

Das Unternehmen Google hat den neuen Audiocodec Lyra vorgestellt, der optimiert ist, um maximale Sprachqualität selbst über sehr langsame Verbindungen zu erreichen. Die Implementierung von Lyra ist in C++ geschrieben und unter der Apache 2.0-Lizenz veröffentlicht, wobei eine proprietäre Bibliothek namens libsparse_inference.so für mathematische Berechnungen erforderlich ist. Es wird darauf hingewiesen, dass die proprietäre Bibliothek vorübergehend ist – Google plant, in Zukunft eine offene Alternative zu entwickeln und die Unterstützung für verschiedene Plattformen sicherzustellen.
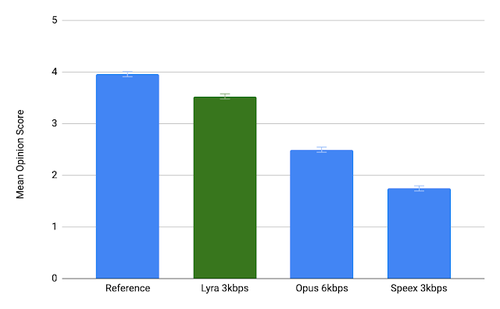
In Bezug auf die Qualität der übermittelten Sprachdaten bei niedrigen Geschwindigkeiten übertrifft Lyra herkömmliche Codecs erheblich, die auf digitale Signalverarbeitungstechniken basieren. Um eine hohe Sprachübertragungsqualität unter Bedingungen mit begrenztem Datenvolumen zu gewährleisten, wird neben herkömmlichen Methoden zur Audiokompression und Signalverarbeitung in Lyra ein auf Maschinenlernen basierendes Sprachmodell verwendet, das es ermöglicht, fehlende Informationen anhand typischer Sprachmerkmale zu rekonstruieren. Das zur Klangerzeugung verwendete Modell wurde mit mehreren tausend Stunden an Sprachaufnahmen in mehr als 70 Sprachen trainiert.
Der Codec umfasst einen Encoder und einen Decoder. Der Encoder extrahiert alle 40 Millisekunden Parameter der Sprachdaten, komprimiert sie und überträgt sie über das Netzwerk an den Empfänger. Für die Datenübertragung genügt eine Verbindung mit einer Geschwindigkeit von 3 Kilobit pro Sekunde. Die extrahierten Klangparameter umfassen logarithmische Mel-Spektrogramme, die die Energiecharakteristika der Sprache in verschiedenen Frequenzbereichen berücksichtigen und nach dem Modell des menschlichen Hörens vorbereitet sind.
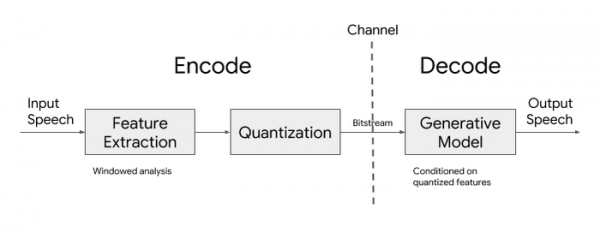
Der Decoder verwendet ein generatives Modell, das basierend auf den übermittelten Klangparametern das Sprachsignal rekonstruiert. Um die Rechenkomplexität zu reduzieren, kommt ein leichtes Modell auf Basis eines rekurrenten neuronalen Netzwerks zum Einsatz, das eine Variante des Sprachsynthesemodels WaveRNN darstellt. Hierbei wird eine niedrigere Abtastrate verwendet, aber es werden gleichzeitig mehrere Signale in verschiedenen Frequenzbereichen parallel generiert. Die erhaltenen Signale werden dann übereinandergelegt, um ein einzelnes Ausgangssignal zu erzeugen, das der vorgegebenen Abtastrate entspricht.
Für eine Beschleunigung wurden auch spezialisierte Prozessoranweisungen verwendet, die in 64-Bit ARM-Prozessoren verfügbar sind. Daher kann der Lyra-Codec trotz des Einsatzes von maschinellem Lernen zur Echtzeit-Codierung und -Decodierung von Sprache auf Smartphones der Mittelklasse verwendet werden, wobei eine Übertragungsverzögerung von 90 Millisekunden erreicht wird.
Quelle: opennet.ru
