

Мы это сделали!
«Цель этого курса — подготовить вас к вашему техническому будущему.»
 Привет, Хабр. Помните офигенную статью (+219, 2588 в закладки, 429k прочтений)?
Привет, Хабр. Помните офигенную статью (+219, 2588 в закладки, 429k прочтений)?
Так вот у Хэмминга (да, да, самоконтролирующиеся и самокорректирующиеся ) есть целая , написанная по мотивам его лекций. Мы ее переводим, ведь мужик дело говорит.
Это книга не просто про ИТ, это книга про стиль мышления невероятно крутых людей. «Это не просто заряд положительного мышления; в ней описаны условия, которые увеличивают шансы сделать великую работу.»
За перевод спасибо Андрею Пахомову.
Die Informationstheorie wurde von C. E. Shannon in den späten 1940er Jahren entwickelt. Die Leitung der Bell Laboratories bestand darauf, dass er sie "Kommunikationstheorie" nannte, da dies eine viel genauere Bezeichnung wäre. Aus offensichtlichen Gründen hat der Titel "Informationstheorie" jedoch einen deutlich größeren Einfluss auf die Öffentlichkeit, weshalb Shannon sich dafür entschied und dieser Titel bis heute bekannt ist. Der Name selbst legt nahe, dass die Theorie sich mit Informationen beschäftigt, was sie besonders relevant macht, da wir zunehmend in das Informationszeitalter eintreten. In diesem Kapitel werde ich einige grundlegende Erkenntnisse aus dieser Theorie ansprechen und nicht strikte, sondern eher intuitiv nachvollziehbare Beweise für einige der einzelnen Aussagen dieser Theorie liefern, damit Sie verstehen, was die "Informationstheorie" wirklich ist, wo Sie sie anwenden können und wo nicht.
Zunächst einmal, was versteht man unter "Information"? Shannon identifiziert Information mit Unsicherheit. Er wählte den negativen Logarithmus der Wahrscheinlichkeit eines Ereignisses als quantitative Maßnahme für die Information, die Sie erhalten, wenn ein Ereignis mit der Wahrscheinlichkeit p eintritt. Zum Beispiel, wenn ich Ihnen sage, dass in Los Angeles nebliges Wetter herrscht, dann ist p nah an 1, was uns im Grunde nicht viel Information gibt. Aber wenn ich sage, dass es im Juni in Monterey regnet, dann ist in dieser Mitteilung Unsicherheit vorhanden, und sie enthält mehr Informationen. Ein sicheres Ereignis enthält keine Informationen, da log 1 = 0 ist.
Lassen Sie uns das näher betrachten. Shannon war der Ansicht, dass die quantitative Messung von Informationen eine kontinuierliche Funktion von der Wahrscheinlichkeit eines Ereignisses p sein sollte und für unabhängige Ereignisse additiv sein muss – die Menge an Informationen, die aus der Durchführung zweier unabhängiger Ereignisse gewonnen wird, sollte der Menge an Informationen entsprechen, die aus der Durchführung eines gemeinsamen Ereignisses gewonnen wird. Zum Beispiel werden die Ergebnisse eines Würfelwurfs und eines Münzwurfs normalerweise als unabhängige Ereignisse betrachtet. Übersetzen wir das Gesagte in mathematische Sprache. Wenn I (p) die Menge an Informationen bezeichnet, die in einem Ereignis mit der Wahrscheinlichkeit p enthalten ist, dann erhalten wir für ein gemeinsames Ereignis, das aus zwei unabhängigen Ereignissen x mit der Wahrscheinlichkeit p1 und y mit der Wahrscheinlichkeit p2 besteht,
![]()
(x und y sind unabhängige Ereignisse)
Dies ist die Cauchy-Funktionalgleichung, die für alle p1 und p2 gültig ist. Um diese Funktionalgleichung zu lösen, nehmen wir an, dass
p1 = p2 = p,
das ergibt
![]()
Wenn p1 = p2 und p2 = p, dann
![]()
usw. Indem wir diesen Prozess fortsetzen und die Standardmethode für Exponenten verwenden, gilt für alle rationalen Zahlen m / n folgendes
![]()
Aus der angenommenen kontinuierlichen Informationsmaßnahme folgt, dass die logarithmische Funktion die einzige kontinuierliche Lösung der Cauchy-Gleichung ist.
In der Informationstheorie wird gewöhnlich die Basis des Logarithmus auf 2 gesetzt, sodass eine binäre Entscheidung genau 1 Bit Information enthält. Daher wird Information mit der Formel gemessen
![]()
Lassen Sie uns innehalten und klären, was oben passiert ist. Zunächst haben wir den Begriff 'Information' nicht definiert, sondern nur die Formel zur quantitativen Messung festgelegt.
Zweitens hängt dieses Maß von der Ungewissheit ab, und obwohl es für Maschinen – wie z. B. Telefonanlagen, Radio, Fernsehen, Computer usw. – gut geeignet ist, spiegelt es nicht das normale menschliche Verhältnis zur Information wider.
Drittens ist dies ein relativer Maßstab, der vom aktuellen Stand Ihres Wissens abhängt. Wenn Sie einen Strom „zufälliger Zahlen“ aus einem Zufallszahlengenerator betrachten, nehmen Sie an, dass jede folgende Zahl unbestimmt ist. Wenn Sie jedoch die Formel zur Berechnung der „zufälligen Zahlen“ kennen, wird die nächste Zahl bekannt sein und somit keine Informationen enthalten.
Daher passt die von Shannon gegebene Definition von Information in vielen Fällen für Maschinen, scheint jedoch nicht dem menschlichen Verständnis dieses Begriffs zu entsprechen. Aus diesem Grund hätte die „Theorie der Information“ besser als „Theorie der Kommunikation“ bezeichnet werden sollen. Dennoch ist es bereits zu spät, um die Definitionen zu ändern (die der Theorie ihre ursprüngliche Popularität verliehen haben und die weiterhin dazu führen, dass Menschen denken, diese Theorie befasse sich mit „Information“). Daher müssen wir damit leben, wobei Sie jedoch deutlich verstehen sollten, wie weit Shannons Definition von Information von ihrem allgemein verstandenen Sinn entfernt ist. Shannons Information befasst sich mit etwas ganz anderem, nämlich mit Ungewissheit.
Das ist, worüber Sie nachdenken sollten, wenn Sie eine Terminologie vorschlagen. Wie stimmt die vorgeschlagene Definition, beispielsweise die von Shannon gegebene Definition von Information, mit Ihrer ursprünglichen Idee überein und wie unterscheidet sie sich davon? Es gibt kaum einen Begriff, der genau Ihre frühere Vorstellung des Konzepts widerspiegelt, aber letztendlich spiegelt die verwendete Terminologie den Sinn des Konzepts wider. Daher erzeugt die Formalisierung von etwas durch klare Definitionen immer ein gewisses Maß an Verwirrung.
Betrachten wir ein System, dessen Alphabet aus Symbolen q mit Wahrscheinlichkeiten pi besteht. In diesem Fall die durchschnittliche Informationsmenge im System (ihr Erwartungswert) ist:
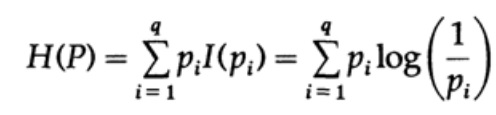
Das wird als Entropie des Systems mit der Wahrscheinlichkeitsverteilung {pi} bezeichnet. Wir verwenden den Begriff 'Entropie', weil dieselbe mathematische Form auch in der Thermodynamik und statistischen Mechanik vorkommt. Deshalb hat der Begriff 'Entropie' eine gewisse Aura der Bedeutung, die letztlich unbegründet ist. Eine identische mathematische Schreibweise impliziert keine identische Interpretation der Symbole!
Die Entropie der Wahrscheinlichkeitsverteilung spielt eine zentrale Rolle in der Codierungstheorie. Die Gibbs-Ungleichung für zwei verschiedene Wahrscheinlichkeitsverteilungen pi und qi ist eine der wichtigen Konsequenzen dieser Theorie. Daher müssen wir beweisen, dass
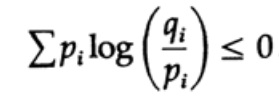
Der Beweis stützt sich auf das offensichtliche Diagramm in Abbildung 13.I, das zeigt, dass
![]()
das Gleichgewicht nur erreicht wird, wenn x = 1 ist. Wir wenden die Ungleichung auf jedes Glied der Summe auf der linken Seite an:
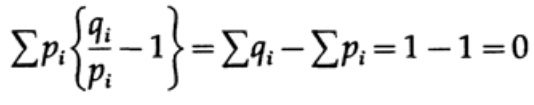
Wenn das Alphabet des Kommunikationssystems aus q Symbolen besteht, wobei die Übertragungswahrscheinlichkeit jedes Symbols qi = 1/q beträgt, und wir q einsetzen, erhalten wir aus der Gibbs-Ungleichung
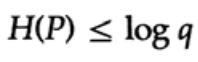
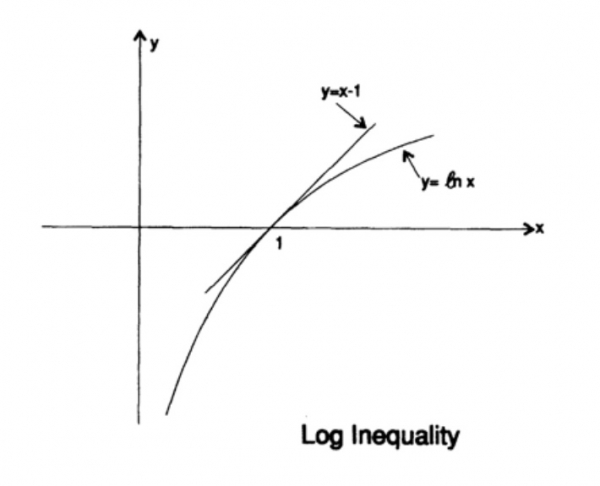
Abbildung 13.I
Das bedeutet, dass, wenn die Wahrscheinlichkeit für die Übertragung aller q Symbole gleich ist und 1/q beträgt, die maximale Entropie gleich ln q ist; andernfalls gilt die Ungleichung.
Im Fall eines eindeutig dekodierbaren Codes haben wir die Kraft-Ungleichung.
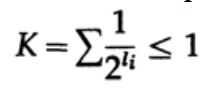
Jetzt, wenn wir die Pseudowahrscheinlichkeiten definieren,
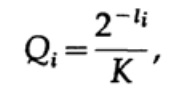
wo sicher 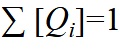 = 1, was aus der Gibbs-Ungleichung folgt,
= 1, was aus der Gibbs-Ungleichung folgt,
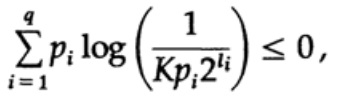
und wir etwas Algebra anwenden (denken Sie daran, dass K ≤ 1, daher können wir den logarithmischen Teil weglassen und möglicherweise die Ungleichung später verstärken), erhalten wir
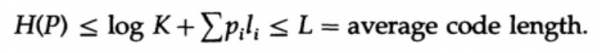
wobei L die durchschnittliche Code-Länge ist.
Die Entropie stellt somit die minimale Grenze für jeden zeichenbasierten Code mit einer durchschnittlichen Codewortlänge von L dar. Dies ist das Shannonsche Theorem für fehlerfreie Kanäle.
Betrachten wir nun das grundlegende Theorem über die Einschränkungen von Kommunikationssystemen, in denen Informationen als Fluss unabhängiger Bits übertragen werden und Rauschen vorhanden ist. Es wird vorausgesetzt, dass die Wahrscheinlichkeit einer korrekten Übertragung eines Bits P > 1 / 2 ist und die Wahrscheinlichkeit, dass der Wert des Bits während der Übertragung invertiert wird (ein Fehler auftritt), gleich Q = 1 — P ist. Der Einfachheit halber nehmen wir an, dass die Fehler unabhängig sind und die Fehlerwahrscheinlichkeit für jedes gesendete Bit gleich ist – das heißt, es tritt im Kommunikationskanal „weißes Rauschen“ auf.
Wir haben einen langen Fluss von n Bits, die in eine Nachricht kodiert sind – n-dimensionales Erweitern eines Ein-Bit-Codes. Der Wert von n wird später bestimmt. Betrachten wir die Nachricht, die aus n Bits besteht, als einen Punkt im n-dimensionalen Raum. Da wir einen n-dimensionalen Raum haben – und der Einfachheit halber annehmen, dass jede Nachricht die gleiche Wahrscheinlichkeit hat, zu entstehen – gibt es M mögliche Nachrichten (M wird ebenfalls später definiert), daher entspricht die Wahrscheinlichkeit einer gesendeten Nachricht
![]()
(Sender)
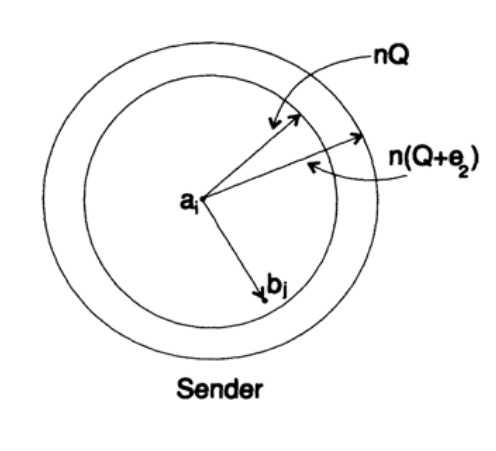
Diagramm 13.II
Lassen Sie uns dann die Idee der Kanalbandbreite betrachten. Ohne ins Detail zu gehen, wird die Bandbreite eines Kanals definiert als das maximale Volumen an Informationen, das zuverlässig über den Kommunikationskanal übertragen werden kann, unter Berücksichtigung der Verwendung der effizientesten Kodierung. Es gibt keine Argumente dafür, dass durch einen Kommunikationskanal mehr Informationen übertragen werden können als dessen Kapazität. Dies kann für einen binär symmetrischen Kanal, den wir in unserem Fall verwenden, bewiesen werden. Die Kapazität des Kanals, bei bitweise Übertragung, wird definiert als
![]()
wo, wie früher, P — die Wahrscheinlichkeit, dass ein Fehler in einem beliebigen gesendeten Bit auftritt. Bei der Übertragung von n unabhängigen Bits wird die Kapazität des Kanals bestimmt als
![]()
Wenn wir uns der Bandbreite des Kanals nähern, müssen wir fast das gleiche Volumen an Informationen für jedes der Symbole ai, i = 1, ..., M, senden. Da die Wahrscheinlichkeit für das Auftreten jedes Symbols ai 1 / M beträgt, erhalten wir
![]()
wenn wir eines der M gleichwahrscheinlichen Nachrichten ai senden, haben wir
![]()
Bei der Übertragung von n Bits erwarten wir das Auftreten von nQ Fehlern. In der Praxis werden wir für eine Nachricht, die aus n Bits besteht, etwa nQ Fehler in der empfangenen Nachricht haben. Bei großen n wird die relative Variation (Variation = Breite der Verteilung, )
der Verteilung der Fehleranzahl immer enger mit steigendem n.
Also nehme ich seitens des Senders die Nachricht ai zum Senden und ziehe eine Kugel mit einem Radius um sie herum auf
![]()
der um einen Betrag e2 größer ist als die erwartete Anzahl der Fehler Q (siehe Abbildung 13.II). Wenn n groß genug ist, gibt es eine beliebig kleine Wahrscheinlichkeit, dass der empfangene Punkt bj außerhalb dieser Sphäre liegt. Lassen Sie uns die Situation aus der Perspektive des Senders betrachten: Wir haben beliebige Radien vom gesendeten Nachricht ai zum empfangenen Nachricht bj mit einer Fehlerwahrscheinlichkeit, die (oder fast) einer Normalverteilung entspricht, die bei nQ ihren Höhepunkt erreicht. Für jede gegebene e2 gibt es ein n, das so groß ist, dass die Wahrscheinlichkeit, dass der empfangene Punkt bj außerhalb meiner Sphäre liegt, so klein ist, wie Sie es wünschen.
Betrachten wir nun dieselbe Situation von Ihrer Seite (siehe Abbildung 13.III). Auf der Empfängerseite gibt es eine Sphäre S(r) mit demselben Radius r um den empfangenen Punkt bj im n-dimensionalen Raum. Wenn die empfangene Nachricht bj innerhalb meiner Sphäre liegt, dann liegt die von mir gesendete Nachricht ai innerhalb Ihrer Sphäre.
Wie kann ein Fehler entstehen? Ein Fehler kann in den in der folgenden Tabelle beschriebenen Fällen eintreten:
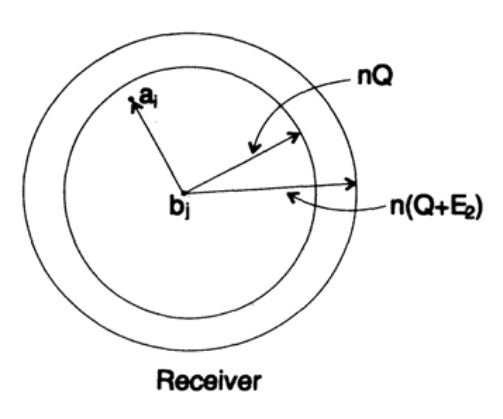
Abbildung 13.III

Hier sehen wir, dass, wenn es im Bereich um den angenommenen Punkt mindestens einen weiteren Punkt gibt, der einer möglichen gesendeten uncodierten Nachricht entspricht, ein Fehler bei der Übertragung aufgetreten ist, da Sie nicht bestimmen können, welches dieser Nachrichten tatsächlich gesendet wurde. Die gesendete Nachricht enthält keinen Fehler, wenn der entsprechende Punkt im Bereich liegt und keine anderen Punkte existieren, die in diesem Code möglich sind und sich im selben Bereich befinden.
Wir haben eine mathematische Gleichung für die Fehlerwahrscheinlichkeit Re, wenn eine Nachricht ai gesendet wurde.
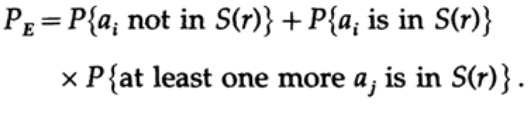
Wir können den ersten Faktor im zweiten Summanden wegwerfen, indem wir ihn als 1 annehmen. So erhalten wir eine Ungleichung.
![]()
Offensichtlich
![]()
folglich
![]()
wenden wir erneut auf den letzten rechten Term an
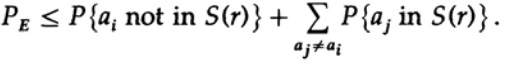
Wenn wir n groß genug wählen, kann der erste Term beliebig klein angenommen werden, sagen wir, kleiner als eine bestimmte Zahl d. Daher haben wir
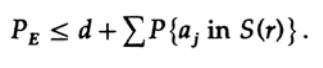
Betrachten wir jetzt, wie man einen einfachen Ersetzungscode für die Codierung von M Nachrichten mit n Bits erstellen kann. Ohne eine Vorstellung davon, wie man den Code tatsächlich erstellt (Fehlerkorrekturcodes waren damals noch nicht erfunden), wählte Shannon das Zufallscodieren. Werfen Sie eine Münze für jedes der n Bits in der Nachricht und wiederholen Sie diesen Prozess für M Nachrichten. Insgesamt sind nM Münzwürfe erforderlich, sodass möglich ist
![]()
eine Sammlung von Codes, die die gleiche Wahrscheinlichkeit von ½nM haben. Natürlich bedeutet der zufällige Prozess der Erstellung des Codes, dass die Wahrscheinlichkeit von Duplikaten sowie von Codes mit näher beieinanderliegenden Punkten besteht, die somit eine Quelle für potenzielle Fehler sind. Es muss bewiesen werden, dass, wenn dies nicht mit einer Wahrscheinlichkeit passiert, die höher ist als ein beliebig klein gewähltes Fehlerniveau, n groß genug ist.
Der entscheidende Punkt ist, dass Shannon alle möglichen Codebücher gemittelt hat, um den mittleren Fehler zu ermitteln! Wir verwenden das Symbol Av [.], um den Durchschnitt aus der Menge aller möglichen zufälligen Codeschlüssel darzustellen. Das Mittel aus der Konstante d ergibt natürlich eine Konstante, da bei der Mittelung jedes Element mit jedem anderen Element in der Summe übereinstimmt.
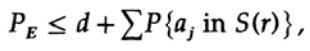
das erhöht werden kann (M–1 wird zu M)
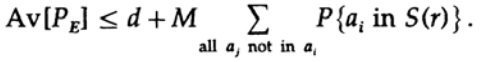
Für jede spezifische Nachricht, wenn man alle Codebücher mittelt, durchläuft die Kodierung alle möglichen Werte, sodass die durchschnittliche Wahrscheinlichkeit, dass der Punkt sich im Bereich befindet, das Verhältnis des Volumens der Kugel zum gesamten Volumen des Raums ist. Das Volumen der Kugel beträgt dabei
![]()
wobei s=Q+e2 < 1/2 und ns eine ganze Zahl sein muss.
Das letzte Summand ist der größte in dieser Summe. Zunächst bewerten wir seinen Wert anhand der Stirling-Formel für Fakultäten. Danach betrachten wir den Reduktionsfaktor des davorstehenden Summanden; beachten Sie, dass dieser Faktor beim Verschieben nach links zunimmt. Daher können wir: (1) den Wert der Summe durch die geometrische Reihe mit diesem Anfangskoeffizienten begrenzen, (2) die geometrische Reihe von n Mitgliedern auf unendlich viele Mitglieder erweitern, (3) die Summe der unendlichen geometrischen Reihe berechnen (Standardalgebra, nichts Wesentliches) und schließlich den Grenzwert erhalten (für ausreichend großes n):
![]()
Beachten Sie, wie die Entropie H(s) im binomialen Identitätsbeweis auftrat. Beachten Sie, dass die Taylor-Reihenentwicklung H(s)=H(Q+e2) eine Schätzung liefert, die nur die erste Ableitung berücksichtigt und alle anderen ignoriert. Lassen Sie uns jetzt das endliche Ausdruck zusammenstellen:
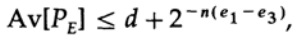
wobei
![]()
Alles, was wir tun müssen, ist, e2 auszuwählen, sodass e3 < e1 ist, und dann kann das letzte Glied beliebig klein werden, wenn n groß genug ist. Folglich kann der durchschnittliche Fehler PE beliebig klein gemacht werden, wenn die Kanalbandbreite C entsprechend nahe kommt.
Wenn der Durchschnittswert über alle Codes einen hinreichend kleinen Fehler aufweist, muss mindestens ein Code geeignet sein; folglich gibt es mindestens ein geeignetes Kodierungssystem. Dies ist ein bedeutendes Ergebnis, das von Shannon erzielt wurde — die „Shannon-Theoreme für Rauschkanäle“. Es sei jedoch darauf hingewiesen, dass er dies für einen viel allgemeineren Fall beweisen konnte als für den einfachen binären symmetrischen Kanal, den ich verwendet habe. Für den allgemeinen Fall sind die mathematischen Ableitungen deutlich komplexer, doch die Ideen unterscheiden sich nicht so sehr, weshalb oftmals das wahre Wesen des Theorems am Beispiel des speziellen Falls verdeutlicht werden kann.
Lassen Sie uns das Ergebnis kritisch betrachten. Wir haben immer wieder betont: "Bei ausreichend großen n." Aber wie groß ist n tatsächlich? Sehr, sehr groß, wenn Sie tatsächlich nahe an der Kanalbandbreite sein und gleichzeitig sicherstellen möchten, dass die Daten korrekt übertragen werden! So groß, dass Sie im Grunde genommen sehr lange warten müssen, um eine Nachricht aus so vielen Bits zu sammeln, um sie später codieren zu können. Dabei wird die Größe des Wörterbuchs des zufälligen Codes einfach riesig sein (denn ein solches Wörterbuch kann nicht kürzer dargestellt werden als die vollständige Liste aller Mn Bits, wobei n und M sehr groß sind)!
Fehlerkorrekturcodes vermeiden das Warten auf eine sehr lange Nachricht, gefolgt von deren Kodierung und Dekodierung über sehr große Codesammlungen, da sie Codesammlungen als solche umgehen und stattdessen gewöhnliche Berechnungen verwenden. In einer einfachen Theorie verlieren solche Codes in der Regel die Fähigkeit, sich der Kapazität des Kanals anzunähern, während sie gleichzeitig eine ausreichend niedrige Fehlerquote aufrechterhalten. Wenn der Code jedoch eine große Anzahl von Fehlern korrigiert, erzielen sie gute Ergebnisse. Mit anderen Worten, wenn Sie eine gewisse Kanal-Kapazität für die Fehlerkorrektur einplanen, sollten Sie die Fehlerkorrekturmöglichkeit die meiste Zeit nutzen; das heißt, in jeder gesendeten Nachricht sollte eine große Anzahl von Fehlern korrigiert werden, andernfalls verschwenden Sie diese Kapazität.
Die oben bewiesene Theoreme sind dennoch nicht bedeutungslos! Sie zeigt, dass effektive Übertragungssysteme durchdachte Codierungsverfahren für sehr lange Bitfolgen verwenden müssen. Ein Beispiel sind Satelliten, die über die äußeren Planeten hinaus geflogen sind; je weiter sie sich von der Erde und der Sonne entfernen, desto mehr Fehler müssen sie in den Datenblöcken korrigieren: Einige Satelliten nutzen Solarzellen, die etwa 5 W liefern, während andere radioaktive Energiequellen verwenden, die eine ähnliche Leistung bieten. Die schwache Leistung der Energiequelle, die kleinen Abmessungen der Sendeschüsseln und die begrenzten Größen der Empfangsschüsseln auf der Erde sowie die enorme Distanz, die das Signal zurücklegen muss – all das erfordert den Einsatz von Codes mit hohem Fehlerkorrekturgrad, um ein effektives Kommunikationssystem aufzubauen.
Kehren wir zu dem n-dimensionalen Raum zurück, den wir im vorherigen Beweis verwendet haben. Während unserer Diskussion haben wir gezeigt, dass fast das gesamte Volumen der Kugel sich an der äußeren Oberfläche konzentriert – es ist also nicht überraschend, dass das empfangene Signal höchstwahrscheinlich an der Oberfläche der Kugel liegt, die um das empfangene Signal herum aufgebaut ist, selbst bei relativ kleinem Radius dieser Kugel. Daher ist es nicht verwunderlich, dass das empfangene Signal nach der Korrektur einer beliebig großen Anzahl von Fehlern, nQ, beliebig nahe am fehlerfreien Signal liegt. Die Kanal-Kapazität, die wir zuvor betrachtet haben, ist der Schlüssel zum Verständnis dieses Phänomens. Beachten Sie, dass solche Kugeln, die für Hamming-Codes zur Fehlerkorrektur erstellt wurden, sich nicht überschneiden. Eine große Anzahl praktisch orthogonaler Dimensionen im n-dimensionalen Raum zeigt, warum wir M Kugeln in einem Raum mit geringfügigen Überlappungen unterbringen können. Wenn wir ein geringfügiges, beliebig kleines Überlappen zulassen, das nur zu einer geringen Anzahl von Fehlern bei der Dekodierung führen kann, können wir eine dichte Anordnung von Kugeln im Raum erreichen. Hamming gewährte ein bestimmtes Maß an Fehlerkorrektur, Shannon eine niedrige Fehlerwahrscheinlichkeit, wobei jedoch die tatsächliche Durchsatzrate beliebig nahe an der Kapazität des Kommunikationskanals bleibt, was Hamming-Codes nicht können.
Die Informationstheorie gibt keine direkten Hinweise darauf, wie man ein effektives System entwirft, sondern zeigt viel mehr auf, in welche Richtung sich effiziente Kommunikationssysteme entwickeln sollten. Sie ist ein wertvolles Werkzeug, um Kommunikationssysteme zwischen Maschinen aufzubauen. Wie bereits erwähnt, hat sie jedoch wenig Bezug dazu, wie Menschen Informationen untereinander austauschen. Inwieweit biologische Vererbung den technischen Kommunikationssystemen ähnelt, ist völlig unklar. Daher bleibt uns nichts anderes übrig, als es einfach auszuprobieren. Wenn der Erfolg uns einen maschinenähnlichen Charakter dieses Phänomens zeigt, wird uns das Scheitern andere wesentliche Aspekte der Natur der Information aufzeigen.
Lassen Sie uns eine kleine Ablenkung machen. Wir haben gesehen, dass alle anfänglichen Definitionen, in geringer oder höherer Maßstab, die Essenz unserer ursprünglichen Überzeugungen ausdrücken sollten, aber sie unterliegen einer gewissen Verzerrung und sind daher oft nicht anwendbar. Traditionell wird angenommen, dass letztendlich die Definition, die wir verwenden, tatsächlich das Wesen bestimmt; aber das weist uns lediglich an, wie wir Dinge handhaben und vermittelt uns in keiner Weise einen Sinn. Der postulative Ansatz, der in mathematischen Kreisen so stark befürwortet wird, lässt in der Praxis zu wünschen übrig.
Jetzt betrachten wir ein Beispiel für IQ-Tests, bei dem die Definition so zyklisch ist, wie Sie es sich wünschen, und folglich zu Verwirrung führt. Ein Test wird erstellt, der, wie angenommen, die Intelligenz messen soll. Danach wird er überarbeitet, um ihn so konsistent wie möglich zu gestalten, und dann wird er veröffentlicht und mithilfe einer einfachen Methode kalibriert, sodass die gemessene "Intelligenz" normal verteilt ist (natürlich nach der Kalibrierungskurve). Alle Definitionen müssen überprüft werden, nicht nur, wenn sie erstmals vorgeschlagen werden, sondern auch viel später, wenn sie in getroffenen Schlussfolgerungen verwendet werden. Inwieweit sind die Grenzen der Definitionen für die zu lösende Aufgabe geeignet? Wie oft beginnen Definitionen, die unter bestimmten Bedingungen gegeben werden, in ziemlich unterschiedlichen Bedingungen angewendet zu werden? Dies kommt recht häufig vor! In den Geisteswissenschaften, mit denen Sie in Ihrem Leben unvermeidlich konfrontiert werden, passiert dies noch häufiger.
So war eines der Ziele dieser Präsentation über die Informationstheorie, neben der Demonstration ihres Nutzens, Sie auf diese Gefahr hinzuweisen oder zu zeigen, wie man sie tatsächlich verwendet, um das gewünschte Ergebnis zu erzielen. Es wurde schon lange beobachtet, dass die ursprünglichen Definitionen in viel größerem Maßstab beeinflussen, was Sie letztendlich finden, als es scheint. Die anfänglichen Definitionen erfordern von Ihnen eine hohe Aufmerksamkeit, nicht nur in jeder neuen Situation, sondern auch in Bereichen, in denen Sie bereits lange tätig sind. Das wird Ihnen helfen zu verstehen, inwieweit die erzielten Ergebnisse eine Tautologie sind und nicht etwas Nützliches.
Die bekannte Geschichte von Eddington erzählt von Menschen, die im Meer mit einem Netz fischen. Nachdem sie die Größe der gefangenen Fische untersucht hatten, bestimmten sie die Mindestgröße des Fisches, der im Meer vorkommt! Ihre Schlussfolgerung war durch das verwendete Werkzeug bedingt, nicht durch die Realität.
Die Fortsetzung folgt…
Wer beim Übersetzen, Layouten und Verlag der Buches helfen möchte, sendet bitte eine private Nachricht oder eine E-Mail an magisterludi2016@yandex.ru
Übrigens haben wir auch die Übersetzung eines weiteren großartigen Buches gestartet — )
Insbesondere suchen wir Techniker, die helfen zu übersetzen . (wir übersetzen in 10-Minuten-Abschnitten, die ersten 20 sind bereits erledigt)
Inhalt des Buches und übersetzte Kapitel
- Einführung in Die Kunst des Wissenschaftlichen Arbeitens und Ingenieurwesens: Lernen zu Lernen (28. März 1995)
- «Fundamente der digitalen (diskreten) Revolution» (30. März 1995)
- «Geschichte der Computer — Hardware» (31. März 1995)
- «Geschichte der Computer — Software» (4. April 1995)
- «Geschichte der Computer — Anwendungen» (6. April 1995)
- «Künstliche Intelligenz — Teil I» (7. April 1995)
- «Künstliche Intelligenz — Teil II» (11. April 1995)
- «Künstliche Intelligenz III» (13. April 1995)
- «n-dimensionaler Raum» (14. April 1995)
- «Kodierungstheorie — Die Darstellung von Informationen, Teil I» (18. April 1995)
- «Kodierungstheorie — Die Darstellung von Informationen, Teil II» (20. April 1995)
- „Fehlerkorrekturcodes“ (21. April 1995)
- „Informationstheorie“ (25. April 1995)
- „Digitale Filter, Teil I“ (27. April 1995)
- „Digitale Filter, Teil II“ (28. April 1995)
- „Digitale Filter, Teil III“ (2. Mai 1995)
- „Digitale Filter, Teil IV“ (4. Mai 1995)
- „Simulation, Teil I“ (5. Mai 1995)
- „Simulation, Teil II“ (9. Mai 1995)
- „Simulation, Teil III“ (11. Mai 1995)
- „Glasfaseroptik“ (12. Mai 1995)
- „Computerunterstütztes Lernen“ (16. Mai 1995)
- „Mathematik“ (18. Mai 1995)
- „Quantenmechanik“ (19. Mai 1995)
- „Kreativität“ (23. Mai 1995). Übersetzung:
- „Experten“ (25. Mai 1995)
- „Unzuverlässige Daten“ (26. Mai 1995)
- „Systemtechnik“ (30. Mai 1995)
- „Man kriegt, was man misst“ (1. Juni 1995)
- (2. Juni 1995) Wir übersetzen in 10-Minuten-Stücken
- Hamming, „Sie und Ihre Forschung“ (6. Juni 1995).
Wer beim Übersetzen, Layouten und Verlag der Buches helfen möchte, sendet bitte eine private Nachricht oder eine E-Mail an magisterludi2016@yandex.ru
Quelle: habr.com
