

Moderne Informationssysteme sind ziemlich komplex. Ihre Komplexität resultiert nicht zuletzt aus der Vielschichtigkeit der verarbeiteten Daten. Oft besteht die Herausforderung der Daten darin, dass unterschiedliche Datenmodelle verwendet werden. Wenn Daten beispielsweise „groß“ werden, wird nicht nur ihr Volumen („volume“) als störend empfunden, sondern auch ihre Vielfalt („variety“).
Wenn Sie bisher keine Fehler in den Argumenten finden, lesen Sie weiter.

Inhalt
Polyglot-Persistenz
Die obigen Ausführungen führen dazu, dass man manchmal innerhalb eines einzigen Systems mehrere unterschiedliche Datenbanksysteme für die Speicherung von Daten und zur Lösung verschiedener Verarbeitungsaufgaben nutzen muss, wobei jedes seine eigene Datenmodell unterstützt. Dies wurde leicht von M. Fowler angeregt. eine Reihe bekannter Bücher und einen der des Agile Manifesto, wurde diese Situation als polyglot persistence bezeichnet.
Fowler liefert auch das folgende Beispiel für die Datenorganisation in einer voll funktionsfähigen und hochbelasteten Anwendung im Bereich E-Commerce.
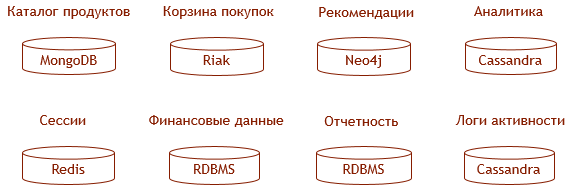
Dieses Beispiel ist zwar etwas überspitzt, aber einige Überlegungen zur Auswahl einer geeigneten Datenbank für den jeweiligen Zweck lassen sich beispielsweise finden. .
Es ist klar, dass es nicht einfach ist, in solch einem Zoo zu arbeiten.
- Der Umfang des Codes, der die Datenspeicherung durchführt, wächst proportional zur Anzahl der verwendeten Datenbanken; das Volumen des Codes, das die Daten synchronisiert, wächst, gut, wenn nicht proportional zum Quadrat dieser Zahl.
- Die Kosten für die Gewährleistung von Enterprise-Eigenschaften (Skalierbarkeit, Ausfallsicherheit, hohe Verfügbarkeit) jeder der verwendeten Datenbanken steigen exponentiell mit der Anzahl der verwendeten Datenbanken.
- Es ist unmöglich, die Enterprise-Eigenschaften des Speichersystems insgesamt zu gewährleisten – insbesondere die Transaktionsfähigkeit.
Aus der Sicht des Zoo-Direktors sieht alles so aus:
- Erhebliche Preiserhöhungen für Lizenzen und technischen Support durch den Hersteller der Datenbank.
- Aufblähen der Belegschaft und Verlängerung der Fristen.
- Direkte finanzielle Verluste oder Strafen aufgrund von Dateninkonsistenzen.
Es gibt einen signifikanten Anstieg der Gesamtkosten der Systemverwaltung (TCO). Gibt es einen Ausweg aus der Situation des „multivariaten Speichers“?
Multimodalität
Der Begriff „multivariater Speicher“ wurde 2011 populär. Die Erkenntnis über die Probleme dieses Ansatzes und die Suche nach Lösungen dauerte mehrere Jahre, und bis 2015 wurde von Analysten bei Gartner die Antwort formuliert:
- Aus „»:
Die Zukunft von Datenbanken, deren Architekturen und Nutzungsmethoden ist—Multimodalität.
- Aus „»:
Führende operationale Datenbanken werden mehrere Modelle—relationale und nicht-relationale—innerhalb einer einzigen Plattform anbieten.
Es scheint, dass die Analysten von Gartner diesmal mit ihrer Prognose richtig lagen. Wenn man die Seite mit der Datenbanken auf DB-Engines besucht, sieht man, dass die meisten ihrer Führer sich als multimodale Datenbanken positionieren. Dies ist auch auf jeder spezifischen Bewertungsseite zu beobachten.größtenDie meisten ihrer Führungskräfte positionieren sich tatsächlich als multimodale Datenbanken. Dies lässt sich auch auf der Seite mit jedem privaten Ranking erkennen.
In der folgenden Tabelle sind die führenden DBMS aufgeführt, die in ihren jeweiligen Rankings ihre Multimodalität angeben. Für jedes DBMS sind das ursprünglich unterstützte Modell (einst das einzige) sowie die derzeit unterstützten Modelle aufgeführt. Außerdem werden DBMS genannt, die sich selbst als „ursprünglich multimodal“ positionieren und nach Angaben ihrer Ersteller über kein ursprüngliches Erbe-Modell verfügen.
| Datenbankmanagementsystem | Ursprüngliches Modell | Zusätzliche Modelle |
|---|---|---|
| Oracle | Relational | Graph, Dokument |
| MS SQL | Relational | Graph, Dokument |
| PostgreSQL | Relational | Graph*, Dokument |
| MarkLogic | Dokument | Graph, relational |
| MongoDB | Dokument | Key-Value, Graph* |
| DataStax | Wide-Column | Dokument, Graph |
| Redis | Key-Value | Dokument, Graph* |
| ArangoDB | — | Graph, Dokument |
| OrientDB | — | Graph, Dokument, relational |
| Azure CosmosDB | — | Graph, Dokument, relational |
Hinweise zur Tabelle
In der Tabelle sind Aussagen mit einem Sternchen gekennzeichnet, die Vorbehalte erfordern:
- Das DBMS PostgreSQL unterstützt das grafische Datenmodell nicht, allerdings wird es von einem solchen Produkt , wie zum Beispiel AgensGraph, unterstützt.
- In Bezug auf MongoDB wäre es korrekter, eher von graphischen Operatoren in der Abfragesprache zu sprechen (, ), als es um die Unterstützung von Graphmodellen geht, wobei ihre Einführung natürlich einige Optimierungen auf der Ebene der physischen Speicherung zur Unterstützung von Graphmodellen erforderte.
- In Bezug auf Redis bezieht sich dies auf die Erweiterung .
Für jede der Klassen werden wir im Folgenden aufzeigen, wie die Unterstützung mehrerer Modelle in Datenbanksystemen dieser Klasse umgesetzt wird. Wir betrachten dabei insbesondere relationale, dokumentenbasierte und graphbasierte Modelle und zeigen anhand konkreter DBMS-Beispiele, wie die 'fehlenden' Modelle realisiert werden.
Multimodale Datenbanksysteme auf Basis des relationalen Modells
Die führenden DBMS sind derzeit relationale. Die Prognose von Gartner könnte nicht als erfüllt gelten, wenn RDBMS keine Bewegungen in Richtung Multimodalität zeigen würden. Und das tun sie. Die Überlegung, dass ein multimodales DBMS einem Schweizer Taschenmesser ähnelt, mit dem man nichts gut machen kann, sollte man direkt an Larry Ellison richten.
Der Autor hingegen bevorzugt die Umsetzung der Multimodalität in Microsoft SQL Server, anhand dessen die Unterstützung von relationalen, dokumentenbasierten und graphbasierten Modellen beschrieben wird.
Dokumentenmodell in MS SQL Server
Bereits zwei hervorragende Artikel auf Habré erläutern, wie die Unterstützung für das Dokumentenmodell in MS SQL Server realisiert ist. Ich werde mich auf eine kurze Zusammenfassung und einen Kommentar beschränken:
Die Unterstützung des Dokumentenmodells in MS SQL Server ist recht typisch für relationale Datenbanksysteme: JSON-Dokumente werden in normalen Textfeldern gespeichert. Die Unterstützung des Dokumentenmodells erfolgt durch spezielle Operatoren zur Analyse dieses JSON:
- zur Extraktion von skalaren Attributwerten,
- zur Extraktion von Unterdokumenten.
Das zweite Argument beider Operatoren ist ein Ausdruck im JSONPath-ähnlichen Syntax.
Abstrakt betrachtet sind Dokumente, die auf diese Weise gespeichert werden, in der relationalen Datenbank keine „Entitäten erster Klasse“, im Gegensatz zu Tupeln. Insbesondere fehlen in MS SQL Server momentan Indizes für JSON-Dokumentfelder, was Joins zwischen Tabellen über die Werte dieser Felder erschwert und selbst das Abrufen von Dokumenten nach diesen Werten kompliziert. Es ist jedoch möglich, eine berechnete Spalte für ein solches Feld zu erstellen und einen Index darauf anzulegen.
Zusätzlich bietet MS SQL Server die Möglichkeit, JSON-Dokumente bequem aus dem Inhalt von Tabellen mit dem Befehl zu konstruieren – eine Möglichkeit, die im gewissen Sinne der üblichen Speicherung entgegensteht. Es ist klar, dass egal wie schnell das RDBMS ist, dieser Ansatz der Ideologie dokumentenorientierter Datenbanken widerspricht, die im Grunde fertige Antworten auf häufige Anfragen speichern und lediglich Entwicklungsbequemlichkeit bieten, nicht jedoch eine hohe Leistungsfähigkeit.
Schließlich ermöglicht es MS SQL Server, die umgekehrte Aufgabe der Dokumentenkonstruierung zu lösen: JSON in Tabellen zu zerlegen mithilfe von . Wenn das Dokument nicht ganz flach ist, ist es notwendig, CROSS APPLY.
Graph-Modell in MS SQL Server
Die Unterstützung des graphbasierten (LPG) Modells ist in Microsoft SQL Server ebenfalls recht : Es werden spezielle Tabellen angeboten, um Knoten und Kanten des Graphen zu speichern. Solche Tabellen werden mit den Ausdrücken CREATE TABLE AS NODE und CREATE TABLE AS EDGE entsprechend.
erstellt. Tabellen des ersten Typs ähneln normalen Tabellen zur Speicherung von Datensätzen, mit dem einzigen äußerlichen Unterschied, dass in der Tabelle ein Systemfeld $node_id existiert – ein einzigartiger Identifikator für Knoten im Graphen innerhalb der Datenbank.
Entsprechend haben zweite Tabellen Arten systemische Felder. $from_id und $to_id, die Einträge in solchen Tabellen definieren verständlicherweise die Beziehungen zwischen Knoten. Zur Speicherung jeder Art von Beziehungen wird eine separate Tabelle verwendet.
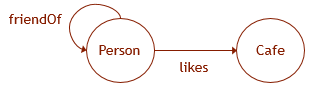 Um das Gesagte zu verdeutlichen, nehmen wir als Beispiel an, dass die Graphdaten ein Schema wie in der dargestellten Abbildung haben. Um die entsprechende Struktur in der Datenbank zu erstellen, müssen die folgenden DDL-Abfragen ausgeführt werden:
Um das Gesagte zu verdeutlichen, nehmen wir als Beispiel an, dass die Graphdaten ein Schema wie in der dargestellten Abbildung haben. Um die entsprechende Struktur in der Datenbank zu erstellen, müssen die folgenden DDL-Abfragen ausgeführt werden:
CREATE TABLE Person (
ID INTEGER NOT NULL,
name VARCHAR(100)
) AS NODE;
CREATE TABLE Cafe (
ID INTEGER NOT NULL,
name VARCHAR(100),
) AS NODE;
CREATE TABLE likes (
rating INTEGER
) AS EDGE;
CREATE TABLE friendOf
AS EDGE;
ALTER TABLE likes
ADD CONSTRAINT EC_LIKES CONNECTION (Person TO Cafe);Die Hauptspezifik dieser Tabellen besteht darin, dass in den Abfragen graphische Muster mit einem Cypher-ähnlichen Syntax verwendet werden können (außerdem werden „*und andere derzeit nicht unterstützt). Basierend auf Leistungsmessungen kann auch vermutet werden, dass die Art der Datenspeicherung in diesen Tabellen sich von dem Mechanismus zur Speicherung in herkömmlichen Tabellen unterscheidet und für die Ausführung solcher graphischen Abfragen optimiert ist.
SELECT Cafe.name
FROM Person, likes, Cafe
WHERE MATCH (Person-(friendOf)-(likes)->Cafe)
AND Person.name = 'John';Darüber hinaus ist es ziemlich herausfordernd, bei der Arbeit mit solchen Tabellen grafische Muster zu umgehen, da es in normalen SQL-Abfragen zusätzliche Anstrengungen erfordert, um die systemischen "grafischen" Identifikatoren der Knoten zu erhalten ($node_id, $from_id, $to_id; aus demselben Grund sind die Abfragen zum Einfügen von Daten hier nicht aufgeführt, da sie als unnötig sperrig gelten).
Zusammenfassend kann ich sagen, dass die Implementierung der Dokumenten- und Graphmodelle in MS SQL Server in erster Linie aus sprachlicher Designperspektive nicht erfolgreich erscheint. Es erfordert, dass eine Sprache die andere erweitert; die Sprachen sind nicht ganz "orthogonal", und die Kombinationsregeln können recht eigenwillig sein.
Multimodale Datenbanksysteme auf Basis des Dokumentenmodells
In diesem Abschnitt möchte ich die Umsetzung der Multimodalität in Dokumenten-Datenbanken anhand des Beispiels von MongoDB illustrieren, die zwar nicht die populärste ist (wie bereits erwähnt, enthält sie nur bedingt grafische Operatoren, $lookup und $graphLookup, die nicht mit sharded Collections funktionieren), sondern anhand einer ausgereifteren und "enterprise-fähigen" Datenbank. .
Stellen Sie sich vor, die Sammlung enthält eine Reihe von XML-Dokumenten folgender Art (MarkLogic unterstützt auch die Speicherung von JSON-Dokumenten):
John
SmithRelationales Modell in MarkLogic
Die relationale Darstellung der Dokumentensammlung kann mittels (der Inhalt der Elemente value im folgenden Beispiel kann beliebiges XPath sein):
/Person
Person
SSN
@SSN
string
name
name
surname
surnameAuf die erstellte Ansicht kann eine SQL-Abfrage (zum Beispiel über ODBC) gerichtet werden:
SELECT name, surname FROM Person WHERE name="John"Leider ist die mit einer Mapping-Vorlage erstellte relationale Darstellung nur schreibgeschützt verfügbar. Bei der Bearbeitung einer Abfrage daran wird MarkLogic versuchen, zu verwenden. Zuvor gab es in MarkLogic auch eingeschränkte relationale Darstellungen, die vollständig und für die Aufnahme verfügbar, aber werden derzeit als veraltet betrachtet.
Graph-Modell in MarkLogic
Mit der Unterstützung des graphenbasierten (RDF) Modells verhält es sich ähnlich. Auch hier kann man mit Hilfe von eine RDF-Darstellung der oben genannten Dokumentensammlung erstellen:
/Person
PREFIX
"http://example.org/example#"
sem:iri( $PREFIX || @SSN )
sem:iri( $PREFIX || surname )
sem:iri( $PREFIX || @SSN )
sem:iri( $PREFIX || name )
Auf das resultierende RDF-Graf kann eine SPARQL-Abfrage gerichtet werden:
PREFIX :
SELECT ?name ?surname {
:631803299804 :name ?name ; :surname ?surname .
}Im Gegensatz zum relationalen Modell unterstützt MarkLogic die graphenbasierte Modellierung auf zwei weitere Arten:
- Die DB kann als eigenständiger RDF-Datenbestand fungieren (die Tripel werden dann genannt im Gegensatz zu den oben beschriebenen ).
- RDF in einer speziellen Serialisierung kann einfach in XML- oder JSON-Dokumente eingefügt werden (und die Tripel werden dann genannt ). Wahrscheinlich ist dies eine Alternative zu den Mechanismen
idrefund so weiter.
Ein gutes Verständnis dafür, wie alles in MarkLogic tatsächlich funktioniert, vermittelt , in diesem Sinne ist es niedriglevelig, obwohl sein Zweck eher umgekehrt ist – zu versuchen, sich von dem verwendeten Datenmodell zu abstrahieren, um eine konsistente Arbeit mit Daten in verschiedenen Modellen sicherzustellen, Transaktionsfähigkeit usw.
Multimodale Datenbanksysteme „ohne Hauptmodell“
Auf dem Markt gibt es auch Datenbanksysteme, die sich von Anfang an als multimodal positionieren und kein vererbtes Hauptmodell haben. Dazu gehören , seit 2018 gehört das Entwicklerunternehmen zu SAP) und (ein Dienst innerhalb der Cloud-Plattform Microsoft Azure).
Tatsächlich gibt es "Haupt"-Modelle in ArangoDB und OrientDB. In beiden Fällen handelt es sich um eigene Datenmodelle, die Verallgemeinerungen des Dokumentenmodells darstellen. Diese Verallgemeinerungen erleichtern hauptsächlich das Ausführen von Anfragen sowohl grafischer als auch relationaler Art.
Diese Modelle sind in den angegebenen Datenbanksystemen die einzigen, die verfügbar sind. Sie benötigen spezielle Abfragesprachen zur Nutzung. Zweifellos sind solche Modelle und Datenbanksysteme vielversprechend, jedoch macht die fehlende Kompatibilität mit Standardmodellen und -sprachen ihre Verwendung in bestehenden Systemen unmöglich – eine Ersetzung der dort bereits genutzten Datenbanksysteme durch diese ist nicht realisierbar.
Über ArangoDB und OrientDB gab es bereits einen hervorragenden Artikel auf Habré: .
ArangoDB
ArangoDB gibt die Unterstützung des graphbasierten Datenmodells an.
Die Knoten des Graphen in ArangoDB sind gewöhnliche Dokumente, während die Kanten spezielle Dokumente sind, die neben den regulären Systemfeldern (_key, _id, _rev) auch systemeigene Felder enthalten, die _from und _to. Dokumente in dokumentenbasierten Datenbanksystemen werden traditionell in Kollektionen gruppiert. Die Kollektionen von Dokumenten, die Kanten darstellen, werden in ArangoDB edge-Kollektionen genannt. Übrigens sind Dokumente in edge-Kollektionen ebenfalls Dokumente, sodass Kanten in ArangoDB auch als Knoten fungieren können.
Rohdaten
Angenommen, wir haben eine Kollektion persons, deren Dokumente folgendermaßen aussehen:
[
{
"_id" : "people/alice" ,
"_key" : "alice" ,
"name" : "Alice"
},
{
"_id" : "people/bob" ,
"_key" : "bob" ,
"name" : "Bob"
}
]Angenommen, es gibt auch eine Kollektion cafes:
[
{
"_id" : "cafes/jd" ,
"_key" : "jd" ,
"name" : "John Donne"
},
{
"_id" : "cafes/jj" ,
"_key" : "jj" ,
"name" : "Jean-Jacques"
}
]Dann sieht die Sammlung Likes so aus:
[
{
"_id" : "likes/1" ,
"_key" : "1" ,
"_from" : "persons/alice" ,
"_to" : "cafes/jd",
"since" : 2010
},
{
"_id" : "likes/2" ,
"_key" : "2" ,
"_from" : "persons/alice" ,
"_to" : "cafes/jj",
"since" : 2011
} ,
{
"_id" : "likes/3" ,
"_key" : "3" ,
"_from" : "persons/bob" ,
"_to" : "cafes/jd",
"since" : 2012
}
]Abfragen und Ergebnisse
Die Abfrage im graphbasierten Stil in der von ArangoDB verwendeten AQL-Sprache, die in lesbarer Form anzeigt, welches Café wem gefällt, lautet wie folgt:
FOR p IN persons
FOR c IN OUTBOUND p likes
RETURN { person : p.name , likes : c.name }Im relationalen Stil, wo wir eher Verbindungen "berechnen" als sie zu speichern, kann diese Abfrage so umgeschrieben werden (übrigens ohne Sammlung Likes könnte man auskommen):
FOR p IN persons
FOR l IN likes
FILTER p._key == l._from
FOR c IN cafes
FILTER l._to == c._key
RETURN { person : p.name , likes : c.name }Das Ergebnis wird in beiden Fällen dasselbe sein:
[
{ "person" : "Alice" , likes : "Jean-Jacques" } ,
{ "person" : "Alice" , likes : "John Donne" } ,
{ "person" : "Bob" , likes : "John Donne" }
]Weitere Abfragen und Ergebnisse
Wenn es scheint, dass das obige Format mehr für relationale Datenbanken charakteristisch ist als für dokumentenbasierte, können Sie eine solche Abfrage versuchen (oder es verwenden) ):
FOR p IN persons
RETURN {
person : p.name,
likes : (
FOR c IN OUTBOUND p likes
RETURN c.name
)
}Das Ergebnis wird folgendermassen aussehen:
[
{ "person" : "Alice" , likes : ["Jean-Jacques" , "John Donne"] } ,
{ "person" : "Bob" , likes : ["John Donne"] }
]OrientDB
Die Implementierung des Graphmodells über der Dokumentenstruktur in OrientDB basiert auf Dokumentenfeldern, die neben mehr oder weniger standardisierten Skalaren auch Werte solcher Typen besitzen können, wie LINK, LINKLIST, LINKSET, LINKMAP und LINKBAG. Die Werte dieser Typen sind Verlinkungen oder Sammlungen von Verlinkungen zu von Dokumenten.
Die von der Systemzuweisung vergebene Identifikation eines Dokuments hat „physikalische Bedeutung“, da sie die Position des Eintrags in der Datenbank angibt, und sieht ungefähr so aus: @rid : #3:16. Damit sind die Werte der Verlinkungseigenschaften tatsächlich eher Zeiger (wie im Graphmodell), anstatt Selektionsbedingungen (wie in relationalen).
Wie bei ArangoDB werden in OrientDB Kanten als eigene Dokumente dargestellt (obwohl man eine Kante ohne eigene Eigenschaften als , und es wird kein separates Dokument entsprechen).
Rohdaten
In einem nahen Format zu von OrientDB würden die Daten aus dem vorherigen Beispiel für ArangoDB ungefähr so aussehen:
[
{
"@type": "document",
"@rid": "#11:0",
"@class": "Person",
"name": "Alice",
"out_likes": [
"#30:1",
"#30:2"
],
"@fieldTypes": "out_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#12:0",
"@class": "Person",
"name": "Bob",
"out_likes": [
"#30:3"
],
"@fieldTypes": "out_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#21:0",
"@class": "Cafe",
"name": "Jean-Jacques",
"in_likes": [
"#30:2",
"#30:3"
],
"@fieldTypes": "in_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#22:0",
"@class": "Cafe",
"name": "John Donne",
"in_likes": [
"#30:1"
],
"@fieldTypes": "in_likes=LINKBAG"
},
{
"@type": "document",
"@rid": "#30:1",
"@class": "likes",
"in": "#22:0",
"out": "#11:0",
"since": 1262286000000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
},
{
"@type": "document",
"@rid": "#30:2",
"@class": "likes",
"in": "#21:0",
"out": "#11:0",
"since": 1293822000000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
},
{
"@type": "document",
"@rid": "#30:3",
"@class": "likes",
"in": "#21:0",
"out": "#12:0",
"since": 1325354400000,
"@fieldTypes": "in=LINK,out=LINK,since=date"
}
]Wie wir sehen, enthalten die Knoten ebenfalls Informationen über eingehende und ausgehende Kanten. Bei Die Dokumenten-API zur Gewährleistung der referenziellen Integrität muss manuell überwacht werden, während die Graph-API diese Aufgabe übernimmt. Lassen Sie uns jedoch sehen, wie eine Abfrage an OrientDB in „reinen“, nicht in Programmiersprachen integrierten Abfragesprachen aussieht.
Abfragen und Ergebnisse
Eine Abfrage, die dem Zweck der Beispielabfrage für ArangoDB entspricht, sieht in OrientDB so aus:
SELECT name AS person_name, OUT('likes').name AS cafe_name
FROM Person
UNWIND cafe_nameDas Ergebnis wird folgendermaßen aussehen:
[
{ "person_name": "Alice", "cafe_name": "John Donne" },
{ "person_name": "Alice", "cafe_name": "Jean-Jacques" },
{ "person_name": "Bob", "cafe_name": "Jean-Jacques" }
]Wenn das Ergebnisformat erneut zu sehr „relationale“ Züge hat, sollte die Zeile mit :
[
{ "person_name": "Alice", "cafe_name": [ "John Donne", "Jean-Jacques" ] },
{ "person_name": "Bob", "cafe_name": [ "Jean-Jacques" ] }
]Die Abfragesprache von OrientDB kann als SQL mit gremlin-ähnlichen Einfügungen charakterisiert werden. In Version 2.2 wurde eine cypher-ähnliche Abfrageform eingeführt. :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe}
RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name
GROUP BY person_nameDas Ergebnisformat wird dasselbe sein wie in der vorherigen Abfrage. Überlegen Sie, was entfernt werden muss, um es „relationeller“ zu machen, wie in der allerersten Abfrage.
Azure CosmosDB
In geringerem Maße gilt das oben Gesagte über ArangoDB und OrientDB auch für Azure CosmosDB. CosmosDB bietet die folgenden APIs für den Datenzugriff: SQL, MongoDB, Gremlin und Cassandra.
Die SQL API und die MongoDB API werden für den Zugriff auf Daten im Dokumentenmodell verwendet. Die Gremlin API und die Cassandra API dienen dem Zugriff auf Daten im Graph- bzw. Spaltenmodell. Daten in allen Modellen werden im Format des internen Modells von CosmosDB gespeichert: („atom-record-sequence“), das ebenfalls dem Dokumentenmodell nahekommt.

Das vom Benutzer gewählte Datenmodell und die verwendete API werden bei der Erstellung des Kontos im Service festgelegt. Es ist nicht möglich, auf Daten einer geladenen Modellart im Format einer anderen Modellart zuzugreifen, was ungefähr durch eine solche Abbildung veranschaulicht werden könnte:

Damit stellt die Multimodellfähigkeit von Azure CosmosDB derzeit lediglich die Möglichkeit dar, mehrere Datenbanken zu verwenden, die verschiedene Modelle von einem Anbieter unterstützen, was nicht alle Probleme der variantenreichen Speicherung löst.
Multimodale Datenbanksysteme auf Basis des Graphmodells?
Es ist bemerkenswert, dass es auf dem Markt derzeit keine multimodalen DBMS gibt, die auf einem Grafikmodell basieren (außer bei der multimodalen Unterstützung von zwei gleichzeitig verwendeten Grafikmodellen: RDF und LPG; siehe dazu in ). Die größte Herausforderung besteht in der Umsetzung eines dokumentenbasierten Modells auf der Grafik- und nicht auf der relationalen Ebene.
Die Frage, wie man ein relationales Modell auf einem Grafikmodell implementieren kann, wurde bereits in den Anfangszeiten des relationalen Modells behandelt. Wie , zum Beispiel, :
Es gibt nichts am Grafikansatz, das es verbietet, eine Schicht (z.B. durch geeignete Indizierung) auf einer Graphdatenbank zu erstellen, die eine relationale Sicht ermöglicht, mit (1) der Wiederherstellung von Tupeln aus den üblichen Schlüssel-Wert-Paaren und (2) der Gruppierung von Tupeln nach Beziehungstyp.
Bei der Implementierung eines dokumentenbasierten Modells auf einer Grafikdatenbank sollte man beispielsweise Folgendes beachten:
- Die Elemente eines JSON-Arrays gelten als geordnet, ausgehend von der Spitze einer Kante des Grafen - nicht so;
- Daten im dokumentenbasierten Modell sind im Allgemeinen denormalisiert; mehrere Kopien desselben eingebetteten Dokuments zu speichern, ist jedoch nicht wünschenswert, und Unterdokumente haben normalerweise keine Identifikatoren.
- Andererseits besteht die Philosophie von dokumentenbasierten DBMS darin, dass Dokumente fertige „Aggregate“ sind, die nicht jedes Mal neu erstellt werden müssen. Es muss sichergestellt werden, dass in der Graphenstruktur schnell ein Teilgraph abgerufen werden kann, der dem fertigen Dokument entspricht.
Ein bisschen Werbung
Der Autor des Artikels ist an der Entwicklung des DBMS NitrosBase beteiligt, dessen internes Modell graphisch ist, während die externen Modelle - relationale und dokumentenbasierte - deren Darstellungen sind. Alle Modelle sind gleichberechtigt: Praktisch alle Daten sind in jedem von ihnen mithilfe der jeweils eigenen Abfragesprache verfügbar. Darüber hinaus können die Daten in jeder Darstellung verändert werden. Diese Änderungen spiegeln sich im internen Modell und folglich in den anderen Darstellungen wider.
Wie die Übereinstimmung der Modelle in NitrosBase aussieht, werde ich hoffentlich in einem der nächsten Artikel beschreiben.
Fazit
Ich hoffe, dass die grundlegenden Merkmale dessen, was als Multimodellität bezeichnet wird, dem Leser mehr oder weniger klar sind. Multimodell-Datenbanken sind ziemlich unterschiedlich, und die "Unterstützung mehrerer Modelle" kann unterschiedlich aussehen. Um zu verstehen, was in jedem speziellen Fall unter "Multimodellität" verstanden wird, ist es nützlich, die folgenden Fragen zu beantworten:
- Geht es um die Unterstützung traditioneller Modelle oder um eine bestimmte "hybride" Modellform?
- Sind die Modelle "gleichwertig", oder ist eines untergeordnet?
- Sind die Modelle einander "gleichgültig"? Können Daten, die in einem Modell gespeichert sind, in einem anderen gelesen oder sogar überschrieben werden?
Ich denke, die Frage nach der Relevanz von multimodalen Datenbanksystemen kann mittlerweile positiv beantwortet werden. Interessant ist jedoch, welche ihrer Varianten in naher Zukunft gefragter sein werden. Es scheint, dass insbesondere multimodale Datenbanksysteme, die traditionelle Modelle unterstützen, insbesondere relationale, an Beliebtheit gewinnen werden; die Popularität von multimodalen Datenbanksystemen, die neue Modelle anbieten und die Vorteile verschiedener traditioneller Modelle kombinieren, ist eher eine Frage der ferneren Zukunft.
Nur registrierte Benutzer können an der Umfrage teilnehmen. Sind Sie an Contour interessiert?
Nutzen Sie multimodale Datenbanksysteme?
Wir nutzen sie nicht, wir speichern alles in einem einzigen Datenbanksystem und in einem einzigen Modell.
Wir verwenden die multimodalen Möglichkeiten traditioneller Datenbanksysteme.
Wir praktizieren polyglot persistence.
Wir nutzen neue multimodale Datenbanksysteme (Arango, Orient, CosmosDB).
19 Benutzer haben abgestimmt. 4 Benutzer haben sich enthalten.
Quelle: habr.com
