

Das DBOS-Projekt (DBMS-orientiertes Betriebssystem) wird vorgestellt, das ein neues Betriebssystem für die Ausführung skalierbarer verteilter Anwendungen entwickelt. Eine Besonderheit des Projekts ist die Verwendung eines DBMS zur Speicherung von Anwendungen und Systemstatus sowie die Organisation des Zugriffs auf den Status ausschließlich über Transaktionen. Das Projekt wird von Forschern des Massachusetts Institute of Technology, der University of Wisconsin und Stanford, der Carnegie Mellon University sowie Google und VMware entwickelt. Das Werk wird unter der MIT-Lizenz vertrieben.
Im Mikrokernel sind Komponenten für die Interaktion mit Geräten und Low-Level-Speicherverwaltungsdiensten untergebracht. Die vom Mikrokernel bereitgestellten Funktionen werden zum Starten der DBMS-Schicht verwendet. Systemdienste auf hoher Ebene, die die Anwendungsausführung ermöglichen, interagieren nur mit dem verteilten DBMS und sind vom Mikrokernel und den systemspezifischen Komponenten getrennt.
Der Aufbau auf einem verteilten DBMS ermöglicht es, Systemdienste zunächst zu verteilen und nicht an einen bestimmten Knoten zu binden, was DBOS von herkömmlichen Clustersystemen unterscheidet, bei denen jeder Knoten seine eigene Instanz des Betriebssystems ausführt, auf der eine separate Instanz ausgeführt wird Cluster-Scheduler, verteilte Dateisysteme und Netzwerkmanager werden eingeführt.
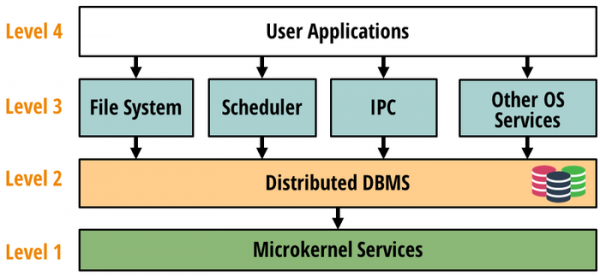
Es wird darauf hingewiesen, dass die Verwendung moderner verteilter DBMS als Basis für DBOS, die Speicherung von Daten im RAM und die Unterstützung von Transaktionen wie VoltDB und FoundationDB eine ausreichende Leistung für die effiziente Ausführung vieler Systemdienste bieten kann. Das DBMS kann auch Scheduler-, Dateisystem- und IPC-Daten speichern. Gleichzeitig sind DBMS hochgradig skalierbar, bieten Atomizität und Transaktionsisolation, können Petabytes an Daten verwalten und bieten Tools für die Zugriffskontrolle und die Verfolgung von Datenflüssen.
Zu den Vorteilen der vorgeschlagenen Architektur gehört eine deutliche Erweiterung der Analysefunktionen und eine Reduzierung der Codekomplexität durch die Verwendung gewöhnlicher Abfragen an das DBMS in den Betriebssystemdiensten, auf deren Seite die Implementierung von Transaktionen und Tools zur Gewährleistung hoher Qualität erfolgt Verfügbarkeit wird durchgeführt (solche Funktionalität kann auf der DBMS-Seite einmal implementiert und in Betriebssystemen und Anwendungen verwendet werden).
Beispielsweise kann ein Cluster-Scheduler Informationen über Aufgaben und Handler in DBMS-Tabellen speichern und Planungsvorgänge als reguläre Transaktionen implementieren, wobei imperativer Code und SQL gemischt werden. Transaktionen erleichtern die Lösung von Problemen wie der Parallelitätsverwaltung und der Wiederherstellung nach Fehlern, da Transaktionen Konsistenz und Zustandspersistenz gewährleisten. Im Kontext des Scheduler-Beispiels ermöglichen Transaktionen den gleichzeitigen Zugriff auf gemeinsam genutzte Daten und stellen sicher, dass die Zustandsintegrität im Falle von Fehlern gewahrt bleibt.
Die vom DBMS bereitgestellten Protokollierungs- und Datenanalysemechanismen können verwendet werden, um Zugriffe und Änderungen im Anwendungsstatus zu verfolgen, zu überwachen, zu debuggen und die Sicherheit aufrechtzuerhalten. Nachdem Sie beispielsweise einen unbefugten Zugriff auf ein System erkannt haben, können Sie SQL-Abfragen ausführen, um das Ausmaß des Lecks zu ermitteln und alle Vorgänge zu identifizieren, die von Prozessen ausgeführt wurden, die Zugriff auf vertrauliche Informationen erhalten haben.
Das Projekt befindet sich seit mehr als einem Jahr in der Entwicklung und befindet sich in der Phase der Erstellung von Prototypen einzelner Architekturkomponenten. Derzeit wurde ein Prototyp von Betriebssystemdiensten vorbereitet, die auf dem DBMS laufen, wie z. B. FS, IPC und Scheduler, und eine Softwareumgebung entwickelt, die eine Schnittstelle zum Ausführen von Anwendungen basierend auf dem FaaS (Function-As-) bereitstellt. a-Service-Modell.
Die nächste Entwicklungsstufe sieht die Bereitstellung eines vollwertigen Software-Stacks für verteilte Anwendungen vor. VoltDB wird derzeit als DBMS in Experimenten eingesetzt, es gibt jedoch Diskussionen darüber, eine eigene Schicht zum Speichern von Daten zu erstellen oder fehlende Funktionen in bestehenden DBMS zu implementieren. Diskutiert wird auch die Frage, welche Komponenten auf Kernel-Ebene ausgeführt werden sollen und welche auf dem DBMS implementiert werden können.
Source: opennet.ru
