüfungsattribute).
Bei Regressionstests, die bereits vorhandene (unveränderte oder geringfügig veränderte) Datensätze verwenden, können im Automatisierungscode bereits vorbereitete Prüfschemata zur Qualitätssicherung gespeichert werden (einschließlich der Beschreibung der erwarteten Metadaten der Tabellen, von Objekten, die während des Tests zufällig ausgewählt werden können, und mehr).
Während des Tests ist es auch notwendig, Test-ETL-Prozesse zu schreiben, mithilfe von Frameworks wie Apache Airflow, oder sogar von Black-Box-Cloud-Tools wie , usw. Diese Situation zwingt den Testingenieur dazu, sich in die Funktionsweise der genannten Tools einzuarbeiten, um sowohl funktionale Tests (wie die bestehenden ETL-Prozesse im Projekt) effektiver durchzuführen als auch sie zur Datenprüfung zu nutzen. Insbesondere für Apache Airflow stehen bereits vorbereitete Operatoren zur Verfügung, um mit beliebten Analyse-Datenbanken zu arbeiten, zum Beispiel . Ein einfaches Beispiel für dessen Verwendung wurde bereits beschrieben, , daher möchte ich das nicht wiederholen.
Neben fertigen Lösungen steht es Ihnen frei, Ihre eigenen Techniken und Werkzeuge zu implementieren. Dies wird nicht nur dem Projekt zugutekommen, sondern auch dem Data Quality Engineer, der dadurch seinen technischen Horizont und seine Programmierfähigkeiten erweitert.
Wie es in einem realen Projekt funktioniert
Ein gutes Beispiel für die letzten Absätze über die „Datenkette“, ETL und die allgegenwärtigen Überprüfungen ist der folgende Prozess aus einem realen Projekt:
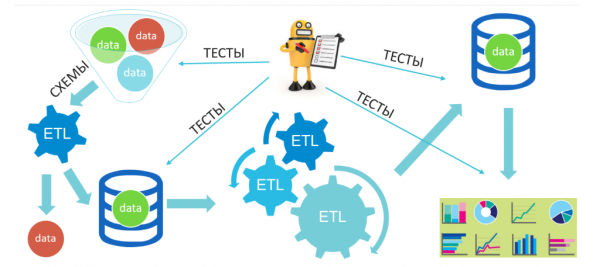
Hier gelangen verschiedene Daten (natürlich von uns vorbereitet) in den Eingangsbereich unseres Systems: gültige, ungültige, gemischte usw., die dann gefiltert und in ein Zwischenlager überführt werden. Anschließend warten sie auf eine Reihe von Transformationen und werden in ein Endlager überführt, aus dem dann die Analytik, Datenvisualisierung und die Suche nach Geschäftseinblicken erfolgen. In einem solchen System konzentrieren wir uns, ohne die funktionale Arbeit der ETL-Prozesse zu überprüfen, auf die Datenqualität vor und nach den Transformationen sowie auf die Ergebnisse in der Analytik.
Zusammenfassend lässt sich sagen, dass ich unabhängig von den Orten, an denen ich gearbeitet habe, immer in Datenprojekten involviert war, die folgende Merkmale aufwiesen:
- Nur durch Automatisierung lassen sich bestimmte Fälle überprüfen und ein für das Geschäft akzeptabler Release-Zyklus erreichen.
- Ein Tester in einem solchen Projekt ist eines der respektiertesten Mitglieder des Teams, da er für jeden Teilnehmer einen enormen Nutzen bringt (Beschleunigung der Tests, gute Daten für Data Scientists, frühzeitige Fehlererkennung).
- Es spielt keine Rolle, ob Sie auf eigener Hardware oder in der Cloud arbeiten — alle Ressourcen sind in einem Cluster vom Typ Hortonworks, Cloudera, Mesos, Kubernetes usw. abstrahiert.
- Die Projekte basieren auf einem Mikroservice-Ansatz, wobei verteilte und parallele Berechnungen überwiegen.
Ich möchte betonen, dass ein Tester im Bereich Data Quality seinen professionellen Fokus auf den Code des Produkts und die verwendeten Werkzeuge verlagert.
Besonderheiten des Data Quality Testings
Darüber hinaus habe ich folgende (sehr verallgemeinerte und ausschließlich subjektive) Merkmale des Testens in Data (Big Data)-Projekten (Systemen) und anderen Bereichen herausgearbeitet:

Nützliche Links
- Theorie: .
- EPAM
- Empfohlene Materialien für angehende Data Quality Ingenieure:
- Kostenloser Kurs auf Stepik: .
- Kurs auf LinkedIn Learning: .
- Artikel:
- ;
- ;
- ;
- Video:
- ;
- ;
Fazit
Datenqualität — ist ein sehr junges und vielversprechendes Gebiet, Teil davon zu sein, bedeutet, Teil eines Startups zu werden. Wenn Sie in die Datenqualität eintauchen, werden Sie mit einer Vielzahl moderner, gefragter Technologien in Kontakt kommen, aber das Wichtigste ist, dass Ihnen riesige Möglichkeiten eröffnet werden, Ihre Ideen zu generieren und umzusetzen. Sie werden den Ansatz der kontinuierlichen Verbesserung nicht nur im Projekt, sondern auch für sich selbst nutzen können, während Sie sich kontinuierlich als Fachkraft weiterentwickeln.
Quelle: habr.com
