

Der Kanarienvogel ist ein kleiner Vogel, der ständig singt. Diese Vögel reagieren empfindlich auf Methan und Kohlenmonoxid. Schon eine geringe Konzentration überschüssiger Gase in der Luft führt dazu, dass sie das Bewusstsein verlieren oder sterben. Goldsucher und Bergleute nahmen die Vögel zum Schürfen mit: Während die Kanarienvögel sangen, konnten sie arbeiten; Wenn sie verstummten, war Gas in der Mine und es war Zeit zu gehen. Bergleute opferten einen kleinen Vogel, um lebend aus den Minen zu kommen.

Eine ähnliche Praxis hat ihren Weg in die IT gefunden. Beispielsweise bei einer Standardaufgabe, bei der eine neue Version eines Dienstes oder einer Anwendung nach vorherigem Test in die Produktion überführt wird. Die Testumgebung ist möglicherweise zu teuer, automatisierte Tests decken nicht alles ab, was Sie möchten, und es ist riskant, nicht zu testen und dabei die Qualität zu beeinträchtigen. Hier bietet sich der Canary-Deployment-Ansatz an, bei dem ein wenig echter Produktionsverkehr an die neue Version gesendet wird. Der Ansatz hilft sicher neue Version prüfen für die Produktion, wenig für ein großes Ziel opfern. Im Detail, wie der Ansatz funktioniert, was nützlich ist und wie man ihn umsetzt, wird Andrej Markelow (), am Beispiel der Implementierung im Unternehmen Infobip.
Andrej Markelow — Leitender Softwareentwickler bei Infobip, entwickelt seit 11 Jahren Java-Anwendungen in den Bereichen Finanzen und Telekommunikation. Entwickelt Open-Source-Produkte, beteiligt sich aktiv an der Atlassian-Community und schreibt Plugins für Atlassian-Produkte. Prometheus, Docker und Redis Evangelist.

Über Infobip
Es handelt sich um eine globale Telekommunikationsplattform, die es Banken, Einzelhändlern, Online-Shops und Transportunternehmen ermöglicht, ihren Kunden Nachrichten per SMS, Push, E-Mail und Sprachnachrichten zu senden. In einem solchen Geschäft sind Stabilität und Zuverlässigkeit wichtig, damit die Kunden ihre Nachrichten rechtzeitig erhalten.
Infobip IT-Infrastruktur in Zahlen:
- 15 Rechenzentren weltweit;
- 500 einzigartige Dienste im Betrieb;
- 2500 Serviceinstanzen, also viel mehr als Befehle;
- 4,5 TB monatlicher Datenverkehr;
- 4,5 Milliarden Telefonnummern;
Das Geschäft wächst und damit auch die Zahl der Veröffentlichungen. Wir führen 60 Veröffentlichungen pro Tag, weil die Kunden mehr Optionen und Leistung wünschen. Aber es ist schwierig – es gibt viele Dienste und wenige Teams. Sie müssen schnell Code schreiben, der in der Produktion fehlerfrei funktionieren sollte.
Veröffentlichungen
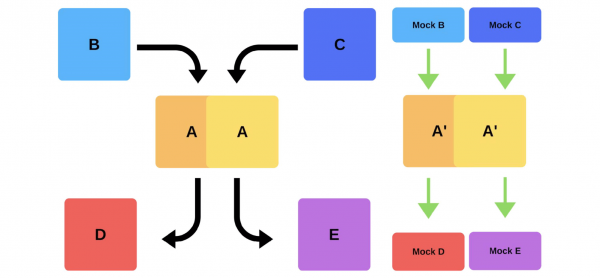
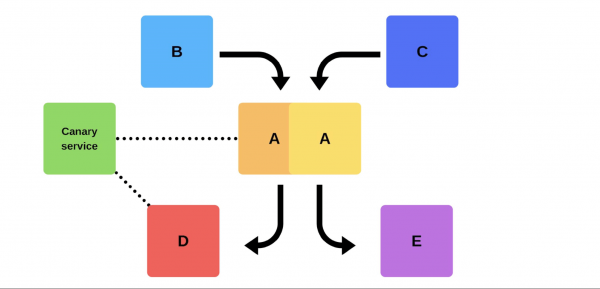
Eine typische Veröffentlichung sieht für uns folgendermaßen aus. Beispielsweise gibt es die Dienste A, B, C, D und E, die jeweils von einem separaten Team entwickelt werden.
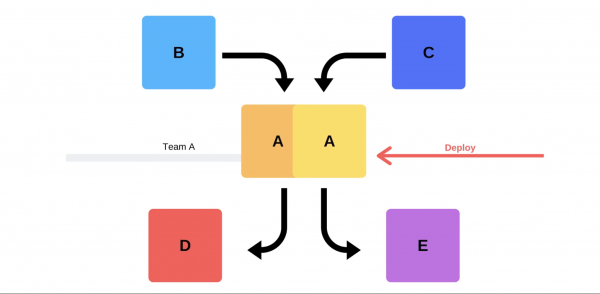
Irgendwann beschließt das Team von Dienst A, eine neue Version bereitzustellen, aber die Teams der Dienste B, C, D und E wissen nichts davon. Für das Vorgehen des Service-A-Teams gibt es zwei Möglichkeiten.
Wird durchführen inkrementelle Veröffentlichung: Ersetzen Sie zuerst eine Version, dann die zweite.
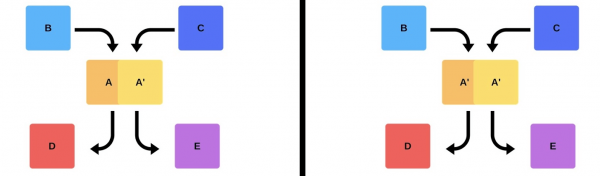
Aber es gibt noch eine zweite Möglichkeit: das Team finden Sie zusätzliche Kapazitäten und Maschinen, stellen Sie die neue Version bereit, wechseln Sie dann den Router und die Version wird in der Produktion funktionieren.

In jedem Fall kommt es nach der Bereitstellung fast immer zu Problemen, auch wenn die Version getestet wurde. Sie können manuell testen, Sie können automatisch testen oder Sie können nicht testen – Probleme werden in jedem Fall auftreten. Die einfachste und korrekteste Lösung besteht darin, auf eine funktionierende Version zurückzusetzen. Nur dann können wir uns mit den Schäden und Ursachen auseinandersetzen und sie beheben.
Was wollen wir also?
Wir brauchen keine Probleme. Wenn Kunden sie vor uns entdecken, schadet das unserem Ruf. Also müssen wir Probleme schneller finden als Kunden. Durch proaktives Handeln minimieren wir den Schaden.
Gleichzeitig wollen wir Beschleunigen Sie die Bereitstellungdamit dies schnell, einfach, natürlich und ohne Stress für das Team geschieht. Ingenieure, DevOps-Ingenieure und Programmierer müssen geschützt werden – die Veröffentlichung einer neuen Version ist stressig. Das Team ist kein Verbrauchsgut, wir streben die Humanressourcen rational einzusetzen.
Bereitstellungsprobleme
Der Kundenverkehr ist unvorhersehbar. Es lässt sich nicht vorhersagen, wann der Kundenverkehr am geringsten ist. Wir wissen nicht, wo und wann Kunden ihre Kampagnen starten werden – es könnte heute Abend in Indien und morgen in Hongkong sein. Angesichts des großen Zeitunterschieds ist selbst eine Bereitstellung um 2 Uhr morgens keine Garantie dafür, dass Clients nicht betroffen sind.
Probleme der Anbieter. Messenger und Provider sind unsere Partner. Manchmal treten Störungen auf, die bei der Bereitstellung neuer Versionen zu Fehlern führen.
Verteilte Teams. Die Teams, die den Client und das Backend entwickeln, befinden sich in unterschiedlichen Zeitzonen. Aus diesem Grund können sie sich untereinander oft nicht einigen.
Rechenzentren können nicht auf der Bühne repliziert werden. In einem Rechenzentrum gibt es 200 Racks – das lässt sich in einer Sandbox nicht einmal annähernd erreichen.
Ausfallzeiteninakzeptabel! Wir verfügen über eine akzeptable Verfügbarkeit (Fehlerbudget), wenn wir beispielsweise 99,99 % der Zeit arbeiten und der verbleibende Prozentsatz das „Recht auf Fehler“ ist. Eine 100-prozentige Zuverlässigkeit lässt sich nicht erreichen, dennoch ist eine ständige Überwachung auf Abstürze und Ausfallzeiten wichtig.
Klassische Lösungen
Schreiben Sie Code ohne Fehler. Als ich ein junger Entwickler war, kamen Manager zu mir und baten mich, fehlerfreie Veröffentlichungen durchzuführen, aber das ist nicht immer möglich.
Schreiben von Tests. Tests funktionieren, aber manchmal nicht so, wie es das Unternehmen möchte. Der Zweck von Tests besteht nicht darin, Geld zu verdienen.
Test auf der Bühne. In meinen dreieinhalb Jahren bei Infobip habe ich noch nie erlebt, dass der Zustand der Bühne auch nur teilweise mit der Produktion übereinstimmte.
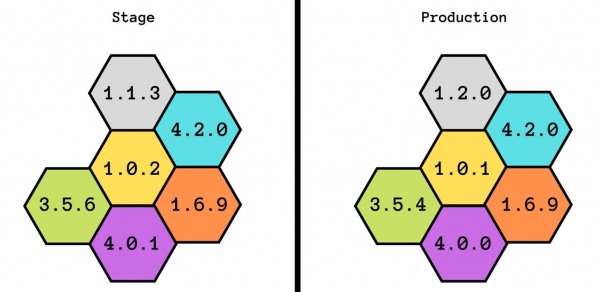
Wir haben sogar versucht, diese Idee weiterzuentwickeln: Zuerst hatten wir die Bühne, dann die Vorproduktion und dann die Vorproduktion der Vorproduktion. Aber auch das half nichts – sie waren nicht einmal gleich stark. Mit Stage können wir eine grundlegende Funktionalität garantieren, wissen aber nicht, wie es unter Last funktioniert.
Die Freigabe erfolgt durch den Entwickler. Dies ist eine bewährte Vorgehensweise: Selbst wenn jemand den Namen eines Kommentars ändert, wird dieser sofort der Produktion hinzugefügt. Dies trägt dazu bei, Verantwortung zu entwickeln und sich an die vorgenommenen Änderungen zu erinnern.
Darüber hinaus gibt es weitere Komplikationen. Für einen Entwickler ist es stressig, viel Zeit damit zu verbringen, alles manuell zu überprüfen.
Koordinierte Veröffentlichungen. Diese Option wird normalerweise vom Management vorgeschlagen: „Lassen Sie uns vereinbaren, dass Sie jeden Tag neue Versionen testen und hinzufügen.“ Das funktioniert nicht: Es gibt immer ein Team, das auf alle anderen wartet, oder umgekehrt.
Rauchtests
Eine andere Möglichkeit, unsere Bereitstellungsprobleme zu lösen. Sehen wir uns anhand des vorherigen Beispiels an, wie Smoke-Tests funktionieren, wenn Team A eine neue Version bereitstellen möchte.
Zunächst stellt das Team eine Instanz für die Produktion bereit. Nachrichten an die Instanz von Mocks simuliert realen Verkehrsodass es mit dem normalen täglichen Verkehr übereinstimmt. Wenn alles gut geht, schaltet das Team die neue Version auf Benutzerverkehr um.
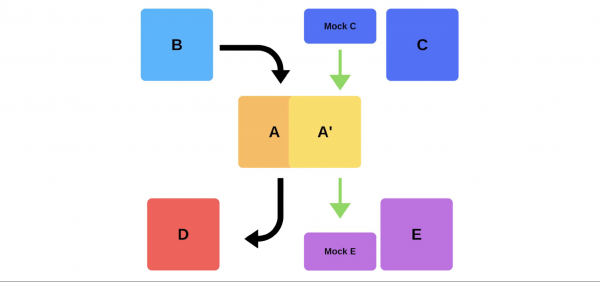
Die zweite Möglichkeit besteht darin, mit zusätzlichem Eisen. Das Team testet es in der Produktion, stellt es dann um und alles funktioniert.
Nachteile von Smoke-Tests:
- Tests sind nicht vertrauenswürdig. Wo kann ich den gleichen Datenverkehr wie für die Produktion erhalten? Sie können die Daten von gestern oder vor einer Woche verwenden, diese stimmen jedoch nicht immer mit den aktuellen Daten überein.
- Schwierig zu pflegen. Sie müssen Testkonten verwalten und diese vor jeder Bereitstellung ständig zurücksetzen, wenn aktive Datensätze an den Speicher gesendet werden. Es ist schwieriger, als einen Test in Ihrer Sandbox zu schreiben.
Der einzige Bonus hier ist Sie können die Leistung überprüfen.
Canary-Veröffentlichungen
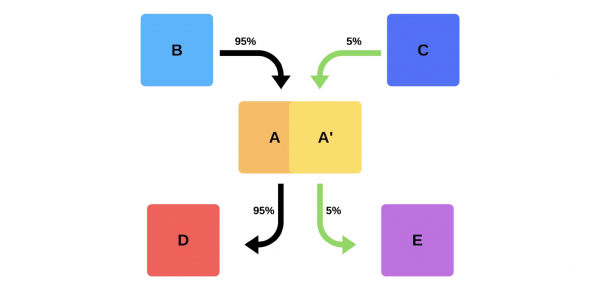
Aufgrund der Mängel der Smoke-Tests haben wir begonnen, Canary-Releases zu verwenden.
Eine ähnliche Vorgehensweise wie bei Bergleuten, die Kanarienvögel zur Anzeige des Gasstands verwendeten, hat ihren Weg in die IT gefunden. Wir lassen herein etwas echter Produktionsverkehr zur neuen Version, während Sie versuchen, das Service Level Agreement (SLA) einzuhalten. SLA ist unser „Recht, Fehler zu machen“, das wir einmal im Jahr (oder für einen anderen Zeitraum) nutzen können. Wenn alles gut geht, werden wir mehr Verkehr hinzufügen. Wenn nicht, senden wir die vorherigen Versionen zurück.
Umsetzung und Nuancen
Wie haben wir Canary-Releases implementiert? Beispielsweise sendet eine Gruppe von Kunden Nachrichten über unseren Dienst.
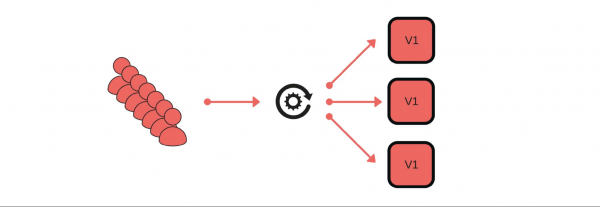
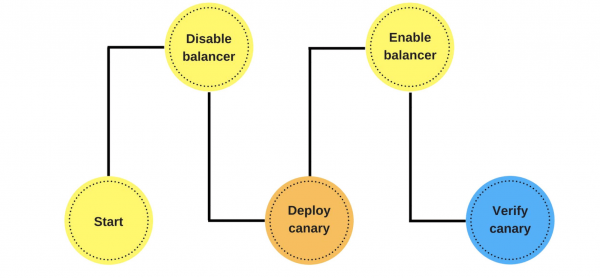
Das Deployment läuft folgendermaßen ab: Wir entfernen einen Knoten aus dem Balancer (1), ändern die Version (2) und starten separat ein wenig Verkehr (3).

Insgesamt sind alle in der Gruppe zufrieden, auch wenn ein Benutzer unzufrieden ist. Wenn alles gut ist, ändern wir alle Versionen.
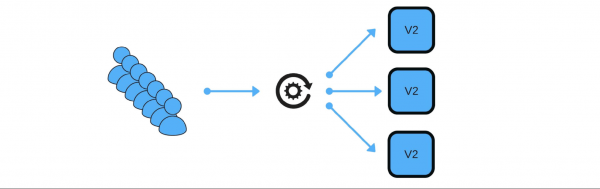
Ich zeige Ihnen schematisch, wie das bei Microservices in den meisten Fällen aussieht.
Es gibt Service Discovery und zwei weitere Dienste: S1N1 und S2. Der erste Dienst (S1N1) benachrichtigt Service Discovery, wenn er startet, und Service Discovery merkt sich dies. Der zweite Dienst mit zwei Knoten (S2N1 und S2N2) benachrichtigt Service Discovery ebenfalls beim Start.
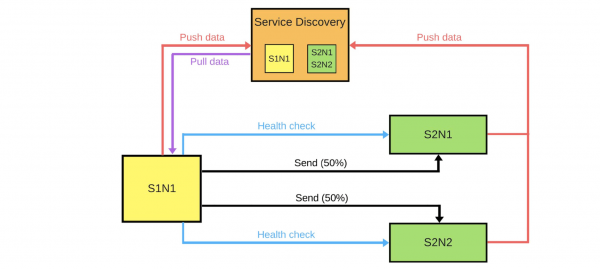
Der zweite Dienst fungiert als Server für den ersten. Der erste fordert von Service Discovery Informationen zu seinen Servern an und sucht und überprüft diese, sobald er sie erhält („Health Check“). Wenn er nachsieht, wird er ihnen Nachrichten senden.
Wenn jemand eine neue Version des zweiten Dienstes bereitstellen möchte, teilt er Service Discovery mit, dass der zweite Knoten ein Canary-Knoten sein wird: Er erhält weniger Datenverkehr, weil die Bereitstellung kurz bevorsteht. Wir entfernen den Canary-Knoten unter dem Balancer und der erste Dienst sendet keinen Datenverkehr dorthin.
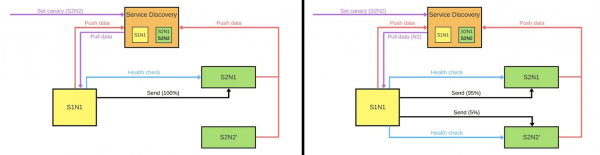
Wir ändern die Version und Service Discovery weiß, dass der zweite Knoten jetzt ein Canary ist – wir können ihm weniger Last (5 %) geben. Wenn alles in Ordnung ist, ändern wir die Version, geben die Ladungen zurück und arbeiten weiter.
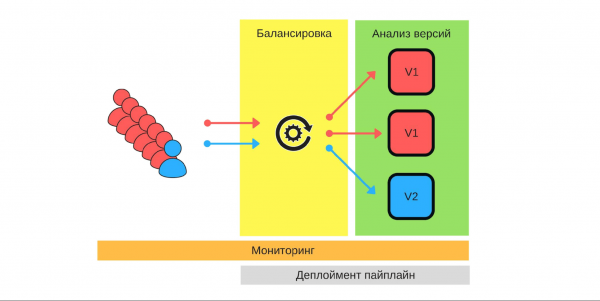
Um all dies umzusetzen, benötigen wir:
- Ausbalancieren;
- Überwachung, weil es wichtig ist zu wissen, was jeder Benutzer erwartet und wie unsere Dienste im Detail funktionieren;
- Versionsanalyse, um zu verstehen, wie gut die neue Version in der Produktion funktionieren wird;
- Automatisierung – wir schreiben die Bereitstellungspipeline.
Ausgleichend
Das ist das Erste, worüber wir nachdenken sollten. Es gibt zwei Ausgleichsstrategien.
Die einfachste Möglichkeit ist, wenn ein Knoten ist immer ein Kanarienvogel. Dieser Knoten erhält immer weniger Verkehr und wir beginnen von dort aus mit der Bereitstellung. Bei Problemen vergleichen wir die Funktionsweise vor und während des Einsatzes. Hat sich beispielsweise die Anzahl der Fehler verdoppelt, dann hat sich auch der Schaden verdoppelt.
Der Canary-Knoten wird während der Bereitstellung festgelegt. Sobald die Bereitstellung abgeschlossen ist und wir den Canary-Knoten-Status entfernen, wird das Verkehrsgleichgewicht wiederhergestellt. Mit weniger Autos erreichen wir eine gerechte Verteilung.
Überwachung
Der Grundstein der Canary-Releases. Wir müssen genau verstehen, warum wir dies tun und welche Messwerte wir erfassen möchten.
Beispiele für Kennzahlen, die wir über unsere Dienste erfassen.
- Anzahl der Fehler, die in die Protokolle geschrieben werden. Dies ist ein klares Zeichen dafür, dass alles wie vorgesehen funktioniert. Insgesamt ist dies ein gutes Maß.
- Abfrageausführungszeit (Latenz). Jeder überwacht diese Kennzahl, weil jeder schnell arbeiten möchte.
- Warteschlangengröße (Durchsatz).
- Anzahl erfolgreicher Antworten pro Sekunde.
- Ausführungszeit für 95 % aller Anfragen.
- Geschäftskennzahlen: wie viel Geld ein Unternehmen über einen bestimmten Zeitraum oder über die Benutzerabwanderung verdient. Diese Metriken sind für unsere neue Version möglicherweise wichtiger als die von den Ingenieuren hinzugefügten.
Beispiele für Metriken in den gängigsten Überwachungssystemen.
Zähler. Es handelt sich um einen steigenden Wert, beispielsweise die Anzahl der Fehler. Diese Metrik lässt sich leicht interpolieren und anhand der Grafik untersuchen: Gestern gab es 2 Fehler und heute 500, was bedeutet, dass etwas schief gelaufen ist.
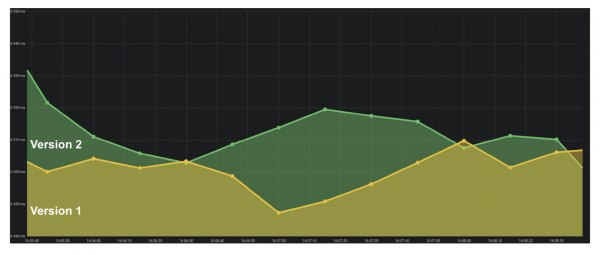
Die Anzahl der Fehler pro Minute oder pro Sekunde ist der wichtigste Indikator, der mit Counter berechnet werden kann. Diese Daten liefern ein klares Bild der Systemleistung im Laufe der Zeit. Sehen wir uns ein Beispieldiagramm der Anzahl der Fehler pro Sekunde für zwei Versionen eines Produktionssystems an.
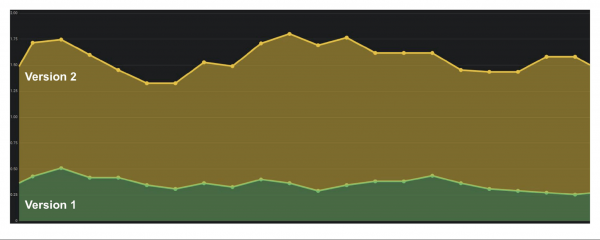
Die erste Version hatte einige Fehler, möglicherweise hat die Prüfung nicht funktioniert. In der zweiten Version ist alles viel schlimmer. Wir können definitiv sagen, dass es Probleme gibt, deshalb müssen wir diese Version zurücksetzen.
Messgerät. Metriken ähneln Zählern, aber wir zeichnen Werte auf, die entweder steigen oder fallen können. Beispielsweise Abfrageausführungszeit oder Warteschlangengröße.
Die Grafik zeigt ein Beispiel für die Reaktionszeit (Latenz). Aus der Grafik ist ersichtlich, dass die Versionen ähnlich sind und man mit ihnen arbeiten kann. Aber wenn man genau hinschaut, kann man erkennen, wie sich die Größe verändert. Wenn sich die Ausführungszeit der Abfrage beim Hinzufügen von Benutzern erhöht, ist sofort klar, dass es Probleme gibt – das ist bisher nicht passiert.
Zusammenfassung. Eine der wichtigsten Kennzahlen für Unternehmen sind Perzentile. Die Metrik zeigt, dass in 95% der Fälle unser System funktioniert so, wie wir es wollen. Wir können akzeptieren, dass es irgendwo Probleme gibt, weil wir die allgemeine Tendenz verstehen, wie gut oder schlecht alles ist.
Werkzeuge
ELK-Stapel. Sie können Canary mit Elasticsearch implementieren – wir schreiben Fehler hinein, wenn Ereignisse auftreten. Mit einem einfachen API-Aufruf können Sie jederzeit die Anzahl der Fehler abrufen und mit früheren Zeiträumen vergleichen: GET /applg/_cunt?q=level:errr.
Prometheus. Gute Leistung bei Infobip. Es ermöglicht die Implementierung mehrdimensionaler Metriken, da Beschriftungen verwendet werden.
Wir können level, instance, service, kombinieren Sie sie in einem System. Mit Hilfe von offset Sie können beispielsweise den Wert einer Menge vor einer Woche mit nur einem Befehl anzeigen GET /api/v1/query?query={query}Wo {query}:
rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)Versionsanalyse
Es gibt mehrere Strategien zur Versionsanalyse.
Zeigen Sie nur Metriken für Canary-Knoten an. Eine der einfachsten Möglichkeiten: Stellen Sie eine neue Version bereit und untersuchen Sie einfach, wie sie funktioniert. Wenn der Ingenieur jedoch zu diesem Zeitpunkt beginnt, die Protokolle zu studieren und die Seiten ständig nervös neu zu laden, unterscheidet sich diese Lösung nicht von den anderen.
Der Canary-Knoten wird mit jedem anderen Knoten verglichen. Dies ist ein Vergleich mit anderen Instanzen, die mit vollem Datenverkehr ausgeführt werden. Wenn es beispielsweise bei geringem Datenverkehr schlechter oder nicht besser läuft als bei realen Instanzen, dann stimmt etwas nicht.
Der Canary-Knoten wird mit seinem früheren Selbst verglichen. Für Canary zugewiesene Knoten können mit historischen Daten verglichen werden. Wenn beispielsweise vor einer Woche alles in Ordnung war, können wir anhand dieser Daten die aktuelle Situation verstehen.
Automatisierung
Wir möchten Ingenieure vom manuellen Vergleichen befreien, daher ist es wichtig, Automatisierung zu implementieren. Die Bereitstellungspipeline sieht normalerweise folgendermaßen aus:
- lasst uns beginnen;
- Entfernen Sie den Knoten unter dem Balancer.
- wir installieren einen Canary-Knoten;
- wir schalten den Balancer mit einer begrenzten Verkehrsmenge ein;
- vergleichen.
In dieser Phase implementieren wir automatischer Vergleich. Sehen wir uns anhand eines Beispiels von Jenkins an, wie es aussehen könnte und warum es besser ist, als nach der Bereitstellung zu prüfen.
Dies ist eine Pipeline zu Groovy.
while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Hier im Zyklus geben wir an, dass wir den neuen Knoten innerhalb einer Stunde vergleichen. Wenn der Canary-Prozess noch nicht beendet ist, rufen wir die Funktion auf. Sie sagt, ob alles gut ist oder nicht: def isOk = compare(srv, canary, time, base, offset, metrics).
Wenn alles gut ist - sleep DEFAULT SLEEP, zum Beispiel für eine Sekunde, und fahren Sie fort. Wenn nicht, beenden – Bereitstellung fehlgeschlagen.
Beschreibung der Metrik. Mal sehen, wie die Funktion aussehen könnte compare am Beispiel DSL.
metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)Nehmen wir an, wir vergleichen die Anzahl der Fehler und möchten die Anzahl der Fehler pro Sekunde in den letzten 5 Minuten wissen.
Wir haben zwei Werte: Basis- und Canary-Knoten. Der Wert des Canary-Knotens ist aktuell. Grundlegend - baseValue – dies ist der Wert jedes anderen Nicht-Canary-Knotens. Wir vergleichen die Werte miteinander anhand einer Formel, die wir aufgrund unserer Erfahrungen und Beobachtungen festlegen. Wenn der Wert canaryValue schlecht, dann ist die Bereitstellung fehlgeschlagen und wir führen ein Rollback durch.
Warum ist das alles notwendig?
Eine Person kann nicht Hunderte und Tausende von Kennzahlen überprüfen, vor allem, um es schnell zu erledigen. Der automatische Vergleich hilft Ihnen, alle Kennzahlen zu überprüfen und macht Sie schnell auf Probleme aufmerksam. Der Zeitpunkt der Benachrichtigung ist entscheidend: Wenn in den letzten 2 Sekunden etwas passiert ist, ist der Schaden nicht so groß, als wenn es vor 15 Minuten passiert wäre. Bis jemand das Problem bemerkt, dem Support schreibt und der Support das Problem beheben muss, könnten wir Kunden verlieren.
Wenn der Vorgang erfolgreich ist und alles in Ordnung ist, stellen wir alle anderen Knoten automatisch bereit. Während dieser Zeit tun die Ingenieure nichts. Erst wenn sie Canary starten, entscheiden sie, welche Messwerte sie heranziehen, wie lange der Vergleich dauern und welche Strategie sie verwenden.
Wenn Probleme auftreten, führen wir automatisch ein Rollback des Canary-Knotens durch, arbeiten an früheren Versionen und beheben die gefundenen Fehler. Anhand von Metriken lassen sie sich leicht finden und der Schaden erkennen, den die neue Version verursacht.
Hindernisse
Dies ist natürlich nicht einfach umzusetzen. Zunächst ist es notwendig Allgemeines Überwachungssystem. Ingenieure haben ihre eigenen Kennzahlen, Support und Analysten haben andere und Unternehmen haben eine dritte. Das gemeinsame System ist die gemeinsame Sprache, die Wirtschaft und Entwicklung sprechen.
Muss in der Praxis getestet werden Stabilität der Metriken. Überprüfen hilft zu verstehen, Welche Kennzahlen sind mindestens erforderlich, um die Qualität sicherzustellen?.
Wie kann ich das erreichen? Verwenden Sie den Canary-Dienst nicht zum Bereitstellungszeitpunkt. Wir fügen der alten Version einen Dienst hinzu, der jederzeit jeden dedizierten Knoten übernehmen und den Datenverkehr ohne Bereitstellung reduzieren kann. Dann vergleichen wir: Wir untersuchen die Fehler und suchen nach der Grenze, an der wir Qualität erreichen.
Wie wir von Canary Releases profitiert haben
Der Prozentsatz des durch Bugs verursachten Schadens wurde minimiert. Die meisten Bereitstellungsfehler entstehen aufgrund von Daten- oder Prioritätsinkonsistenzen. Solche Fehler treten deutlich seltener auf, da wir das Problem in den ersten Sekunden lösen können.
Optimierte die Arbeit von Teams. Neulinge haben das „Recht, Fehler zu machen“: Sie können ohne Angst vor Fehlern in die Produktion einsteigen und entwickeln zusätzliche Initiative und Arbeitsmotivation. Wenn sie etwas kaputt machen, ist das nicht schlimm und die Person, die den Fehler gemacht hat, wird nicht gefeuert.
Automatisierte Bereitstellung. Dies ist kein manueller Prozess mehr wie zuvor, sondern ein wirklich automatisierter. Aber es dauert länger.
Hervorgehobene wichtige Kennzahlen. Das gesamte Unternehmen, vom Geschäft bis zur Technik, versteht, was bei unserem Produkt wirklich wichtig ist, welche Kennzahlen beispielsweise Benutzerabwanderung und -zustrom sind. Wir kontrollieren den Prozess: Wir testen Metriken, führen neue ein und beobachten, wie alte funktionieren, um ein System aufzubauen, mit dem Sie effizienter Geld verdienen.
Wir verfügen über viele großartige Verfahren und Systeme, die uns helfen. Trotzdem streben wir danach, professionell zu sein und unsere Arbeit gut zu machen, unabhängig davon, ob wir ein System haben, das uns dabei hilft oder nicht.
Ingenieuransätze und -praktiken - . Wenn Sie auf dem Weg zur technischen Exzellenz Erfolge erzielt haben und bereit sind, uns mitzuteilen, was Ihnen dabei geholfen hat, .
Wir planen, 8. Juni. Wir verstehen, dass es schwierig ist, jetzt eine Entscheidung über die Teilnahme an der Konferenz zu treffen. Gleichzeitig glauben wir jedoch, dass die Quarantäne kein Grund ist, die berufliche Kommunikation und Entwicklung einzustellen. Daher werden wir in jedem Fall einen Weg finden, die Aufgaben des Tech Leads und Lösungsansätze zu besprechen – bei Bedarf auch online und dort die Vernetzung auszubauen!
Source: habr.com
