

Hallo, ich erstelle Anwendungen für DBMS ist eine von der Mail.ru Group entwickelte Plattform, die ein leistungsstarkes DBMS und einen Anwendungsserver in der Lua-Sprache kombiniert. Die hohe Geschwindigkeit der auf Tarantool basierenden Lösungen wird insbesondere durch die Unterstützung des In-Memory-Modus des DBMS und die Möglichkeit erreicht, Anwendungsgeschäftslogik in einem einzigen Adressraum mit Daten auszuführen. Gleichzeitig wird die Datenpersistenz durch ACID-Transaktionen sichergestellt (ein WAL-Protokoll wird auf der Festplatte geführt). Tarantool verfügt über integrierte Unterstützung für Replikation und Sharding. Ab Version 2.1 werden Abfragen in SQL-Sprache unterstützt. Tarantool ist Open Source und unter der Simplified BSD-Lizenz lizenziert. Es gibt auch eine kommerzielle Enterprise-Version.

Fühle die Kraft! (…also genieße die Aufführung)
All dies macht Tarantool zu einer attraktiven Plattform für die Erstellung hochlastiger Anwendungen, die mit Datenbanken arbeiten. Bei solchen Anwendungen ist häufig eine Datenreplikation erforderlich.
Wie oben erwähnt, verfügt Tarantool über eine integrierte Datenreplikation. Das Funktionsprinzip besteht darin, alle im Master-Protokoll (WAL) enthaltenen Transaktionen nacheinander auf Replikaten auszuführen. Normalerweise ist eine solche Replikation (wir werden sie später nennen) niedriges Niveau) wird verwendet, um die Fehlertoleranz der Anwendung sicherzustellen und/oder die Leselast zwischen den Clusterknoten zu verteilen.
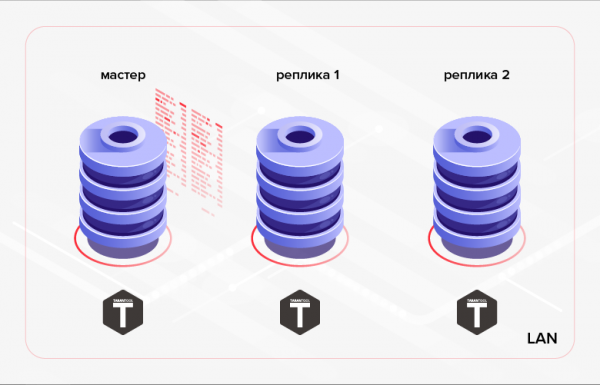
Reis. 1. Replikation innerhalb eines Clusters
Ein Beispiel für ein alternatives Szenario wäre die Übertragung von in einer Datenbank erstellten Daten in eine andere Datenbank zur Verarbeitung/Überwachung. Im letzteren Fall kann die Verwendung eine bequemere Lösung sein hohes Level Replikation – Datenreplikation auf der Ebene der Anwendungsgeschäftslogik. Diese. Wir verwenden keine vorgefertigte Lösung, die in das DBMS integriert ist, sondern implementieren die Replikation selbst innerhalb der von uns entwickelten Anwendung. Dieser Ansatz hat sowohl Vor- als auch Nachteile. Lassen Sie uns die Vorteile auflisten.
1. Verkehrseinsparungen:
- Sie können nicht alle Daten übertragen, sondern nur einen Teil davon (Sie können beispielsweise nur einige Tabellen, einige ihrer Spalten oder Datensätze übertragen, die ein bestimmtes Kriterium erfüllen);
- Im Gegensatz zur Low-Level-Replikation, die kontinuierlich im asynchronen (implementiert in der aktuellen Version von Tarantool - 1.10) oder synchronen (wird in späteren Versionen von Tarantool implementierten) Modus durchgeführt wird, kann die High-Level-Replikation in Sitzungen (d. h Die Anwendung synchronisiert zuerst die Daten – eine Datenaustauschsitzung, dann gibt es eine Pause in der Replikation, danach findet die nächste Austauschsitzung statt usw.);
- Wenn sich ein Datensatz mehrmals geändert hat, können Sie nur seine neueste Version übertragen (im Gegensatz zur Low-Level-Replikation, bei der alle auf dem Master vorgenommenen Änderungen nacheinander auf den Replikaten wiedergegeben werden).
2. Es gibt keine Schwierigkeiten bei der Implementierung des HTTP-Austauschs, der die Synchronisierung entfernter Datenbanken ermöglicht.
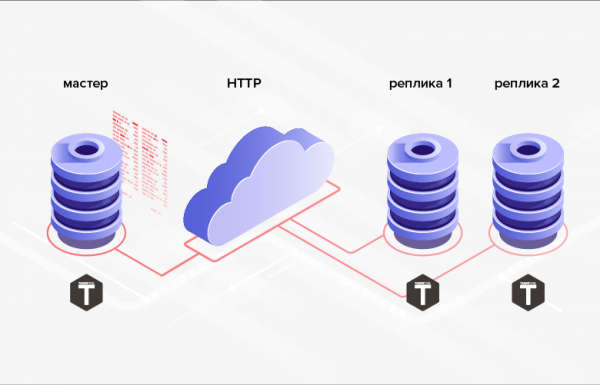
Reis. 2. Replikation über HTTP
3. Die Datenbankstrukturen, zwischen denen Daten übertragen werden, müssen nicht gleich sein (im Allgemeinen ist es sogar möglich, verschiedene DBMS, Programmiersprachen, Plattformen usw. zu verwenden).
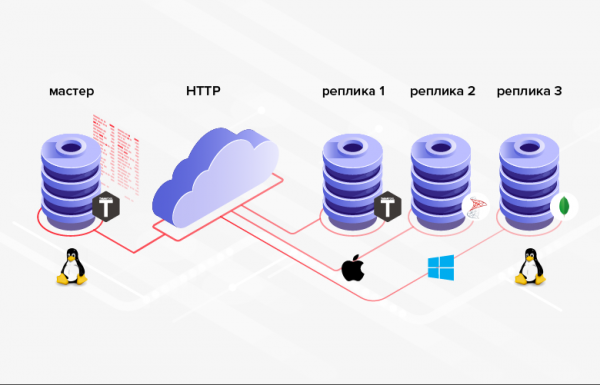
Reis. 3. Replikation in heterogenen Systemen
Der Nachteil besteht darin, dass die Programmierung im Durchschnitt schwieriger/kostspieliger ist als die Konfiguration, und anstatt die integrierten Funktionen anzupassen, müssen Sie Ihre eigenen implementieren.
Wenn in Ihrer Situation die oben genannten Vorteile entscheidend sind (oder eine notwendige Voraussetzung sind), dann ist es sinnvoll, eine Replikation auf hoher Ebene zu verwenden. Sehen wir uns verschiedene Möglichkeiten zur Implementierung einer Datenreplikation auf hoher Ebene im Tarantool-DBMS an.
Verkehrsminimierung
Einer der Vorteile der High-Level-Replikation ist also die Verkehrseinsparung. Damit dieser Vorteil voll zum Tragen kommt, ist es notwendig, die während jeder Austauschsitzung übertragene Datenmenge zu minimieren. Natürlich dürfen wir nicht vergessen, dass am Ende der Sitzung der Datenempfänger mit der Quelle synchronisiert werden muss (zumindest für den Teil der Daten, der an der Replikation beteiligt ist).
Wie kann die während der High-Level-Replikation übertragene Datenmenge minimiert werden? Eine einfache Lösung könnte darin bestehen, Daten nach Datum und Uhrzeit auszuwählen. Dazu können Sie das bereits in der Tabelle vorhandene Datum-Uhrzeit-Feld verwenden (sofern vorhanden). Beispielsweise kann ein Dokument „Bestellung“ ein Feld „Erforderliche Auftragsausführungszeit“ enthalten. delivery_time. Das Problem bei dieser Lösung besteht darin, dass die Werte in diesem Feld nicht in der Reihenfolge vorliegen müssen, die der Erstellung von Aufträgen entspricht. Daher können wir uns nicht an den maximalen Feldwert erinnern delivery_time, während der vorherigen Austauschsitzung übertragen, und wählen Sie während der nächsten Austauschsitzung alle Datensätze mit einem höheren Feldwert aus delivery_time. Möglicherweise wurden zwischen Austauschsitzungen Datensätze mit einem niedrigeren Feldwert hinzugefügt delivery_time. Außerdem könnte es zu Änderungen in der Bestellung gekommen sein, die jedoch keinen Einfluss auf den Bereich hatten delivery_time. In beiden Fällen werden die Änderungen nicht von der Quelle zum Ziel übertragen. Um diese Probleme zu lösen, müssen wir Daten „überlappend“ übertragen. Diese. In jeder Austauschsitzung übertragen wir alle Daten mit dem Feldwert delivery_time, einen bestimmten Punkt in der Vergangenheit überschreiten (z. B. N Stunden ab dem aktuellen Zeitpunkt). Es ist jedoch offensichtlich, dass dieser Ansatz für große Systeme hochredundant ist und die von uns angestrebten Verkehrseinsparungen zunichte machen kann. Darüber hinaus verfügt die übertragene Tabelle möglicherweise nicht über ein Feld, das mit einem Datum und einer Uhrzeit verknüpft ist.
Eine andere, in der Umsetzung aufwändigere Lösung besteht darin, den Empfang von Daten zu quittieren. In diesem Fall werden bei jeder Austauschsitzung alle Daten übermittelt, deren Empfang vom Empfänger nicht bestätigt wurde. Um dies zu implementieren, müssen Sie der Quelltabelle eine boolesche Spalte hinzufügen (z. B. is_transferred). Wenn der Empfänger den Empfang des Datensatzes bestätigt, übernimmt das entsprechende Feld den Wert true, danach ist der Eintrag nicht mehr am Austausch beteiligt. Diese Implementierungsoption hat die folgenden Nachteile. Zunächst muss für jeden übertragenen Datensatz eine Bestätigung generiert und versendet werden. Grob gesagt könnte dies einer Verdoppelung der übertragenen Datenmenge entsprechen und zu einer Verdoppelung der Anzahl der Roundtrips führen. Zweitens besteht keine Möglichkeit, denselben Datensatz an mehrere Empfänger zu senden (der erste Empfänger bestätigt den Empfang für sich selbst und für alle anderen).
Eine Methode, die die oben genannten Nachteile nicht aufweist, besteht darin, der übertragenen Tabelle eine Spalte hinzuzufügen, um Änderungen in ihren Zeilen zu verfolgen. Eine solche Spalte kann vom Typ „Datum/Uhrzeit“ sein und muss von der Anwendung jedes Mal, wenn Datensätze hinzugefügt/geändert werden, auf die aktuelle Zeit eingestellt/aktualisiert werden (atomar mit der Hinzufügung/Änderung). Als Beispiel nennen wir die Spalte update_time. Indem wir den maximalen Feldwert dieser Spalte für die übertragenen Datensätze speichern, können wir die nächste Austauschsitzung mit diesem Wert starten (Datensätze mit dem Feldwert auswählen). update_time, den zuvor gespeicherten Wert überschreiten). Das Problem bei letzterem Ansatz besteht darin, dass Datenänderungen stapelweise erfolgen können. Als Ergebnis der Feldwerte in der Spalte update_time ist möglicherweise nicht eindeutig. Daher kann diese Spalte nicht für die portionierte (seitenweise) Datenausgabe verwendet werden. Um Daten Seite für Seite anzuzeigen, müssen Sie zusätzliche Mechanismen erfinden, die höchstwahrscheinlich eine sehr geringe Effizienz haben (z. B. das Abrufen aller Datensätze mit dem Wert aus der Datenbank). update_time höher als angegeben und gibt eine bestimmte Anzahl von Datensätzen aus, beginnend mit einem bestimmten Offset vom Beginn des Beispiels).
Sie können die Effizienz der Datenübertragung verbessern, indem Sie den vorherigen Ansatz leicht verbessern. Dazu verwenden wir den Integer-Typ (Long Integer) als Spaltenfeldwerte zur Nachverfolgung von Änderungen. Benennen wir die Spalte row_ver. Der Feldwert dieser Spalte muss immer noch jedes Mal festgelegt/aktualisiert werden, wenn ein Datensatz erstellt/geändert wird. In diesem Fall wird dem Feld jedoch nicht das aktuelle Datum und die aktuelle Uhrzeit zugewiesen, sondern der Wert eines Zählers, erhöht um eins. Als Ergebnis die Spalte row_ver enthält eindeutige Werte und kann nicht nur zur Anzeige von „Delta“-Daten (seit dem Ende der vorherigen Austauschsitzung hinzugefügte/geänderte Daten) verwendet werden, sondern auch zur einfachen und effektiven Aufschlüsselung in Seiten.
Die zuletzt vorgeschlagene Methode zur Minimierung der im Rahmen der High-Level-Replikation übertragenen Datenmenge scheint mir die optimalste und universellste zu sein. Schauen wir es uns genauer an.
Übergeben von Daten mithilfe eines Zeilenversionszählers
Implementierung des Server-/Master-Teils
In MS SQL Server gibt es einen speziellen Spaltentyp, um diesen Ansatz zu implementieren – rowversion. Jede Datenbank verfügt über einen Zähler, der sich jedes Mal um eins erhöht, wenn ein Datensatz in einer Tabelle mit einer Spalte wie folgt hinzugefügt/geändert wird rowversion. Der Wert dieses Zählers wird automatisch dem Feld dieser Spalte im hinzugefügten/geänderten Datensatz zugewiesen. Das Tarantool-DBMS verfügt nicht über einen ähnlichen integrierten Mechanismus. In Tarantool ist es jedoch nicht schwierig, es manuell zu implementieren. Schauen wir uns an, wie das gemacht wird.
Zunächst ein wenig Terminologie: Tabellen werden in Tarantool Leerzeichen und Datensätze Tupel genannt. In Tarantool können Sie Sequenzen erstellen. Sequenzen sind nichts anderes als benannte Generatoren geordneter ganzzahliger Werte. Diese. Das ist genau das, was wir für unsere Zwecke brauchen. Im Folgenden erstellen wir eine solche Sequenz.
Bevor Sie eine Datenbankoperation in Tarantool ausführen, müssen Sie den folgenden Befehl ausführen:
box.cfg{}Infolgedessen beginnt Tarantool, Datenbank-Snapshots und Transaktionsprotokolle in das aktuelle Verzeichnis zu schreiben.
Lassen Sie uns eine Sequenz erstellen row_version:
box.schema.sequence.create('row_version',
{ if_not_exists = true })
Option if_not_exists ermöglicht die mehrfache Ausführung des Erstellungsskripts: Wenn das Objekt vorhanden ist, versucht Tarantool nicht, es erneut zu erstellen. Diese Option wird in allen nachfolgenden DDL-Befehlen verwendet.
Lassen Sie uns als Beispiel einen Raum erstellen.
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
},
{
name = 'row_ver',
type = 'unsigned'
}
},
if_not_exists = true
})
Hier legen wir den Namen des Raums fest (goods), Feldnamen und deren Typen.
Auch automatisch inkrementierende Felder in Tarantool werden mithilfe von Sequenzen erstellt. Lassen Sie uns einen automatisch inkrementierenden Primärschlüssel nach Feld erstellen id:
box.schema.sequence.create('goods_id',
{ if_not_exists = true })
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})Tarantool unterstützt mehrere Arten von Indizes. Die am häufigsten verwendeten Indizes sind TREE- und HASH-Typen, die auf Strukturen basieren, die dem Namen entsprechen. TREE ist der vielseitigste Indextyp. Es ermöglicht Ihnen, Daten auf organisierte Weise abzurufen. Für die Gleichheitsauswahl ist HASH jedoch besser geeignet. Dementsprechend empfiehlt es sich, HASH für den Primärschlüssel zu verwenden (was wir auch getan haben).
Um die Spalte zu verwenden row_ver Um geänderte Daten zu übertragen, müssen Sie Sequenzwerte an die Felder dieser Spalte binden row_ver. Aber im Gegensatz zum Primärschlüssel ist der Spaltenfeldwert row_ver sollte nicht nur beim Hinzufügen neuer Datensätze um eins erhöht werden, sondern auch beim Ändern vorhandener Datensätze. Hierfür können Sie Trigger verwenden. Tarantool verfügt über zwei Arten von Leerzeichen-Triggern: before_replace и on_replace. Trigger werden immer dann ausgelöst, wenn sich Daten im Bereich ändern (für jedes von den Änderungen betroffene Tupel wird eine Triggerfunktion gestartet). Im Gegensatz zu on_replace, before_replaceMit -Triggern können Sie die Daten des Tupels ändern, für das der Trigger ausgeführt wird. Dementsprechend passt die letzte Art von Auslösern zu uns.
box.space.goods:before_replace(function(old, new)
return box.tuple.new({new[1], new[2], new[3],
box.sequence.row_version:next()})
end)
Der folgende Trigger ersetzt den Feldwert row_ver gespeichertes Tupel zum nächsten Wert der Sequenz row_version.
Um Daten aus dem Weltraum extrahieren zu können goods nach Spalte row_ver, erstellen wir einen Index:
box.space.goods:create_index('row_ver', {
parts = { 'row_ver' },
unique = true,
type = 'TREE',
if_not_exists = true
})
Indextyp - Baum (TREE), Weil Wir müssen die Daten in aufsteigender Reihenfolge der Werte in der Spalte extrahieren row_ver.
Fügen wir dem Raum einige Daten hinzu:
box.space.goods:insert{nil, 'pen', 123}
box.space.goods:insert{nil, 'pencil', 321}
box.space.goods:insert{nil, 'brush', 100}
box.space.goods:insert{nil, 'watercolour', 456}
box.space.goods:insert{nil, 'album', 101}
box.space.goods:insert{nil, 'notebook', 800}
box.space.goods:insert{nil, 'rubber', 531}
box.space.goods:insert{nil, 'ruler', 135}
Weil Das erste Feld ist ein automatisch inkrementierender Zähler; wir übergeben stattdessen Null. Tarantool ersetzt automatisch den nächsten Wert. Ebenso wie der Wert der Spaltenfelder row_ver Sie können Null übergeben – oder den Wert überhaupt nicht angeben, weil Diese Spalte nimmt die letzte Position im Raum ein.
Überprüfen wir das Einfügeergebnis:
tarantool> box.space.goods:select()
---
- - [1, 'pen', 123, 1]
- [2, 'pencil', 321, 2]
- [3, 'brush', 100, 3]
- [4, 'watercolour', 456, 4]
- [5, 'album', 101, 5]
- [6, 'notebook', 800, 6]
- [7, 'rubber', 531, 7]
- [8, 'ruler', 135, 8]
...
Wie Sie sehen, werden das erste und das letzte Feld automatisch ausgefüllt. Jetzt ist es einfach, eine Funktion zum seitenweisen Hochladen von Space-Änderungen zu schreiben goods:
local page_size = 5
local function get_goods(row_ver)
local index = box.space.goods.index.row_ver
local goods = {}
local counter = 0
for _, tuple in index:pairs(row_ver, {
iterator = 'GT' }) do
local obj = tuple:tomap({ names_only = true })
table.insert(goods, obj)
counter = counter + 1
if counter >= page_size then
break
end
end
return goods
end
Als Parameter übernimmt die Funktion den Wert row_ver, ab dem die Änderungen entladen werden müssen, und gibt einen Teil der geänderten Daten zurück.
Die Datenerfassung in Tarantool erfolgt über Indizes. Funktion get_goods verwendet einen Iterator nach Index row_ver um geänderte Daten zu erhalten. Der Iteratortyp ist GT (Greater Than, größer als). Dies bedeutet, dass der Iterator die Indexwerte ausgehend vom übergebenen Schlüssel (Feldwert) nacheinander durchläuft row_ver).
Der Iterator gibt Tupel zurück. Um anschließend Daten über HTTP übertragen zu können, ist es notwendig, die Tupel in eine für die spätere Serialisierung geeignete Struktur zu konvertieren. Das Beispiel verwendet hierfür die Standardfunktion tomap. Anstatt zu verwenden tomap Sie können Ihre eigene Funktion schreiben. Beispielsweise möchten wir möglicherweise ein Feld umbenennen name, das Feld nicht passieren code und fügen Sie ein Feld hinzu comment:
local function unflatten_goods(tuple)
local obj = {}
obj.id = tuple.id
obj.goods_name = tuple.name
obj.comment = 'some comment'
obj.row_ver = tuple.row_ver
return obj
end
Die Seitengröße der Ausgabedaten (die Anzahl der Datensätze in einem Teil) wird durch die Variable bestimmt page_size. Im Beispiel der Wert page_size ist 5. In einem echten Programm ist die Seitengröße normalerweise wichtiger. Dies hängt von der durchschnittlichen Größe des Raumtupels ab. Die optimale Seitengröße kann empirisch durch Messung der Datenübertragungszeit ermittelt werden. Je größer die Seitengröße, desto geringer ist die Anzahl der Roundtrips zwischen der sendenden und der empfangenden Seite. Auf diese Weise können Sie die Gesamtzeit für das Herunterladen von Änderungen verkürzen. Wenn die Seitengröße jedoch zu groß ist, verbringen wir zu viel Zeit damit, das Beispiel auf dem Server zu serialisieren. Dadurch kann es zu Verzögerungen bei der Verarbeitung anderer Anfragen kommen, die an den Server gehen. Parameter page_size kann aus der Konfigurationsdatei geladen werden. Für jedes übertragene Leerzeichen können Sie einen eigenen Wert festlegen. Für die meisten Leerzeichen kann jedoch der Standardwert (z. B. 100) geeignet sein.
Lassen Sie uns die Funktion ausführen get_goods:
tarantool> get_goods(0)
---
- - row_ver: 1
code: 123
name: pen
id: 1
- row_ver: 2
code: 321
name: pencil
id: 2
- row_ver: 3
code: 100
name: brush
id: 3
- row_ver: 4
code: 456
name: watercolour
id: 4
- row_ver: 5
code: 101
name: album
id: 5
...
Nehmen wir den Feldwert row_ver aus der letzten Zeile und rufen Sie die Funktion erneut auf:
tarantool> get_goods(5)
---
- - row_ver: 6
code: 800
name: notebook
id: 6
- row_ver: 7
code: 531
name: rubber
id: 7
- row_ver: 8
code: 135
name: ruler
id: 8
...Und nochmal:
tarantool> get_goods(8)
---
- []
...
Wie Sie sehen, gibt die Funktion bei dieser Verwendung alle Space-Datensätze Seite für Seite zurück goods. Auf die letzte Seite folgt eine leere Auswahl.
Nehmen wir Änderungen am Raum vor:
box.space.goods:update(4, {{'=', 6, 'copybook'}})
box.space.goods:insert{nil, 'clip', 234}
box.space.goods:insert{nil, 'folder', 432}
Wir haben den Feldwert geändert name für einen Eintrag und fügte zwei neue Einträge hinzu.
Wiederholen wir den letzten Funktionsaufruf:
tarantool> get_goods(8)
---
- - row_ver: 9
code: 800
name: copybook
id: 6
- row_ver: 10
code: 234
name: clip
id: 9
- row_ver: 11
code: 432
name: folder
id: 10
...
Die Funktion hat die geänderten und hinzugefügten Datensätze zurückgegeben. Also die Funktion get_goods ermöglicht den Empfang von Daten, die sich seit dem letzten Aufruf geändert haben und die Grundlage der betrachteten Replikationsmethode sind.
Die Ausgabe von Ergebnissen über HTTP in Form von JSON wird in diesem Artikel nicht behandelt. Dies können Sie hier nachlesen:
Implementierung des Client/Slave-Teils
Schauen wir uns an, wie die Implementierung auf der empfangenden Seite aussieht. Erstellen wir auf der Empfängerseite einen Platz zum Speichern der heruntergeladenen Daten:
box.schema.space.create('goods', {
format = {
{
name = 'id',
type = 'unsigned'
},
{
name = 'name',
type = 'string'
},
{
name = 'code',
type = 'unsigned'
}
},
if_not_exists = true
})
box.space.goods:create_index('primary', {
parts = { 'id' },
sequence = 'goods_id',
unique = true,
type = 'HASH',
if_not_exists = true
})
Die Struktur des Raumes ähnelt der Struktur des Raumes in der Quelle. Da wir die empfangenen Daten aber nirgendwo anders weitergeben werden, ist die Spalte row_ver befindet sich nicht im Bereich des Empfängers. Auf dem Feld id Quellenkennungen werden aufgezeichnet. Daher besteht auf der Empfängerseite keine Notwendigkeit, die automatische Inkrementierung vorzunehmen.
Darüber hinaus brauchen wir einen Raum zum Speichern von Werten row_ver:
box.schema.space.create('row_ver', {
format = {
{
name = 'space_name',
type = 'string'
},
{
name = 'value',
type = 'string'
}
},
if_not_exists = true
})
box.space.row_ver:create_index('primary', {
parts = { 'space_name' },
unique = true,
type = 'HASH',
if_not_exists = true
})
Für jeden geladenen Raum (field space_name) speichern wir hier den zuletzt geladenen Wert row_ver (Feld value). Die Spalte fungiert als Primärschlüssel space_name.
Erstellen wir eine Funktion zum Laden von Raumdaten goods über HTTP. Dazu benötigen wir eine Bibliothek, die einen HTTP-Client implementiert. Die folgende Zeile lädt die Bibliothek und instanziiert den HTTP-Client:
local http_client = require('http.client').new()Wir benötigen außerdem eine Bibliothek für die JSON-Deserialisierung:
local json = require('json')Dies reicht aus, um eine Datenladefunktion zu erstellen:
local function load_data(url, row_ver)
local url = ('%s?rowVer=%s'):format(url,
tostring(row_ver))
local body = nil
local data = http_client:request('GET', url, body, {
keepalive_idle = 1,
keepalive_interval = 1
})
return json.decode(data.body)
end
Die Funktion führt eine HTTP-Anfrage an die URL-Adresse aus und sendet diese row_ver als Parameter und gibt das deserialisierte Ergebnis der Anfrage zurück.
Die Funktion zum Speichern empfangener Daten sieht folgendermaßen aus:
local function save_goods(goods)
local n = #goods
box.atomic(function()
for i = 1, n do
local obj = goods[i]
box.space.goods:put(
obj.id, obj.name, obj.code)
end
end)
end
Zyklus zum Speichern von Daten im Weltraum goods in eine Transaktion gestellt (hierfür wird die Funktion verwendet). box.atomic), um die Anzahl der Festplattenvorgänge zu reduzieren.
Schließlich die lokale Raumsynchronisationsfunktion goods Mit einer Quelle können Sie es so implementieren:
local function sync_goods()
local tuple = box.space.row_ver:get('goods')
local row_ver = tuple and tuple.value or 0
—— set your url here:
local url = 'http://127.0.0.1:81/test/goods/list'
while true do
local goods = load_goods(url, row_ver)
local count = #goods
if count == 0 then
return
end
save_goods(goods)
row_ver = goods[count].rowVer
box.space.row_ver:put({'goods', row_ver})
end
end
Zuerst lesen wir den zuvor gespeicherten Wert aus row_ver für Platz goods. Wenn es fehlt (die erste Austauschsitzung), dann nehmen wir es als row_ver null. Als nächstes führen wir im Zyklus einen seitenweisen Download der geänderten Daten von der Quelle unter der angegebenen URL durch. Bei jeder Iteration speichern wir die empfangenen Daten im entsprechenden lokalen Bereich und aktualisieren den Wert row_ver (im Weltraum row_ver und in der Variablen row_ver) - nimm den Wert row_ver ab der letzten Zeile der geladenen Daten.
Zum Schutz vor versehentlichem Schleifendurchlauf (im Falle eines Fehlers im Programm) wird die Schleife while kann ersetzt werden durch for:
for _ = 1, max_req do ...
Als Ergebnis der Ausführung der Funktion sync_goods Raum goods Der Empfänger enthält die neuesten Versionen aller Weltraumaufzeichnungen goods in der Quelle.
Offensichtlich kann die Datenlöschung auf diese Weise nicht verbreitet werden. Wenn ein solcher Bedarf besteht, können Sie eine Löschmarkierung verwenden. Zum Platz hinzufügen goods boolesches Feld is_deleted und anstatt einen Datensatz physisch zu löschen, verwenden wir die logische Löschung – wir legen den Feldwert fest is_deleted in die Bedeutung true. Manchmal anstelle eines booleschen Feldes is_deleted Es ist bequemer, das Feld zu verwenden deleted, das das Datum und die Uhrzeit der logischen Löschung des Datensatzes speichert. Nach der Durchführung eines logischen Löschvorgangs wird der zum Löschen markierte Datensatz von der Quelle zum Ziel übertragen (gemäß der oben erläuterten Logik).
Sequenz row_ver kann zur Übertragung von Daten aus anderen Räumen verwendet werden: Es ist nicht erforderlich, für jeden übertragenen Raum eine separate Sequenz zu erstellen.
Wir haben eine effektive Möglichkeit zur Datenreplikation auf hoher Ebene in Anwendungen mithilfe des Tarantool-DBMS untersucht.
Befund
- Tarantool DBMS ist ein attraktives, vielversprechendes Produkt für die Erstellung hochlastiger Anwendungen.
- Die Datenreplikation auf hoher Ebene hat gegenüber der Replikation auf niedriger Ebene eine Reihe von Vorteilen.
- Mit der im Artikel beschriebenen High-Level-Replikationsmethode können Sie die Menge der übertragenen Daten minimieren, indem Sie nur die Datensätze übertragen, die sich seit der letzten Austauschsitzung geändert haben.
Source: habr.com
