


In diesem Artikel erkläre ich, wie Sie in 30 Minuten eine Umgebung für maschinelles Lernen einrichten, ein neuronales Netzwerk zur Bilderkennung erstellen und dieses Netzwerk anschließend auf einer Grafikkarte (GPU) ausführen können.
Lassen Sie uns zunächst klären, was ein neuronales Netzwerk ist.
In unserem Fall handelt es sich um ein mathematisches Modell sowie um dessen Software- oder Hardware-Implementierung, die auf dem Prinzip der Organisation und Funktionsweise biologischer neuronaler Netzwerke – Netzwerke von Nervenzellen lebender Organismen – basiert. Dieser Begriff entstand aus dem Verständnis der Prozesse, die im Gehirn ablaufen, und dem Versuch, diese Prozesse zu modellieren.
Neuronale Netzwerke werden nicht auf die herkömmliche Weise programmiert, sondern sie werden trainiert. Die Fähigkeit zum Lernen ist eines der Hauptmerkmale, die neuronale Netzwerke von traditionellen Algorithmen unterscheiden. Technisch gesehen besteht das Lernen darin, die Gewichtungsfaktoren der Verbindungen zwischen den Neuronen zu bestimmen. Während des Lernprozesses kann das neuronale Netzwerk komplexe Zusammenhänge zwischen Eingabedaten und Ausgaben erkennen sowie Verallgemeinerungen durchführen.
Im Hinblick auf maschinelles Lernen ist ein neuronales Netzwerk ein spezifischer Fall von Methoden der Mustererkennung, diskriminanter Analyse, Clustering-Methoden und anderen Verfahren.
Ausrüstung
Lassen Sie uns zunächst die Hardware klären. Wir benötigen einen Server mit einem installierten Linux-Betriebssystem. Für den Betrieb von maschinellen Lernsystemen ist leistungsstarke und somit kostspielige Hardware erforderlich. Wer keine geeignete Maschine zur Verfügung hat, sollte ein Angebot von Cloud-Anbietern in Betracht ziehen. Den benötigten Server kann man schnell mieten und nur für die Nutzungsdauer bezahlen.
In Projekten, die die Erstellung von neuronalen Netzwerken erfordern, nutze ich Server eines russischen Cloud-Anbieters. Das Unternehmen bietet Cloud-Server speziell für maschinelles Lernen zur Miete an, ausgestattet mit leistungsstarken Tesla V100-Grafikprozessoren (GPU) von NVIDIA. Kurz gesagt: Die Nutzung eines Servers mit GPU kann in vielen Fällen deutlich effizienter (schneller) sein im Vergleich zu einem Server, der ähnliche Kosten hat und auf einem CPU (dem allgemein bekannten zentralen Prozessor) basiert. Dies wird durch die Architektur der GPU ermöglicht, die schneller mit Berechnungen umgehen kann.
Für die Ausführung der nachfolgenden Beispiele haben wir für ein paar Tage einen solchen Server erworben:
- SSD-Festplatte 150 GB
- RAM 32 GB
- Tesla V100-Prozessor 16 Gb mit 4 Kernen
Auf der Maschine haben wir Ubuntu 18.04 installiert.
Umgebung einrichten
Jetzt installieren wir alles Notwendige für die Arbeit auf dem Server. Da unser Artikel in erster Linie für Anfänger gedacht ist, werde ich einige Punkte erläutern, die gerade für sie nützlich sind.
Bei der Einrichtung der Umgebung wird viel Arbeit über die Kommandozeile erledigt. Die meisten Benutzer nutzen als Arbeitsbetriebssystem Windows. Die Standardkonsole in diesem System lässt jedoch zu wünschen übrig. Daher werden wir ein hilfreiches Tool verwenden. . Laden Sie die Mini-Version herunter und starten Sie Cmder.exe. Als Nächstes müssen Sie sich mit dem Server über das SSH-Protokoll verbinden:
ssh root@server-ip-or-hostnameAnstelle von server-ip-or-hostname geben Sie die IP-Adresse oder den DNS-Namen Ihres Servers ein. Geben Sie dann das Passwort ein, und bei erfolgreicher Verbindung sollten Sie etwa folgende Meldung erhalten.
Willkommen bei Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)Die Hauptprogrammiersprache zur Entwicklung von ML-Modellen ist Python. Die beliebteste Plattform für dessen Nutzung unter Linux ist .
Wir werden sie auf unserem Server installieren.
Wir beginnen mit der Aktualisierung des lokalen Paketmanagers:
sudo apt-get updateWir installieren curl (das Kommandozeilenwerkzeug):
sudo apt-get install curlLaden Sie die neueste Version von Anaconda Distribution herunter:
cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.shStarten Sie die Installation:
bash Anaconda3-2019.10-Linux-x86_64.shIm Installationsprozess müssen Sie den Lizenzvertrag bestätigen. Bei erfolgreicher Installation sollten Sie Folgendes sehen:
Danke, dass Sie Anaconda3 installiert haben!Für die Entwicklung von ML-Modellen gibt es heutzutage viele Frameworks. Wir arbeiten mit den gängigsten: und .
Die Verwendung des Frameworks ermöglicht eine schnellere Entwicklung und die Nutzung bereits vorhandener Werkzeuge für Standardaufgaben.
In diesem Beispiel werden wir mit PyTorch arbeiten. Lassen Sie uns es installieren:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorchNun müssen wir Jupyter Notebook starten – ein bei ML-Spezialisten beliebtes Entwicklungswerkzeug. Es ermöglicht das Schreiben von Code und Sichtbarmachen der Ergebnisse der Ausführung. Jupyter Notebook ist Teil von Anaconda und bereits auf unserem Server installiert. Wir müssen uns von unserem Desktop-System aus damit verbinden.
Dazu starten wir zuerst Jupyter auf dem Server und geben den Port 8080 an:
jupyter notebook --no-browser --port=8080 --allow-rootÖffnen Sie dann in unserem Konsolenprogramm Cmder einen weiteren Tab (oberes Menü – Neue Konsolendialog) und verbinden Sie sich über SSH am Port 8080 mit dem Server:
ssh -L 8080:localhost:8080 root@server-ip-or-hostnameBeim Eingeben des ersten Befehls erhalten wir Links zur Öffnung von Jupyter in unserem Browser:
Um auf das Notizbuch zuzugreifen, öffnen Sie diese Datei in einem Browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Oder kopieren Sie eine dieser URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
oder http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Nutzen Sie den Link für localhost:8080. Kopieren Sie den vollständigen Pfad und fügen Sie ihn in die Adresszeile Ihres lokalen Browsers ein. Jupyter Notebook wird geöffnet.
Erstellen wir ein neues Notizbuch: Neu — Notizbuch — Python 3.
Überprüfen wir, ob alle Komponenten, die wir installiert haben, korrekt funktionieren. Geben Sie ein Beispiel für PyTorch in Jupyter ein und führen Sie es aus (Taste Ausführen):
from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
Das Ergebnis sollte etwa so aussehen:
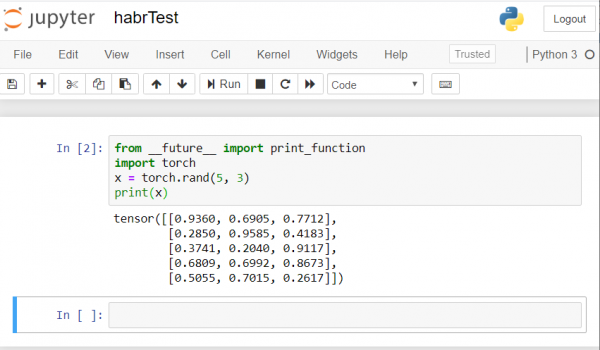
Wenn Sie ein ähnliches Ergebnis erhalten, haben wir alles richtig eingerichtet und können mit der Entwicklung des neuronalen Netzwerks beginnen!
Erstellen eines neuronalen Netzwerks
Wir werden ein neuronales Netzwerk zur Bilderkennung erstellen. Wir nehmen dies als Grundlage. .
Für das Training des Netzwerks werden wir den öffentlichen Datensatz CIFAR10 verwenden. Er enthält die Klassen: „Flugzeug“, „Auto“, „Vogel“, „Katze“, „Reh“, „Hund“, „Frosch“, „Pferd“, „Schiff“, „Lkw“. Die Bilder im CIFAR10 haben die Größe 3x32x32, also 3-kanalige Farbabbildungen mit einer Größe von 32×32 Pixeln.

Für unsere Arbeit verwenden wir das erstellte PyTorch-Paket für die Bildbearbeitung – torchvision.
Wir werden die folgenden Schritte in der Reihenfolge durchführen:
- Laden und Normalisieren der Trainings- und Testdatensätze
- Definieren des neuronalen Netzwerks
- Training des Netzwerks mit den Trainingsdaten
- Testen des Netzwerks mit den Testdaten
- Wir wiederholen das Training und die Tests unter Verwendung von GPU
Den gesamten nachstehenden Code führen wir in Jupyter Notebook aus.
Laden und Normalisieren von CIFAR10
Kopieren und führen Sie den folgenden Code in Jupyter aus:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('Flugzeug', 'Auto', 'Vogel', 'Katze',
'Reh', 'Hund', 'Frosch', 'Pferd', 'Schiff', 'Lkw')Die Antwort sollte so aussehen:
Herunterladen von https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz nach ./data/cifar-10-python.tar.gz
Entpacken von ./data/cifar-10-python.tar.gz nach ./data
Dateien bereits heruntergeladen und überprüftLassen Sie uns einige Trainingsbilder zur Überprüfung anzeigen:
import matplotlib.pyplot as plt
import numpy as np
# Funktionen zum Anzeigen eines Bildes
def imshow(img):
img = img / 2 + 0.5 # Normalisieren
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Einige zufällige Trainingsbilder holen
dataiter = iter(trainloader)
images, labels = dataiter.next()
# Bilder anzeigen
imshow(torchvision.utils.make_grid(images))
# Labels ausgeben
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definieren des neuronalen Netzwerks
Schauen wir uns zunächst an, wie ein neuronales Netzwerk zur Bilderkennung funktioniert. Es handelt sich um ein einfaches Feedforward-Netzwerk. Es nimmt Eingabedaten entgegen, durchläuft diese schichtweise, und gibt schließlich die Ausgabedaten aus.
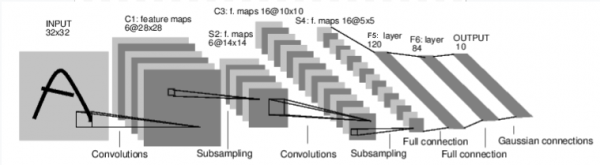
Lassen Sie uns ein ähnliches Netzwerk in unserer Umgebung erstellen:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Lassen Sie uns auch die Verlustfunktion und den Optimierer definieren.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Training des Netzwerks mit den Trainingsdaten
Wir beginnen mit dem Training unseres neuronalen Netzwerks. Beachten Sie, dass Sie nach dem Ausführen dieses Codes eine Weile warten müssen, bis der Vorgang abgeschlossen ist. Bei mir hat es 5 Minuten gedauert. Das Training des Netzwerks benötigt Zeit.
für epoch in range(2): # Schleife über das Dataset mehrere Male
laufender_verlust = 0.0
für i, daten in enumerate(trainloader, 0):
# Eingaben erhalten; daten sind eine Liste von [Eingaben, Labels]
eingaben, labels = daten
# Gradienten der Parameter zurücksetzen
optimizer.zero_grad()
# vorwärts + rückwärts + optimieren
ausgaben = net(eingaben)
verlust = criterion(ausgaben, labels)
verlust.backward()
optimizer.step()
# Statistiken drucken
laufender_verlust += verlust.item()
wenn i % 2000 == 1999: # alle 2000 Mini-Batches drucken
print('[%d, ] Verlust: %.3f' %
(epoch + 1, i + 1, laufender_verlust / 2000))
laufender_verlust = 0.0
print('Training abgeschlossen')
Wir erhalten folgendes Ergebnis:
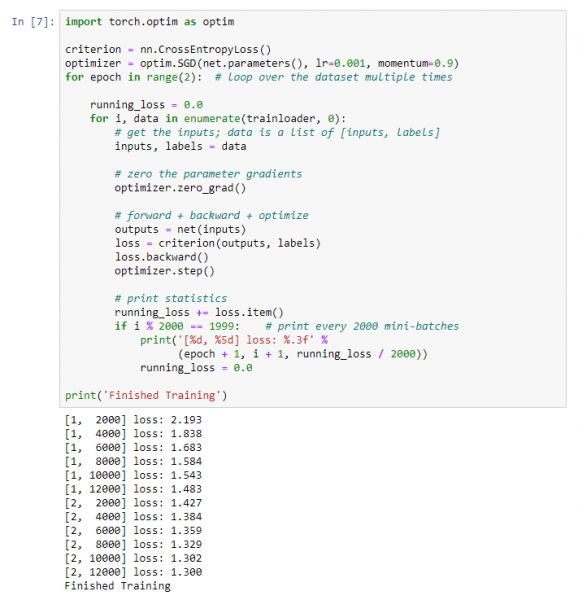
Wir speichern unser trainiertes Modell:
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Testen des Netzwerks mit den Testdaten
Wir haben das Netzwerk mit einem Trainingsdatensatz trainiert. Aber wir müssen überprüfen, ob das Netzwerk überhaupt etwas gelernt hat.
Wir werden dies überprüfen, indem wir das Klassenlabel vorhersagen, das das neuronale Netzwerk ausgibt, und es auf Richtigkeit prüfen. Wenn die Vorhersage korrekt ist, fügen wir das Beispiel der Liste der korrekten Vorhersagen hinzu.
Lassen Sie uns ein Bild aus dem Testdatensatz zeigen:
dataiter = iter(testloader)
images, labels = dataiter.next()
# Bilder ausgeben
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4))) 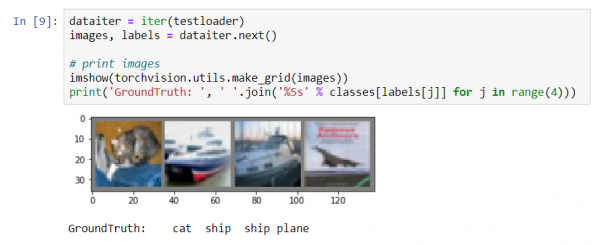
Jetzt bitten wir das neuronale Netzwerk, uns zu sagen, was auf diesen Bildern zu sehen ist:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Vorhersage: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
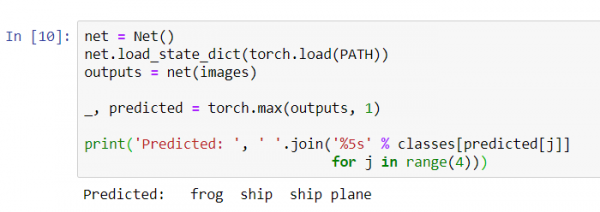
Die Ergebnisse scheinen ziemlich gut zu sein: Das Netzwerk hat drei von vier Bildern korrekt identifiziert.
Schauen wir uns an, wie das Netzwerk im gesamten Datensatz funktioniert.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Genauigkeit des Netzwerks bei den 10000 Testbildern: %d %%' % (
100 * correct / total)) 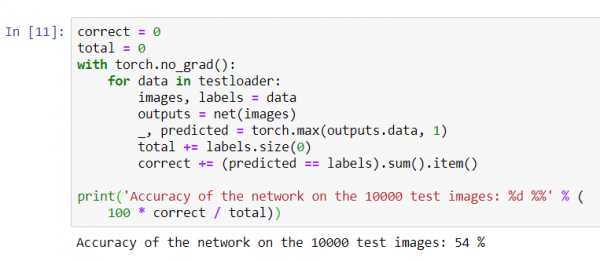
Es scheint, als wüsste das Netzwerk etwas und funktioniert. Wenn es die Klassen zufällig identifizieren würde, wäre die Genauigkeit bei 10 %.
Sehen wir uns jetzt an, welche Klassen das Netzwerk besser erkennt:
klasse_richtig = list(0. für i in range(10))
klasse_total = list(0. für i in range(10))
mit torch.no_grad():
für daten in testloader:
bilder, labels = daten
ausgaben = net(bilder)
_, vorhergesagt = torch.max(ausgaben, 1)
c = (vorhergesagt == labels).squeeze()
für i in range(4):
label = labels[i]
klasse_richtig[label] += c[i].item()
klasse_total[label] += 1
für i in range(10):
print('Genauigkeit von %5s : %%' % (
klassen[i], 100 * klasse_richtig[i] / klasse_total[i])) 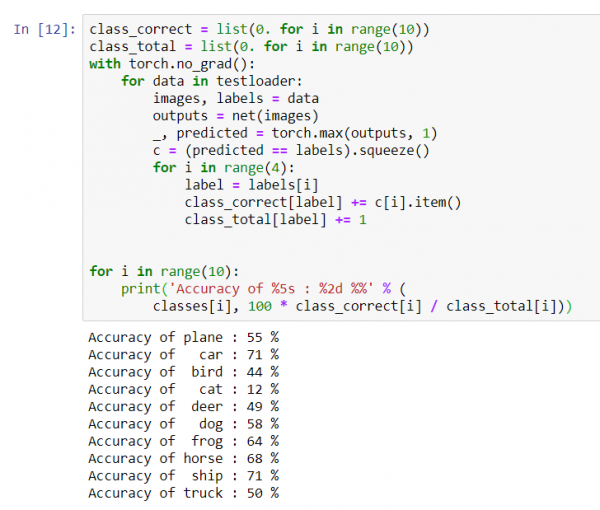
Es scheint, dass das Netzwerk Autos und Schiffe am besten erkennt: 71 % Genauigkeit.
Jetzt funktioniert das Netzwerk. Lassen Sie uns versuchen, es auf die Grafikkarte (GPU) zu übertragen und sehen, was sich ändert.
Training des neuronalen Netzwerks auf der GPU
Zuerst erkläre ich kurz, was CUDA ist. CUDA (Compute Unified Device Architecture) ist eine von NVIDIA entwickelte Plattform für paralleles Rechnen, die allgemeine Berechnungen auf Grafikkarten (GPU) ermöglicht. Mit CUDA können Entwickler ihre Rechenanwendungen erheblich beschleunigen, indem sie die Leistungsfähigkeit von Grafikkarten nutzen. Auf unserem Server, den wir erworben haben, ist diese Plattform bereits installiert.
Lassen Sie uns zunächst unsere GPU als das erste sichtbare CUDA-Gerät festlegen.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Angenommen, wir befinden uns auf einer CUDA-Maschine, sollte dies ein CUDA-Gerät ausgeben:
print(device) 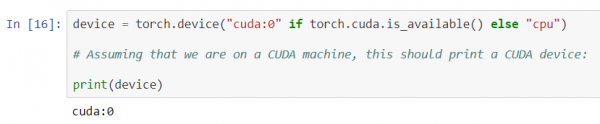
Wir senden das Netzwerk an die GPU:
net.to(device)Außerdem müssen wir die Eingaben und Ziele bei jedem Schritt ebenfalls an die GPU senden:
inputs, labels = data[0].to(device), data[1].to(device)Lassen Sie uns das erneute Training des Netzwerks bereits auf der GPU starten:
importiere torch.optim als optim
kriterium = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
für epoch in range(2): # Schleife über das Dataset mehrere Male
laufender_verlust = 0.0
für i, daten in enumerate(trainloader, 0):
# Eingaben erhalten; daten sind eine Liste von [Eingaben, Labels]
eingaben, labels = daten[0].to(device), daten[1].to(device)
# Gradienten der Parameter zurücksetzen
optimizer.zero_grad()
# vorwärts + rückwärts + optimieren
ausgaben = net(eingaben)
verlust = kriterium(ausgaben, labels)
verlust.backward()
optimizer.step()
# Statistiken drucken
laufender_verlust += verlust.item()
wenn i % 2000 == 1999: # alle 2000 Mini-Batches drucken
print('[%d, ] Verlust: %.3f' %
(epoch + 1, i + 1, laufender_verlust / 2000))
laufender_verlust = 0.0
print('Training abgeschlossen')Dieses Mal dauerte das Training des Netzwerks etwa 3 Minuten. Zum Vergleich: Der gleiche Schritt dauerte auf einer herkömmlichen CPU 5 Minuten. Der Unterschied ist nicht signifikant, da unser Netzwerk nicht besonders groß ist. Bei der Verwendung größerer Datenmengen wird der Geschwindigkeitsunterschied zwischen GPU und traditioneller CPU zunehmen.
Das scheint alles zu sein. Was wir erreicht haben:
- Wir haben untersucht, was eine GPU ist, und einen Server ausgewählt, auf dem sie installiert ist;
- Wir haben die Programmierumgebung für die Erstellung des neuronalen Netzwerks eingerichtet;
- Wir haben ein neuronales Netzwerk zur Bilderkennung erstellt und es trainiert;
- Wir haben das Netzwerktraining mit GPU-Unterstützung wiederholt und eine Geschwindigkeitssteigerung erzielt.
Ich beantworte gerne Fragen in den Kommentaren.
Quelle: habr.com
