


Kürzlich stand ich vor einer ziemlich untypischen Aufgabe, als es darum ging, das Routing für MetalLB zu konfigurieren. Normalerweise sind für MetalLB keine besonderen Maßnahmen erforderlich, aber in unserem Fall haben wir einen recht großen Cluster mit einer relativ einfachen Netzwerk-Konfiguration.
In diesem Artikel erkläre ich, wie man source-basiertes und policy-basiertes Routing für das externe Netzwerk Ihres Clusters einrichtet.
Ich werde nicht ausführlich auf die Installation und Einrichtung von MetalLB eingehen, da ich davon ausgehe, dass Sie bereits über einige Erfahrungen verfügen. Lassen Sie uns direkt zur Sache kommen, nämlich zur Einrichtung des Routings. Wir haben also vier Fälle:
Fall 1: Wenn keine Einrichtung erforderlich ist
Lassen Sie uns einen einfachen Fall betrachten.
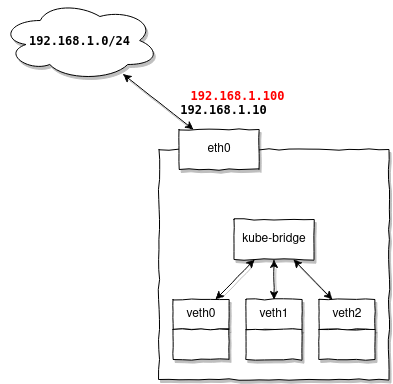
Zusätzliche Routing-Einstellungen sind nicht erforderlich, wenn die von MetalLB vergebenen Adressen im gleichen Subnetz liegen wie die Adressen Ihrer Knoten.
Nehmen wir an, Sie haben ein Subnetz 192.168.1.0/24, in dem sich ein Router befindet 192.168.1.1, und Ihre Knoten erhalten Adressen: 192.168.1.10-30, dann können Sie für MetalLB den Bereich 192.168.1.100-120 einstellen und sicher sein, dass sie ohne zusätzliche Einstellungen funktionieren.
Warum ist das so? Weil Ihre Knoten bereits konfigurierte Routen haben:
# ip route
default via 192.168.1.1 dev eth0 onlink
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.10Und Adressen aus demselben Bereich werden ohne zusätzliche Schritte wiederverwendet.
Fall 2: Wenn zusätzliche Konfiguration erforderlich ist
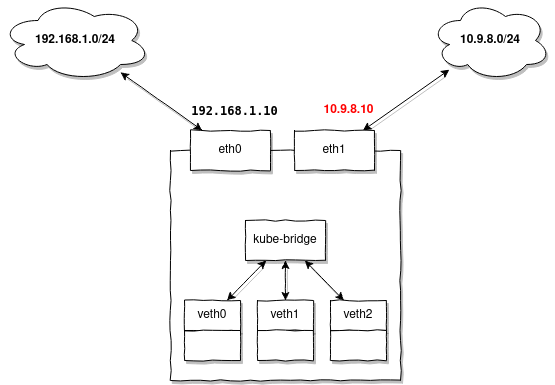
Sie sollten zusätzliche Routen konfigurieren, jedes Mal, wenn Ihre Knoten keine eingerichtet haben IP-Adressen oder eine Route im Subnetz, für das MetalLB Adressen vergibt.
Ich erkläre es etwas ausführlicher. Jedes Mal, wenn MetalLB eine Adresse vergibt, kann dies mit einer einfachen Zuweisung verglichen werden:
ip addr add 10.9.8.7/32 dev loBeachten Sie:
- a) Die Adresse wird mit einem Präfix zugewiesen,
/32das heißt, eine Route im Subnetz wird nicht automatisch hinzugefügt (es ist einfach eine Adresse). - b) Die Adresse wird an ein beliebiges Interface des Knotens (z. B. Loopback) angehängt. Hier ist es erwähnenswert, dass das Verhalten des Linux-Netzwerkstacks wichtig ist. Es spielt keine Rolle, an welchem Interface Sie die Adresse hinzufügen; der Kernel bearbeitet immer ARP-Anfragen und sendet ARP-Antworten an jedes davon. Dieses Verhalten gilt als korrekt und wird zudem recht häufig in dynamischen Umgebungen wie Kubernetes verwendet.
Dieses Verhalten kann konfiguriert werden, indem man zum Beispiel strikt ARP aktiviert:
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announceIn diesem Fall werden ARP-Antworten nur dann gesendet, wenn die Schnittstelle ausdrücklich eine bestimmte IP-Adresse enthält. Diese Einstellung ist erforderlich, wenn Sie planen, MetalLB zu verwenden und Ihr kube-proxy im IPVS-Modus läuft.
Dennoch nutzt MetalLB den Kernel nicht zur Verarbeitung von ARP-Anfragen, sondern erledigt dies selbst im User-Space, sodass diese Option keinen Einfluss auf die Funktionsweise von MetalLB hat.
Kehren wir zu unserer Aufgabe zurück. Wenn es für die ausgegebenen Adressen auf Ihren Knoten keine Route gibt, fügen Sie diese im Voraus für alle Knoten hinzu:
ip route add 10.9.8.0/24 dev eth1Fall 3: Wenn source-based Routing benötigt wird
Source-based Routing müssen Sie dann einrichten, wenn Sie Pakete über ein separates Gateway erhalten, das nicht als Standard konfiguriert ist. Entsprechend sollten auch die Antwortpakete über dieses Gateway gesendet werden.
Zum Beispiel haben Sie dasselbe Subnetz 192.168.1.0/24 das für Ihre Knoten reserviert ist, aber Sie möchten externe Adressen mithilfe von MetalLB ausgeben. Angenommen, Sie haben mehrere Adressen aus dem Subnetz 1.2.3.0/24 die sich in VLAN 100 befinden, und Sie möchten diese nutzen, um auf Kubernetes-Dienste von außen zuzugreifen.
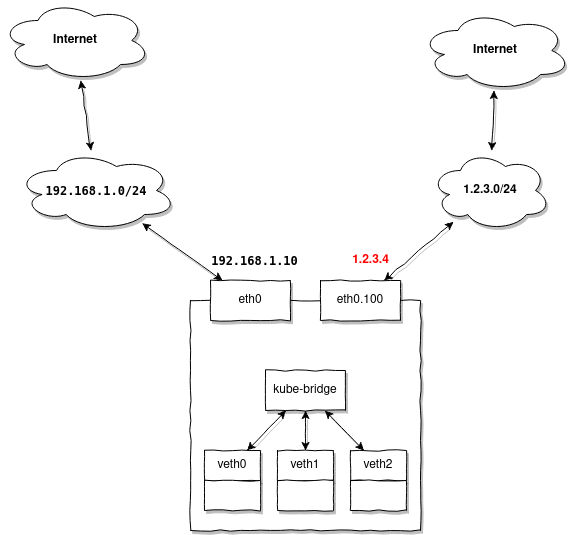
Bei Zugriff auf 1.2.3.4 werden Sie Anfragen aus einem anderen Subnetz senden als 1.2.3.0/24 und auf eine Antwort warten. Der Knoten, der derzeit der Master für die zugewiesene MetalLB-Adresse ist 1.2.3.4, erhält das Paket vom Router 1.2.3.1, aber die Antwort muss unbedingt denselben Weg gehen, über 1.2.3.1.
Da unser Knoten bereits ein konfiguriertes Standard-Gateway hat 192.168.1.1, wird die Antwort standardmäßig zu ihm geleitet, und nicht zu 1.2.3.1, über den wir das Paket erhalten haben.
Wie gehen wir mit dieser Situation um?
In diesem Fall müssen Sie alle Ihre Knoten so vorbereiten, dass sie in der Lage sind, externe Adressen ohne zusätzliche Konfiguration zu bedienen. Das heißt, für das obige Beispiel müssen Sie im Voraus ein VLAN-Interface am Knoten erstellen:
ip link add link eth0 name eth0.100 type vlan id 100
ip link set eth0.100 upUnd dann Routen hinzufügen:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Beachten Sie, dass wir die Routen in eine separate Routing-Tabelle hinzufügen 100 sie wird nur zwei Routen enthalten, die für die Versendung des Antwortpakets über das Gateway erforderlich sind 1.2.3.1, das sich hinter dem Interface befindet eth0.100.
Jetzt müssen wir eine einfache Regel hinzufügen:
ip rule add from 1.2.3.0/24 lookup 100die klar besagt: Wenn die Quelladresse des Pakets sich in 1.2.3.0/24, dann muss die Routing-Tabelle verwendet werden 100. Darin haben wir bereits die Route beschrieben, die sie über sendet. 1.2.3.1
Fall 4: Wenn policy-basiertes Routing benötigt wird.
Die Netzwerktopologie ist wie im vorherigen Beispiel, aber nehmen wir an, Sie möchten auch die Möglichkeit haben, auf externe Adressen des Pools zuzugreifen. 1.2.3.0/24 von Ihren Pods:
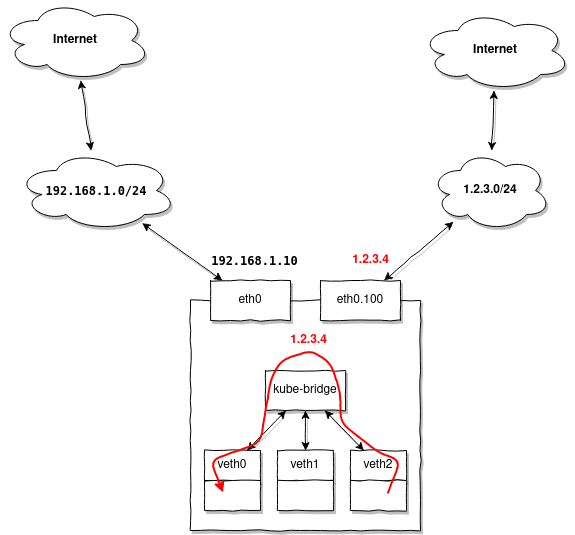
Das Besondere ist, dass beim Zugriff auf jede Adresse in 1.2.3.0/24, das Antwortpaket, das an den Knoten gelangt und die Quelladresse im Bereich hat, 1.2.3.0/24 gehorsam an gesendet wird eth0.100, aber wir möchten, dass Kubernetes es an unseren ersten Pod umleitet, der die ursprüngliche Anfrage generiert hat.
Diese Herausforderung war nicht einfach zu lösen, aber es wurde dank policy-basiertem Routing möglich:
Um den Prozess besser zu verstehen, führe ich das Blockdiagramm von netfilter an:
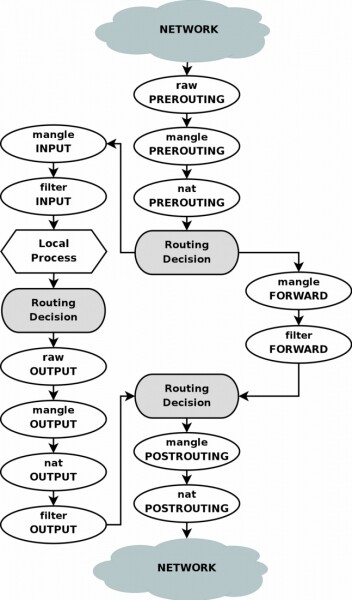
Zunächst, wie im vorherigen Beispiel, erstellen wir eine zusätzliche Routingtabelle:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Jetzt fügen wir einige Regeln in iptables hinzu:
iptables -t mangle -A PREROUTING -i eth0.100 -j CONNMARK --set-mark 0x100
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j RETURN
iptables -t mangle -A POSTROUTING -j CONNMARK --save-markDiese Regeln werden eingehende Verbindungen am Interface markieren eth0.100, wobei alle Pakete mit einem Tag versehen werden, 0x100, auch die Antworten innerhalb einer Verbindung werden mit demselben Tag markiert.
Jetzt können wir eine Routing-Regel hinzufügen:
ip rule add from 1.2.3.0/24 fwmark 0x100 lookup 100Das heißt, alle Pakete mit der Quelladresse 1.2.3.0/24 und dem Tag 0x100 sollen unter Verwendung der Tabelle geleitet werden. 100.
So fallen andere Pakete, die über eine andere Schnittstelle empfangen werden, nicht unter diese Regel, was es ihnen ermöglicht, mit den Standardmethoden von Kubernetes weitergeleitet zu werden.
Es gibt jedoch noch etwas: In Linux gibt es den sogenannten Reverse-Pfadfilter, der die gesamte Sache ruiniert, indem er eine einfache Überprüfung durchführt: Für alle eingehenden Pakete ändert er die Quelladresse des Pakets mit der Adresse des Absenders und überprüft, ob das Paket durch dasselbe Interface gesendet werden kann, über das es empfangen wurde. Wenn nicht, wird es herausgefiltert.
Das Problem ist, dass er in unserem Fall nicht korrekt funktioniert, aber wir können ihn deaktivieren:
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/eth0.100/rp_filterBitte beachten Sie, dass der erste Befehl das globale Verhalten des rp_filter steuert. Wenn er nicht deaktiviert wird, hat der zweite Befehl keine Wirkung. Dennoch bleiben die anderen Schnittstellen mit aktivem rp_filter.
Um die Filterarbeit nicht vollständig zu beschränken, können wir die Implementierung von rp_filter für Netfilter nutzen. Mit rpfilter als iptables-Modul können wir recht flexible Regeln festlegen, zum Beispiel:
iptables -t raw -A PREROUTING -i eth0.100 -d 1.2.3.0/24 -j RETURN
iptables -t raw -A PREROUTING -i eth0.100 -m rpfilter --invert -j DROPaktiviere rp_filter an der Schnittstelle eth0.100 für alle Adressen außer 1.2.3.0/24.
Quelle: habr.com
