


Allen gute Wünsche!
Ich bin Nikita, Teamleiter des Ingenieurteams bei Cian. Eine meiner Aufgaben im Unternehmen besteht darin, die Anzahl der infrastrukturellen Vorfälle in der Produktion auf null zu reduzieren.
Das Thema, das ich gleich behandeln werde, hat uns viel Schmerz bereitet. Ziel dieses Artikels ist es, anderen zu helfen, unsere Fehler zu vermeiden oder deren Auswirkungen zumindest zu minimieren.
Präambel
Vor langer Zeit, als Cian aus Monolithen bestand und es noch keine Anzeichen von Mikrodiensten gab, haben wir die Verfügbarkeit der Ressource durch die Überprüfung von 3–5 Seiten gemessen.
Wenn sie antworten — alles in Ordnung, wenn sie über längere Zeit nicht antworten — Alarm. Wie lange sie nicht funktionieren müssen, damit das als Vorfall gilt, wurde in Besprechungen entschieden. Das Ingenieurteam war stets an der Untersuchung von Vorfällen beteiligt. Wenn die Untersuchung abgeschlossen war, wurde ein Post-Mortem verfasst — ein Bericht in Form von: was passiert ist, wie lange es gedauert hat, was im Moment unternommen wurde und was wir in Zukunft tun werden.
Die Hauptseiten der Website oder wie wir erkennen, dass wir den Tiefpunkt erreicht haben
Um die Fehlerpriorität besser zu verstehen, haben wir die kritischsten Seiten für die Geschäftsabläufe der Website hervorgehoben. Anhand dieser Seiten zählen wir die Anzahl der erfolgreichen und nicht erfolgreichen Anfragen sowie Zeitüberschreitungen. So messen wir die Verfügbarkeit.
Angenommen, wir haben einige extrem wichtige Bereiche der Website identifiziert, die für den Hauptservice - die Suche und Veröffentlichung von Anzeigen - verantwortlich sind. Wenn die Anzahl der fehlerhaften Anfragen 1 % übersteigt, handelt es sich um einen kritischen Vorfall. Übersteigt der Fehlerprozentsatz während der Hauptsendezeit von 0,1 % in einem Zeitraum von 15 Minuten, wird auch dies als kritischer Vorfall betrachtet. Diese Kriterien decken den Großteil der Vorfälle ab, während andere außerhalb dieses Artikels liegen.
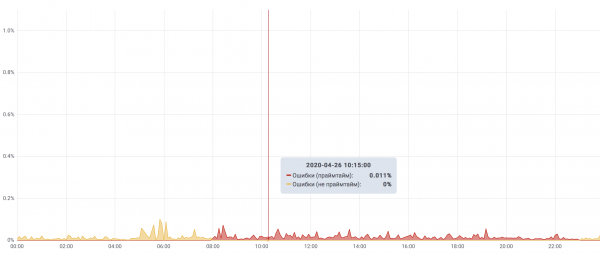
Die besten Vorfälle bei Cian
Wir haben also eindeutig gelernt, dass ein Vorfall aufgetreten ist.
Jetzt ist jeder Vorfall detailliert beschrieben und in einem Jira-Epic dokumentiert. Übrigens haben wir dafür ein separates Projekt gegründet, das wir FAIL genannt haben – dort können nur Epics erstellt werden.
Wenn man alle Fehlschläge der letzten Jahre zusammenfasst, sind die häufigsten:
- Vorfälle im Zusammenhang mit mssql;
- Vorfälle, die durch externe Faktoren verursacht wurden;
- Fehler des Administrators.
Lassen Sie uns genauer auf die Fehler von Administratoren eingehen, sowie auf einige andere interessante Fehltritte.
Platz fünf – „Ordnung im DNS schaffen“
Es war ein trüber Dienstag. Wir beschlossen, Ordnung in unser DNS-Cluster zu bringen.
Wir wollten die internen DNS-Server von BIND auf PowerDNS umstellen und dafür vollkommen separate Server einrichten, auf denen nichts außer DNS läuft.
Wir haben in jeder Location unserer Rechenzentren einen DNS-Server platziert, und es kam der Moment, die Zonen von BIND auf PowerDNS zu migrieren und die Infrastruktur auf die neuen Server umzuschalten.
Mitten im Umzug blieb von all den ServerServern, die in den lokalen Caches der BIND-Server angegeben waren, nur einer übrig, der im Rechenzentrum in St. Petersburg war. Dieses Rechenzentrum wurde ursprünglich als nicht kritisch für uns deklariert, wurde aber plötzlich zum Single Point of Failure.
Gerade in dieser Phase des Umzugs fiel die Verbindung zwischen Moskau und St. Petersburg aus. Wir hatten faktisch fünf Minuten lang keinen DNS und kamen erst wieder online, als der Hoster die Probleme behoben wurden.
Fazit:
Früher haben wir externe Faktoren bei der Vorbereitung auf Arbeiten vernachlässigt, aber jetzt gehören sie ebenfalls zu den Aspekten, auf die wir uns vorbereiten. Wir streben nun an, dass alle Komponenten nach dem n-2 Prinzip reserviert sind, und während der Arbeiten können wir dieses Niveau auf n-1 absenken.
- Beim Erstellen des Aktionsplans sollten Sie Punkte markieren, an denen der Service ausfallen kann, und ein Szenario durchdenken, bei dem alles "schlimmer als gedacht" läuft, um vorbereitet zu sein.
- Verteilen Sie die internen DNS-Server auf verschiedene geografische Standorte/Rechenzentren/Racks/Switches/Eingänge.
- Auf jedem Server installieren Sie einen lokalen caching DNS-Server, der Anfragen an die Haupt-DNS-Server weiterleitet und im Falle seiner Nichterreichbarkeit aus dem Cache antwortet.
Platz vier – „Ordnung in Nginx schaffen“
Eines Tages beschloss unser Team, dass es „das reicht“, und der Prozess zur Umstrukturierung der nginx-Konfigurationen begann. Das Hauptziel war es, die Konfigurationen in eine intuitive Struktur zu bringen. Früher war alles „historisch bedingt“ und machte wenig Sinn. Jetzt haben wir jeden server_name in eine gleichnamige Datei ausgelagert und alle Konfigurationen in verschiedene Ordner verteilt. Übrigens enthält die Konfiguration 253.949 Zeilen oder 7.836.520 Zeichen und belegt fast 7 Megabyte. Die oberste Ebene der Struktur:
Nginx-Struktur
├── access
│ ├── allow.list
...
│ └── whitelist.conf
├── geobase
│ ├── exclude.conf
...
│ └── geo_ip_to_region_id.conf
├── geodb
│ ├── GeoIP.dat
│ ├── GeoIP2-Country.mmdb
│ └── GeoLiteCity.dat
├── inc
│ ├── error.inc
...
│ └── proxy.inc
├── lists.d
│ ├── bot.conf
...
│ ├── dynamic
│ └── geo.conf
├── lua
│ ├── cookie.lua
│ ├── log
│ │ └── log.lua
│ ├── logics
│ │ ├── include.lua
│ │ ├── ...
│ │ └── utils.lua
│ └── prom
│ ├── stats.lua
│ └── stats_prometheus.lua
├── map.d
│ ├── access.conf
│ ├── ..
│ └── zones.conf
├── nginx.conf
├── robots.txt
├── server.d
│ ├── cian.ru
│ │ ├── cian.ru.conf
│ │ ├── ...
│ │ └── my.cian.ru.conf
├── service.d
│ ├── ...
│ └── status.conf
└── upstream.d
├── cian-mcs.conf
├── ...
└── wafserver.confEs ist deutlich besser geworden, allerdings hatten beim Umbenennen und der Verteilung der Konfigurationen einige von ihnen die falsche Erweiterung und wurden nicht in die Direktive include *.conf aufgenommen. Infolgedessen waren einige Hosts nicht erreichbar und gaben einen 301-Redirect zur Hauptseite zurück. Da der Antwortcode nicht 5xx/4xx war, fiel dies nicht sofort auf, sondern erst am Morgen. Daraufhin begannen wir mit dem Schreiben von Tests zur Überprüfung der Infrastrukturkomponenten.
Fazit:
- Strukturieren Sie Ihre Konfigurationen (nicht nur nginx) sorgfältig und planen Sie die Struktur bereits in der frühen Projektphase. So machen Sie es Ihrem Team verständlicher, was wiederum die Time-to-Market verkürzt.
- Für einige Infrastrukturkomponenten schreiben Sie Tests. Zum Beispiel: Überprüfen Sie, ob alle wichtigen server_name den richtigen Status zurückgeben und die Antwort richtig ist. Es genügt, ein paar Skripte zur Verfügung zu haben, die die grundlegenden Funktionen der Komponente überprüfen, damit Sie nicht um 3 Uhr nachts in Panik geraten müssen, was Sie noch überprüfen müssen.
Der dritte Platz - "Plötzlich war der Speicher in Cassandra voll"
Die Daten wuchsen stetig, und alles war gut, bis die Reparaturen großer Keyspaces im Cassandra-Cluster fehlschlugen, weil die Kompaktierung nicht durchgeführt werden konnte.
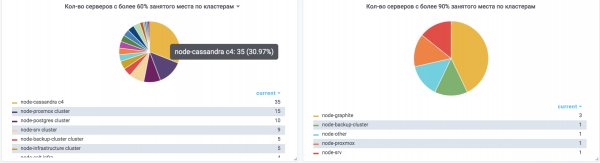
An einem nebligen Tag verwandelte sich der Cluster fast in einen Kürbis, und zwar:
- es waren noch etwa 20% des Gesamtspeichers im Cluster verfügbar;
- Es ist nicht möglich, Nodes hinzuzufügen, da der Cleanup nach der Hinzufügung eines Nodes aufgrund von Speichermangel auf den Partitionen nicht erfolgt;
- Die Leistung sinkt allmählich, da die Kompaktierung nicht funktioniert;
- der Cluster arbeitet im Notfallmodus.
Ausgang — wir haben 5 weitere Nodes ohne Bereinigung hinzugefügt, anschließend begannen wir, systematisch Nodes aus dem Cluster zu entfernen und wieder als leere Nodes einzuführen, auf denen kein Platz mehr war. Die dafür benötigte Zeit war erheblich höher, als wir uns gewünscht hätten. Es bestand das Risiko einer teilweisen oder vollständigen Unzugänglichkeit des Clusters.
Fazit:
- Auf allen Cassandra-Servern sollte nicht mehr als 60 % des Speicherplatzes in jedem Abschnitt belegt sein.
- Sie sollten nicht mehr als zu 50 % ausgelastet sein, was die CPU betrifft.
- Man sollte das Capacity Planning nicht vernachlässigen und dieses für jede Komponente, basierend auf ihren spezifischen Anforderungen, gründlich durchdenken.
- Je mehr Nodes im Cluster enthalten sind, desto besser. Server, die nur einen geringen Datensatz enthalten, lassen sich schneller neu starten, und ein solcher Cluster ist leichter wiederherzustellen.
Der zweite Punkt — «Daten aus dem Consul Key-Value-Speicher sind verschwunden»
Für die Service-Discovery verwenden wir, wie viele andere, Consul. Allerdings nutzen wir es auch für die Blue-Green-Bereitstellung unseres Monolithen. Dort wird die Information über aktive und inaktive Upstreams gespeichert, die während des Deployments wechseln. Zu diesem Zweck wurde ein Deployment-Service entwickelt, der mit KV interagiert. Irgendwann gingen die Daten aus dem KV verloren. Wir haben sie aus dem Gedächtnis wiederhergestellt, jedoch mit einigen Fehlern. Infolgedessen wurde die Last auf die Upstreams ungleichmäßig verteilt, und wir erhielten viele 502-Fehler aufgrund von CPU-Überlastung der Backends. Letztendlich sind wir von Consul KV auf Postgres umgestiegen, von wo aus es nicht so einfach ist, sie zu entfernen.
Fazit:
- Dienste ohne jegliche Autorisierung sollten keine kritischen Daten für den Betrieb der Website enthalten. Wenn Sie beispielsweise keine Autorisierung in ES haben, wäre es besser, den Zugriff auf Netzwerkebene überall dort zu sperren, wo er nicht benötigt wird, nur notwendige Zugriffe zuzulassen und außerdem action.destructive_requires_name: true zu setzen.
- Testen Sie den Backup- und Wiederherstellungsmechanismus im Voraus. Erstellen Sie beispielsweise im Voraus ein Skript (zum Beispiel in Python), das sowohl Backups erstellen als auch wiederherstellen kann.
Der erste Platz geht an 'Captain Offensichtlichkeit'.
Wir haben zu einem bestimmten Zeitpunkt eine ungleichmäßige Lastverteilung auf die Upstreams von Nginx festgestellt, wenn im Backend mehr als 10 Server aktiv waren. Da das Round-Robin-Verfahren die Anfragen nacheinander an die Upstreams weiterleitete und jeder Nginx-Reload von vorne begann, erhielten die ersten Upstreams immer mehr Anfragen als die anderen. Infolgedessen arbeiteten sie langsamer und die gesamte Website litt darunter. Dies wurde mit steigendem Traffic immer deutlicher. Ein einfaches Update von Nginx auf random brachte nichts – wir mussten eine Menge Lua-Code überarbeiten, der bei Version 1.15 nicht funktionierte (zu diesem Zeitpunkt). Also haben wir unsere Nginx-Version 1.14.2 gepatcht und die Unterstützung für random integriert. Damit war das Problem gelöst. Dieser Bug gewinnt den Preis für „Captain Offensichtlich“.
Fazit:
Es war sehr faszinierend und interessant, diesen Bug zu untersuchen).
- Richten Sie das Monitoring so ein, dass es Ihnen hilft, solche Fluktuationen schnell zu erkennen. Zum Beispiel kann man ELK nutzen, um die RPS (Requests per Second) für jedes Backend jedes Upstreams zu überwachen und die Antwortzeiten aus der Perspektive von Nginx zu verfolgen. In diesem Fall hat uns das geholfen, das Problem zu identifizieren.
Die Mehrheit der Fehler lässt sich durch einen sorgfältigeren Ansatz vermeiden, wenn man bei der Arbeit aufmerksam bleibt. Man sollte immer an das Murphy-Gesetz denken: Alles, was schiefgehen kann, wird schiefgehen, und Komponenten sollten entsprechend gestaltet werden.
Quelle: habr.com
