

Heute erklären wir die Prinzipien und Modelle von GitOps sowie deren Umsetzung auf der OpenShift-Plattform. Ein interaktives Handbuch zu diesem Thema ist verfügbar. .

Kurz gesagt, GitOps ist eine Sammlung praktischer Methoden zur Verwendung von Git-Pull-Anfragen zur Verwaltung von Infrastruktur- und Anwendungs-Konfigurationen. Im Rahmen von GitOps wird ein Git-Repository als die einzige Informationsquelle über den Zustand des Systems betrachtet, wobei alle Änderungen dieses Zustands vollständig nachvollziehbar und auditierbar sind.
Die Idee der Nachverfolgbarkeit von Änderungen in GitOps ist nicht neu; dieser Ansatz wird seit langem und weitreichend in der Arbeit mit Quellcode verwendet. GitOps setzt einfach ähnliche Funktionen (Überprüfungen, Pull-Anfragen, Tags usw.) bei der Verwaltung von Infrastruktur- und Anwendungs-Konfigurationen um und bietet ähnliche Vorteile wie bei der Verwaltung von Quellcode.
Für GitOps gibt es keine akademische Definition oder festgelegten Regelkatalog, sondern lediglich einen Satz von Prinzipien, auf denen diese Praxis basiert:
- Die deklarative Beschreibung des Systems wird in einem Git-Repository gespeichert (Konfigurationen, Monitoring usw.).
- Zustandsänderungen werden über Pull-Requests durchgeführt.
- Der Zustand aktiver Systeme wird mithilfe von Git Push-Requests an die Daten im Repository angepasst.
GitOps-Prinzipien
- Systemdefinitionen werden als Quellcode beschrieben
Systemkonfigurationen werden als Code betrachtet, sodass sie im Git-Repository gespeichert und automatisch versioniert werden können, welches als einzige Wahrheit dient. Dieser Ansatz ermöglicht es, Änderungen in Systemen einfach auszurollen (Rollout) und zurückzusetzen (Rollback).
- Der gewünschte Zustand und die Systemkonfigurationen werden in Git definiert und versioniert.
Durch das Speichern und Versionieren des gewünschten Systemzustands in Git erhalten wir die Möglichkeit, Änderungen in Systemen und Anwendungen problemlos auszurollen und zurückzusetzen. Außerdem können wir die Sicherheitsmechanismen von Git nutzen, um den Code zu verwalten und seine Authentizität zu bestätigen.
- Änderungen an Konfigurationen können automatisch über Pull-Requests angewendet werden.
Mit Git-Pull-Requests können wir einfach steuern, wie Änderungen an Konfigurationen im Repository angewendet werden. Zum Beispiel können sie zur Überprüfung an andere Teammitglieder weitergegeben oder durch CI-Tests geleitet werden.
Dabei ist es nicht notwendig, Administratorrechte wahllos zu vergeben. Um Änderungen an der Konfiguration zu committen, benötigen die Benutzer lediglich die entsprechenden Berechtigungen im Git-Repository, in dem diese Konfigurationen gespeichert sind.
- Behebung des Problems der unkontrollierten Drift von Konfigurationen
Wenn der gewünschte Zustand des Systems im Git-Repository gespeichert ist, müssen wir lediglich eine Software finden, die sicherstellt, dass der aktuelle Zustand des Systems mit dem gewünschten Zustand übereinstimmt. Falls dies nicht der Fall ist, sollte diese Software – je nach Konfiguration – entweder die Abweichung automatisch beheben oder uns über die Drift der Konfigurationen informieren.
GitOps-Modelle für OpenShift
On-Cluster Ressourcen-Reconciler
In diesem Modell gibt es im Cluster einen Controller, der für den Vergleich von Kubernetes-Ressourcen (YAML-Dateien) im Git-Repository mit den tatsächlichen Ressourcen des Clusters verantwortlich ist. Bei festgestellten Abweichungen sendet der Controller Benachrichtigungen und ergreift möglicherweise Maßnahmen, um die Diskrepanzen zu beheben. Dieses GitOps-Modell wird in Anthos Config Management und Weaveworks Flux eingesetzt.
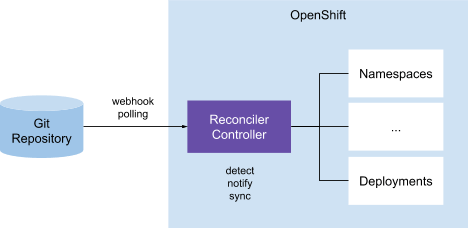
External Resource Reconciler (Push)
Dieses Modell kann als eine Variante des vorherigen betrachtet werden, wenn es einen oder mehrere Controller gibt, die für die Synchronisierung von Ressourcen zwischen 'Git-Repository – Kubernetes-Cluster' verantwortlich sind. Der Unterschied besteht darin, dass nicht unbedingt für jedes verwaltete Cluster ein eigener Controller erforderlich ist. Die Paare 'Git – k8s-Cluster' werden oft als CRD-Beschreibungen (custom resources definition) definiert, in denen beschrieben werden kann, wie der Controller die Synchronisation durchführen soll. In diesem Modell vergleichen die Controller das im CRD angegebene Git-Repository mit den im CRD festgelegten Kubernetes-Ressourcen und führen entsprechende Maßnahmen basierend auf den Ergebnissen des Vergleichs durch. Insbesondere wird ein solches GitOps-Modell in ArgoCD verwendet.
GitOps auf der OpenShift-Plattform
Verwaltung einer Multi-Cluster-Kubernetes-Infrastruktur
Mit der Verbreitung von Kubernetes und dem wachsenden Interesse an Multi-Cloud-Strategien und Edge Computing steigt auch die durchschnittliche Anzahl an OpenShift-Clustern pro Kunde.
Zum Beispiel können bei der Nutzung von Edge Computing Cluster eines Kunden in Hunderten und sogar Tausenden bereitgestellt werden. Infolgedessen ist er gezwungen, mehrere unabhängige oder konsolidierte OpenShift-Cluster in der Public Cloud und On-Premise zu verwalten.
Dabei müssen zahlreiche Herausforderungen gemeistert werden, unter anderem:
- Überwachung, dass die Cluster sich im identischen Zustand befinden (Konfigurationen, Monitoring, Speicher usw.)
- Cluster basierend auf einem bekannten Zustand neu erstellen (oder wiederherstellen).
- Neue Cluster gemäß einem bekannten Zustand erstellen.
- Änderungen auf mehreren OpenShift-Clustern anwenden.
- Änderungen auf mehreren OpenShift-Clustern zurücksetzen.
- Vorlage-konfigurierte Konfigurationen mit verschiedenen Umgebungen verknüpfen.
Anwendungs-Konfigurationen
Im Verlauf ihres Lebenszyklus durchlaufen Anwendungen häufig eine Reihe von Clustern (dev, stage usw.), bevor sie im Produktionscluster landen. Außerdem implementieren Kunden aufgrund von Anforderungen an Verfügbarkeit und Skalierbarkeit oft Anwendungen gleichzeitig auf mehreren Clustern on-premise oder in verschiedenen Regionen öffentlicher Cloud-Plattformen.
Dabei müssen folgende Aufgaben gelöst werden:
- Die Bewegung von Anwendungen (Binaries, Konfigurationen usw.) zwischen Clustern (dev, stage usw.) sicherzustellen.
- Änderungen in Anwendungen (Binaries, Konfigurationen usw.) in mehreren OpenShift-Clustern anzuwenden.
- Änderungen in Anwendungen auf den Stand des vorherigen bekannten Zustands zurückzusetzen.
Anwendungsfälle für OpenShift GitOps
1. Anwendung von Änderungen aus dem Git-Repository
Der Cluster-Administrator kann die Konfigurationen des OpenShift-Clusters in einem Git-Repository speichern und sie automatisch anwenden, um ohne großen Aufwand neue Cluster zu erstellen und diese in einen Zustand zu versetzen, der dem bekannten Zustand im Git-Repository entspricht.
2. Synchronisierung mit dem Secret Manager
Für Administratoren könnte es hilfreich sein, secret-Objekte von OpenShift mit entsprechender Software wie Vault zu synchronisieren, um sie mit speziell entwickelten Werkzeugen verwalten zu können.
3. Überwachung von Konfigurationsabweichungen
Ein Administrator wird es begrüßen, wenn OpenShift GitOps eigenständig Abweichungen zwischen den aktuellen Konfigurationen und den im Repository festgelegten erkennt und meldet, um schnell auf diese Abweichungen reagieren zu können.
4. Benachrichtigungen über Konfigurationsabweichungen
Diese sind nützlich, wenn der Administrator schnell über Abweichungen in den Konfigurationen informiert werden möchte, um umgehend geeignete Maßnahmen ergreifen zu können.
5. Manuelle Synchronisation von Konfigurationen bei Abweichungen
Dies ermöglicht dem Administrator die Synchronisation des OpenShift-Clusters mit dem Git-Repository bei Abweichungen, um den Cluster zügig in einen vorherigen bekannten Zustand zurückzuführen.
6. Automatische Synchronisation von Konfigurationen bei Abweichungen
Der Administrator kann auch den OpenShift-Cluster so konfigurieren, dass er sich bei Erkennung von Abweichungen automatisch mit dem Repository synchronisiert, sodass die Cluster-Konfiguration immer den Konfigurationen im Git entspricht.
7. Mehrere Cluster – ein Repository
Der Administrator kann in einem Git-Repository die Konfigurationen mehrerer verschiedener OpenShift-Cluster speichern und diese bei Bedarf selektiv anwenden.
8. Hierarchie der Clusterkonfigurationen (Vererbung)
Der Administrator kann in dem Repository eine Hierarchie von Clusterkonfigurationen festlegen (Stage, Prod, App-Portfolio usw. mit Vererbung). Das heißt, er kann definieren, wie die Konfigurationen – für einen oder mehrere Cluster – angewendet werden sollen.
Wenn der Administrator beispielsweise im Git-Repository die Hierarchie „Produktions-Cluster (Prod) → Cluster von System X → Produktions-Cluster von System X“ festlegt, dann wird für die Produktions-Cluster von System X die Kombination der folgenden Konfigurationen angewendet:
- Konfigurationen, die für alle Produktions-Cluster gelten.
- Konfigurationen für das Cluster von System X.
- Konfigurationen für das Produktions-Cluster von System X.
9. Vorlagen und Überschreibung von Konfigurationen
Der Administrator kann eine Reihe von geerbten Konfigurationen und deren Werten überschreiben, um die Konfiguration für bestimmte Cluster feiner anzupassen, auf die sie angewendet werden.
10. Selektive Includes und Excludes für Konfigurationen, Anwendungskonfigurationen
Der Administrator kann Bedingungen für die Anwendung oder Nichtanwendung bestimmter Konfigurationen auf Cluster mit spezifischen Eigenschaften festlegen.
11. Unterstützung von Vorlagen
Entwickler werden die Möglichkeit schätzen, wie die Ressourcen einer Anwendung definiert werden (z. B. Helm Chart, reines Kubernetes-YAML usw.), um das am besten geeignete Format für jede spezifische Anwendung zu nutzen.
GitOps-Tools auf der OpenShift-Plattform
ArgoCD
ArgoCD implementiert das Modell der externen Ressourcenabstimmung und bietet eine zentralisierte Benutzeroberfläche zur Orchestrierung der Beziehungen zwischen Clustern und Git-Repositorys nach dem Muster „eins zu vielen“. Ein Nachteil dieses Programms ist die Unmöglichkeit, Anwendungen bei Ausfall von ArgoCD zu verwalten.
Flux
Flux implementiert das Modell der Ressourcenabstimmung im Cluster, weshalb es hier kein zentrales Management des Definitionsrepositories gibt, was eine Schwachstelle darstellt. Andererseits bleibt die Möglichkeit, Anwendungen zu verwalten, auch bei einem Ausfall eines Clusters bestehen, da die Zentralisierung fehlt.
Installation von ArgoCD auf OpenShift
ArgoCD bietet eine hervorragende Kommandozeile und ein webbasiertes Dashboard. Daher werden wir hier Flux und andere Alternativen nicht behandeln.
Um ArgoCD auf der OpenShift 4 Plattform zu implementieren, führen Sie bitte die folgenden Schritte als Cluster-Administrator aus:
Bereitstellung der ArgoCD-Komponenten auf der OpenShift-Plattform
# Create a new namespace for ArgoCD components
oc create namespace argocd
# Apply the ArgoCD Install Manifest
oc -n argocd apply -f https://raw.githubusercontent.com/argoproj/argo-cd/v1.2.2/manifests/install.yaml
# Get the ArgoCD Server password
ARGOCD_SERVER_PASSWORD=$(oc -n argocd get pod -l "app.kubernetes.io/name=argocd-server" -o jsonpath='{.items[*].metadata.name}')Anpassung des ArgoCD Servers, damit er von OpenShift Route erkannt wird
# Patch ArgoCD Server so no TLS is configured on the server (--insecure)
PATCH='{"spec":{"template":{"spec":{"$setElementOrder/containers":[{"name":"argocd-server"}],"containers":[{"command":["argocd-server","--insecure","--staticassets","/shared/app"],"name":"argocd-server"}]}}}}'
oc -n argocd patch deployment argocd-server -p $PATCH
# Expose the ArgoCD Server using an Edge OpenShift Route so TLS is used for incoming connections
oc -n argocd create route edge argocd-server --service=argocd-server --port=http --insecure-policy=RedirectBereitstellung des ArgoCD CLI-Tools
# Download the argocd binary, place it under /usr/local/bin and give it execution permissions
curl -L https://github.com/argoproj/argo-cd/releases/download/v1.2.2/argocd-linux-amd64 -o /usr/local/bin/argocd
chmod +x /usr/local/bin/argocdÄndern des Admin-Passworts für den ArgoCD Server
# Get ArgoCD Server Route Hostname
ARGOCD_ROUTE=$(oc -n argocd get route argocd-server -o jsonpath='{.spec.host}')
# Login with the current admin password
argocd --insecure --grpc-web login ${ARGOCD_ROUTE}:443 --username admin --password ${ARGOCD_SERVER_PASSWORD}
# Update admin's password
argocd --insecure --grpc-web --server ${ARGOCD_ROUTE}:443 account update-password --current-password ${ARGOCD_SERVER_PASSWORD} --new-password Nach Abschluss dieser Schritte kann mit dem ArgoCD Server über das ArgoCD WebUI oder das ArgoCD CLI-Tool gearbeitet werden.
GitOps – es ist nie zu spät
„Der Zug ist abgefahren“ – so wird eine Situation beschrieben, in der eine Gelegenheit verpasst wurde. Im Fall von OpenShift führt der Wunsch, sofort mit dieser neuen und innovativen Plattform zu arbeiten, oft zu genau einer solchen Situation beim Management und der Wartung von Routen, Deployments und anderen OpenShift-Objekten. Aber ist die Chance wirklich endgültig vertan?
Fortsetzung der Artikelserie über , heute zeigen wir Ihnen, wie Sie eine manuell erstellte Anwendung und ihre Ressourcen in einen Prozess umwandeln, der vollständig von den GitOps-Tools verwaltet wird. Dazu werden wir zunächst die httpd-Anwendung manuell bereitstellen. Im Screenshot unten sehen Sie, wie wir einen Namespace, ein Deployment und einen Service erstellen und diesen Service anschließend exponieren, um eine Route zu erstellen.
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/namespace.yaml
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/deployment.yaml
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/service.yaml
oc expose svc/httpd -n simple-appNun haben wir eine manuell erstellte Anwendung. Jetzt müssen wir sie unter GitOps verwalten, ohne die Verfügbarkeit zu verlieren. Kurz gesagt, so funktioniert es:
- Erstellen Sie ein Git-Repository für den Code.
- Exportieren Sie unsere aktuellen Objekte und laden Sie sie in das Git-Repository hoch.
- Wählen Sie die GitOps-Tools aus und stellen Sie diese bereit.
- Fügen Sie unser Repository zu diesen Tools hinzu.
- Definieren Sie die Anwendung in unseren GitOps-Tools.
- Führen Sie einen Testlauf der Anwendung unter Verwendung der GitOps-Tools durch.
- Synchronisieren Sie die Objekte mit den GitOps-Tools.
- Aktivieren Sie die Bereinigung (Pruning) und die automatische Synchronisierung der Objekte.
Wie bereits erwähnt, gibt es in GitOps lediglich eine einzige Informationsquelle für alle Objekte in den Kubernetes-Clustern – das Git-Repository. Wir setzen voraus, dass in Ihrer Organisation bereits ein Git-Repository verwendet wird. Es kann öffentlich oder privat sein, muss jedoch auf die Kubernetes-Cluster zugänglich sein. Es kann dasselbe Repository sein, das auch für den Anwendungscode genutzt wird, oder ein separates Repository, das speziell für Deployments erstellt wurde. Es wird empfohlen, im Repository strenge Berechtigungen einzurichten, da dort sensible Objekte wie Secrets, Routen und andere sicherheitsrelevante Elemente gespeichert werden. In unserem Beispiel erstellen wir ein neues öffentliches Repository auf GitHub. Es kann beliebig benannt werden; wir verwenden den Namen blogpost.
Wenn die YAML-Dateien der Objekte nicht lokal oder im Git gespeichert waren, müssen Sie die Binaries oc oder kubectl verwenden. Im folgenden Screenshot fordern wir das YAML für unseren Namensraum, das Deployment, den Service und die Route an. Zuvor haben wir das gerade erstellte Repository geklont und sind mit dem Befehl cd in dieses gewechselt.
Wenn die YAML-Dateien der Objekte nicht lokal oder in Git gespeichert wurden, müssen die Binaries oc oder kubectl verwendet werden. Im Screenshot unten fordern wir YAML für unseren Namespace, das Deployment, den Service und die Route an. Zuvor haben wir das gerade erstellte Repository geklont und sind mit dem Befehl cd dorthin gewechselt.
oc get namespace simple-app -o yaml --export > namespace.yaml
oc get deployment httpd -o yaml -n simple-app --export > deployment.yaml
oc get service httpd -o yaml -n simple-app --export > service.yaml
oc get route httpd -o yaml -n simple-app --export > route.yamlJetzt passen wir die Datei deployment.yaml an, um das Feld zu entfernen, das Argo CD nicht synchronisieren kann.
sed -i '/sgeneration: .*/d' deployment.yamlAußerdem müssen wir die Route ändern. Zuerst definieren wir eine mehrzeilige Variable und ersetzen dann ingress: null durch den Inhalt dieser Variable.
export ROUTE=" ingress:
- conditions:
- status: 'True'
type: Admitted"
sed -i "s/ ingress: null/$ROUTE/g" route.yamlSo, die Dateien sind jetzt klar, wir müssen sie nur noch im Git-Repository speichern. Danach wird dieses Repository zur einzigen Informationsquelle, und jegliche manuelle Änderungen an Objekten sollten strikt verboten werden.
git commit -am 'initial commit of objects'
git push origin masterWir gehen davon aus, dass ArgoCD bereits bereitgestellt wurde (siehe dazu das vorherige ). Fügen wir daher das von uns erstellte Repository in Argo CD hinzu, das den Anwendungs-Code aus unserem Beispiel enthält. Stellen Sie nur sicher, dass Sie das Repository angeben, das Sie zuvor erstellt haben.
argocd repo add https://github.com/cooktheryan/blogpostJetzt erstellen wir die Anwendung. Die Anwendung definiert Werte, die dem GitOps-Toolkit helfen, zu verstehen, welches Repository und welche Pfade verwendet werden sollen, welches OpenShift zur Verwaltung der Objekte benötigt wird und welcher spezifische Branch des Repositories erforderlich ist, sowie ob eine automatische Synchronisierung der Ressourcen durchgeführt werden soll.
argocd app create --project default
--name simple-app --repo https://github.com/cooktheryan/blogpost.git
--path . --dest-server https://kubernetes.default.svc
--dest-namespace simple-app --revision master --sync-policy none Nachdem die Anwendung in Argo CD definiert wurde, beginnt dieses Toolkit, die bereits bereitgestellten Objekte auf Übereinstimmung mit den Definitionen im Repository zu überprüfen. In unserem Beispiel sind die automatische Synchronisierung und das Säubern deaktiviert, daher ändern sich die Elemente noch nicht. Beachten Sie, dass unsere Anwendung im Argo CD-Interface den Status „Out of Sync“ hat, da kein Label gesetzt ist, das von ArgoCD zugewiesen wird.
Deshalb wird bei der späteren Durchführung der Synchronisierung keine erneute Bereitstellung der Objekte erfolgen.
Jetzt führen wir einen Testlauf durch, um sicherzustellen, dass in unseren Dateien keine Fehler vorhanden sind.
argocd app sync simple-app --dry-runWenn keine Fehler vorliegen, können wir zur Synchronisierung übergehen.
argocd app sync simple-appNachdem Sie den Befehl argocd get für unsere Anwendung ausgeführt haben, sollten wir sehen, dass der Status der Anwendung auf Healthy (Funktionsfähig) oder Synced (Synchronisiert) geändert wurde. Das bedeutet, dass alle Ressourcen im Git-Repository jetzt mit den bereits bereitgestellten Ressourcen übereinstimmen.
argocd app get simple-app
Name: simple-app
Projekt: default
Server: https://kubernetes.default.svc
Namespace: simple-app
URL: https://argocd-server-route-argocd.apps.example.com/applications/simple-app
Repo: https://github.com/cooktheryan/blogpost.git
Ziel: master
Pfad: .
Sync-Richtlinie:
Sync-Status: Sync zu master (60e1678)
Health-Status: Healthy
... Jetzt können wir die automatische Synchronisation und Bereinigung aktivieren, um sicherzustellen, dass nichts manuell erstellt wird und dass jedes Mal, wenn ein Objekt im Repository erstellt oder aktualisiert wird, ein Deployment durchgeführt wird.
argocd app set simple-app --sync-policy automated --auto-prune So haben wir erfolgreich eine Anwendung unter GitOps verwaltet, die ursprünglich nicht GitOps verwendet hat.
Quelle: habr.com
