

Heutzutage stellt sich wahrscheinlich niemand mehr die Frage, warum es wichtig ist, Service-Metriken zu sammeln. Der nächste logische Schritt ist die Einrichtung von Alarmierungen für die gesammelten Metriken, die über jede Datenabweichung in Ihren bevorzugten Kanälen (E-Mail, Slack, Telegram) informieren. Alle Metriken unserer Services fließen in InfluxDB und werden in Grafana angezeigt, wo auch eine grundlegende Alarmierung konfiguriert ist. Für Aufgaben wie ‚etwas berechnen und mit einem Wert vergleichen‘ nutzen wir Kapacitor.

Kapacitor ist Teil des TICK-Stacks und kann Metriken aus InfluxDB verarbeiten. Er kann mehrere Messungen miteinander verbinden (join), aus den gewonnenen Daten nützliche Informationen berechnen, die Ergebnisse wieder in InfluxDB speichern und Alarme an Slack/Twitter/E-Mail senden.
Der gesamte Stack bietet eine robuste und detaillierte , aber es gibt immer nützliche Dinge, die nicht explizit in den Handbüchern erwähnt werden. In diesem Artikel habe ich beschlossen, eine Reihe solcher nützlicher, aber unauffälliger Tipps zusammenzustellen (die grundlegende Syntax von TICKscript ist beschrieben ) und zu zeigen, wie man sie am Beispiel einer unserer Aufgaben anwenden kann.
Los geht's!
float & int, Berechnungsfehler
Ein absolut gängiges Problem, das durch Casting gelöst wird.
var alert_float = 5.0
var alert_int = 10
data|eval(lambda: float("value") > alert_float OR float("value") < float("alert_int"))
Verwendung von default()
Wenn das Tag/Feld nicht ausgefüllt ist, treten Berechnungsfehler auf:
|default()
.tag('status', 'empty')
.field('value', 0)
fill in join (inner vs outer)
Standardmäßig wird join Punkte, an denen keine Daten vorhanden sind, verwerfen (inner).
Bei fill('null') wird ein outer join durchgeführt, nach dem default() ausgeführt werden muss, um die leeren Werte zu füllen:
var data = res1
|join(res2)
.as('res1', 'res2)
.fill('null')
|default()
.field('res1.value', 0.0)
.field('res2.value', 100.0)
Hier gibt es jedoch einen Nuance. Wenn in dem obigen Beispiel eine der Serien (res1 oder res2) leer ist, wird die endgültige Serie (data) ebenfalls leer sein. Dazu gibt es mehrere Tickets auf GitHub (, , ) – wir warten auf Fixes und leiden ein wenig.
Verwendung von Bedingungen in Berechnungen (if in lambda)
|eval(lambda: if("value" > 0, true, false)
Die letzten fünf Minuten aus der Pipeline für den Zeitraum
Beispielsweise müssen Sie die Werte der letzten fünf Minuten mit der Vorwoche vergleichen. Sie können zwei Datenmengen in zwei separaten Batches nehmen oder einen Teil der Daten aus einem größeren Zeitraum abrufen:
|where(lambda: duration((unixNano(now()) - unixNano("time")) / 1000, 1u) < 5m)
Eine Alternative in den letzten fünf Minuten könnte die Verwendung des BarrierNode sein, der die Daten früher als angegeben abschneidet:
|barrier()
.period(5m)
Beispiele für die Verwendung von Go-Vorlagen in Nachrichten
Die Vorlagen entsprechen dem Format aus dem Paket , hier sind einige häufige Aufgaben.
if-else
Wir halten Ordnung, ohne die Leute unnötig mit Text zu triggern:
|alert()
...
.message(
'{{ if eq .Level "OK" }}Es ist jetzt in Ordnung{{ else }}Chef, alles ist kaputt{{end}}'
)
Zwei Dezimalstellen in der Nachricht
Wir verbessern die Lesbarkeit der Nachricht:
|alert()
...
.message(
'Der aktuelle Wert ist {{ index .Fields "value" | printf "%0.2f" }}'
)
Variablen in der Nachricht entpacken
Wir geben in der Nachricht mehr Informationen aus, um die Frage "Warum schreit es?" zu beantworten.
var warnAlert = 10
|alert()
...
.message(
'Heute ist der Wert weniger als ' + string(warnAlert) + '%'
)
Eindeutige Alarm-ID
Wichtig, wenn es in den Daten mehr als eine Gruppe gibt, da sonst nur ein Alarm generiert werden würde:
|alert()
...
.id('{{ index .Tags "myname" }}/{{ index .Tags "myfield" }}')
Kundenspezifische Handler
In einer langen Liste von Handlern gibt es exec, das es ermöglicht, Ihr Skript mit übergebenen Parametern (stdin) auszuführen – Kreativität pur!
Einer unserer Anpassungen ist ein kleines Python-Skript zur Versendung von Benachrichtigungen an Slack.
Zuerst wollten wir ein Bild aus Grafana, das durch Authentifizierung geschützt ist, in die Nachricht einfügen. Danach war der Wunsch, OK in den Thread des vorherigen Alerts aus derselben Gruppe zu schreiben, anstatt eine separate Nachricht zu senden. Etwas später sollte die häufigste Fehlermeldung der letzten X Minuten in die Nachricht aufgenommen werden.
Ein weiteres Thema ist die Verbindung zu anderen Diensten und alle durch den Alarm initiierten Aktionen (nur wenn Ihr Monitoring ausreichend gut funktioniert).
Ein Beispiel für die Beschreibung des Handlers, wobei slack_handler.py unser eigenes Skript ist:
topic: slack_graph
id: slack_graph.alert
match: level() != INFO AND changed() == TRUE
kind: exec
options:
prog: /sbin/slack_handler.py
args: ["-c", "CHANNELID", "--graph", "--search"]
Wie debuggt man?
Variante mit Log-Ausgabe
|log()
.level("error")
.prefix("something")
Ansehen (cli): kapacitor -url :9092 logs lvl=error
Variante mit httpOut
Zeigt Daten im aktuellen Pipeline an:
|httpOut('something')
Ansehen (get): :9092/kapacitor/v1/tasks/task_name/something
Ausführungs-Schema
- Jede Aufgabe gibt einen Ausführungsbaum mit nützlichen Zahlen im Format zurück .
- Wir nehmen den Block .
- Fügen wir in den Viewer ein, .
Wo man noch mit den Händen
Timestamp in InfluxDB bei der Rückschreibung erhält
Zum Beispiel richten wir einen Alarm für die Anzahl der Anfragen pro Stunde (groupBy(1h)) ein und möchten den aufgetretenen Alarm in influxdb aufzeichnen (um das Vorhandensein eines Problems schön grafisch in Grafana darzustellen).
influxDBOut() wird den Zeitstempelwert time aus dem Alarm aufzeichnen, entsprechend wird der Punkt auf dem Diagramm früher/später aufgezeichnet als der eingegangene Alarm.
Wenn Genauigkeit erforderlich ist, umgehen wir dieses Problem durch den Aufruf eines benutzerdefinierten Handlers, der die Daten mit dem aktuellen Zeitstempel in influxdb aufzeichnet.
docker, Build und Deployment
Beim Start von Kapacitor kann es Aufgaben, Vorlagen und Handler aus dem im Konfigurationsblock [load] angegebenen Verzeichnis laden.
Für die korrekte Erstellung einer Aufgabe sind folgende Dinge erforderlich:
- Dateiname – wird in id/name des Skripts umgesetzt
- Typ – stream/batch
- dbrp – Schlüsselwort für die Angabe, in welcher Datenbank + Politik das Skript läuft (dbrp „supplier“.„autogen“)
Wenn in einer batch-Aufgabe keine Zeile mit dbrp enthalten ist, weigert sich der gesamte Dienst zu starten und schreibt dies ehrlich ins Log.
In Chronograf hingegen sollte diese Zeile nicht vorhanden sein, da sie über die Schnittstelle nicht akzeptiert wird und einen Fehler anzeigt.
Ein Trick beim Erstellen von Containern: Dockerfile liefert -1, wenn es Zeilen mit //.+dbrp gibt, was sofort die Ursache für das Build-Fehlverhalten verdeutlicht.
Join einer zu vielen
Beispielaufgabe: Ermitteln Sie den 95. Percentil der Service-Laufzeit über eine Woche und vergleichen Sie jede der letzten zehn Minuten mit diesem Wert.
Ein Join einer zu vielen ist nicht möglich; last/mean/median pro Gruppe von Punkten verwandeln den Knoten in einen Stream, was zu dem Fehler „cannot add child mismatched edges: batch -> stream“ führt.
Das Ergebnis eines Batches kann ebenfalls nicht als Variable in einem Lambda-Ausdruck eingesetzt werden.
Es gibt die Möglichkeit, die benötigten Zahlen aus dem ersten Batch über eine UDF in eine Datei zu speichern und diese Datei über Sideload zu laden.
Was haben wir damit gelöst?
Wir haben etwa 100 Hotelanbieter, zu jedem von ihnen können mehrere Verbindungen bestehen, die wir als Kanäle bezeichnen. Es gibt ungefähr 300 dieser Kanäle, und jeder Kanal kann ausfallen. Von allen aufgezeichneten Metriken werden wir die Fehlerquote (Requests und Errors) überwachen.
Warum nicht Grafana?
Die Fehlerbenachrichtigungen, die in Grafana eingerichtet sind, haben einige Nachteile. Einige sind kritisch, auf andere kann man je nach Situation verzichten.
Grafana kann keine Berechnungen zwischen Metriken und Alarmierungen durchführen, und wir benötigen die Rate (Anfragen-Fehler) / Anfragen.
Die Fehler sehen unheilvoll aus:
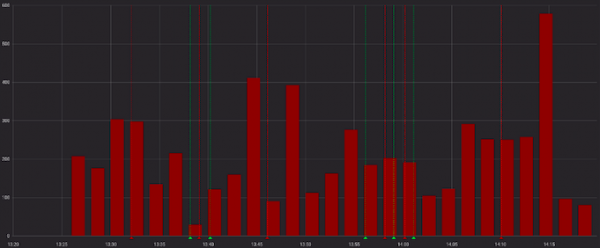
Und weniger unheilvoll, wenn man sie zusammen mit erfolgreichen Anfragen betrachtet:
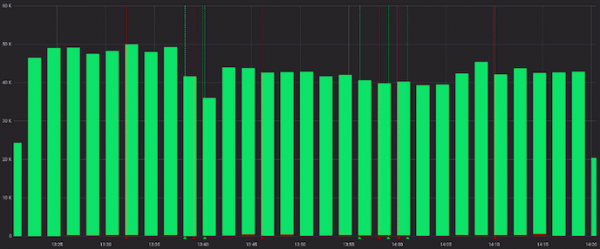
Okay, wir könnten die Rate im Service vor Grafana vorab berechnen, und in manchen Fällen wäre das ausreichend. Aber nicht in unserem Fall, da für jeden Kanal ein eigenes "normales" Verhältnis ermittelt werden muss, und Alarme funktionieren mit statischen Werten (wir suchen händisch, ändern, wenn sie oft auslösen).
Hier sind Beispiele für "normal" bei verschiedenen Kanälen:


Vernachlässigen wir den vorherigen Punkt und nehmen an, dass das "normale" Bild bei allen Anbietern ähnlich aussieht. Ist jetzt alles gut und können wir uns auf Alarme in Grafana verlassen?
Können wir, aber wir möchten das wirklich nicht, da wir eine der folgenden Optionen wählen müssen:
a) Viele Grafiken für jeden Kanal separat erstellen (und sie mühsam pflegen)
b) Eine Grafik mit allen Kanälen behalten (und in bunten Linien und konfigurierten Alarmen verloren gehen)

Wie haben wir es gemacht?
Wiederum gibt es in der Dokumentation ein gutes erstes Beispiel (), das man als Anhaltspunkt verwenden oder für ähnliche Aufgaben übernehmen kann.
Was haben wir letztendlich gemacht:
- Schließen Sie zwei Serien in wenigen Stunden zusammen, gruppiert nach Kanälen;
- Wir füllen Serien nach Gruppen aus, wenn keine Daten vorhanden waren;
- Wir vergleichen das Median der letzten 10 Minuten mit den vorherigen Daten;
- Wir rufen, wenn wir etwas entdeckt haben;
- Wir schreiben die berechneten Raten und aufgetretenen Alarme in influxdb;
- Wir senden eine hilfreiche Nachricht in Slack.
Meiner Ansicht nach ist es uns gelungen, alles, was wir uns gewünscht haben, zum Abschluss möglichst ansprechend zu gestalten (und sogar ein wenig mehr mit benutzerdefinierten Handlers).
Auf github.com kann man schauen und des erhaltenen Skripts.
Beispiel des resultierenden Codes:
dbrp "supplier"."autogen"
var name = 'requests.rate'
var grafana_dash = 'pczpmYZWU/mydashboard'
var grafana_panel = '26'
var period = 8h
var todayPeriod = 10m
var every = 1m
var warnAlert = 15
var warnReset = 5
var reqQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."requests"'
var errQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."errors"'
var prevErr = batch
|query(errQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var prevReq = batch
|query(reqQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var rates = prevReq
|join(prevErr)
.as('req', 'err')
.tolerance(1m)
.fill('null')
// заполняем значения нулями, если их не было
|default()
.field('err.value', 0.0)
.field('req.value', 0.0)
// if в lambda: считаем рейт, только если ошибки были
|eval(lambda: if("err.value" > 0, 100.0 * (float("req.value") - float("err.value")) / float("req.value"), 100.0))
.as('rate')
// записываем посчитанные значения в инфлюкс
rates
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('rates')
// выбираем данные за последние 10 минут, считаем медиану
var todayRate = rates
|where(lambda: duration((unixNano(now()) - unixNano("time")) / 1000, 1u) < todayPeriod)
|median('rate')
.as('median')
var prevRate = rates
|median('rate')
.as('median')
var joined = todayRate
|join(prevRate)
.as('today', 'prev')
|httpOut('join')
var trigger = joined
|alert()
.warn(lambda: ("prev.median" - "today.median") > warnAlert)
.warnReset(lambda: ("prev.median" - "today.median") < warnReset)
.flapping(0.25, 0.5)
.stateChangesOnly()
// собираем в message ссылку на график дашборда графаны
.message(
'{{ .Level }}: {{ index .Tags "channel" }} err/req ratio ({{ index .Tags "supplier" }})
{{ if eq .Level "OK" }}It is ok now{{ else }}
'+string(todayPeriod)+' median is {{ index .Fields "today.median" | printf "%0.2f" }}%, by previous '+string(period)+' is {{ index .Fields "prev.median" | printf "%0.2f" }}%{{ end }}
http://grafana.ostrovok.in/d/'+string(grafana_dash)+
'?var-supplier={{ index .Tags "supplier" }}&var-channel={{ index .Tags "channel" }}&panelId='+string(grafana_panel)+'&fullscreen&tz=UTC%2B03%3A00'
)
.id('{{ index .Tags "name" }}/{{ index .Tags "channel" }}')
.levelTag('level')
.messageField('message')
.durationField('duration')
.topic('slack_graph')
// "today.median" дублируем как "value", также пишем в инфлюкс остальные филды алерта (keep)
trigger
|eval(lambda: "today.median")
.as('value')
.keep()
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('alerts')
.tag('alertName', name)
Was gibt es für Neuigkeiten?
Kapacitor kann hervorragend Monitoring und Alerting mit vielen Gruppierungen durchführen, zusätzliche Berechnungen auf bereits erfassten Metriken vornehmen, benutzerdefinierte Aktionen ausführen und Skripte (udf) starten.
Die Einstiegshürde ist nicht sehr hoch – probieren Sie es aus, wenn Grafana oder andere Tools Ihre Wünsche nicht vollständig erfüllen.
Quelle: habr.com
