

Σημείωση. μετάφρ.: Αυτό το άρθρο, γραμμένο από τον Galo Navarro, ο οποίος κατέχει τη θέση του Κύριου Μηχανικού Λογισμικού στην ευρωπαϊκή εταιρεία Adevinta, είναι μια συναρπαστική και διδακτική «έρευνα» στον τομέα των λειτουργιών υποδομής. Ο αρχικός τίτλος του επεκτάθηκε ελαφρώς στη μετάφραση για έναν λόγο που εξηγεί ο συγγραφέας στην αρχή.
Σημείωση από τον συγγραφέα: Μοιάζει με αυτήν την ανάρτηση πολύ περισσότερη προσοχή από την αναμενόμενη. Εξακολουθώ να έχω θυμωμένα σχόλια ότι ο τίτλος του άρθρου είναι παραπλανητικός και ότι κάποιοι αναγνώστες στεναχωριούνται. Κατανοώ τους λόγους για αυτό που συμβαίνει, επομένως, παρά τον κίνδυνο να καταστρέψω την όλη ίντριγκα, θέλω να σας πω αμέσως περί τίνος πρόκειται για αυτό το άρθρο. Ένα περίεργο πράγμα που έχω δει καθώς οι ομάδες μεταναστεύουν στο Kubernetes είναι ότι κάθε φορά που προκύπτει ένα πρόβλημα (όπως αυξημένη καθυστέρηση μετά από μια μετεγκατάσταση), το πρώτο πράγμα που κατηγορείται είναι το Kubernetes, αλλά στη συνέχεια αποδεικνύεται ότι ο ενορχηστρωτής δεν είναι πραγματικά κατηγορώ. Αυτό το άρθρο μιλάει για μια τέτοια περίπτωση. Το όνομά του επαναλαμβάνει το επιφώνημα ενός από τους προγραμματιστές μας (αργότερα θα δείτε ότι το Kubernetes δεν έχει καμία σχέση με αυτό). Δεν θα βρείτε καμία εκπληκτική αποκάλυψη για το Kubernetes εδώ, αλλά μπορείτε να περιμένετε μερικά καλά μαθήματα για πολύπλοκα συστήματα.
Πριν από μερικές εβδομάδες, η ομάδα μου μετέφερε μια ενιαία microservice σε μια βασική πλατφόρμα που περιελάμβανε CI/CD, χρόνο εκτέλεσης βασισμένο στο Kubernetes, μετρήσεις και άλλα καλούδια. Η κίνηση ήταν δοκιμαστικής φύσης: σχεδιάζαμε να τη λάβουμε ως βάση και να μεταφέρουμε περίπου 150 επιπλέον υπηρεσίες τους επόμενους μήνες. Όλοι τους είναι υπεύθυνοι για τη λειτουργία ορισμένων από τις μεγαλύτερες διαδικτυακές πλατφόρμες στην Ισπανία (Infojobs, Fotocasa κ.λπ.).
Αφού αναπτύξαμε την εφαρμογή στο Kubernetes και ανακατευθύναμε κάποια κίνηση σε αυτήν, μας περίμενε μια ανησυχητική έκπληξη. Καθυστέρηση (αφάνεια) Τα αιτήματα στο Kubernetes ήταν 10 φορές υψηλότερα από ό,τι στο EC2. Γενικά, ήταν απαραίτητο είτε να βρεθεί μια λύση σε αυτό το πρόβλημα είτε να εγκαταλειφθεί η μετανάστευση της microservice (και, ενδεχομένως, ολόκληρου του έργου).
Γιατί η καθυστέρηση είναι τόσο μεγαλύτερη στο Kubernetes από ότι στο EC2;
Για να βρούμε το σημείο συμφόρησης, συλλέξαμε μετρήσεις σε ολόκληρη τη διαδρομή αιτήματος. Η αρχιτεκτονική μας είναι απλή: μια πύλη API (Zuul) εκτελεί αιτήματα μεσολάβησης σε παρουσίες microservice στο EC2 ή το Kubernetes. Στο Kubernetes χρησιμοποιούμε NGINX Ingress Controller και τα backends είναι συνηθισμένα αντικείμενα όπως με μια εφαρμογή JVM στην πλατφόρμα Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Το πρόβλημα φαινόταν να σχετίζεται με τον αρχικό λανθάνοντα χρόνο στο backend (σημείωσα την προβληματική περιοχή στο γράφημα ως "xx"). Στο EC2, η απόκριση της εφαρμογής χρειάστηκε περίπου 20 ms. Στο Kubernetes, η καθυστέρηση αυξήθηκε στα 100-200 ms.
Απορρίψαμε γρήγορα τους πιθανούς ύποπτους που σχετίζονται με την αλλαγή χρόνου εκτέλεσης. Η έκδοση JVM παραμένει η ίδια. Τα προβλήματα μεταφοράς εμπορευματοκιβωτίων επίσης δεν είχαν καμία σχέση με αυτό: η εφαρμογή εκτελούσε ήδη με επιτυχία σε κοντέινερ στο EC2. Φόρτωση? Αλλά παρατηρήσαμε υψηλές καθυστερήσεις ακόμη και με 1 αίτημα ανά δευτερόλεπτο. Οι παύσεις για τη συλλογή απορριμμάτων θα μπορούσαν επίσης να παραμεληθούν.
Ένας από τους διαχειριστές του Kubernetes αναρωτήθηκε αν η εφαρμογή είχε εξωτερικές εξαρτήσεις επειδή τα ερωτήματα DNS είχαν προκαλέσει παρόμοια προβλήματα στο παρελθόν.
Υπόθεση 1: Ανάλυση ονόματος DNS
Για κάθε αίτημα, η εφαρμογή μας έχει πρόσβαση σε μια παρουσία AWS Elasticsearch μία έως τρεις φορές σε έναν τομέα όπως elastic.spain.adevinta.com. Μέσα στα δοχεία μας , ώστε να μπορούμε να ελέγξουμε αν η αναζήτηση για έναν τομέα διαρκεί πραγματικά πολύ.
Ερωτήματα DNS από κοντέινερ:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecΠαρόμοια αιτήματα από μία από τις περιπτώσεις EC2 όπου εκτελείται η εφαρμογή:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecΛαμβάνοντας υπόψη ότι η αναζήτηση διήρκεσε περίπου 30 ms, έγινε σαφές ότι η ανάλυση DNS κατά την πρόσβαση στο Elasticsearch συνέβαλε πράγματι στην αύξηση του λανθάνοντος χρόνου.
Ωστόσο, αυτό ήταν περίεργο για δύο λόγους:
- Έχουμε ήδη έναν τόνο εφαρμογών Kubernetes που αλληλεπιδρούν με πόρους AWS χωρίς να υποφέρουν από υψηλή καθυστέρηση. Όποιος και αν είναι ο λόγος, σχετίζεται συγκεκριμένα με αυτή την υπόθεση.
- Γνωρίζουμε ότι το JVM κάνει προσωρινή αποθήκευση DNS στη μνήμη. Στις εικόνες μας, η τιμή TTL είναι γραμμένη
$JAVA_HOME/jre/lib/security/java.securityκαι ορίστε σε 10 δευτερόλεπτα:networkaddress.cache.ttl = 10. Με άλλα λόγια, το JVM θα πρέπει να αποθηκεύει προσωρινά όλα τα ερωτήματα DNS για 10 δευτερόλεπτα.
Για να επιβεβαιώσουμε την πρώτη υπόθεση, αποφασίσαμε να σταματήσουμε να καλούμε DNS για λίγο και να δούμε αν το πρόβλημα εξαφανίστηκε. Αρχικά, αποφασίσαμε να διαμορφώσουμε εκ νέου την εφαρμογή έτσι ώστε να επικοινωνεί απευθείας με το Elasticsearch μέσω διεύθυνσης IP και όχι μέσω ονόματος τομέα. Αυτό θα απαιτούσε αλλαγές κώδικα και μια νέα ανάπτυξη, επομένως απλώς αντιστοιχίσαμε τον τομέα στη διεύθυνση IP του /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comΤώρα το κοντέινερ έλαβε μια IP σχεδόν αμέσως. Αυτό είχε ως αποτέλεσμα κάποια βελτίωση, αλλά ήμασταν μόνο ελαφρώς πιο κοντά στα αναμενόμενα επίπεδα καθυστέρησης. Παρόλο που η ανάλυση DNS πήρε πολύ χρόνο, ο πραγματικός λόγος εξακολουθεί να μας διαφεύγει.
Διαγνωστικά μέσω δικτύου
Αποφασίσαμε να αναλύσουμε την κίνηση από το κοντέινερ χρησιμοποιώντας tcpdumpγια να δείτε τι ακριβώς συμβαίνει στο δίκτυο:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Στη συνέχεια στείλαμε πολλά αιτήματα και κατεβάσαμε τη λήψη τους (kubectl cp my-service:/capture.pcap capture.pcap) για περαιτέρω ανάλυση στο .
Δεν υπήρχε τίποτα ύποπτο σχετικά με τα ερωτήματα DNS (εκτός από ένα μικρό πράγμα για το οποίο θα μιλήσω αργότερα). Αλλά υπήρχαν ορισμένες παραξενιές στον τρόπο με τον οποίο η υπηρεσία μας χειρίστηκε κάθε αίτημα. Ακολουθεί ένα στιγμιότυπο οθόνης της λήψης που δείχνει το αίτημα να γίνεται αποδεκτό πριν ξεκινήσει η απάντηση:
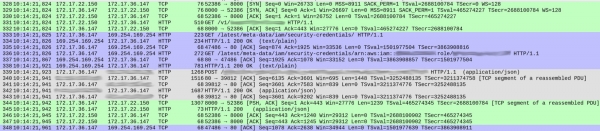
Οι αριθμοί πακέτων εμφανίζονται στην πρώτη στήλη. Για λόγους σαφήνειας, έχω κωδικοποιήσει τις διαφορετικές ροές TCP.
Η πράσινη ροή που ξεκινά με το πακέτο 328 δείχνει πώς ο πελάτης (172.17.22.150) δημιούργησε μια σύνδεση TCP με το κοντέινερ (172.17.36.147). Μετά την αρχική χειραψία (328-330), έφερε το πακέτο 331 HTTP GET /v1/.. — ένα εισερχόμενο αίτημα στην υπηρεσία μας. Η όλη διαδικασία κράτησε 1 ms.
Η γκρι ροή (από το πακέτο 339) δείχνει ότι η υπηρεσία μας έστειλε ένα αίτημα HTTP στην παρουσία του Elasticsearch (δεν υπάρχει χειραψία TCP επειδή χρησιμοποιεί μια υπάρχουσα σύνδεση). Αυτό χρειάστηκε 18 ms.
Μέχρι στιγμής όλα είναι καλά και οι χρόνοι αντιστοιχούν κατά προσέγγιση στις αναμενόμενες καθυστερήσεις (20-30 ms όταν μετρώνται από τον πελάτη).
Ωστόσο, το μπλε τμήμα διαρκεί 86 ms. Τι συμβαίνει σε αυτό; Με το πακέτο 333, η υπηρεσία μας έστειλε ένα αίτημα HTTP GET στο /latest/meta-data/iam/security-credentialsκαι αμέσως μετά, μέσω της ίδιας σύνδεσης TCP, ένα άλλο αίτημα GET προς /latest/meta-data/iam/security-credentials/arn:...
Βρήκαμε ότι αυτό επαναλαμβανόταν με κάθε αίτημα σε όλο το ίχνος. Η ανάλυση DNS είναι πράγματι λίγο πιο αργή στα κοντέινερ μας (η εξήγηση για αυτό το φαινόμενο είναι αρκετά ενδιαφέρουσα, αλλά θα την αποθηκεύσω για ξεχωριστό άρθρο). Αποδείχθηκε ότι η αιτία των μεγάλων καθυστερήσεων ήταν οι κλήσεις προς την υπηρεσία Μεταδεδομένων παρουσίας AWS για κάθε αίτημα.
Υπόθεση 2: περιττές κλήσεις σε AWS
Και τα δύο τελικά σημεία ανήκουν . Η μικρουπηρεσία μας χρησιμοποιεί αυτήν την υπηρεσία ενώ εκτελεί το Elasticsearch. Και οι δύο κλήσεις αποτελούν μέρος της βασικής διαδικασίας εξουσιοδότησης. Το τελικό σημείο στο οποίο προσεγγίζεται το πρώτο αίτημα εκδίδει τον ρόλο IAM που σχετίζεται με την παρουσία.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleΤο δεύτερο αίτημα ζητά από το δεύτερο τελικό σημείο προσωρινές άδειες για αυτήν την περίπτωση:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Ο πελάτης μπορεί να τα χρησιμοποιήσει για σύντομο χρονικό διάστημα και πρέπει να αποκτά περιοδικά νέα πιστοποιητικά (πριν αυτά γίνουν Expiration). Το μοντέλο είναι απλό: το AWS περιστρέφει συχνά τα προσωρινά κλειδιά για λόγους ασφαλείας, αλλά οι πελάτες μπορούν να τα αποθηκεύσουν προσωρινά για λίγα λεπτά για να αντισταθμίσουν την ποινή απόδοσης που σχετίζεται με την απόκτηση νέων πιστοποιητικών.
Το AWS Java SDK θα πρέπει να αναλάβει την ευθύνη για την οργάνωση αυτής της διαδικασίας, αλλά για κάποιο λόγο αυτό δεν συμβαίνει.
Μετά από αναζήτηση προβλημάτων στο GitHub, συναντήσαμε ένα πρόβλημα . Μας βοήθησε να προσδιορίσουμε την κατεύθυνση προς την οποία θα «σκάψουμε» περαιτέρω.
Το AWS SDK ενημερώνει τα πιστοποιητικά όταν προκύπτει μία από τις ακόλουθες συνθήκες:
- Ημερομηνία λήξης (
Expiration) Πέφτω μέσαEXPIRATION_THRESHOLD, κωδικοποιημένο σε 15 λεπτά. - Έχει περάσει περισσότερος χρόνος από την τελευταία προσπάθεια ανανέωσης πιστοποιητικών παρά
REFRESH_THRESHOLD, κωδικοποιημένο για 60 λεπτά.
Για να δούμε την πραγματική ημερομηνία λήξης των πιστοποιητικών που λαμβάνουμε, εκτελέσαμε τις παραπάνω εντολές cURL τόσο από το κοντέινερ όσο και από την παρουσία EC2. Η περίοδος ισχύος του πιστοποιητικού που ελήφθη από το κοντέινερ αποδείχθηκε πολύ μικρότερη: ακριβώς 15 λεπτά.
Τώρα όλα έχουν γίνει ξεκάθαρα: για το πρώτο αίτημα, η υπηρεσία μας έλαβε προσωρινά πιστοποιητικά. Δεδομένου ότι δεν ήταν έγκυρα για περισσότερα από 15 λεπτά, το AWS SDK θα αποφάσιζε να τα ενημερώσει σε επόμενο αίτημα. Και αυτό συνέβαινε με κάθε αίτημα.
Γιατί έχει μειωθεί η περίοδος ισχύος των πιστοποιητικών;
Το AWS Instance Metadata έχει σχεδιαστεί για να λειτουργεί με παρουσίες EC2, όχι με Kubernetes. Από την άλλη πλευρά, δεν θέλαμε να αλλάξουμε τη διεπαφή της εφαρμογής. Για αυτό χρησιμοποιήσαμε - ένα εργαλείο που, χρησιμοποιώντας πράκτορες σε κάθε κόμβο Kubernetes, επιτρέπει στους χρήστες (μηχανικούς που αναπτύσσουν εφαρμογές σε ένα σύμπλεγμα) να εκχωρούν ρόλους IAM σε κοντέινερ σε pods σαν να ήταν στιγμιότυπα EC2. Το KIAM παρακολουθεί κλήσεις προς την υπηρεσία Μεταδεδομένων Στιγμιότυπου AWS και τις επεξεργάζεται από την κρυφή μνήμη του, έχοντας προηγουμένως λάβει από το AWS. Από πλευράς εφαρμογής δεν αλλάζει τίποτα.
Η KIAM παρέχει βραχυπρόθεσμα πιστοποιητικά σε pods. Αυτό είναι λογικό λαμβάνοντας υπόψη ότι η μέση διάρκεια ζωής ενός λοβού είναι μικρότερη από αυτή μιας παρουσίας EC2. Προεπιλεγμένη περίοδος ισχύος για πιστοποιητικά .
Ως αποτέλεσμα, εάν επικαλύψετε και τις δύο προεπιλεγμένες τιμές η μία πάνω στην άλλη, προκύπτει πρόβλημα. Κάθε πιστοποιητικό που παρέχεται σε μια εφαρμογή λήγει μετά από 15 λεπτά. Ωστόσο, το AWS Java SDK αναγκάζει την ανανέωση οποιουδήποτε πιστοποιητικού έχει λιγότερο από 15 λεπτά πριν από την ημερομηνία λήξης του.
Ως αποτέλεσμα, το προσωρινό πιστοποιητικό αναγκάζεται να ανανεώνεται με κάθε αίτημα, κάτι που συνεπάγεται μερικές κλήσεις στο API AWS και προκαλεί σημαντική αύξηση του λανθάνοντος χρόνου. Στο AWS Java SDK βρήκαμε , που αναφέρει παρόμοιο πρόβλημα.
Η λύση αποδείχθηκε απλή. Απλώς αναδιαμορφώσαμε το KIAM ώστε να ζητά πιστοποιητικά με μεγαλύτερη περίοδο ισχύος. Μόλις συνέβη αυτό, τα αιτήματα άρχισαν να ρέουν χωρίς τη συμμετοχή της υπηρεσίας Μεταδεδομένων AWS και η καθυστέρηση έπεσε σε ακόμη χαμηλότερα επίπεδα από ό,τι στο EC2.
Ευρήματα
Με βάση την εμπειρία μας με τις μετεγκαταστάσεις, μία από τις πιο κοινές πηγές προβλημάτων δεν είναι σφάλματα στο Kubernetes ή άλλα στοιχεία της πλατφόρμας. Επίσης, δεν αντιμετωπίζει θεμελιώδεις ατέλειες στις μικροϋπηρεσίες που μεταφέρουμε. Τα προβλήματα συχνά προκύπτουν απλώς και μόνο επειδή βάζουμε διαφορετικά στοιχεία μαζί.
Αναμιγνύουμε πολύπλοκα συστήματα που δεν έχουν ποτέ αλληλεπιδράσει μεταξύ τους, περιμένοντας ότι μαζί θα σχηματίσουν ένα ενιαίο, μεγαλύτερο σύστημα. Αλίμονο, όσο περισσότερα στοιχεία, τόσο περισσότερο χώρο για λάθη, τόσο μεγαλύτερη είναι η εντροπία.
Στην περίπτωσή μας, η υψηλή καθυστέρηση δεν ήταν αποτέλεσμα σφαλμάτων ή κακών αποφάσεων στο Kubernetes, το KIAM, το AWS Java SDK ή τη μικρουπηρεσία μας. Ήταν το αποτέλεσμα του συνδυασμού δύο ανεξάρτητων προεπιλεγμένων ρυθμίσεων: η μία στο KIAM, η άλλη στο AWS Java SDK. Λαμβάνοντας ξεχωριστά, και οι δύο παράμετροι έχουν νόημα: η ενεργή πολιτική ανανέωσης πιστοποιητικού στο AWS Java SDK και η σύντομη περίοδος ισχύος των πιστοποιητικών στο KAIM. Αλλά όταν τα συνδυάζεις, τα αποτελέσματα γίνονται απρόβλεπτα. Δύο ανεξάρτητες και λογικές λύσεις δεν χρειάζεται να έχουν νόημα όταν συνδυάζονται.
ΥΓ από τον μεταφραστή
Μπορείτε να μάθετε περισσότερα σχετικά με την αρχιτεκτονική του βοηθητικού προγράμματος KIAM για την ενοποίηση του AWS IAM με το Kubernetes στο από τους δημιουργούς του.
Διαβάστε επίσης στο blog μας:
- «"?
- «"?
- «"?
- «».
Πηγή: www.habr.com
