

Im Rahmen eines Forschungsprojekts wurde die Arbeit an der Implementierung einer Funktion in GCC begonnen, die es ermöglicht, den Kompilierungsprozess auf mehrere parallel ausgeführte Threads zu verteilen. Derzeit wird zur Steigerung der Baugeschwindigkeit auf Multi-Core-Systemen im Rahmen des Make-Tools das Starten separater Compiler-Prozesse genutzt, von denen jeder eine separate Datei mit Code kompiliert. Das neue Projekt experimentiert mit der Bereitstellung von Parallelisierung auf Compiler-Ebene, was potenziell die Effizienz auf Multi-Core-Systemen erhöhen könnte.
Zur Durchführung von Tests eine separate Parallelisierungszweig von GCC, für den ein neuer Parameter "—param=num-threads=N" vorgeschlagen wurde, um die Anzahl der Threads festzulegen. In der Anfangsphase wurden interprozedurale Optimierungen in separate Ausführungsthreads ausgelagert, die zyklisch für jede Funktion aufgerufen werden und gut parallelisierbar sind. In separate Threads wurden GIMPLE-Operationen ausgegliedert, die für hardwareunabhängige Optimierungen verantwortlich sind und die Wechselwirkungen zwischen den Funktionen bewerten.
In der nächsten Phase ist geplant, auch die interprozeduralen RTL-Optimierungen, die spezifische Merkmale der Hardware-Plattform berücksichtigen, in separate Ströme auszulagern. Danach soll das Parallelisieren der intra-prozeduralen Optimierungen (IPA) realisiert werden, die auf den Code innerhalb der Funktion angewendet werden, unabhängig von den Besonderheiten des Aufrufs. Derzeit ist der begrenzende Faktor der Garbage Collector, dem eine globale Sperre hinzugefügt wurde, die die Garbage Collection während des Multithread-Betriebs deaktiviert (künftig wird der Garbage Collector für die parallele Ausführung von GCC angepasst).
Um die Leistungsänderung zu bewerten, wurde ein Testset vorbereitet, das die Datei gimple-match.c kompiliert, die mehr als 100.000 Zeilen Code und 1700 Funktionen umfasst. Tests auf einem System mit einem Intel Core i5-8250U-CPU mit 4 physischen Kernen und 8 virtuellen Kernen (Hyperthreading) zeigten eine Verringerung der Ausführungszeit der Intra Procedural GIMPLE-Optimierungen von 7 auf 4 Sekunden bei der Ausführung von 2 Threads und auf 3 Sekunden bei der Ausführung von 4 Threads, was eine Geschwindigkeitssteigerung des betrachteten Kompilierungsschritts von 1,72 bzw. 2,52 ergibt. Die Tests zeigten auch, dass die Verwendung virtueller Kerne bei Hyperthreading nicht zu einer Leistungssteigerung führt.
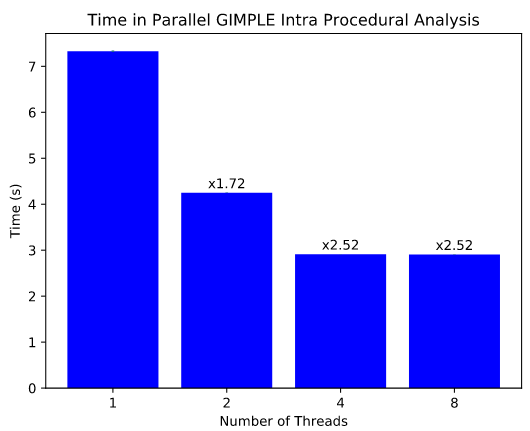
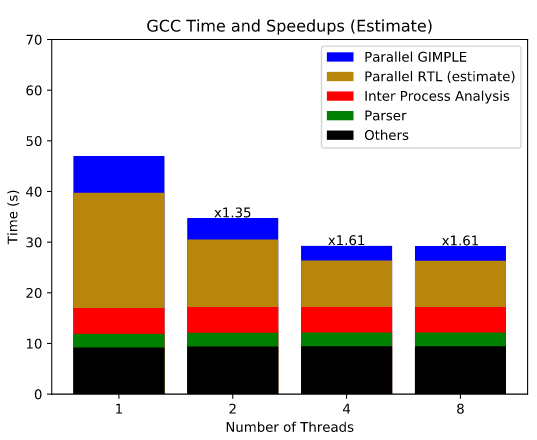
Die gesamte Bauzeit wurde um etwa 10 % verkürzt, jedoch wird prognostiziert, dass die Parallelisierung der RTL-Optimierungen deutlichere Ergebnisse liefern wird, da diese Phase bei der Kompilierung erheblich mehr Zeit in Anspruch nimmt. Schätzungsweise wird nach der Parallelisierung der RTL die gesamte Bauzeit um den Faktor 1,61 reduziert. Danach kann die Bauzeit noch um 5–10 % durch die Parallelisierung der IPA-Optimierungen weiter verkürzt werden.
Quelle: opennet.ru
