


Με βάση τις παρουσιάσεις μου στο Highload++ και στο DataFest Minsk 2019.
Για πολλούς σήμερα, η αλληλογραφία αποτελεί αναπόσπαστο κομμάτι της διαδικτυακής ζωής. Με τη βοήθειά της, διεξάγουμε επαγγελματική αλληλογραφία, αποθηκεύουμε κάθε είδους σημαντικές πληροφορίες που σχετίζονται με τα οικονομικά, τις κρατήσεις ξενοδοχείων, την επεξεργασία παραγγελιών και πολλά άλλα. Στα μέσα του 2018, διαμορφώσαμε μια στρατηγική προϊόντος για την ανάπτυξη αλληλογραφίας. Πώς θα έπρεπε να είναι η σύγχρονη αλληλογραφία;
Το ταχυδρομείο πρέπει να είναι έξυπνος, δηλαδή, για να βοηθήσει τους χρήστες να πλοηγηθούν στον αυξανόμενο όγκο πληροφοριών: φιλτράροντάς τες, δομώντας τες και παρουσιάζοντάς τες με τον πιο βολικό τρόπο. Θα πρέπει να είναι χρήσιμος, επιτρέποντάς σας να λύνετε διάφορα προβλήματα απευθείας στο γραμματοκιβώτιό σας, για παράδειγμα, να πληρώνετε πρόστιμα (μια λειτουργία που δυστυχώς χρησιμοποιώ). Και ταυτόχρονα, φυσικά, το ταχυδρομείο θα πρέπει να παρέχει προστασία πληροφοριών, διακόπτοντας τα ανεπιθύμητα μηνύματα και προστατεύοντας από την πειρατεία, δηλαδή να είναι ασφαλής.
Αυτοί οι τομείς ορίζουν μια σειρά από βασικές εργασίες, πολλές από τις οποίες μπορούν να επιλυθούν αποτελεσματικά χρησιμοποιώντας μηχανική μάθηση. Ακολουθούν παραδείγματα ήδη υπαρχόντων χαρακτηριστικών που έχουν αναπτυχθεί στο πλαίσιο της στρατηγικής - ένα για κάθε τομέα.
- Έξυπνη απάντησηΤο email διαθέτει λειτουργία έξυπνης απάντησης. Το νευρωνικό δίκτυο αναλύει το κείμενο της επιστολής, κατανοεί τη σημασία και τον σκοπό της και, ως αποτέλεσμα, προσφέρει τρεις πιο κατάλληλες επιλογές απάντησης: θετική, αρνητική και ουδέτερη. Αυτό βοηθά στην εξοικονόμηση πολύ χρόνου κατά την απάντηση σε επιστολές, ενώ συχνά απαντάτε με έναν ασυνήθιστο και αστείο τρόπο για τον εαυτό σας.
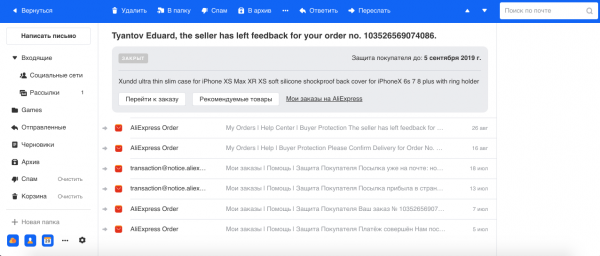
- Ομαδοποίηση γραμμάτων, που σχετίζονται με παραγγελίες σε ηλεκτρονικά καταστήματα. Συχνά πραγματοποιούμε αγορές στο Διαδίκτυο και, κατά κανόνα, τα καταστήματα μπορούν να στείλουν πολλές επιστολές για κάθε παραγγελία. Για παράδειγμα, το AliExpress, η μεγαλύτερη υπηρεσία, στέλνει πολλές επιστολές για μία παραγγελία και υπολογίσαμε ότι στην περίπτωση του τερματικού ο αριθμός τους μπορεί να φτάσει τις 29. Επομένως, χρησιμοποιώντας το μοντέλο Αναγνώρισης Ονομαστικής Οντότητας, εξάγουμε τον αριθμό παραγγελίας και άλλες πληροφορίες από το κείμενο και ομαδοποιούμε όλα τα γράμματα σε ένα νήμα. Επίσης, εμφανίζουμε τις κύριες πληροφορίες σχετικά με την παραγγελία σε ξεχωριστό πλαίσιο, γεγονός που διευκολύνει την εργασία με αυτό το είδος επιστολών.

- Anti-phishingΤο ηλεκτρονικό "ψάρεμα" (phishing) είναι ένας ιδιαίτερα επικίνδυνος τύπος δόλιου email, με τη βοήθεια του οποίου οι εισβολείς προσπαθούν να αποκτήσουν οικονομικές πληροφορίες (συμπεριλαμβανομένων των τραπεζικών καρτών του χρήστη) και στοιχεία σύνδεσης. Τέτοια email μιμούνται τα πραγματικά email που αποστέλλονται από την υπηρεσία, συμπεριλαμβανομένων και των οπτικών. Επομένως, με τη βοήθεια του Computer Vision, αναγνωρίζουμε τα λογότυπα και το στυλ των email από μεγάλες εταιρείες (για παράδειγμα, Mail.ru, Sber, Alfa) και το λαμβάνουμε υπόψη μαζί με το κείμενο και άλλα χαρακτηριστικά στους ταξινομητές ανεπιθύμητης αλληλογραφίας και ηλεκτρονικού "ψαρέματος" (phishing).
Μηχανική εκμάθηση
Λίγα λόγια για τη μηχανική μάθηση στην αλληλογραφία γενικά. Η αλληλογραφία είναι ένα σύστημα με υψηλό φόρτο εργασίας: κατά μέσο όρο, 1,5 δισεκατομμύρια επιστολές περνούν από τους διακομιστές μας την ημέρα για 30 εκατομμύρια χρήστες DAU. Όλες οι απαραίτητες λειτουργίες και δυνατότητες υποστηρίζονται από περίπου 30 συστήματα μηχανικής μάθησης.
Κάθε επιστολή περνάει από έναν ολόκληρο μεταφορέα ταξινόμησης. Αρχικά, φιλτράρουμε τα ανεπιθύμητα μηνύματα και αφήνουμε καλές επιστολές. Οι χρήστες συχνά δεν παρατηρούν το έργο του antispam, επειδή το 95-99% των ανεπιθύμητων μηνυμάτων δεν φτάνει καν στον κατάλληλο φάκελο. Η αναγνώριση ανεπιθύμητων μηνυμάτων είναι ένα πολύ σημαντικό μέρος του συστήματός μας και το πιο δύσκολο, καθώς στον τομέα του antispam υπάρχει συνεχής προσαρμογή μεταξύ των συστημάτων άμυνας και επίθεσης, γεγονός που αποτελεί μια συνεχή πρόκληση μηχανικής για την ομάδα μας.
Στη συνέχεια, διαχωρίζουμε τις επιστολές από ανθρώπους και τα ρομπότ. Οι επιστολές από ανθρώπους είναι οι πιο σημαντικές, γι' αυτό παρέχουμε λειτουργίες όπως η Έξυπνη Απάντηση για αυτούς. Οι επιστολές από ρομπότ χωρίζονται σε δύο μέρη: συναλλακτικές - πρόκειται για σημαντικές επιστολές από υπηρεσίες, για παράδειγμα, επιβεβαίωση αγορών ή κρατήσεις ξενοδοχείων, οικονομικά και ενημερωτικές - πρόκειται για επιχειρηματική διαφήμιση, εκπτώσεις.
Πιστεύουμε ότι τα συναλλακτικά email είναι εξίσου σημαντικά με την προσωπική αλληλογραφία. Θα πρέπει να είναι εύκολα προσβάσιμα, επειδή συχνά χρειάζεται να βρίσκουμε γρήγορα πληροφορίες σχετικά με μια παραγγελία ή μια κράτηση πτήσης και αφιερώνουμε χρόνο στην αναζήτηση αυτών των email. Επομένως, για λόγους ευκολίας, τα χωρίζουμε αυτόματα σε έξι κύριες κατηγορίες: ταξίδια, παραγγελίες, οικονομικά, εισιτήρια, εγγραφές και, τέλος, πρόστιμα.
Οι ενημερωτικές επιστολές είναι η πιο πολυάριθμη και πιθανώς η λιγότερο σημαντική ομάδα, που δεν απαιτεί άμεση απάντηση, καθώς τίποτα σημαντικό δεν θα αλλάξει στη ζωή του χρήστη αν δεν διαβάσει μια τέτοια επιστολή. Στη νέα μας διεπαφή, τις συμπτύσσουμε σε δύο νήματα: κοινωνικά δίκτυα και ενημερωτικά δελτία, καθαρίζοντας έτσι οπτικά τα εισερχόμενα και αφήνοντας μόνο τις σημαντικές επιστολές ορατές.
Εκμετάλλευση
Ένας μεγάλος αριθμός συστημάτων προκαλεί πολλές δυσκολίες στη λειτουργία. Άλλωστε, τα μοντέλα υποβαθμίζονται με την πάροδο του χρόνου, όπως κάθε λογισμικό: οι λειτουργίες παρουσιάζουν προβλήματα, οι μηχανές παρουσιάζουν σφάλματα, ο κώδικας παρουσιάζεται στρεβλός. Επιπλέον, τα δεδομένα αλλάζουν συνεχώς: προστίθενται νέα, τα πρότυπα συμπεριφοράς των χρηστών μεταβάλλονται κ.λπ., επομένως ένα μοντέλο χωρίς κατάλληλη υποστήριξη θα λειτουργεί όλο και χειρότερα με την πάροδο του χρόνου.
Δεν πρέπει να ξεχνάμε ότι όσο βαθύτερα διεισδύει η μηχανική μάθηση στη ζωή των χρηστών, τόσο μεγαλύτερος είναι ο αντίκτυπος που έχει στο οικοσύστημα και, ως εκ τούτου, τόσο περισσότερες οικονομικές απώλειες ή κέρδη μπορούν να αποκομίσουν οι παράγοντες της αγοράς. Επομένως, σε όλο και περισσότερους τομείς, οι παράγοντες προσαρμόζονται στο έργο των αλγορίθμων μηχανικής μάθησης (κλασικά παραδείγματα είναι η διαφήμιση, η αναζήτηση και το ήδη αναφερθέν antispam).
Οι εργασίες μηχανικής μάθησης έχουν επίσης μια ιδιαιτερότητα: οποιαδήποτε αλλαγή στο σύστημα, ακόμη και μια μικρή, μπορεί να δημιουργήσει πολλή δουλειά με το μοντέλο: εργασία με δεδομένα, επανεκπαίδευση, ανάπτυξη, η οποία μπορεί να διαρκέσει εβδομάδες ή μήνες. Επομένως, όσο πιο γρήγορα αλλάζει το περιβάλλον στο οποίο λειτουργούν τα μοντέλα σας, τόσο περισσότερη προσπάθεια απαιτεί η υποστήριξή τους. Η ομάδα μπορεί να δημιουργήσει πολλά συστήματα και να είναι ευχαριστημένη με αυτό, και στη συνέχεια να ξοδέψει σχεδόν όλους τους πόρους στην υποστήριξή της, χωρίς τη δυνατότητα να κάνει κάτι νέο. Κάποτε αντιμετωπίσαμε μια τέτοια κατάσταση στην ομάδα κατά του spam. Και καταλήξαμε στο προφανές συμπέρασμα ότι η υποστήριξη πρέπει να αυτοματοποιηθεί.
Αυτοματοποίηση
Τι μπορεί να αυτοματοποιηθεί; Σχεδόν τα πάντα, στην πραγματικότητα. Έχω εντοπίσει τέσσερις τομείς που ορίζουν την υποδομή μηχανικής μάθησης:
- συλλογή δεδομένων;
- περαιτέρω εκπαίδευση·
- αναπτύσσω;
- δοκιμές και παρακολούθηση.
Εάν το περιβάλλον είναι ασταθές και μεταβάλλεται συνεχώς, τότε ολόκληρη η υποδομή γύρω από το μοντέλο είναι πολύ πιο σημαντική από το ίδιο το μοντέλο. Θα μπορούσε να είναι ένας καλός παλιός γραμμικός ταξινομητής, αλλά αν του τροφοδοτήσετε με τα σωστά χαρακτηριστικά και δημιουργήσετε καλή ανατροφοδότηση από τους χρήστες, θα λειτουργήσει πολύ καλύτερα από τα μοντέλα τελευταίας τεχνολογίας με όλα τα χαρακτηριστικά.
Βρόχος ανατροφοδότησης
Αυτός ο κύκλος συνδυάζει τη συλλογή δεδομένων, την πρόσθετη εκπαίδευση και την ανάπτυξη — ουσιαστικά ολόκληρο τον κύκλο ενημέρωσης μοντέλου. Γιατί είναι αυτό σημαντικό; Δείτε το πρόγραμμα καταχώρισης αλληλογραφίας:
Ένας προγραμματιστής μηχανικής μάθησης έχει εφαρμόσει ένα μοντέλο anti-bot που εμποδίζει τα bots να εγγραφούν στο email. Το γράφημα πέφτει σε μια τιμή όπου παραμένουν μόνο πραγματικοί χρήστες. Όλα είναι υπέροχα! Αλλά περνούν τέσσερις ώρες, οι χειριστές bot τροποποιούν τα σενάρια τους και όλα επιστρέφουν στο φυσιολογικό. Σε αυτήν την εφαρμογή, ο προγραμματιστής αφιέρωσε ένα μήνα προσθέτοντας λειτουργίες και επανεκπαιδεύοντας το μοντέλο, αλλά ο spammer κατάφερε να προσαρμοστεί σε τέσσερις ώρες.
Για να αποφύγουμε έναν τόσο βασανιστικό πόνο και να αποφύγουμε να χρειαστεί να επαναλάβουμε τα πάντα αργότερα, πρέπει αρχικά να σκεφτούμε πώς θα μοιάζει ο βρόχος ανατροφοδότησης και τι θα κάνουμε αν αλλάξει το περιβάλλον. Ας ξεκινήσουμε με τη συλλογή δεδομένων - αυτό είναι το καύσιμο για τους αλγόριθμούς μας.
Συλλογή δεδομένων
Είναι σαφές ότι όσο περισσότερα δεδομένα έχουν τα σύγχρονα νευρωνικά δίκτυα, τόσο το καλύτερο, και ουσιαστικά παράγονται από τους χρήστες του προϊόντος. Οι χρήστες μπορούν να μας βοηθήσουν επισημαίνοντας τα δεδομένα, αλλά δεν μπορούμε να το καταχραστούμε αυτό, επειδή κάποια στιγμή οι χρήστες θα κουραστούν να εκπαιδεύουν τα μοντέλα σας και θα στραφούν σε άλλο προϊόν.
Ένα από τα πιο συνηθισμένα λάθη (αναφέρομαι στον Andrew Ng εδώ) είναι η υπερβολική εστίαση στις μετρήσεις του συνόλου δεδομένων δοκιμής, αντί για τα σχόλια των χρηστών, τα οποία είναι στην πραγματικότητα το κύριο μέτρο της ποιότητας της εργασίας, αφού δημιουργούμε ένα προϊόν για τον χρήστη. Εάν ο χρήστης δεν καταλαβαίνει ή δεν του αρέσει η εργασία του μοντέλου, τότε όλα είναι μάταια.
Επομένως, ο χρήστης θα πρέπει πάντα να έχει την ευκαιρία να ψηφίσει, θα πρέπει να του δώσουμε ένα εργαλείο για ανατροφοδότηση. Εάν πιστεύουμε ότι έχει φτάσει στο γραμματοκιβώτιο μια επιστολή που σχετίζεται με τα οικονομικά, θα πρέπει να την επισημάνουμε ως "οικονομικά" και να σχεδιάσουμε ένα κουμπί που ο χρήστης μπορεί να πατήσει και να πει ότι αυτό δεν είναι οικονομικά.
Ποιότητα σχολίων
Ας μιλήσουμε για την ποιότητα των σχολίων των χρηστών. Πρώτον, εσείς και ο χρήστης μπορεί να δίνετε διαφορετικές ερμηνείες σε μια έννοια. Για παράδειγμα, εσείς και οι υπεύθυνοι προϊόντων πιστεύετε ότι τα «οικονομικά» είναι επιστολές από την τράπεζα και ο χρήστης πιστεύει ότι μια επιστολή από τη γιαγιά σχετικά με τη σύνταξή της σχετίζεται επίσης με τα οικονομικά. Δεύτερον, υπάρχουν χρήστες που αρέσκονται να πατούν κουμπιά χωρίς λογική. Τρίτον, ο χρήστης μπορεί να κάνει μεγάλο λάθος στα συμπεράσματά του. Ένα εντυπωσιακό παράδειγμα από την πρακτική μας είναι η εφαρμογή ενός ταξινομητή. , ένα πολύ αστείο είδος ανεπιθύμητου μηνύματος (spam), όταν στον χρήστη προσφέρεται να πάρει αρκετά εκατομμύρια δολάρια από έναν ξαφνικά βρεθεί μακρινό συγγενή στην Αφρική. Αφού εφαρμόσαμε αυτόν τον ταξινομητή, ελέγξαμε τα κλικ "Μη ανεπιθύμητο" σε αυτά τα γράμματα και αποδείχθηκε ότι το 80% αυτών είναι ζουμερό νιγηριανό ανεπιθύμητο μήνυμα, γεγονός που υποδηλώνει ότι οι χρήστες μπορεί να είναι εξαιρετικά εύπιστοι.
Και ας μην ξεχνάμε ότι δεν είναι μόνο οι άνθρωποι που μπορούν να κάνουν κλικ σε κουμπιά, αλλά και τα bots που προσποιούνται ότι είναι προγράμματα περιήγησης. Επομένως, η ακατέργαστη ανατροφοδότηση δεν είναι καλή για τη μάθηση. Τι μπορείτε να κάνετε με αυτές τις πληροφορίες;
Χρησιμοποιούμε δύο προσεγγίσεις:
- Ανατροφοδότηση από το σχετικό MLΓια παράδειγμα, έχουμε ένα διαδικτυακό σύστημα anti-bot, το οποίο, όπως ήδη ανέφερα, λαμβάνει μια γρήγορη απόφαση με βάση έναν περιορισμένο αριθμό χαρακτηριστικών. Και υπάρχει ένα δεύτερο, αργό σύστημα, που λειτουργεί εκ των υστέρων. Έχει περισσότερα δεδομένα για τον χρήστη, τη συμπεριφορά του κ.λπ. Ως αποτέλεσμα, λαμβάνεται η πιο ισορροπημένη απόφαση και, κατά συνέπεια, έχει υψηλότερη ακρίβεια και πληρότητα. Μπορείτε να κατευθύνετε τη διαφορά στην εργασία αυτών των συστημάτων στο πρώτο ως δεδομένα εκπαίδευσης. Έτσι, το απλούστερο σύστημα θα προσπαθεί πάντα να πλησιάσει στην απόδοση του πιο σύνθετου.
- Ταξινόμηση κλικΜπορείτε απλώς να ταξινομήσετε κάθε κλικ χρήστη, να αξιολογήσετε την εγκυρότητα και τη χρηστικότητά του. Αυτό το κάνουμε στο antispam αλληλογραφίας, χρησιμοποιώντας χαρακτηριστικά χρήστη, το ιστορικό τους, χαρακτηριστικά αποστολέα, το ίδιο το κείμενο και το αποτέλεσμα των ταξινομητών. Ως αποτέλεσμα, έχουμε ένα αυτόματο σύστημα που επικυρώνει τα σχόλια των χρηστών. Και επειδή χρειάζεται επανεκπαίδευση πολύ λιγότερο συχνά, η εργασία του μπορεί να γίνει η κύρια για όλα τα άλλα συστήματα. Η κύρια προτεραιότητα σε αυτό το μοντέλο είναι η ακρίβεια, επειδή η εκπαίδευση ενός μοντέλου σε ανακριβή δεδομένα είναι γεμάτη συνέπειες.
Ενώ καθαρίζουμε τα δεδομένα και εκπαιδεύουμε περαιτέρω τα συστήματα μηχανικής μάθησης (ML), δεν πρέπει να ξεχνάμε τους χρήστες, επειδή για εμάς, χιλιάδες, εκατομμύρια σφάλματα στο γράφημα είναι στατιστικά στοιχεία και για τον χρήστη, κάθε σφάλμα είναι μια τραγωδία. Εκτός από το γεγονός ότι ο χρήστης πρέπει με κάποιο τρόπο να ζήσει με το σφάλμα του στο προϊόν, μετά την ανατροφοδότηση, αναμένει μια εξαίρεση σε μια τέτοια κατάσταση στο μέλλον. Επομένως, αξίζει πάντα να δίνεται στους χρήστες όχι μόνο η ευκαιρία να ψηφίσουν, αλλά και να διορθώσουν τη συμπεριφορά των συστημάτων μηχανικής μάθησης, δημιουργώντας, για παράδειγμα, προσωπικές ευρετικές για κάθε κλικ ανατροφοδότησης. Στην περίπτωση της αλληλογραφίας, αυτό θα μπορούσε να είναι η δυνατότητα φιλτραρίσματος τέτοιων επιστολών ανά αποστολέα και τίτλο για αυτόν τον χρήστη.
Είναι επίσης απαραίτητο να χρησιμοποιήσετε ορισμένες αναφορές ή αιτήματα για υποστήριξη σε ημιαυτόματη ή χειροκίνητη λειτουργία για να τροποποιήσετε το μοντέλο, ώστε άλλοι χρήστες να μην αντιμετωπίζουν παρόμοια προβλήματα.
Ευρετικές για τη μάθηση
Υπάρχουν δύο προβλήματα με αυτές τις ευρετικές μεθόδους και τα δεκανίκια. Το πρώτο είναι ότι ο συνεχώς αυξανόμενος αριθμός δεκανικιών είναι δύσκολο να συντηρηθεί, για να μην αναφέρουμε την ποιότητα και την απόδοσή τους σε μεγάλη απόσταση. Το δεύτερο πρόβλημα είναι ότι το σφάλμα μπορεί να μην είναι συχνό και πολλά κλικ για την επανεκπαίδευση του μοντέλου δεν θα είναι αρκετά. Φαίνεται ότι αυτά τα δύο άσχετα αποτελέσματα μπορούν να εξισορροπηθούν σημαντικά εφαρμόζοντας την ακόλουθη προσέγγιση.
- Ας δημιουργήσουμε ένα προσωρινό δεκανίκι.
- Στέλνουμε δεδομένα από αυτό στο μοντέλο, το οποίο εκπαιδεύεται τακτικά, συμπεριλαμβανομένων των δεδομένων που λαμβάνονται. Εδώ, φυσικά, είναι σημαντικό οι ευρετικές μέθοδοι να έχουν υψηλή ακρίβεια, ώστε να μην μειώνεται η ποιότητα των δεδομένων στο σύνολο εκπαίδευσης.
- Στη συνέχεια, ρυθμίζουμε την παρακολούθηση για να λειτουργήσει το δεκανίκι και, εάν μετά από κάποιο χρονικό διάστημα το δεκανίκι δεν λειτουργεί πλέον και καλύπτεται πλήρως από το μοντέλο, τότε μπορούμε να το αφαιρέσουμε με ασφάλεια. Τώρα είναι απίθανο να επανεμφανιστεί αυτό το πρόβλημα.
Έτσι, ένας στρατός από δεκανίκια είναι πολύ χρήσιμος. Το κυριότερο είναι ότι η υπηρεσία τους είναι προσωρινή, όχι μόνιμη.
Περαιτέρω εκπαίδευση
Η επανεκπαίδευση είναι η διαδικασία προσθήκης νέων δεδομένων, τα οποία λαμβάνονται από σχόλια χρηστών ή άλλων συστημάτων, και εκπαίδευσης ενός υπάρχοντος μοντέλου σε αυτά. Υπάρχουν αρκετά προβλήματα με την επανεκπαίδευση:
- Το μοντέλο μπορεί απλώς να μην υποστηρίζει πρόσθετη εκπαίδευση, αλλά να μαθαίνει μόνο από την αρχή.
- Πουθενά στο βιβλίο της φύσης δεν είναι γραμμένο ότι η πρόσθετη εκπαίδευση θα βελτιώσει απαραίτητα την ποιότητα της εργασίας στην παραγωγή. Συχνά, συμβαίνει το αντίθετο, δηλαδή, μόνο η επιδείνωση είναι πιθανή.
- Οι αλλαγές μπορεί να είναι απρόβλεπτες. Αυτό είναι ένα μάλλον λεπτό σημείο που έχουμε εντοπίσει οι ίδιοι. Ακόμα κι αν ένα νέο μοντέλο σε μια δοκιμή A/B δείξει παρόμοια αποτελέσματα σε σύγκριση με το τρέχον, αυτό δεν σημαίνει ότι θα λειτουργήσει με τον ίδιο τρόπο. Η δουλειά τους μπορεί να διαφέρει κατά περίπου ένα τοις εκατό, κάτι που μπορεί να φέρει νέα σφάλματα ή να επιστρέψει ήδη διορθωμένα παλιά. Τόσο εμείς όσο και οι χρήστες γνωρίζουμε ήδη πώς να ζούμε με τα τρέχοντα σφάλματα και όταν προκύπτει ένας μεγάλος αριθμός νέων σφαλμάτων, ο χρήστης μπορεί επίσης να μην καταλαβαίνει τι συμβαίνει, επειδή αναμένει προβλέψιμη συμπεριφορά.
Επομένως, το πιο σημαντικό πράγμα στην επανεκπαίδευση είναι να διασφαλιστεί ότι το μοντέλο θα βελτιωθεί ή τουλάχιστον δεν θα επιδεινωθεί.
Το πρώτο πράγμα που μας έρχεται στο μυαλό όταν μιλάμε για πρόσθετη εκπαίδευση είναι η προσέγγιση της Ενεργητικής Μάθησης. Τι σημαίνει αυτό; Για παράδειγμα, ένας ταξινομητής καθορίζει εάν μια επιστολή σχετίζεται με τα χρηματοοικονομικά και γύρω από το όριο απόφασής του προσθέτουμε ένα δείγμα παραδειγμάτων με ετικέτες. Αυτό λειτουργεί καλά, για παράδειγμα, στη διαφήμιση, όπου υπάρχει πολλή ανατροφοδότηση και μπορείτε να εκπαιδεύσετε το μοντέλο online. Αλλά αν υπάρχει λίγη ανατροφοδότηση, τότε λαμβάνουμε ένα έντονα μεροληπτικό δείγμα σε σχέση με την κατανομή των δεδομένων παραγωγής, βάσει του οποίου είναι αδύνατο να αξιολογηθεί η συμπεριφορά του μοντέλου κατά τη λειτουργία.
Στην πραγματικότητα, ο στόχος μας είναι να διατηρήσουμε παλιά μοτίβα, ήδη γνωστά μοντέλα και να αποκτήσουμε νέα. Η συνέχεια είναι σημαντική εδώ. Το μοντέλο που συχνά αναπτύσσαμε με μεγάλη δυσκολία λειτουργεί ήδη, επομένως μπορούμε να επικεντρωθούμε στην απόδοσή του.
Διαφορετικά μοντέλα χρησιμοποιούνται στο ηλεκτρονικό ταχυδρομείο: δέντρα, γραμμικά, νευρωνικά δίκτυα. Για το καθένα, δημιουργούμε τον δικό μας αλγόριθμο για πρόσθετη εκπαίδευση. Κατά τη διαδικασία της πρόσθετης εκπαίδευσης, λαμβάνουμε όχι μόνο νέα δεδομένα, αλλά και συχνά νέα χαρακτηριστικά, τα οποία θα λάβουμε υπόψη σε όλους τους παρακάτω αλγόριθμους.
Γραμμικά μοντέλα
Ας υποθέσουμε ότι έχουμε μια λογιστική παλινδρόμηση. Αποτελούμε το μοντέλο ζημιών από τα ακόλουθα στοιχεία:
- LogLoss σε νέα δεδομένα;
- κανονικοποιούμε τα βάρη των νέων χαρακτηριστικών (αφήνουμε στην ησυχία τους τα παλιά).
- Μαθαίνουμε από παλιά δεδομένα για να διατηρήσουμε παλιά μοτίβα.
- και, ίσως, το πιο σημαντικό: κρεμάμε την Αρμονική Κανονικοποίηση, η οποία εγγυάται ότι δεν θα υπάρξει έντονη αλλαγή στα βάρη σε σχέση με το παλιό μοντέλο σύμφωνα με τον κανόνα.
Δεδομένου ότι κάθε στοιχείο απώλειας έχει συντελεστές, μπορούμε να επιλέξουμε τις βέλτιστες τιμές για την εργασία μας χρησιμοποιώντας διασταυρούμενη επικύρωση ή με βάση τις απαιτήσεις του προϊόντος.
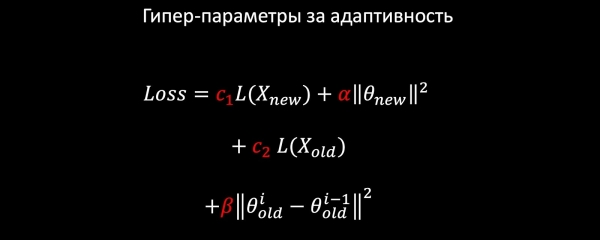
Деревья
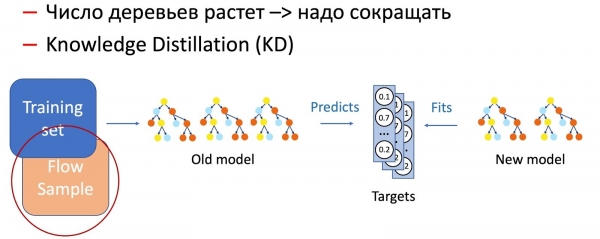
Ας προχωρήσουμε στα δέντρα αποφάσεων. Έχουμε καταλήξει στον ακόλουθο αλγόριθμο για την επανεκπαίδευση δέντρων:
- Η παραγωγή διαχειρίζεται ένα δάσος 100-300 δέντρων, τα οποία έχουν εκπαιδευτεί με βάση το παλιό σύνολο δεδομένων.
- Αφαιρούμε M = 5 κομμάτια στο τέλος και προσθέτουμε 2M = 10 νέα, εκπαιδευμένα σε ολόκληρο το σύνολο δεδομένων, αλλά με υψηλό βάρος για νέα δεδομένα, το οποίο φυσικά εγγυάται μια σταδιακή αλλαγή στο μοντέλο.
Είναι προφανές ότι με την πάροδο του χρόνου ο αριθμός των δέντρων αυξάνεται σημαντικά και πρέπει να μειώνεται περιοδικά για να ανταποκρίνεται στους χρονισμούς. Για αυτό, χρησιμοποιούμε την πλέον πανταχού παρούσα Απόσταξη Γνώσης (KD). Εν συντομία για την αρχή της λειτουργίας της.
- Έχουμε ένα τρέχον «σύνθετο» μοντέλο. Το εκτελούμε στο σύνολο δεδομένων εκπαίδευσης και λαμβάνουμε την κατανομή πιθανοτήτων των κλάσεων εξόδου.
- Στη συνέχεια, εκπαιδεύουμε το μοντέλο μαθητή (το μοντέλο με λιγότερα δέντρα σε αυτήν την περίπτωση) ώστε να αναπαράγει την απόδοση του μοντέλου χρησιμοποιώντας την κατανομή κλάσης ως μεταβλητή-στόχο.
- Είναι σημαντικό να σημειωθεί εδώ ότι δεν χρησιμοποιούμε καμία επισήμανση συνόλου δεδομένων και επομένως μπορούμε να χρησιμοποιήσουμε αυθαίρετα δεδομένα. Φυσικά, χρησιμοποιούμε ένα δείγμα των δεδομένων παραγωγής ως σύνολο εκπαίδευσης για το μοντέλο μαθητή. Έτσι, το σύνολο εκπαίδευσης μας επιτρέπει να διασφαλίσουμε την ακρίβεια του μοντέλου και το δείγμα της ροής εξασφαλίζει παρόμοια απόδοση στην κατανομή παραγωγής, αντισταθμίζοντας την μεροληψία του συνόλου εκπαίδευσης.
Ο συνδυασμός αυτών των δύο τεχνικών (προσθήκη δέντρων και περιοδική μείωση του αριθμού τους χρησιμοποιώντας την Απόσταξη Γνώσης) διασφαλίζει την εισαγωγή νέων προτύπων και την πλήρη συνέχεια.
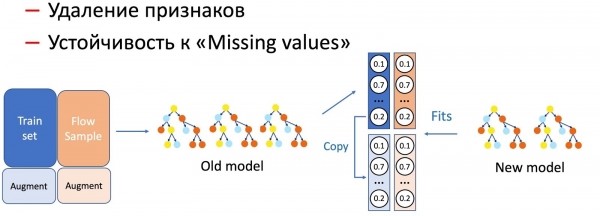
Με το KD, κάνουμε επίσης διάκριση μεταξύ λειτουργιών με χαρακτηριστικά μοντέλου, όπως η αφαίρεση χαρακτηριστικών και η εργασία με κενά. Στην περίπτωσή μας, έχουμε μια σειρά από σημαντικά στατιστικά χαρακτηριστικά (από αποστολείς, hashes κειμένου, URL κ.λπ.) που αποθηκεύονται σε μια βάση δεδομένων και έχουν την τάση να αποτυγχάνουν. Το μοντέλο, φυσικά, δεν είναι προετοιμασμένο για μια τέτοια εξέλιξη, καθώς δεν υπάρχουν καταστάσεις αποτυχίας στο σύνολο εκπαίδευσης. Σε τέτοιες περιπτώσεις, συνδυάζουμε τεχνικές KD και επαύξησης: όταν εκπαιδεύουμε ένα μέρος των δεδομένων, αφαιρούμε ή μηδενίζουμε τα απαραίτητα χαρακτηριστικά και παίρνουμε τις αρχικές ετικέτες (έξοδοι του τρέχοντος μοντέλου), το μοντέλο-μαθητή μαθαίνει να επαναλαμβάνει αυτήν την κατανομή.
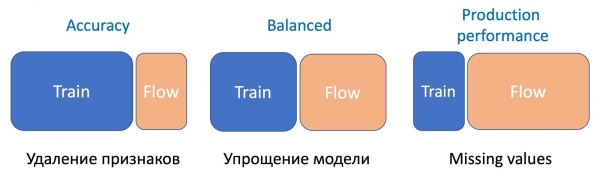
Παρατηρήσαμε ότι όσο πιο σοβαρός χειρισμός γίνεται στο μοντέλο, τόσο υψηλότερο είναι το ποσοστό των απαιτούμενων δειγμάτων ροής.
Η αφαίρεση χαρακτηριστικών, η απλούστερη λειτουργία, απαιτεί μόνο ένα μικρό μέρος της ροής, καθώς αλλάζουν μόνο μερικά χαρακτηριστικά και το τρέχον μοντέλο εκπαιδεύτηκε στο ίδιο σύνολο - η διαφορά είναι ελάχιστη. Η απλοποίηση του μοντέλου (μείωση του αριθμού των δέντρων αρκετές φορές) απαιτεί αναλογία 50/50. Και η έλλειψη σημαντικών στατιστικών χαρακτηριστικών που επηρεάζουν σοβαρά την απόδοση του μοντέλου απαιτεί ακόμη περισσότερη ροή για να εξισορροπηθεί η εργασία του νέου μοντέλου, ανθεκτική στις παραλείψεις, σε όλους τους τύπους γραμμάτων.
FastText
Ας προχωρήσουμε στο FastText. Επιτρέψτε μου να σας υπενθυμίσω ότι η αναπαράσταση (Ενσωμάτωση) μιας λέξης αποτελείται από το άθροισμα της ενσωμάτωσης της ίδιας της λέξης και όλων των γραμμάτων N-γραμμάτων της, συνήθως τριγραμμάτων. Δεδομένου ότι μπορεί να υπάρχουν αρκετά τριγράμματα, χρησιμοποιείται το Bucket Hashing, δηλαδή ο μετασχηματισμός ολόκληρου του χώρου σε ένα συγκεκριμένο σταθερό hashmap. Ως αποτέλεσμα, λαμβάνεται ο πίνακας βαρών με τη διάσταση του εσωτερικού επιπέδου επί τον αριθμό των λέξεων + κουβάδες.
Κατά την επανεκπαίδευση, εμφανίζονται νέα χαρακτηριστικά: λέξεις και τριγράμματα. Στην τυπική επανεκπαίδευση από το Facebook, δεν συμβαίνει τίποτα σημαντικό. Μόνο παλιά βάρη με διασταυρούμενη εντροπία σε νέα δεδομένα επανεκπαιδεύονται. Έτσι, δεν χρησιμοποιούνται νέα χαρακτηριστικά, φυσικά, αυτή η προσέγγιση έχει όλα τα παραπάνω περιγραφόμενα μειονεκτήματα που σχετίζονται με την απρόβλεπτοτητα του μοντέλου στην παραγωγή. Επομένως, έχουμε βελτιώσει ελαφρώς το FastText. Προσθέτουμε όλα τα νέα βάρη (λέξεις και τριγράμματα), επανεκπαιδεύουμε ολόκληρο τον πίνακα με διασταυρούμενη εντροπία και προσθέτουμε αρμονική κανονικοποίηση κατ' αναλογία με το γραμμικό μοντέλο, η οποία εγγυάται μια ασήμαντη αλλαγή στα παλιά βάρη.

CNN
Με τα συνελικτικά δίκτυα είναι λίγο πιο περίπλοκο. Εάν τα τελευταία επίπεδα εκπαιδεύονται σε CNN, τότε, φυσικά, μπορεί να εφαρμοστεί αρμονική κανονικοποίηση και να διασφαλιστεί η συνέχεια. Αλλά εάν ολόκληρο το δίκτυο χρειάζεται εκπαίδευση, τότε μια τέτοια κανονικοποίηση δεν μπορεί να εφαρμοστεί σε όλα τα επίπεδα. Ωστόσο, υπάρχει μια επιλογή με εκπαίδευση συμπληρωματικών ενσωματώσεων μέσω Triplet Loss ().
Απώλεια τριδύμου
Χρησιμοποιώντας την εργασία antiphishing ως παράδειγμα, θα αναλύσουμε το Triplet Loss σε γενικές γραμμές. Παίρνουμε το λογότυπό μας, καθώς και θετικά και αρνητικά παραδείγματα λογότυπων άλλων εταιρειών. Ελαχιστοποιούμε την απόσταση μεταξύ του πρώτου και μεγιστοποιούμε την απόσταση μεταξύ του δεύτερου, κάνοντας αυτό με ένα μικρό κενό για να εξασφαλίσουμε μεγαλύτερη συμπύκνωση των κλάσεων.
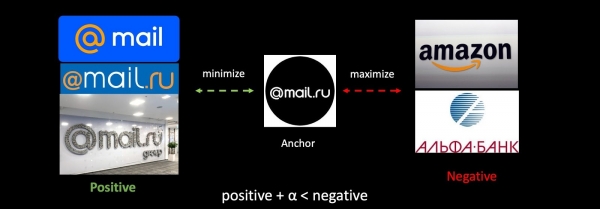
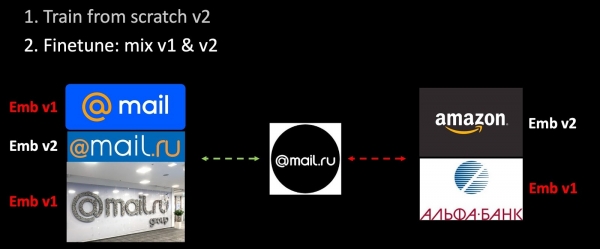
Αν επανεκπαιδεύσουμε το δίκτυο, τότε ο μετρικός μας χώρος αλλάζει εντελώς και καθίσταται απολύτως ασύμβατος με τον προηγούμενο. Αυτό είναι ένα σοβαρό πρόβλημα σε εργασίες που χρησιμοποιούν διανύσματα. Για να παρακάμψουμε αυτό το πρόβλημα, θα αναμίξουμε παλιές ενσωματώσεις κατά την εκπαίδευση.
Προσθέσαμε νέα δεδομένα στο σύνολο εκπαίδευσης και εκπαιδεύσαμε τη δεύτερη έκδοση του μοντέλου από την αρχή. Στο δεύτερο στάδιο, βελτιστοποιούμε το δίκτυό μας: πρώτα, βελτιστοποιείται το τελευταίο επίπεδο και στη συνέχεια ξεπαγώνει ολόκληρο το δίκτυο. Κατά τη διαδικασία σύνθεσης τριπλετών, μόνο ένα μέρος των ενσωματώσεων υπολογίζεται χρησιμοποιώντας το εκπαιδευμένο μοντέλο, τα υπόλοιπα - χρησιμοποιώντας το παλιό. Έτσι, κατά τη διαδικασία βελτιστοποίησης, διασφαλίζουμε τη συμβατότητα των μετρικών χώρων v1 και v2. Μια ιδιόμορφη εκδοχή αρμονικής κανονικοποίησης.
Η αρχιτεκτονική στο σύνολό της
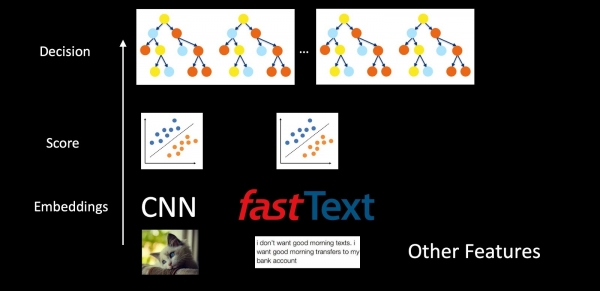
Αν εξετάσουμε ολόκληρο το σύστημα χρησιμοποιώντας το παράδειγμα antispam, τα μοντέλα δεν είναι μεμονωμένα, αλλά ένθετα. Λαμβάνουμε εικόνες, κείμενο και άλλα χαρακτηριστικά, και με τη βοήθεια του CNN και του Fast Text λαμβάνουμε ενσωματώσεις. Στη συνέχεια, εφαρμόζονται ταξινομητές πάνω από τις ενσωματώσεις, οι οποίοι παράγουν βαθμολογίες για διαφορετικές κλάσεις (τύποι email, spam, παρουσία λογότυπου). Οι βαθμολογίες και τα χαρακτηριστικά τοποθετούνται στη συνέχεια στο δάσος των δέντρων για να ληφθεί η τελική απόφαση. Οι ξεχωριστοί ταξινομητές σε αυτό το σχήμα μας επιτρέπουν να ερμηνεύουμε καλύτερα τα αποτελέσματα της εργασίας του συστήματος και πιο συγκεκριμένα να εκπαιδεύουμε στοιχεία σε περίπτωση προβλημάτων, αντί να τροφοδοτούμε όλα τα δεδομένα στα δέντρα αποφάσεων σε ακατέργαστη μορφή.
Τέλος, εγγυόμαστε τη συνέχεια σε κάθε επίπεδο. Στο κατώτερο επίπεδο στο CNN και στο Fast Text χρησιμοποιούμε αρμονική κανονικοποίηση, για τους ταξινομητές στη μέση - επίσης αρμονική κανονικοποίηση και βαθμονόμηση βαθμολογίας για τη συνέπεια της κατανομής πιθανοτήτων. Και τα ενισχυμένα δέντρα εκπαιδεύονται σταδιακά ή με Απόσταξη Γνώσης.
Γενικά, η διατήρηση ενός τέτοιου ενσωματωμένου συστήματος μηχανικής μάθησης είναι συνήθως μια ταλαιπωρία, καθώς οποιοδήποτε στοιχείο στο χαμηλότερο επίπεδο οδηγεί σε ενημέρωση ολόκληρου του συστήματος παραπάνω. Αλλά επειδή στη ρύθμισή μας κάθε στοιχείο αλλάζει ελαφρώς και είναι συμβατό με το προηγούμενο, ολόκληρο το σύστημα μπορεί να ενημερωθεί σε κομμάτια χωρίς να χρειάζεται να επανεκπαιδευτεί ολόκληρη η δομή, γεγονός που επιτρέπει τη συντήρησή του χωρίς σοβαρή επιβάρυνση.
Αναπτύσσω
Έχουμε καλύψει τη συλλογή δεδομένων και την πρόσθετη εκπαίδευση διαφορετικών τύπων μοντέλων, επομένως προχωράμε στην ανάπτυξή τους στο περιβάλλον παραγωγής.
Δοκιμή A/B
Όπως είπα και νωρίτερα, κατά τη διάρκεια της διαδικασίας συλλογής δεδομένων, συνήθως λαμβάνουμε ένα μεροληπτικό δείγμα, το οποίο καθιστά αδύνατη την αξιολόγηση της απόδοσης παραγωγής του μοντέλου. Επομένως, κατά την ανάπτυξη, το μοντέλο πρέπει να συγκριθεί με την προηγούμενη έκδοση για να κατανοήσουμε πώς πάνε τα πράγματα στην πραγματικότητα, δηλαδή για να διεξαχθούν δοκιμές A/B. Στην πραγματικότητα, η διαδικασία κυκλοφορίας και ανάλυσης γραφημάτων είναι αρκετά ρουτίνας και προσφέρεται για αυτοματοποίηση. Αναπτύσσουμε σταδιακά τα μοντέλα μας στο 5%, 30%, 50% και 100% των χρηστών, συλλέγοντας παράλληλα όλες τις διαθέσιμες μετρήσεις για τις απαντήσεις του μοντέλου και τα σχόλια των χρηστών. Σε περίπτωση σοβαρών ακραίων τιμών, αναιρούμε αυτόματα το μοντέλο και, σε άλλες περιπτώσεις, έχοντας συγκεντρώσει επαρκή αριθμό κλικ χρηστών, αποφασίζουμε να αυξήσουμε το ποσοστό. Ως αποτέλεσμα, φέρνουμε το νέο μοντέλο στο 50% των χρηστών εντελώς αυτόματα και η κυκλοφορία σε ολόκληρο το κοινό εγκρίνεται από ένα άτομο, αν και αυτό το βήμα μπορεί επίσης να αυτοματοποιηθεί.
Ωστόσο, η διαδικασία δοκιμής A/B παρέχει περιθώρια βελτιστοποίησης. Το γεγονός είναι ότι οποιαδήποτε δοκιμή A/B είναι αρκετά μεγάλη (στην περίπτωσή μας, διαρκεί από 6 έως 24 ώρες ανάλογα με την ποσότητα των ανατροφοδότησης), γεγονός που την καθιστά αρκετά ακριβή και περιορισμένη σε πόρους. Επιπλέον, απαιτείται ένα αρκετά υψηλό ποσοστό της ροής για τη δοκιμή για να επιταχυνθεί ουσιαστικά ο συνολικός χρόνος της δοκιμής A/B (μπορεί να χρειαστεί πολύς χρόνος για να συλλεχθεί ένα στατιστικά σημαντικό δείγμα για την αξιολόγηση μετρήσεων σε ένα μικρό ποσοστό), γεγονός που καθιστά τον αριθμό των υποδοχών A/B εξαιρετικά περιορισμένο. Προφανώς, πρέπει να βάλουμε στη δοκιμή μόνο τα πιο υποσχόμενα μοντέλα, από τα οποία λαμβάνουμε αρκετά στη διαδικασία πρόσθετης εκπαίδευσης.
Για να λύσουμε αυτό το πρόβλημα, εκπαιδεύσαμε έναν ξεχωριστό ταξινομητή που προβλέπει την επιτυχία μιας δοκιμής A/B. Για να το κάνουμε αυτό, λαμβάνουμε ως χαρακτηριστικά τα στατιστικά στοιχεία της λήψης αποφάσεων, της ακρίβειας, της ανάκλησης και άλλων μετρήσεων στο σύνολο εκπαίδευσης, στο αναβαλλόμενο σύνολο και στο δείγμα από τη ροή. Συγκρίνουμε επίσης το μοντέλο με το τρέχον σε παραγωγή, με ευρετικές μεθόδους, και λαμβάνουμε υπόψη την πολυπλοκότητα του μοντέλου. Χρησιμοποιώντας όλα αυτά τα χαρακτηριστικά, ο ταξινομητής που εκπαιδεύεται στο ιστορικό δοκιμών βαθμολογεί τα υποψήφια μοντέλα, στην περίπτωσή μας αυτά είναι δάση δέντρων, και αποφασίζει ποια από αυτά θα βάλει στη δοκιμή A/B.
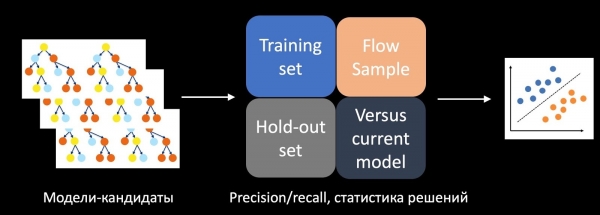
Κατά τη στιγμή της εφαρμογής, αυτή η προσέγγιση μας επέτρεψε να αυξήσουμε τον αριθμό των επιτυχημένων δοκιμών A/B αρκετές φορές.
Δοκιμές & Παρακολούθηση
Οι δοκιμές και η παρακολούθηση, παραδόξως, δεν βλάπτουν την υγεία μας, αντίθετα, τη βελτιώνουν και ανακουφίζουν από το περιττό άγχος. Οι δοκιμές σάς επιτρέπουν να αποτρέψετε μια αποτυχία και η παρακολούθηση σάς επιτρέπει να την εντοπίσετε εγκαίρως για να μειώσετε τον αντίκτυπο στους χρήστες.
Είναι σημαντικό να κατανοήσετε ότι αργά ή γρήγορα το σύστημά σας θα κάνει πάντα λάθη - αυτό οφείλεται στον κύκλο ανάπτυξης οποιουδήποτε λογισμικού. Στην αρχή της ανάπτυξης του συστήματος υπάρχουν πάντα πολλά σφάλματα μέχρι να ηρεμήσουν όλα και να ολοκληρωθεί το κύριο στάδιο των καινοτομιών. Αλλά με την πάροδο του χρόνου, η εντροπία επηρεάζει αρνητικά και τα σφάλματα εμφανίζονται ξανά - λόγω της υποβάθμισης των στοιχείων γύρω και των αλλαγών στα δεδομένα, τα οποία ανέφερα στην αρχή.
Εδώ θα ήθελα να σημειώσω ότι κάθε σύστημα μηχανικής μάθησης θα πρέπει να εξετάζεται με βάση το κέρδος του καθ' όλη τη διάρκεια του κύκλου ζωής του. Το παρακάτω γράφημα δείχνει ένα παράδειγμα του συστήματος που προσπαθεί να εντοπίσει ένα σπάνιο είδος ανεπιθύμητης αλληλογραφίας (η γραμμή στο γράφημα είναι γύρω στο μηδέν). Κάποτε, λόγω μιας λανθασμένα αποθηκευμένης λειτουργίας στην προσωρινή μνήμη, τρελάθηκε. Τυχαία, δεν υπήρχε παρακολούθηση για μη φυσιολογική ενεργοποίηση, με αποτέλεσμα το σύστημα να αρχίσει να αποθηκεύει γράμματα στον φάκελο ανεπιθύμητης αλληλογραφίας στο όριο λήψης αποφάσεων σε μεγάλες ποσότητες. Παρά τη διόρθωση των συνεπειών, το σύστημα έχει ήδη κάνει τόσα πολλά λάθη που δεν θα ξεπληρώσει τα έξοδά του σε πέντε χρόνια. Και αυτό είναι μια πλήρης αποτυχία όσον αφορά τον κύκλο ζωής του μοντέλου.
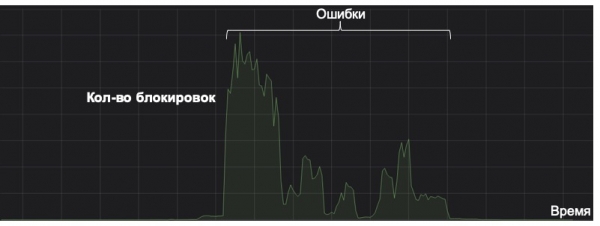
Επομένως, κάτι τόσο απλό όσο η παρακολούθηση μπορεί να γίνει κλειδί στη ζωή ενός μοντέλου. Εκτός από τις τυπικές και προφανείς μετρήσεις, λαμβάνουμε υπόψη την κατανομή των αποκρίσεων και των ρυθμών του μοντέλου, καθώς και την κατανομή των τιμών των βασικών χαρακτηριστικών. Χρησιμοποιώντας την απόκλιση KL, μπορούμε να συγκρίνουμε την τρέχουσα κατανομή με την ιστορική ή τις τιμές στη δοκιμή A/B με την υπόλοιπη ροή, κάτι που μας επιτρέπει να παρατηρήσουμε ανωμαλίες στο μοντέλο και να αναιρέσουμε τις αλλαγές στο χρόνο.
Στις περισσότερες περιπτώσεις, λανσάρουμε τις πρώτες εκδόσεις συστημάτων μας χρησιμοποιώντας απλές ευρετικές μεθόδους ή μοντέλα που χρησιμοποιούμε για παρακολούθηση στο μέλλον. Για παράδειγμα, παρακολουθούμε το μοντέλο NER σε σύγκριση με κανονικές εκφράσεις για συγκεκριμένα ηλεκτρονικά καταστήματα και, εάν η κάλυψη των ταξινομητών μειωθεί σε σύγκριση με αυτά, καταλαβαίνουμε τους λόγους. Μια άλλη χρήσιμη εφαρμογή των ευρετικών!
Αποτελέσματα της
Ας επανεξετάσουμε τις βασικές ιδέες του άρθρου.
- ΦίμπντεκΠάντα σκεφτόμαστε τον χρήστη: πώς θα ζήσει με τα λάθη μας, πώς θα είναι σε θέση να τα αναφέρει. Δεν ξεχνάμε ότι οι χρήστες δεν αποτελούν πηγή καθαρής ανατροφοδότησης για τα μοντέλα εκπαίδευσης και πρέπει να καθαρίζονται με τη βοήθεια βοηθητικών συστημάτων μηχανικής μάθησης. Εάν δεν υπάρχει τρόπος να συλλέξουμε ένα σήμα από τον χρήστη, τότε αναζητούμε εναλλακτικές πηγές ανατροφοδότησης, για παράδειγμα, σχετικά συστήματα.
- Περαιτέρω εκπαίδευσηΤο κύριο πράγμα εδώ είναι η συνέχεια, επομένως βασιζόμαστε στο τρέχον μοντέλο παραγωγής. Εκπαιδεύουμε νέα μοντέλα έτσι ώστε να μην διαφέρουν πολύ από το προηγούμενο λόγω αρμονικής κανονικοποίησης και παρόμοιων κόλπων.
- ΑναπτύσσωΗ αυτόματη ανάπτυξη μέσω μετρήσεων μειώνει σημαντικά τον χρόνο υλοποίησης των μοντέλων. Η παρακολούθηση των στατιστικών και της κατανομής των αποφάσεων, ο αριθμός των πτώσεων των χρηστών είναι απαραίτητος για τον ήρεμο ύπνο σας και τα παραγωγικά Σαββατοκύριακά σας.
Λοιπόν, ελπίζω ότι αυτά που διαβάσατε θα σας βοηθήσουν να βελτιώσετε τα συστήματα μηχανικής μάθησης (ML) σας πιο γρήγορα, να τα διαθέσετε στην αγορά πιο γρήγορα και να τα κάνετε πιο αξιόπιστα, μειώνοντας το άγχος που προκαλεί η εργασία.
Πηγή: www.habr.com
