

Google hat den Audiocodec Lyra V2 vorgestellt, der maschinelles Lernen nutzt, um die höchste Sprachübertragungsqualität über sehr langsame Verbindungen zu erzielen. Die neue Version zeichnet sich durch eine Umstellung auf eine neue Neuralnetzarchitektur, Unterstützung zusätzlicher Plattformen, erweiterte Bitratesteuerungsmöglichkeiten, verbesserte Leistung und eine höhere Klangqualität aus. Die Referenzimplementierung des Codes ist in C++ geschrieben und steht unter der Apache 2.0-Lizenz.
In Bezug auf die Qualität der übertragenden Sprachdaten bei niedrigen Geschwindigkeiten übertrifft Lyra traditionell verwendete Codecs, die auf digitale Signalverarbeitung setzen, erheblich. Um eine hohe Sprachübertragungsqualität bei begrenztem Datenvolumen zu gewährleisten, nutzt Lyra neben herkömmlichen Audiokomprimierungsmethoden und Signalumwandlungen ein Sprachmodell basierend auf maschinellem Lernen, das es ermöglicht, fehlende Informationen anhand typischer Sprachmerkmale zu rekonstruieren.
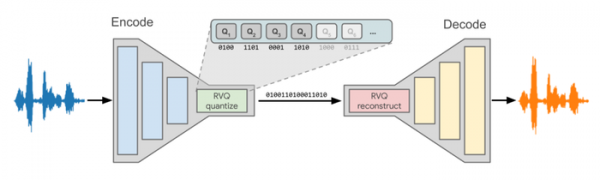
Der Codec umfasst einen Encoder und einen Decoder. Der Arbeitsalgorithmus des Encoders besteht darin, alle 20 Millisekunden Sprachdatenparameter zu extrahieren, diese zu komprimieren und sie über das Netzwerk mit einer Bitrate von 3,2 kbps bis 9,2 kbps an den Empfänger zu übertragen. Auf der Seite des Empfängers verwendet der Decoder ein generatives Modell, um das ursprüngliche Sprachsignal auf Grundlage der übermittelten akustischen Parameter, die logarithmisch gemessene Mel-Spektrogramme enthalten, nachzubilden. Diese berücksichtigen die energetischen Eigenschaften der Sprache in verschiedenen Frequenzbereichen und sind unter Berücksichtigung des menschlichen Hörvermögens vorbereitet.
In Lyra V2 kommt ein neues generatives Modell zum Einsatz, das auf einem konvolutionalen neuronalen Netzwerk namens SoundStream basiert. Es zeichnet sich durch niedrige Anforderungen an die Rechenressourcen aus, was die Echtzeit-Decodierung selbst auf weniger leistungsstarken Systemen ermöglicht. Das zur Klanggenerierung verwendete Modell wurde mit mehreren tausend Stunden Sprachaufnahmen in über 90 Sprachen trainiert. Für die Ausführung des Modells wird TensorFlow Lite verwendet. Die Leistung der angebotenen Implementierung reicht aus, um Sprache auf Smartphones im Einstiegspreissegment zu kodieren und zu dekodieren.
Neben der Verwendung eines anderen Generationsmodells zeichnet sich die neue Version insbesondere durch die Integration von Codierungsbausteinen mit dem Residual Vector Quantizer (RVQ) in die Architektur aus. Dieser Quantisierer wird auf der Senderseite vor der Datenübertragung und auf der Empfängerseite nach dem Empfang der Daten ausgeführt. Der Quantisierer wandelt die vom Codec ausgegebenen Parameter in Datenpakete um, wobei die Informationen entsprechend der Wahl der Bitrate kodiert werden. Um unterschiedliche Qualitätsstufen zu gewährleisten, gibt es Quantisierer für drei Bitraten (3,2 kps, 6 kbps und 9,2 kbps). Je höher die Bitrate, desto besser die Qualität, jedoch steigen auch die Anforderungen an die Bandbreite.
Die neue Architektur hat die Signalübertragungsverzögerung von 100 auf 20 Millisekunden reduziert. Zum Vergleich zeigte der Codec Opus für WebRTC bei den getesteten Bitraten ein Verzögerung von 26,5 ms, 46,5 ms und 66,5 ms. Auch die Leistung des Encoders und Decoders hat sich erheblich verbessert – im Vergleich zur vorherigen Version wurde eine Beschleunigung von bis zu 5-fach festgestellt. Beispielsweise führt der neue Codec auf dem Smartphone Pixel 6 Pro die Kodierung und Dekodierung einer 20-Millisekunden-Stichprobe in 0,57 ms durch, was 35 Mal schneller ist als erforderlich für die Übertragung in Echtzeit.
Neben der Leistung wurde auch eine Verbesserung der Klangwiedergabe erreicht – auf der MUSHRA-Skala entspricht die Sprachqualität bei den Bitraten 3,2 kbps, 6 kbps und 9,2 kbps unter Verwendung des Codecs Lyra V2 den Bitraten von 10 kbps, 13 kbps und 14 kbps bei Verwendung des Codecs Opus.
Quelle: opennet.ru
