

Das OpenAI-Projekt, das öffentliche Projekte im Bereich der künstlichen Intelligenz entwickelt, hat Entwicklungen im Zusammenhang mit dem Spracherkennungssystem Whisper veröffentlicht. Es wird behauptet, dass das System für Sprache in Englisch ein Maß an Zuverlässigkeit und Genauigkeit der automatischen Erkennung bietet, das der menschlichen Erkennung nahe kommt. Der Code für die Referenzimplementierung basierend auf dem PyTorch-Framework und eine Reihe bereits trainierter, einsatzbereiter Modelle wurden geöffnet. Der Code ist unter der MIT-Lizenz geöffnet.
Zum Trainieren des Modells wurden 680 Stunden Sprachdaten verwendet, die aus mehreren Sammlungen zu verschiedenen Sprachen und Fachgebieten gesammelt wurden. Etwa 1/3 der beim Training beteiligten Sprachdaten liegen in anderen Sprachen als Englisch vor. Das vorgeschlagene System geht korrekt mit Situationen wie akzentuierter Aussprache, Hintergrundgeräuschen und der Verwendung von Fachjargon um. Neben der Transkription von Sprache in Text kann das System auch Sprache aus jeder Sprache ins Englische übersetzen und das Auftreten von Sprache im Audiostream erkennen.
Die Modelle werden in zwei Darstellungen gebildet: einem Modell für die englische Sprache und einem mehrsprachigen Modell, das auch russische, ukrainische und weißrussische Sprachen unterstützt. Jede Darstellung ist wiederum in 5 Optionen unterteilt, die sich in Größe und Anzahl der im Modell abgedeckten Parameter unterscheiden. Je größer die Größe, desto höher die Genauigkeit und Qualität der Erkennung, aber auch desto höher die Anforderungen an die Größe des GPU-Videospeichers und desto geringer die Leistung. Beispielsweise umfasst die Mindestoption 39 Millionen Parameter und erfordert 1 GB Videospeicher, und die Höchstoption umfasst 1550 Millionen Parameter und erfordert 10 GB Videospeicher. Die minimale Option ist 32-mal schneller als die maximale.
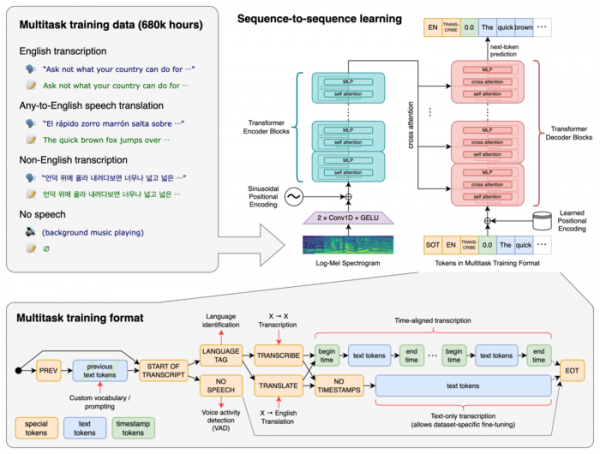
Das System nutzt die neuronale Netzwerkarchitektur Transformer, die einen Encoder und einen Decoder umfasst, die miteinander interagieren. Das Audio wird in 30-Sekunden-Blöcke zerlegt, die in ein Log-Mel-Spektrogramm umgewandelt und an den Encoder gesendet werden. Die Ausgabe des Encoders wird an den Decoder gesendet, der eine mit speziellen Token gemischte Textdarstellung vorhersagt, die es in einem allgemeinen Modell ermöglicht, Probleme wie Spracherkennung, Berücksichtigung der Chronologie der Aussprache von Phrasen und Transkription von Sprache zu lösen verschiedene Sprachen und Übersetzung ins Englische.
Source: opennet.ru
