


Für ein umfassendes Verständnis von Kubernetes ist es wichtig, verschiedene Methoden zur Skalierung von Clusterressourcen zu kennen: Laut den Entwicklern des Systems , это одна из главных задач Kubernetes. Мы подготовили высокоуровневый обзор механизмов горизонтального и вертикального автомасштабирования и изменения размера кластеров, а также рекомендации, как их эффективно использовать.
Der Artikel wurde von dem Team übersetzt, das das automatische Skalieren in .
Warum es wichtig ist, über Skalierung nachzudenken
— ein Werkzeug zur Verwaltung von Ressourcen und Orchestrierung. Natürlich ist es nicht schlecht, sich mit den tollen Funktionen von Deployment, Monitoring und Pod-Management (das Modul Pod ist eine Gruppe von Containern, die als Antwort auf Anfragen gestartet werden) zu beschäftigen.
Es ist jedoch auch wichtig, über folgende Fragen nachzudenken:
- Wie skalieren Sie Module und Anwendungen?
- Wie halten Sie Container in einem funktionalen und effizienten Zustand?
- Wie reagieren Sie auf ständige Änderungen im Code und auf Benutzerlasten?
Die Konfiguration von Kubernetes-Clustern zur Ressourcenauslastung und Leistungsoptimierung kann eine komplexe Aufgabe sein und erfordert Fachwissen über die inneren Abläufe von Kubernetes. Die Auslastung Ihrer Anwendung oder Dienste kann im Laufe des Tages oder sogar innerhalb einer Stunde schwanken, weshalb das Lastenausgleich als ein kontinuierlicher Prozess betrachtet werden sollte.
Kubernetes-Automatisierungsebenen
Effektive Automatisierung erfordert eine Koordination zwischen zwei Ebenen:
- Die Pod-Ebene, die horizontale (Horizontal Pod Autoscaler, HPA) und vertikale Automatisierung (Vertical Pod Autoscaler, VPA) umfasst. Diese Automatisierung skaliert die vorhandenen Ressourcen für Ihre Container.
- Die Cluster-Ebene, die durch das Cluster-Autoscaling-System (Cluster Autoscaler, CA) verwaltet wird, erhöht oder verringert die Anzahl der Knoten innerhalb des Clusters.
Modul zur horizontalen Automatisierung (HPA)
Wie der Name schon sagt, skaliert HPA die Anzahl der Pod-Replikate. Als Auslöser für die Änderung der Anzahl der Replikate verwenden die meisten DevOps die CPU- und Speicherauslastung. Es ist jedoch auch möglich, die Systeme basierend auf , deren oder sogar .
Hochlevel-Schema des HPA-Betriebs:
- HPA überwacht kontinuierlich die bei der Installation angegebenen Metriken in einem Standardintervall von 30 Sekunden.
- HPA versucht die Anzahl der Pods zu erhöhen, wenn der festgelegte Schwellenwert erreicht wird.
- HPA aktualisiert die Anzahl der Replikate innerhalb des Bereitstellungs-/Replikationscontrollers.
- Der Bereitstellungs-/Replikationscontroller implementiert dann alle erforderlichen zusätzlichen Pods.
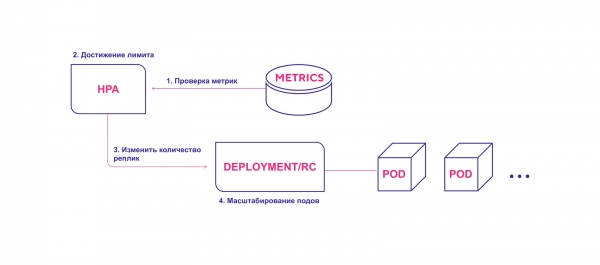
HPA initiiert den Bereitstellungsprozess der Pods, wenn der Schwellenwert der Metriken erreicht ist.
Bitte beachten Sie Folgendes bei der Verwendung von HPA:
- Das Standard-Überwachungsintervall des HPA beträgt 30 Sekunden. Es wird mit dem Flag horizontal-pod-autoscaler-sync-period im Controller-Manager festgelegt.
- Die Standard-Toleranz beträgt 10%.
- Nach der letzten Erhöhung der Anzahl der Pods wartet HPA drei Minuten auf die Stabilisierung der Metriken. Dieses Intervall wird mit dem Flag horizontal-pod-autoscaler-upscale-delay.
- Nach der letzten Verringerung der Anzahl der Pods wartet HPA fünf Minuten auf die Stabilisierung. Dieses Intervall wird mit dem Flag horizontal-pod-autoscaler-downscale-delay.
- HPA funktioniert am besten mit Deployments anstelle von Replikationscontrollern. Horizontale Automatisierung ist nicht mit dem Rolling Update kompatibel, das direkt Replikationscontroller manipuliert. Bei der Bereitstellung hängt die Anzahl der Replikate direkt von den Deployments ab.
Vertikale Automatisierung von Pods
Vertikale Automatisierung (VPA) weist bestehenden Pods mehr (oder weniger) CPU- oder Speicherkapazität zu. Sie eignet sich sowohl für zustandsbehaftete (stateful) als auch für zustandslose (stateless) Pods, ist jedoch hauptsächlich für stateful-Dienste konzipiert. Allerdings können Sie VPA auch für zustandslose Module anwenden, wenn Sie automatisch die anfänglich zugewiesenen Ressourcen anpassen möchten.
VPA reagiert zudem auf OOM-Ereignisse (out of memory, nicht genügend Speicher). Um Prozessoreinheiten und Speichervolumen zu ändern, ist ein Neustart der Pods erforderlich. Bei einem Neustart hält VPA das Verteilungskapital ein (), um die minimal erforderliche Anzahl von Modulen zu gewährleisten.
Sie können den minimalen und maximalen Ressourcenbedarf für jedes Modul festlegen. So können Sie den maximalen zugewiesenen Speicher auf 8 GB begrenzen. Dies ist nützlich, wenn die aktuellen Knoten nicht mehr als 8 GB Speicher für den Container bereitstellen können. Detaillierte Spezifikationen und Funktionsweise sind beschrieben in .
Darüber hinaus bietet VPA eine interessante Empfehlungsfunktion (VPA Recommender). Diese verfolgt die Ressourcennutzung und OOM-Ereignisse aller Module, um neue Werte für Speicher und CPU-Zeit basierend auf einem intelligenten Algorithmus unter Berücksichtigung historischer Metriken vorzuschlagen. Es gibt auch eine API, die einen Pod-Descriptor akzeptiert und empfohlene Ressourcenwerte zurückgibt.
Es ist erwähnenswert, dass der VPA Recommender die "Limits" der Ressourcen nicht überwacht. Dies kann dazu führen, dass ein Modul die Ressourcen innerhalb der Knoten monopolisiert. Es ist besser, ein Grenzwert auf Namespace-Ebene festzulegen, um einen übermäßigen Speicher- oder CPU-Verbrauch zu vermeiden.
hochlevelige Funktionsweise von VPA:
- VPA überprüft kontinuierlich die bei der Installation angegebenen Metrikwerte in einem Standardintervall von 10 Sekunden.
- Wenn die festgelegte Schwelle erreicht ist, versucht der VPA, die zugewiesene Menge an Ressourcen zu ändern.
- Der VPA aktualisiert die Ressourcenzahl innerhalb des Deployment-Replication-Controllers.
- Beim Neustart der Module werden alle neuen Ressourcen auf die erstellten Instanzen angewendet.
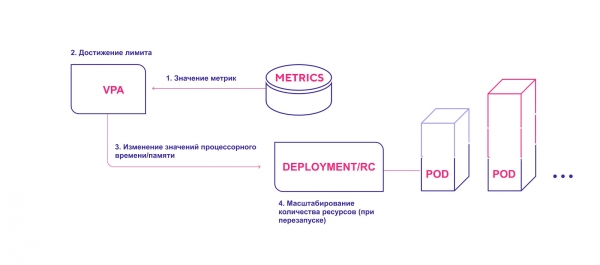
Der VPA fügt die erforderliche Menge an Ressourcen hinzu.
Bitte beachten Sie die folgenden Punkte bei der Verwendung des VPA:
- Das Skalieren erfordert einen zwingenden Neustart des Pods. Dies ist notwendig, um eine instabile Leistung nach den Änderungen zu vermeiden. Zur Zuverlässigkeit werden die Module neu gestartet und basierend auf den neu zugewiesenen Ressourcen auf die Knoten verteilt.
- Der VPA und der HPA sind derzeit nicht miteinander kompatibel und können nicht auf denselben Pods arbeiten. Wenn Sie in einem Cluster beide Skalierungsmechanismen anwenden, stellen Sie sicher, dass die Einstellungen nicht zulassen, dass sie auf denselben Objekten aktiviert werden.
- Der VPA passt Containeranfragen an Ressourcen basierend auf der vergangenen und aktuellen Nutzung an. Es werden keine Nutzungslimits für Ressourcen festgelegt. Es können Probleme mit der ordnungsgemäßen Funktion von Anwendungen auftreten, die beginnen, immer mehr Ressourcen zu beanspruchen, was dazu führt, dass Kubernetes diesen Pod deaktiviert.
- Der VPA befindet sich derzeit in einer frühen Entwicklungsphase. Seien Sie darauf vorbereitet, dass das System in naher Zukunft einige Änderungen erfahren könnte. Sie können mehr über die und . So ist geplant, die Zusammenarbeit von VPA und HPA sowie die Bereitstellung von Modulen zusammen mit einer vertikalen Skalierungspolitik für diese (z. B. mit einem speziellen Label ‘requires VPA’) zu implementieren.
Automatisches Skalieren des Kubernetes-Clusters
Das Clusterausgleichsmodul (Cluster Autoscaler, CA) passt die Anzahl der Knoten basierend auf der Anzahl der wartenden Pods an. Das System überprüft regelmäßig, ob Pods warten, und vergrößert den Cluster, wenn zusätzliche Ressourcen benötigt werden und die vordefinierten Grenzen nicht überschritten werden. CA kommuniziert mit dem Cloud-Anbieter, um zusätzliche Knoten anzufordern oder inaktive freizugeben. Die erste öffentliche Version von CA wurde in Kubernetes 1.8 vorgestellt.
Hochrangiges Schema der Funktionsweise von CA:
- CA überprüft alle 10 Sekunden standardmäßig die Anzahl wartender Pods.
- Wenn einer oder mehrere Pods aufgrund unzureichender Ressourcen im Cluster warten, versucht es, einen oder mehrere zusätzliche Knoten bereitzustellen.
- Sobald der Cloud-Anbieter den erforderlichen Knoten bereitstellt, wird dieser dem Cluster hinzugefügt und ist bereit, Pods zu bedienen.
- Der Kubernetes-Planer verteilt die wartenden Pods auf einen neuen Knoten. Wenn danach einige Pods weiterhin im Wartestatus bleiben, wird der Prozess wiederholt – und es werden neue Knoten zum Cluster hinzugefügt.
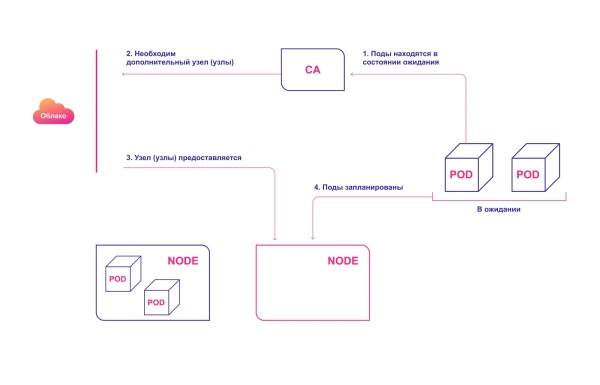
Automatische Zuweisung von Clusterknoten in der Cloud
Beachten Sie Folgendes bei der Verwendung von CA:
- CA gewährleistet, dass alle Pods im Cluster Platz zum Ausführen haben, unabhängig von der CPU-Auslastung. Außerdem versucht er sicherzustellen, dass es im Cluster keine unnötigen Knoten gibt.
- CA registriert die Notwendigkeit zur Skalierung nach etwa 30 Sekunden.
- Nachdem ein Knoten überflüssig wird, wartet CA standardmäßig 10 Minuten, bevor es das System skaliert.
- Im automatischen Skalierungssystem gibt es das Konzept der Expanders. Dies sind verschiedene Strategien zur Auswahl einer Gruppe von Knoten, zu der neue hinzugefügt werden.
- Verwenden Sie die Option verantwortungsbewusst cluster-autoscaler.kubernetes.io/safe-to-evict (true). Wenn Sie viele Pods erstellen oder wenn viele von ihnen über mehrere Knoten verteilt sind, verlieren Sie weitgehend die Möglichkeit, das Cluster zu verkleinern.
- Nutzen Sie , um das Löschen von Pods zu verhindern, was dazu führen kann, dass Teile Ihrer Anwendung vollständig ausfallen.
Wie automatisches Skalieren in Kubernetes-Systemen miteinander interagiert
Für eine optimale Harmonie sollte sowohl auf Pod-Ebene (HPA/VPA) als auch auf Cluster-Ebene automatisches Skalieren angewendet werden. Sie interagieren relativ einfach miteinander:
- HPA oder VPA aktualisieren die Replikate der Pods oder die Ressourcen, die für bestehende Pods zugewiesen sind.
- Wenn nicht genügend Knoten für die geplante Skalierung vorhanden sind, erkennt CA Pods im Wartestatus.
- CA weist neue Knoten zu.
- Die Pods werden auf die neuen Knoten verteilt.
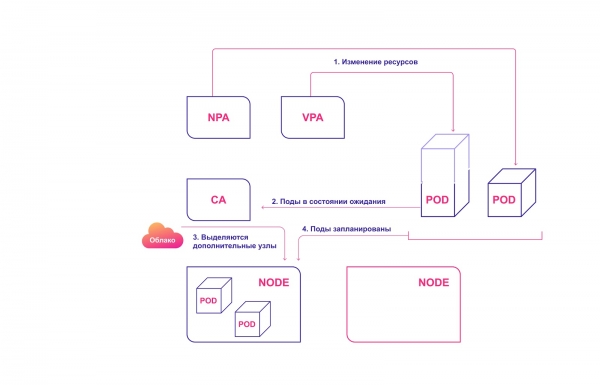
Zusammenarbeitende Skalierungssysteme in Kubernetes
Typische Fehler beim automatischen Skalieren in Kubernetes
Es gibt mehrere typische Probleme, mit denen DevOps-Teams konfrontiert sind, wenn sie versuchen, automatisches Skalieren anzuwenden.
HPA und VPA sind von Metriken und bestimmten historischen Daten abhängig. Wenn nicht genügend Ressourcen zugewiesen sind, werden die Pods heruntergefahren und können keine Metriken generieren. In diesem Fall wird das automatische Skalieren niemals stattfinden.
Der gesamte Skalierungsprozess ist zeitkritisch. Wir möchten, dass die Module und Cluster sich schnell skalieren, bevor die Nutzer irgendwelche Probleme oder Ausfälle bemerken. Daher sollte die durchschnittliche Skalierungszeit der Pods und des Clusters berücksichtigt werden.
Ideales Szenario – 4 Minuten:
- 30 Sekunden. Aktualisierung der Zielmetriken: 30–60 Sekunden.
- 30 Sekunden. HPA überprüft die Metrikwerte: 30 Sekunden.
- Weniger als 2 Sekunden. Pods werden erstellt und gehen in den Wartemodus: 1 Sekunde.
- Weniger als 2 Sekunden. CA sieht die wartenden Pods und sendet Aufrufe zur Bereitstellung der Nodes: 1 Sekunde.
- 3 Minuten. Der Cloud-Anbieter weist Knoten zu. K8s wartet, bis sie bereit sind: bis zu 10 Minuten (abhängig von mehreren Faktoren).
Schlechtestes (realistischeres) Szenario – 12 Minuten:
- 30 Sekunden. Aktualisierung der Zielmetriken.
- 30 Sekunden. HPA überprüft die Metrikwerte.
- Weniger als 2 Sekunden. Pods werden erstellt und gehen in den Wartemodus.
- Weniger als 2 Sekunden. CA sieht die wartenden Pods und sendet Aufrufe zur Bereitstellung der Nodes.
- 10 Minuten. Der Cloud-Anbieter stellt Knoten bereit. K8s wartet, bis sie einsatzbereit sind. Die Wartezeit hängt von verschiedenen Faktoren ab, wie der Verzögerung des Anbieters, der Verzögerung des Betriebssystems und der Funktionsweise der unterstützenden Tools.
Verwechseln Sie die Skalierungsmechanismen der Cloud-Anbieter nicht mit unserem CA. Letzteres funktioniert innerhalb des Kubernetes-Clusters, während der Mechanismus des Cloud-Anbieters auf der Verteilung von Knoten basiert. Er weiß nicht, was mit Ihren Pods oder Anwendungen passiert. Diese Systeme arbeiten parallel.
Wie man das Scaling in Kubernetes steuert
- Kubernetes ist ein Tool zur Ressourcenverwaltung und Orchestrierung. Die Verwaltung der Pods und Ressourcen im Cluster ist ein entscheidender Schritt im Verständnis von Kubernetes.
- Verstehen Sie die Logik der Skalierbarkeit von Pods unter Berücksichtigung von HPA und VPA.
- CA sollte nur verwendet werden, wenn Sie die Anforderungen Ihrer Pods und Container gut verstehen.
- Um den Cluster optimal zu konfigurieren, müssen Sie verstehen, wie verschiedene Skalierungssysteme zusammenarbeiten.
- Berücksichtigen Sie beim Bewerten der Skalierungszeit die worst-case- und best-case-Szenarien.
Quelle: habr.com
