

Θα ήθελα να μοιραστώ μαζί σας την πρώτη μου επιτυχημένη εμπειρία επαναφοράς μιας βάσης δεδομένων Postgres σε πλήρη λειτουργικότητα. Γνώρισα το Postgres DBMS πριν από μισό χρόνο· πριν από αυτό δεν είχα καθόλου εμπειρία στη διαχείριση βάσεων δεδομένων.

Εργάζομαι ως μηχανικός semi-DevOps σε μια μεγάλη εταιρεία πληροφορικής. Η εταιρεία μας αναπτύσσει λογισμικό για υπηρεσίες υψηλού φορτίου και είμαι υπεύθυνος για την απόδοση, τη συντήρηση και την ανάπτυξη. Μου δόθηκε μια τυπική εργασία: να ενημερώσω μια εφαρμογή σε έναν διακομιστή. Η εφαρμογή είναι γραμμένη σε Django, κατά τη διάρκεια της ενημέρωσης πραγματοποιούνται μετεγκαταστάσεις (αλλαγές στη δομή της βάσης δεδομένων) και πριν από αυτή τη διαδικασία κάνουμε μια πλήρη ένδειξη δεδομένων μέσω του τυπικού προγράμματος pg_dump, για κάθε ενδεχόμενο.
Παρουσιάστηκε απροσδόκητο σφάλμα κατά τη λήψη μιας ένδειξης (έκδοση Postgres 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly Ошибка "μη έγκυρη σελίδα στο μπλοκ" μιλά για προβλήματα σε επίπεδο συστήματος αρχείων, κάτι που είναι πολύ κακό. Σε διάφορα φόρουμ προτάθηκε να γίνει ΠΛΗΡΕΣ ΚΕΝΟ με επιλογή zero_damaged_pages να λύσει αυτό το πρόβλημα. Λοιπόν, ας προσπαθήσουμε…
Προετοιμασία για ανάκαμψη
ΠΡΟΣΟΧΗ! Φροντίστε να δημιουργήσετε αντίγραφο ασφαλείας του Postgres πριν από οποιαδήποτε προσπάθεια επαναφοράς της βάσης δεδομένων σας. Εάν διαθέτετε εικονική μηχανή, σταματήστε τη βάση δεδομένων και τραβήξτε ένα στιγμιότυπο. Εάν δεν είναι δυνατό να τραβήξετε ένα στιγμιότυπο, σταματήστε τη βάση δεδομένων και αντιγράψτε τα περιεχόμενα του καταλόγου Postgres (συμπεριλαμβανομένων των αρχείων wal) σε ασφαλές μέρος. Το κύριο πράγμα στην επιχείρησή μας είναι να μην κάνουμε τα πράγματα χειρότερα. Ανάγνωση .
Δεδομένου ότι η βάση δεδομένων γενικά λειτούργησε για μένα, περιορίστηκα σε μια κανονική απόδειξη βάσης δεδομένων, αλλά απέκλεισα τον πίνακα με κατεστραμμένα δεδομένα (επιλογή -T, --exclude-table=TABLE στο pg_dump).
Ο διακομιστής ήταν φυσικός, ήταν αδύνατο να τραβήξετε ένα στιγμιότυπο. Το αντίγραφο ασφαλείας έχει αφαιρεθεί, ας προχωρήσουμε.
Έλεγχος συστήματος αρχείων
Πριν επιχειρήσουμε να επαναφέρουμε τη βάση δεδομένων, πρέπει να βεβαιωθούμε ότι όλα είναι εντάξει με το ίδιο το σύστημα αρχείων. Και σε περίπτωση λαθών, διορθώστε τα, γιατί αλλιώς μόνο χειρότερα μπορείτε να κάνετε τα πράγματα.
Στην περίπτωσή μου, το σύστημα αρχείων με τη βάση δεδομένων ήταν προσαρτημένο "/srv" και ο τύπος ήταν ext4.
Διακοπή της βάσης δεδομένων: systemctl stop postgresql@9.5-main.service και ελέγξτε ότι το σύστημα αρχείων δεν χρησιμοποιείται από κανέναν και ότι μπορεί να αποπροσαρτηθεί χρησιμοποιώντας την εντολή lsof:
lsof +D /srv
Έπρεπε επίσης να σταματήσω τη βάση δεδομένων redis, μιας και χρησιμοποιούσε επίσης "/srv". Στη συνέχεια αποπροσαρτήθηκα / srv (ποσό).
Το σύστημα αρχείων ελέγχθηκε χρησιμοποιώντας το βοηθητικό πρόγραμμα e2fsck με το διακόπτη -f (Αναγκαστικός έλεγχος ακόμη και αν το σύστημα αρχείων έχει επισημανθεί ως καθαρό):
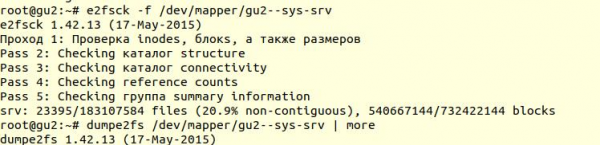
Στη συνέχεια, χρησιμοποιώντας το βοηθητικό πρόγραμμα dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep ελεγμένο) μπορείτε να επαληθεύσετε ότι ο έλεγχος πραγματοποιήθηκε πραγματικά:

e2fsck λέει ότι δεν βρέθηκαν προβλήματα σε επίπεδο συστήματος αρχείων ext4, πράγμα που σημαίνει ότι μπορείτε να συνεχίσετε να προσπαθείτε να επαναφέρετε τη βάση δεδομένων ή μάλλον να επιστρέψετε στο κενό γεμάτο (φυσικά, πρέπει να προσαρτήσετε ξανά το σύστημα αρχείων και να ξεκινήσετε τη βάση δεδομένων).
Εάν διαθέτετε φυσικό διακομιστή, φροντίστε να ελέγξετε την κατάσταση των δίσκων (μέσω smartctl -a /dev/XXX) ή ελεγκτή RAID για να βεβαιωθείτε ότι το πρόβλημα δεν είναι σε επίπεδο υλικού. Στην περίπτωσή μου, το RAID αποδείχθηκε "υλικό", οπότε ζήτησα από τον τοπικό διαχειριστή να ελέγξει την κατάσταση του RAID (ο διακομιστής ήταν αρκετές εκατοντάδες χιλιόμετρα μακριά μου). Είπε ότι δεν υπήρχαν σφάλματα, πράγμα που σημαίνει ότι μπορούμε σίγουρα να ξεκινήσουμε την αποκατάσταση.
Προσπάθεια 1: zero_damaged_pages
Συνδεόμαστε στη βάση δεδομένων μέσω psql με έναν λογαριασμό που έχει δικαιώματα υπερχρήστη. Χρειαζόμαστε έναν υπερχρήστη, γιατί... επιλογή zero_damaged_pages μόνο αυτός μπορεί να αλλάξει. Στην περίπτωσή μου είναι postgres:
psql -h 127.0.0.1 -U postgres -s [όνομα_βάσης δεδομένων]
Επιλογή zero_damaged_pages απαιτείται για να αγνοηθούν τα σφάλματα ανάγνωσης (από τον ιστότοπο postgrespro):
Όταν η PostgreSQL εντοπίζει μια κατεστραμμένη κεφαλίδα σελίδας, συνήθως αναφέρει ένα σφάλμα και ματαιώνει την τρέχουσα συναλλαγή. Εάν το zero_damaged_pages είναι ενεργοποιημένο, το σύστημα εκδίδει μια προειδοποίηση, μηδενίζει την κατεστραμμένη σελίδα στη μνήμη και συνεχίζει την επεξεργασία. Αυτή η συμπεριφορά καταστρέφει δεδομένα, δηλαδή όλες τις σειρές στην κατεστραμμένη σελίδα.
Ενεργοποιούμε την επιλογή και προσπαθούμε να κάνουμε ένα πλήρες κενό των πινάκων:
VACUUM FULL VERBOSE 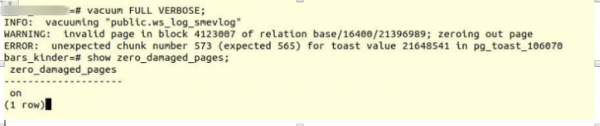
Δυστυχώς, κακή τύχη.
Αντιμετωπίσαμε ένα παρόμοιο σφάλμα:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– ένας μηχανισμός αποθήκευσης «μεγάλων δεδομένων» στο Poetgres εάν δεν χωράει σε μία σελίδα (8 kb από προεπιλογή).
Προσπάθεια 2: αναπροσαρμογή ευρετηρίου
Η πρώτη συμβουλή από την Google δεν βοήθησε. Μετά από λίγα λεπτά αναζήτησης, βρήκα τη δεύτερη συμβουλή - να φτιάξω εκ νέου ευρετήριο κατεστραμμένο τραπέζι. Είδα αυτή τη συμβουλή σε πολλά σημεία, αλλά δεν ενέπνεε εμπιστοσύνη. Ας αναπροσαρμόσουμε το ευρετήριο:
reindex table ws_log_smevlog 
εκ νέου ευρετήριο ολοκληρωθεί χωρίς προβλήματα.
Ωστόσο, αυτό δεν βοήθησε, ΚΕΝΟ ΠΛΗΡΕΣ συνετρίβη με παρόμοιο σφάλμα. Δεδομένου ότι έχω συνηθίσει σε αποτυχίες, άρχισα να ψάχνω περαιτέρω για συμβουλές στο Διαδίκτυο και βρήκα μια αρκετά ενδιαφέρουσα .
Προσπάθεια 3: SELECT, LIMIT, OFFSET
Το παραπάνω άρθρο πρότεινε να δείτε τον πίνακα σειρά προς σειρά και να αφαιρέσετε τα προβληματικά δεδομένα. Πρώτα έπρεπε να δούμε όλες τις γραμμές:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneΣτην περίπτωσή μου, ο πίνακας περιείχε 1 628 991 γραμμές! Ήταν απαραίτητο να φροντίσουμε καλά , αλλά αυτό είναι ένα θέμα για ξεχωριστή συζήτηση. Ήταν Σάββατο, έτρεξα αυτή την εντολή στο tmux και πήγα για ύπνο:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneΜέχρι το πρωί αποφάσισα να ελέγξω πώς πήγαιναν τα πράγματα. Προς έκπληξή μου, ανακάλυψα ότι μετά από 20 ώρες, μόνο το 2% των δεδομένων είχε σαρωθεί! Δεν ήθελα να περιμένω 50 μέρες. Άλλη μια πλήρης αποτυχία.
Αλλά δεν τα παράτησα. Αναρωτήθηκα γιατί η σάρωση κράτησε τόσο πολύ. Από την τεκμηρίωση (πάλι στο postgrespro) ανακάλυψα:
Το OFFSET καθορίζει την παράλειψη του καθορισμένου αριθμού σειρών πριν από την έναρξη της παραγωγής σειρών.
Εάν έχουν καθοριστεί και οι δύο σειρές OFFSET και LIMIT, το σύστημα παραλείπει πρώτα τις σειρές OFFSET και στη συνέχεια αρχίζει να μετράει τις σειρές για τον περιορισμό LIMIT.Όταν χρησιμοποιείτε το LIMIT, είναι σημαντικό να χρησιμοποιείτε επίσης μια ρήτρα ORDER BY, έτσι ώστε οι σειρές αποτελέσματος να επιστρέφονται με συγκεκριμένη σειρά. Διαφορετικά, θα επιστραφούν απρόβλεπτα υποσύνολα σειρών.
Προφανώς, η παραπάνω εντολή ήταν λάθος: πρώτον, δεν υπήρχε παραγγελία από, το αποτέλεσμα μπορεί να είναι λανθασμένο. Δεύτερον, η Postgres έπρεπε πρώτα να σαρώσει και να παρακάμψει σειρές OFFSET, και με την αύξηση OFFSET η παραγωγικότητα θα μειωνόταν ακόμη περισσότερο.
Προσπάθεια 4: πάρτε μια ένδειξη σε μορφή κειμένου
Τότε μου ήρθε στο μυαλό μια φαινομενικά λαμπρή ιδέα: κάντε μια χωματερή σε μορφή κειμένου και αναλύστε την τελευταία ηχογραφημένη γραμμή.
Αλλά πρώτα, ας ρίξουμε μια ματιά στη δομή του πίνακα. ws_log_smevlog:
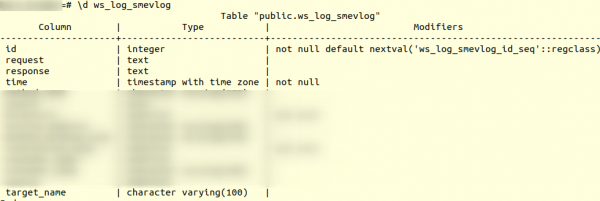
Στην περίπτωσή μας έχουμε μια στήλη "Ταυτότητα", το οποίο περιείχε το μοναδικό αναγνωριστικό (μετρητή) της σειράς. Το σχέδιο είχε ως εξής:
- Αρχίζουμε να κάνουμε ένα dump σε μορφή κειμένου (με τη μορφή εντολών sql)
- Σε μια συγκεκριμένη χρονική στιγμή, η ένδειξη θα διακοπεί λόγω σφάλματος, αλλά το αρχείο κειμένου θα εξακολουθούσε να αποθηκευτεί στο δίσκο
- Κοιτάζουμε το τέλος του αρχείου κειμένου, βρίσκουμε έτσι το αναγνωριστικό (id) της τελευταίας γραμμής που αφαιρέθηκε με επιτυχία
Άρχισα να παίρνω μια χωματερή σε μορφή κειμένου:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpΗ χωματερή, όπως αναμενόταν, διακόπηκε με το ίδιο σφάλμα:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Περαιτέρω μέσα ουρά Κοίταξα το τέλος της χωματερής (ουρά -5 ./my_dump.dump) ανακάλυψε ότι το dump διακόπηκε στη γραμμή με id 186 525. "Λοιπόν, το πρόβλημα βρίσκεται στη γραμμή με το αναγνωριστικό 186 526, είναι χαλασμένο και πρέπει να διαγραφεί!" - Σκέφτηκα. Αλλά, κάνοντας ένα ερώτημα στη βάση δεδομένων:
«επιλέξτε * από το ws_log_smevlog όπου id=186529«Αποδείχθηκε ότι όλα ήταν καλά με αυτή τη γραμμή... Σειρές με δείκτες 186 - 530 λειτούργησαν επίσης χωρίς προβλήματα. Μια άλλη «λαμπρή ιδέα» απέτυχε. Αργότερα κατάλαβα γιατί συνέβη αυτό: κατά τη διαγραφή και την αλλαγή δεδομένων από έναν πίνακα, δεν διαγράφονται φυσικά, αλλά επισημαίνονται ως "νεκρές πλειάδες", μετά έρχεται αυτόματη σκούπα και επισημαίνει αυτές τις γραμμές ως διαγραμμένες και επιτρέπει την επαναχρησιμοποίηση αυτών των γραμμών. Για να καταλάβετε, εάν τα δεδομένα στον πίνακα αλλάξουν και το autovacuum είναι ενεργοποιημένο, τότε δεν αποθηκεύονται διαδοχικά.
Προσπάθεια 5: SELECT, FROM, WHERE id=
Οι αποτυχίες μας κάνουν πιο δυνατούς. Δεν πρέπει ποτέ να τα παρατάτε, πρέπει να πάτε μέχρι το τέλος και να πιστέψετε στον εαυτό σας και τις δυνατότητές σας. Έτσι αποφάσισα να δοκιμάσω μια άλλη επιλογή: απλώς κοιτάξτε όλες τις εγγραφές στη βάση δεδομένων μία προς μία. Γνωρίζοντας τη δομή του πίνακα μου (δείτε παραπάνω), έχουμε ένα πεδίο αναγνωριστικού που είναι μοναδικό (πρωτεύον κλειδί). Έχουμε 1 σειρές στον πίνακα και id είναι στη σειρά, πράγμα που σημαίνει ότι μπορούμε απλώς να τα περάσουμε ένα προς ένα:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneΕάν κάποιος δεν καταλαβαίνει, η εντολή λειτουργεί ως εξής: σαρώνει τον πίνακα σειρά προς σειρά και στέλνει το stdout στο / dev / null, αλλά εάν η εντολή SELECT αποτύχει, τότε εκτυπώνεται το κείμενο σφάλματος (το stderr αποστέλλεται στην κονσόλα) και εκτυπώνεται μια γραμμή που περιέχει το σφάλμα (χάρη στο ||, που σημαίνει ότι το select είχε προβλήματα (ο κωδικός επιστροφής της εντολής δεν είναι 0)).
Ήμουν τυχερός, είχα δημιουργήσει ευρετήρια στο γήπεδο id:

Αυτό σημαίνει ότι η εύρεση μιας γραμμής με το επιθυμητό αναγνωριστικό δεν χρειάζεται πολύ χρόνο. Θεωρητικά θα έπρεπε να λειτουργεί. Λοιπόν, ας εκτελέσουμε την εντολή μέσα tmux και πάμε για ύπνο.
Μέχρι το πρωί διαπίστωσα ότι είχαν προβληθεί περίπου 90 συμμετοχές, που είναι λίγο πάνω από το 000%. Εξαιρετικό αποτέλεσμα σε σύγκριση με την προηγούμενη μέθοδο (5%)! Αλλά δεν ήθελα να περιμένω 2 μέρες…
Προσπάθεια 6: SELECT, FROM, WHERE id >= και id <
Ο πελάτης είχε έναν εξαιρετικό διακομιστή αφιερωμένο στη βάση δεδομένων: dual-processor Intel Xeon E5-2697 v2, υπήρχαν έως και 48 νήματα στην τοποθεσία μας! Ο φόρτος στον διακομιστή ήταν μέτριος· μπορούσαμε να κατεβάσουμε περίπου 20 νήματα χωρίς κανένα πρόβλημα. Υπήρχε επίσης αρκετή μνήμη RAM: έως και 384 gigabyte!
Επομένως, η εντολή έπρεπε να παραλληλιστεί:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneΕδώ ήταν δυνατό να γράψω ένα όμορφο και κομψό σενάριο, αλλά επέλεξα την ταχύτερη μέθοδο παραλληλοποίησης: χωρίζω χειροκίνητα το εύρος 0-1628991 σε διαστήματα 100 εγγραφών και εκτελούμε χωριστά 000 εντολές της φόρμας:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneΑλλά δεν είναι μόνο αυτό. Θεωρητικά, η σύνδεση σε μια βάση δεδομένων απαιτεί επίσης κάποιο χρόνο και πόρους συστήματος. Η σύνδεση 1 δεν ήταν πολύ έξυπνη, θα συμφωνήσετε. Επομένως, ας ανακτήσουμε 628 σειρές αντί για σύνδεση μία προς μία. Ως αποτέλεσμα, η ομάδα μεταμορφώθηκε σε αυτό:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneΑνοίξτε 16 παράθυρα σε μια συνεδρία tmux και εκτελέστε τις εντολές:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Μια μέρα μετά έλαβα τα πρώτα αποτελέσματα! Δηλαδή (οι τιμές XXX και ZZZ δεν διατηρούνται πλέον):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Αυτό σημαίνει ότι τρεις γραμμές περιέχουν ένα σφάλμα. Τα αναγνωριστικά της πρώτης και της δεύτερης εγγραφής προβλήματος ήταν μεταξύ 829 και 000, τα αναγνωριστικά της τρίτης ήταν μεταξύ 830 και 000. Στη συνέχεια, έπρεπε απλώς να βρούμε την ακριβή τιμή αναγνωριστικού των εγγραφών προβλήματος. Για να το κάνουμε αυτό, εξετάζουμε το εύρος μας με προβληματικές εγγραφές με βήμα 146 και προσδιορίζουμε το αναγνωριστικό:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
χαρούμενο τέλος
Βρήκαμε τις προβληματικές γραμμές. Μπαίνουμε στη βάση δεδομένων μέσω psql και προσπαθούμε να τα διαγράψουμε:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Προς έκπληξή μου, οι καταχωρήσεις διαγράφηκαν χωρίς κανένα πρόβλημα ακόμη και χωρίς την επιλογή zero_damaged_pages.
Μετά συνδέθηκα στη βάση δεδομένων, το έκανα ΚΕΝΟ ΠΛΗΡΕΣ (Νομίζω ότι δεν ήταν απαραίτητο να γίνει αυτό) και τελικά αφαίρεσα με επιτυχία το αντίγραφο ασφαλείας χρησιμοποιώντας pg_dump. Η χωματερή έγινε χωρίς σφάλματα! Το πρόβλημα λύθηκε με τόσο ηλίθιο τρόπο. Η χαρά δεν είχε όρια, μετά από τόσες αποτυχίες καταφέραμε να βρούμε λύση!
Ευχαριστίες και Συμπέρασμα
Έτσι προέκυψε η πρώτη μου εμπειρία επαναφοράς μιας πραγματικής βάσης δεδομένων Postgres. Θα θυμάμαι αυτή την εμπειρία για πολύ καιρό.
Και τέλος, θα ήθελα να ευχαριστήσω την PostgresPro για τη μετάφραση της τεκμηρίωσης στα ρωσικά και για , που βοήθησε πολύ κατά την ανάλυση του προβλήματος.
Πηγή: www.habr.com
