


Du stehst erneut vor der Aufgabe der Objekterkennung. Priorität hat die Geschwindigkeit bei akzeptabler Genauigkeit. Du nimmst die Architektur YOLOv3 und feinstimmst sie. Genauigkeit (mAp75) über 0,95. Doch die Geschwindigkeit ist immer noch niedrig. Verdammt.
Heute lassen wir die Quantisierung beiseite. Im Anschluss betrachten wir Model Pruning — das Entfernen überflüssiger Teile des Netzwerks zur Beschleunigung der Inferenz bei Erhaltung der Genauigkeit. Anschaulich — wo, wie viel und wie kann ausgeschnitten werden. Wir werden besprechen, wie man dies manuell macht und wo man es automatisieren kann. Am Ende — ein Repository für Keras.
Einführung
Bei meinem vorherigen Arbeitgeber, dem Permer Macroscop, habe ich mir eine Angewohnheit angeeignet — stets die Laufzeit der Algorithmen zu überwachen. Und die Laufzeit der Netzwerke immer über einen Angemessenheitsfilter zu überprüfen. In der Regel bestehen state-of-the-art Modelle in der Produktion diesen Filter nicht, was mich zum Pruning geführt hat.
Pruning — ein altes Thema, das in den Im Jahr 2017. Die grundlegende Idee ist, die Größe des trainierten Netzwerks zu verringern, ohne dass die Genauigkeit leidet, indem verschiedene Knoten entfernt werden. Klingt cool, aber ich höre selten von seiner Anwendung. Wahrscheinlich mangelt es an Implementierungen, es gibt keine deutschsprachigen Artikel oder einfach alle halten pruning für ein Geheimnis und schweigen.
Aber lass uns das auseinandernehmen.
Ein Blick in die Biologie
Ich liebe es, wenn Ideen aus der Biologie im Deep Learning Anwendung finden. Auf sie, ebenso wie auf die Evolution, kann man vertrauen (wusstest du, dass ReLU sehr ähnlich ist wie ?)
Der Prozess des Model Pruning ist ebenfalls eng mit der Biologie verbunden. Die Reaktion des Netzwerks lässt sich mit der Plastizität des Gehirns vergleichen. Einige interessante Beispiele findet man im Buch :
- Das Gehirn einer Frau, die von Geburt an nur eine Gehirnhälfte hatte, hat sich selbst umprogrammiert, um die Funktionen der fehlenden Hälfte auszuführen.
- Ein Mann hatte sich einen Teil seines Gehirns entfernt, der für das Sehen verantwortlich war. Im Laufe der Zeit übernahmen andere Teile des Gehirns diese Funktionen. (Wir versuchen nicht, das zu wiederholen.)
So kann auch aus deinem Modell ein Teil schwacher Schichten entfernt werden. Im Zweifelsfall helfen die verbleibenden Schichten, die entfernten zu ersetzen.
Liebst du Transfer Learning oder lernst du von Grund auf?
Option Nummer eins. Sie nutzen Transfer Learning mit Yolov3, Retina, Mask-RCNN oder U-Net. Doch häufig müssen wir nicht 80 Objektklassen wie im COCO-Datensatz erkennen. In meiner Erfahrung beschränkt sich das alles auf 1-2 Klassen. Man könnte annehmen, dass die Architektur für 80 Klassen hier übertrieben ist. Daher liegt der Gedanke nahe, die Architektur zu verkleinern. Und das möchte ich gerne tun, ohne die bestehenden vortrainierten Gewichte zu verlieren.
Option Nummer zwei. Vielleicht haben Sie viele Daten und Rechenressourcen oder benötigen einfach eine hochgradig angepasste Architektur. Das ist irrelevant. Aber Sie trainieren das Netzwerk von Grund auf. Der übliche Ablauf besteht darin, sich die Datenstruktur anzusehen, eine ÜBERFLÜSSIGE leistungsstarke Architektur auszuwählen und Dropouts gegen Überanpassung anzuwenden. Ich habe Dropouts von 0.6 gesehen, Karl.
In beiden Fällen lässt sich das Netzwerk verkleinern. Wir haben einen Grund dafür formuliert. Jetzt wollen wir herausfinden, was es mit dem Pruning auf sich hat.
Algorithmus insgesamt
Wir haben entschieden, dass wir Faltungen entfernen können. Das sieht ziemlich einfach aus:
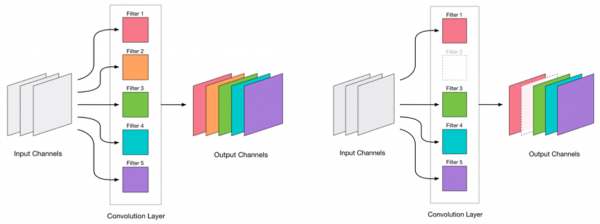
Das Entfernen von Faltungen belastet das Netzwerk und führt in der Regel zu einem gewissen Anstieg der Fehlerquote. Einerseits zeigt dieser Anstieg, wie gut wir die Faltungen entfernen (ein großer Anstieg deutet darauf hin, dass wir etwas falsch machen). Ein kleiner Anstieg ist jedoch durchaus akzeptabel und kann oft durch anschließendes leichtes Nachtraining mit einer kleinen Lernrate behoben werden. Fügen wir einen Nachtrainingsschritt hinzu:
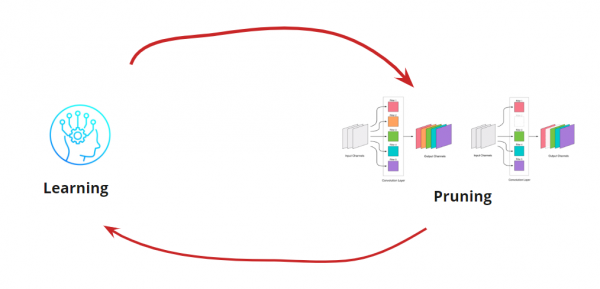
Jetzt müssen wir verstehen, wann wir unseren Lern-Pruning-Zyklus stoppen möchten. Es kann exotische Szenarien geben, in denen wir das Netzwerk auf eine bestimmte Größe und Geschwindigkeit reduzieren müssen (z. B. für mobile Geräte). Das häufigste Szenario ist jedoch das Fortsetzen des Zyklus, bis der Fehler über den akzeptablen Wert steigt. Fügen wir eine Bedingung hinzu:
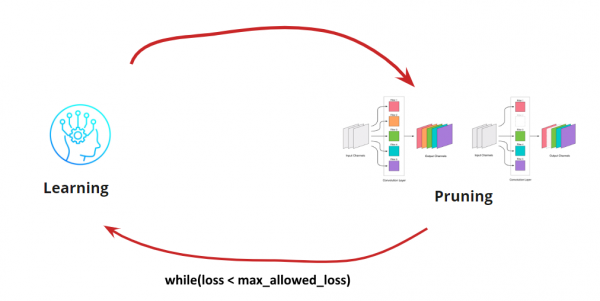
Somit wird der Algorithmus klar. Es bleibt zu klären, wie die zu entfernenden Faltungen identifiziert werden.
Suche nach entfernbaren Faltungen
Wir müssen einige Faltungen entfernen. Einfach unüberlegt und willkürlich Faltungen zu entfernen, ist keine gute Idee, auch wenn es funktionieren könnte. Aber wenn wir klug sind, können wir versuchen, "schwache" Faltungen zur Entfernung auszuwählen. Es gibt mehrere Ansätze:
- . Die Idee besagt, dass Faltungen mit geringen Gewichtswerten nur einen kleinen Einfluss auf die endgültige Entscheidungsfindung haben.
- Die kleinste L1-Metrik unter Berücksichtigung des Mittelwerts und der Standardabweichung. Ergänzt durch eine Bewertung der Verteilungsart.
- . Eine genauere Bestimmung von unbedeutenden Faltungen, aber sehr zeit- und ressourcenintensiv.
- Andere
Jede der Varianten hat ihre Daseinsberechtigung und spezifische Implementierungsmerkmale. Hier betrachten wir die Variante mit der kleinsten L1-Metrik.
Manueller Prozess für YOLOv3
Die ursprüngliche Architektur enthält Restblöcke. Aber egal wie effektiv sie für tiefe Netzwerke sind, sie stören uns ein wenig. Das Problem ist, dass wir in diesen Schichten keine Faltungen mit unterschiedlichen Indizes löschen können:
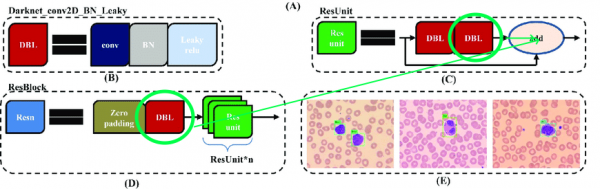
Deshalb heben wir die Schichten hervor, aus denen wir Faltungen ohne Bedenken entfernen können:

Jetzt bauen wir einen Arbeitszyklus auf:
- Aktivierungen exportieren
- Schätzen, wie viel ausgeschnitten werden soll
- Ausschneiden
- Trainieren über 10 Epochen mit LR=1e-4
- Testen
Es ist hilfreich, Faltungen zu exportieren, um zu bewerten, welchen Teil wir zu einem bestimmten Zeitpunkt entfernen können. Beispiele für den Export:
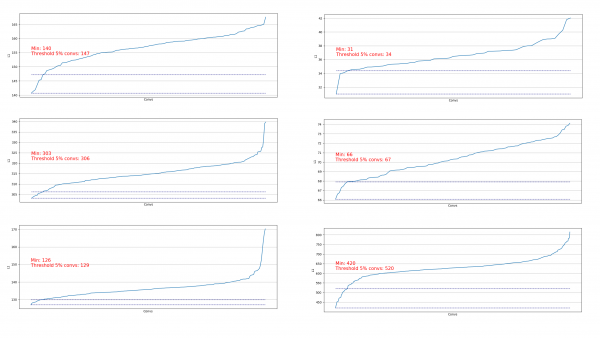
Wir sehen, dass praktisch überall 5 % der Faltung eine sehr niedrige L1-Norm aufweisen, sodass wir sie entfernen können. Bei jedem Schritt wiederholte sich diese Auslagerung und es wurde bewertet, aus welchen Schichten und wie viel ausgeschnitten werden kann.
Der gesamte Prozess wurde in 4 Schritte gegliedert (hier und überall beziehen sich die Zahlen auf die RTX 2060 Super):
| Schritt | mAp75 | Anzahl der Parameter, Millionen | Netzwerkgröße, MB | Von der ursprünglichen, % | Durchlaufzeit, ms | Bedienung des Zuschneidens |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | — |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 5 % von allem |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 5 % von allem |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15 % für Schichten mit 400+ Faltungen |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10 % für Schichten mit 100+ Faltungen |
Zu Schritt 2 kam ein positiver Effekt hinzu — der Batch-Size 4 konnte in den Speicher geladen werden, was den Prozess des Nachtrainierens erheblich beschleunigte.
Im Schritt 4 wurde der Prozess gestoppt, da selbst umfangreiches Nachtrainieren den mAp75 nicht auf die alten Werte hob.
Letztendlich gelang es, die Inferenz um 15%, die Größe um 35% zu reduzieren und dabei die Genauigkeit nicht zu verlieren.
Automatisierung für einfachere Architekturen
Für einfachere Netzwerkarchitekturen (ohne bedingte Additionen, Konkatenierungen und Residualblöcke) kann man sich gut auf die Verarbeitung aller Faltungen konzentrieren und den Prozess des Ausschneidens von Faltungen automatisieren.
Diese Option habe ich implementiert. .
Es ist ganz einfach: Sie benötigen lediglich die Verlustfunktion, den Optimierer und die Batch-Generatoren:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)Bei Bedarf können die Konfigurationsparameter geändert werden:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # Anzahl der Epochen für das Training zwischen den Pruning-Schritten
"stop_loss": 0.1, # Verlust zum Stoppen des Prozesses
"pruning_percent_step": 0.05, # Anteil der Convolutionen, die bei jedem Pruning-Schritt gelöscht werden
"pruning_standart_deviation_part": 0.2 # Verschiebung zur Begrenzung des Pruning-Anteils
}Zusätzlich wurde eine Einschränkung basierend auf der Standardabweichung implementiert. Ziel ist es, den Anteil der entfernten Elemente zu begrenzen, indem Convolutions mit bereits "ausreichenden" L1-Messungen ausgeschlossen werden:
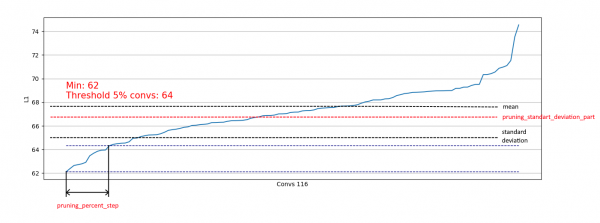
So erlauben wir es, nur schwache Convolutionen aus Verteilungen zu entfernen, die der rechten ähnlich sind, und beeinflussen nicht die Entfernung aus Verteilungen, die der linken ähnlich sind:

Wenn sich die Verteilung dem Normalverteilung annähert, kann der Koeffizient pruning_standart_deviation_part aus folgendem ausgewählt werden:
Ich empfehle einen Toleranzwert von 2 Sigma. Alternativ kann man sich auch nicht an dieser Besonderheit orientieren und einen Wert < 1,0 beibehalten.
Das Ergebnis ist ein Diagramm, das die Netzgröße, den Verlust und die Laufzeit über den gesamten Test hinweg anzeigt, normiert auf 1.0. Zum Beispiel wurde hier die Netzgröße fast halbiert, ohne Qualitätsverlust (eine kleine Faltungsnetzwerk mit 100k Gewichten):
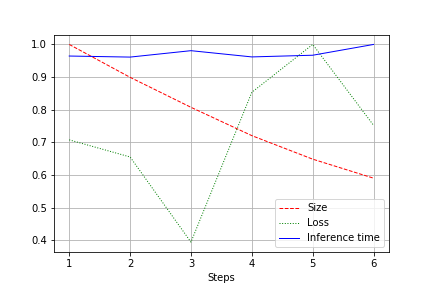
Die Laufgeschwindigkeit unterliegt normalen Schwankungen und hat sich praktisch nicht verändert. Das hat seine Erklärung:
- Die Anzahl der Faltungen wechselt von bequemen (32, 64, 128) zu weniger praktischen für Grafikkarten — 27, 51 usw. Ich könnte mich irren, aber wahrscheinlich hat das einen Einfluss.
- Die Architektur ist nicht breit, aber sequenziell. Durch Verkleinerung der Breite berühren wir nicht die Tiefe. Dadurch reduzieren wir die Last, ändern jedoch nicht die Geschwindigkeit.
Daher zeigt sich die Verbesserung in der Reduzierung der CUDA-Last während des Laufs um 20-30%, jedoch nicht in der Verringerung der Laufzeit.
Ergebnisse
Lassen Sie uns reflektieren. Wir haben zwei Varianten des Pruning betrachtet — für YOLOv3 (wenn man manuell arbeiten muss) und für Netzwerke mit einfacheren Architekturen. Es ist evident, dass man in beiden Fällen die Netzgröße reduzieren und die Geschwindigkeit erhöhen kann, ohne an Genauigkeit zu verlieren. Ergebnisse:
- Reduzierung der Größe
- Beschleunigung des Laufs
- Reduzierung der CUDA-Last
- Infolgedessen legen wir Wert auf Nachhaltigkeit (Wir optimieren die zukünftige Nutzung von Rechenressourcen. Irgendwo freut sich jemand. )
Anhang
- Nach dem Schritt pruning kann man auch die Quantisierung anwenden (zum Beispiel mit TensorRT)
- TensorFlow bietet Möglichkeiten für . Es funktioniert.
- Ich möchte mich weiterentwickeln und freue mich über Hilfe.
Quelle: habr.com
