

Σήμερα, υπάρχουν έτοιμες (ιδιόκτητες) λύσεις για την παρακολούθηση ροών IP(TS), για παράδειγμα и , έχουν ένα αρκετά πλούσιο σύνολο λειτουργιών και συνήθως τέτοιες λύσεις είναι διαθέσιμες από μεγάλους παρόχους που ασχολούνται με τηλεοπτικές υπηρεσίες. Αυτό το άρθρο περιγράφει μια λύση που βασίζεται σε έργο ανοιχτού κώδικα , σχεδιασμένο για ελάχιστο έλεγχο των ροών IP(TS) από τον CC (μετρητή συνέχειας) και το bitrate. Μια πιθανή εφαρμογή είναι η παρακολούθηση της απώλειας πακέτων ή μιας ολόκληρης ροής μέσω ενός μισθωμένου καναλιού L2 (το οποίο δεν μπορεί να παρακολουθηθεί κανονικά, για παράδειγμα διαβάζοντας μετρητές απώλειας αναμονής).
Πολύ σύντομα για το TSDuck
Το TSDuck είναι ένα λογισμικό ανοιχτού κώδικα (άδεια BSD 2 ρητρών) (ένα σύνολο βοηθητικών προγραμμάτων κονσόλας και μια βιβλιοθήκη για την ανάπτυξη των δικών σας βοηθητικών προγραμμάτων ή προσθηκών) για το χειρισμό των ροών TS. Ως είσοδος μπορεί να λειτουργήσει με IP (multicast/unicast), http, hls, dvb-tuners, dektec dvb-asi demoulator, διαθέτει εσωτερική γεννήτρια TS-stream και ανάγνωση από αρχεία. Η έξοδος μπορεί να είναι εγγραφή σε αρχείο, IP (multicast/unicast), hls, διαμορφωτές dektec dvb-asi και HiDes, προγράμματα αναπαραγωγής (mplayer, vlc, xine) και απόθεση. Μεταξύ της εισόδου και της εξόδου, μπορείτε να ενεργοποιήσετε διάφορους επεξεργαστές κυκλοφορίας, όπως επαναχαρτογράφηση PID, κρυπτογράφηση/αποσύνδεση, ανάλυση μετρητή CC, υπολογισμός ρυθμού bit και άλλες τυπικές λειτουργίες ροής TS.
Σε αυτό το άρθρο, οι ροές IP (πολλαπλή διανομή) θα χρησιμοποιηθούν ως είσοδος, θα χρησιμοποιηθούν επεξεργαστές bitrate_monitor (το όνομα καθιστά σαφές τι είναι) και η συνέχεια (ανάλυση μετρητή CC). Χωρίς κανένα πρόβλημα, μπορείτε να αντικαταστήσετε το IP multicast με άλλο τύπο εισόδου που υποστηρίζεται από το TSDuck.
Υπάρχουν TSDuck για τα περισσότερα πρόσφατα λειτουργικά συστήματα. Για Debian Δεν υπάρχουν, αλλά κατάφερα να τα συναρμολογήσω χωρίς κανένα πρόβλημα debian 8 και debian 10.
Στη συνέχεια, χρησιμοποιείται η έκδοση TSDuck 3.19-1520 και το λειτουργικό σύστημα είναι Linux (χρησιμοποιείται για την παρασκευή του διαλύματος) debian 10, για πραγματική χρήση - CentOS 7)
Προετοιμασία TSDuck και OS
Πριν παρακολουθήσετε τις πραγματικές ροές, πρέπει να βεβαιωθείτε ότι το TSDuck λειτουργεί σωστά και ότι δεν υπάρχουν πτώσεις στο επίπεδο της κάρτας δικτύου ή του λειτουργικού συστήματος (πρίζα). Αυτό απαιτείται, ώστε αργότερα να μην χρειάζεται να μαντέψετε πού συνέβησαν οι πτώσεις - στο δίκτυο ή "μέσα στον διακομιστή". Μπορείτε να ελέγξετε τις πτώσεις σε επίπεδο κάρτας δικτύου με την εντολή ethtool -S ethX, ο συντονισμός γίνεται με το ίδιο ethtool (συνήθως, πρέπει να αυξήσετε την προσωρινή μνήμη RX (-G) και μερικές φορές να απενεργοποιήσετε ορισμένες εκφορτώσεις (-K)). Ως γενική σύσταση, μπορούμε να συμβουλεύσουμε τη χρήση μιας ξεχωριστής θύρας για τη λήψη της αναλυόμενης κίνησης, εάν είναι δυνατόν, αυτό θα ελαχιστοποιήσει τα ψευδώς θετικά που σχετίζονται με το γεγονός ότι η πτώση συνέβη ειδικά στη θύρα του αναλυτή λόγω της παρουσίας άλλης κίνησης. Εάν αυτό δεν είναι δυνατό (χρησιμοποιείται ένας μίνι υπολογιστής/NUC με μία θύρα), τότε είναι πολύ επιθυμητό να διαμορφώσετε την ιεράρχηση της αναλυόμενης κίνησης σε σχέση με την υπόλοιπη συσκευή στη συσκευή στην οποία είναι συνδεδεμένος ο αναλυτής. Όσον αφορά τα εικονικά περιβάλλοντα, πρέπει να είστε προσεκτικοί και να μπορείτε να βρείτε πακέτα που ξεκινούν από τη φυσική θύρα και τελειώνουν με την εφαρμογή μέσα στην εικονική μηχανή.
Δημιουργία και λήψη ροής σε έναν κεντρικό υπολογιστή
Ως πρώτο βήμα για την προετοιμασία του TSDuck, θα δημιουργήσουμε και θα λάβουμε επισκεψιμότητα σε έναν μόνο κεντρικό υπολογιστή χρησιμοποιώντας netns.
Προετοιμασία περιβάλλοντος:
ip netns add P #создаём netns P, в нём будет происходить анализ трафика
ip link add type veth #создаём veth-пару - veth0 оставляем в netns по умолчанию (в этот интерфейс будет генерироваться трафик)
ip link set dev veth1 netns P #veth1 - помещаем в netns P (на этом интерфейсе будет приём трафика)
ip netns exec P ifconfig veth1 192.0.2.1/30 up #поднимаем IP на veth1, не имеет значения какой именно
ip netns exec P ip ro add default via 192.0.2.2 #настраиваем маршрут по умолчанию внутри nents P
sysctl net.ipv6.conf.veth0.disable_ipv6=1 #отключаем IPv6 на veth0 - это делается для того, чтобы в счётчик TX не попадал посторонний мусор
ifconfig veth0 up #поднимаем интерфейс veth0
ip route add 239.0.0.1 dev veth0 #создаём маршрут, чтобы ОС направляла трафик к 239.0.0.1 в сторону veth0Το περιβάλλον είναι έτοιμο. Ας εκκινήσουμε τον αναλυτή κίνησης:
ip netns exec P tsp --realtime -t
-I ip 239.0.0.1:1234
-P continuity
-P bitrate_monitor -p 1 -t 1
-O dropόπου "-p 1 -t 1" σημαίνει ότι πρέπει να υπολογίζετε το bitrate κάθε δευτερόλεπτο και να εξάγετε πληροφορίες σχετικά με το bitrate κάθε δευτερόλεπτο
Εκκινούμε μια γεννήτρια κίνησης με ταχύτητα 10 Mbit/s:
tsp -I craft
-P regulate -b 10000000
-O ip -p 7 -e --local-port 6000 239.0.0.1:1234όπου "-p 7 -e" σημαίνει ότι πρέπει να συσκευάσετε 7 πακέτα TS σε 1 πακέτο IP και να το κάνετε αυστηρά (-e), δηλαδή να περιμένετε πάντα 7 πακέτα TS από τον τελευταίο επεξεργαστή πριν στείλετε ένα πακέτο IP.
Ο αναλυτής αρχίζει να εξάγει τα αναμενόμενα μηνύματα:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s
* 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s
* 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/sΤώρα ας προσθέσουμε μερικές σταγόνες:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROPκαι εμφανίζονται τέτοια μηνύματα:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets
* 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets που αναμένεται. Απενεργοποιούμε την απώλεια πακέτων (ip netns exec P iptables -F) και προσπαθούμε να αυξήσουμε το bitrate της γεννήτριας στα 100 Mbit/s. Ο αναλυτής αναφέρει μια δέσμη σφαλμάτων CC και περίπου 75 Mbit/s αντί για 100. Προσπαθούμε να καταλάβουμε ποιος φταίει - η γεννήτρια δεν συμβαδίζει ή το πρόβλημα δεν βρίσκεται σε αυτήν, για αυτό ξεκινάμε να δημιουργούμε έναν σταθερό αριθμό πακέτων (700000 πακέτα TS = 100000 πακέτα IP):
# ifconfig veth0 | grep TX
TX packets 151825460 bytes 205725459268 (191.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
* count: PID 0 (0x0000): 700,000 packets
# ifconfig veth0 | grep TX
TX packets 151925460 bytes 205861259268 (191.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Όπως μπορείτε να δείτε, δημιουργήθηκαν ακριβώς 100000 πακέτα IP (151925460-151825460). Έτσι, καταλαβαίνουμε τι συμβαίνει με τον αναλυτή, γι 'αυτό ελέγχουμε με τον μετρητή RX στο veth1, είναι αυστηρά ίσος με τον μετρητή TX στο veth0 και, στη συνέχεια, εξετάζουμε τι συμβαίνει στο επίπεδο υποδοχής:
# ip netns exec P cat /proc/net/udp
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops
133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355 Εδώ μπορείτε να δείτε τον αριθμό των σταγόνων = 24355. Στα πακέτα TS είναι 170485 ή 24.36% των 700000, επομένως βλέπουμε ότι το ίδιο 25% του χαμένου bitrate είναι σταγόνες στην υποδοχή udp. Οι πτώσεις σε μια υποδοχή UDP συνήθως συμβαίνουν λόγω έλλειψης buffer, ας δούμε ποιο είναι το προεπιλεγμένο μέγεθος buffer υποδοχής και το μέγιστο μέγεθος buffer υποδοχής:
# sysctl net.core.rmem_default
net.core.rmem_default = 212992
# sysctl net.core.rmem_max
net.core.rmem_max = 212992Έτσι, εάν οι εφαρμογές δεν ζητούν ρητά το μέγεθος του buffer, δημιουργούνται υποδοχές με buffer 208 KB, αλλά εάν ζητήσουν περισσότερα, και πάλι δεν θα λάβουν αυτό που ζήτησαν. Δεδομένου ότι το μέγεθος buffer (--buffer-size) μπορεί να οριστεί για την είσοδο IP σε tsp, δεν θα αγγίξουμε το προεπιλεγμένο μέγεθος υποδοχής, αλλά θα ορίσουμε μόνο το μέγιστο μέγεθος buffer και θα καθορίσουμε ρητά το μέγεθος buffer μέσω των ορισμάτων tsp:
sysctl net.core.rmem_max=8388608
ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O dropΜε τέτοιο συντονισμό του buffer της υποδοχής, ο αναφερόμενος ρυθμός bit είναι τώρα περίπου 100 Mbit/s, δεν υπάρχουν σφάλματα CC.
Με βάση την κατανάλωση CPU από την ίδια την εφαρμογή tsp. Σε σχέση με έναν πυρήνα CPU i5-4260U @ 1.40GHz, η ανάλυση ροής 10Mbps θα απαιτεί 3-4% CPU, 100Mbps - 25%, 200Mbps - 46%. Όταν ορίζετε το ποσοστό απώλειας πακέτων, το φορτίο της CPU πρακτικά δεν αυξάνεται (αλλά μπορεί να μειωθεί).
Σε πιο ισχυρό υλικό, ήταν δυνατή η δημιουργία και η ανάλυση ροών άνω του 1 Gb/s χωρίς προβλήματα.
Δοκιμή σε πραγματικές κάρτες δικτύου
Μετά τη δοκιμή σε ένα ζεύγος veth, πρέπει να πάρετε δύο κεντρικούς υπολογιστές ή δύο θύρες ενός κεντρικού υπολογιστή, να συνδέσετε τις θύρες μεταξύ τους, να εκτελέσετε τη γεννήτρια στη μία και τον αναλυτή στη δεύτερη. Δεν υπήρχαν εκπλήξεις εδώ, αλλά στην πραγματικότητα όλα εξαρτώνται από το υλικό, όσο πιο αδύναμο είναι, τόσο πιο ενδιαφέρον θα είναι εδώ.
Χρήση των δεδομένων που λαμβάνονται από το σύστημα παρακολούθησης (Zabbix)
Το tsp δεν διαθέτει μηχανικά αναγνώσιμο API όπως το SNMP ή παρόμοιο. Τα μηνύματα CC πρέπει να συγκεντρωθούν τουλάχιστον κατά 1 δευτερόλεπτο (με υψηλό ποσοστό απώλειας πακέτων, μπορεί να υπάρχουν εκατοντάδες/χιλιάδες/δεκάδες χιλιάδες ανά δευτερόλεπτο, ανάλογα με το bitrate).
Έτσι, για να αποθηκεύσετε πληροφορίες και να σχεδιάσετε γραφήματα σχετικά με τα σφάλματα CC και τον ρυθμό μετάδοσης bit και να προκαλέσετε περαιτέρω ατυχήματα, ενδέχεται να υπάρχουν οι ακόλουθες επιλογές:
- Αναλύστε και συγκεντρώστε (κατά CC) την έξοδο tsp, δηλαδή μετατρέψτε την στην επιθυμητή μορφή.
- Βελτιώστε το ίδιο το tsp ή/και τα πρόσθετα επεξεργαστή bitrate_monitor και τη συνέχεια, έτσι ώστε το αποτέλεσμα να δίνεται σε αναγνώσιμη από μηχανή μορφή κατάλληλη για το σύστημα παρακολούθησης.
- Γράψτε τη δική σας εφαρμογή πάνω από τη βιβλιοθήκη tsduck.
Προφανώς, από την άποψη του κόστους εργασίας, η επιλογή 1 είναι η απλούστερη, ειδικά αν σκεφτεί κανείς ότι το ίδιο το tsduck είναι γραμμένο σε γλώσσα χαμηλού επιπέδου (με τα σύγχρονα πρότυπα) (C++)
Ένα απλό πρωτότυπο ενός αναλυτή+συγκεντρωτή στο bash έδειξε ότι σε ροή 10 Mbit/s και απώλεια πακέτων 50% (η χειρότερη περίπτωση), η διαδικασία bash κατανάλωνε 3-4 φορές περισσότερη CPU από την ίδια τη διαδικασία tsp. Αυτό το σενάριο είναι απαράδεκτο. Το πραγματικό κομμάτι αυτού του πρωτοτύπου είναι παρακάτω.
Noodles on the bash
#!/usr/bin/env bash
missingPackets=0
ccErrorSeconds=0
regexMissPackets='^* (.+) - continuity:.*missing ([0-9]+) packets$'
missingPacketsTime=""
ip netns exec P tsp --realtime -t -I ip -b 8388608 "239.0.0.1:1234" -O drop -P bitrate_monitor -p 1 -t 1 -P continuity 2>&1 |
while read i
do
#line example:* 2019/12/28 23:41:14 - continuity: packet index: 6,078, PID: 0x0100, missing 5 packets
#line example 2: * 2019/12/28 23:55:11 - bitrate_monitor: 2019/12/28 23:55:11, TS bitrate: 4,272,864 bits/s
if [[ "$i" == *continuity:* ]]
then
if [[ "$i" =~ $regexMissPackets ]]
then
missingPacketsTimeNew="${BASH_REMATCH[1]}" #timestamp (seconds)
if [[ "$missingPacketsTime" != "$missingPacketsTimeNew" ]] #new second with CC error
then
((ccErrorSeconds += 1))
fi
missingPacketsTime=$missingPacketsTimeNew
packets=${BASH_REMATCH[2]} #TS missing packets
((missingPackets += packets))
fi
elif [[ "$i" == *bitrate_monitor:* ]]
then
: #...
fi
doneΕκτός από το γεγονός ότι αυτό λειτουργεί απαράδεκτα αργά, το bash δεν έχει κανονικά νήματα, οι εργασίες bash είναι ανεξάρτητες διεργασίες και έπρεπε να καταγράψω την τιμή missingPackets μία φορά το δευτερόλεπτο ως παρενέργεια (όταν λαμβάνω ένα μήνυμα bitrate, που έρχεται κάθε δευτερόλεπτο). Ως αποτέλεσμα, ο bash έμεινε μόνος του και αποφασίστηκε να γραφτεί ένα περιτύλιγμα (parser + aggregator) σε golang. Η κατανάλωση CPU παρόμοιου κώδικα στο golang είναι 4-5 φορές μικρότερη από αυτή της ίδιας της διαδικασίας tsp. Η επιτάχυνση του περιτυλίγματος με την αντικατάσταση του bash με το golang ήταν περίπου 16 φορές και συνολικά το αποτέλεσμα είναι αποδεκτό (επιβάρυνση της CPU κατά 25% στη χειρότερη περίπτωση). Το αρχείο προέλευσης στο golang βρίσκεται .
Εκκίνηση του περιτυλίγματος
Για την εκκίνηση του περιτυλίγματος, δημιουργήθηκε ένα απλό πρότυπο υπηρεσίας για το systemd (). Το ίδιο το περιτύλιγμα θεωρείται ότι έχει μεταγλωττιστεί σε ένα δυαδικό αρχείο (go build tsduck-stat.go) που βρίσκεται στο /opt/tsduck-stat/. Υποτίθεται ότι χρησιμοποιείται golang με υποστήριξη μονοτονικού ρολογιού (>=1.9).
Για να δημιουργήσετε μια παρουσία της υπηρεσίας, πρέπει να εκτελέσετε την εντολή systemctl enable tsduck-stat@239.0.0.1:1234 και, στη συνέχεια, να την εκκινήσετε χρησιμοποιώντας την εντολή systemctl start tsduck-stat@239.0.0.1:1234.
Ανακάλυψη από το Zabbix
Για να μπορέσει το zabbix να πραγματοποιεί εντοπισμό εκτελούμενων υπηρεσιών, έγιναν τα εξής: (discovery.sh), στη μορφή που απαιτείται για την ανακάλυψη Zabbix, θεωρείται ότι βρίσκεται στο ίδιο μέρος - στο /opt/tsduck-stat. Για να εκτελέσετε το Discovery μέσω zabbix-agent, πρέπει να προσθέσετε στον κατάλογο με διαμορφώσεις zabbix-agent για να προσθέσετε την παράμετρο χρήστη.
Πρότυπο Zabbix
(tsduck_stat_template.xml) περιέχει τον κανόνα αυτόματης ανακάλυψης, πρωτότυπα στοιχείων δεδομένων, γραφήματα και ενεργοποιητές.
Μια σύντομη λίστα ελέγχου (ακριβώς σε περίπτωση που κάποιος αποφασίσει να τη χρησιμοποιήσει)
- Βεβαιωθείτε ότι το tsp δεν ρίχνει πακέτα σε "ιδανικές" συνθήκες (η γεννήτρια και ο αναλυτής συνδέονται απευθείας), εάν υπάρχουν πτώσεις, δείτε το σημείο 2 ή το κείμενο του άρθρου σχετικά με αυτό το θέμα.
- Εκτελέστε συντονισμό του μέγιστου buffer υποδοχής (net.core.rmem_max=8388608).
- Μεταγλώττιση tsduck-stat.go (πηγαίνετε να δημιουργήσετε tsduck-stat.go).
- Τοποθετήστε το πρότυπο υπηρεσίας στο /lib/systemd/system.
- Ξεκινήστε τις υπηρεσίες χρησιμοποιώντας το systemctl, ελέγξτε ότι έχουν αρχίσει να εμφανίζονται μετρητές (grep "" /dev/shm/tsduck-stat/*). Αριθμός υπηρεσιών ανά αριθμό ροών πολλαπλής διανομής. Εδώ μπορεί να χρειαστεί να δημιουργήσετε μια διαδρομή σε μια ομάδα πολλαπλής διανομής, ίσως να απενεργοποιήσετε το rp_filter ή να δημιουργήσετε μια διαδρομή προς την πηγή ip.
- Εκτελέστε το discovery.sh, βεβαιωθείτε ότι δημιουργεί json.
- Επισυνάψτε το zabbix agent config, επανεκκινήστε τον zabbix agent.
- Φορτώστε το πρότυπο στο zabbix, εφαρμόστε το στον κεντρικό υπολογιστή όπου εκτελείται η παρακολούθηση και έχει εγκατασταθεί το zabbix-agent, περιμένετε περίπου 5 λεπτά, δείτε ότι έχουν εμφανιστεί νέα στοιχεία δεδομένων, γραφήματα και ενεργοποιητές.
Αποτέλεσμα
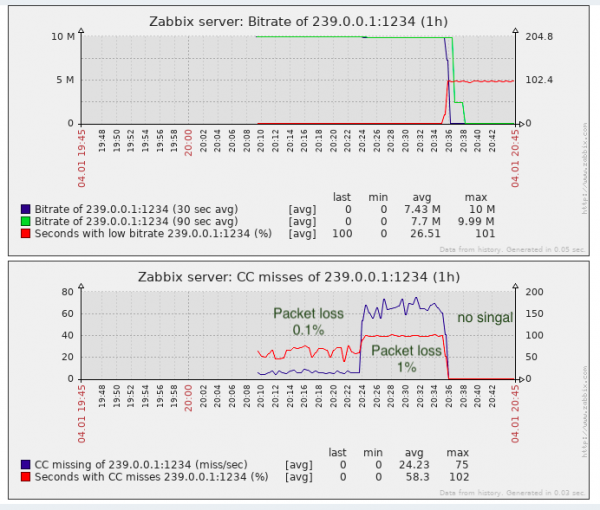
Για την ανίχνευση απώλειας πακέτων είναι σχεδόν αρκετό, τουλάχιστον είναι καλύτερο από την απουσία παρακολούθησης.
Στην πραγματικότητα, μπορεί να προκύψουν "απώλειες" CC όταν κολληθούν θραύσματα βίντεο (από όσο γνωρίζω, έτσι γίνονται τα ένθετα σε τοπικά τηλεοπτικά κέντρα στη Ρωσική Ομοσπονδία, δηλαδή χωρίς επανυπολογισμό του μετρητή CC), αυτό πρέπει να το θυμόμαστε. Σε ιδιόκτητες λύσεις, αυτό το πρόβλημα παρακάμπτεται εν μέρει με την ανίχνευση ετικετών SCTE-35 (εάν προστεθούν από τη γεννήτρια ροής).
Όσον αφορά την παρακολούθηση της ποιότητας της μεταφοράς, λείπει η παρακολούθηση jitter (IAT), επειδή ο εξοπλισμός τηλεόρασης (είτε διαμορφωτές είτε τελικές συσκευές) έχει απαιτήσεις για αυτήν την παράμετρο και δεν είναι πάντα δυνατό να διογκωθεί το jitbuffer στο άπειρο. Και το jitter μπορεί να επιπλέει όταν χρησιμοποιείται εξοπλισμός με μεγάλα buffer κατά τη μεταφορά και το QoS δεν έχει ρυθμιστεί ή δεν έχει ρυθμιστεί αρκετά καλά για τη μετάδοση τέτοιας κίνησης σε πραγματικό χρόνο.
Πηγή: www.habr.com
