

Im Vorfeld des Starts des Kurses Wir haben für Sie eine weitere nützliche Übersetzung vorbereitet.
Graphdatenbanken sind eine bedeutende Technologie für Datenbankspezialisten. Ich bemühe mich, die Innovationen und neuen Technologien in diesem Bereich im Blick zu behalten, und nachdem ich mit relationalen und NoSQL-Datenbanken gearbeitet habe, sehe ich, dass die Rolle von Graphdatenbanken immer wichtiger wird. Bei der Arbeit mit komplexen hierarchischen Daten erweisen sich nicht nur traditionelle Datenbanken, sondern auch NoSQL-Lösungen als wenig effizient. Oft ist ein Leistungsrückgang zu beobachten, wenn die Anzahl der Beziehungsebenen und die Größe der Datenbank zunehmen. Mit zunehmender Komplexität der Beziehungen wächst auch die Anzahl der JOINs.
Natürlich gibt es in der relationalen Modellierung Lösungen zur Bearbeitung von Hierarchien (zum Beispiel durch rekursive CTEs), aber das bleibt dennoch ein Umweg. Der Funktionsumfang der graphbasierten Datenbanken in SQL Server ermöglicht es jedoch, mehrere Ebenen von Hierarchien problemlos zu verarbeiten. Sowohl das Datenmodell als auch die Abfragen werden vereinfacht, was ihre Effizienz erhöht. Die Menge des benötigten Codes wird deutlich reduziert.
Graphdatenbanken sind eine ausdrucksstarke Sprache zur Darstellung komplexer Systeme. Diese Technologie wird bereits umfassend in der IT-Branche eingesetzt, in Bereichen wie sozialen Netzwerken, Betrugserkennungssystemen, IT-Netzwerkanalyse, sozialen Empfehlungen sowie Produkt- und Inhaltsanpassungen.
Die Funktionalität von Graphdatenbanken in SQL Server eignet sich für Szenarien, in denen die Daten stark miteinander verknüpft sind und klar definierte Beziehungen aufweisen.
Graphdatenmodell
Ein Graph besteht aus einer Menge von Knoten (Nodes) und Kanten (Edges). Die Knoten repräsentieren Entitäten, während die Kanten die Beziehungen darstellen, in deren Attributen Informationen enthalten sein können.
Eine Graphdatenbank modelliert Entitäten in Form eines Graphen, wie es in der Graphentheorie definiert ist. Die Datenstrukturen bestehen aus Knoten und Kanten. Attribute sind die Eigenschaften von Knoten und Kanten. Eine Verbindung ist die Beziehung zwischen den Knoten.
Im Gegensatz zu anderen Datenmodellen stehen in graphbasierten Datenbanken die Beziehungen zwischen den Entitäten im Vordergrund. Daher ist es nicht erforderlich, Verbindungen über externe Schlüssel oder andere Methoden zu berechnen. Es können komplexe Datenmodelle erstellt werden, die lediglich die Abstraktionen von Knoten und Kanten verwenden.
In der heutigen Welt erfordert die Modellierung von Beziehungen immer kompliziertere Methoden. SQL Server 2017 bietet für die Modellierung von Beziehungen Möglichkeiten graphbasierter Datenbanken. Knoten und Kanten des Graphen werden als neue Tabellentypen dargestellt: NODE und EDGE. Für Abfragen an den Graphen steht eine neue T-SQL-Funktion namens MATCH() zur Verfügung. Da diese Funktionalität in SQL Server 2017 integriert ist, kann sie in Ihren bestehenden Datenbanken verwendet werden, ohne dass eine Umwandlung erforderlich ist.
Vorteile des graphbasierten Modells
Heutzutage verlangen Unternehmen und Nutzer von Anwendungen, dass sie zunehmend größere Datenmengen verarbeiten und gleichzeitig hohe Leistung und Zuverlässigkeit bieten. Die Darstellung von Daten als Graph ermöglicht effektive Mittel zur Verarbeitung komplexer Beziehungen. Dieser Ansatz hilft, viele Herausforderungen zu bewältigen und Ergebnisse im entsprechenden Kontext zu erzielen.
Es scheint, dass viele Anwendungen in Zukunft von der Nutzung graphbasierter Datenbanken profitieren können.
Datenmodellierung: Vom relationalen Modell zur Graphmodellierung
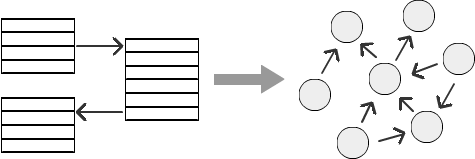
Beispiel
Betrachten wir ein Beispiel für eine Organisationsstruktur mit einer Hierarchie der Mitarbeiter: Ein Mitarbeiter berichtet an einen Manager, der Manager an einen Senior Manager und so weiter. Je nach Unternehmen kann es in dieser Hierarchie beliebig viele Ebenen geben. Mit zunehmender Anzahl der Ebenen wird die Berechnung der Verbindungen in der relationalen Datenbank jedoch immer komplexer. Es ist recht schwierig, die Hierarchie der Mitarbeiter, die Hierarchien im Marketing oder die Verbindungen in sozialen Netzwerken darzustellen. Schauen wir uns an, wie SQL Graph das Problem der Verarbeitung verschiedener Hierarchieebenen lösen kann.
Für dieses Beispiel erstellen wir ein einfaches Datenmodell. Wir erstellen eine Tabelle für Mitarbeiter. EMP mit der Kennung EMPNO und einer Spalte, MGRdie auf die Kennung des Vorgesetzten (Managers) des Mitarbeiters verweist. Alle Informationen zur Hierarchie werden in dieser Tabelle gespeichert und können über die Spalten abgerufen werden. EMPNO und MGR.
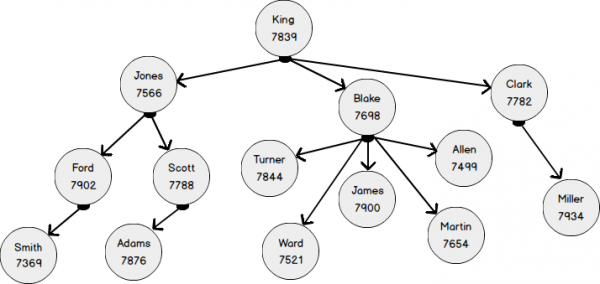
Im nächsten Diagramm ist dasselbe Modell der Organisationsstruktur mit vier Ebenen der Verschachtelung in einer vertrauteren Darstellung abgebildet. Die Mitarbeiter sind die Knoten des Graphen aus der Tabelle. EMP. Die Entität „Mitarbeiter“ ist über die Beziehung „untersteht“ (ReportsTo) mit sich selbst verbunden. In grafischen Begriffen ist die Beziehung eine Kante (EDGE), die Knoten (NODE) von Mitarbeitern verbindet.
Erstellen wir eine herkömmliche Tabelle EMP und fügen wir dort Werte gemäß dem obigen Diagramm hinzu.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
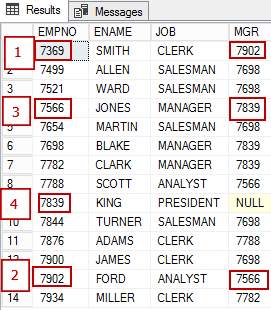
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)In der untenstehenden Abbildung sind die Mitarbeiter dargestellt:
- Mitarbeiter mit EMPNO 7369 untersteht 7902;
- Mitarbeiter mit EMPNO 7902 untersteht 7566
- Mitarbeiter mit EMPNO 7566 untersteht 7839
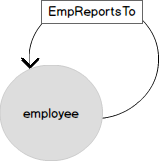
Lassen Sie uns nun die Darstellung derselben Daten in Form eines Graphen betrachten. Der Knoten EMPLOYEE hat mehrere Attribute und ist durch die Beziehung "berichtet an" (EmplReportsTo) mit sich selbst verbunden. EmplReportsTo ist der Name dieser Beziehung.
In der Kante-Tabelle (EDGE) können ebenfalls Attribute vorhanden sein.
Lassen Sie uns die Knoten-Tabelle EmpNode erstellen.
Die Syntax zur Erstellung eines Knotens ist recht einfach: Am Ausdruck CREATE TABLE wird am Ende hinzugefügt "AS NODE".
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Jetzt konvertieren wir die Daten von einer regulären Tabelle in einen Graphen. Der folgende INSERT fügt Daten aus der relationalen Tabelle ein. EMP.
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp 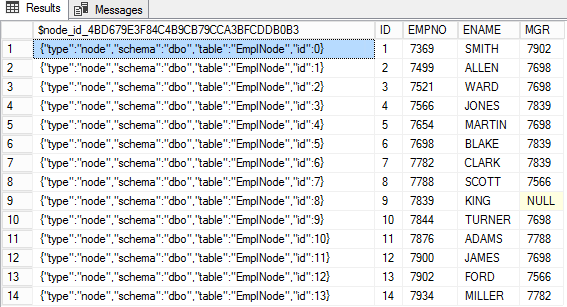
In der Knoten-Tabelle wird in einer speziellen Spalte $node_id_* die Knoten-ID im JSON-Format gespeichert. In den übrigen Spalten dieser Tabelle befinden sich die Attribute des Knotens.
Lassen Sie uns Kanten (EDGE) erstellen.
Die Erstellung der Kanten-Tabelle ist der Erstellung der Knoten-Tabelle sehr ähnlich, mit dem Unterschied, dass das Schlüsselwort "AS EDGE".
CREATE TABLE empReportsTo(Deptno int) AS EDGE 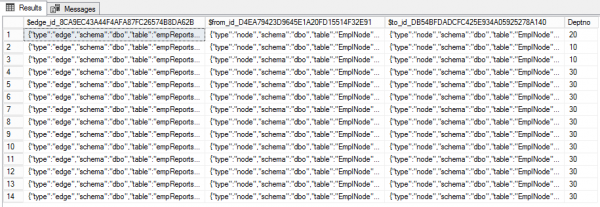
Nun definieren wir die Beziehungen zwischen den Mitarbeitern mithilfe der Spalten EMPNO und MGR. Anhand des Organigramms ist gut zu erkennen, wie man es schreibt. INSERT.
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30); Die Standard-Rib-Tabelle besteht aus drei Spalten. Die erste, $edge_id — der Kanten-Identifier im JSON-Format. Die beiden anderen ($from_id und $to_id) stellen die Verbindung zwischen den Knoten dar. Außerdem können Kanten zusätzliche Eigenschaften haben. In unserem Fall sind das Deptno.
Systemansichten
In der Systemansicht sys.tables sind zwei neue Spalten hinzugefügt worden:
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%' 
SSMS
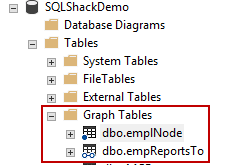
Objekte, die mit Grafen verbunden sind, befinden sich im Ordner Graph Tables. Das Symbol der Knotentabelle ist mit einem Punkt markiert, während die Kanten Tabellen mit zwei verbundenen Kreisen (was ein wenig wie eine Brille aussieht).
Der Ausdruck MATCH
Ein Ausdruck MATCH stammt aus CQL (Cypher Query Language). Dies ist eine effiziente Methode zum Abfragen von Graf-Eigenschaften. CQL beginnt mit dem Ausdruck MATCH.
Syntax
MATCH ()
::=
{ {
{ <-( )- }
| { -( )-> }
}
}
[ { AND } { ( ) } ]
[ ,...n ]
::=
node_table_name | node_alias
::=
edge_table_name | edge_aliasBeispiele
Lassen Sie uns einige Beispiele ansehen.
Die folgende Abfrage zeigt Mitarbeiter, die Smith und seinen Manager unterstellt sind.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH' 
Die nächste Abfrage dient dazu, Mitarbeiter und Manager der zweiten Ebene für Smith zu suchen. Wenn Sie den Satz weglassen, WHERE, werden alle Mitarbeiter angezeigt.
SELECT
E.EMPNO, E.ENAME, E.MGR, E1.EMPNO, E1.ENAME, E1.MGR, E2.EMPNO, E2.ENAME, E2.MGR
FROM
empnode e, empnode e1, empReportsTo m, empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)-e1-(m1)->e2)
AND e.ENAME='SMITH' 
Und schließlich die Abfrage für Mitarbeiter und Manager der dritten Ebene.
SELECT
E.EMPNO, E.ENAME, E.MGR, E1.EMPNO, E1.ENAME, E1.MGR, E2.EMPNO, E2.ENAME, E2.MGR, E3.EMPNO, E3.ENAME, E3.MGR
FROM
empnode e, empnode e1, empReportsTo m, empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)-e1-(m1)->e2-(m2)->e3)
AND e.ENAME='SMITH' 
Lassen Sie uns nun die Richtung ändern, um die Vorgesetzten von Smith zu erhalten.
SELECT
E.EMPNO, E.ENAME, E.MGR, E1.EMPNO, E1.ENAME, E1.MGR, E2.EMPNO, E2.ENAME, E2.MGR, E3.EMPNO, E3.ENAME, E3.MGR
FROM
empnode e, empnode e1, empReportsTo m, empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3) 
Fazit
SQL Server 2017 hat sich als vollwertige Unternehmenslösung für verschiedene IT-Aufgaben im Geschäft bewährt. Die erste Version von SQL Graph ist sehr vielversprechend. Trotz einiger Einschränkungen gibt es bereits jetzt ausreichend Funktionen, um die Möglichkeiten von Graphen zu erkunden.
Die SQL Graph-Funktion ist vollständig in die SQL Engine integriert. Wie bereits erwähnt, gibt es jedoch in SQL Server 2017 folgende Einschränkungen:
Keine Unterstützung für Polymorphismus.
- Es werden nur unidirektionale Beziehungen unterstützt.
- Die Spalten $from_id und $to_id von Kanten können nicht über UPDATE aktualisiert werden.
- Transitive Abschlüsse werden nicht unterstützt, können jedoch mithilfe von CTEs erzielt werden.
- Eingeschränkte Unterstützung für In-Memory OLTP-Objekte.
- Temporale Tabellen (System-Versionierte Temporale Tabelle), temporäre lokale und globale Tabellen werden nicht unterstützt.
- Tabellentypen und Tabellevariablen können nicht als NODE oder EDGE deklariert werden.
- Abfragen zwischen Datenbanken (Cross-Datenbank-Abfragen) werden nicht unterstützt.
- Es gibt keinen direkten Weg oder einen Wizard, um reguläre Tabellen in Graph-Tabellen umzuwandeln.
- Für die Visualisierung von Graphen gibt es kein GUI, aber Power BI kann verwendet werden.
Weiterlesen:
Quelle: habr.com
