

In diesem Artikel werden mehrere Methoden zur Bestimmung der mathematischen Gleichung der einfachen (paarweisen) Regression betrachtet.
Alle hier diskutierten Lösungsverfahren basieren auf der Methode der kleinsten Quadrate. Wir kennzeichnen die Methoden wie folgt:
- Analytische Lösung
- Gradientenabstieg
- Stochastischer Gradientabstieg
Für jede der Methoden zur Lösung der Geradengleichung werden in dem Artikel verschiedene Funktionen präsentiert, die hauptsächlich in solche unterteilt werden, die ohne die Verwendung der Bibliothek NumPy geschrieben sind, und solche, die zur Durchführung der Berechnungen verwenden NumPy. Es wird angenommen, dass eine geschickte Nutzung NumPy die Berechnungskosten senken kann.
Der gesamte im Artikel angegebene Code ist in der Sprache python 2.7 geschrieben und verwendet Jupyter Notebook. Der Quellcode und die Datendatei sind auf
veröffentlicht. Der Artikel richtet sich in erster Linie an Anfänger sowie an diejenigen, die bereits beginnen, sich in einem sehr umfassenden Bereich der künstlichen Intelligenz — dem maschinellen Lernen — zurechtzufinden.
Zur Veranschaulichung des Materials verwenden wir ein sehr einfaches Beispiel.
Bedingungen des Beispiels
Wir haben fünf Werte, die die Abhängigkeit charakterisieren. Y ab X (Tabelle Nr. 1):
Tabelle Nr. 1 „Bedingungen des Beispiels“

Wir nehmen an, dass die Werte  — der Monat des Jahres sind, und
— der Monat des Jahres sind, und  — der Umsatz in diesem Monat. Anders ausgedrückt, der Umsatz hängt vom Monat des Jahres ab, und
— der Umsatz in diesem Monat. Anders ausgedrückt, der Umsatz hängt vom Monat des Jahres ab, und  — das ist das einzige Merkmal, von dem der Umsatz abhängt.
— das ist das einzige Merkmal, von dem der Umsatz abhängt.
Das Beispiel ist nicht ideal, sowohl hinsichtlich der hypothetischen Abhängigkeit des Umsatzes vom Monat als auch hinsichtlich der Anzahl der Werte – es sind sehr wenige. Dieses Vereinfachung ermöglicht jedoch, sozusagen auf den Fingern, zu erklären, was für Anfänger nicht immer einfach zu erlernen ist. Zudem erlaubt die Einfachheit der Zahlen, dass Interessierte dieses Beispiel ohne großen Aufwand "auf Papier" durchrechnen können.
Angenommen, die im Beispiel dargestellte Abhängigkeit kann ziemlich gut durch eine mathematische Gleichung der einfachen (paarweisen) Regression der folgenden Form approximiert werden:

wobei  — der Monat ist, in dem der Umsatz erzielt wurde,
— der Monat ist, in dem der Umsatz erzielt wurde,  — der Umsatz, der dem Monat entspricht,
— der Umsatz, der dem Monat entspricht,  und
und  — die Koeffizienten der regressierten Linie sind.
— die Koeffizienten der regressierten Linie sind.
Es sei darauf hingewiesen, dass der Koeffizient  oft als Steigungskoeffizient oder Gradient der regressierten Linie bezeichnet wird; er stellt die Größe dar, um die sich
oft als Steigungskoeffizient oder Gradient der regressierten Linie bezeichnet wird; er stellt die Größe dar, um die sich  bei der Änderung
bei der Änderung  .
.
Offensichtlich besteht unsere Aufgabe im Beispiel darin, im Gleichung die geeigneten Koeffizienten auszuwählen  und
und  , bei denen die Abweichungen unserer berechneten Umsatzwerte über die Monate von den tatsächlichen Antworten, d.h. den Werten, die in der Stichprobe präsentiert sind, minimal sind.
, bei denen die Abweichungen unserer berechneten Umsatzwerte über die Monate von den tatsächlichen Antworten, d.h. den Werten, die in der Stichprobe präsentiert sind, minimal sind.
Die Methode der kleinsten Quadrate
Gemäß der Methode der kleinsten Quadrate sollte die Abweichung berechnet werden, indem man sie quadriert. Diese Vorgehensweise verhindert eine gegenseitige Aufhebung der Abweichungen, wenn sie entgegengesetzte Vorzeichen haben. Zum Beispiel, wenn in einem Fall die Abweichung +5 (plus fünf) beträgt, und im anderen -5 (minus fünf), dann wird die Summe der Abweichungen sich gegenseitig aufheben und 0 (null) ergeben. Man kann die Abweichung auch nicht quadrieren, sondern die Eigenschaft des Moduls nutzen, sodass alle Abweichungen positiv sind und sich addieren. Wir werden an diesem Punkt nicht ausführlich verweilen, sondern einfach festhalten, dass es zur Vereinfachung der Berechnungen üblich ist, die Abweichung zu quadrieren.
So sieht die Formel aus, mit der wir die kleinste Summe der quadratischen Abweichungen (Fehler) bestimmen werden:

wobei  — das ist eine Funktion zur Annäherung an die tatsächlichen Antworten (also der von uns berechnete Umsatz),
— das ist eine Funktion zur Annäherung an die tatsächlichen Antworten (also der von uns berechnete Umsatz),
 — das sind die tatsächlichen Antworten (der in der Stichprobe angegebene Umsatz),
— das sind die tatsächlichen Antworten (der in der Stichprobe angegebene Umsatz),
 — das ist der Index der Stichprobe (die Monatsnummer, in der die Abweichung bestimmt wird),
— das ist der Index der Stichprobe (die Monatsnummer, in der die Abweichung bestimmt wird),
Lassen Sie uns die Funktion ableiten, die Gleichungen der partiellen Ableitungen bestimmen und bereit sein, zur analytischen Lösung überzugehen. Zunächst jedoch machen wir einen kurzen Ausflug in das Thema Differenzierung und erinnern uns an die geometrische Bedeutung der Ableitung.
Differenzierung
Differenzierung bezeichnet die operation zur Bestimmung der Ableitung einer Funktion.
Wozu dient die Ableitung? Die Ableitung einer Funktion zeigt die Änderungsrate der Funktion an und weist uns deren Richtung. Ist die Ableitung an einem bestimmten Punkt positiv, steigt die Funktion; im umgekehrten Fall sinkt die Funktion. Je größer der Betrag der Ableitung, desto höher ist die Änderungsrate der Funktionswerte sowie steiler der Anstieg des Funktionsgraphen.
Zum Beispiel, im Kontext des kartesischen Koordinatensystems bedeutet der Wert der Ableitung am Punkt M(0,0), +25 dass an diesem bestimmten Punkt bei einer Veränderung des Wertes  nach rechts um eine Einheit, der Wert
nach rechts um eine Einheit, der Wert  steigt um 25 Einheiten. Auf dem Diagramm sieht das aus wie ein ziemlich steiler Anstieg der Werte
steigt um 25 Einheiten. Auf dem Diagramm sieht das aus wie ein ziemlich steiler Anstieg der Werte  von einem bestimmten Punkt.
von einem bestimmten Punkt.
Ein weiteres Beispiel. Der Wert der Ableitung ist gleich -0,1 was bedeutet, dass bei einer Verschiebung  um eine Einheit der Wert
um eine Einheit der Wert  nur um 0,1 Einheit abnimmt. Dabei können wir im Graphen der Funktion eine kaum merkliche Neigung nach unten beobachten. Im Vergleich dazu scheinen wir wie sehr langsam einen sanften Hang des Berges hinunterzugehen, während wir im vorherigen Beispiel sehr steile Gipfel nehmen mussten :)
nur um 0,1 Einheit abnimmt. Dabei können wir im Graphen der Funktion eine kaum merkliche Neigung nach unten beobachten. Im Vergleich dazu scheinen wir wie sehr langsam einen sanften Hang des Berges hinunterzugehen, während wir im vorherigen Beispiel sehr steile Gipfel nehmen mussten :)
Somit führen wir die Differenzierung der Funktion  nach den Koeffizienten
nach den Koeffizienten  und
und  , um die Gleichungen der partiellen Ableitungen 1. Ordnung zu bestimmen. Nach der Bestimmung der Gleichungen erhalten wir ein System aus zwei Gleichungen, dessen Lösung es uns ermöglicht, geeignete Werte für die Koeffizienten zu finden.
, um die Gleichungen der partiellen Ableitungen 1. Ordnung zu bestimmen. Nach der Bestimmung der Gleichungen erhalten wir ein System aus zwei Gleichungen, dessen Lösung es uns ermöglicht, geeignete Werte für die Koeffizienten zu finden.  und
und  , bei denen sich die Werte der entsprechenden Ableitungen an den bestimmten Punkten nur sehr geringfügig ändern, während sie im Fall der analytischen Lösung überhaupt nicht verändert werden. Mit anderen Worten, die Fehlerfunktion bei den gefundenen Koeffizienten erreicht ein Minimum, da die Werte der partiellen Ableitungen an diesen Punkten null sind.
, bei denen sich die Werte der entsprechenden Ableitungen an den bestimmten Punkten nur sehr geringfügig ändern, während sie im Fall der analytischen Lösung überhaupt nicht verändert werden. Mit anderen Worten, die Fehlerfunktion bei den gefundenen Koeffizienten erreicht ein Minimum, da die Werte der partiellen Ableitungen an diesen Punkten null sind.
Also, nach den Regeln der Differenzierung hat die Gleichung der partiellen Ableitung 1. Ordnung bezüglich des Koeffizienten  die folgende Form:
die folgende Form:

die Gleichung der partiellen Ableitung 1. Ordnung bezüglich  die folgende Form:
die folgende Form:

Letztendlich haben wir ein Gleichungssystem erhalten, das eine relativ einfache analytische Lösung hat:
begin{equation*}
begin{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
end{cases}
end{equation*}
Bevor wir die Gleichung lösen, laden wir zunächst die Daten hoch, überprüfen die Richtigkeit des Uploads und formatieren die Daten.
Daten hochladen und formatieren
Es ist darauf hinzuweisen, dass wir für die analytische Lösung und später für den Gradienten- und stochastischen Gradientenabstieg den Code in zwei Varianten anwenden werden: mit der Verwendung der Bibliothek NumPy Und ohne ihre Nutzung benötigen wir die entsprechende Datenformatierung (siehe Code).
Code zum Laden und Verarbeiten von Daten
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualisierung
Jetzt, nachdem wir zuerst die Daten geladen, zweitens die Richtigkeit des Ladevorgangs überprüft und schließlich die Daten formatiert haben, führen wir die erste Visualisierung durch. Oft wird dafür die Methode pairplot der Bibliothek Seaborn. In unserem Beispiel macht es aufgrund der begrenzten Zahlen keinen Sinn, die Bibliothek zu verwenden. SeabornWir werden die gängige Bibliothek Matplotlib verwenden und uns nur das Streudiagramm ansehen.
Code für das Streudiagramm
print 'Grafik Nr. 1 "Abhängigkeit der Einnahmen vom Monat des Jahres"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Monate$', size=16)
plt.ylabel('$Verkäufe$', size=16)
plt.show()Grafik Nr. 1 «Abhängigkeit der Einnahmen vom Monat des Jahres»
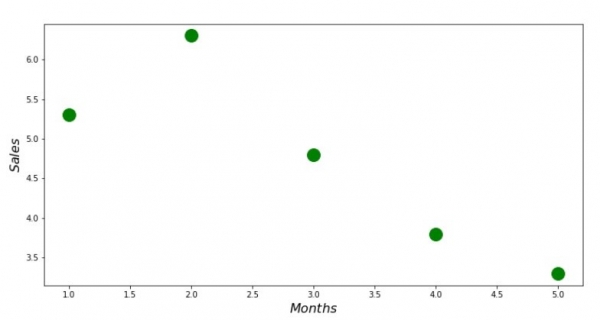
Analytische Lösung
Wir nutzen die einfachsten Werkzeuge in Python und lösen das Gleichungssystem:
begin{equation*}
begin{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
end{cases}
end{equation*}
Nach der Regel von Cramer bestimmen wir den allgemeinen Determinanten sowie die Determinanten nach  und nach
und nach  , und teilen dann die Determinante nach
, und teilen dann die Determinante nach  durch die allgemeine Determinante – um den Koeffizienten
durch die allgemeine Determinante – um den Koeffizienten  zu finden. Analog finden wir den Koeffizienten
zu finden. Analog finden wir den Koeffizienten  .
.
Code für die analytische Lösung
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Das ist das Ergebnis:

Die Werte der Koeffizienten sind gefunden, die Summe der quadratischen Abweichungen ist festgelegt. Lassen Sie uns eine Linie im Streudiagramm gemäß den gefundenen Koeffizienten zeichnen.
Regressionsliniencode
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Grafik Nr. 2 „Korrekte und berechnete Antworten“
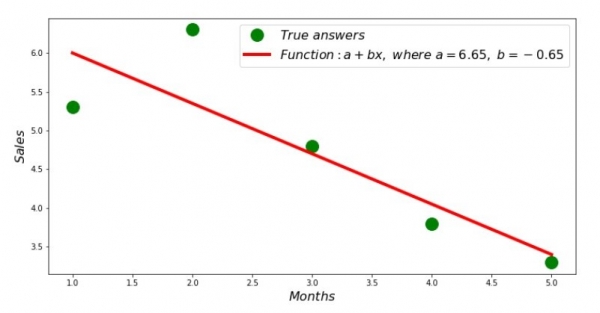
Wir können das Diagramm der Abweichungen für jeden Monat betrachten. In unserem Fall werden wir daraus keinen signifikanten praktischen Nutzen ziehen, aber wir stillen die Neugier, wie gut die Gleichung der einfachen linearen Regression die Abhängigkeit des Umsatzes vom Monat im Jahr beschreibt.
Code für das Abweichungsdiagramm
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Grafik Nr. 3 „Abweichungen, %“
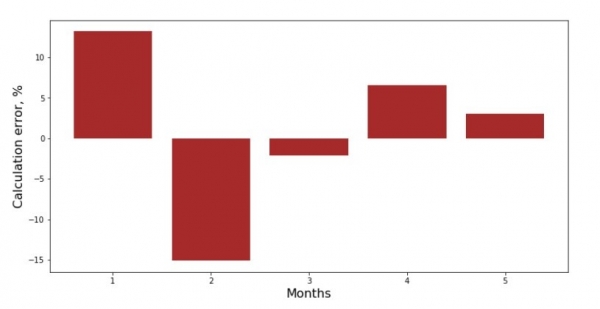
Nicht perfekt, aber wir haben unsere Aufgabe erfüllt.
Lassen Sie uns eine Funktion schreiben, die zur Bestimmung der Koeffizienten  und
und  die Bibliothek verwendet NumPy, genauer gesagt — wir werden zwei Funktionen schreiben: eine mithilfe der pseudo-inversen Matrix (nicht empfohlen in der Praxis, da der Prozess rechenintensiv und instabil ist) und die andere mit der Verwendung der Matrixgleichung.
die Bibliothek verwendet NumPy, genauer gesagt — wir werden zwei Funktionen schreiben: eine mithilfe der pseudo-inversen Matrix (nicht empfohlen in der Praxis, da der Prozess rechenintensiv und instabil ist) und die andere mit der Verwendung der Matrixgleichung.
Code der analytischen Lösung (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npLassen Sie uns die Zeit vergleichen, die für die Bestimmung der Koeffizienten benötigt wurde  und
und  , entsprechend den 3 präsentierten Methoden.
, entsprechend den 3 präsentierten Methoden.
Code zur Berechnung der Berechnungszeit
print ' 33[1m' + ' 33[4m' + "Berechnungszeit der Koeffizienten ohne die Verwendung der Bibliothek NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_methode(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Berechnungszeit der Koeffizienten unter Verwendung der pseudoinversen Matrix:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Berechnungszeit der Koeffizienten unter Verwendung der Matrizen-Gleichung:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Bei einer kleinen Datenmenge hat die "hausgemachte" Funktion, die die Koeffizienten nach der Kramer-Methode findet, die Nase vorn.
Jetzt können wir zu anderen Methoden zur Ermittlung der Koeffizienten übergehen.  und
und  .
.
Gradientenabstieg
Lassen Sie uns zunächst klären, was ein Gradient ist. Einfach ausgedrückt ist ein Gradient ein Vektor, der die Richtung des größten Anstiegs einer Funktion angibt. Verglichen mit dem Anstieg eines Berges zeigt der Gradient in die Richtung des steilsten Aufstiegs zum Gipfel. Wenn wir das Beispiel mit dem Berg weiterführen, müssen wir jedoch daran denken, dass wir tatsächlich den steilsten Abstieg suchen, um so schnell wie möglich den Tiefpunkt zu erreichen, also das Minimum – den Punkt, an dem die Funktion weder steigt noch fällt. An diesem Punkt ist die Ableitung gleich null. Daher benötigen wir nicht den Gradient, sondern den Anti-Gradient. Um den Anti-Gradienten zu finden, muss man nur den Gradient mit -1 (minus eins) multiplizieren.
Es ist wichtig zu beachten, dass eine Funktion mehrere Minima haben kann. Wenn wir nach dem im Folgenden vorgeschlagenen Algorithmus in eines davon hinuntersteigen, können wir das andere Minimum, das möglicherweise tiefer liegt, nicht finden. Aber keine Sorge, das ist uns in diesem Fall nicht möglich! Wir haben es hier mit einem eindeutigen Minimum zu tun, denn unsere Funktion  stellt im Graphen eine gewöhnliche Parabel dar. Und wie wir alle aus dem Mathematikunterricht wissen, hat eine Parabel nur ein Minimum.
stellt im Graphen eine gewöhnliche Parabel dar. Und wie wir alle aus dem Mathematikunterricht wissen, hat eine Parabel nur ein Minimum.
Nachdem wir geklärt haben, wozu wir den Gradienten benötigen, und auch, dass der Gradient ein Segment ist, also ein Vektor mit bestimmten Koordinaten, welche genau die gesuchten Koeffizienten darstellen,  und
und  können wir den Gradientenabstieg umsetzen.
können wir den Gradientenabstieg umsetzen.
Vor dem Start empfehle ich, nur ein paar Sätze über den Abstieg-Algorithmus zu lesen:
- Wir bestimmen die Koeffizienten pseudorandom.
 und In unserem Beispiel werden wir die Koeffizienten in der Nähe von null festlegen. Dies ist eine gängige Praxis, jedoch kann für jeden Fall eine eigene Herangehensweise vorgesehen werden.
und In unserem Beispiel werden wir die Koeffizienten in der Nähe von null festlegen. Dies ist eine gängige Praxis, jedoch kann für jeden Fall eine eigene Herangehensweise vorgesehen werden. - Von der Koordinate ziehen wir den Wert der ersten partiellen Ableitung an der Stelle ab. Ist die Ableitung positiv, steigt die Funktion. Indem wir den Wert der Ableitung abziehen, bewegen wir uns also in die entgegengesetzte Richtung des Anstiegs, also bergab. Ist die Ableitung negativ, dann sinkt die Funktion an diesem Punkt, und durch das Abziehen des Wertes der Ableitung bewegen wir uns in Richtung Abstieg.
- Wir führen eine ähnliche Operation mit der Koordinate durch: wir ziehen den Wert der partiellen Ableitung an der Stelle ab. .
- Um nicht das Minimum zu überspringen und in den tiefen Weltraum zu entgleisen, sollten wir die Schrittgröße für den Abstieg festlegen. Grundsätzlich könnte man einen ganzen Artikel darüber schreiben, wie man die Schrittgröße richtig einstellt und während des Abstiegs anpasst, um die Rechenkosten zu reduzieren. Doch jetzt stehen wir vor einer etwas anderen Aufgabe, und durch einen wissenschaftlichen Versuch, oder wie man im Volksmund sagt, empirisch, werden wir die Schrittgröße bestimmen.
- Nachdem wir die angegebenen Koordinaten und um die Werte der Ableitungen reduziert haben, erhalten wir neue Koordinaten und . Wir machen den nächsten Schritt (Subtraktion), bereits aus den berechneten Koordinaten. Und so startet der Zyklus immer wieder neu, bis die erforderliche Konvergenz erreicht ist.
 und
und  In unserem Beispiel werden wir die Koeffizienten in der Nähe von null festlegen. Dies ist eine gängige Praxis, jedoch kann für jeden Fall eine eigene Herangehensweise vorgesehen werden.
In unserem Beispiel werden wir die Koeffizienten in der Nähe von null festlegen. Dies ist eine gängige Praxis, jedoch kann für jeden Fall eine eigene Herangehensweise vorgesehen werden. ziehen wir den Wert der ersten partiellen Ableitung an der Stelle
ziehen wir den Wert der ersten partiellen Ableitung an der Stelle  ab. Ist die Ableitung positiv, steigt die Funktion. Indem wir den Wert der Ableitung abziehen, bewegen wir uns also in die entgegengesetzte Richtung des Anstiegs, also bergab. Ist die Ableitung negativ, dann sinkt die Funktion an diesem Punkt, und durch das Abziehen des Wertes der Ableitung bewegen wir uns in Richtung Abstieg.
ab. Ist die Ableitung positiv, steigt die Funktion. Indem wir den Wert der Ableitung abziehen, bewegen wir uns also in die entgegengesetzte Richtung des Anstiegs, also bergab. Ist die Ableitung negativ, dann sinkt die Funktion an diesem Punkt, und durch das Abziehen des Wertes der Ableitung bewegen wir uns in Richtung Abstieg.  durch: wir ziehen den Wert der partiellen Ableitung an der Stelle ab.
durch: wir ziehen den Wert der partiellen Ableitung an der Stelle ab.  .
. und
und  um die Werte der Ableitungen reduziert haben, erhalten wir neue Koordinaten
um die Werte der Ableitungen reduziert haben, erhalten wir neue Koordinaten  und
und  . Wir machen den nächsten Schritt (Subtraktion), bereits aus den berechneten Koordinaten. Und so startet der Zyklus immer wieder neu, bis die erforderliche Konvergenz erreicht ist.
. Wir machen den nächsten Schritt (Subtraktion), bereits aus den berechneten Koordinaten. Und so startet der Zyklus immer wieder neu, bis die erforderliche Konvergenz erreicht ist.Fertig! Jetzt sind wir bereit, uns auf die Suche nach dem tiefsten Punkt des Marianengrabens zu begeben. Loslegen.
Code für den Gradientenabstieg
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Wir sind in die tiefsten Regionen des Marianengrabens eingetaucht und haben dort dieselben Koeffizientenwerte gefunden  und
und  , die wir eigentlich erwartet hatten.
, die wir eigentlich erwartet hatten.
Wir werden noch einen weiteren Tauchgang machen, aber dieses Mal wird die Ausstattung unseres Unterwassergeräts andere Technologien beinhalten, nämlich eine Bibliothek. NumPy.
Code für den Gradientabstieg (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Werte der Koeffizienten  und
und  unveränderlich.
unveränderlich.
Lassen Sie uns betrachten, wie sich der Fehler während des Gradientabstiegs verändert hat, d.h. wie sich die Summe der quadratischen Abweichungen bei jedem Schritt verändert hat.
Code für das Diagramm der quadratischen Abweichungen
print 'Diagramm Nr. 4 "Summe der quadratischen Abweichungen schrittweise"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Schritte (Iteration)', size=16)
plt.ylabel('Summe der quadratischen Abweichungen', size=16)
plt.show()Diagramm Nr. 4 „Summe der quadratischen Abweichungen beim Gradientabstieg“
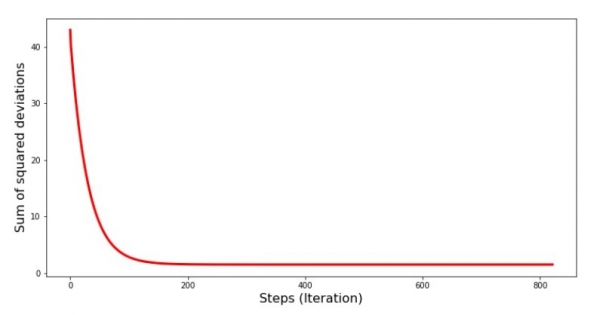
Im Diagramm sehen wir, dass der Fehler bei jedem Schritt abnimmt, und nach einer gewissen Anzahl von Iterationen beobachten wir eine nahezu horizontale Linie.
Zum Schluss bewerten wir den Unterschied in der Ausführungszeit des Codes:
Code zur Bestimmung der Rechenzeit für den Gradientabstieg
print ' 33[1m' + ' 33[4m' + "Ausführungszeit des Gradientabstiegs ohne Verwendung der NumPy-Bibliothek:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Ausführungszeit des Gradientabstiegs unter Verwendung der NumPy-Bibliothek:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Vielleicht machen wir etwas falsch, aber erneut übertrifft eine einfache, selbstgeschriebene Funktion, die keine Bibliothek verwendet, die Laufzeit einer Funktion, die eine Bibliothek nutzt. NumPy Aber wir stehen nicht still und bewegen uns in Richtung Erforschung einer weiteren spannenden Methode zur Lösung der Gleichung der einfachen linearen Regression. Lernen Sie sie kennen! NumPy.
Um das Prinzip des stochastischen Gradientenabstiegs besser zu verstehen, ist es sinnvoll, seine Unterschiede zum normalen Gradientenabstieg zu definieren. Im Fall des Gradientenabstiegs haben wir in den Ableitungsformeln von
Stochastischer Gradientabstieg
die Summen der Werte aller Merkmale und der tatsächlichen Antworten in der Stichprobe verwendet (also die Summen aller  und
und  ). Beim stochastischen Gradientenabstieg werden wir nicht alle Werte in der Stichprobe verwenden, sondern stattdessen pseudozufällig einen sogenannten Stichprobenindex auswählen und dessen Werte verwenden.
). Beim stochastischen Gradientenabstieg werden wir nicht alle Werte in der Stichprobe verwenden, sondern stattdessen pseudozufällig einen sogenannten Stichprobenindex auswählen und dessen Werte verwenden.  und
und  Wenn der Index beispielsweise auf die Nummer 3 (drei) festgelegt wurde, nehmen wir die Werte
Wenn der Index beispielsweise auf die Nummer 3 (drei) festgelegt wurde, nehmen wir die Werte
Wenn beispielsweise der Index auf 3 (drei) festgelegt ist, nehmen wir die Werte.  und
und  , dann setzen wir die Werte in die Ableitungsformeln ein und bestimmen neue Koordinaten. Nachdem wir die Koordinaten festgelegt haben, wählen wir wieder pseudozufällig einen Index aus, setzen die entsprechenden Werte in die Gleichungen der partiellen Ableitungen ein und bestimmen die Koordinaten erneut.
, dann setzen wir die Werte in die Ableitungsformeln ein und bestimmen neue Koordinaten. Nachdem wir die Koordinaten festgelegt haben, wählen wir wieder pseudozufällig einen Index aus, setzen die entsprechenden Werte in die Gleichungen der partiellen Ableitungen ein und bestimmen die Koordinaten erneut.  und
und  usw. bis zur Konvergenz. Auf den ersten Blick mag es seltsam erscheinen, wie das überhaupt funktionieren kann, aber es funktioniert. Es ist jedoch zu beachten, dass nicht bei jedem Schritt der Fehler verringert wird, die Tendenz ist jedoch eindeutig vorhanden.
usw. bis zur Konvergenz. Auf den ersten Blick mag es seltsam erscheinen, wie das überhaupt funktionieren kann, aber es funktioniert. Es ist jedoch zu beachten, dass nicht bei jedem Schritt der Fehler verringert wird, die Tendenz ist jedoch eindeutig vorhanden.
Was sind die Vorteile des stochastischen Gradientenabstiegs im Vergleich zum herkömmlichen? Wenn wir eine sehr große Stichprobe haben, die sich in Zehntausenden von Werten misst, ist es viel einfacher, beispielsweise eine zufällige Tausend davon zu verarbeiten, als die gesamte Stichprobe. Genau in diesem Fall kommt der stochastische Gradientenabstieg zum Einsatz. In unserem Fall werden wir natürlich keinen großen Unterschied merken.
Lass uns den Code anschauen.
Code für den stochastischen Gradientenabstieg
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Schauen wir uns die Koeffizienten genau an und stellen uns die Frage: „Wie kann das sein?“. Wir haben andere Koeffizientenwerte erhalten.  und
und  Hat der stochastische Gradientabstieg möglicherweise optimalere Parameter für die Gleichung gefunden? Leider nicht. Es genügt, die Summe der quadrierten Abweichungen zu betrachten und zu sehen, dass der Fehler mit den neuen Koeffizienten größer ist. Lassen Sie uns jedoch nicht verzweifeln. Lassen Sie uns ein Diagramm der Fehleränderung erstellen.
Hat der stochastische Gradientabstieg möglicherweise optimalere Parameter für die Gleichung gefunden? Leider nicht. Es genügt, die Summe der quadrierten Abweichungen zu betrachten und zu sehen, dass der Fehler mit den neuen Koeffizienten größer ist. Lassen Sie uns jedoch nicht verzweifeln. Lassen Sie uns ein Diagramm der Fehleränderung erstellen.
Code für das Diagramm der Summe der quadrierten Abweichungen beim stochastischen Gradientabstieg
print 'Diagramm Nr. 5 "Summe der quadrierten Abweichungen schrittweise"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Schritte (Iteration)', size=16)
plt.ylabel('Summe der quadrierten Abweichungen', size=16)
plt.show()Diagramm Nr. 5 „Summe der quadrierten Abweichungen beim stochastischen Gradientabstieg“
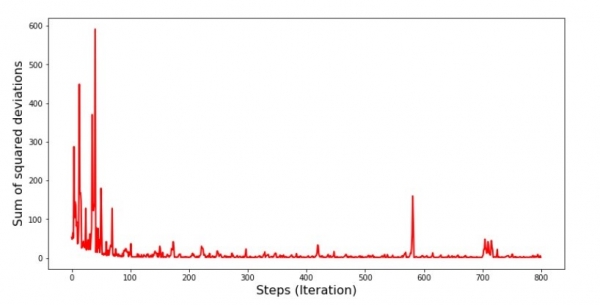
Wenn wir uns das Diagramm ansehen, wird alles klar, und jetzt werden wir alles korrigieren.
Was ist also passiert? Folgendes ist geschehen. Wenn wir einen Monat zufällig auswählen, versucht unser Algorithmus, den Fehler bei der Berechnung des Umsatzes für genau diesen Monat zu minimieren. Dann wählen wir einen anderen Monat und wiederholen die Berechnung, wobei wir den Fehler nun für den zweiten gewählten Monat verringern. Erinnern wir uns daran, dass die ersten beiden Monate erheblich von der Geraden der einfachen linearen Regression abweichen. Das bedeutet, dass, wenn einer dieser beiden Monate ausgewählt wird, unser Algorithmus durch die Minimierung des Fehlers für jeden von ihnen den Fehler über die gesamte Stichprobe erheblich erhöht. Was tun? Die Antwort ist einfach: wir müssen die Schrittweite verringern. Denn durch die Verringerung der Schrittweite wird der Fehler ebenfalls nicht mehr so stark „springen“, mal nach oben, mal nach unten. Genauer gesagt, wird der Fehler nicht aufhören zu springen, aber es wird nicht mehr so hektisch passieren :) Lassen Sie uns das überprüfen.
Code zur Ausführung von SGD mit kleinerer Schrittweite
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Diagramm Nr. 6 „Summe der Quadrate der Abweichungen bei stochastischem Gradientenspringen (80.000 Schritte)“
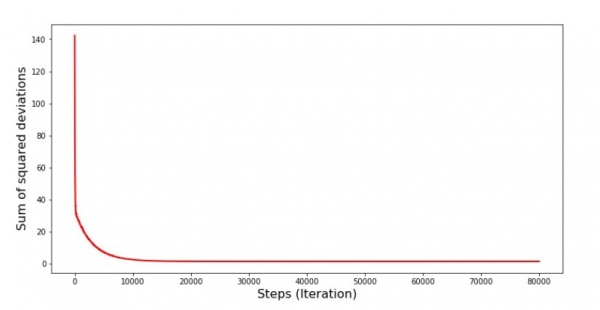
Die Werte der Koeffizienten haben sich verbessert, sind jedoch immer noch nicht ideal. Hypothetisch könnte man dies folgendermaßen beheben. Wir wählen beispielsweise aus den letzten 1000 Iterationen die Koeffizientenwerte aus, bei denen der geringste Fehler aufgetreten ist. Allerdings müssten wir dafür auch die Werte der Koeffizienten aufzeichnen. Das wollen wir nicht tun; stattdessen konzentrieren wir uns besser auf das Diagramm. Es sieht glatt aus, und der Fehler scheint gleichmäßig zu sinken. In Wirklichkeit ist das jedoch nicht der Fall. Lassen Sie uns die ersten 1000 Iterationen betrachten und mit den letzten vergleichen.
Code für das SGD-Diagramm (erste 1000 Schritte)
print 'Diagramm Nr. 7 "Summe der quadrierten Abweichungen Schritt für Schritt. Erste 1000 Iterationen"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Schritte (Iteration)', size=16)
plt.ylabel('Summe der quadrierten Abweichungen', size=16)
plt.show()
print 'Diagramm Nr. 7 "Summe der quadrierten Abweichungen Schritt für Schritt. Letzte 1000 Iterationen"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Schritte (Iteration)', size=16)
plt.ylabel('Summe der quadrierten Abweichungen', size=16)
plt.show()Diagramm Nr. 7 «Summe der quadrierten Abweichungen SGD (erste 1000 Schritte)»
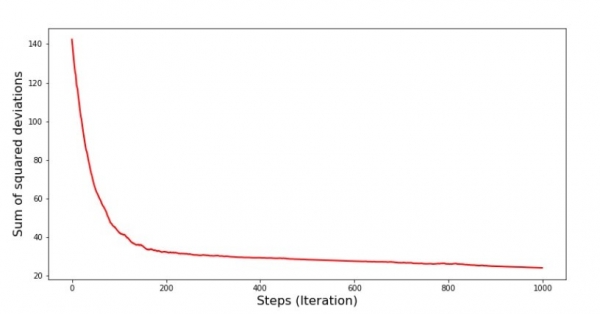
Diagramm Nr. 8 „Summe der quadrierten Abweichungen des SGD (letzte 1000 Schritte)“
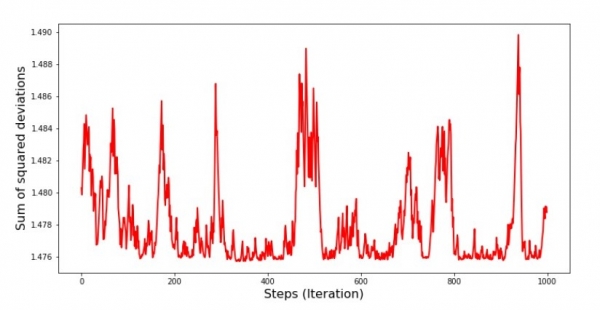
Zu Beginn des Abstiegs beobachten wir ein relativ gleichmäßiges und starkes Sinken des Fehlers. In den letzten Iterationen sehen wir, dass der Fehler um den Wert 1,475 schwankt und in einigen Momenten sogar diesem optimalen Wert entspricht, aber dann dennoch wieder ansteigt… Ich wiederhole, man könnte die Koeffizientenwerte aufzeichnen  und
und  , und dann die auswählen, bei denen der Fehler minimal ist. Allerdings hatten wir ein ernsthafteres Problem: Wir mussten 80.000 Schritte (siehe Code) machen, um Werte zu erhalten, die nahe an den optimalen liegen. Das widerspricht bereits der Idee, Zeit bei den Berechnungen im Vergleich zum Gradientenabstieg zu sparen. Was kann man verbessern? Es ist nicht schwer zu erkennen, dass wir in den ersten Iterationen sicher nach unten gehen und es daher sinnvoll ist, zu Beginn einen großen Schritt zu lassen und diesen Schritt mit zunehmendem Fortschritt zu verkleinern. Dies werden wir in diesem Artikel nicht tun – er ist bereits lang genug. Interessierte können selbst überlegen, wie man das umsetzen kann, es ist nicht schwer 🙂
, und dann die auswählen, bei denen der Fehler minimal ist. Allerdings hatten wir ein ernsthafteres Problem: Wir mussten 80.000 Schritte (siehe Code) machen, um Werte zu erhalten, die nahe an den optimalen liegen. Das widerspricht bereits der Idee, Zeit bei den Berechnungen im Vergleich zum Gradientenabstieg zu sparen. Was kann man verbessern? Es ist nicht schwer zu erkennen, dass wir in den ersten Iterationen sicher nach unten gehen und es daher sinnvoll ist, zu Beginn einen großen Schritt zu lassen und diesen Schritt mit zunehmendem Fortschritt zu verkleinern. Dies werden wir in diesem Artikel nicht tun – er ist bereits lang genug. Interessierte können selbst überlegen, wie man das umsetzen kann, es ist nicht schwer 🙂
Nun führen wir den stochastischen Gradientenabstieg mit der Bibliothek durch NumPy (und wir werden nicht über die Steine stolpern, die wir zuvor identifiziert haben)
Code für den stochastischen Gradientenabstieg (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Die Werte sind fast identisch mit denen, die ohne Nutzung entstanden sind NumPy. Das ist jedoch logisch.
Lassen Sie uns herausfinden, wie viel Zeit der stochastische Gradientenabstieg in Anspruch genommen hat.
Code zur Bestimmung der Berechnungszeit des SGD (80.000 Schritte)
print ' 33[1m' + ' 33[4m' +
"Die Ausführungszeit des stochastischen Gradientenabstiegs ohne Verwendung der NumPy-Bibliothek:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Die Ausführungszeit des stochastischen Gradientenabstiegs mit Verwendung der NumPy-Bibliothek:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Je weiter man in den Wald geht, desto dunkler werden die Wolken: wieder zeigt die „hausgemachte“ Formel das bessere Ergebnis. All dies lässt einen darüber nachdenken, dass es möglicherweise noch raffiniertere Methoden zur Nutzung der Bibliothek gibt. NumPy, die tatsächlich die Rechenoperationen beschleunigen. In diesem Artikel werden wir sie jedoch nicht kennenlernen. Es wird Raum für Überlegungen geben :)
Zusammenfassung
Bevor wir zur Zusammenfassung kommen, möchten wir eine Frage beantworten, die wahrscheinlich unserem geschätzten Leser in den Sinn kommt. Warum diese "Mühen" mit dem Abstieg, warum sollten wir den Berg hinauf und hinunter (hauptsächlich hinunter) gehen, um die begehrte Senke zu finden, wenn wir ein so leistungsstarkes und einfaches Werkzeug in Form einer analytischen Lösung in der Hand haben, das uns sofort an den richtigen Ort teleportiert?
Die Antwort auf diese Frage liegt auf der Hand. Wir haben uns gerade ein sehr einfaches Beispiel angesehen, bei dem die wahre Antwort  von einem Kriterium abhängt
von einem Kriterium abhängt  . Im Leben kommt so etwas nicht häufig vor, daher stellen wir uns vor, dass wir 2, 30, 50 oder mehr Merkmale haben. Fügen wir dazu Tausende, wenn nicht sogar Zehntausende von Werten für jedes Merkmal hinzu. In diesem Fall kann die analytische Lösung überfordert sein und ausfallen. Der Gradientenabstieg und seine Varianten werden uns jedoch langsam, aber sicher dem Ziel — dem Minimum der Funktion — näherbringen. Machen Sie sich keine Sorgen um die Geschwindigkeit — wir werden sicherlich noch verschiedene Methoden besprechen, mit denen wir die Schrittgröße (also die Geschwindigkeit) festlegen und anpassen können.
. Im Leben kommt so etwas nicht häufig vor, daher stellen wir uns vor, dass wir 2, 30, 50 oder mehr Merkmale haben. Fügen wir dazu Tausende, wenn nicht sogar Zehntausende von Werten für jedes Merkmal hinzu. In diesem Fall kann die analytische Lösung überfordert sein und ausfallen. Der Gradientenabstieg und seine Varianten werden uns jedoch langsam, aber sicher dem Ziel — dem Minimum der Funktion — näherbringen. Machen Sie sich keine Sorgen um die Geschwindigkeit — wir werden sicherlich noch verschiedene Methoden besprechen, mit denen wir die Schrittgröße (also die Geschwindigkeit) festlegen und anpassen können.
Und jetzt hier eine kurze Zusammenfassung.
Erstens hoffe ich, dass das in diesem Artikel behandelte Material anfangenden „Data Scientists“ hilft, zu verstehen, wie man Gleichungen einfacher (und nicht nur) linearer Regression löst.
Zweitens haben wir mehrere Methoden zur Lösung von Gleichungen betrachtet. Je nach Situation können wir nun die Methode wählen, die am besten geeignet ist, um die gestellte Aufgabe zu lösen.
Drittens haben wir die Bedeutung zusätzlicher Einstellungen, insbesondere der Schrittgröße beim Gradientenabstieg, festgestellt. Dieser Parameter sollte nicht vernachlässigt werden. Wie bereits erwähnt, ist es ratsam, die Schrittgröße während des Abstiegs zu ändern, um die Berechnungskosten zu senken.
Viertens haben in unserem Fall die »selbstgeschriebenen« Funktionen die besten Berechnungszeiten gezeigt. Wahrscheinlich liegt das an einer nicht ganz professionellen Nutzung der Bibliotheksfunktionen. NumPyWie dem auch sei, die Schlussfolgerung liegt nahe. Einerseits sollte man etablierte Meinungen manchmal hinterfragen, aber andererseits ist es nicht immer notwendig, alles zu komplizieren; manchmal erweist sich ein einfacherer Lösungsansatz als effektiver. Da unser Ziel darin bestand, drei Ansätze zur Lösung der einfachen linearen Regression zu untersuchen, war die Verwendung von »selbstgeschriebenen« Funktionen für uns ausreichend.
Literatur (oder etwas in der Art)
1. Lineare Regression
2. Methode der kleinsten Quadrate
3. Ableitung
4. Gradient
5. Gradientenabstieg
6. NumPy-Bibliothek
Quelle: habr.com
