

Ich teile aus persönlicher Erfahrung, was wo und wann hilfreich war. Eine Übersicht mit Kernaussagen, damit klar ist, was und wo weiter erforscht werden kann – aber hier beziehe ich mich ausschließlich auf meine subjektive persönliche Erfahrung, bei Ihnen könnte es ganz anders sein.
Warum ist es wichtig, sich mit Abfragesprachen auszukennen? Im Wesentlichen gibt es in der Datenwissenschaft mehrere entscheidende Arbeitsschritte, und der erste und wichtigste (ohne den funktioniert nichts!) ist das Abrufen oder Extrahieren von Daten. In der Regel sitzen die Daten in irgendeiner Form irgendwo und müssen von dort "herausgeholt" werden.
Abfragesprachen ermöglichen genau das Extrahieren dieser Daten! Heute werde ich Ihnen von den Abfragesprachen erzählen, die mir nützlich waren, und ich werde Ihnen zeigen, wo und wie genau – warum es wichtig ist, sie zu lernen.
Es wird insgesamt drei Hauptkategorien von Abfragen geben, die wir in diesem Artikel behandeln werden:
- "Standard"-Abfragesprachen – das, was üblicherweise gemeint ist, wenn man von Abfragesprachen spricht, wie etwa relationale Algebra oder SQL.
- Skriptsprache-Abfragen: zum Beispiel Python-Bibliotheken wie Pandas, Numpy oder Shell-Scripting.
- Abfragesprachen für Wissensgraphen und graphbasierte Datenbanken.
Alles, was hier geschrieben steht, ist nur persönliche Erfahrung, die sich als nützlich erwiesen hat, mit der Beschreibung von Situationen und dem „Warum es notwendig war“ – jeder kann überlegen, wie oft ähnliche Situationen auf ihn zukommen könnten, und versuchen, sich im Voraus darauf vorzubereiten, indem er sich mit diesen Sprachen auseinandersetzt, bevor er sie (dringend) in einem Projekt anwenden muss oder überhaupt in ein Projekt kommt, wo sie benötigt werden.
„Standard“-Abfragesprachen
Abfragesprachen im Standard-Sinne bedeuten, dass wir normalerweise genau an sie denken, wenn wir von Abfragen sprechen.
Relationale Algebra
Warum ist relationale Algebra heute notwendig? Um ein gutes Verständnis dafür zu haben, warum Abfragesprachen auf eine bestimmte Weise aufgebaut sind und um sie bewusst zu verwenden, muss man sich mit dem Kern beschäftigen, der diesen zugrunde liegt.
Was ist relationale Algebra?
Die formale Definition lautet: Relationale Algebra ist ein abgeschlossenes System von Operationen über Beziehungen im relationalen Datenmodell. Wenn man es etwas verständlicher ausdrücken möchte, ist es ein System von Operationen über Tabellen, sodass das Ergebnis ebenfalls immer eine Tabelle ist.
Siehe alle relationalen Operationen in In diesem Artikel von Habr — hier beschreiben wir, warum es wichtig ist, zu wissen und wo es nützlich sein kann.
Warum?
Du beginnst zu verstehen, wie sich die Abfragesprachen zusammensetzen und welche Operationen hinter den Ausdrücken spezifischer Abfragesprachen stehen — das gibt oft ein tieferes Verständnis dafür, was und wie in Abfragesprachen funktioniert.
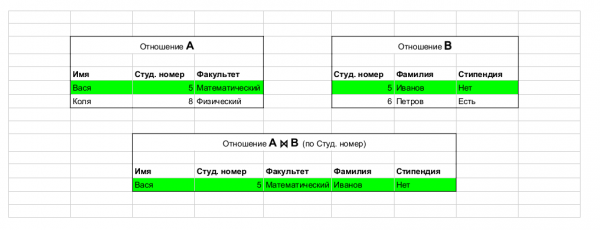
Entnommen aus einem Artikel. Beispiel für eine Operation: join, die Tabellen miteinander verbindet.
Materialien zum Lernen:
. Generell gibt es viele Materialien zur relationalen Algebra und Theorie — Coursera, Udacity. Es gibt auch eine riesige Anzahl an Materialien online, darunter gute . Mein persönlicher Rat: Es ist wichtig, die relationale Algebra sehr gut zu verstehen — das ist die Grundlage.
SQL

Entnommen aus des Artikels gehen.
SQL ist im Grunde eine Implementierung der relationalen Algebra — mit dem wichtigen Hinweis, dass SQL deklarativ ist! Das heißt, wenn du eine Anfrage in der Sprache der relationalen Algebra schreibst, sagst du faktisch, wie die Berechnung erfolgen soll — während du mit SQL angibst, was du extrahieren möchtest, und die Datenbankmanagementsystem (DBMS) generiert dann (effektive) Ausdrücke in der Sprache der relationalen Algebra (deren Äquivalenz ist uns als ).
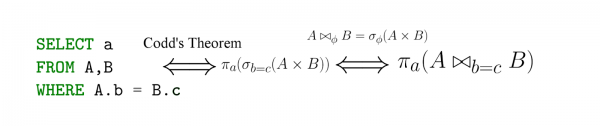
Entnommen aus des Artikels gehen.
Warum?
Relationale Datenbanken: Oracle, Postgres, SQL Server usw. sind nach wie vor nahezu überall anzutreffen. Die Wahrscheinlichkeit ist groß, dass Sie mit ihnen in Kontakt kommen, was bedeutet, dass Sie entweder SQL lesen müssen (was sehr wahrscheinlich ist) oder es sogar selbst schreiben (was ebenfalls nicht unwahrscheinlich ist).
Was zu lesen und zu lernen
Über die obigen Links (zur relationalen Algebra) gibt es eine unglaubliche Menge an Material, zum Beispiel: .
Übrigens, was ist NoSQL?
„Es sollte nochmals betont werden, dass der Begriff ‚NoSQL‘ absolut spontan entstanden ist und keine allgemein akzeptierte Definition oder wissenschaftliche Institution hinter sich hat.“ Entsprechend auf Habr erstellt haben.
Im Grunde genommen haben die Menschen erkannt, dass das vollständige relationale Modell für viele Aufgaben nicht erforderlich ist, insbesondere für solche, bei denen beispielsweise die Leistung entscheidend ist und bestimmte einfache Abfragen mit Aggregation dominieren. Hier ist es entscheidend, Metriken schnell zu berechnen und sie in die Datenbank zu schreiben. Viele Merkmale relationaler Systeme erwiesen sich nicht nur als unnötig, sondern sogar als schädlich. Warum sollte man etwas normalisieren, wenn es die für uns (für eine bestimmte Aufgabe) wichtigste Anforderung, nämlich die Leistung, beeinträchtigt?
Häufig benötigte flexible Modelle statt starrer mathematischer Modelle der klassischen relationalen Datenbank – das vereinfacht die Anwendungsentwicklung enorm, wenn es darauf ankommt, das System schnell zu implementieren und zu arbeiten, um Ergebnisse zu verarbeiten – oder die Struktur und die Arten der gespeicherten Daten sind nicht so entscheidend.
Wenn wir beispielsweise ein Expertensystem erstellen und Informationen zu einem bestimmten Bereich zusammen mit einigen Metainformationen speichern möchten – könnten wir nicht alle Felder kennen und einfach JSON für jeden Datensatz speichern – was uns eine sehr flexible Umgebung für die Erweiterung des Datenmodells und schnelles Iterieren bietet – weshalb in diesem Fall NoSQL sogar vorzuziehen und lesbarer ist. Ein Beispiel aus einem meiner Projekte, in dem NoSQL genau dort eingesetzt wurde, wo es notwendig war.
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775,"Джонни Кэш","ru"],
"en_wiki_pagecount":2338861}
Mehr dazu können Sie lesen über NoSQL.
Was sollte ich lernen?
Hier ist es wichtig, seine Aufgaben gut zu analysieren, ihre Eigenschaften zu verstehen und die passenden NoSQL-Systeme zu identifizieren, bevor man mit dem Studium einer bestimmten Lösung beginnt.
Script-Programmiersprachen
Zunächst scheint es, als hätte Python damit überhaupt nichts zu tun – es ist eine Programmiersprache und nicht direkt für Abfragen gedacht.

- Pandas ist wie das Schweizer Taschenmesser der Datenwissenschaft; hier finden zahlreiche Datenumwandlungen, Aggregationen usw. statt.
- Numpy beschäftigt sich mit vektorisierten Berechnungen, Matrizen und linearer Algebra.
- Scipy bietet viele mathematische Funktionen, insbesondere in der Statistik.
- Jupyter Lab eignet sich hervorragend für explorative Datenanalysen und ist nützlich, um mit Notebooks zu arbeiten.
- Requests ermöglichen die einfache Kommunikation mit Netzwerken.
- Pyspark ist unter Dateningenieuren sehr beliebt, und es ist wahrscheinlich, dass Sie mit diesem oder Spark in Berührung kommen werden, einfach aufgrund ihrer Popularität.
- *Selenium ist äußerst nützlich zum Scraping von Daten von Websites und Ressourcen, da man manchmal anders keine Daten erhalten kann.
Mein größter Ratschlag: Lernen Sie Python!
Pandas
Lassen Sie uns als Beispiel den folgenden Code betrachten:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Berechne und benenne Aggregationen um
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': 'min_duration_seconds',
‘amax': 'max_duration_seconds'}))Im Grunde sehen wir, dass der Code in ein klassisches SQL-Muster passt.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUP BY start_station_name, end_station_nameEin wichtiger Punkt ist, dass dieser Code Teil eines Skripts und Pipelines ist; faktisch integrieren wir Abfragen in eine Python-Pipeline. In dieser Situation stammt die Abfragesprache aus Bibliotheken wie Pandas oder pySpark.
Insgesamt sehen wir in pySpark einen ähnlichen Datentransformationstyp durch die Abfragesprache in folgendem Stil:
df.filter(df.trip_type = “return”)
.groupby(“day”)
.agg({duration: 'mean'})
.sort()Wo und was zu lesen
Über Python insgesamt Materialien zu finden, um zu lernen. Im Internet gibt es eine riesige Menge an Tutorials zu , und Kursen über (sowie über ). Insgesamt sind die Materialien hier großartig auffindbar, und wenn ich ein Paket auswählen müsste, auf das ich mich konzentrieren sollte, dann wäre es natürlich pandas. Auch die Kombination von DS + Python hat viele Materialien. .
Shell als Abfragesprache
Es gibt zahlreiche Projekte zur Datenverarbeitung und -analyse, mit denen ich gearbeitet habe – das sind im Grunde shell-Skripte, die Code in Python und Java aufrufen sowie die Shell-Kommandos selbst. Deshalb kann man Pipelines in bash/zsh/etc. als eine Art hochstufige Abfrage betrachten (man kann auch Schleifen einfügen, aber das ist untypisch für DS-Code in Shell-Sprachen). Hier ein einfaches Beispiel – ich musste ein Mapping von QID in Wikidata zu den vollständigen Links in der russischen und englischen Wikipedia erstellen, dafür habe ich eine einfache Abfrage aus Bash-Kommandos geschrieben und zur Ausgabe ein einfaches Skript in Python verfasst, das ich so zusammengebaut habe:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
wobei
JQ_QUERY = 'select((.[0][1] == "sitelinks" und (.[0][2]=="enwiki" oder .[0][2] =="ruwiki") und .[0][3] =="title") oder .[0][1] == "id")' Das war im Grunde die gesamte Pipeline, die das erforderliche Mapping erstellt hat. Wie wir sehen, lief alles im Stream-Modus:
- pv filepath — zeigt einen Fortschrittsbalken basierend auf der Dateigröße und gibt den Inhalt weiter
- unpigz -c las einen Teil des Archivs und gab ihn an jq weiter
- jq mit dem Schlüssel — stream gab sofort das Ergebnis aus und übergab es dem Nachbearbeiter (genauso wie im ersten Beispiel) in Python
- Im Nachbearbeiter — handelt es sich um eine einfache Zustandsmaschine, die die Ausgabe formatiert
Insgesamt ein komplexer Pipeline, der im Streaming-Modus mit großen Daten (0,5 TB) läuft, ohne wesentliche Ressourcen, und aus einer einfachen Pipeline und einigen Tools besteht.
Ein weiterer wichtiger Rat: Lernen Sie, effektiv und gut im Terminal zu arbeiten und in bash/zsh/etc. zu schreiben.
Wo ist das nützlich? Fast überall — es gibt WIRKLICH viele Materialien im Internet zu lernen. Insbesondere hier mein vorheriger Artikel.
R-Scripting
Wieder könnte der Leser ausrufen — das ist doch eine ganze Programmiersprache! Und er hätte absolut recht. Allerdings habe ich R meistens in einem Kontext erlebt, der eigentlich sehr ähnlich zu einer Abfragesprache war.
R ist eine Umgebung für statistische Berechnungen sowie eine Sprache für statistische Berechnungen und Visualisierung (laut ).
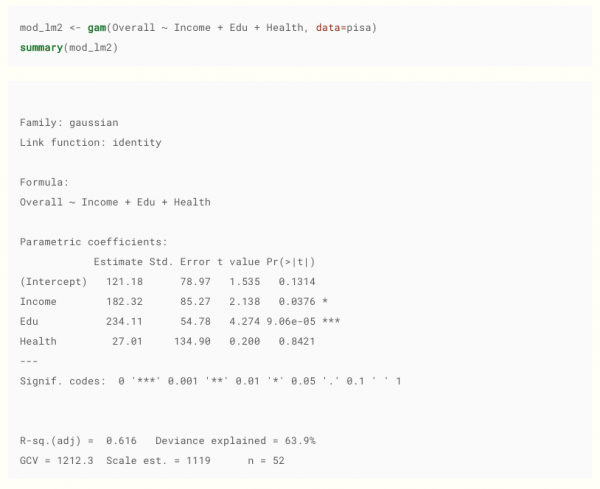
Entnommen . Übrigens empfehlenswert, ein gutes Material.
Warum sollte ein Data Scientist R kennen? Mindestens weil es eine große Anzahl von Personen außerhalb der IT gibt, die Datenanalyse mit R betreiben. Mir sind folgende Bereiche begegnet:
- Pharmazeutischer Sektor.
- Biologen.
- Finanzsektor.
- Menschen mit rein mathematischem Hintergrund, die sich mit Statistik beschäftigen.
- Spezialisierte statistische Modelle und Maschinenlernmodelle (die häufig nur in einer Autorenversion als R-Paket verfügbar sind).
Warum ist es tatsächlich eine Abfragesprache? In der Form, wie sie häufig vorkommt, dient sie tatsächlich zur Modellierung, einschließlich des Lesens von Daten und der Festlegung der Abfrageparameter (Modelle), sowie der Datenvisualisierung in Paketen wie ggplot2 — dies ist auch eine Form des Schreibens von Abfragen.
Beispielabfragen zur Visualisierung
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))Insgesamt sind viele Ideen aus R in Python-Pakete wie pandas, numpy oder scipy übergegangen, beispielsweise in DataFrames und Datenvektorisierung — viele Dinge in R werden Ihnen daher vertraut und angenehm erscheinen.
Es gibt viele Quellen zum Lernen, zum Beispiel: .
Wissensgraph (Knowledge graph)
Hier habe ich eine etwas ungewöhnliche Erfahrung, da ich häufig mit Wissensgraphen und den Abfragesprachen für diese Graphen arbeite. Daher werden wir nur kurz die Grundlagen durchgehen, da dieser Teil etwas exotischer ist.
In klassischen relationalen Datenbanken haben wir ein festgelegtes Schema – hier hingegen ist das Schema flexibel, jedes Prädikat entspricht faktisch einer „Spalte“ und sogar mehr.
Stellen Sie sich vor, Sie würden eine Person modellieren und möchten die wichtigsten Merkmale beschreiben. Nehmen wir als Beispiel die konkrete Person Douglas Adams und verwenden wir diese Beschreibung als Grundlage.
Wenn wir eine relationale Datenbank verwenden würden, müssten wir eine riesige Tabelle oder Tabellen mit einer Vielzahl von Spalten erstellen, von denen die meisten NULL oder mit einem Standardwert von False gefüllt wären. Zum Beispiel haben wahrscheinlich nur wenige von uns einen Eintrag in der nationalen koreanischen Bibliothek. Natürlich könnten wir diese in separate Tabellen auslagern, doch letztlich wäre das der Versuch, ein flexibles logisches Schema mit Prädikaten mithilfe einer festen relationalen Struktur zu modellieren.
Stellen Sie sich vor, dass alle Daten in Form eines Graphen oder als binäre und unäre logische Ausdrücke gespeichert werden.
Wo können Sie überhaupt auf so etwas stoßen? Zunächst einmal bei der Arbeit mit , sowie mit beliebigen graphbasierten Datenbanken oder relationalen Daten.
Im Folgenden finden Sie die wichtigsten Abfragesprachen, die ich anwenden musste und mit denen ich gearbeitet habe.
SPARQL
Wiki:
SPARQL ( ab SPARQL-Protokoll und RDF-Abfragesprache) — die nach dem Modell , sowie zur Übertragung dieser Abfragen und Antworten dient. SPARQL ist eine Empfehlung des und eine der Technologien .
Tatsächlich ist es eine Abfragesprache für logische unäre und binäre Prädikate. Es wird einfach условно angegeben, was im logischen Ausdruck festgelegt ist und was nicht (sehr vereinfacht).
Die RDF-Datenbank (Resource Description Framework), auf der SPARQL-Abfragen ausgeführt werden, besteht aus einem Triple. Objekt, Prädikat, Subjekt. — und die Anfrage wählt die erforderlichen Gruppen basierend auf den angegebenen Einschränkungen aus, wie: finde ein solches X, dass p_55(X, q_33) wahr ist — wobei p_55 natürlich eine Beziehung mit ID 55 ist und q_33 ein Objekt mit ID 33 (und das ist die ganze Geschichte, wobei wir alle möglichen Details weglassen).
Beispiel für die Datenpräsentation:
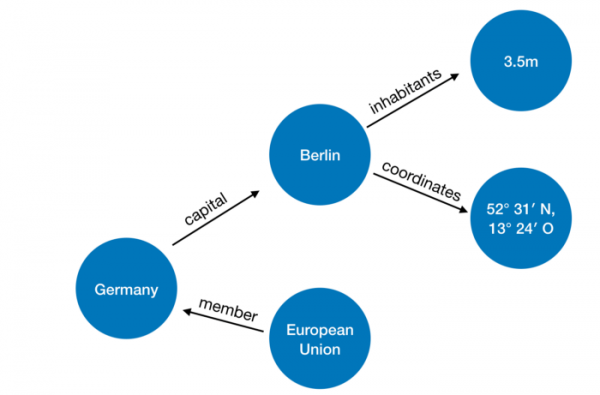
Bilder und Beispiel mit Ländern sind hier .
Beispiel einer grundlegenden Anfrage

Tatsächlich möchten wir den Wert der Variablen ?country finden, sodass für das Prädikat
member_of, wahr ist, dass member_of(?country, q458), wobei q458 die ID der Europäischen Union ist.
Beispiel einer realen SPARQL-Abfrage innerhalb der Python-Engine:
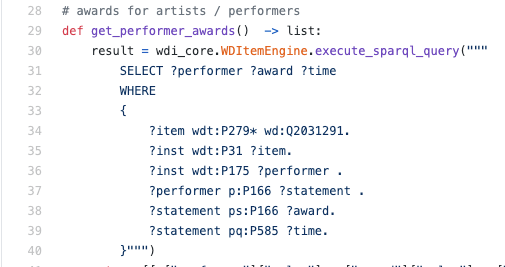
In der Regel habe ich SPARQL gelesen und nicht geschrieben – in einer solchen Situation ist es wahrscheinlich hilfreich, die Sprache zumindest auf einem grundlegenden Niveau zu verstehen, um zu begreifen, wie die Daten tatsächlich abgerufen werden.
Online gibt es viele Materialien zum Lernen: hier zum Beispiel und . Ich suche normalerweise nach spezifischen Konstruktionen und Beispielen und es reicht bisher aus.
Logische Abfragesprachen
Mehr zu diesem Thema kann in meinem Artikel gelesen werden. . Hier erklären wir kurz, warum logische Sprachen gut geeignet sind, um Anfragen zu formulieren. Im Grunde genommen ist RDF einfach eine Sammlung von logischen Aussagen in der Form p(X) und h(X,Y), während eine logische Anfrage folgenden Aufbau hat:
output(X) :- country(X), member_of(X, "EU").
Hier sprechen wir über die Erstellung eines neuen Prädikats output/1 ( /1 steht für unär), unter der Bedingung, dass für X gilt, dass country(X) — d.h. X ist ein Land und auch member_of(X, "EU").
Das bedeutet, dass sowohl die Daten als auch die Regeln in diesem Fall völlig identisch dargestellt sind, was das Modellieren von Aufgaben sehr einfach und effektiv macht.
Wo wir in der Branche aufgetroffen sind: Ein umfangreiches Projekt mit einem Unternehmen, das auf dieser Sprache Anfragen schreibt, sowie im aktuellen Projekt im Kernsystem — auf den ersten Blick scheint es etwas exotisch zu sein, kommt jedoch manchmal vor.
Ein Beispiel für einen Codeausschnitt in einer logischen Sprache, der Wikidata verarbeitet:
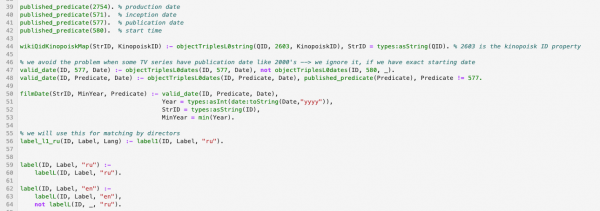
Materialien: Ich werde hier ein paar Links zu der modernen logischen Programmiersprache Answer Set Programming bereitstellen — ich empfehle, genau diese zu studieren:
Quelle: habr.com
