


Cloud Computing dringt immer tiefer in unser Leben ein, und es gibt wahrscheinlich keinen Menschen, der nicht mindestens einmal irgendeinen Cloud-Service genutzt hat. Was genau ist jedoch die Cloud und wie funktioniert sie? Die meisten Menschen wissen das nicht einmal auf einer grundlegenden Ebene. 5G wird zunehmend zur Realität, und die Telekommunikationsinfrastruktur beginnt, von stationären Lösungen zu Cloud-Lösungen überzugehen, ähnlich wie sie zuvor von rein hardwarebasierten Lösungen zu virtualisierten "Säulen" überging.
Heute sprechen wir über die innere Welt der Cloud-Infrastruktur, insbesondere über die Grundlagen des Netzwerks.
Was ist die Cloud? Ist diese nicht einfach nur eine Art von Virtualisierung?
Eine durchaus logische Frage. Nein, es handelt sich nicht um Virtualisierung, auch wenn sie eine Rolle spielt. Lassen Sie uns zwei Definitionen betrachten:
Cloud Computing (im Folgenden die Cloud) ist ein Modell, das den benutzerfreundlichen Zugang zu verteilten Rechenressourcen ermöglicht, die auf Anfrage mit minimaler Verzögerung und minimalen Kosten seitens des Dienstanbieters bereitgestellt und in Betrieb genommen werden sollen.
Virtualisierung — ist die Möglichkeit, eine physische Entität (zum Beispiel einen Server) in mehrere virtuelle zu unterteilen, wodurch die Ressourcenauslastung erhöht wird (beispielsweise hatten Sie zuvor 3 Server, die mit 25-30 Prozent ausgelastet waren, nach der Virtualisierung erhalten Sie 1 Server mit 80-90 Prozent Auslastung). Natürlich benötigt die Virtualisierung einige Ressourcen — Sie müssen den Hypervisor betreiben, doch die Erfahrung zeigt, dass es sich lohnt. Ein perfektes Beispiel für Virtualisierung ist VMWare, das hervorragende virtuelle Maschinen erstellt, oder KVM, das mir persönlich besser gefällt, aber das ist Geschmackssache.
Wir nutzen Virtualisierung, ohne es zu merken; sogar Hardware-Router verwenden bereits Virtualisierung — zum Beispiel wird in den neuesten Versionen von JunOS das Betriebssystem als virtuelle Maschine über einem Echtzeit-Linux-Distribution (Wind River 9) installiert. Aber Virtualisierung ist nicht gleich Cloud; dennoch kann die Cloud ohne Virtualisierung nicht existieren.
Virtualisierung ist einer der Grundbausteine, auf denen die Cloud aufgebaut ist.
Ein Cloud-System zu erstellen, indem man einfach mehrere Hypervisoren in eine L2-Domain zusammenfasst, ein paar YAML-Playbooks für die automatische VLAN-Definition über Ansible hinzufügt und darauf etwas wie ein Orchestrierungssystem für die automatische Erstellung virtueller Maschinen legt, wird nicht funktionieren. Genauer gesagt, es wird funktionieren, aber das resultierende Frankenstein-Konstrukt ist nicht die Art von Cloud, die wir benötigen. Obwohl es sein könnte, dass dies für manche der Höhepunkt ihrer Träume ist. Zudem, wenn man sich OpenStack ansieht — im Grunde ist es ebenfalls ein gewisses Frankenstein, aber lassen wir das zunächst beiseite.
Aber ich verstehe, dass aus der obigen Definition nicht ganz klar ist, was tatsächlich als Cloud bezeichnet werden kann.
Deshalb nennt das Dokument des NIST (National Institute of Standards and Technology) fünf grundlegende Merkmale, die eine Cloud-Infrastruktur aufweisen muss:
Bereitstellung von Diensten auf Anfrage. Benutzern muss ein ungehinderter Zugang zu den ihnen zugewiesenen Computerressourcen (wie Netzwerken, virtuellen Festplatten, Speicher, CPU-Kernen usw.) gewährt werden, wobei diese Ressourcen automatisch bereitgestellt werden müssen — also ohne Eingriff des Dienstanbieters.
Hohe Verfügbarkeit des Dienstes. Der Zugriff auf Ressourcen sollte über standardisierte Mechanismen gewährleistet sein, um sowohl auf herkömmliche PCs als auch auf Thin Clients und mobile Geräte zugreifen zu können.
Ressourcenspeicherung in Pools. Ressourcenpools müssen die gleichzeitige Bereitstellung von Ressourcen für mehrere Kunden ermöglichen und dabei Isolierung der Kunden sowie gegenseitigen Einfluss und Konkurrenz um Ressourcen verhindern. Die Pools umfassen auch Netzwerke, was die Möglichkeit der Verwendung von überlappenden Adressbereichen bedeutet. Sie sollten eine skalierbare On-Demand-Nutzung unterstützen. Durch die Verwendung von Pools kann ein erforderliches Niveau an Ausfallsicherheit der Ressourcen gewährleistet und die physischen und virtuellen Ressourcen abstrahiert werden — dem Dienstempfänger wird einfach der angeforderte Ressourcensatz bereitgestellt (wo diese Ressourcen physisch angeordnet sind, auf wie vielen Servern und Switches — das ist für den Kunden unerheblich). Es muss jedoch berücksichtigt werden, dass der Anbieter eine transparente Reservierung dieser Ressourcen sicherstellen muss.
Schnelle Anpassung an unterschiedliche Bedingungen. Die Dienste sollten flexibel sein – eine schnelle Bereitstellung von Ressourcen, deren Umverteilung, Hinzufügen oder Verringern auf Kundenanfrage, wobei der Kunde das Gefühl haben sollte, dass die Cloud-Ressourcen unbegrenzt sind. Zum besseren Verständnis: Sie sehen zum Beispiel nicht die Warnung, dass Ihnen bei Apple iCloud ein Teil des Speicherplatzes fehlt, weil die Festplatte auf dem Server defekt ist, und Festplatten können tatsächlich ausfallen. Zudem sind Ihre Möglichkeiten mit diesem Service praktisch unbegrenzt – benötigen Sie 2 TB – kein Problem, zahlen und erhalten. Ähnlich kann man das Beispiel mit Google Drive oder Yandex Disk anführen.
Die Möglichkeit zur Messung des bereitgestellten Services. Cloud-Systeme sollten automatisch die verbrauchten Ressourcen überwachen und optimieren, wobei diese Mechanismen sowohl für den Benutzer als auch für den Dienstanbieter transparent sein sollten. Das bedeutet, Sie können jederzeit überprüfen, wie viele Ressourcen Sie und Ihre Kunden verbrauchen.
Es ist wichtig zu beachten, dass diese Anforderungen hauptsächlich an öffentliche Cloud-Dienste gerichtet sind. Daher können sie für private Clouds (also Clouds, die für interne Unternehmensbedürfnisse betrieben werden) etwas angepasst werden. Dennoch müssen sie erfüllt werden, sonst entgehen uns die Vorteile des Cloud-Computings.
Warum brauchen wir eine Cloud?
Jede neue oder bereits bestehende Technologie sowie jeder neue Protokoll wird für einen bestimmten Zweck entwickelt (außer RIP-ng, selbstverständlich). Ein Protokoll nur um des Protokolls willen ist nicht erforderlich (außer RIP-ng, selbstverständlich). Es liegt auf der Hand, dass die Cloud dazu dient, dem Nutzer/Kunden einen bestimmten Service bereitzustellen. Wir alle kennen mindestens einige Cloud-Dienste, wie zum Beispiel Dropbox oder Google Docs, und ich nehme an, dass die meisten erfolgreich mit ihnen arbeiten – zum Beispiel wurde dieser Artikel mit dem Cloud-Dienst Google Docs verfasst. Die uns bekannten Cloud-Dienste stellen jedoch nur einen Teil der Möglichkeiten der Cloud dar – genauer gesagt, sie sind lediglich SaaS-Angebote. Die Bereitstellung eines Cloud-Dienstes kann auf drei Arten erfolgen: als SaaS, PaaS oder IaaS. Welcher Service für Sie am besten geeignet ist, hängt von Ihren Bedürfnissen und Möglichkeiten ab.
Schauen wir uns jeden von ihnen der Reihe nach an:
Software as a Service (SaaS) — ist ein Modell zur Bereitstellung eines umfassenden Services für den Kunden, wie etwa ein E-Mail-Service wie Yandex.Mail oder Gmail. In einem solchen Service-Modell müssen Sie als Kunde praktisch nichts weiter tun, als den Service zu nutzen – das bedeutet, dass Sie sich nicht um die Konfiguration des Dienstes, dessen Ausfallsicherheit oder die Datensicherung kümmern müssen. Das Wichtigste ist, Ihr Passwort nicht zu kompromittieren, alles andere übernimmt der Anbieter dieses Services. Aus Sicht des Dienstanbieters trägt er die volle Verantwortung für den gesamten Service – beginnend mit der Serverhardware und den Host-Betriebssystemen, bis hin zu den Konfigurationen der Datenbanken und der Software.
Platform as a Service (PaaS) — Bei Verwendung dieses Modells stellt der Dienstanbieter dem Kunden eine Vorlage für den Service zur Verfügung, beispielsweise einen Webserver. Der Dienstanbieter hat dem Kunden einen virtuellen Server bereitgestellt (tatsächlich ein Set von Ressourcen wie RAM, CPU, Speicher, Netzwerke usw.) und sogar das Betriebssystem sowie die erforderliche Software auf diesem Server installiert. Die Konfiguration all dieser Elemente obliegt jedoch dem Kunden, und der Kunde ist auch für die Funktionsfähigkeit des Services verantwortlich. Der Dienstanbieter bleibt, wie im vorherigen Fall, für die Funktionsfähigkeit der physischen Hardware, der Hypervisoren, der virtuellen Maschine selbst, ihre Netzwerkverfügbarkeit usw. verantwortlich, jedoch liegt der Service außerhalb seiner Verantwortung.
Infrastructure as a Service (IaaS) Dieser Ansatz ist bereits interessanter, da der Dienstanbieter dem Kunden eine vollständige virtualisierte Infrastruktur bereitstellt – also eine Art Ressourcensatz (Pool) wie CPU-Kerne, RAM, Netzwerke usw. Alles Weitere liegt in der Verantwortung des Kunden – was der Kunde mit diesen Ressourcen innerhalb seines zugewiesenen Pools (Quota) machen möchte, ist dem Anbieter nicht besonders wichtig. Ob der Kunde ein eigenes vEPC erstellen oder sogar einen kleinen Anbieter für Kommunikationsdienste aufbauen möchte – kein Problem, machen Sie es. In diesem Szenario ist der Dienstanbieter verantwortlich für die Bereitstellung der Ressourcen, deren Ausfallsicherheit und Verfügbarkeit sowie für das Betriebssystem, das es ermöglicht, diese Ressourcen in Pools zu bündeln und sie dem Kunden mit der Möglichkeit anzubieten, jederzeit Ressourcen nach Bedarf zu erhöhen oder zu reduzieren. Alle virtuellen Maschinen und andere Feinheiten konfiguriert der Kunde selbst über das Self-Service-Portal und die Konsole, einschließlich der Netzwerkkonfiguration (ausgenommen externe Netzwerke).
Was ist OpenStack?
In allen drei Varianten benötigt der Dienstleister ein Betriebssystem, das den Aufbau einer Cloud-Infrastruktur ermöglicht. Tatsächlich ist bei SaaS jedoch nicht eine Abteilung für den gesamten Technologie-Stack verantwortlich – es gibt eine Abteilung, die für die Infrastruktur zuständig ist, also IaaS an eine andere Abteilung bereitstellt, die wiederum die SaaS für die Kunden bereitstellt. OpenStack ist eines der Cloud-Betriebssysteme, das es ermöglicht, eine Vielzahl von Switches, Servern und Speichersystemen in einen einheitlichen Ressourcenpool zu integrieren, diesen Pool in Subpools (Tenants) aufzuteilen und die Ressourcen über das Netzwerk den Kunden zur Verfügung zu stellen.
OpenStack ist ein Cloud-Betriebssystem, das die Kontrolle über große Pools von Rechenressourcen, Datenspeichern und Netzwerkressourcen ermöglicht, wobei das Provisioning und Management über APIs unter Verwendung standardmäßiger Authentifizierungsmechanismen erfolgt.
Mit anderen Worten handelt es sich um eine Sammlung von Open-Source-Projekten, die zur Erstellung von Cloud-Diensten (sowohl öffentlich als auch privat) gedacht sind – also eine Reihe von Werkzeugen, die es ermöglichen, Server- und Netzwerkhardware zu einem Pool von Ressourcen zu vereinen, diese Ressourcen zu verwalten und ein erforderliches Maß an Ausfallsicherheit zu gewährleisten.
Zum Zeitpunkt der Erstellung dieses Materials sieht die Struktur von OpenStack folgendermaßen aus:
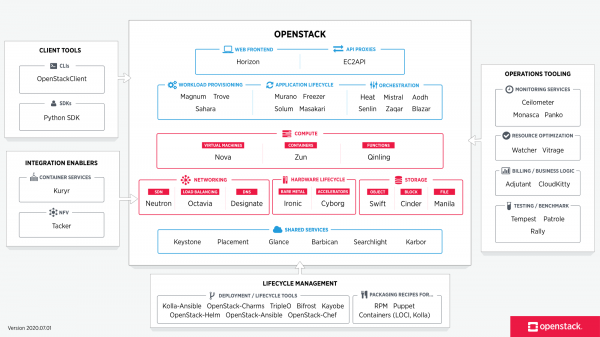
Das Bild wurde von
Jede der Komponenten, die Teil von OpenStack sind, erfüllt eine bestimmte Funktion. Diese verteilte Architektur ermöglicht es, die spezifischen funktionalen Komponenten in die Lösung einzubeziehen, die Sie benötigen. Einige Komponenten hingegen sind grundlegende Bestandteile, deren Entfernung zur vollständigen oder teilweisen Nichtfunktion der Lösung führen würde. Zu diesen Komponenten gehören in der Regel:
- Instrumententafel — Webbasierte GUI zur Verwaltung von OpenStack-Diensten
- Keystone — ein zentralisierter Identifikationsdienst, der Funktionen für Authentifizierung und Autorisierung für andere Dienste bereitstellt sowie die Verwaltung von Benutzeranmeldeinformationen und deren Rollen ermöglicht.
- Neutron — ein Netzwerkdienst, der die Konnektivität zwischen den Schnittstellen verschiedener OpenStack-Dienste gewährleistet (einschließlich der Verbindung zwischen VMs und ihrem Zugriff auf die Außenwelt)
- Cinder — bietet Zugriff auf Blockspeicher für virtuelle Maschinen
- Nova — Verwaltung des Lebenszyklus von virtuellen Maschinen
- Glance — Repository für Maschinenbilder und Snapshots
- Swift — bietet Zugang zu Objektspeicher
- Ceilometer — Dienst, der die Möglichkeit zur Erfassung von Telemetrie und Messung vorhandener und verbrauchter Ressourcen bietet
- Heat — Orchestrierung basierend auf Vorlagen zur automatischen Erstellung und Provisionierung von Ressourcen
Eine vollständige Liste aller Projekte und deren Zweck finden Sie hier .
Jede Komponente von OpenStack ist ein Dienst, der für eine bestimmte Funktion verantwortlich ist und ein API zur Verwaltung dieser Funktion sowie zur Interaktion mit anderen Diensten des Cloud-Betriebssystems bereitstellt, um eine einheitliche Infrastruktur zu schaffen. Beispielsweise verwaltet Nova die Rechenressourcen und bietet ein API zur Konfiguration dieser Ressourcen, Glance kümmert sich um die Images und stellt ein API zu deren Verwaltung bereit, Cinder ist für den Blockspeicher zuständig und bietet ein API zur Steuerung, und so weiter. Alle Funktionen sind eng miteinander verknüpft.
Wenn man jedoch darüber nachdenkt, stellt man fest, dass alle Dienste, die in OpenStack ausgeführt werden, letztlich eine Art virtuelle Maschine (oder Container) sind, die mit dem Netzwerk verbunden ist. Die Frage stellt sich – warum benötigen wir so viele Elemente?
Lassen Sie uns den Ablauf zur Erstellung einer virtuellen Maschine und deren Verbindung mit dem Netzwerk und dem permanenten Speicher in OpenStack durchgehen.
- Wenn Sie eine Anfrage zur Erstellung einer Maschine stellen, sei es über Horizon (Dashboard) oder über die CLI, erfolgt zunächst die Authentifizierung Ihrer Anfrage bei Keystone. Dabei wird geprüft, ob Sie eine Maschine erstellen dürfen, ob Sie das Recht zur Nutzung dieses Netzwerks haben, ob Ihr Projekt über die erforderlichen Kontingente verfügt usw.
- Keystone authentifiziert Ihre Anfrage und generiert in der Antwort eine Auth-Token, die später verwendet wird. Nachdem die Antwort von Keystone eingegangen ist, wird die Anfrage an Nova (nova API) weitergeleitet.
- Die Nova-API überprüft die Gültigkeit Ihrer Anfrage, indem sie sich unter Verwendung des zuvor generierten Auth-Tokens an Keystone wendet.
- Keystone führt die Authentifizierung durch und stellt basierend auf dem Auth-Token Informationen zu Berechtigungen und Einschränkungen zur Verfügung.
- Die Nova-API erstellt in der Nova-Datenbank einen Eintrag für die neue VM und leitet die Anfrage zur Erstellung der Maschine an den Nova-Planer weiter.
- Der Nova-Planer wählt einen Host (Compute-Node) aus, auf dem die VM basierend auf den angegebenen Parametern, Gewichten und Zonen bereitgestellt wird. Der Eintrag hierzu sowie die Identifikation der VM werden in der Nova-Datenbank gespeichert.
- Anschließend kontaktiert nova-scheduler nova-compute mit einer Anfrage zur Bereitstellung einer Instanz. Nova-compute wendet sich an nova-conductor, um Informationen zu den Maschinenparametern zu erhalten (nova-conductor ist ein Bestandteil von nova, der als Proxy-Server zwischen nova-database und nova-compute fungiert und die Anzahl der Anfragen an die nova-database einschränkt, um Probleme mit der Konsistenz der Datenbank zu vermeiden und die Last zu reduzieren).
- Nova-conductor erhält die angeforderten Informationen aus der nova-database und leitet sie an nova-compute weiter.
- Anschließend wendet sich nova-compute an glance, um die ID des Abbilds zu erhalten. Glance validiert die Anfrage in Keystone und gibt die angeforderten Informationen zurück.
- Nova-compute kontaktiert neutron, um Informationen zu den Netzwerkparametern zu erhalten. Ähnlich wie glance validiert neutron die Anfrage in Keystone, erstellt dann einen Datensatz in der Datenbank (Port-ID usw.), generiert eine Anfrage zur Erstellung des Ports und gibt die angeforderten Informationen an nova-compute zurück.
- Nova-compute wendet sich an cinder mit der Anfrage, einem virtuellen Rechner einen Volume zuzuweisen. Ähnlich wie glance validiert cinder die Anfrage in Keystone, erstellt eine Anfrage zur Erstellung des Volumes und gibt die angeforderten Informationen zurück.
- Nova-Compute sendet eine Anfrage an libvirt zur Bereitstellung einer virtuellen Maschine mit den angegebenen Parametern.
Die Erstellung einer einfachen virtuellen Maschine scheint auf den ersten Blick eine unkomplizierte Aufgabe zu sein, verwickelt sich jedoch in ein Netz von API-Calls zwischen den verschiedenen Elementen der Cloud-Plattform. Dabei bestehen sogar die zuvor genannten Dienste aus kleineren Komponenten, die miteinander interagieren. Die Erstellung einer Maschine ist nur ein kleiner Teil dessen, was die Cloud-Plattform ermöglicht – es gibt Dienste, die für das Lastenausgleich, das Blockspeicher, DNS, das Provisioning von Bare Metal-Servern usw. verantwortlich sind. Die Cloud ermöglicht es Ihnen, Ihre virtuellen Maschinen wie eine Herde von Schafen zu behandeln (im Gegensatz zur Virtualisierung). Wenn in einer virtuellen Umgebung etwas mit einer Maschine passiert, stellen Sie sie aus Backups wieder her, während Cloud-Anwendungen so konzipiert sind, dass virtuelle Maschinen nicht die zentrale Rolle spielen – fällt eine virtuelle Maschine aus, ist das kein Problem; es wird einfach eine neue Maschine auf Basis einer Vorlage erstellt und, wie man sagt, das Team merkt nicht, dass ein Mitglied fehlt. Natürlich erfordert dies die Verfügbarkeit von Orchestrierungsmechanismen – mit Heat-Vorlagen können Sie ohne große Schwierigkeiten eine komplexe Funktion bereitstellen, die aus Dutzenden von Netzwerken und virtuellen Maschinen besteht.
Es ist wichtig, stets im Hinterkopf zu behalten, dass es keine Cloud-Infrastruktur ohne Netzwerk gibt – jedes Element interagiert auf die eine oder andere Weise mit anderen Elementen über das Netzwerk. Darüber hinaus ist das Netzwerk der Cloud alles andere als statisch. Natürlich ist das Underlay-Netzwerk mehr oder weniger statisch – neue Knoten und Switches werden nicht täglich hinzugefügt. Die Overlay-Komponente hingegen kann und wird sich unvermeidlich ständig ändern – neue Netzwerke werden hinzugefügt oder entfernt, neue virtuelle Maschinen entstehen und alte vergehen. Und wie Sie sich aus der zu Beginn des Artikels gegebenen Definition der Cloud erinnern, sollten Ressourcen automatisch und mit minimalem (oder besser: ohne) Eingreifen des Serviceanbieters dem Benutzer zugewiesen werden. Das heißt, der derzeitige Typ der Bereitstellung von Netzwerkressourcen, der in Form des Frontends Ihres persönlichen Dashboards verfügbar ist über http/https und des zuständigen Netzwerktechnikers Wladimir als Backend – das ist keine Cloud, selbst wenn Wladimir acht Arme hätte.
Neutron fungiert als Netzwerkdienst und bietet eine API zur Verwaltung der Netzwerkkomponenten der Cloud-Infrastruktur. Dieser Dienst gewährleistet die Funktionalität und Verwaltung des Netzwerkteils von OpenStack und bietet ein Abstraktionslevel, das als Network-as-a-Service (NaaS) bezeichnet wird. Das bedeutet, dass das Netzwerk eine ebenso virtuelle messbare Einheit ist wie beispielsweise virtuelle CPU-Kerne oder der RAM-Speicher.
Bevor wir uns jedoch mit der Architektur des Netzwerkteils von OpenStack befassen, betrachten wir, wie das Netzwerk in OpenStack funktioniert und warum es ein wichtiger und integraler Bestandteil der Cloud ist.
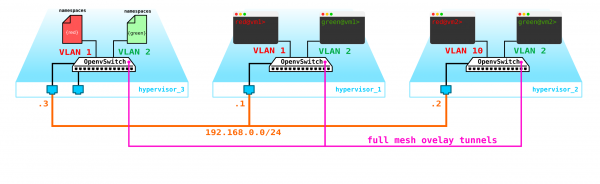
Wir haben also zwei virtuelle Maschinen des Kunden RED und zwei virtuelle Maschinen des Kunden GREEN. Angenommen, diese Maschinen sind auf zwei Hypervisoren wie folgt angeordnet:
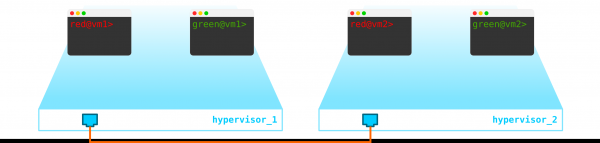
Derzeit handelt es sich lediglich um die Virtualisierung von vier Servern, und nicht mehr, da wir bisher nur die vier Server virtualisiert haben, indem wir sie auf zwei physischen Servern positioniert haben. Bislang sind sie sogar noch nicht mit dem Netzwerk verbunden.
Um eine Cloud zu erstellen, müssen wir einige Komponenten hinzufügen. Zunächst virtualisieren wir den Netzwerkbereich – wir müssen diese 4 Maschinen paarweise verbinden, wobei die Kunden speziell eine L2-Verbindung wünschen. Natürlich kann man einen Switch verwenden und darauf Trunks einrichten, und alles mit einem Linux-Bereich steuern, oder für die fortgeschritteneren Benutzer OpenvSwitch (darauf kommen wir später zurück). Aber es kann sehr viele Netzwerke geben, und ständig L2 durch einen Switch zu drücken, ist nicht die beste Idee – verschiedene Abteilungen, Servicedesk, Monate Wartezeit auf die Anfrage, Wochen Troubleshooting – in der modernen Welt funktioniert dieser Ansatz einfach nicht. Je früher das Unternehmen dies erkennt, desto leichter wird es vorankommen. Daher werden wir zwischen den Hypervisoren ein L3-Netzwerk einrichten, über das unsere virtuellen Maschinen kommunizieren, und auf diesem L3-Netzwerk werden wir virtuelle, auf L2 basierende Overlay-Netze aufbauen, in denen der Verkehr unserer virtuellen Maschinen stattfinden wird. Zur Kapselung können wir GRE, Geneve oder VxLAN verwenden. Lassen Sie uns vorerst auf Letzterem stehen bleiben, obwohl das nicht allzu wichtig ist.
Wir müssen irgendwo den VTEP platzieren (ich hoffe, jeder ist mit der VxLAN-Terminologie vertraut). Da wir direkt von den Servern ein L3-Netzwerk erhalten, steht dem nichts entgegen, den VTEP auf den Servern selbst zu platzieren, was OVS (Open vSwitch) hervorragend beherrscht. Das Ergebnis ist folgender Aufbau:
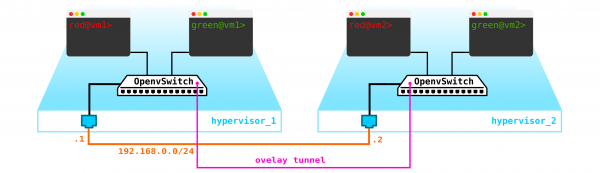
Da der Verkehr zwischen den VMs getrennt werden muss, werden die Ports in Richtung der virtuellen Maschinen verschiedene VLAN-IDs haben. Die Tag-Nummer spielt nur im Rahmen eines virtuellen Switches eine Rolle, da wir sie beim Kapseln in VxLAN problemlos entfernen können, da wir eine VNI haben.
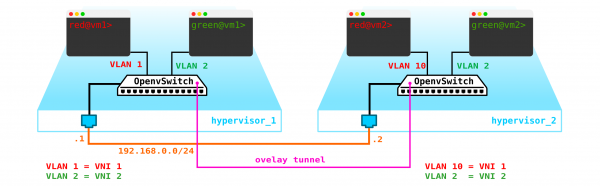
Jetzt können wir unsere Maschinen und die virtuellen Netzwerke für sie ohne Probleme erstellen.
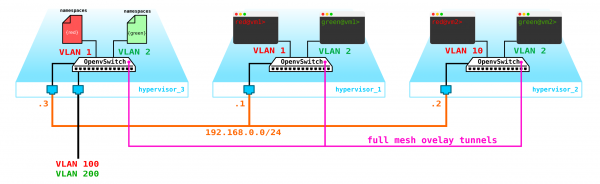
Was aber, wenn der Kunde noch eine weitere Maschine hat, die sich in einem anderen Netzwerk befindet? Wir benötigen Routing zwischen den Netzwerken. Wir werden einen einfachen Fall betrachten, in dem ein zentrales Routing verwendet wird – das heißt, der Verkehr wird über spezielle dedizierte Netzwerk-Knoten geroutet (die normalerweise mit den Kontrollknoten kombiniert sind, sodass wir das gleiche haben).
Es scheint einfach zu sein – wir erstellen ein Bridge-Interface auf der Kontrollnode, leiten den Traffic dorthin und routen ihn von dort aus weiter. Die Herausforderung besteht jedoch darin, dass der Kunde RED das Netzwerk 10.0.0.0/24 und der Kunde GREEN ebenfalls das Netzwerk 10.0.0.0/24 verwenden möchte. Das bedeutet, dass wir eine Überlappung der Adressräume haben. Darüber hinaus möchten die Kunden nicht, dass andere Kunden auf ihre internen Netzwerke zugreifen können, was verständlich ist. Um die Netzwerke und die Datentraffikte der Kunden zu trennen, werden wir für jeden von ihnen einen eigenen Namespace bereitstellen. Ein Namespace ist im Grunde eine Kopie des Linux-Netzstack, das heißt, die Kunden im Namespace RED sind vollständig von den Kunden im Namespace GREEN isoliert (es sei denn, die Routing zwischen diesen Kundennetzwerken ist über den Default-Namespace oder bereits über die übergeordnete Transportausstattung erlaubt).
Das ergibt das folgende Schema:
L2-Tunnel convergieren von allen Compute-Nodes zur Kontrollnode, wo sich das L3-Interface für diese Netzwerke befindet, jeweils in einem zugewiesenen Namespace zur Isolation.
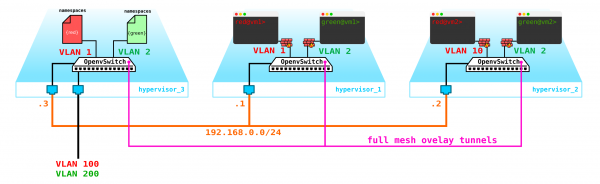
Dennoch haben wir das Wichtigste vergessen. Die virtuelle Maschine muss den Kunden einen Service bieten, das heißt, sie muss mindestens eine externe Schnittstelle haben, über die sie erreichbar ist. Wir müssen also nach außen treten. Es gibt verschiedene Optionen. Lassen Sie uns die einfachste Variante wählen. Wir fügen jedem Kunden ein Netzwerk hinzu, das im Netzwerk des Anbieters gültig ist und sich nicht mit anderen Netzwerken überschneidet. Diese Netzwerke können ebenfalls überlappen und auf verschiedene VRFs im Netzwerk des Anbieters zugreifen. Diese Netzwerke werden auch im Namespace jedes Kunden existieren. Der Zugang zur Außenwelt erfolgt aber dennoch über eine physische (oder Bonding-, was sinnvoller ist) Schnittstelle. Um den Datenverkehr der Kunden zu trennen, wird der ausgehende Verkehr mit einem VLAN-Tag gekennzeichnet, das dem Kunden zugewiesen ist.
Insgesamt haben wir folgendes Schema erhalten:
Eine berechtigte Frage – warum nicht Gateways direkt auf den Compute-Knoten einrichten? Damit haben wir keine größeren Probleme, zudem wird es mit einem verteilten Router (DVR) so funktionieren. In diesem Szenario betrachten wir die einfachste Variante mit einem zentralisierten Gateway, das in OpenStack standardmäßig verwendet wird. Für stark belastete Funktionen werden sowohl ein verteilter Router als auch Beschleunigungstechnologien wie SR-IOV und Passthrough eingesetzt, aber wie gesagt, das ist eine ganz andere Geschichte. Lassen Sie uns zunächst mit den Grundlagen beschäftigen, bevor wir in die Einzelheiten gehen.
Tatsächlich ist unser System bereits funktionsfähig, jedoch gibt es ein paar Nuancen:
- Wir müssen unsere Maschinen irgendwie schützen, das heißt, wir sollten einen Filter an den Switch-Schnittstellen zur Client-Seite anbringen.
- Es sollte möglich sein, dass die virtuelle Maschine automatisch eine IP-Adresse erhält, damit man nicht jedes Mal über die Konsole darauf zugreifen und die Adresse manuell eingeben muss.
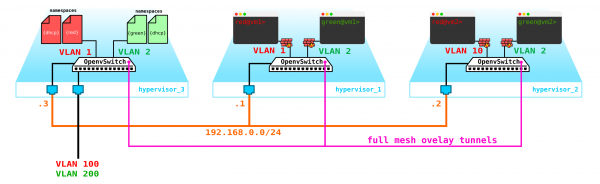
Lassen Sie uns mit dem Schutz der Maschinen beginnen. Dazu können wir einfache iptables verwenden, warum nicht?
Das heißt, unsere Topologie hat sich jetzt ein wenig kompliziert.
Gehen wir weiter. Wir müssen einen DHCP-Server hinzufügen. Der beste Standort für die DHCP-Server für jeden der Clients ist der bereits erwähnte Kontrollknoten, an dem sich die Namespaces befinden:
Es gibt jedoch ein kleines Problem. Was passiert, wenn alles neu gestartet wird und alle Informationen zur Adressmiete im DHCP verloren gehen? Es ist logisch, dass die Maschinen neue Adressen zugeteilt bekommen, was nicht besonders praktisch ist. Es gibt zwei Lösungsmöglichkeiten: Entweder verwenden wir Domainnamen und fügen für jeden Client einen DNS-Server hinzu, dann ist uns die Adresse nicht besonders wichtig (ähnlich wie bei der Netzwerkteil in k8s) — aber hier gibt es ein Problem mit externen Netzwerken, da dort Adressen auch per DHCP zugewiesen werden können — eine Synchronisation zwischen den DNS-Servern in der Cloud-Plattform und dem externen DNS-Server ist erforderlich, was meiner Meinung nach nicht besonders flexibel ist, jedoch durchaus möglich. Oder die zweite Variante — Metadaten verwenden — d.h. Informationen über die zugewiesene Maschinenadresse speichern, damit der DHCP-Server weiß, welche Adresse an die Maschine ausgegeben werden soll, wenn die Maschine bereits eine Adresse erhalten hat. Die zweite Variante ist einfacher und flexibler, da sie ermöglicht, zusätzliche Informationen über die Maschine zu speichern. Jetzt fügen wir dem Schema den Metadata-Agenten hinzu:
Ein weiterer Punkt, der ebenfalls angesprochen werden sollte, ist die Möglichkeit, ein einheitliches externes Netzwerk für alle Kunden zu nutzen. Wenn externe Netzwerke in der gesamten Infrastruktur gültig sein sollen, wird es komplex, da man ständig diese Netzwerke zuweisen und überwachen muss. Die Möglichkeit, ein gemeinsames, vorconfiguriertes externes Netzwerk für alle Kunden zu verwenden, wäre besonders vorteilhaft beim Aufbau einer öffentlichen Cloud. Das würde die Bereitstellung von Maschinen erleichtern, da wir nicht die Datenbank mit Adressen abgleichen und einen einzigartigen Adressbereich für das externe Netzwerk jedes Kunden auswählen müssten. Außerdem könnten wir das externe Netzwerk im Voraus konfigurieren und während der Bereitstellung müssten wir lediglich die externen Adressen mit den Maschinen der Kunden verknüpfen.
Hier kommt NAT ins Spiel – wir ermöglichen es unseren Kunden, über den Default-Namespace mithilfe von NAT-Übersetzung ins externe Netz zu gelangen. Allerdings gibt es hierbei ein kleines Problem. Das funktioniert gut, wenn der Server des Kunden als Client agiert und nicht als Server, also wenn er Verbindungen initiiert statt sie anzunehmen. Bei uns wird die Situation jedoch umgekehrt sein. In diesem Fall müssen wir Destination NAT (dNAT) einrichten, damit die Kontrollknoten verstehen, dass der eingehende Verkehr für die virtuelle Maschine A von Kunde A bestimmt ist. Das bedeutet, wir müssen die Übersetzung von einer externen Adresse, beispielsweise 100.1.1.1, in eine interne Adresse, zum Beispiel 10.0.0.1, vornehmen. Auf diese Weise bleibt, obwohl alle Kunden dasselbe Netzwerk verwenden, die interne Isolierung vollständig gewährleistet. Das bedeutet, dass wir auf der Kontrollknoten sowohl dNAT als auch Source NAT (sNAT) einrichten müssen. Die Verwendung eines gemeinsamen Netzwerks mit der Zuteilung von Floating IPs, externen Netzwerken oder einer Kombination aus beidem hängt davon ab, was Sie in die Cloud integrieren möchten. Wir werden keine Floating IPs in das Diagramm einfügen, sondern die bereits zuvor hinzugefügten externen Netzwerke beibehalten – jeder Kunde hat sein eigenes externes Netzwerk (im Diagramm dargestellt als VLAN 100 und 200 am externen Interface).
Am Ende haben wir eine interessante und gleichzeitig durchdachte Lösung gefunden, die eine bestimmte Flexibilität aufweist, jedoch derzeit noch über keine ausfallsicheren Mechanismen verfügt.
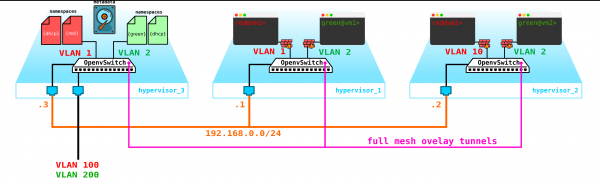
Erstens haben wir nur einen Kontrollknoten – dessen Ausfall würde zum Zusammenbruch aller Systeme führen. Um dieses Problem zu beheben, bedarf es mindestens eines Quorums von drei Knoten. Lassen Sie uns dies in das Diagramm einfügen:
Natürlich sind alle Knoten synchronisiert, und im Falle des Ausfalls eines aktiven Knotens übernimmt ein anderer Knoten dessen Aufgaben.
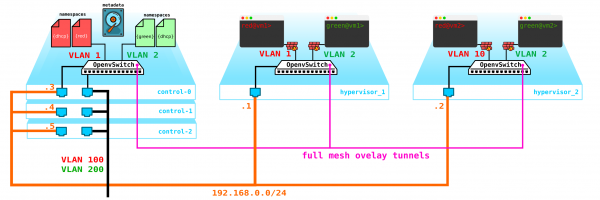
Das nächste Problem sind die Festplatten der virtuellen Maschinen. Momentan werden sie direkt auf den Hypervisoren gespeichert, und im Falle von Problemen mit dem Hypervisor verlieren wir alle Daten – und ein RAID hilft hier nicht, wenn wir nicht nur eine Festplatte, sondern den gesamten Server verlieren. Daher benötigen wir einen Dienst, der als Frontend für irgendeinen Speicher fungiert. Welcher Speicher das sein wird, spielt für uns keine große Rolle, wichtig ist nur, dass er unsere Daten vor einem Ausfall sowohl der Festplatte als auch der Node, und möglicherweise sogar des gesamten Racks, schützt. Es gibt mehrere Optionen – natürlich gibt es SAN-Netzwerke mit Fiber Channel, aber seien wir ehrlich: FC ist ein Relikt aus der Vergangenheit – das Äquivalent zu E1 im Transportbereich. Ja, ich stimme zu, dass es noch verwendet wird, aber nur dort, wo es absolut notwendig ist. Daher würde ich im Jahr 2020 nicht freiwillig ein FC-Netzwerk aufbauen, da es bereits interessantere Alternativen gibt. Aber jeder hat seine eigene Meinung, und es wird sicherlich Menschen geben, die der Meinung sind, dass FC mit all seinen Einschränkungen alles ist, was wir brauchen – ich werde nicht streiten, jeder hat seine Sichtweise. Allerdings halte ich die Verwendung von SDS, beispielsweise Ceph, für die interessanteste Lösung.
Ceph ermöglicht den Aufbau einer hochverfügbaren Speicherlösung mit zahlreichen Optionen für die Datensicherung, angefangen bei Paritätsprüfziffern (ähnlich RAID 5 oder 6) bis hin zur vollständigen Datenreplikation auf verschiedene Laufwerke unter Berücksichtigung der Anordnung der Laufwerke in den Servern und der Server in den Racks usw.
Für die Installation von Ceph sind mindestens drei Knoten erforderlich. Der Zugriff auf den Speicher erfolgt ebenfalls über das Netzwerk mithilfe von Block-, Objekt- und Dateispeicherdiensten. Lassen Sie uns den Speicher in das Schema integrieren:
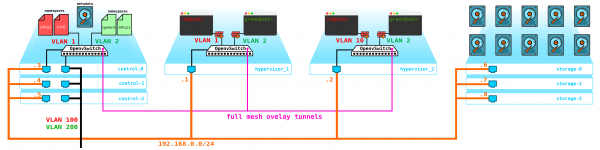
Hinweis: Hyperkonvergente Compute-Knoten sind ebenfalls möglich – dies ist ein Konzept, das mehrere Funktionen auf einem Knoten vereint, beispielsweise Storage + Compute, ohne spezielle Knoten für Ceph Storage abzutrennen. Wir erhalten ein ebenso ausfallsicheres Schema, da SDS die Daten mit dem von uns festgelegten Grad der Redundanz reserviert. Dennoch sind hyperkonvergente Knoten immer ein Kompromiss – denn der Storage-Knoten erwärmt nicht einfach die Luft, wie es auf den ersten Blick scheint (da darauf keine virtuellen Maschinen laufen) – sie verbraucht CPU-Ressourcen für die Verwaltung von SDS (tatsächlich führt sie im Hintergrund alle Replikationen, Wiederherstellungen nach Knoten- und Festplattenausfällen usw. durch). Das heißt, Sie verlieren einen Teil der Leistung des Compute-Knotens, wenn Sie ihn mit Storage kombinieren.
All diese Ressourcen müssen irgendwie verwaltet werden – wir benötigen etwas, über das wir eine Maschine, ein Netzwerk, einen virtuellen Router usw. erstellen können. Dazu fügen wir auf die Kontrollknoten einen Dienst hinzu, der die Rolle eines Dashboards übernimmt – der Kunde kann sich über http/https mit diesem Portal verbinden und fast alles tun, was er braucht.
Am Ende haben wir jetzt ein ausfallsicheres System. Alle Elemente dieser Infrastruktur müssen irgendwie verwaltet werden. Zuvor wurde beschrieben, dass OpenStack eine Sammlung von Projekten ist, von denen jedes eine bestimmte Funktion erfüllt. Wie wir sehen, gibt es mehr als genug Elemente, die konfiguriert und kontrolliert werden müssen. Heute sprechen wir über den Netzwerkbereich.
Neutron Architektur
In OpenStack ist Neutron dafür verantwortlich, Ports von virtuellen Maschinen mit dem gemeinsamen L2-Netzwerk zu verbinden, den Datenverkehr zwischen VMs in unterschiedlichen L2-Netzwerken zu routen sowie nach außen zu routen und Dienste wie NAT, Floating IP, DHCP usw. bereitzustellen.
Die hochgradige Funktionsweise des Netzwerksdienstes (Basisfunktion) lässt sich so beschreiben.
Beim Starten einer VM führt der Netzwerkdienst folgende Schritte aus:
- Er erstellt einen Port für diese VM (oder Ports) und benachrichtigt den DHCP-Dienst darüber;
- Ein neues virtuelles Netzwerkgerät wird erstellt (über libvirt);
- Die VM wird mit dem im ersten Schritt erstellten Port (Ports) verbunden;
Merkwürdigerweise basieren die grundlegenden Funktionen von Neutron auf standardmäßigen Mechanismen, die allen bekannt sein sollten, die jemals in Linux eingetaucht sind – das sind Namespaces, iptables, Linux-Brücken, openvswitch, conntrack usw.
Es sollte sofort klargestellt werden, dass Neutron kein SDN-Controller ist.
Neutron besteht aus mehreren miteinander verbundenen Komponenten:
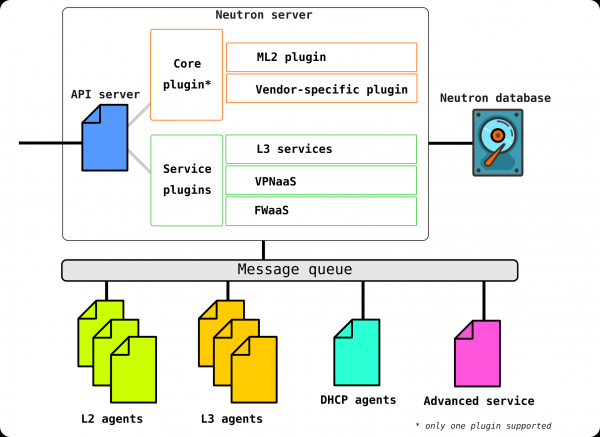
Openstack-neutron-server — ist ein Daemon, der über die API mit den Benutzeranfragen arbeitet. Dieser Daemon kümmert sich nicht um die Erstellung von Netzverbindungen, sondern liefert die notwendigen Informationen an seine Plugins, die dann das gewünschte Netzwerkelement konfigurieren. Neutron-Agenten auf den OpenStack-Knoten registrieren sich beim Neutron-Server.
Neutron-server ist tatsächlich eine Anwendung, die in Python geschrieben ist und aus zwei Teilen besteht:
- REST-Service
- Neutron-Plugin (core/service)
Der REST-Service dient der Entgegennahme von API-Aufrufen von anderen Komponenten (zum Beispiel Anfragen zur Bereitstellung von Informationen usw.).
Plugins sind anschlussfähige Softwarekomponenten/Module, die bei API-Anfragen aufgerufen werden – das heißt, die Zuordnung eines bestimmten Dienstes erfolgt über sie. Plugins werden in zwei Typen unterteilt – Dienst- und Kern-Plugins. In der Regel ist das Kern-Plugin hauptsächlich für die Verwaltung des Adressraums und der L2-Verbindungen zwischen VMs verantwortlich, während die Dienst-Plugins zusätzliche Funktionen wie VPN oder FW bereitstellen.
Eine Liste der heute verfügbaren Plugins kann beispielsweise eingesehen werden.
Es kann mehrere Service-Plugins geben, jedoch kann es nur ein Core-Plugin geben.
Openstack-neutron-ml2 — ist das Standard-Core-Plugin von OpenStack. Dieses Plugin hat eine modulare Architektur (im Gegensatz zu seinem Vorgänger) und konfiguriert den Netzwerkdienst über anpassbare Treiber. Wir werden das Plugin später näher betrachten, da es tatsächlich die Flexibilität bietet, die OpenStack im Netzwerkbereich auszeichnet. Das Core-Plugin kann ersetzt werden (zum Beispiel durch Contrail Networking).
RPC-Service (rabbitmq-server) — ein Dienst, der das Management von Warteschlangen und die Interaktion mit anderen OpenStack-Diensten sowie die Kommunikation zwischen Netzwerkdienst-Agenten ermöglicht.
Netzwerkagenten — Agenten, die auf jedem Knoten platziert sind und über die die Konfiguration der Netzwerkdienste erfolgt.
Es gibt mehrere Arten von Agenten.
Der Hauptagent ist der L2-Agent. Diese Agenten werden auf jedem Hypervisor, einschließlich der Kontrollknoten (genauer gesagt, auf allen Knoten, die irgendeinen Dienst für die Mandanten bereitstellen), gestartet. Ihre Hauptfunktion besteht darin, virtuelle Maschinen mit dem gemeinsamen L2-Netzwerk zu verbinden und Benachrichtigungen bei Ereignissen (zum Beispiel beim Ein- oder Ausschalten eines Ports) zu generieren.
Ein weiterer, nicht weniger wichtiger Agent ist der L3-Agent. Standardmäßig wird dieser Agent ausschließlich auf dem Netzwerk-Knoten (häufig wird der Netzwerk-Knoten mit dem Kontrollknoten kombiniert) gestartet und sorgt für die Routing-Funktionalität zwischen den Netzwerken der Mandanten (sowohl zwischen deren eigenen Netzwerken als auch zu den Netzwerken anderer Mandanten) und ermöglicht den Zugang zur Außenwelt, indem er NAT und einen DHCP-Dienst bereitstellt. Bei Verwendung eines DVR (Distributed Virtual Router) wird jedoch auch auf den Compute-Knoten die Notwendigkeit eines L3-Plugins laut.
Der L3-Agent verwendet Linux-Namespace, um jedem Mandanten einen Satz isolierter Netzwerke und die Funktionalität virtueller Router bereitzustellen, die den Datenverkehr routen und Gateway-Dienste für Layer-2-Netzwerke anbieten.
Datenbank — eine Datenbank von Netzwerk-IDs, Subnetzen, Ports, Pools usw.
Neutron empfängt API-Anfragen zur Erstellung von Netzwerkentitäten, authentifiziert diese Anfragen und überträgt über RPC (wenn ein Plugin oder Agent angesprochen wird) oder REST API (wenn in SDN kommuniziert wird) Anweisungen an die Agents (über Plugins), die für die Bereitstellung des angeforderten Dienstes erforderlich sind.
Jetzt betrachten wir die Testinstallation (wie sie bereitgestellt ist und was sie enthält, werden wir später im praktischen Teil sehen) und schauen uns an, wo sich welche Komponente befindet:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 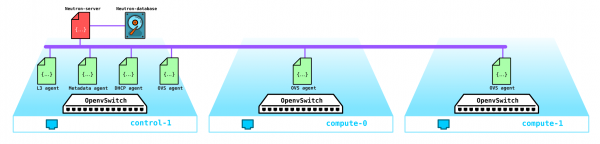
Das ist also die gesamte Struktur von Neutron. Jetzt sollten wir etwas Zeit dem ML2-Plugin widmen.
Modular Layer 2
Wie bereits erwähnt, ist das Plugin ein standardmäßiges OpenStack-Root-Plugin und verfügt über eine modulare Architektur.
Der Vorgänger des ML2-Plugins hatte eine monolithische Struktur, die es beispielsweise nicht ermöglichte, eine Mischung aus mehreren Technologien in einer Installation zu verwenden. Man konnte beispielsweise openvswitch und linuxbridge nicht gleichzeitig verwenden – entweder das eine oder das andere. Aus diesem Grund wurde das ML2-Plugin mit seiner Architektur entwickelt.
ML2 besteht aus zwei Komponenten – zwei Arten von Treibern: Type Drivers und Mechanism Drivers.
Type Drivers definieren die Technologien, die zur Einrichtung von Netzwerkverbindungen verwendet werden, wie VxLAN, VLAN und GRE. Der Treiber ermöglicht die Verwendung unterschiedlicher Technologien. Die Standardtechnologie ist die VxLAN-Kapselung für Overlay-Netze und VLANs für externe Netze.
Zu den Type Drivers gehören folgende Netzwerktypen:
Flat – ein Netzwerk ohne Tagging
VLAN – ein getaggtes Netzwerk
Lokal – ein spezieller Netzwerktyp für All-in-One-Installationen (solche Installationen sind entweder für Entwickler oder für Schulungszwecke notwendig)
GRE – ein Overlay-Netz, das GRE-Tunnel verwendet
VxLAN – ein Overlay-Netz, das VxLAN-Tunnel verwendet
Mechanism Drivers definiert die Mittel, die die Organisation der im Typdriver angegebenen Technologien bereitstellen – beispielsweise Open vSwitch, SR-IOV, OpenDaylight, OVN usw.
Je nach Implementierung dieses Drivers werden entweder von Neutron verwaltete Agenten verwendet oder Verbindungen zu einem externen SDN-Controller hergestellt, der alle Fragen zur Organisation von L2-Netzwerken, Routing usw. übernimmt.
Ein Beispiel: Wenn wir ML2 zusammen mit OVS verwenden, wird auf jedem Compute-Knoten ein L2-Agent installiert, der OVS verwaltet. Wenn wir jedoch beispielsweise OVN oder OpenDaylight verwenden, fällt die Verwaltung von OVS unter deren Jurisdiktion – Neutron gibt über das Root-Plugin Befehle an den Controller, der dann tut, was ihm gesagt wurde.
Erinnern wir uns an Open vSwitch
Derzeit ist Open vSwitch einer der Schlüsselfunktionen von OpenStack.
Bei der Installation von OpenStack ohne zusätzliche vendor-spezifische SDN-Lösungen wie Juniper Contrail oder Nokia Nuage ist OVS die Hauptkomponente des cloudbasierten Netzwerks. Zusammen mit iptables, conntrack und Namespaces ermöglicht es die Einrichtung vollständiger Overlay-Netzwerke mit Multi-Tenancy. Natürlich kann diese Komponente ersetzt werden, zum Beispiel durch die Verwendung von externen proprietären SDN-Lösungen.
OVS ist ein Open-Source-Software-Switch, der für den Einsatz in virtualisierten Umgebungen als virtueller Datenverkehrs-Vorwärts-Mechanismus konzipiert ist.
Derzeit bietet OVS eine beeindruckende Funktionalität, die Technologien wie QoS, LACP, VLAN, VxLAN, GENEVE, OpenFlow, DPDK usw. umfasst.
Hinweis: OVS wurde ursprünglich nicht als Software-Switch für leistungsstarke Telekommunikationsfunktionen gedacht und war mehr auf weniger bandbreitenintensive IT-Funktionen wie Web- oder Mailserver ausgelegt. Dennoch wird OVS kontinuierlich weiterentwickelt, und die aktuellen Implementierungen von OVS haben seine Leistung und Fähigkeiten erheblich verbessert, sodass es von Kommunikationsanbietern für hochbelastete Funktionen eingesetzt werden kann, beispielsweise gibt es eine OVS-Implementierung mit DPDK-Beschleunigung.
Es gibt drei wichtige Komponenten von OVS, die man kennen sollte:
- Kernelmodul — eine Komponente, die im Kernel-Space angesiedelt ist und den Datenverkehr basierend auf den vom Steuerungselement empfangenen Regeln verarbeitet;
- vSwitch Daemon (ovs-vswitchd) — dieser Prozess läuft im User-Space und ist verantwortlich für die Programmierung des Kernelmoduls — er stellt also direkt die Logik des Switches dar.
- Datenbankserver — eine lokale Datenbank, die sich auf jedem Host befindet, auf dem OVS läuft, und in der die Konfiguration gespeichert ist. Über dieses Modul können SDN-Controller über das OVSDB-Protokoll kommunizieren.
Außerdem gehört eine Reihe von Diagnose- und Verwaltungstools dazu, wie ovs-vsctl, ovs-appctl, ovs-ofctl usw.
Derzeit wird OpenStack von Telekommunikationsanbietern weit verbreitet genutzt, um Netzfunktionalitäten wie EPC, SBC, HLR usw. zu migrieren. Einige Funktionen können problemlos mit OVS in der aktuellen Form arbeiten, jedoch verarbeitet das EPC beispielsweise den Verkehr der Abonnenten – das heißt, es leitet eine enorme Menge an Daten (aktuell erreichen die Verkehrsvolumina mehrere Hundert Gigabit pro Sekunde). Es ist offensichtlich, dass solch ein Datenverkehr nicht durch den Kernel-Space geleitet werden sollte (da der Forwarder standardmäßig dort angesiedelt ist) – das ist nicht die beste Idee. Deshalb wird OVS oft vollständig im User-Space mit wykorzystaniem der DPDK-Technologie implementiert, um den Verkehr von der NIC in den User-Space zu leiten, ohne den Kernel zu durchlaufen.
Hinweis: Für die Cloud, die für Telekom-Funktionen bereitgestellt wird, besteht die Möglichkeit, den Verkehr von der Compute-Node direkt in die Netzwerkhardware zu leiten, ohne OVS zu verwenden. Hierfür kommen die Mechanismen SR-IOV und Passthrough zum Einsatz.
Wie funktioniert das in einem realen Modell?
Nun kommen wir zum praktischen Teil und sehen uns an, wie das alles in der Praxis funktioniert.
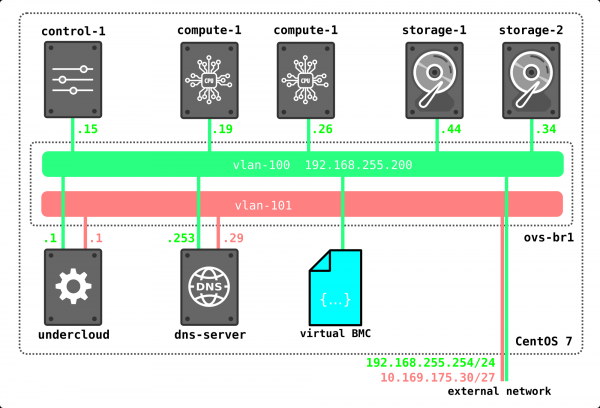
Zunächst werden wir eine einfache OpenStack-Installation aufsetzen. Da ich für Experimente keine Server zur Verfügung habe, werden wir das Setup auf einem physischen Server mit virtuellen Maschinen erstellen. Natürlich ist diese Lösung für kommerzielle Zwecke nicht geeignet, aber um zu demonstrieren, wie das Netzwerk in OpenStack funktioniert, genügt diese Installation vollkommen. Zudem ist diese Art der Installation für Lernzwecke sogar interessanter, da man den Datenverkehr gezielt analysieren kann.
Da wir nur den grundlegenden Teil sehen möchten, können wir auf mehrere Netzwerke verzichten und alles mit nur zwei Netzwerken einrichten. Das zweite Netzwerk in diesem Setup wird ausschließlich für den Zugang zum Undercloud und zum DNS-Server verwendet. Externe Netzwerke werden wir vorerst nicht berücksichtigen – das ist ein Thema für einen separaten, umfangreichen Artikel.
Fangen wir der Reihe nach an. Zuerst ein wenig Theorie. Wir installieren OpenStack mithilfe von TripleO (OpenStack on OpenStack). Das Konzept hinter TripleO ist, dass wir OpenStack all-in-one (das heißt auf einer Node), bezeichnet als Undercloud, installieren, und dann die Möglichkeiten des implementierten OpenStack nutzen, um die produktionsbereite Version von OpenStack, genannt Overcloud, zu installieren. Undercloud wird die integrierte Möglichkeit verwenden, physische Server (Bare Metal) zu verwalten – das Projekt Ironic – um Hypervisoren bereitzustellen, die die Rollen von Compute-, Control- und Storage-Nodes übernehmen. Das bedeutet, wir verwenden keine externen Werkzeuge zur Bereitstellung von OpenStack – wir setzen OpenStack mit den Mitteln von OpenStack selbst um. Im Verlauf der Installation wird vieles klarer werden, daher halten wir hier nicht an und machen weiter.
Hinweis: In diesem Artikel habe ich zur Vereinfachung keine netzwerktechnische Isolierung für interne OpenStack-Netzwerke verwendet, sondern alles über ein einziges Netzwerk bereitgestellt. Die vorhandene oder fehlende Netzwerkinisolierung beeinflusst jedoch nicht die grundlegende Funktionalität der Lösung – alles funktioniert genau so, als würde Isolierung genutzt werden, aber der Datenverkehr wird innerhalb eines Netzwerks abgewickelt. Für eine kommerzielle Installation ist es natürlich erforderlich, Isolierung durch verschiedene VLANs und Schnittstellen zu verwenden. Zum Beispiel verwenden der Verwaltungsverkehr für das Ceph-Storage und der tatsächliche Datenverkehr (Zugriffe von Maschinen auf Datenträger usw.) bei Isolierung unterschiedliche Subnetze (Storage-Management und Storage), was die Lösung fehlertoleranter macht, indem dieser Verkehr beispielsweise über verschiedene Ports geleitet wird oder unterschiedliche QoS-Profile für verschiedene Verkehrsarten verwendet werden, um sicherzustellen, dass der Datenverkehr die Signalisierung nicht verdrängt. In unserem Fall wird der gesamte Verkehr jedoch im selben Netzwerk ablaufen, was uns nicht einschränkt.
Hinweis: Da wir virtuelle Maschinen in einer virtuellen Umgebung, die auf virtuellen Maschinen basiert, starten möchten, müssen wir zuerst die verschachtelte Virtualisierung aktivieren.
So überprüfen Sie, ob die verschachtelte Virtualisierung aktiviert ist oder nicht:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#Wenn Sie das Zeichen N sehen, aktivieren Sie die Unterstützung für die verschachtelte Virtualisierung gemäß einer Anleitung, die Sie im Internet finden, zum Beispiel .
Wir müssen ein solches Schema aus virtuellen Maschinen erstellen:
In meinem Fall habe ich OpenvSwitch verwendet, um die Konnektivität der virtuellen Maschinen sicherzustellen, die Teil der zukünftigen Installation sind (ich habe 7 Stück, aber man kann auch mit 4 auskommen, wenn Sie nicht viele Ressourcen haben). Ich habe einen OVS-Bridge erstellt und die virtuellen Maschinen über Port-Gruppen angeschlossen. Dazu habe ich eine XML-Datei im folgenden Format erstellt:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
ovs-network-1
7a2e7de7-fc16-4e00-b1ed-4d190133af67Hier sind drei Portgruppen definiert – zwei zugehörige Zugangsgruppen und eine trunk (letztere wird für den DNS-Server benötigt, kann aber auch weggelassen oder auf dem Host-System eingerichtet werden – ganz nach Ihrem Belieben). Anschließend definieren wir unser Netzwerk mithilfe dieser Vorlage über virsh net-define:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 Jetzt passen wir die Konfigurationen der Hypervisor-Ports an:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# Hinweis: In diesem Szenario wird die Adresse am Port ovs-br1 nicht verfügbar sein, da sie kein VLAN-Tag hat. Um dies zu beheben, geben Sie den Befehl sudo ovs-vsctl set port ovs-br1 tag=100 ein. Allerdings wird dieses Tag nach einem Neustart verschwinden (ich wäre Ihnen sehr dankbar, wenn jemand wüsste, wie man es beibehalten kann). Aber das ist nicht so wichtig, da wir diese Adresse nur während der Installation benötigen und sie nicht mehr benötigt wird, wenn OpenStack vollständig eingerichtet ist.
Als Nächstes erstellen wir die Undercloud-Maschine:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0Während der Installation geben Sie alle erforderlichen Parameter wie den Namen der Maschine, Passwörter, Benutzer, NTP-Server usw. ein. Sie können auch die Ports sofort konfigurieren, aber persönlich finde ich es einfacher, nach der Installation über die Konsole in die Maschine zu gehen und die benötigten Dateien anzupassen. Wenn Sie bereits ein fertiges Image haben, können Sie dieses verwenden oder wie ich vorgehen — das minimalistische CentOS 7-Image herunterladen und zur Installation der VM verwenden.
Nach der erfolgreichen Installation sollte Ihnen eine virtuelle Maschine zur Verfügung stehen, auf die Sie untercloud installieren können.
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud runningZuerst installieren wir die erforderlichen Werkzeuge für die Installation:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
Installation von Undercloud
Wir erstellen den Benutzer stack, setzen ein Passwort, fügen ihn zu sudoer hinzu und ermöglichen ihm, Root-Befehle über sudo ohne Eingabe eines Passworts auszuführen:
useradd stack
passwd stack
echo "stack ALL=(root) NOPASSWD:ALL" > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stackJetzt geben wir im Hosts-Datei den vollständigen Namen untercloud an:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6Als nächstes fügen wir die Repositories hinzu und installieren die benötigte Software:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansibleHinweis: Wenn Sie Ceph nicht installieren möchten, müssen Sie keine Befehle zu Ceph eingeben. Ich habe die Version Queens verwendet, aber Sie können jede andere Version verwenden, die Ihnen gefällt.
Als nächstes kopieren wir die Konfigurationsdatei undercloud in das Home-Verzeichnis des Benutzers stack:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.confJetzt müssen wir diese Datei an unsere Installation anpassen.
Fügen Sie am Anfang der Datei die folgenden Zeilen hinzu:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10Lassen Sie uns die Einstellungen durchgehen:
undercloud_hostname — der vollständige Name des undercloud-Servers, sollte mit dem DNS-Eintrag übereinstimmen
local_ip — die lokale Adresse des undercloud in Richtung des Bereitstellungsnetzwerks
network_gateway — dieselbe lokale Adresse, die während der Installation der Overcloud-Knoten als Gateway für den Zugriff auf die Außenwelt fungiert, stimmt ebenfalls mit der lokalen IP überein
undercloud_public_host — Adresse der externen API, es kann jede verfügbare Adresse aus dem Provisioning-Netzwerk zugewiesen werden
undercloud_admin_host Adresse der internen API, es kann jede verfügbare Adresse aus dem Provisioning-Netzwerk zugewiesen werden
undercloud_nameservers — DNS-Server
generate_service_certificate — Diese Zeile ist in diesem Beispiel sehr wichtig, da Sie ohne die Einstellung auf false beim Installieren einen Fehler erhalten werden, das Problem ist im Bugtracker von Red Hat beschrieben
local_interface Schnittstelle im Provisioning-Netzwerk. Diese Schnittstelle wird während der Bereitstellung von undercloud neu konfiguriert, daher sind zwei Schnittstellen für undercloud erforderlich — eine für den Zugriff darauf, die andere für das Provisioning
local_mtu — MTU. Da wir ein Testlabor haben und die MTU an meinen OVS-Switch-Ports 1500 beträgt, muss sie auf 1450 eingestellt werden, damit VxLAN-kapsulierte Pakete passieren können
network_cidr — Provisioning-Netzwerk
masquerade — Verwendung von NAT für den Zugriff auf das externe Netzwerk
masquerade_network — Netzwerk, das NAT wird
dhcp_start — Startadresse des Adresspools, aus dem während des Deployments von overcloud Adressen an die Knoten zugewiesen werden
dhcp_end — Endadresse des Adresspools, aus dem während des Deployments von overcloud Adressen an die Knoten zugewiesen werden
inspection_iprange — Pool von Adressen, die für die Inspektion benötigt werden (sollte nicht mit dem oben genannten Pool überlappen)
scheduler_max_attempts — maximale Anzahl an Versuchen zur Einrichtung des Overcloud (sollte größer oder gleich der Anzahl der Nodes sein)
Nachdem die Datei beschrieben wurde, können Sie den Befehl zur Bereitstellung von Undercloud geben:
openstack undercloud install
Der Vorgang dauert je nach Ihrer Hardware zwischen 10 und 30 Minuten. Am Ende sollten Sie folgende Ausgabe sehen:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Installation von Undercloud abgeschlossen.
Die Datei mit den Passwörtern dieser Installation befindet sich unter
/home/stack/undercloud-passwords.conf.
Es gibt auch eine stackrc-Datei unter /home/stack/stackrc.
Diese Dateien sind erforderlich, um mit den OpenStack-Diensten zu interagieren, und sollten
sicher aufbewahrt werden.
#############################################################################Diese Ausgabe zeigt, dass Sie Undercloud erfolgreich installiert haben und jetzt den Status von Undercloud überprüfen und mit der Installation von Overcloud fortfahren können.
Wenn Sie die Ausgabe von ifconfig betrachten, werden Sie sehen, dass ein neuer Bridge-Interface hinzugefügt wurde.
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163 mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Über diese Schnittstelle wird nun die Bereitstellung des Overcloud durchgeführt.
Aus der folgenden Ausgabe geht hervor, dass alle Dienste auf einem Knoten laufen:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+Unten sehen Sie die Konfiguration des Netzwerkbereichs des Undercloud:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Installation von overcloud
Aktuell haben wir nur die undercloud, und uns fehlen die Knoten, aus denen die overcloud aufgebaut werden soll. Daher werden wir zunächst die benötigten virtuellen Maschinen bereitstellen. Während des Deployments installiert die undercloud das Betriebssystem und die erforderliche Software auf den overcloud-Maschinen – das bedeutet, wir müssen die Maschine nicht vollständig aufbauen, sondern lediglich eine Festplatte (oder mehrere Festplatten) erstellen und ihre Parameter definieren – wir erhalten also letztendlich einen nackten Server ohne installiertes Betriebssystem.
Wir wechseln in den Ordner mit den Festplatten unserer virtuellen Maschinen und erstellen die Festplatten mit dem benötigten Volumen:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160GDa wir als root agieren, müssen wir den Besitzer dieser Festplatten ändern, um keine Probleme mit den Berechtigungen zu bekommen:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# Hinweis: Wenn Sie Ceph nicht zu Lernzwecken installieren möchten, erstellen Sie bitte mindestens 3 Knoten mit jeweils mindestens zwei Datenträgern. Geben Sie im Template an, dass virtuelle Datenträger wie vda, vdb usw. verwendet werden.
Prima, jetzt müssen wir all diese Maschinen definieren:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml Am Ende finden sich die Befehle —print-xml > /tmp/storage-1.xml, die eine XML-Datei mit der Beschreibung jeder Maschine im Ordner /tmp/ erstellt. Wenn Sie dies nicht hinzufügen, können Sie die virtuellen Maschinen nicht identifizieren.
Jetzt müssen wir all diese Maschinen in virsh registrieren:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name Status
----------------------------------------------------
6 dns-server läuft
64 undercloud läuft
- compute-1 aus
- compute-2 aus
- control-1 aus
- storage-1 aus
- storage-2 aus
[root@hp-gen9 ~]#Ein kleiner Hinweis — tripleO nutzt IPMI, um die Server während der Installation und Introspektion zu verwalten.
Die Introspektion ist der Prozess der Überprüfung der Hardware, um die notwendigen Parameter für die weitere Provisionierung der Knoten zu erhalten. Die Introspektion erfolgt mithilfe von ironic — einem Dienst, der für die Arbeit mit Bare-Metal-Servern konzipiert ist.
Hier liegt jedoch das Problem – während physische Server über einen separaten IPMI-Port (oder einen gemeinsamen Port, was nicht entscheidend ist) verfügen, haben virtuelle Maschinen solche Ports nicht. Hier kommt uns ein Trick namens vbmc zur Hilfe – ein Tool, das es ermöglicht, einen IPMI-Port zu emulieren. Diese Besonderheit sollte besonders von denen beachtet werden, die ein solches Labor auf einem ESXi-Hypervisor aufbauen möchten – ich weiß allerdings nicht, ob es dort ein Pendant zu vbmc gibt, daher sollte man sich mit dieser Frage beschäftigen, bevor man alles aufsetzt.
Installation von vbmc:
yum install python2-virtualbmcFalls Ihr Betriebssystem das Paket nicht finden kann, fügen Sie das Repository hinzu:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpmJetzt konfigurieren wir das Tool. Hier ist alles äußerst einfach. Es ist nun logisch, dass in der Liste von vbmc keine Server angezeigt werden.
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# Um sie erscheinen zu lassen, müssen sie manuell wie folgt deklariert werden:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domainname | Status | Adresse | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#Ich denke, die Syntax des Befehls ist auch ohne Erklärung klar. Aber bisher sind alle unsere Sessions im Status DOWN. Damit sie in den Status UP wechseln, müssen sie eingeschaltet werden:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] vBMC-Instanz für die Domäne control-1 gestartet
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] vBMC-Instanz für die Domäne storage-1 gestartet
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] vBMC-Instanz für die Domäne storage-2 gestartet
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] vBMC-Instanz für die Domäne compute-1 gestartet
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] vBMC-Instanz für die Domäne compute-2 gestartet
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#Und zum Schluss — die Firewall-Regeln müssen angepasst werden (oder sie gleich ganz deaktiviert werden):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
Jetzt loggen wir uns in die Undercloud ein und überprüfen, ob alles funktioniert. Die Adresse der Host-Maschine ist 192.168.255.200, und während der Vorbereitung für das Deployment haben wir das benötigte Paket ipmitool hinzugefügt:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power ist aus
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Hoch/Ein
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name Status
----------------------------------------------------
6 dns-server läuft
64 undercloud läuft
65 control-1 läuftWie Sie sehen können, haben wir den Control-Knoten erfolgreich über vbmc gestartet. Jetzt schalten wir ihn aus und fahren fort:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Runter/Aus
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power ist aus
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name Status
----------------------------------------------------
6 dns-server läuft
64 undercloud läuft
- compute-1 ist aus
- compute-2 ist aus
- control-1 ist aus
- storage-1 ist aus
- storage-2 ist aus
[root@hp-gen9 ~]#Der nächste Schritt ist die Introspektion der Knoten, auf denen das Overcloud installiert werden soll. Dazu müssen wir eine JSON-Datei mit der Beschreibung unserer Knoten vorbereiten. Beachten Sie, dass im Vergleich zur Installation auf nackten Servern in der Datei der Port angegeben ist, auf dem vbmc für jede der Maschinen läuft.
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
- Netzwerk ovs-network-1 virtio 52:54:00:20:a2:2f
- Netzwerk ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
- Netzwerk ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
- Netzwerk ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
- Netzwerk ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
- Netzwerk ovs-network-1 virtio 52:54:00:a7:fe:27Hinweis: An der Steuerknoten befinden sich zwei Schnittstellen, aber in diesem Fall ist das nicht wichtig; für diese Installation reicht uns eine einzige Schnittstelle.
Jetzt bereiten wir die JSON-Datei vor. Wir müssen die MAC-Adresse des Ports angeben, über den das Provisioning erfolgen wird, die Knotenparameter festlegen, ihnen Namen geben und angeben, wie man auf IPMI zugreift:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}Jetzt müssen wir die Images für ironic vorbereiten. Dazu laden wir sie mit wget herunter und installieren sie:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$Laden der Images in undercloud:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Das Image "overcloud-full-vmlinuz" wurde hochgeladen.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk-Format | Größe | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | aktiv |
+--------------------------------------+------------------------+-------------+---------+--------+
Das Image "overcloud-full-initrd" wurde hochgeladen.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk-Format | Größe | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | aktiv |
+--------------------------------------+-----------------------+-------------+----------+--------+
Das Image "overcloud-full" wurde hochgeladen.
+--------------------------------------+-----------------+-------------+------------+--------+
| ID | Name | Disk-Format | Größe | Status |
+--------------------------------------+-----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | aktiv |
+--------------------------------------+-----------------+-------------+------------+--------+
Das Image "bm-deploy-kernel" wurde hochgeladen.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk-Format | Größe | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | aktiv |
+--------------------------------------+------------------+-------------+---------+--------+
Das Image "bm-deploy-ramdisk" wurde hochgeladen.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk-Format | Größe | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | aktiv |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$Wir überprüfen, ob alle Images erfolgreich geladen wurden.
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aktiv |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | aktiv |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | aktiv |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | aktiv |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aktiv |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$Ein weiterer Schritt – einen DNS-Server hinzufügen:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Feld | Wert |
+-------------------+-----------------------------------------------------------+
| Zuweisungspools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| erstellt_am | 2020-08-13T20:10:37Z |
| Beschreibung | |
| dns_nameserver | |
| dhcp_aktivieren | Wahr |
| gateway_ip | 192.168.255.1 |
| host_routes | ziel='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_adress_modus | Keine |
| ipv6_ra_modus | Keine |
| name | ctlplane-subnet |
| netzwerk_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | Keine |
| projekt_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revisionsnummer | 0 |
| segment_id | Keine |
| diensttypen | |
| subnetpool_id | Keine |
| tags | |
| aktualisiert_am | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI ist veraltet und wird in Zukunft entfernt. Verwenden Sie stattdessen openstack CLI.
Aktualisiertes Subnetz: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$Jetzt können wir den Befehl zur Introspektion erteilen:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Workflow von Mistral gestartet: tripleo.baremetal.v1.register_or_update. Ausführungs-ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Warten auf Nachrichten in der Warteschlange 'tripleo' ohne Zeitüberschreitung.
5 Knoten erfolgreich in den "verwaltbaren" Zustand verschoben.
Knoten mit UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 erfolgreich registriert
Knoten mit UUID b89a72a3-6bb7-429a-93bc-48393d225838 erfolgreich registriert
Knoten mit UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e erfolgreich registriert
Knoten mit UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 erfolgreich registriert
Knoten mit UUID 766ab623-464c-423d-a529-d9afb69d1167 erfolgreich registriert
Warten auf das Ende der Introspektion...
Workflow von Mistral gestartet: tripleo.baremetal.v1.introspect. Ausführungs-ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Warten auf Nachrichten in der Warteschlange 'tripleo' ohne Zeitüberschreitung.
Introspektion des Knotens b89a72a3-6bb7-429a-93bc-48393d225838 abgeschlossen. Status: ERFOLG. Fehler: Keine
Introspektion des Knotens 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e abgeschlossen. Status: ERFOLG. Fehler: Keine
Introspektion des Knotens bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 abgeschlossen. Status: ERFOLG. Fehler: Keine
Introspektion des Knotens 766ab623-464c-423d-a529-d9afb69d1167 abgeschlossen. Status: ERFOLG. Fehler: Keine
Introspektion des Knotens b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 abgeschlossen. Status: ERFOLG. Fehler: Keine
5 Knoten erfolgreich introspektiert.
Workflow von Mistral gestartet: tripleo.baremetal.v1.provide. Ausführungs-ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Warten auf Nachrichten in der Warteschlange 'tripleo' ohne Zeitüberschreitung.
5 Knoten erfolgreich in den "verfügbaren" Zustand verschoben.
(undercloud) [stack@undercloud ~]$Wie aus der Ausgabe hervorgeht, lief alles ohne Fehler ab. Lassen Sie uns überprüfen, ob alle Knoten im Zustand verfügbar sind:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ Sollten sich die Knoten in einem anderen Zustand befinden, z.B. verwaltbar, ist etwas schief gelaufen und Sie müssen die Protokolle überprüfen, um herauszufinden, warum das passiert ist. Bitte beachten Sie, dass wir in diesem Szenario Virtualisierung verwenden und es möglicherweise Fehler im Zusammenhang mit der Nutzung virtueller Maschinen oder vbmc gibt.
Als nächstes müssen wir angeben, welche Funktion jeder Knoten ausführen soll – das heißt, welches Profil der Knoten für die Bereitstellung erhalten wird:
(untercloud) [stack@untercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Bereitstellungsstatus | Aktuelles Profil | Mögliche Profile |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | verfügbar | Keine | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | verfügbar | Keine | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | verfügbar | Keine | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | verfügbar | Keine | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | verfügbar | Keine | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(untercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Ist Öffentlich |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | Wahr |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | Wahr |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | Wahr |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | Wahr |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | Wahr |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | Wahr |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(untercloud) [stack@untercloud ~]$Wir geben das Profil für jede Knotenstelle an:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167Wir überprüfen, ob alles korrekt gemacht wurde:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | verfügbar | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | verfügbar | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | verfügbar | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | verfügbar | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | verfügbar | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$Wenn alles korrekt ist, geben wir den Befehl zum Deployment des Overclouds:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemuBei einer realen Installation werden natürlich angepasste Vorlagen verwendet, was in unserem Fall den Prozess erheblich komplizieren würde, da jede Anpassung im Template erklärt werden müsste. Wie bereits erwähnt — eine einfache Installation reicht aus, um zu sehen, wie es funktioniert.
Hinweis: Die Variable —libvirt-type qemu ist in diesem Fall notwendig, da wir nested Virtualisierung verwenden werden. Andernfalls lassen sich keine virtuellen Maschinen starten.
Jetzt haben Sie etwa eine Stunde, vielleicht auch mehr (abhängig von der Hardware), und Sie können nur hoffen, dass Sie nach Ablauf dieser Zeit folgende Nachricht sehen:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE erfolgreich abgeschlossen
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 nicht in /home/stack/.ssh/known_hosts gefunden
Mistral Workflow tripleo.deployment.v1.get_horizon_url gestartet. Ausführungs-ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard-URL: http://192.168.255.21:80/dashboard
Overcloud rc-Datei: /home/stack/overcloudrc
Overcloud bereitgestellt
(undercloud) [stack@undercloud ~]$Jetzt haben Sie eine fast vollständige Version von OpenStack, auf der Sie lernen, experimentieren usw. können.
Lassen Sie uns überprüfen, ob alles ordnungsgemäß funktioniert. Im Home-Verzeichnis des Benutzers stack gibt es zwei Dateien – eine stackrc (zur Verwaltung des Undercloud) und die zweite overcloudrc (zur Verwaltung des Overcloud). Diese Dateien müssen als Quelle angegeben werden, da sie die für die Authentifizierung erforderlichen Informationen enthalten.
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Netzwerke | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | AKTIV | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | AKTIV | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | AKTIV | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | AKTIV | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | AKTIV | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$In meiner Installation fehlt noch ein kleiner Schritt – wir müssen eine Route auf dem Controller hinzufügen, da die Maschine, mit der ich arbeite, in einem anderen Netzwerk ist. Dazu loggen wir uns als heat-admin auf control-1 ein und fügen die Route hinzu.
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Letzte Anmeldung: Fr 14. Aug 09:47:40 2020 von 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254Jetzt können Sie sich im Dashboard anmelden. Alle Informationen – Adressen, Benutzername und Passwort – befinden sich in der Datei /home/stack/overcloudrc. Das endgültige Schema sieht folgendermaßen aus:
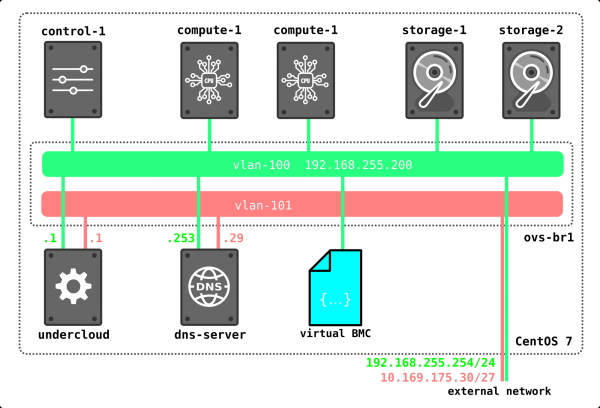
Übrigens, in unserer Installation wurden die Adressen der Maschinen über DHCP zugewiesen und wie Sie sehen, werden sie „willkürlich“ vergeben. Sie können im Template festlegen, welche Adresse während des Deployments an welche Maschine gebunden werden soll, falls dies erforderlich ist.
Wie fließt der Traffic zwischen den virtuellen Maschinen?
In diesem Artikel betrachten wir drei Möglichkeiten für den Datenverkehr
- Zwei Maschinen auf einem Hypervisor in demselben L2-Netzwerk
- Zwei Maschinen auf verschiedenen Hypervisors in demselben L2-Netzwerk
- Zwei Maschinen in verschiedenen Netzwerken (Routing zwischen Netzwerken)
In der nächsten Sitzung werden wir CASES mit externem Zugriff über ein externes Netzwerk, unter Verwendung von Floating IPs und verteiltem Routing betrachten. Heute konzentrieren wir uns jedoch auf den internen Verkehr.
Für die Überprüfung stellen wir folgendes Schema zusammen:
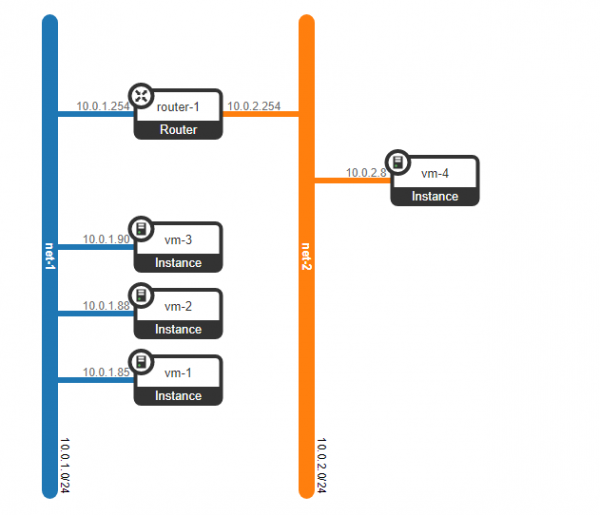
Wir haben 4 virtuelle Maschinen eingerichtet – 3 in einem L2-Netzwerk – net-1, und 1 weitere im Netzwerk net-2.
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | AKTIV | - | Laufend | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | AKTIV | - | Laufend | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | AKTIV | - | Laufend | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | AKTIV | - | Laufend | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ Lassen Sie uns sehen, auf welchen Hypervisoren die erstellten Maschinen sitzen:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 | (overcloud) [stack@undercloud ~]$
Die Maschinen vm-1 und vm-3 sind auf compute-0 platziert, die Maschinen vm-2 und vm-4 befinden sich auf der Node compute-1.
Zudem wurde ein virtueller Router eingerichtet, um das Routing zwischen den angegebenen Netzwerken zu ermöglichen:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | AKTIV | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ Der Router hat zwei virtuelle Ports, die als Gateways für die Netzwerke fungieren:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ Bevor wir jedoch den Datenverkehr analysieren, sehen wir uns an, was wir derzeit auf der Kontrollknoten (die auch der Netzwerk-Knoten ist) und auf dem Compute-Knoten haben. Lassen Sie uns mit dem Compute-Knoten beginnen.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (intern)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (intern)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (intern)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Aktuell sind auf dem Knoten drei OVS-Bridges vorhanden - br-int, br-tun, br-ex. Zwischen ihnen sehen wir eine Reihe von Schnittstellen. Um die Informationen besser zu veranschaulichen, lassen Sie uns alle Schnittstellen auf ein Diagramm skizzieren und schauen, was dabei herauskommt.
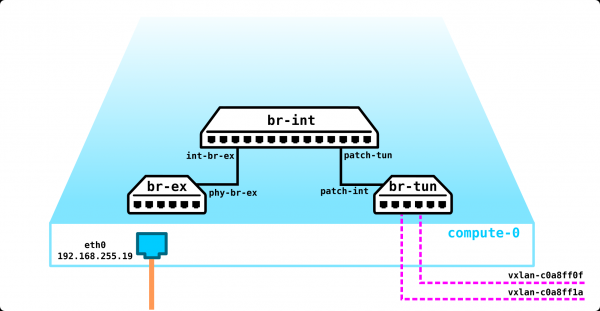
An den Adressen, an denen die VxLAN-Tunnel aktiviert sind, ist zu erkennen, dass ein Tunnel zu compute-1 (192.168.255.26) und der andere zu control-1 (192.168.255.15) führt. Besonders interessant ist jedoch, dass br-ex keine physischen Schnittstellen hat. Wenn wir uns die konfigurierten Flows ansehen, stellt sich heraus, dass diese Bridge momentan nur Traffic abweisen kann.
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163 mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ Wie aus der Ausgabe zu erkennen ist, ist die Adresse direkt an den physischen Port und nicht an die virtuelle Bridge-Schnittstelle angeschlossen.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ Gemäß der ersten Regel sollte alles, was vom Port phy-br-ex kommt, verworfen werden.
Dieser Bridge kann aktuell nur Verkehr von diesem Interface (Verbindung zu br-int) zugeführt werden, und laut den Drops hat der Bridge bereits BUM-Verkehr empfangen.
Das bedeutet, dass der Traffic von diesem Knoten nur über einen VxLAN-Tunnel abgewickelt werden kann, und nicht anders. Wenn jedoch DVR aktiviert wird, ändert sich die Situation, aber darauf kommen wir ein anderes Mal zurück. Bei der Isolation von Netzwerken, beispielsweise durch VLANs, werden Sie nicht nur ein L3-Interface im 0. VLAN haben, sondern mehrere Interfaces. Der VxLAN-Traffic wird jedoch weiterhin genau so von dem Knoten ausgehen, aber zusätzlich in ein zugewiesenes VLAN gekapselt sein.
Wir haben das Compute-Knoten geklärt, jetzt kommen wir zum Control-Knoten.
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$Tatsächlich kann man sagen, dass alles gleich bleibt, jedoch befindet sich die IP-Adresse nicht mehr auf dem physischen Interface, sondern auf dem virtuellen Bridge. Dies wurde so implementiert, da dieser Port der Port ist, über den der Traffic in die externe Welt geleitet wird.
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163 mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ Dieser Port ist mit dem Bridge br-ex verbunden und da keine VLAN-IDs auf ihm gesetzt sind, handelt es sich um einen Trunk-Port, auf dem alle VLANs erlaubt sind. Der Verkehr wird derzeit ohne Tag nach außen geleitet, was durch die VLAN-ID 0 im obigen Output angezeigt wird.
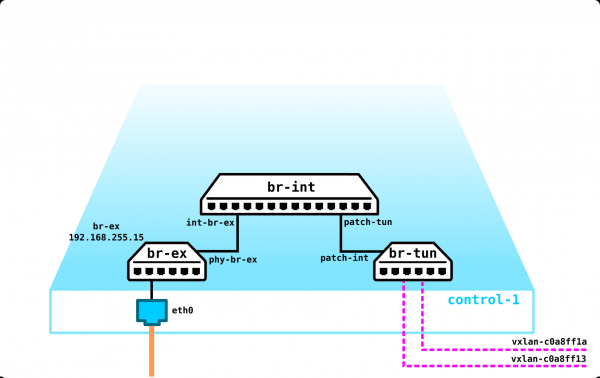
Alles andere ist momentan identisch mit dem Compute-Knoten – die gleichen Bridges, die gleichen Tunnel, die zu den zwei Compute-Knoten führen.
In diesem Artikel werden wir die Speicher-Nodes nicht behandeln, aber zur besseren Verständnis ist es notwendig zu sagen, dass der Netzwerkanteil dieser Nodes einfach lächerlich banal ist. In unserem Fall gibt es nur einen physischen Port (eth0) mit einer zugewiesenen IP-Adresse, und das war's. Es gibt keine VxLAN-Tunnel, Tunnel-Bridges usw. — es gibt überhaupt kein OVS, da es keinen Sinn macht. Bei der Verwendung von Netzwerkauslastung wird es auf dieser Node zwei Schnittstellen (physische Ports, Bonding oder einfach zwei VLANs — das ist unerheblich — es hängt davon ab, was Sie möchten) geben — eine für die Verwaltung, die andere für den Datenverkehr (Schreiben auf die Festplatte der VM, Lesen von der Festplatte usw.).
Wir haben untersucht, was auf den Nodes ohne irgendwelche Services vorhanden ist. Nun werden wir 4 virtuelle Maschinen starten und sehen, wie sich das oben beschriebene Schema ändern wird — wir sollten Ports, virtuelle Router usw. sehen.
Bisher sieht unser Netzwerk folgendermaßen aus:
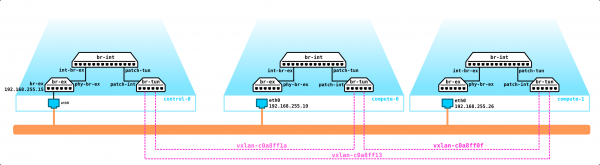
Wir haben zwei virtuelle Maschinen auf jeder Compute-Node. Lassen Sie uns am Beispiel von compute-0 sehen, wie alles verbunden ist.
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ Das System hat nur ein virtuelles Interface – tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Typ Quelle Modell MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
Dieses Interface zeigt auf den Linux Bridge:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
Bridge-Name Bridge-ID STP aktiviert Interfaces
docker0 8000.0242904c92a8 nein
qbr5bd37136-47 8000.5e4e05841423 nein qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 nein qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ Wie aus der Ausgabe der Bridge zu erkennen ist, gibt es nur zwei Interfaces – tap95d96a75-a0 und qvb95d96a75-a0.
Hier lohnt es sich, einen Moment über die Typen virtueller Netzwerkausrüstungen in OpenStack zu sprechen:
vtap – virtuelles Interface, das an eine Instanz (VM) angeschlossen ist.
qbr – Linux Bridge
qvb und qvo – vEth-Paare, die mit Linux Bridge und Open vSwitch Bridge verbunden sind.
br-int, br-tun, br-vlan – Open vSwitch Bridges
patch-, int-br-, phy-br- – Open vSwitch Patch-Interfaces, die Bridges verbinden.
qg, qr, ha, fg, sg – Ports des Open vSwitch, die von virtuellen Geräten zur Verbindung mit OVS verwendet werden.
Wie Sie sehen, wenn wir in der Bridge den Port qvb95d96a75-a0 haben, der ein vEth-Paar ist, gibt es irgendwo seine Gegenstelle, die logischerweise qvo95d96a75-a0 genannt werden sollte. Lassen Sie uns prüfen, welche Ports auf dem OVS verfügbar sind.
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ Wie wir sehen, befindet sich der Port im br-int. Br-int fungiert als Switch, der die Ports der virtuellen Maschinen terminiert. Neben qvo95d96a75-a0 ist im Output der Port qvo5bd37136-47 sichtbar. Dies ist der Port zur zweiten virtuellen Maschine. Insgesamt sieht unser Schema jetzt so aus:
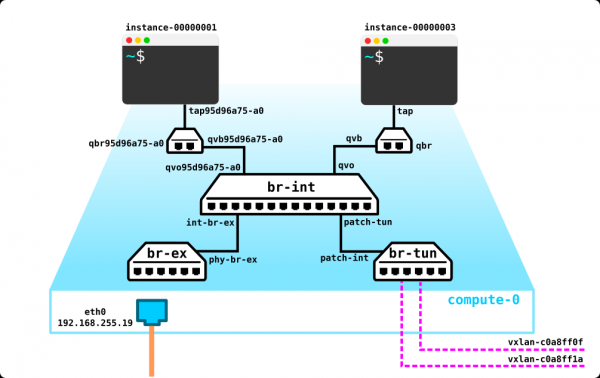
Eine Frage, die sofort das Interesse des aufmerksamen Lesers wecken sollte: Warum ein Linux-Bridge zwischen dem Port der virtuellen Maschine und dem OVS-Port? Der Grund dafür ist, dass zur Sicherung der Maschine Sicherheitsgruppen verwendet werden, die nichts anderes sind als iptables. OVS funktioniert jedoch nicht mit iptables, weshalb dieser "Workaround" geschaffen wurde. Aber er hat sich überlebt – stattdessen kommt nun conntrack in den neuen Versionen zum Einsatz.
Das Schema sieht letztendlich so aus:
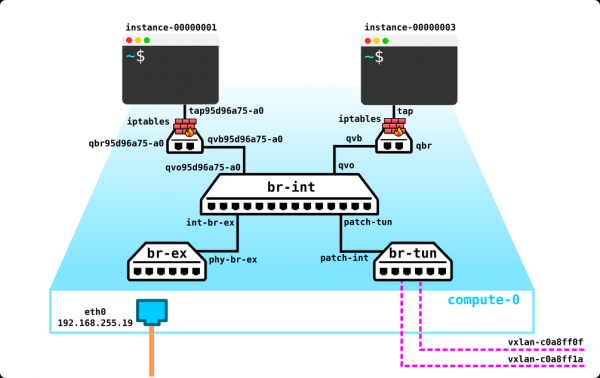
Zwei Maschinen auf einem Hypervisor in demselben L2-Netzwerk
Da sich die beiden VMs im selben L2-Netzwerk und auf demselben Hypervisor befinden, wird der Verkehr zwischen ihnen sinnvoll lokal über br-int geleitet, da beide Maschinen im selben VLAN sind:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Typ Quelle Modell MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Typ Quelle Modell MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
Port VLAN MAC Alter
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ Zwei Maschinen auf verschiedenen Hypervisors in demselben L2-Netzwerk
Jetzt schauen wir uns an, wie der Datenverkehr zwischen zwei Maschinen in einem L2-Netzwerk verläuft, die jedoch auf unterschiedlichen Hypervisoren liegen. Um ehrlich zu sein, wird sich nicht viel ändern; der Datenverkehr zwischen den Hypervisoren wird einfach über einen VXLAN-Tunnel geleitet. Lassen Sie uns das anhand eines Beispiels betrachten.
Die Adressen der virtuellen Maschinen, zwischen denen wir den Datenverkehr beobachten werden:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Typ Quelle Modell MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Schnittstelle Typ Quelle Modell MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ Betrachten wir die Forwarding-Tabelle in br-int auf compute-0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]Der Datenverkehr sollte auf Port 2 gehen – schauen wir, was das für ein Port ist:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$Das ist patch-tun – also das Interface in br-tun. Schauen wir uns an, was mit dem Paket auf br-tun passiert:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, dauer=1387.959s, tabelle=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priorität=1, vlan_tci=0x0001/0x0fff, dl_dst=fa:16:3e:72:ad:53 aktionen=load:0->NXM_OF_VLAN_TCI[], load:0x16->NXM_NX_TUN_ID[], ausgabe:2
[heat-admin@overcloud-novacompute-0 ~]$ Das Paket wird in VxLAN verpackt und an Port 2 gesendet. Lassen Sie uns sehen, wohin Port 2 führt:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$Das ist der VxLAN-Tunnel auf compute-1:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Gehen wir zu compute-1 und sehen, was weiter mit dem Paket geschieht:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ Der Mac ist in der Weiterleitungstabelle br-int auf compute-1 enthalten, und wie aus der obigen Ausgabe hervorgeht, ist er über Port 2 sichtbar, der zu br-tun führt:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46Schauen wir uns zunächst an, dass es im br-int auf compute-1 eine MAC-Adresse gibt:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ Das bedeutet, dass das empfangene Paket an Port 3 gesendet wird, hinter dem sich die virtuelle Maschine instance-00000003 befindet.
Der Vorteil des OpenStack-Deployments zur Untersuchung mithilfe virtueller Infrastrukturen ist, dass wir den Datenverkehr zwischen Hypervisoren problemlos abfangen und analysieren können. Das werden wir jetzt tun, indem wir tcpdump am vnet-Port in Richtung compute-0 ausführen:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: lauscht auf vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************ausgelassen*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [kein cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [kein cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************ausgelassen*******************Die erste Zeile zeigt, dass das Paket mit der Adresse 10.0.1.85 an die Adresse 10.0.1.88 (ICMP-Verkehr) weitergeleitet wird, wobei es in ein VxLAN-Paket mit der vni 22 eingekapselt ist. Dieses Paket wird vom Host 192.168.255.19 (compute-0) an den Host 192.168.255.26 (compute-1) gesendet. Wir können überprüfen, dass die VNI mit der in ovs angegebenen übereinstimmt.
Kehren wir zu dieser Zeile zurück: actions=load:0->NXM_OF_VLAN_TCI[], load:0x16->NXM_NX_TUN_ID[], output:2. 0x16 ist die vni im hexadezimalen Zahlensystem. Lassen Sie uns diese Zahl in das Dezimalsystem umwandeln:
16 = 6*16^0+1*16^1 = 6+16 = 22Das heißt, die vni ist korrekt.
Die zweite Zeile zeigt den Rückverkehr; es besteht keine Notwendigkeit, dies weiter zu erläutern, da dort alles klar ist.
Zwei Maschinen in verschiedenen Netzwerken (Routing zwischen Netzwerken)
Der letzte Fall für heute ist das Routing zwischen Netzwerken innerhalb eines Projekts mit einem virtuellen Router. Wir betrachten den Fall ohne DVR (dieses Thema werden wir in einem anderen Artikel behandeln), daher erfolgt das Routing auf der Netzwerk-Node. In unserem Fall ist die Netzwerk-Node nicht in eine separate Entität ausgelagert und befindet sich auf der Control-Node.
Lassen Sie uns zunächst überprüfen, ob das Routing funktioniert:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 Datenbytes
64 Bytes von 10.0.2.8: seq=0 ttl=63 Zeit=7,727 ms
64 Bytes von 10.0.2.8: seq=1 ttl=63 Zeit=3,832 ms
^C
--- 10.0.2.8 Ping-Statistik ---
2 Pakete übertragen, 2 Pakete empfangen, 0 % Paketverlust
Round-Trip min/avg/max = 3,832/5,779/7,727 msDa in diesem Fall das Paket zum Gateway gesendet werden muss und dort weitergeleitet wird, müssen wir die MAC-Adresse des Gateways herausfinden. Dazu schauen wir uns die ARP-Tabelle in der Instanz an:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0Jetzt sehen wir uns an, wohin der Verkehr mit dem Ziel (10.0.1.254) fa:16:3e:c4:64:70 gesendet werden soll:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ Wir schauen uns an, wohin Port 2 führt:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ Das ist logisch, der Verkehr geht in br-tun. Lassen Sie uns sehen, in welchen VXLAN-Tunnel er eingewickelt wird:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, Dauer=3514.566s, Tabelle=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff, dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ Der dritte Port ist der VXLAN-Tunnel:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ Der Blick auf den Steuerknoten:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Der Traffic hat den Steuerknoten erreicht, also müssen wir darauf umschalten und sehen, wie das Routing funktioniert.
Wie Sie sich erinnern, sah der Steuerknoten genau so aus wie der Compute-Knoten – die gleichen drei Bridges, nur dass br-ex einen physischen Port hatte, über den der Knoten Traffic nach außen senden konnte. Die Erstellung von Instanzen hat die Konfiguration auf den Compute-Knoten geändert – es wurden Linux-Bridge, iptables und Schnittstellen zu den Knoten hinzugefügt. Auch die Erstellung von Netzwerken und virtuellen Routern hat ihre Spuren in der Konfiguration des Steuerknotens hinterlassen.
Es ist also klar, dass die MAC-Adresse des Gateways in der Weiterleitungstabelle von br-int auf dem Steuerknoten vorhanden sein sollte. Überprüfen wir, ob sie dort ist und wohin sie zeigt:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Der QR-Port qr-0c52b15f-8f ist sichtbar. Wenn wir zum Listing der virtuellen Ports in OpenStack zurückkehren, zeigt dieser Porttyp die Verbindung von verschiedenen virtuellen Geräten zu OVS an. Genauer gesagt, ist qr der Port zum virtuellen Router, der in Form eines Namespaces dargestellt wird.
Schauen wir uns an, welche Namespaces auf dem Server verfügbar sind:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Es gibt insgesamt drei Instanzen. Aber anhand der Namen kann man den Zweck jeder einzelnen erraten. Zu den Instanzen mit der ID 0 und 1 kommen wir später zurück; jetzt interessiert uns der Namespace qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ In diesem Namespace gibt es zwei interne Schnittstellen, die wir zuvor erstellt haben. Beide virtuellen Ports wurden zu br-int hinzugefügt. Lassen Sie uns die MAC-Adresse des Ports qr-0c52b15f-8f überprüfen, da der Verkehr, laut der Ziel-MAC-Adresse, tatsächlich über dieses Interface lief.
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163 mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ Das heißt, in diesem Fall funktioniert alles nach den Regeln der Standard-Routing. Da der Verkehr für den Host 10.0.2.8 bestimmt ist, sollte er über die zweite Schnittstelle qr-92fa49b5-54 hinausgehen und durch den VXLAN-Tunnel zum Compute-Knoten geleitet werden:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Adresse HWtyp HWadresse Flags Maske Schnittstelle
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ Alles klar, keine Überraschungen. Schauen wir, wo die MAC-Adresse des Hosts 10.0.2.8 im br-int sichtbar ist:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Wie vorgesehen, geht der Datenverkehr in br-tun. Schauen wir, in welchen Tunnel der Verkehr als Nächstes geleitet wird:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, Dauer=5346.829s, Tabelle=20, n_packets=5248, n_bytes=498512, harte_zeitüberschreitung=300, idle_age=0, hard_age=0, Priorität=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c Aktionen=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Der Datenverkehr kommt durch den Tunnel zu compute-1. Auf compute-1 ist es einfach – vom br-tun gelangt das Paket zu br-int und von dort zum Interface der virtuellen Maschine:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ Lassen Sie uns überprüfen, ob dies tatsächlich das richtige Interface ist:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$ Wir haben den gesamten Weg des Pakets durchlaufen. Ich denke, Sie haben bemerkt, dass der Datenverkehr durch verschiedene VXLAN-Tunnel ging und mit verschiedenen VNIs herauskam. Lassen Sie uns sehen, welche VNIs das sind, danach sammeln wir einen Dump am Kontrollknotenport und stellen sicher, dass der Datenverkehr genau so fließt, wie oben beschrieben.
Der Tunnel zu compute-0 hat folgende Anweisungen: actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3. Lassen Sie uns 0x16 in das dezimale System umwandeln:
0x16 = 6*16^0 + 1*16^1 = 6 + 16 = 22Der Tunnel zu compute-1 hat folgenden VNI: actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2. Lassen Sie uns 0x63 in das dezimale System umwandeln:
0x63 = 3*16^0 + 6*16^1 = 3 + 96 = 99Und jetzt schauen wir uns den Dump an:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************Das erste Paket ist ein VXLAN-Paket vom Host 192.168.255.19 (compute-0) zum Host 192.168.255.15 (control-1) mit VNI 22, in dem ein ICMP-Paket vom Host 10.0.1.85 zum Host 10.0.2.8 verpackt ist. Wie bereits oben erwähnt, entspricht der VNI dem, was wir in den Ausgaben gesehen haben.
Das zweite Paket ist ein VXLAN-Paket von Host 192.168.255.15 (control-1) zu Host 192.168.255.26 (compute-1) mit VNI 99, in dem ein ICMP-Paket von Host 10.0.1.85 zu Host 10.0.2.8 verpackt ist. Wie bereits oben berechnet, entspricht die VNI dem, was wir in den Ausgaben gesehen haben.
Die nächsten beiden Pakete sind der rückwärtige Datenverkehr von 10.0.2.8 zu 10.0.1.85.
Das bedeutet, dass wir letztendlich ein solches Schema für die Control-Node erhalten haben:
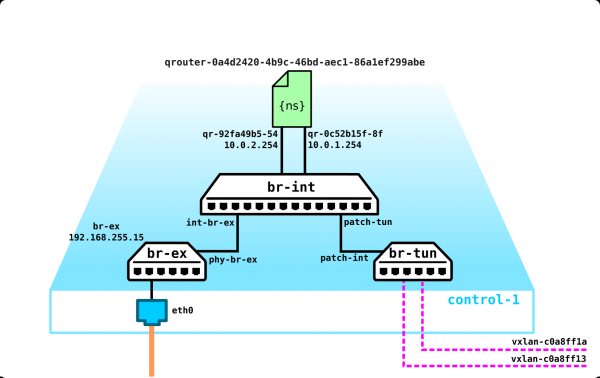
Scheint alles? Wir haben zwei Namespaces vergessen:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Wie wir über die Architektur der Cloud-Plattform gesprochen haben — es wäre ideal, wenn die Maschinen automatisch Adressen vom DHCP-Server erhalten. Das sind die beiden DHCP-Server für unsere beiden Netzwerke 10.0.1.0/24 und 10.0.2.0/24.
Überprüfen wir, ob das der Fall ist. In diesem Namespace gibt es nur eine Adresse — 10.0.1.1 — die Adresse des DHCP-Servers selbst, und sie ist ebenfalls in br-int enthalten:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163 mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Lassen Sie uns überprüfen, ob Prozesse mit dem Namen qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 auf dem Control-Knoten vorhanden sind:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ Es gibt einen solchen Prozess und basierend auf den Informationen aus der obigen Ausgabe können wir beispielsweise sehen, was wir derzeit gemietet haben:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$Am Ende erhalten wir so einen Satz von Diensten auf dem Control-Knoten:
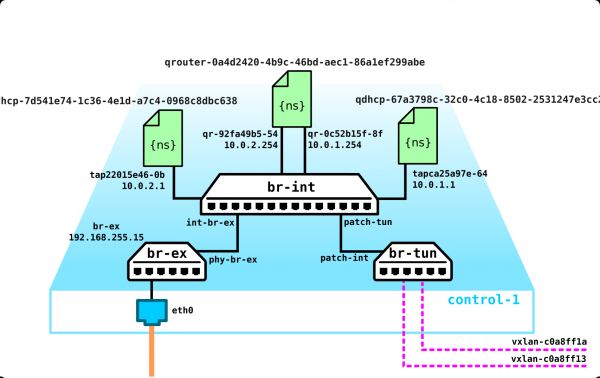
Bitte beachten Sie, dass dies nur 4 Maschinen, 2 interne Netzwerke und einen virtuellen Router sind… Momentan haben wir hier keine externen Netzwerke oder viele verschiedene Projekte, jedes mit seinen eigenen (überlappenden) Netzwerken, und unser verteilter Router ist deaktiviert. Schließlich gab es im Testaufbau nur einen Control-Knoten (für Hochverfügbarkeit sollte ein Quorum aus drei Knoten vorhanden sein). Es ist logisch, dass es im kommerziellen Bereich "etwas" komplexer ist, aber anhand dieses einfachen Beispiels verstehen wir, wie es funktionieren sollte – ob Sie 3 oder 300 Namespaces haben, ist natürlich wichtig, aber aus der Sicht des Gesamtkonstrukts ändert sich nicht viel… es sei denn, Sie integrieren eine vendor-spezifische SDN. Aber das ist eine ganz andere Geschichte.
Ich hoffe, es war interessant. Wenn es Anmerkungen oder Ergänzungen gibt oder wenn ich irgendwo offensichtlich falsch lag (ich bin ein Mensch und meine Meinung wird immer subjektiv sein) – lassen Sie es mich wissen, was ich korrigieren oder hinzufügen soll – wir werden alles anpassen oder hinzufügen.
Abschließend möchte ich einige Worte zum Vergleich von OpenStack (sowohl in der Vanilla-Version als auch den Vendor-Varianten) mit der Cloud-Lösung von VMware sagen – ich habe in den letzten Jahren oft danach gefragt worden, und ehrlich gesagt bin ich ein wenig müde von diesem Thema. Dennoch ist es schwierig, diese beiden Lösungen zu vergleichen, aber man kann definitiv sagen, dass beide ihre Schwächen haben. Bei der Wahl einer der beiden Lösungen sollte man alle Vor- und Nachteile abwägen.
Wenn OpenStack eine Community-getriebene Lösung ist, hat VMware das Recht, nur das zu tun, was ihr gefällt (d.h. was für sie profitabel ist), und das ist logisch – schließlich ist es ein kommerzielles Unternehmen, das daran gewöhnt ist, Geld mit seinen Kunden zu verdienen. Aber es gibt ein großes und wichtiges ABER – Sie können beispielsweise von OpenStack (z.B. von Nokia) zu einer Lösung von Juniper (Contrail Cloud) wechseln, aber ein Wechsel von VMware wird Ihnen wahrscheinlich schwerfallen. Für mich erscheinen diese beiden Lösungen so: OpenStack (Vendor-Version) ist ein einfacher Käfig, in den Sie gesetzt werden, aber Sie haben den Schlüssel und können jederzeit hinaus. VMware hingegen ist ein goldener Käfig, der Schlüssel gehört dem Besitzer und wird Sie teuer zu stehen kommen.
Ich empfehle weder das eine Produkt noch das andere – Sie wählen, was Sie benötigen. Aber wenn ich die Wahl hätte, würde ich beide Lösungen wählen: VMWare für die IT-Cloud (geringe Lasten, benutzerfreundliche Verwaltung) und OpenStack von einem Anbieter wie Nokia oder Juniper (die bieten sehr solide schlüsselfertige Lösungen) für die Telekom-Cloud. Ich würde OpenStack nicht für reine IT verwenden – das wäre, als würde man mit Kanonen auf Spatzen schießen, aber außer der Überdimensionierung sehe ich keine Gründe, es nicht zu nutzen. Allerdings VMWare im Telekomsektor zu nutzen – das ist, als würde man Kies mit einem Ford Raptor transportieren – sieht zwar schön aus, aber der Fahrer muss zehn Fahrten anstelle von einer machen.
Meiner Meinung nach ist der größte Nachteil von VMWare deren vollständige Intransparenz – das Unternehmen gibt keine Informationen darüber preis, wie beispielsweise vSAN funktioniert oder was im Kern des Hypervisors steckt – das ist für sie einfach nicht rentabel. Mit anderen Worten, man wird nie ein Experte in VMWare werden – ohne Unterstützung des Herstellers ist man verloren (häufig treffe ich auf VMWare-Experten, die bei banalen Fragen ins Stocken geraten). Für mich ist VMWare wie der Kauf eines Autos mit einem verschlossenen Motorhaube – ja, vielleicht gibt es bei Ihnen Fachleute, die den Zahnriemen wechseln können, aber öffnen kann die Haube nur derjenige, der Ihnen diese Lösung verkauft hat. Persönlich mag ich Lösungen nicht, bei denen ich nicht eingreifen kann. Sie könnten sagen, dass Sie wahrscheinlich nicht unter die Haube schauen müssen. Das mag sein, aber ich werde Sie ansehen, wenn Sie eine große Funktion in der Cloud aus 20-30 virtuellen Maschinen aufbauen müssen, 40-50 Netzwerken, von denen die eine Hälfte nach außen möchte, während die andere Hälfte SR-IOV-Beschleunigung anfordert – sonst brauchen Sie noch einige Dutzend solcher Maschinen, denn die Leistung wird nicht ausreichen.
Es gibt auch andere Perspektiven, daher liegt die Entscheidung allein bei Ihnen, und am wichtigsten ist, dass Sie für Ihre Wahl verantwortlich sind. Das ist nur meine Meinung – basiert auf meinen Erfahrungen mit mindestens vier Produkten: Nokia, Juniper, Red Hat und VMWare. Ich habe also Vergleichsmöglichkeiten.
Quelle: habr.com
