

Data Science für Einsteiger
1. Sentiment-Analyse (Stimmungsanalyse durch Text)

Sehen Sie sich die vollständige Implementierung des Data Science-Projekts mit Quellcode an — .
Die Sentiment-Analyse analysiert Wörter, um Stimmungen und Meinungen zu bestimmen, die positiv oder negativ sein können. Dies ist eine Art der Klassifikation, bei der die Klassen binär (positiv und negativ) oder mehrere (glücklich, wütend, traurig, unangenehm …) sein können. Wir werden dieses Data Science-Projekt in der Sprache R umsetzen und ein Datenset aus dem Paket „janeaustenR“ verwenden. Wir werden allgemeine Wörterbücher wie AFINN, bing und loughran nutzen, interne Joins durchführen, und am Ende erstellen wir eine Word Cloud, um das Ergebnis darzustellen.
Sprache: R
Datensatz/Packet: janeaustenR
Der Artikel wurde mit Unterstützung von EDISON Software übersetzt, einem Unternehmen, das , sowie .
2. Fake News-Erkennung (Erkennung von Fake News)
Bringen Sie Ihre Fähigkeiten auf ein neues Niveau, indem Sie an einem Data Science-Projekt für Einsteiger arbeiten — .
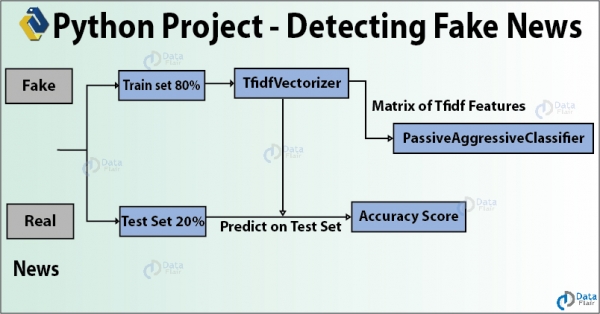
Falsche Nachrichten sind falsche Informationen, die über soziale Medien und andere Online-Medien verbreitet werden, um politische Ziele zu erreichen. In diesem Data-Science-Projekt werden wir Python einsetzen, um ein Modell zu entwickeln, das genau bestimmen kann, ob eine Nachricht echt oder falsch ist. Wir werden TfidfVectorizer erstellen und den PassiveAggressiveClassifier verwenden, um Nachrichten in "echt" und "falsch" zu klassifizieren. Wir werden einen Datensatz mit der Form 7796 × 4 verwenden und alles im Jupyter Lab durchführen.
Sprache: Python
Datensatz/Packet: news.csv
3. Detecting Parkinson’s Disease (Erkennung der Parkinson-Krankheit)
Gehen Sie voran, indem Sie an der Idee des Data-Science-Projekts arbeiten – .
Wir haben begonnen, Data Science zur Verbesserung der Gesundheitsversorgung und Dienstleistungen zu nutzen — wenn wir eine Krankheit im Frühstadium vorhersagen können, haben wir viele Vorteile. In diesem Data Science-Projekt lernen wir, die Parkinson-Krankheit mit Python zu erkennen. Dies ist eine neurodegenerative, fortschreitende Erkrankung des zentralen Nervensystems, die sich auf die Beweglichkeit auswirkt und Zittern und Steifheit verursacht. Sie betrifft die Dopamin-produzierenden Neuronen im Gehirn und jedes Jahr sind mehr als 1 Million Menschen in Indien betroffen.
Sprache: Python
Datensatz/Packet: UCI ML Parkinsons-Datensatz
Data Science-Projekte mittlerer Schwierigkeit
4. Speech Emotion Recognition (Emotionserkennung aus Sprache)
Sehen Sie sich die vollständige Umsetzung des Data Science-Projekts an — .
Lassen Sie uns nun lernen, wie man verschiedene Bibliotheken verwendet. Dieses Data-Science-Projekt nutzt librosa zur Spracherkennung. SER ist der Prozess, menschliche Emotionen und affektive Zustände anhand der Sprache zu erkennen. Da wir Ton und Tonhöhe zur Ausdruck von Emotionen verwenden, ist SER relevant. Da Emotionen jedoch subjektiv sind, ist es eine schwierige Aufgabe, den Klang zu annotieren. Wir werden die Funktionen mfcc, chroma und mel verwenden und den RAVDESS-Datensatz zur Emotionsrecognition nutzen. Wir werden einen MLPC-Klassifikator für dieses Modell erstellen.
Sprache: Python
Datensatz/Packet: RAVDESS-Datensatz
5. Geschlechts- und Altersbestimmung
Beeindrucken Sie Arbeitgeber mit dem neuesten Data-Science-Projekt — .
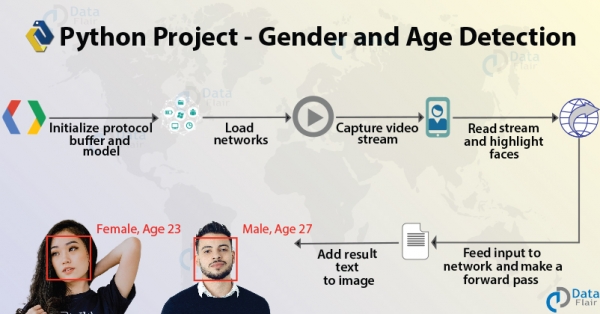
Dies ist ein interessantes Data-Science-Projekt mit Python. Nur mit einem Bild lernen Sie, das Geschlecht und das Alter einer Person vorherzusagen. Dabei werden wir Sie mit Computer Vision und seinen Prinzipien vertraut machen. Wir werden bauen und die von Tal Hassner und Gil Levi für den Adience-Datensatz trainierten Modelle verwenden. Unterwegs werden wir einige .pb-, .pbtxt-, .prototxt- und .caffemodel-Dateien verwenden.
Sprache: Python
Datensatz/Packet: Adience
6. Uber-Datenanalyse
Sehen Sie sich die vollständige Implementierung des Data Science-Projekts mit Quellcode an — .
Dies ist ein Datenvisualisierungsprojekt mit ggplot2, in dem wir R und seine Bibliotheken verwenden und verschiedene Parameter analysieren. Wir nutzen den Datensatz Uber Pickups in New York und erstellen Visualisierungen für verschiedene Zeitrahmen im Jahr. Das zeigt uns, wie die Zeit die Fahrten der Kunden beeinflusst.
Sprache: R
Datensatz/Packet: Datensatz Uber Pickups in New York City
7. Fahrerermüdungsdetektion
Verbessern Sie Ihre Fähigkeiten, indem Sie an einem Top-Data-Science-Projekt arbeiten — .
Müdigkeit beim Fahren ist äußerst gefährlich, und jedes Jahr kommt es zu etwa tausend Unfällen, weil Fahrer während der Fahrt einschlafen. In diesem Python-Projekt werden wir ein System erstellen, das müde Fahrer erkennen und sie mit einem akustischen Signal warnen kann.
Dieses Projekt wird mit Keras und OpenCV umgesetzt. Wir verwenden OpenCV zur Gesichts- und Augenerkennung, und mit Keras klassifizieren wir den Augenstatus (Offen oder Geschlossen) mithilfe von Methoden des Deep Learning.
8. Chatbot
Erstellen Sie einen Chatbot mit Python und machen Sie einen Schritt nach vorne in Ihrer Karriere — .

Chatbots sind ein unverzichtbarer Bestandteil von Unternehmen. Viele Unternehmen müssen ihren Kunden Dienstleistungen anbieten, und deren Betreuung erfordert viel Arbeitskraft, Zeit und Mühe. Chatbots können einen großen Teil der Kundeninteraktion automatisieren, indem sie einige häufig gestellte Fragen der Kunden beantworten. Grundsätzlich gibt es zwei Arten von Chatbots: Domänenspezifische und Open-Domain. Domänenspezifische Chatbots werden häufig zur Lösung spezifischer Probleme eingesetzt. Daher müssen Sie ihn anpassen, um effektiv in Ihrem Bereich zu arbeiten. Open-Domain-Chatbots können zu beliebigen Fragen gestellt werden, weshalb für ihr Training eine enorme Menge an Daten erforderlich ist.
Datensatz: Intents JSON-Datei
Sprache: Python
Fortgeschrittene Data Science Projekte
9. Bildbeschreibungs-Generator
Überprüfen Sie die vollständige Implementierung des Projekts mit dem Quellcode — .

Die Beschreibung dessen, was auf einem Bild zu sehen ist, stellt für Menschen eine einfache Aufgabe dar, aber für Computer ist ein Bild nur eine Ansammlung von Zahlen, die den Farbwert jedes Pixels repräsentieren. Es ist eine schwierige Aufgabe für Computer, zu verstehen, was sich im Bild befindet, und dann eine Beschreibung in natürlicher Sprache (zum Beispiel auf Englisch) zu erstellen. Dieses Projekt verwendet Methoden des Deep Learning, bei denen wir ein Convolutional Neural Network (CNN) mit einem Recurrent Neural Network (LSTM) kombinieren, um einen Bildbeschreibungsgenerator zu entwickeln.
Datensatz: Flickr 8K
Sprache: Python
Framework: Keras
10. Kreditkartenbetrugserkennung
Setzen Sie alles daran, während Sie an der Data Science-Projektidee arbeiten — .
Bis jetzt haben Sie die Methoden und Konzepte begonnen zu verstehen. Lassen Sie uns zu einigen fortgeschrittenen Projekten in der Datenwissenschaft übergehen. In diesem Projekt werden wir die R-Sprache mit Algorithmen wie , logistische Regression, künstliche neuronale Netze und Gradient Boosting-Klassifikatoren. Wir werden einen Datensatz von Kreditkarten-Transaktionen verwenden, um diese als betrügerisch oder legitim zu klassifizieren. Wir werden verschiedene Modelle ausprobieren und Leistungskennlinien erstellen.
Sprache: R
Datensatz/Packet: Datensatz zu Kreditkartentransaktionen
11. Movie Recommendation System (Filmempfehlungssystem)
Entdecken Sie die Umsetzung des besten Data Science-Projekts mit Quellcode —
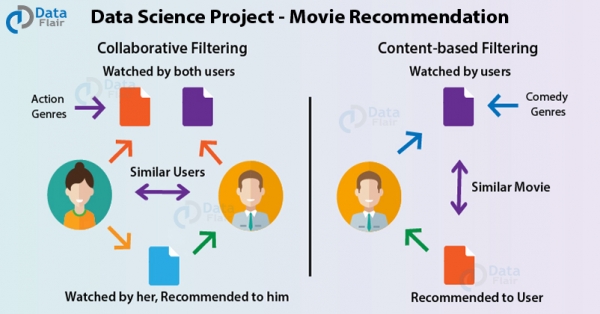
In diesem Data Science-Projekt werden wir R nutzen, um Filme durch maschinelles Lernen zu empfehlen. Das Empfehlungssystem sendet Vorschläge an Benutzer basierend auf den Vorlieben anderer Benutzer und deren Sehgewohnheiten. Wenn A und B „Kevin – Allein zu Hause“ mögen und B „Die Mädchen von anderen“ liebt, kann A ebenfalls empfohlen werden – das könnte ihm auch gefallen. Dadurch können Kunden mit der Plattform interagieren.
Sprache: R
Datensatz/Packet: MovieLens-Datensatz
12. Customer Segmentation (Kundensegmentierung)
Beeindrucken Sie Arbeitgeber mit einem Data Science-Projekt (einschließlich Quellcode) — .
Die Segmentierung von Kunden ist eine gängige Anwendung . Durch die Clusteranalyse identifizieren Unternehmen Kundensegmente, um mit einer potenziellen Nutzerbasis zu arbeiten. Sie teilen Kunden in Gruppen entsprechend gemeinsamen Eigenschaften wie Geschlecht, Alter, Interessen und Ausgabengewohnheiten, um ihre Produkte effektiv jeder Gruppe anzubieten. Wir werden einsetzen und die Verteilung nach Geschlecht und Alter visualisieren. Danach analysieren wir deren jährliches Einkommen und Ausgabenlevel.
Sprache: R
Datensatz/Packet: Mall_Customers-Datensatz
13. Brustkrebs-Klassifikation
Sehen Sie sich die vollständige Umsetzung des Data Science-Projekts in Python an — .

Kehren wir zurück zum medizinischen Beitrag der Datenwissenschaft, lernen wir, Brustkrebs mit Python zu identifizieren. Wir werden den Datensatz IDC_regular verwenden, um das invasive Duktalkarzinom, die häufigste Form von Brustkrebs, zu identifizieren. Es entwickelt sich in den Milchgängen und dringt in das faserige oder fettige Gewebe der Brust außerhalb des Kanals ein. In diesem Data-Science-Projekt werden wir und die Keras-Bibliothek für die Klassifizierung verwenden.
Sprache: Python
Datensatz/Packet: IDC_regular
14. Verkehrsschilderkennung
Die Erreichung von Genauigkeit in der Technologie des autonomen Fahrens durch ein Data-Science-Projekt zur mit Open Source.

Verkehrsschilder und Verkehrsregeln sind für jeden Fahrer von großer Bedeutung, um Unfälle zu vermeiden. Um den Regeln zu folgen, muss man zunächst verstehen, wie ein Verkehrsschild aussieht. Eine Person muss alle Verkehrsschilder lernen, bevor sie die Berechtigung zum Führen eines Fahrzeugs erhält. Doch heutzutage nimmt die Anzahl autonomer Fahrzeuge zu, und in naher Zukunft wird der Mensch nicht mehr selbstständig ein Auto fahren. Im Projekt „Erkennung von Verkehrsschildern“ erfahren Sie, wie ein Programm den Typ des Verkehrsschilds anhand eines Bildes als Eingangsquelle erkennen kann. Der Datensatz zur Erkennung von Verkehrsschildern in Deutschland (GTSRB) wird verwendet, um ein tiefes neuronales Netzwerk zum Erkennen der Klasse des jeweiligen Verkehrsschildes aufzubauen. Wir erstellen auch eine einfache grafische Benutzeroberfläche, um mit der Anwendung zu interagieren.
Sprache: Python
Datensatz: GTSRB (German Traffic Sign Recognition Benchmark)
Mehr lesen
Quelle: habr.com
