

In Wir haben über die Prognose von Zeitreihen gesprochen. Ein logischer nächster Schritt wäre ein Artikel über die Anomalieerkennung.
Anwendung
Anomalieerkennung wird in Bereichen wie folgt eingesetzt:
1) Vorhersage von Geräteausfällen
So wurden im Jahr 2010 iranische Zentrifugen von dem Virus Stuxnet angegriffen, das einen suboptimalen Betrieb der Geräte verursachte und Teile der Ausrüstung durch beschleunigte Abnutzung außer Betrieb setzte.
Wenn auf den Geräten Anomalieerkennungsalgorithmen eingesetzt worden wären, hätte man die Ausfälle möglicherweise vermeiden können.

Die Anomalieerkennung bei Geräten wird nicht nur in der Atomindustrie, sondern auch in der Metallurgie und bei Flugzeugturbinen verwendet. Und in anderen Bereichen, in denen der Einsatz von prädiktiver Diagnostik kostengünstiger ist als die möglichen Verluste bei unerwartetem Ausfall.
2) Vorhersage von betrügerischen Aktivitäten
Wenn von einer Karte, die Sie in Podolsk verwenden, Geld in Albanien abgehoben wird, sollten die Transaktionen möglicherweise zusätzlich geprüft werden.
3) Erkennung anomaler Verbrauchermuster
Wenn ein Teil der Kunden anormales Verhalten zeigt, könnte es ein Problem geben, von dem Sie nichts wissen.
4) Identifizierung von anormaler Nachfrage und Belastung
Wenn die Verkäufe im FMCG-Geschäft unter die Grenzen des Vertrauensintervalls der Prognose fallen, sollte die Ursache für das Geschehen ermittelt werden.
Ansätze zur Aufdeckung von Anomalien
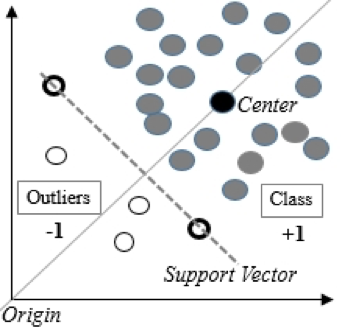
1) Ein-Klassen-Support-Vektor-Methode (One-Class SVM)
Geeignet, wenn die Daten im Trainingssatz normal verteilt sind und im Test Anomalien enthalten.
Die Ein-Klassen-Support-Vektor-Methode erstellt eine nichtlineare Oberfläche um den Ursprung. Es kann eine Schnittgrenze definiert werden, um festzulegen, welche Daten als anormal gelten.
Basierend auf den Erfahrungen unseres DATA4-Teams ist One-Class SVM der am häufigsten verwendete Algorithmus zur Identifizierung von Anomalien.
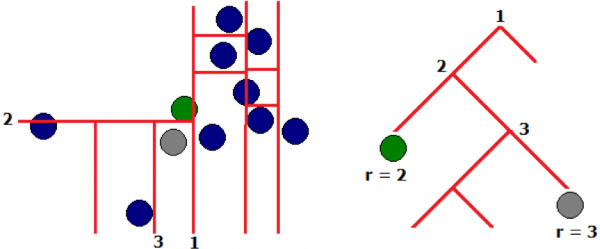
2) Isolierender Wald – Isolation Forest
Beim zufälligen Aufbau von Bäumen werden Ausreißer früh in Blätter gelangen (in geringer Baumtiefe), d.h. sie sind einfacher zu isolieren. Die Identifizierung anormaler Werte erfolgt in den ersten Iterationen des Algorithmus.
3) Elliptische Hülle und statistische Methoden
Wird verwendet, wenn Daten normal verteilt sind. Je näher die Messung am Ende der Mischverteilungen ist, desto anomaler ist der Wert.
Dieser Klasse können auch andere statistische Methoden zugeordnet werden.
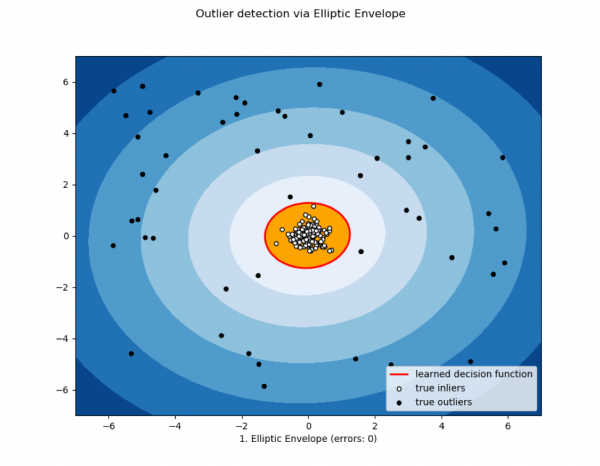
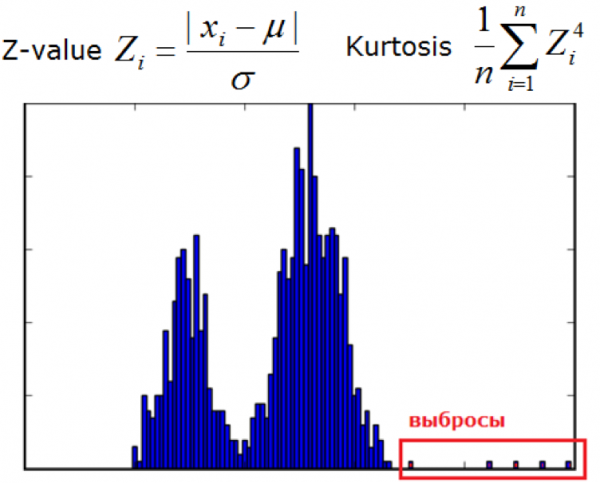
Bild von der Website dyakonov.org
4) Metrische Methoden
Zu den Methoden gehören Algorithmen wie k nächster Nachbar, k-nearest neighbor, ABOD (angle-based outlier detection) oder LOF (local outlier factor).
Geeignet, wenn der Abstand zwischen den Werten in den Merkmalen gleichwertig oder normiert ist (um nicht die Schlange in Papageien zu messen).
Der k-nächste-Nachbarn-Algorithmus geht davon aus, dass normale Werte sich in einem bestimmten Bereich des mehrdimensionalen Raums befinden und der Abstand zu Anomalien größer ist als zum trennenden Hyperflächen.
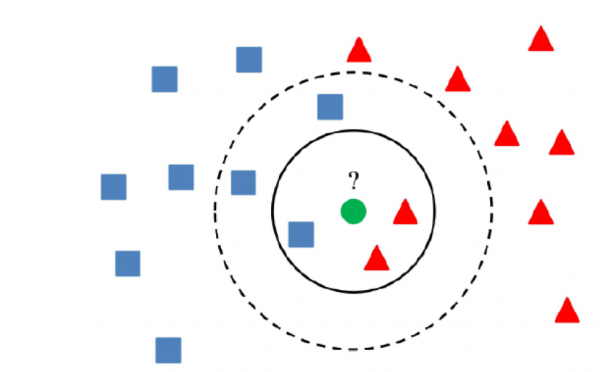
5) Cluster-Methoden
Der Kern der Cluster-Methoden besteht darin, dass ein Wert als anomal betrachtet werden kann, wenn er mehr als einen bestimmten Betrag von den Clusterzentren entfernt ist.
Wichtig ist, einen Algorithmus zu verwenden, der die Daten korrekt clustert, was von der spezifischen Aufgabe abhängt.
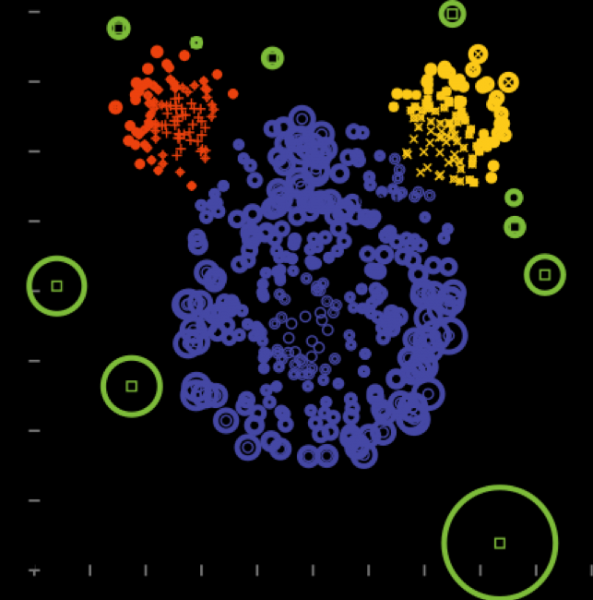
6) Hauptkomponentenanalyse
Geeignet, wenn Richtung der größten Veränderung der Varianz identifiziert wird.
7) Algorithmen zur Vorhersage von Zeitreihen
Die Idee ist, dass ein Wert als anormal betrachtet wird, wenn er außerhalb des Vertrauensintervalls der Vorhersage liegt. Zur Vorhersage von Zeitreihen werden Verfahren wie exponentielle Glättung, S(ARIMA), Boosting usw. verwendet.
In dem vorherigen Artikel wurden Algorithmen zur Vorhersage von Zeitreihen behandelt.
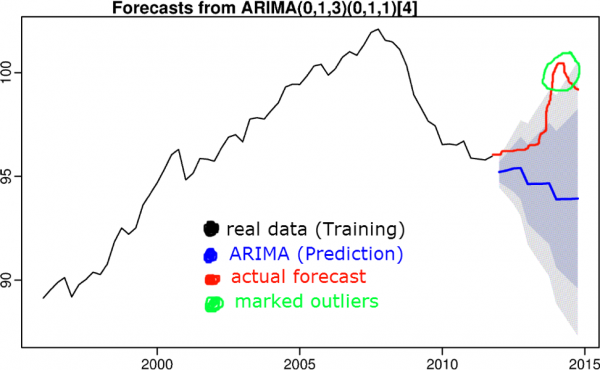
8) Überwachtes Lernen (Regression, Klassifikation)
Wenn die Daten es zulassen, verwenden wir Algorithmen von linearer Regression bis hin zu rekurrenten Netzen. Wir messen die Differenz zwischen der Vorhersage und dem tatsächlichen Wert und ziehen daraus Rückschlüsse, wie stark die Daten von der Norm abweichen. Es ist wichtig, dass der Algorithmus über eine ausreichende Verallgemeinerungsfähigkeit verfügt und die Trainingsdaten keine anomalen Werte enthalten.
9) Modultests
Betrachten wir die Anomalieerkennung als eine Empfehlungsaufgabe. Wir zerlegen unsere Merkmalsmatrix mithilfe von SVD oder Faktorisierungsmaschinen, und Werte in der neuen Matrix, die wesentlich von den ursprünglichen abweichen, betrachten wir als anormal.
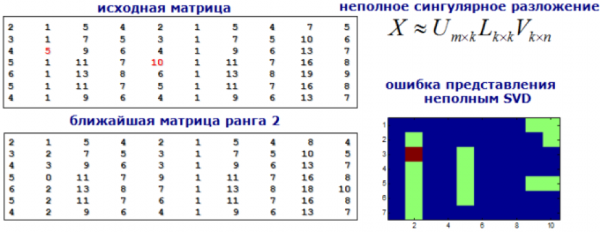
Bild von der Website dyakonov.org
Fazit
In diesem Artikel haben wir die grundlegenden Ansätze zur Anomalieerkennung behandelt.
Die Suche nach Anomalien kann in vielerlei Hinsicht als Kunst betrachtet werden. Es gibt keinen perfekten Algorithmus oder Ansatz, der alle Probleme löst. Häufig kommt ein Methodenmix zum Einsatz, um spezifische Fälle zu bearbeiten. Die Anomalien werden mittels Methoden wie Support Vector Machines, Isolation Forests, metrischen und Clusterverfahren sowie durch Einsatz von Hauptkomponenten und Zeitreihenprognosen identifiziert.
Wenn Sie andere Methoden kennen, teilen Sie diese bitte in den Kommentaren zu dem Artikel mit.
Quelle: habr.com
