

Hallo, Habr!
Angesichts der aktuellen Ereignisse aufgrund des Coronavirus haben viele Internetdienste einen Anstieg der Last erfahren. Zum Beispiel, da die Kapazitäten nicht ausreichten. Und es ist nicht immer möglich, einen Server einfach durch leistungsfähigere Hardware zu beschleunigen, jedoch müssen die Kundenanfragen bearbeitet werden (oder sie wenden sich an die Konkurrenz).
In diesem Artikel werde ich kurz über beliebte Praktiken sprechen, die es ermöglichen, einen schnellen und ausfallsicheren Dienst zu erstellen. Ich habe jedoch nur die Entwicklungsansätze ausgewählt, die derzeit einfach anzuwenden sind.Für jeden Punkt stehen Ihnen entweder bereits vorhandene Bibliotheken zur Verfügung oder es besteht die Möglichkeit, die Aufgabe über eine Cloud-Plattform zu lösen.
Horizontale Skalierung
Der einfachste und bekannteste Punkt. Allgemein gesagt gibt es zwei häufig anzutreffende Lastverteilungsschemata – horizontale und vertikale Skalierung. erlauben Sie es den Diensten, parallel zu arbeiten, wodurch die Last zwischen ihnen verteilt wird. Sie bestellen leistungsstärkere Server oder optimieren den Code.
Als Beispiel nehme ich einen abstrakten Cloud-Speicher, also eine Art von OwnCloud, OneDrive usw.
Das Standarddiagramm einer solchen Architektur ist unten dargestellt, zeigt jedoch lediglich die Komplexität des Systems. Wir müssen die Dienste verstehen und synchronisieren. Was passiert, wenn ein Nutzer von seinem Tablet eine Datei speichert und sie dann auf seinem Smartphone ansehen möchte?
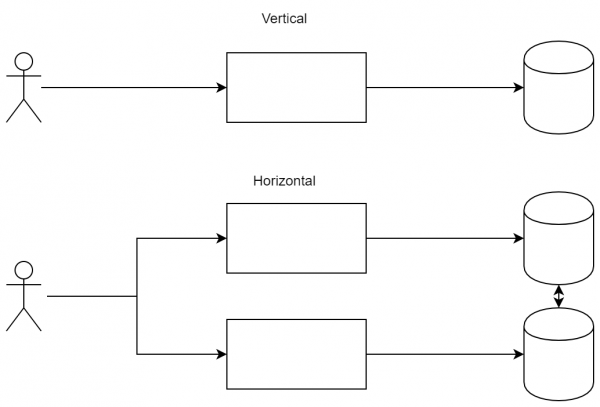
Der Unterschied zwischen den Ansätzen: Beim vertikalen Scaling sind wir bereit, die Leistung der Knoten zu erhöhen, während wir beim horizontalen Scaling neue Knoten hinzufügen, um die Last zu verteilen.
CQRS
Dies ist ein ziemlich wichtiges Muster, da es verschiedenen Clients nicht nur ermöglicht, sich mit unterschiedlichen Diensten zu verbinden, sondern auch identische Ereignisströme zu erhalten. Die Vorteile sind für einfache Anwendungen nicht sofort ersichtlich, jedoch sind sie entscheidend (und einfach) für stark belastete Dienste. Die Grundidee ist: Eingehende und ausgehende Datenströme sollten sich nicht überschneiden. Das heißt, Sie können eine Anfrage senden und nicht auf eine Antwort warten; stattdessen senden Sie eine Anfrage an Dienst A, erhalten jedoch die Antwort von Dienst B.
Der erste Vorteil dieses Ansatzes ist die Möglichkeit, die Verbindung (im weitesten Sinne des Wortes) während einer langen Anfrage zu unterbrechen. Nehmen wir als Beispiel eine mehr oder weniger standardmäßige Abfolge:
- Der Kunde hat eine Anfrage an den Server gesendet.
- Der Server hat die langwierige Verarbeitung gestartet.
- Der Server hat dem Kunden mit dem Ergebnis geantwortet.
Stellen wir uns vor, dass in Punkt 2 die Verbindung unterbrochen wurde (entweder wurde das Netzwerk neu verbunden oder der Benutzer ist auf eine andere Seite gewechselt, wodurch die Verbindung unterbrochen wurde). In diesem Fall wäre es für den Server schwierig, dem Benutzer zu vermitteln, was genau verarbeitet wurde. Wenn wir CQRS anwenden, wird die Abfolge etwas anders aussehen:
- Der Kunde hat sich für Updates angemeldet.
- Der Kunde hat eine Anfrage an den Server gesendet.
- Der Server hat mit «Anfrage angenommen» geantwortet.
- Der Server hat das Ergebnis über den Kanal aus Punkt «1» übermittelt.
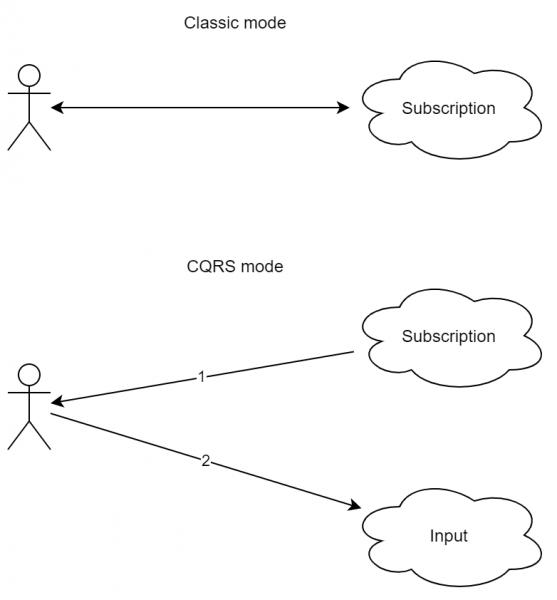
Wie zu sehen ist, ist das Schema etwas komplexer. Darüber hinaus fehlt der intuitive Request-Response-Ansatz hier. Doch wie man sieht, führt eine Unterbrechung der Verbindung während der Anfrageverarbeitung nicht zu einem Fehler. Tatsächlich kann, wenn der Benutzer mit mehreren Geräten (z.B. mit einem Mobiltelefon und einem Tablet) verbunden ist, sichergestellt werden, dass die Antwort auf beide Geräte gesendet wird.
Interessanterweise wird der Code zur Verarbeitung eingehender Nachrichten ähnlich (aber nicht zu 100 %) für Ereignisse, die durch den Kunden selbst beeinflusst wurden, sowie für andere Ereignisse, einschließlich solcher von anderen Kunden.
In der Praxis erhalten wir jedoch zusätzliche Vorteile, da der einseitige Datenstrom im funktionalen Stil verarbeitet werden kann (unter Verwendung von RX und ähnlichen Technologien). Das ist ein erheblicher Vorteil, denn so kann die Anwendung vollständig reaktiv gestaltet werden, wobei ein funktionaler Ansatz zum Einsatz kommt. Für umfangreiche Anwendungen kann das die Ressourcen für Entwicklung und Support erheblich einsparen.
Kombinieren wir diesen Ansatz mit horizontaler Skalierung, erhalten wir zusätzlich die Möglichkeit, Anfragen an einen Server zu senden und Antworten von einem anderen zu empfangen. So kann der Kunde den für ihn passenden Dienst wählen, während das System intern die Ereignisse dennoch korrekt verarbeiten kann.
Event Sourcing
Wie Sie wissen, ist eine der Hauptmerkmale eines verteilten Systems das Fehlen einer gemeinsamen Zeit und eines gemeinsamen kritischen Abschnitts. Für einen einzelnen Prozess können Sie eine Synchronisierung (unter Verwendung der gleichen Mutexes) durchführen, innerhalb derer Sie sicherstellen können, dass niemand sonst diesen Code ausführt. In einem verteilten System ist dies jedoch gefährlich, da es zusätzlichen Overhead verursacht und die wundervolle Möglichkeit der Skalierung beeinträchtigt — letztlich werden alle Komponenten auf ein einzelnes Element warten.
Hieraus ergibt sich eine wichtige Erkenntnis — ein schnelles verteiltes System kann nicht synchronisiert werden, da dies die Leistung verringern würde. Andererseits benötigen wir oft eine gewisse Konsistenz der Komponenten. Dafür kann der Ansatz der verwendet werden, der garantiert, dass in Abwesenheit von Datenänderungen nach einer bestimmten Zeitspanne seit der letzten Aktualisierung („letztendlich“) alle Anfragen den letzten aktualisierten Wert zurückgeben.
Es ist wichtig zu verstehen, dass für klassische Datenbanken oft , wo jeder Knoten über die gleichen Informationen verfügt (dies wird häufig erreicht, wenn eine Transaktion erst dann als abgeschlossen gilt, wenn die Antwort des zweiten Servers vorliegt). Es gibt hier einige Ausnahmen aufgrund der Isolationslevel, aber das grundlegende Konzept bleibt gleich – Sie können in einer vollständig konsistenten Welt leben.
Kehren wir jedoch zu der ursprünglichen Aufgabe zurück. Wenn ein Teil des Systems aufgebaut werden kann mit , dann kann das folgende Schema aufgebaut werden.
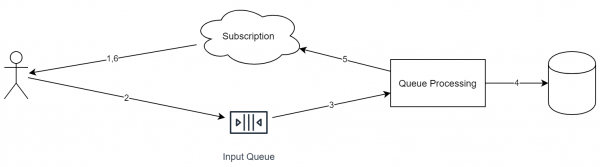
Wichtige Merkmale dieses Ansatzes:
- Jede eingehende Anfrage wird in eine Warteschlange eingefügt.
- Während der Verarbeitung der Anfrage kann der Dienst auch Aufgaben in andere Warteschlangen einfügen.
- Jedes eingehende Ereignis hat einen Identifikator (der für die Deduplizierung erforderlich ist).
- Die Warteschlange arbeitet ideologisch nach dem "append only"-Schema. Elemente können nicht entfernt oder umsortiert werden.
- Die Warteschlange arbeitet nach dem FIFO-Prinzip (Entschuldigung für die tautologische Aussage). Wenn die parallele Ausführung erforderlich ist, sollten die Objekte in einer der Phasen in verschiedene Warteschlangen verschoben werden.
Ich erinnere daran, dass wir den Fall eines Online-Dateispeichers betrachten. In diesem Fall wird das System ungefähr so aussehen:
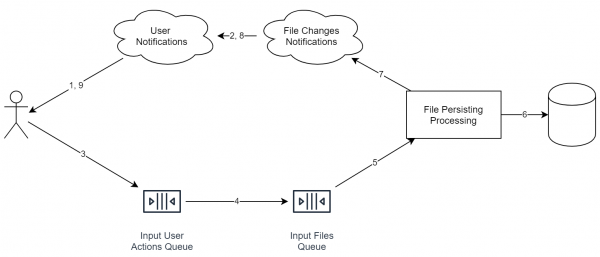
Es ist wichtig zu beachten, dass die Dienste in der Grafik nicht unbedingt einen separaten Server darstellen. Sogar der Prozess kann derselbe sein. Entscheidend ist jedoch, dass diese Konzepte ideologisch so voneinander getrennt sind, dass eine einfache horizontale Skalierung möglich ist.
Für zwei Benutzer würde das Diagramm folgendermaßen aussehen (Dienste, die für unterschiedliche Benutzer bestimmt sind, sind durch verschiedene Farben gekennzeichnet):
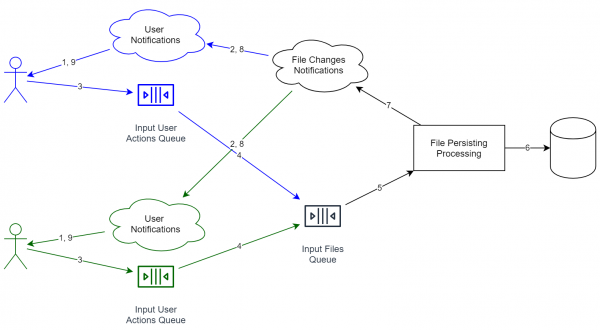
Vorteile einer solchen Kombination:
- Die Informationsverarbeitungsdienste sind getrennt. Die Warteschlangen sind ebenfalls getrennt. Wenn wir die Systemkapazität erhöhen müssen, genügt es, mehr Dienste auf einer größeren Anzahl von Servern zu starten.
- Wenn wir Informationen vom Benutzer erhalten, müssen wir nicht auf die vollständige Speicherung der Daten warten. Im Gegenteil, es reicht aus, mit 'ok' zu antworten und dann schrittweise zu beginnen. Gleichzeitig mildert die Warteschlange die Spitzen, da das Hinzufügen eines neuen Objekts schnell geschieht und der Benutzer nicht auf den vollständigen Durchlauf des gesamten Prozesses warten muss.
- Als Beispiel habe ich einen Deduplication-Dienst hinzugefügt, der versucht, identische Dateien zusammenzuführen. Wenn er lange in 1 % der Fälle arbeitet, wird der Kunde das praktisch nicht bemerken (siehe oben), was ein großer Vorteil ist, da wir nicht unbedingt eine hundertprozentige Geschwindigkeit und Zuverlässigkeit benötigen.
Allerdings sind auch die Nachteile sofort sichtbar:
- Unser System hat die strenge Konsistenz verloren. Das bedeutet, dass man theoretisch bei der Anmeldung zu verschiedenen Diensten unterschiedliche Zustände erhalten kann (da einer der Dienste möglicherweise nicht rechtzeitig die Benachrichtigung von der internen Warteschlange annimmt). Ein weiteres Ergebnis ist, dass das System jetzt keine gemeinsame Zeit hat. Man kann also beispielsweise nicht einfach alle Ereignisse nach ihrem Eintreffen sortieren, da die Uhren zwischen den Servern nicht synchron sein können (darüber hinaus ist es eine Utopie, dass zwei Server die gleiche Zeit haben).
- Es können nun keine Ereignisse einfach zurückgesetzt werden (wie man es mit einer Datenbank tun könnte). Stattdessen muss ein neues Ereignis hinzugefügt werden — , der den letzten Zustand auf den erforderlichen ändern wird. Ein Beispiel aus einem verwandten Bereich: Ohne die Historie zu überschreiben (was in manchen Fällen schlecht ist) kann man in Git keinen Commit zurücksetzen, jedoch kann man einen speziellen , der im Grunde genommen einfach den alten Zustand wiederherstellt. Allerdings bleibt sowohl der fehlerhafte Commit als auch der Rollback in der Historie erhalten.
- Das Daten-Schema kann sich von Version zu Version ändern, jedoch können alte Ereignisse nun nicht auf den neuen Standard aktualisiert werden (da Ereignisse grundsätzlich nicht geändert werden können).
Wie man sieht, harmoniert Event Sourcing hervorragend mit CQRS. Darüber hinaus ist es bereits schwierig, ein System mit effizienten und benutzerfreundlichen Warteschlangen zu implementieren, ohne Datenströme zu trennen. Es müssen Synchronisationspunkte hinzugefügt werden, die den gesamten positiven Effekt der Warteschlangen zunichte machen. Bei der Anwendung beider Ansätze ist es notwendig, den Code der Anwendung geringfügig anzupassen. In unserem Fall, wenn eine Datei an den Server gesendet wird, kommt als Antwort nur "ok", was lediglich bedeutet, dass "die Datei erfolgreich hinzugefügt wurde". Formal bedeutet dies nicht, dass die Daten bereits auf anderen Geräten verfügbar sind (zum Beispiel kann der Deduplizierungsdienst den Index neu aufbauen). Nach einiger Zeit erhält der Kunde jedoch eine Benachrichtigung in der Art von "Datei X gespeichert".
Das Ergebnis:
- Die Anzahl der Statusmeldungen für Dateiübertragungen steigt: Anstelle des klassischen "Datei gesendet" erhalten wir zwei: "Datei in die Warteschlange auf dem Server eingefügt" und "Datei im Speicher gespeichert". Letzteres bedeutet, dass andere Geräte die Datei bereits erhalten können (unter Berücksichtigung der Tatsache, dass Warteschlangen mit unterschiedlicher Geschwindigkeit arbeiten).
- Da Informationen über den Versand nun über verschiedene Kanäle eintreffen, müssen wir Lösungen entwickeln, um den Status der Dateiverarbeitung zu erhalten. Folglich kann der Client während der Dateiverarbeitung neu gestartet werden, während der Status dieser Verarbeitung dennoch korrekt bleibt. Dieses Prinzip funktioniert im Grunde genommen sofort. Dadurch sind wir nun toleranter gegenüber Ausfällen.
Sharding
Wie bereits erwähnt, weisen Systeme mit Event-Sourcing keine strikte Konsistenz auf. Das bedeutet, dass wir mehrere Speicherlösungen nutzen können, ohne dass eine Synchronisation zwischen ihnen erforderlich ist. In Bezug auf unsere Aufgabe können wir:
- Dateien nach Typen trennen. Beispielsweise können Bilder/Videos dekodiert werden, um ein effizienteres Format auszuwählen.
- Konten nach Ländern aufteilen. Aufgrund verschiedener Gesetze kann dies erforderlich sein, doch dieses Architekturdesign ermöglicht dies automatisch.
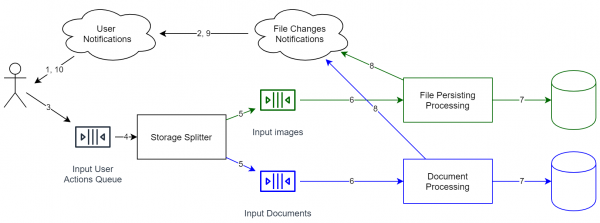
Wenn Sie Daten von einem Speicherort zu einem anderen übertragen möchten, reicht dies nicht mit den Standardmitteln aus. Leider müssen Sie in diesem Fall die Warteschlange anhalten, die Migration durchführen und sie dann wieder starten. Im Allgemeinen können Daten nicht "live" übertragen werden, allerdings, wenn die Ereigniswarteschlange vollständig gespeichert ist und Sie Snapshots der vorherigen Zustände des Speichers haben, können wir die Ereignisse folgendermaßen neu abspielen:
- In der Ereignisquelle hat jedes Ereignis seine eigene Identifikationsnummer (idealerweise eine, die nicht abnimmt). Das bedeutet, dass wir im Speicher ein Feld hinzufügen können — die ID des letzten verarbeiteten Elements.
- Wir duplizieren die Warteschlange, sodass alle Ereignisse für mehrere unabhängige Speicherorte verarbeitet werden können (das erste ist der Speicher, in dem die Daten bereits gespeichert sind, das zweite ist neu und derzeit jedoch leer). Die zweite Warteschlange wird natürlich vorerst nicht bearbeitet.
- Wir starten die zweite Warteschlange (das heißt, wir beginnen mit dem erneuten Abspielen der Ereignisse).
- Wenn die neue Warteschlange relativ leer ist (d.h. der durchschnittliche Zeitunterschied zwischen dem Hinzufügen eines Elements und dessen Abruf akzeptabel ist), können wir damit beginnen, die Leser auf den neuen Speicherort umzuschalten.
Wie zu sehen ist, haben wir in unserem System keine strenge Konsistenz. Es gibt nur eventual consistency, was bedeutet, dass Ereignisse in der gleichen Reihenfolge verarbeitet werden, jedoch möglicherweise mit unterschiedlicher Verzögerung. Daher können wir die Daten vergleichsweise einfach ohne Systemunterbrechung an einen anderen Ort auf der Erde übertragen.
Auf diese Weise bringt unsere Architektur im Beispiel eines Online-Dateispeichers bereits eine Reihe von Vorteilen mit sich:
- Wir können Objekte dynamisch näher zu den Nutzern verschieben, was die Servicequalität verbessert.
- Wir können einen Teil der Daten innerhalb der Unternehmen speichern. Beispielsweise verlangen Enterprise-Kunden oft, dass ihre Daten in kontrollierten Rechenzentren gespeichert werden, um Datenlecks zu vermeiden. Durch Sharding können wir dies leicht unterstützen. Die Aufgabe wird noch einfacher, wenn der Kunde eine kompatible Cloud hat (zum Beispiel, ).
- Das Wichtigste ist, dass wir das nicht zwingend tun müssen. Zu Beginn würde uns ein einziges Speicherangebot für alle Konten genügen, um schnell mit der Arbeit zu beginnen. Das Hauptmerkmal dieses Systems ist, obwohl es erweiterbar ist, dass es in der Anfangsphase relativ einfach gehalten wird. Man muss nicht sofort Code schreiben, der mit einer Million separater, unabhängiger Warteschlangen arbeitet usw. Wenn nötig, kann das in der Zukunft umgesetzt werden.
Hosting für statische Inhalte
Dieser Punkt mag offensichtlich erscheinen, ist jedoch für eine mehr oder weniger standardisierte, stark belastete Anwendung unerlässlich. Die Idee dahinter ist einfach: Alle statischen Inhalte werden nicht von demselben Server bereitgestellt, auf dem sich die Anwendung befindet, sondern von speziellen Servern, die genau dafür vorgesehen sind. Dadurch erfolgen diese Vorgänge schneller (ein typischer nginx-Server liefert Dateien effizienter und kostengünstiger als ein Java-Server). Zudem ermöglicht die Architektur eines CDN () unsere Dateien näher an den Endnutzern zu positionieren, was sich positiv auf die Benutzerfreundlichkeit des Services auswirkt.
Das einfachste und Standardbeispiel für statische Inhalte ist ein Set aus Skripten und Bildern für eine Website. Diese sind im Voraus bekannt, dann wird das Archiv auf die CDN-Server hochgeladen, von wo aus sie an die Endbenutzer verteilt werden.
In der Praxis kann jedoch ein Ansatz verwendet werden, der etwas der Lambda-Architektur ähnelt. Kommen wir zurück zu unserem Ziel (Online-Dateispeicher), bei dem wir Dateien an Benutzer bereitstellen müssen. Die einfachste Lösung wäre, einen Dienst zu erstellen, der für jede Benutzeranfrage alle notwendigen Prüfungen (z. B. Autorisierung usw.) durchführt und dann die Datei direkt aus unserem Speicher herunterlädt. Der Hauptnachteil dieses Ansatzes ist, dass der statische Inhalt (und eine Datei mit einer bestimmten Revision ist im Grunde statischer Inhalt) vom selben Server bereitgestellt wird, der auch die Geschäftslogik enthält. Stattdessen kann folgendes Schema implementiert werden:
- Der Server gibt eine URL zum Herunterladen aus. Diese kann die Form file_id + key haben, wobei key eine kleine digitale Signatur ist, die den Zugang zum Ressourcen innerhalb der nächsten 24 Stunden ermöglicht.
- Das Bereitstellen der Datei erfolgt durch einen einfachen Nginx mit den folgenden Optionen:
- Content-Caching. Da dieser Dienst auf einem separaten Server liegen kann, haben wir uns die Möglichkeit offen gehalten, alle zuletzt heruntergeladenen Dateien auf der Festplatte zu speichern.
- Schlüsselüberprüfung beim Verbindungsaufbau
- Optional: Stream-Verarbeitung von Inhalten. Wenn wir beispielsweise alle Dateien im Dienst komprimieren, kann die Dekomprimierung direkt in diesem Modul erfolgen. Das bedeutet, dass IO-Operationen dort durchgeführt werden, wo sie am sinnvollsten sind. Ein Java-Archivierer kann viel zusätzlichen Speicher beanspruchen, aber einen Dienst mit Geschäftslogik in Rust/C++ umzuschreiben, könnte ebenfalls unwirtschaftlich sein. In unserem Fall verwenden wir verschiedene Prozesse (oder sogar Dienste), sodass wir Geschäftslogik und IO-Operationen recht effektiv trennen können.
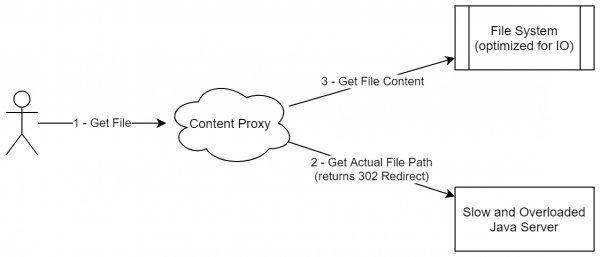
Ein solches Schema ähnelt nicht wirklich der Bereitstellung statischer Inhalte (da wir das gesamte Paket an Statik nicht an einen Ort auslagern), jedoch befasst sich dieser Ansatz tatsächlich mit der Bereitstellung unveränderlicher Daten. Darüber hinaus kann dieses Schema auch auf andere Situationen erweitert werden, in denen der Inhalt nicht nur statisch ist, sondern in Form einer Sammlung von unveränderlichen und nicht löschbaren Blöcken präsentiert werden kann (auch wenn weitere hinzugefügt werden können).
Ein weiteres Beispiel zur Veranschaulichung: Wenn Sie mit Jenkins oder TeamCity gearbeitet haben, wissen Sie, dass beide Lösungen in Java geschrieben sind. Beide sind Java-Prozesse, die sowohl die Orchestrierung von Builds als auch das Management von Inhalten übernehmen. Insbesondere haben sie Aufgaben wie "eine Datei/einen Ordner vom Server übertragen". Zum Beispiel: Bereitstellung von Artefakten, Übertragung des Quellcodes (wenn der Agent den Code nicht direkt aus dem Repository herunterlädt, sondern der Server dies übernimmt), Zugriff auf Protokolle. All diese Aufgaben unterscheiden sich im IO-Aufwand. Das bedeutet, dass der Server, der für eine komplexe Geschäftslogik verantwortlich ist, gleichzeitig in der Lage sein muss, große Datenströme effizient zu verarbeiten. Interessanterweise kann eine solche Operation genau nach dem gleichen Schema an nginx delegiert werden (außer dass im Anfrage-Header ein Daten-Schlüssel hinzugefügt werden muss).
Wenn wir jedoch zu unserem System zurückkehren, ergibt sich folgendes Schema:
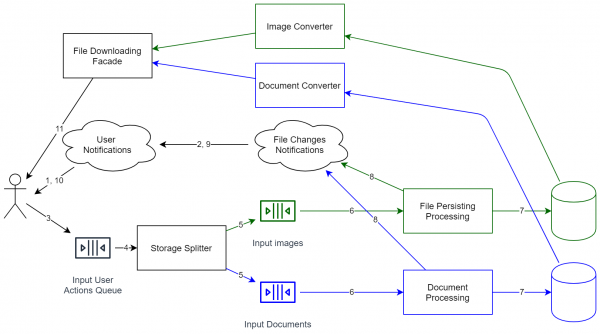
Wie man sieht, ist das System radikal komplexer geworden. Es handelt sich nun nicht mehr nur um einen Mini-Prozess, der Dateien lokal speichert. Jetzt erfordert es eine durchaus anspruchsvolle Unterstützung, API-Versionierung und so weiter. Daher ist es nach dem Zeichnen aller Diagramme ratsam, die Skalierbarkeit solcher Kosten genau zu bewerten. Wenn Sie jedoch die Fähigkeit haben möchten, das System zu erweitern (insbesondere für eine noch höhere Anzahl von Benutzern), müssen Sie solche Lösungen in Betracht ziehen. Das Resultat ist, dass das architektonische System für eine höhere Last bereit ist (fast jede Komponente kann für horizontale Skalierung geklont werden). Das System kann ohne Unterbrechung aktualisiert werden (einfach einige Operationen werden geringfügig langsamer).
Wie ich bereits zu Beginn erwähnt habe, sind eine Reihe von Internetdiensten derzeit mit einer erhöhten Nachfrage konfrontiert. Einige von ihnen haben einfach aufgehört, richtig zu funktionieren. Im Grunde haben die Systeme genau zu dem Zeitpunkt versagt, als das Geschäft gerade Geld verdienen sollte. Anstatt eine verzögerte Lieferung anzubieten oder den Kunden zu sagen: „Planen Sie die Lieferung für die kommenden Monate“, hat das System einfach gesagt: „Gehen Sie zu den Konkurrenten“. Das ist der Preis für eine niedrige Leistung: Verluste treten genau dann auf, wenn der Gewinn am höchsten wäre.
Fazit
All diese Ansätze waren auch früher bekannt. Zum Beispiel nutzt VK bereits seit langem die Idee des Static Content Hosting zur Bereitstellung von Bildern. Viele Online-Spiele verwenden ein Sharding-System, um Spieler nach Regionen zu unterteilen oder um Spielareale (wenn die Welt einheitlich ist) zu unterteilen. Der Event Sourcing-Ansatz wird aktiv im E-Mail-Verkehr genutzt. Die meisten Handelsanwendungen, die kontinuierlich Daten empfangen, basieren tatsächlich auf dem CQRS-Ansatz, um die erhaltenen Daten filtern zu können. Horizontal Scaling wird zudem seit langem in vielen Diensten angewendet.
Doch das Wichtigste ist, dass all diese Muster in modernen Anwendungen sehr einfach anzuwenden sind (wenn sie natürlich passend sind). Clouds bieten Sharding und horizontale Skalierung auf einfache Weise an, was viel einfacher ist, als verschiedene dedizierte Server in unterschiedlichen Rechenzentren selbst zu bestellen. CQRS wurde dank Entwicklungen in Bibliotheken wie RX wesentlich zugänglicher. Vor etwa 10 Jahren konnte eine seltene Website so etwas unterstützen. Event Sourcing lässt sich ebenfalls unglaublich leicht dank bereits vorhandener Container mit Apache Kafka einrichten. Vor einem Jahrzehnt wäre das eine Innovation gewesen, heute ist es überall verbreitet. Das Gleiche gilt für das Hosting statischer Inhalte: Dank besserer Technologien (einschließlich umfangreicher Dokumentation und einer großen Wissensdatenbank) ist dieser Ansatz noch einfacher geworden.
Zusammenfassend lässt sich sagen, dass die Implementierung einer Reihe komplexer Architektur-Patterns jetzt viel einfacher geworden ist, was bedeutet, dass es sich lohnt, sie im Voraus in Betracht zu ziehen. Wenn in einer zehnjährigen Anwendung aufgrund hoher Implementierungs- und Betriebskosten von einer der oben genannten Lösungen abgesehen wurde, kann man im neuen Projekt oder nach dem Refactoring einen Service erstellen, der architektonisch sowohl skalierbar (in Bezug auf die Leistung) als auch bereit für neue Anforderungen der Kunden ist (zum Beispiel zur Lokalisierung personenbezogener Daten).
Und das Wichtigste: Bitte verwenden Sie diese Ansätze nicht, wenn Sie eine einfache Anwendung haben. Ja, sie sind schön und interessant, aber für eine Website mit einem Spitzenaufkommen von 100 Besuchern kann man oft mit einem klassischen Monolithen auskommen (zumindest von außen; intern kann alles in Module unterteilt werden usw.).
Quelle: habr.com
