

VictoriaMetrics, TimescaleDB und InfluxDB wurden verglichen auf einem Datensatz mit einer Milliarde Datenpunkten, die zu 40 einzigartigen Zeitreihen gehören.
Vor ein paar Jahren gab es eine Ära von Zabbix. Jeder Bare-Metal-Server hatte nicht mehr als ein paar Indikatoren – CPU-Auslastung, RAM-Auslastung, Festplattennutzung und Netzwerknutzung. Auf diese Weise können Metriken von Tausenden von Servern in 40 einzigartige Zeitreihen passen, und Zabbix kann MySQL als Backend für Zeitreihendaten verwenden :)
Derzeit allein Mit Standardkonfigurationen werden über 500 Metriken für einen durchschnittlichen Host bereitgestellt. Da sind viele für verschiedene Datenbanken, Webserver, Hardwaresysteme usw. Sie alle bieten eine Vielzahl nützlicher Metriken. Alle beginnen, verschiedene Indikatoren für sich selbst zu setzen. Es gibt Kubernetes mit Clustern und Pods, die viele Metriken offenlegen. Dies führt dazu, dass Server Tausende einzigartiger Metriken pro Host offenlegen. Die einzigartige 40K-Zeitreihe ist also keine Hochleistungszeitreihe mehr. Es wird zum Mainstream und sollte von jeder modernen TSDB auf einem einzelnen Server problemlos gehandhabt werden können.
Wie groß ist derzeit die große Anzahl einzigartiger Zeitreihen? Wahrscheinlich 400K oder 4M? Oder 40m? Vergleichen wir moderne TSDBs mit diesen Zahlen.
Einen Benchmark installieren
ist ein hervorragendes Benchmarking-Tool für TSDBs. Es ermöglicht Ihnen, eine beliebige Anzahl von Metriken zu generieren, indem Sie die erforderliche Anzahl von Zeitreihen dividiert durch 10 übergeben – Flag (ehemalig -scale-var). 10 ist die Anzahl der Messungen (Metriken), die auf jedem Host oder Server generiert werden. Die folgenden Datensätze wurden mit TSBS für den Benchmark generiert:
- 400 einzigartige Zeitreihen, 60-Sekunden-Intervall zwischen Datenpunkten, Daten erstrecken sich über volle 3 Tage, ~1.7 Milliarden Gesamtzahl der Datenpunkte.
- 4 Millionen einzigartige Zeitreihen, 600-Sekunden-Intervall, Daten umfassen 3 volle Tage, ~1.7 Milliarden Gesamtzahl der Datenpunkte.
- 40 Millionen einzigartige Zeitreihen, 1-Stunden-Intervall, Daten umfassen 3 volle Tage, ~2.8 Milliarden Gesamtzahl der Datenpunkte.
Der Client und der Server liefen auf dedizierten Instanzen in der Google-Cloud. Diese Instanzen hatten die folgenden Konfigurationen:
- vCPUs: 16
- RAM: 60 GB
- Speicher: Standard-Festplatte mit 1 TB. Es bietet einen Lese-/Schreibdurchsatz von 120 Mbit/s, 750 Lesevorgänge pro Sekunde und 1,5 Schreibvorgänge pro Sekunde.
TSDBs wurden aus offiziellen Docker-Images extrahiert und in Docker mit den folgenden Konfigurationen ausgeführt:
VictoriaMetriken:
docker run -it --rm -v /mnt/disks/storage/vmetrics-data:/victoria-metrics-data -p 8080:8080 valyala/victoria-metricsZur Unterstützung hoher Leistung sind InfluxDB-Werte (-e) erforderlich. Weitere Informationen finden Sie unter ):
docker run -it --rm -p 8086:8086 -e INFLUXDB_DATA_MAX_VALUES_PER_TAG=4000000 -e INFLUXDB_DATA_CACHE_MAX_MEMORY_SIZE=100g -e INFLUXDB_DATA_MAX_SERIES_PER_DATABASE=0 -v /mnt/disks/storage/influx-data:/var/lib/influxdb influxdbTimescaleDB (Konfiguration entnommen aus Datei):
MEM=`free -m | grep "Mem" | awk ‘{print $7}’`
let "SHARED=$MEM/4"
let "CACHE=2*$MEM/3"
let "WORK=($MEM-$SHARED)/30"
let "MAINT=$MEM/16"
let "WAL=$MEM/16"
docker run -it — rm -p 5432:5432
--shm-size=${SHARED}MB
-v /mnt/disks/storage/timescaledb-data:/var/lib/postgresql/data
timescale/timescaledb:latest-pg10 postgres
-cmax_wal_size=${WAL}MB
-clog_line_prefix="%m [%p]: [%x] %u@%d"
-clogging_collector=off
-csynchronous_commit=off
-cshared_buffers=${SHARED}MB
-ceffective_cache_size=${CACHE}MB
-cwork_mem=${WORK}MB
-cmaintenance_work_mem=${MAINT}MB
-cmax_files_per_process=100Der Datenlader wurde mit 16 parallelen Threads ausgeführt.
Dieser Artikel enthält nur Ergebnisse für Einfüge-Benchmarks. Die Ergebnisse des selektiven Benchmarks werden in einem separaten Artikel veröffentlicht.
400 einzigartige Zeitreihen
Beginnen wir mit einfachen Elementen – 400K. Benchmark-Ergebnisse:
- VictoriaMetrics: 2,6 Millionen Datenpunkte pro Sekunde; RAM-Nutzung: 3 GB; Endgültige Datengröße auf der Festplatte: 965 MB
- InfluxDB: 1.2 Millionen Datenpunkte pro Sekunde; RAM-Nutzung: 8.5 GB; Endgültige Datengröße auf der Festplatte: 1.6 GB
- Zeitskala: 849 Datenpunkte pro Sekunde; RAM-Nutzung: 2,5 GB; Endgültige Datengröße auf der Festplatte: 50 GB
Wie Sie den obigen Ergebnissen entnehmen können, übertrifft VictoriaMetrics die Einfügeleistung und das Komprimierungsverhältnis. Timeline gewinnt bei der RAM-Nutzung, verbraucht aber viel Speicherplatz – 29 Byte pro Datenpunkt.
Nachfolgend finden Sie die CPU-Auslastungsdiagramme für jede der TSDBs während des Benchmarks:
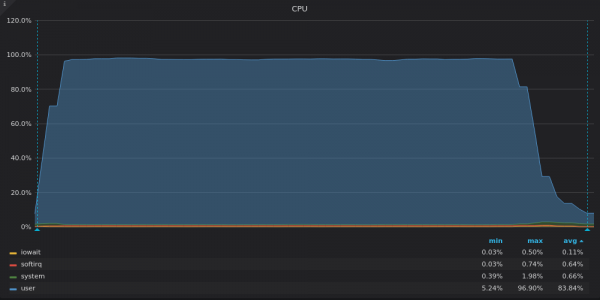
Oben ist ein Screenshot: VictoriaMetrics – CPU-Auslastung während des Einfügungstests für eine eindeutige 400-KByte-Metrik.
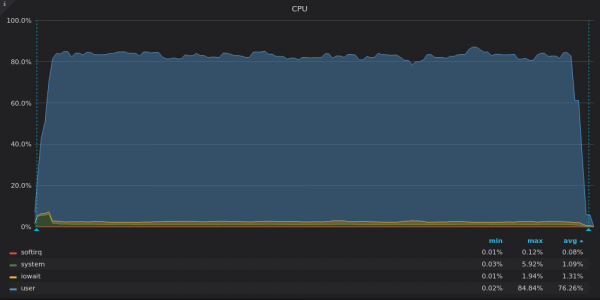
Oben ist ein Screenshot: InfluxDB – CPU-Auslastung während des Einfügungstests für die eindeutige Metrik 400 KB.
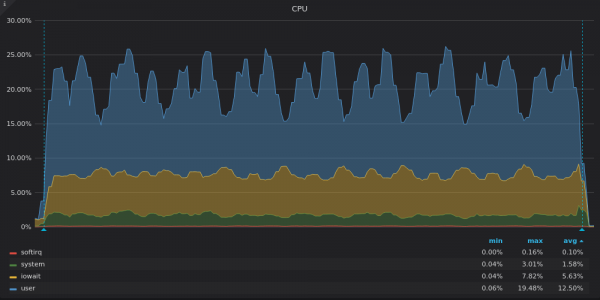
Oben ist ein Screenshot: TimescaleDB – CPU-Auslastung während des Einfügungstests für eine eindeutige Metrik von 400 KB.
VictoriaMetrics nutzt alle verfügbaren vCPUs, während InfluxDB etwa 2 von 16 vCPUs nicht ausreichend nutzt.
Timescale nutzt nur 3–4 der 16 vCPUs. Hohe Anteile von „iowait“ und „system“ im TimescaleDB-Zeitskalendiagramm weisen auf einen Engpass im Eingabe-/Ausgabe-Subsystem (E/A) hin. Schauen wir uns die Diagramme zur Festplattenbandbreitennutzung an:
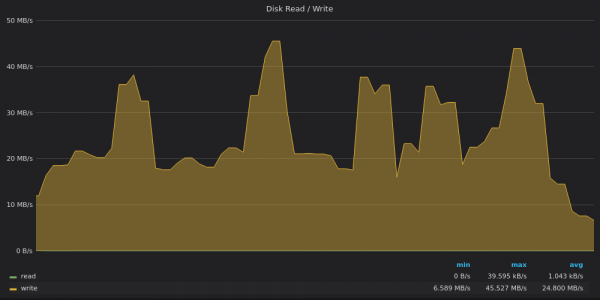
Oben ist ein Screenshot: VictoriaMetrics – Festplattenbandbreitennutzung im Einfügungstest für Unique Metrics 400K.
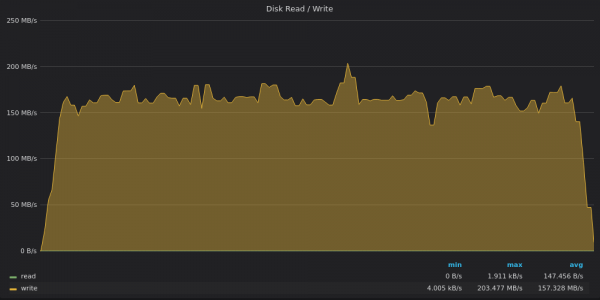
Oben ist ein Screenshot: InfluxDB – Festplattenbandbreitennutzung beim Einfügungstest für eindeutige Metriken 400K.
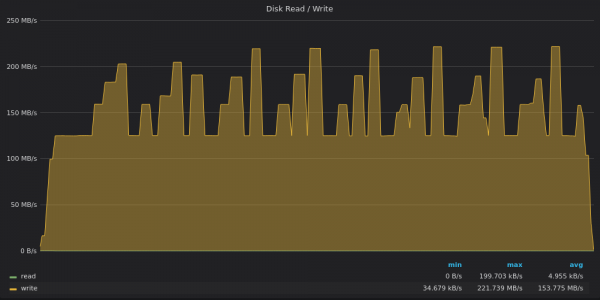
Oben ist ein Screenshot: TimescaleDB – Festplattenbandbreitennutzung beim Einfügungstest für eindeutige Metriken 400 KB.
VictoriaMetrics zeichnet Daten mit 20 Mbit/s auf, mit Spitzenwerten von bis zu 45 Mbit/s. Spitzen entsprechen großen Teilverschmelzungen im Baum .
InfluxDB schreibt Daten mit 160 MB/s, während ein 1-TB-Laufwerk Schreibdurchsatz 120 MB/s.
TimescaleDB ist auf einen Schreibdurchsatz von 120 Mbit/s begrenzt, manchmal durchbricht es diese Grenze und erreicht Spitzenwerte von 220 Mbit/s. Diese Spitzen entsprechen den Tälern unzureichender CPU-Auslastung im vorherigen Diagramm.
Schauen wir uns die Eingabe-/Ausgabe-(I/O)-Nutzungsdiagramme an:
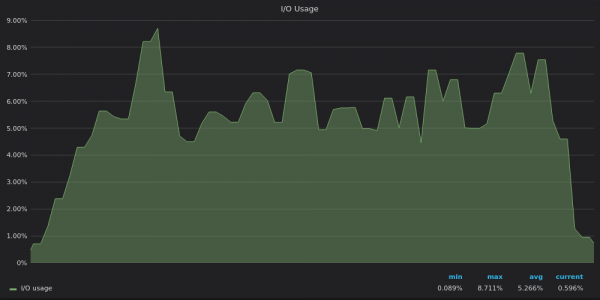
Oben ist ein Screenshot: VictoriaMetrics – Test-E/A-Nutzung für 400 eindeutige Metriken einfügen.
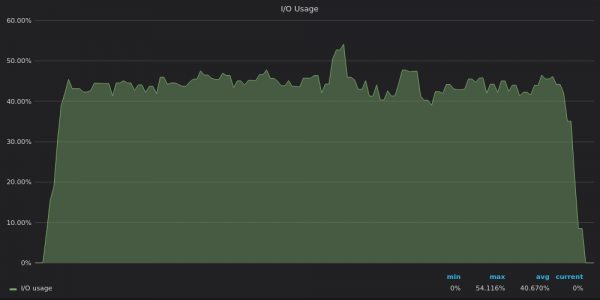
Oben ist ein Screenshot: InfluxDB – Test-E/A-Nutzung für 400 eindeutige Metriken einfügen.
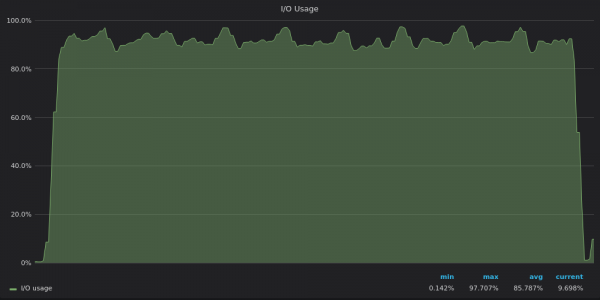
Oben ist ein Screenshot: TimescaleDB – Test-E/A-Nutzung für 400 eindeutige Metriken einfügen.
Es ist jetzt klar, dass TimescaleDB sein I/O-Limit erreicht und daher die verbleibenden 12 vCPUs nicht nutzen kann.
4M einzigartige Zeitreihen
4M-Zeitreihen sehen etwas herausfordernd aus. Aber unsere Konkurrenten bestehen diese Prüfung erfolgreich. Benchmark-Ergebnisse:
- VictoriaMetrics: 2,2 Millionen Datenpunkte pro Sekunde; RAM-Nutzung: 6 GB; Endgültige Datengröße auf der Festplatte: 3 GB.
- InfluxDB: 330 Datenpunkte pro Sekunde; RAM-Nutzung: 20,5 GB; Endgültige Datengröße auf der Festplatte: 18,4 GB.
- TimescaleDB: 480 Datenpunkte pro Sekunde; RAM-Nutzung: 2,5 GB; Endgültige Datengröße auf der Festplatte: 52 GB.
Die Leistung von InfluxDB sank von 1,2 Millionen Datenpunkten pro Sekunde für eine 400-Zeitreihe auf 330 Datenpunkte pro Sekunde für eine 4-Millionen-Zeitreihe. Dies ist ein erheblicher Leistungsverlust im Vergleich zu anderen Wettbewerbern. Schauen wir uns die CPU-Auslastungsdiagramme an, um die Grundursache für diesen Verlust zu verstehen:
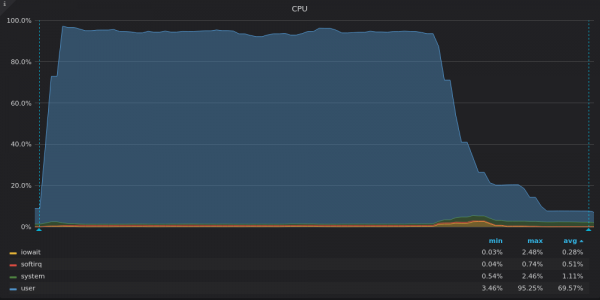
Oben ist ein Screenshot: VictoriaMetrics – CPU-Auslastung während des Einfügungstests für eine einzigartige 4M-Zeitreihe.
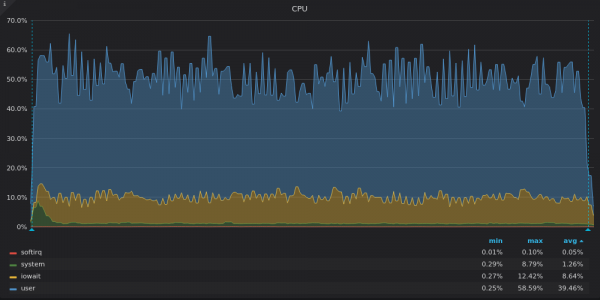
Oben ist ein Screenshot: InfluxDB – CPU-Auslastung während des Einfügungstests für einzigartige 4M-Zeitreihen.
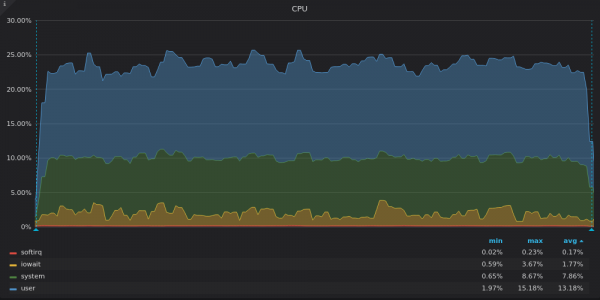
Oben ist ein Screenshot: TimescaleDB – CPU-Auslastung während des Einfügungstests für eine einzigartige 4M-Zeitreihe.
VictoriaMetrics verbraucht fast die gesamte Prozessorleistung (CPU). Der Abfall am Ende entspricht den verbleibenden LSM-Zusammenführungen, nachdem alle Daten eingefügt wurden.
InfluxDB nutzt nur 8 von 16 vCPUs, während TimsecaleDB 4 von 16 vCPUs nutzt. Was haben ihre Grafiken gemeinsam? Hoher Anteil iowait, was wiederum auf einen I/O-Engpass hinweist.
TimescaleDB hat einen hohen Anteil system. Wir gehen davon aus, dass hohe Leistung zu vielen oder vielen Systemaufrufen führte .
Schauen wir uns die Diagramme zum Festplattendurchsatz an:
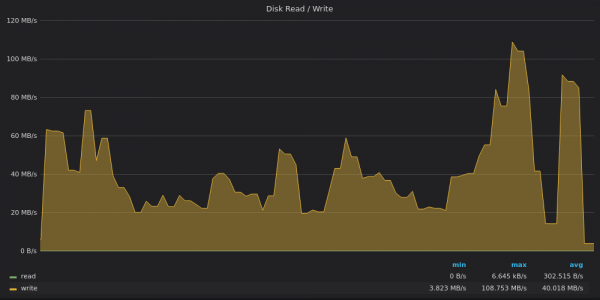
Oben ist ein Screenshot: VictoriaMetrics – Verwendung der Festplattenbandbreite zum Einfügen von 4 Millionen eindeutigen Metriken.
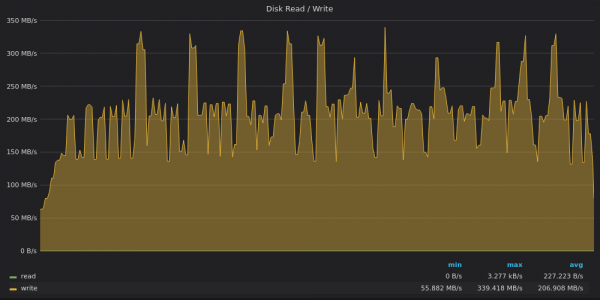
Oben ist ein Screenshot: InfluxDB – Verwendung der Festplattenbandbreite zum Einfügen von 4 Millionen eindeutigen Metriken.
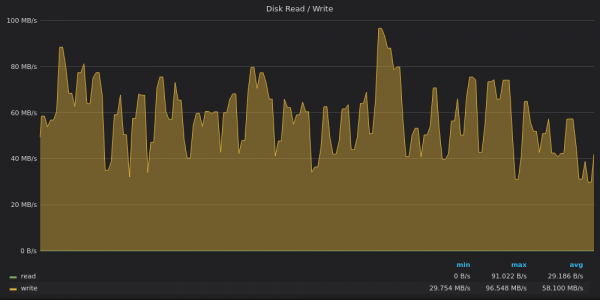
Oben ist ein Screenshot: TimescaleDB – Verwendung der Festplattenbandbreite zum Einfügen von 4 Millionen eindeutigen Metriken.
VictoriaMetrics erreichte in der Spitze eine Grenze von 120 MB/s, während die durchschnittliche Schreibgeschwindigkeit 40 MB/s betrug. Es ist wahrscheinlich, dass während des Höhepunkts mehrere schwere LSM-Fusionen durchgeführt wurden.
InfluxDB erreicht erneut einen durchschnittlichen Schreibdurchsatz von 200 MB/s mit Spitzenwerten von bis zu 340 MB/s auf einer Festplatte mit einem Schreiblimit von 120 MB/s :)
TimescaleDB ist nicht mehr auf die Festplatte beschränkt. Es scheint durch etwas anderes begrenzt zu sein, das mit einem hohen Anteil zusammenhängt системной CPU-Last.
Schauen wir uns die IO-Nutzungsdiagramme an:
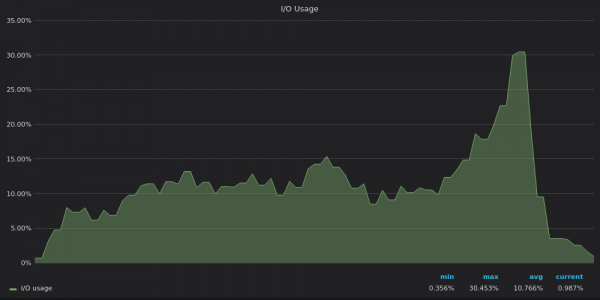
Oben ist ein Screenshot: VictoriaMetrics – Verwendung von E/A während des Einfügungstests für eine einzigartige 4M-Zeitreihe.
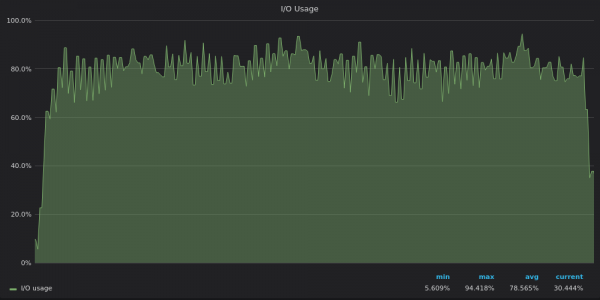
Oben ist ein Screenshot: InfluxDB – Verwendung von E/A während des Einfügungstests für eine einzigartige 4M-Zeitreihe.
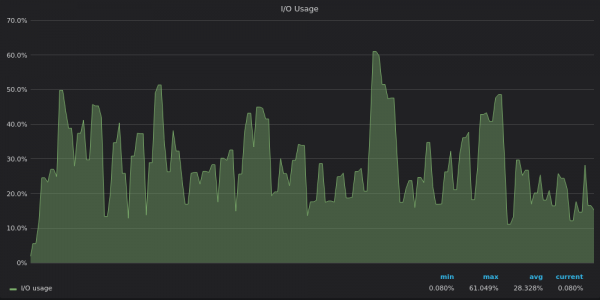
Oben ist ein Screenshot: TimescaleDB – E/A-Nutzung während des Einfügungstests für einzigartige 4M-Zeitreihen.
Die E/A-Nutzungsmuster spiegeln die der Festplattenbandbreite wider – InfluxDB ist E/A-begrenzt, während VictoriaMetrics und TimescaleDB über freie E/A-Ressourcen verfügen.
40 Millionen einzigartige Zeitreihen
40 Millionen einzigartige Zeitreihen waren zu groß für InfluxDB :)
Benchmark-Ergebnisse:
- VictoriaMetrics: 1,7 Millionen Datenpunkte pro Sekunde; RAM-Nutzung: 29 GB; Speicherplatznutzung: 17 GB.
- InfluxDB: Nicht abgeschlossen, da mehr als 60 GB RAM erforderlich waren.
- TimescaleDB: 330 Datenpunkte pro Sekunde, RAM-Nutzung: 2,5 GB; Speicherplatznutzung: 84 GB.
TimescaleDB zeigt mit 2,5 GB eine außergewöhnlich niedrige und stabile RAM-Nutzung – dasselbe wie für die einzigartigen 4M- und 400K-Metriken.
VictoriaMetrics skalierte langsam mit einer Rate von 100 Datenpunkten pro Sekunde, bis alle 40 Millionen getaggten Metriknamen verarbeitet waren. Anschließend erreichte er eine dauerhafte Einfügungsrate von 1,5 bis 2,0 Millionen Datenpunkten pro Sekunde, sodass das Endergebnis 1,7 Millionen Datenpunkte pro Sekunde betrug.
Die Diagramme für 40 Mio. einzigartige Zeitreihen ähneln den Diagrammen für 4 Mio. eindeutige Zeitreihen. Überspringen wir sie also.
Befund
- Moderne TSDBs sind in der Lage, Einfügungen für Millionen einzigartiger Zeitreihen auf einem einzigen Server zu verarbeiten. Im nächsten Artikel testen wir, wie gut TSDBs die Auswahl über Millionen einzigartiger Zeitreihen hinweg durchführt.
- Eine unzureichende CPU-Auslastung weist normalerweise auf einen E/A-Engpass hin. Es kann auch darauf hinweisen, dass die Blockierung zu grob ist und nur wenige Threads gleichzeitig ausgeführt werden können.
- Der I/O-Engpass besteht tatsächlich, insbesondere bei Nicht-SSD-Speichern wie den virtualisierten Blockgeräten von Cloud-Anbietern.
- VictoriaMetrics bietet die beste Optimierung für langsamen I/O-Speicher. Es bietet die beste Geschwindigkeit und das beste Komprimierungsverhältnis.
Herunterladen und probieren Sie es mit Ihren Daten aus. Die entsprechende statische Binärdatei ist unter verfügbar .
Lesen Sie hier mehr über VictoriaMetrics .
Update: veröffentlicht mit reproduzierbaren Ergebnissen.
Update Nr. 2: Lesen Sie auch .
Update Nr. 3: !
Telegram чат:
Source: habr.com
