

Zweiter Teil:
Jedes Raster- bild lässt sich als zweidimensionale Matrixdarstellen. Wenn es um Farben geht, kann das Konzept weiterentwickelt werden, indem man das Bild als dreidimensionale Matrixbetrachtet, in der zusätzliche Dimensionen zur Speicherung von Daten für jede der Farben verwendet werden.
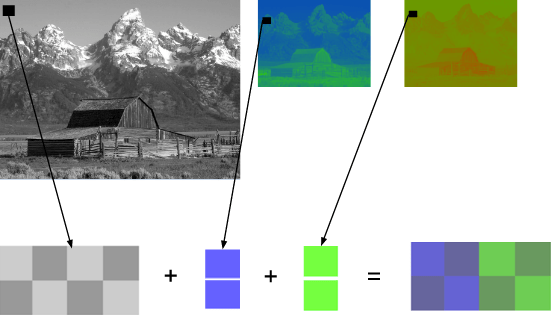
Wenn wir die endgültige Farbe als Kombination der sogenannten Primärfarben (rot, grün und blau) betrachten, definieren wir in unserer dreidimensionalen Matrix drei Ebenen: die erste für die rote Farbe, die zweite für die grüne und die letzte für die blaue.
Jeden Punkt in dieser Matrix nennen wir ein Pixel (Bildelement). Jedes Pixel enthält Informationen zur Intensität (normalerweise in Form eines Zahlenwerts) jeder Farbe. Zum Beispiel, ein rotes Pixel bedeutet, dass es 0 grün und 0 blau sowie maximal rot enthält. Ein pinkfarbenes Pixel kann durch die Kombination der drei Farben gebildet werden. Mit einem Zahlenbereich von 0 bis 255 wird ein pinkfarbenes Pixel definiert als Rot = 255, Grün = 192 und Blau = 203.
Der Artikel wurde unterstützt von der Firma EDISON.Wir entwickeln , außerdem befassen wir uns mit .
Alternative Methoden zur Kodierung von Farbabbildungen
Um die Farben darzustellen, aus denen das Bild besteht, gibt es zahlreiche andere Modelle. Beispielsweise kann eine indizierte Palette verwendet werden, die nur ein Byte zur Darstellung jedes Pixels benötigt, anstelle der drei, die für das RGB-Modell erforderlich sind. In einem solchen Modell kann eine 2D-Matrix anstelle einer 3D-Matrix zur Darstellung jeder Farbe verwendet werden. Das spart Speicher, bietet jedoch eine geringere Farbpalette.

RGB
Sehen Sie sich beispielsweise das Bild unten an. Das erste Bild ist vollständig eingefärbt. Die anderen sind die roten, grünen und blauen Flächen (die Intensität der entsprechenden Farben ist in Graustufen dargestellt).

Wir sehen, dass die Rottöne im Original an den gleichen Stellen erscheinen, an denen die hellsten Teile des zweiten Gesichts sichtbar sind. Während der Beitrag des blauen Farbtons hauptsächlich nur in den Augen von Mario (dem letzten Gesicht) und in Elementen seiner Kleidung zu erkennen ist. Beachten Sie, wo alle drei Farbflächen den geringsten Beitrag leisten (die dunkelsten Teile der Bilder) – das sind die Schnurrhaare von Mario.
Um die Intensität jeder Farbe zu speichern, werden eine bestimmte Anzahl von Bits benötigt – dieser Wert wird als Farbtiefebezeichnet. Angenommen, es werden 8 Bit (von 0 bis 255) für eine Farbfläche verwendet. Dann ergibt sich eine Farbtiefe von 24 Bit (8 Bit * 3 Flächen R/G/B).
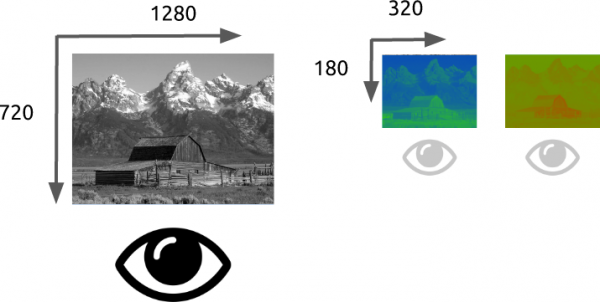
Ein weiteres Merkmal eines Bildes ist das Auflösungsvermögen, das die Anzahl der Pixel in einer Dimension darstellt. Häufig wird es als Breite × Höheangegeben, wie im folgenden Bildbeispiel 4 auf 4.
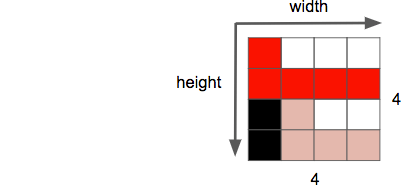
Ein weiteres Merkmal, das wir beim Arbeiten mit Bildern/Videos berücksichtigen müssen, ist das Seitenverhältnis, das die übliche proportionale Beziehung zwischen der Breite und der Höhe des Bildes oder Pixels beschreibt.
Wenn von einem Film oder Bild in einem Format von 16 zu 9 die Rede ist, bezieht man sich normalerweise auf das Seitenverhältnis des Displays (DAR — von Display-Seitenverhältnis). Manchmal kann es jedoch unterschiedliche Formen einzelner Pixel geben — in diesem Fall sprechen wir von Pixelverhältnis (PAR — von Pixel-Seitenverhältnis).

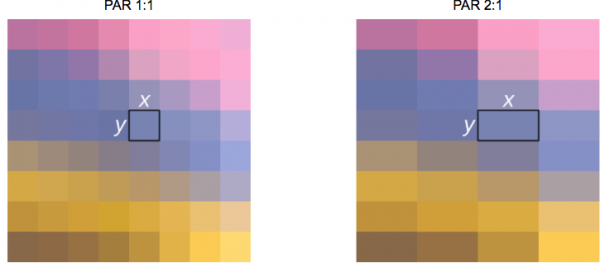
Für die Hausfrau zur Notiz: DVD entspricht DAR 4 zu 3
Obwohl die tatsächliche Auflösung einer DVD 704×480 beträgt, behält sie dennoch das Seitenverhältnis 4:3 bei, da PAR 10:11 entspricht (704×10 / 480×11).
Und schließlich können wir definieren Video als eine Abfolge von n Bildern über einen Zeitraum von Zeit, das als zusätzliche Dimension angesehen werden kann. Und n dann — ist die Bildfrequenz oder die Anzahl der Bilder pro Sekunde (FPS — von Frames pro Sekunde).
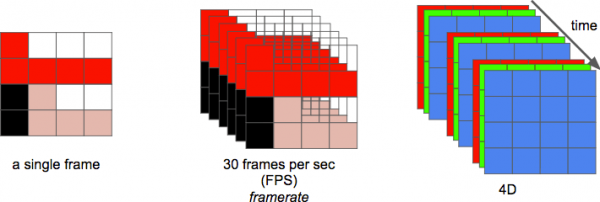
Die Anzahl an Bits pro Sekunde, die erforderlich ist, um Video anzuzeigen, ist dessen Datenrate — Bitrate.
Bitrate = Breite * Höhe * Farbtiefe * Bilder pro Sekunde
Zum Beispiel benötigt ein Video mit 30 Bildern pro Sekunde, 24 Bit pro Pixel und einer Auflösung von 480×240 82.944.000 Bits pro Sekunde oder 82,944 Mbit/s (30x480x240x24) — aber das gilt, wenn keine Komprimierungsmethoden verwendet werden.
Wenn die Datenrate fast konstantist, wird sie genannt konstante Datenrate (CBR — von konstante Bitrate). Sie kann jedoch auch variieren, in diesem Fall spricht man von variabler Bitrate (VBR — von variable Bitrate).
Dieses Diagramm zeigt eine eingeschränkte VBR, bei der nicht zu viele Bits in einem völlig dunklen Bild verbraucht werden.

Ursprünglich entwickelten Ingenieure eine Methode zur Verdopplung der wahrgenommenen Bildwiederholfrequenz von Video-Displays, ohne zusätzliche Bandbreite zu verwenden. Diese Methode ist bekannt als Interlaced video; sie sendet hauptsächlich die halbe Anzeige im ersten „Frame“ und die andere Hälfte im nächsten „Frame“.
Derzeit erfolgt die Visualisierung von Szenen hauptsächlich mit Hilfe von progressiver Scanning-Technologie. Dies ist eine Methode zur Anzeige, Speicherung oder Übertragung von Bewegungsbildern, bei der alle Zeilen jedes Frames nacheinander gezeichnet werden.

Nun, wir wissen jetzt, wie ein Bild digital dargestellt wird, wie seine Farben aufgebaut sind und wie viele Bits pro Sekunde wir benötigen, um Video bei konstanter (CBR) oder variabler (VBR) Bitrate anzuzeigen. Wir sind uns des festgelegten Auflösungsformats bei einer bestimmten Bildwiederholfrequenz bewusst und haben uns mit vielen anderen Begriffen vertraut gemacht, wie etwa interlaced Video, PAR und einigen anderen.
Entfernung von Redundanzen
Es ist bekannt, dass unkomprimiertes Video nicht praxisgerecht ist. Eine Stunde Video in 720p mit 30 Bildern pro Sekunde würde 278 GB beanspruchen. Dieses Ergebnis erhalten wir, indem wir 1280 x 720 x 24 x 30 x 3600 multiplizieren (Breite, Höhe, Bits pro Pixel, FPS und Zeit in Sekunden).
Nutzung verlustfreie Kompressionsalgorithmen, wie DEFLATE (verwendet in PKZIP, Gzip und PNG), werden nicht ausreichend Bandbreite reduzieren. Daher müssen wir nach anderen Methoden zur Videokompression suchen.
Dafür können wir die Eigenschaften unseres Sehens nutzen. Wir nehmen Helligkeit besser wahr als Farben. Ein Video ist eine Abfolge von Bildern, die über die Zeit wiederholt werden. Die Unterschiede zwischen benachbarten Frames einer Szene sind gering. Außerdem enthält jedes Bild viele Bereiche, die die gleiche (oder ähnliche) Farbe nutzen.
Farbe, Helligkeit und unsere Augen
Unsere Augen sind empfindlicher gegenüber Helligkeit als gegenüber Farbe. Sie können dies selbst überprüfen, indem Sie sich dieses Bild ansehen.
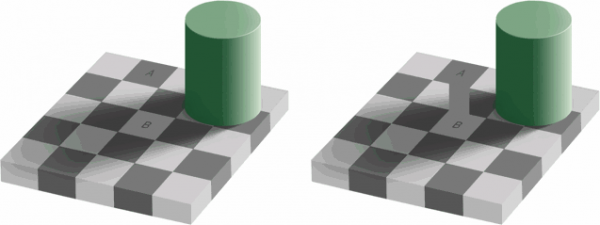
Wenn Sie nicht erkennen, dass die Farben der Quadrate in der linken Hälfte des Bildes A und B tatsächlich identisch sind, ist das normal. Unser Gehirn lenkt unsere Aufmerksamkeit stärker auf Licht und Schatten als auf Farbe. Auf der rechten Seite gibt es eine Verbindung zwischen den markierten Quadraten, die die gleiche Farbe haben – deshalb kann unser Gehirn leicht erkennen, dass es tatsächlich die gleiche Farbe ist.
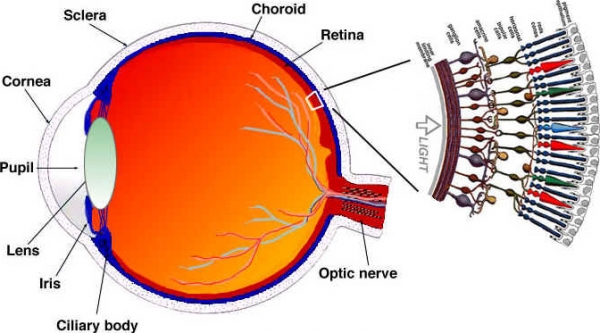
Lassen Sie uns (vereinfacht) anschauen, wie unsere Augen funktionieren. Das Auge ist ein komplexes Organ, das aus vielen Teilen besteht. Allerdings interessieren uns vor allem die Zapfen und Stäbchen. Das Auge enthält etwa 120 Millionen Stäbchen und 6 Millionen Zapfen.
Betrachten wir die Wahrnehmung von Farbe und Helligkeit als separate Funktionen bestimmter Teile des Auges (in Wirklichkeit ist das etwas komplexer, aber wir vereinfachen es). Stäbchenzellen sind hauptsächlich für die Helligkeit verantwortlich, während Zapfenzellen für die Farbe zuständig sind. Zapfen werden je nach dem enthaltenen Pigment in drei Typen unterteilt: S-Zapfen (blau), M-Zapfen (grün) und L-Zapfen (rot).
Da wir viel mehr Stäbchen (Helligkeit) als Zapfen (Farbe) haben, können wir schlussfolgern, dass wir besser in der Lage sind, Übergänge zwischen Dunkelheit und Licht zu unterscheiden als Farben.
Funktionen der Kontrastempfindlichkeit
Forschende der experimentellen Psychologie und vieler anderer Bereiche haben zahlreiche Theorien über das menschliche Sehen entwickelt. Eine davon nennt sich Funktionen der KontrastempfindlichkeitSie beziehen sich auf räumliche und zeitliche Beleuchtung. Kurz gesagt, es geht darum, wie viele Veränderungen erforderlich sind, bevor der Beobachter diese bemerkt. Beachten Sie die Mehrzahl des Wortes „Funktion“. Das liegt daran, dass wir die Empfindlichkeit gegenüber Kontrastfunktionen nicht nur für Schwarz-Weiß-Bilder, sondern auch für Farbige messen können. Die Ergebnisse dieser Experimente zeigen, dass unsere Augen in den meisten Fällen empfindlicher auf Helligkeit reagieren als auf Farbe.
Da bekannt ist, dass wir empfindlicher auf die Helligkeit eines Bildes reagieren, könnte man versuchen, diese Tatsache zu nutzen.
Farbmodell
Wir haben bereits ein wenig verstanden, wie man mit Farb Bildern unter Verwendung des RGB-Schemas arbeitet. Es gibt auch andere Modelle. Es gibt ein Modell, das Helligkeit von Farbdaten trennt, und es ist bekannt als YCbCr. Übrigens gibt es auch andere Modelle, die eine ähnliche Trennung vornehmen, aber wir werden nur dieses betrachten.
In diesem Farbmodell Y — dies ist die Darstellung der Helligkeit, und es werden zwei Farbkanäle verwendet: Cb (intensives Blau) und Cr (sattes Rot). YCbCr kann aus RGB gewonnen werden, ebenso ist eine Umwandlung in die entgegengesetzte Richtung möglich. Mit diesem Modell können wir Farbbilder erstellen, wie unten dargestellt:

Umwandlung zwischen YCbCr und RGB
Einige könnten einwenden: Wie ist es möglich, alle Farben zu erhalten, wenn Grün nicht verwendet wird?
Um diese Frage zu beantworten, wandeln wir RGB in YCbCr um. Wir verwenden die Koeffizienten, die im Standard festgelegt sind BT.601, der von einer Abteilung empfohlen wurde ITU-R. Diese Abteilung definiert die Standards im digitalen Video. Zum Beispiel: Was ist 4K? Was sollten die Bildfrequenz, die Auflösung und das Farbmodell sein?
Zuerst berechnen wir die Helligkeit. Wir verwenden die von der ITU vorgeschlagenen Konstanten und ersetzen die RGB-Werte.
Y = 0.299R + 0.587G + 0.114B
Nachdem wir die Helligkeit erhalten haben, trennen wir die blaue und rote Farbe:
Cb = 0.564(B — Y)
Cr = 0.713(R — Y)
Und wir können auch zurückwandeln und sogar Grün mit YCbCr erhalten:
R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y — 0.344Cb — 0.714Cr
In der Regel verwenden Displays (Monitore, Fernseher, Bildschirme usw.) ausschließlich das RGB-Modell. Aber dieses Modell kann unterschiedlich organisiert sein:

Farbunterabtastung
Bei der Darstellung von Bildern durch eine Kombination aus Helligkeit und Farbigkeit können wir die höhere Empfindlichkeit des menschlichen Sehens für Helligkeit im Vergleich zu Farbigkeit nutzen, indem wir selektiv Informationen entfernen. Die Farbunterabtastung ist eine Methode zur Bildkodierung, die eine niedrigere Auflösung für Farbigkeit als für Helligkeit verwendet.
Wie weit darf die Auflösung der Farbigkeit reduziert werden?! Es gibt bereits einige Schemen, die beschreiben, wie man die Auflösung und das Zusammenführen behandelt (Endfarbe = Y + Cb + Cr).
Diese Schemen sind bekannt als Unterabtastungssysteme und werden in einem Verhältnis von 3 zu 1 ausgedrückt - a:x:y, das die Anzahl der Abtastungen der Helligkeits- und Farbdifferenzsignale festlegt.
a - die Referenz-Horizontalabtastung (in der Regel gleich 4)
x - die Anzahl der Abtastungen der Farbigkeit in der ersten Zeile der Pixel (die horizontale Auflösung im Verhältnis zu a)
y - die Anzahl der Änderungen der Abtastungen der Farbigkeit zwischen der ersten und zweiten Zeile der Pixel.
Eine Ausnahme bilden 4:1:0, die eine Abtastung der Farbigkeit in jedem Block mit einer Auflösung von 4 auf 4 ermöglicht.
Allgemeine Schemen, die in modernen Codecs verwendet werden:
- 4:4:4 (ohne Subsampling)
- 4:2:2
- 4:1:1
- 4:2:0
- 4:1:0
- 3:1:1
YCbCr 4:2:0 – Beispiel einer Zusammenführung
Hier ist ein zusammengefügter Bildausschnitt unter Verwendung von YCbCr 4:2:0. Beachten Sie, dass wir nur 12 Bit pro Pixel verwenden.
So sieht dasselbe Bild aus, kodiert mit den gängigsten Arten von Farbsampling. Die oberste Reihe zeigt den finalen YCbCr, die untere Reihe zeigt die Farbauflösung. Sehr ansehnliche Ergebnisse, wenn man die geringen Qualitätsverluste berücksichtigt.

Erinnern Sie sich, dass wir 278 GB Speicherplatz für eine einstündige Video-Datei in 720p und 30 Bildern pro Sekunde berechnet haben? Bei Verwendung von YCbCr 4:2:0 wird diese Größe halbiert – auf 139 GB. Bis zu einem akzeptablen Ergebnis ist es trotzdem noch ein weiter Weg.
Sie können das YCbCr-Histogramm selbst mit FFmpeg erstellen. In diesem Bild überwiegt Blau über Rot, was auf dem Histogramm deutlich sichtbar ist.

Farbsättigung, Helligkeit, Farbton – Videoübersicht
Ich empfehle, dieses großartige Video anzusehen. Es erklärt, was Helligkeit ist und bringt alle Punkte klar auf den Tisch. Zur Helligkeit und Farbe.

Arten von Frames
Lass uns weitermachen. Wir versuchen, die Zeitredundanz zu beseitigen. Zuerst definieren wir jedoch einige grundlegende Begriffe. Angenommen, wir haben einen Film mit 30 Bildern pro Sekunde. Hier sind die ersten 4 Bilder:




Wir können viele Wiederholungen in den Bildern sehen: Zum Beispiel der blaue Hintergrund, der sich von Bild zu Bild nicht ändert. Um dieses Problem zu lösen, können wir sie abstrakt in drei Arten von Bildern klassifizieren.
I-Frame (IIntro Frame)
Der I-Frame (Referenzbild, Schlüsselbild, internes Bild) ist autonom. Unabhängig davon, was visualisiert werden soll, ist der I-Frame im Grunde ein statisches Foto. Das erste Bild ist normalerweise ein I-Frame, jedoch werden wir regelmäßig I-Frames auch unter den nicht ganz vorderen Bildern beobachten.

P-Frame (PPredicted Frame)
Ein P-Frame (prädiktiver Frame) nutzt den Vorteil, dass das aktuelle Bild fast immer unter Verwendung des vorherigen Bildes wiedergegeben werden kann. Zum Beispiel besteht im zweiten Bild die einzige Änderung im vorwärtsbewegenden Ball. Wir können Frame 2 einfach erhalten, indem wir Frame 1 leicht anpassen und nur die Unterschiede zwischen diesen Frames verwenden. Um Frame 2 zu erstellen, beziehen wir uns auf das vorhergehende Frame 1.
 ←
← 
Ein B-Frame (Bi-prädiktiver Frame)
Was ist mit Verweisen auf nicht nur vergangene, sondern auch zukünftige Frames, um eine noch bessere Kompression zu erreichen?! Das ist im Wesentlichen ein B-Frame (bidirektionaler Frame).
 ←
←  →
→ 
Zwischenausgabe
Diese Frame-Typen werden verwendet, um die bestmögliche Kompression zu gewährleisten. Wir werden uns im nächsten Abschnitt ansehen, wie das funktioniert. Vorab ist zu erwähnen, dass der „teuerste“ in Bezug auf den Speicherverbrauch der I-Frame ist, während der P-Frame deutlich günstiger ist, und der B-Frame die kosteneffizienteste Option für Videos darstellt.

Zeitliche Redundanz (interframe Vorhersage)
Lassen Sie uns überlegen, welche Möglichkeiten wir haben, um zeitliche Wiederholungen zu minimieren. Diese Art der Redundanz werden wir mit Methoden der gegenseitigen Prognose lösen.
Wir streben an, so wenige Bits wie möglich zu verwenden, um die Sequenz der Frames 0 und 1 zu codieren.
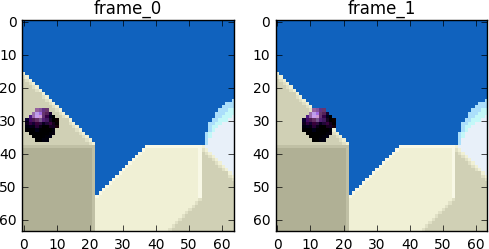
Wir können Subtraktion, indem wir einfach Frame 1 von Frame 0 abziehen. Wir erhalten Frame 1, nutzen jedoch nur die Differenz zu dem vorherigen Frame und codieren faktisch nur den verbleibenden Rest.
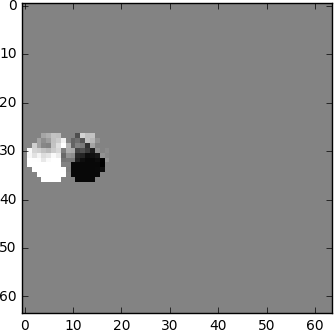
Aber was, wenn ich Ihnen sage, dass es eine noch bessere Methode gibt, die noch weniger Bits benötigt?! Lassen Sie uns zunächst Frame 0 in ein klares Gitter aus Blöcken unterteilen. Danach versuchen wir, Blöcke aus Frame 0 mit Frame 1 abzugleichen. Anders gesagt, wir bewerten die Bewegung zwischen den Frames.
Aus Wikipedia — Blockbasierte Bewegungscompensation
Die blockbasierte Bewegungscompensation teilt den aktuellen Frame in nicht überlappende Blöcke, und der Bewegungsvektor zeigt den Ursprung der Blöcke an (ein weit verbreitetes Missverständnis ist, dass der vorherige Ein Frame wird in nicht überlappende Blöcke unterteilt, und die Bewegungsvektoren zeigen an, wohin diese Blöcke verschoben werden. Tatsächlich wird jedoch nicht der vorherige Frame analysiert, sondern der nächste. Es wird ermittelt, woher die Blöcke kommen, nicht wohin sie gehen. Normalerweise sind die ursprünglichen Blöcke im Ausgangsframe überlappt. Einige Video-Komprimierungsalgorithmen setzen den aktuellen Frame sogar aus Teilen mehrerer zuvor übertragener Frames zusammen.
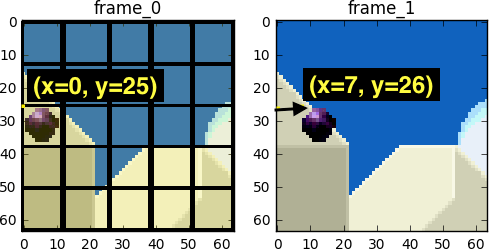
Im Bewertungsprozess sehen wir, dass sich die Kugel von (x=0, y=25) auf (x=6, y=26) bewegt hat, die Werte x und y definieren den Bewegungsvektor. Ein weiterer Schritt, den wir unternehmen können, um Bits zu sparen, besteht darin, nur die Differenz der Bewegungsvektoren zwischen der letzten Position des Blocks und der prognostizierten zu kodieren. Daher wird der endgültige Bewegungsvektor (x=6-0=6, y=26-25=1) sein.
In einer realen Situation wäre diese Kugel in n Blöcke unterteilt, aber das ändert nichts am Wesentlichen.
Die Objekte im Bild bewegen sich in drei Dimensionen, sodass die Kugel beim Bewegen visuell kleiner (oder größer, wenn sie sich auf den Betrachter zubewegt) erscheinen kann. Es ist normal, dass es keine perfekte Übereinstimmung zwischen den Blöcken gibt. Hier ist eine kombinierte Ansicht unserer Schätzung und des tatsächlichen Bildes.
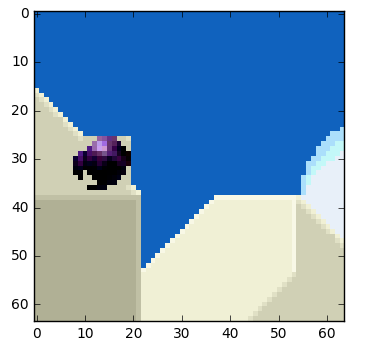
Aber wir sehen, dass, wenn wir die Bewegungseinschätzung anwenden, die Daten zur Kodierung deutlich weniger sind als bei der Verwendung einer einfacheren Methode, die die Delta zwischen den Frames berechnet.
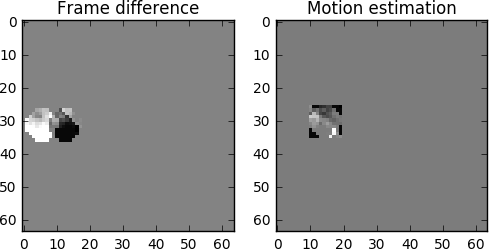
So wird die tatsächliche Bewegungskompensation aussehen.
Diese Methode wird sofort auf alle Blöcke angewendet. Oft wird unser hypothetischer beweglicher Ball in mehrere Blöcke unterteilt.

Sie können diese Konzepte selbst erkunden, indem Sie .
Um die Bewegungsvektoren zu sehen, können Sie ein Video mit einer externen Vorhersage mithilfe von .

Außerdem können Sie auf (dies ist kostenpflichtig, aber es gibt eine kostenlose Testversion, die nur auf die ersten zehn Frames beschränkt ist).
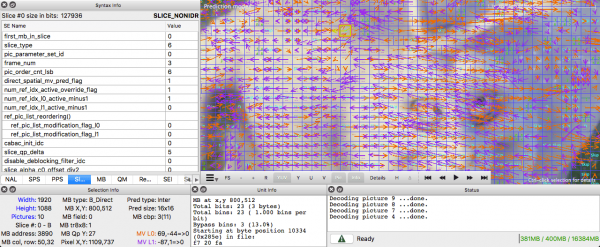
Räumliche Redundanz (interne Vorhersage)
Wenn man jeden Frame im Video analysiert, wird man viele miteinander verbundene Bereiche entdecken.

Lassen Sie uns dieses Beispiel durchgehen. Diese Szene besteht hauptsächlich aus Blau- und Weißtönen.

Das ist ein I-Frame. Wir können die vorherigen Frames zur Vorhersage nicht heranziehen, aber wir können ihn komprimieren. Lassen Sie uns die Markierung des roten Blocks kodieren. Wenn wir uns die Nachbarn ansehen, stellen wir fest, dass es um ihn herum einige Farbtrends gibt.
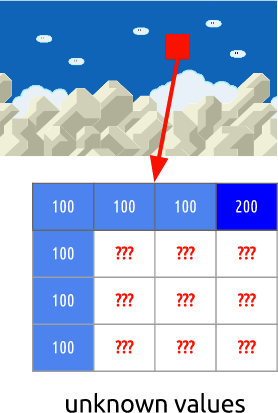
Wir nehmen an, dass die Farben im Frame vertikal verteilt sind. Das bedeutet, dass die Farben der unbekannten Pixel Werte ihrer Nachbarn enthalten werden.
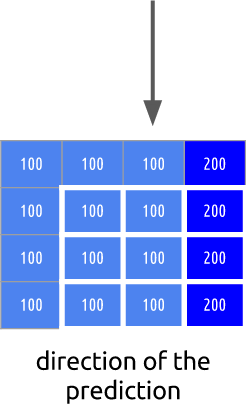
Diese Vorhersage kann sich als falsch herausstellen. Aus diesem Grund ist es notwendig, diese Methode (interne Vorhersage) anzuwenden und dann die tatsächlichen Werte abzuziehen. Dies gibt uns einen Restblock, der zu einer viel kompakteren Matrix im Vergleich zum Original führt.

Wenn Sie mit internen Vorhersagen üben möchten, können Sie mit ffmpeg ein Video mit Macroblox und ihren Vorhersagen erstellen. Um die Bedeutung jeder Farbe des Blocks zu verstehen, müssen Sie die ffmpeg-Dokumentation konsultieren.

Oder Sie können den Intel Video Pro Analyzer verwenden (wie ich oben erwähnt habe, gibt es in der kostenlosen Testversion eine Einschränkung von 10 Frames, aber das sollte anfangs ausreichen).
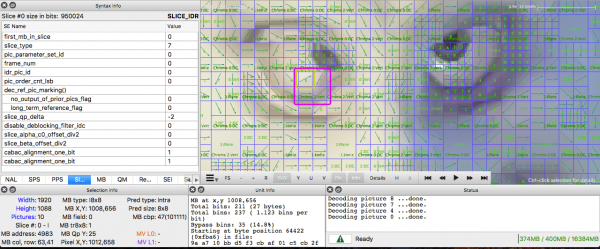
Zweiter Teil:
Quelle: habr.com
