


Πριν από μερικά χρόνια Kubernetes στο επίσημο ιστολόγιο του GitHub. Από τότε, έχει γίνει η τυπική τεχνολογία για την ανάπτυξη υπηρεσιών. Η Kubernetes διαχειρίζεται πλέον ένα σημαντικό μέρος των εσωτερικών και δημόσιων υπηρεσιών. Καθώς τα συμπλέγματά μας μεγάλωσαν και οι απαιτήσεις απόδοσης έγιναν πιο αυστηρές, αρχίσαμε να παρατηρούμε ότι ορισμένες υπηρεσίες στο Kubernetes αντιμετώπιζαν σποραδικά λανθάνουσα κατάσταση που δεν μπορούσε να εξηγηθεί από το φόρτο της ίδιας της εφαρμογής.
Ουσιαστικά, οι εφαρμογές αντιμετωπίζουν φαινομενικά τυχαίο λανθάνοντα χρόνο δικτύου έως και 100 ms ή περισσότερο, με αποτέλεσμα χρονικά όρια ή επαναλήψεις. Οι υπηρεσίες αναμενόταν να είναι σε θέση να ανταποκρίνονται σε αιτήματα πολύ πιο γρήγορα από 100ms. Αλλά αυτό είναι αδύνατο εάν η ίδια η σύνδεση παίρνει τόσο πολύ χρόνο. Ξεχωριστά, παρατηρήσαμε πολύ γρήγορα ερωτήματα MySQL που θα έπρεπε να είχαν διαρκέσει χιλιοστά του δευτερολέπτου και η MySQL ολοκληρώθηκε σε χιλιοστά του δευτερολέπτου, αλλά από την πλευρά της αιτούσας εφαρμογής, η απάντηση χρειάστηκε 100 ms ή περισσότερο.
Αμέσως έγινε σαφές ότι το πρόβλημα παρουσιάστηκε μόνο κατά τη σύνδεση σε έναν κόμβο Kubernetes, ακόμα κι αν η κλήση προερχόταν εκτός του Kubernetes. Ο ευκολότερος τρόπος για να αναπαραχθεί το πρόβλημα είναι σε μια δοκιμή , που εκτελείται από οποιονδήποτε εσωτερικό κεντρικό υπολογιστή, δοκιμάζει την υπηρεσία Kubernetes σε μια συγκεκριμένη θύρα και καταγράφει σποραδικά υψηλή καθυστέρηση. Σε αυτό το άρθρο, θα δούμε πώς μπορέσαμε να εντοπίσουμε την αιτία αυτού του προβλήματος.
Εξάλειψη της περιττής πολυπλοκότητας στην αλυσίδα που οδηγεί σε αποτυχία
Αναπαράγοντας το ίδιο παράδειγμα, θέλαμε να περιορίσουμε την εστίαση του προβλήματος και να αφαιρέσουμε περιττά επίπεδα πολυπλοκότητας. Αρχικά, υπήρχαν πάρα πολλά στοιχεία στη ροή μεταξύ του Vegeta και των λοβών Kubernetes. Για να εντοπίσετε ένα βαθύτερο πρόβλημα δικτύου, πρέπει να αποκλείσετε μερικά από αυτά.
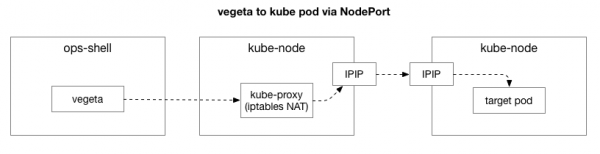
Ο πελάτης (Vegeta) δημιουργεί μια σύνδεση TCP με οποιονδήποτε κόμβο στο σύμπλεγμα. Το Kubernetes λειτουργεί ως δίκτυο επικάλυψης (πάνω από το υπάρχον δίκτυο κέντρων δεδομένων) που χρησιμοποιεί , δηλαδή, ενσωματώνει τα πακέτα IP του δικτύου επικάλυψης μέσα στα πακέτα IP του κέντρου δεδομένων. Κατά τη σύνδεση στον πρώτο κόμβο, εκτελείται μετάφραση διεύθυνσης δικτύου (NAT) κατάσταση για τη μετάφραση της διεύθυνσης IP και της θύρας του κόμβου Kubernetes στη διεύθυνση IP και στη θύρα στο δίκτυο επικάλυψης (συγκεκριμένα, το pod με την εφαρμογή). Για τα εισερχόμενα πακέτα, εκτελείται η αντίστροφη ακολουθία ενεργειών. Είναι ένα πολύπλοκο σύστημα με πολλή κατάσταση και πολλά στοιχεία που ενημερώνονται και αλλάζουν συνεχώς καθώς αναπτύσσονται και μετακινούνται οι υπηρεσίες.
Χρησιμότητα tcpdump στο τεστ Vegeta υπάρχει καθυστέρηση κατά τη χειραψία TCP (μεταξύ SYN και SYN-ACK). Για να αφαιρέσετε αυτήν την περιττή πολυπλοκότητα, μπορείτε να χρησιμοποιήσετε hping3 για απλά «ping» με πακέτα SYN. Ελέγχουμε αν υπάρχει καθυστέρηση στο πακέτο απόκρισης και, στη συνέχεια, επαναφέρουμε τη σύνδεση. Μπορούμε να φιλτράρουμε τα δεδομένα ώστε να περιλαμβάνουν μόνο πακέτα μεγαλύτερα από 100ms και να έχουμε έναν ευκολότερο τρόπο αναπαραγωγής του προβλήματος από τη δοκιμή πλήρους επιπέδου δικτύου 7 στο Vegeta. Ακολουθούν τα "ping" του κόμβου Kubernetes που χρησιμοποιούν TCP SYN/SYN-ACK στην υπηρεσία "node port" (30927) σε διαστήματα 10ms, φιλτραρισμένα με τις πιο αργές αποκρίσεις:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms
Μπορεί να κάνει αμέσως την πρώτη παρατήρηση. Κρίνοντας από τους αριθμούς σειράς και τους χρόνους, είναι σαφές ότι δεν πρόκειται για συμφορήσεις μιας φοράς. Η καθυστέρηση συχνά συσσωρεύεται και τελικά υποβάλλεται σε επεξεργασία.
Στη συνέχεια, θέλουμε να μάθουμε ποια στοιχεία μπορεί να εμπλέκονται στην εμφάνιση συμφόρησης. Ίσως αυτοί είναι μερικοί από τους εκατοντάδες κανόνες iptables στο NAT; Ή υπάρχουν προβλήματα με τη διοχέτευση IPIP στο δίκτυο; Ένας τρόπος για να το ελέγξετε αυτό είναι να δοκιμάσετε κάθε βήμα του συστήματος εξαλείφοντάς το. Τι συμβαίνει εάν καταργήσετε τη λογική NAT και τείχους προστασίας, αφήνοντας μόνο το τμήμα IPIP:
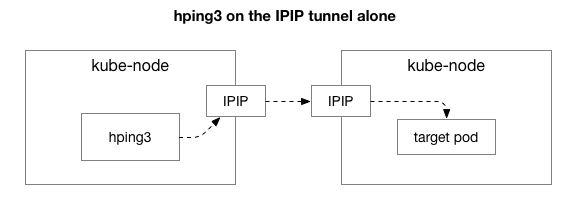
Ευτυχώς, Linux σας επιτρέπει να έχετε εύκολη πρόσβαση στο επίπεδο επικάλυψης IP απευθείας εάν το μηχάνημα βρίσκεται στο ίδιο δίκτυο:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms
Αν κρίνουμε από τα αποτελέσματα, το πρόβλημα παραμένει! Αυτό εξαιρεί τα iptable και το NAT. Δηλαδή το πρόβλημα είναι το TCP; Ας δούμε πώς πάει ένα κανονικό ping ICMP:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Τα αποτελέσματα δείχνουν ότι το πρόβλημα δεν έχει εξαφανιστεί. Ίσως αυτό είναι μια σήραγγα IPIP; Ας απλοποιήσουμε περαιτέρω το τεστ:
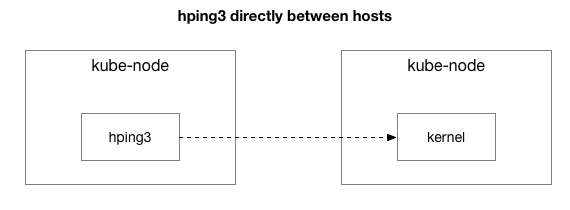
Αποστέλλονται όλα τα πακέτα μεταξύ αυτών των δύο κεντρικών υπολογιστών;
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
Απλοποιήσαμε την κατάσταση σε δύο κόμβους Kubernetes που στέλνουν ο ένας στον άλλο οποιοδήποτε πακέτο, ακόμη και ένα ping ICMP. Εξακολουθούν να βλέπουν καθυστέρηση εάν ο κεντρικός υπολογιστής-στόχος είναι "κακός" (μερικοί χειρότεροι από άλλους).
Τώρα η τελευταία ερώτηση: γιατί η καθυστέρηση εμφανίζεται μόνο σε διακομιστές kube-node; Και συμβαίνει όταν το kube-node είναι ο αποστολέας ή ο παραλήπτης; Ευτυχώς, αυτό είναι επίσης πολύ εύκολο να το καταλάβετε στέλνοντας ένα πακέτο από έναν κεντρικό υπολογιστή εκτός του Kubernetes, αλλά με τον ίδιο «γνωστό κακό» παραλήπτη. Όπως μπορείτε να δείτε, το πρόβλημα δεν έχει εξαφανιστεί:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms
Στη συνέχεια, θα εκτελέσουμε τα ίδια αιτήματα από τον προηγούμενο κόμβο kube πηγής στον εξωτερικό κεντρικό υπολογιστή (ο οποίος αποκλείει τον κεντρικό υπολογιστή προέλευσης, καθώς το ping περιλαμβάνει ένα στοιχείο RX και TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Εξετάζοντας τις συλλήψεις πακέτων με καθυστέρηση, λάβαμε ορισμένες πρόσθετες πληροφορίες. Συγκεκριμένα, ότι ο αποστολέας (κάτω) βλέπει αυτό το χρονικό όριο, αλλά ο παραλήπτης (πάνω) όχι - δείτε τη στήλη Delta (σε δευτερόλεπτα):
Επιπλέον, εάν κοιτάξετε τη διαφορά στη σειρά των πακέτων TCP και ICMP (κατά αριθμούς ακολουθίας) στην πλευρά του παραλήπτη, τα πακέτα ICMP φτάνουν πάντα με την ίδια σειρά με την οποία στάλθηκαν, αλλά με διαφορετικό χρονισμό. Ταυτόχρονα, τα πακέτα TCP μερικές φορές παρεμβάλλονται και μερικά από αυτά κολλάνε. Συγκεκριμένα, αν εξετάσετε τις θύρες των πακέτων SYN, είναι σε σειρά από την πλευρά του αποστολέα, αλλά όχι από την πλευρά του παραλήπτη.
Υπάρχει μια λεπτή διαφορά στο πώς σύγχρονοι διακομιστές (όπως αυτοί στο κέντρο δεδομένων μας) επεξεργάζονται πακέτα που περιέχουν TCP ή ICMP. Όταν φθάνει ένα πακέτο, ο προσαρμογέας δικτύου "το κατακερματίζει ανά σύνδεση", δηλαδή προσπαθεί να σπάσει τις συνδέσεις σε ουρές και να στείλει κάθε ουρά σε έναν ξεχωριστό πυρήνα επεξεργαστή. Για το TCP, αυτός ο κατακερματισμός περιλαμβάνει τη διεύθυνση IP προέλευσης και προορισμού και τη θύρα. Με άλλα λόγια, κάθε σύνδεση κατακερματίζεται (δυνητικά) διαφορετικά. Για το ICMP, μόνο οι διευθύνσεις IP κατακερματίζονται, καθώς δεν υπάρχουν θύρες.
Μια άλλη νέα παρατήρηση: κατά τη διάρκεια αυτής της περιόδου βλέπουμε καθυστερήσεις ICMP σε όλες τις επικοινωνίες μεταξύ δύο κεντρικών υπολογιστών, αλλά το TCP όχι. Αυτό μας λέει ότι η αιτία πιθανότατα σχετίζεται με τον κατακερματισμό της ουράς RX: η συμφόρηση είναι σχεδόν σίγουρα στην επεξεργασία των πακέτων RX, όχι στην αποστολή απαντήσεων.
Αυτό εξαλείφει την αποστολή πακέτων από τη λίστα των πιθανών αιτιών. Τώρα γνωρίζουμε ότι το πρόβλημα επεξεργασίας πακέτων βρίσκεται στην πλευρά λήψης σε ορισμένους διακομιστές κόμβου kube.
Κατανόηση της επεξεργασίας πακέτων στον πυρήνα Linux
Για να κατανοήσουμε γιατί παρουσιάζεται το πρόβλημα στον δέκτη σε ορισμένους διακομιστές kube-node, ας δούμε πώς λειτουργεί ο πυρήνας Linux επεξεργάζεται πακέτα.
Επιστρέφοντας στην απλούστερη παραδοσιακή υλοποίηση, η κάρτα δικτύου λαμβάνει το πακέτο και αποστέλλει πυρήνας Linuxότι υπάρχει ένα πακέτο που πρέπει να υποβληθεί σε επεξεργασία. Ο πυρήνας διακόπτει άλλες εργασίες, αλλάζει το περιβάλλον στον χειριστή διακοπών, επεξεργάζεται το πακέτο και στη συνέχεια επιστρέφει στις τρέχουσες εργασίες.
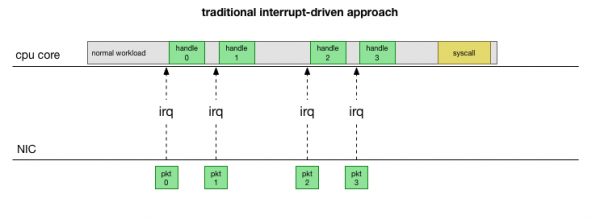
Αυτή η εναλλαγή περιβάλλοντος είναι αργή: η καθυστέρηση μπορεί να μην ήταν αισθητή σε κάρτες δικτύου 10 Mbps στη δεκαετία του '90, αλλά στις σύγχρονες κάρτες 10G με μέγιστη απόδοση 15 εκατομμυρίων πακέτων ανά δευτερόλεπτο, κάθε πυρήνας ενός μικρού διακομιστή οκτώ πυρήνων μπορεί να διακοπεί εκατομμύρια φορές το δευτερόλεπτο.
Για να αποφευχθεί η συνεχής διαχείριση διακοπών, πριν από πολλά χρόνια Linux προστέθηκε : Network API που χρησιμοποιούν όλα τα σύγχρονα προγράμματα οδήγησης για τη βελτίωση της απόδοσης σε υψηλές ταχύτητες. Σε χαμηλές ταχύτητες ο πυρήνας εξακολουθεί να λαμβάνει διακοπές από την κάρτα δικτύου με τον παλιό τρόπο. Μόλις φτάσουν αρκετά πακέτα που υπερβαίνουν το όριο, ο πυρήνας απενεργοποιεί τις διακοπές και, αντί αυτού, αρχίζει να μετράει τον προσαρμογέα δικτύου και να παραλαμβάνει πακέτα σε κομμάτια. Η επεξεργασία πραγματοποιείται σε softirq, δηλαδή σε μετά από κλήσεις συστήματος και διακοπές υλικού, όταν ο πυρήνας (σε αντίθεση με τον χώρο χρήστη) εκτελείται ήδη.
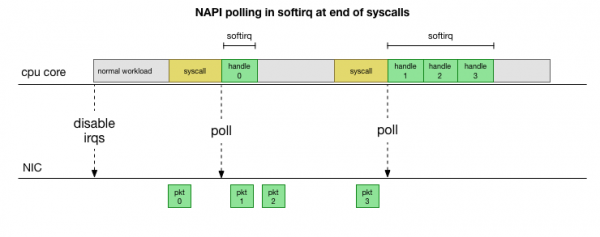
Αυτό είναι πολύ πιο γρήγορο, αλλά προκαλεί διαφορετικό πρόβλημα. Εάν υπάρχουν πάρα πολλά πακέτα, τότε όλος ο χρόνος δαπανάται για την επεξεργασία πακέτων από την κάρτα δικτύου και οι διεργασίες χώρου χρήστη δεν έχουν χρόνο να αδειάσουν πραγματικά αυτές τις ουρές (ανάγνωση από συνδέσεις TCP κ.λπ.). Τελικά οι ουρές γεμίζουν και αρχίζουμε να ρίχνουμε πακέτα. Σε μια προσπάθεια να βρει μια ισορροπία, ο πυρήνας ορίζει έναν προϋπολογισμό για τον μέγιστο αριθμό πακέτων που υποβάλλονται σε επεξεργασία στο περιβάλλον softirq. Μόλις ξεπεραστεί αυτός ο προϋπολογισμός, ενεργοποιείται ένα ξεχωριστό νήμα ksoftirqd (θα δείτε ένα από αυτά ps ανά πυρήνα) που χειρίζεται αυτά τα softirq εκτός της κανονικής διαδρομής syscall/interrupt. Αυτό το νήμα προγραμματίζεται χρησιμοποιώντας τον τυπικό προγραμματιστή διεργασιών, ο οποίος προσπαθεί να κατανείμει τους πόρους δίκαια.
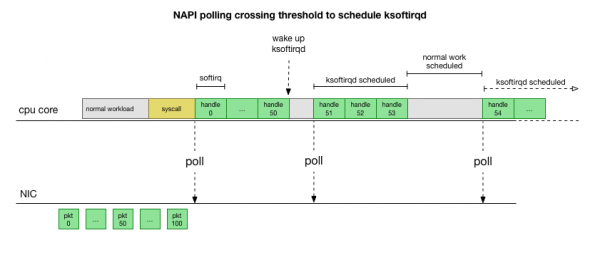
Έχοντας μελετήσει πώς ο πυρήνας επεξεργάζεται τα πακέτα, μπορείτε να δείτε ότι υπάρχει μια ορισμένη πιθανότητα συμφόρησης. Εάν οι κλήσεις softirq λαμβάνονται λιγότερο συχνά, τα πακέτα θα πρέπει να περιμένουν για κάποιο χρονικό διάστημα για να επεξεργαστούν στην ουρά RX στην κάρτα δικτύου. Αυτό μπορεί να οφείλεται σε κάποια εργασία που μπλοκάρει τον πυρήνα του επεξεργαστή ή κάτι άλλο εμποδίζει τον πυρήνα να εκτελεί το softirq.
Περιορίζοντας την επεξεργασία στον πυρήνα ή τη μέθοδο
Οι καθυστερήσεις του Softirq είναι απλώς μια εικασία προς το παρόν. Αλλά είναι λογικό, και ξέρουμε ότι βλέπουμε κάτι πολύ παρόμοιο. Το επόμενο βήμα λοιπόν είναι να επιβεβαιώσουμε αυτή τη θεωρία. Και αν επιβεβαιωθεί, τότε βρείτε τον λόγο για τις καθυστερήσεις.
Ας επιστρέψουμε στα αργά πακέτα μας:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Όπως αναφέρθηκε προηγουμένως, αυτά τα πακέτα ICMP κατακερματίζονται σε μία μόνο ουρά NIC RX και υποβάλλονται σε επεξεργασία από έναν μόνο πυρήνα CPU. Αν θέλουμε να κατανοήσουμε τη λειτουργία Linux, είναι χρήσιμο να γνωρίζουμε πού (σε ποιον πυρήνα CPU) και πώς (softirq, ksoftirqd) επεξεργάζονται αυτά τα πακέτα προκειμένου να παρακολουθήσουμε τη διαδικασία.
Τώρα είναι η ώρα να χρησιμοποιήσετε εργαλεία που σας επιτρέπουν να παρακολουθείτε την απόδοση του πυρήνα σε πραγματικό χρόνο. LinuxΕδώ χρησιμοποιήσαμε . Αυτό το σύνολο εργαλείων σάς επιτρέπει να γράφετε μικρά προγράμματα C που συνδέουν αυθαίρετες συναρτήσεις στον πυρήνα και αποθηκεύουν τα συμβάντα σε ένα πρόγραμμα Python στο χώρο χρήστη που μπορεί να τα επεξεργαστεί και να σας επιστρέψει το αποτέλεσμα. Η σύνδεση αυθαίρετων λειτουργιών στον πυρήνα είναι μια δύσκολη υπόθεση, αλλά το βοηθητικό πρόγραμμα έχει σχεδιαστεί για μέγιστη ασφάλεια και έχει σχεδιαστεί για να εντοπίζει ακριβώς το είδος των προβλημάτων παραγωγής που δεν αναπαράγονται εύκολα σε περιβάλλον δοκιμής ή ανάπτυξης.
Το σχέδιο εδώ είναι απλό: γνωρίζουμε ότι ο πυρήνας επεξεργάζεται αυτά τα ping ICMP, οπότε θα βάλουμε ένα άγκιστρο στη συνάρτηση του πυρήνα , το οποίο δέχεται ένα εισερχόμενο πακέτο αίτησης ηχούς ICMP και ξεκινά την αποστολή μιας απόκρισης ηχούς ICMP. Μπορούμε να αναγνωρίσουμε ένα πακέτο αυξάνοντας τον αριθμό icmp_seq, που εμφανίζεται hping3 πιο ψηλά.
Κώδικας φαίνεται περίπλοκο, αλλά δεν είναι τόσο τρομακτικό όσο φαίνεται. Λειτουργία icmp_echo μεταδίδει struct sk_buff *skb: Αυτό είναι ένα πακέτο με "αίτημα ηχούς". Μπορούμε να το παρακολουθήσουμε, να βγάλουμε τη σειρά echo.sequence (το οποίο συγκρίνεται με icmp_seq από το hping3 выше), και στείλτε το στο χώρο χρήστη. Είναι επίσης βολικό να καταγράψετε το όνομα/αναγνωριστικό της τρέχουσας διαδικασίας. Παρακάτω είναι τα αποτελέσματα που βλέπουμε απευθείας ενώ ο πυρήνας επεξεργάζεται πακέτα:
ΟΝΟΜΑ ΔΙΑΔΙΚΑΣΙΑΣ TGID PID ICMP_SEQ 0 0 swapper/11 770 0 swapper/0 11 771 swapper/0 0 11 swapper/772 0 0 swapper/11 773 0 προμηθέας 0 11 774 swapper/20041 20086 775 swapper/0 0 11 swapper/776 0 0 spokes-report-s 11
Να σημειωθεί εδώ ότι στο πλαίσιο softirq Οι διεργασίες που πραγματοποιούν κλήσεις συστήματος θα εμφανίζονται ως "διεργασίες", ενώ στην πραγματικότητα είναι ο πυρήνας που επεξεργάζεται με ασφάλεια τα πακέτα στο πλαίσιο του πυρήνα.
Με αυτό το εργαλείο μπορούμε να συσχετίσουμε συγκεκριμένες διεργασίες με συγκεκριμένα πακέτα που εμφανίζουν καθυστέρηση hping3. Ας το κάνουμε απλό grep σε αυτήν τη σύλληψη για ορισμένες τιμές icmp_seq. Τα πακέτα που αντιστοιχούν στις παραπάνω τιμές icmp_seq επισημάνθηκαν μαζί με το RTT που παρατηρήσαμε παραπάνω (σε παρένθεση είναι οι αναμενόμενες τιμές RTT για πακέτα που φιλτράραμε λόγω τιμών RTT μικρότερες από 50ms):
ΟΝΟΜΑ ΔΙΑΔΙΚΑΣΙΑΣ TGID PID ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ksoftirqd/11 1954 ** 89ms 76 76 ksoftirqd/11 1955 ** 79ms 76 76 ksoftirqd/11 1956 ** 69ms 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 1958 ** (49ms) 76 76 ksoftirqd/11 1959 ** (39ms) 76 76 ksoftirqd/11 1960 ** (29ms) 76 76 ksoftirqd/11 1961 ** (19ms) 76 76 ksoftirqd/11 1962 ** (9ms) -- 10137 10436 cadvisor 2068 10137 10436 cadvisor 2069 76 76 ksoftirqd/11 2070 ** 75ms 76 76 ksoftirqd/11 2071 ** 65ms 76 76 ksoftirqd/11 2072 ** 55ms 76 76 ksoftirqd/11 2073 ** (45ms) 76 76 ksoftirqd/11 2074 ** (35 ms) 76 76 ksoftirqd/11 2075 ** (25 ms) 76 76 ksoftirqd/11 2076 ** (15 ms) 76 76 ksoftirqd/11 2077 ** (5ms)
Τα αποτελέσματα μας λένε πολλά πράγματα. Πρώτον, όλα αυτά τα πακέτα επεξεργάζονται από το περιβάλλον ksoftirqd/11. Αυτό σημαίνει ότι για αυτό το συγκεκριμένο ζεύγος μηχανών, τα πακέτα ICMP κατακερματίστηκαν στον πυρήνα 11 στο άκρο λήψης. Βλέπουμε επίσης ότι όποτε υπάρχει εμπλοκή, υπάρχουν πακέτα που υποβάλλονται σε επεξεργασία στο πλαίσιο της κλήσης συστήματος cadvisor. Τότε ksoftirqd αναλαμβάνει την εργασία και επεξεργάζεται τη συσσωρευμένη ουρά: ακριβώς ο αριθμός των πακέτων που έχει συσσωρευτεί μετά cadvisor.
Το γεγονός ότι αμέσως πριν λειτουργεί πάντα cadvisor, υπονοεί την εμπλοκή του στο πρόβλημα. Κατά ειρωνικό τρόπο, ο σκοπός - "αναλύστε τη χρήση πόρων και τα χαρακτηριστικά απόδοσης των κοντέινερ που λειτουργούν" αντί να προκαλούν αυτό το πρόβλημα απόδοσης.
Όπως και με άλλες πτυχές των εμπορευματοκιβωτίων, αυτά είναι όλα εξαιρετικά προηγμένα εργαλεία και μπορεί να αναμένεται ότι θα αντιμετωπίσουν προβλήματα απόδοσης υπό ορισμένες απρόβλεπτες συνθήκες.
Τι κάνει το cadvisor που επιβραδύνει την ουρά πακέτων;
Τώρα έχουμε μια αρκετά καλή κατανόηση του πώς συμβαίνει η συντριβή, ποια διεργασία την προκαλεί και σε ποια CPU. Βλέπουμε ότι λόγω του hard lock, ο πυρήνας Linux δεν έχει χρόνο να σχεδιάσει εγκαίρως ksoftirqd. Και βλέπουμε ότι τα πακέτα επεξεργάζονται στο πλαίσιο cadvisor. Είναι λογικό να το υποθέσουμε cadvisor εκκινεί ένα αργό syscall, μετά το οποίο υποβάλλονται σε επεξεργασία όλα τα πακέτα που συσσωρεύτηκαν εκείνη τη στιγμή:
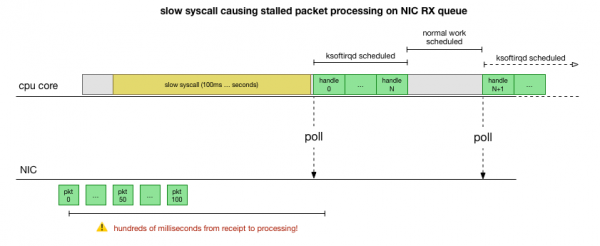
Αυτή είναι μια θεωρία, αλλά πώς να τη δοκιμάσετε; Αυτό που μπορούμε να κάνουμε είναι να ανιχνεύσουμε τον πυρήνα της CPU σε όλη αυτή τη διαδικασία, να βρούμε το σημείο όπου ο αριθμός των πακέτων υπερβαίνει τον προϋπολογισμό και ονομάζεται ksoftirqd και, στη συνέχεια, να κοιτάξουμε λίγο πιο πίσω για να δούμε τι ακριβώς λειτουργούσε στον πυρήνα της CPU λίγο πριν από αυτό το σημείο . Είναι σαν να ακτινογραφείτε την CPU κάθε λίγα χιλιοστά του δευτερολέπτου. Θα μοιάζει κάπως έτσι:
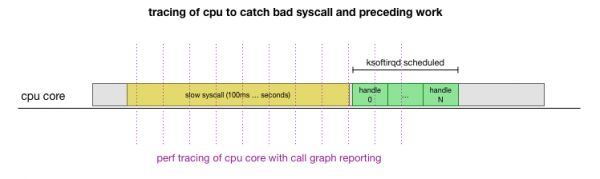
Βολικά, όλα αυτά μπορούν να γίνουν με τα υπάρχοντα εργαλεία. Για παράδειγμα, Ελέγχει έναν δεδομένο πυρήνα CPU σε μια καθορισμένη συχνότητα και μπορεί να δημιουργήσει ένα γράφημα κλήσεων του συστήματος που εκτελείται, συμπεριλαμβανομένου τόσο του χώρου χρήστη όσο και του πυρήνα LinuxΜπορείτε να πάρετε αυτήν την εγγραφή και να την επεξεργαστείτε χρησιμοποιώντας ένα μικρό fork του προγράμματος. από τον Brendan Gregg, το οποίο διατηρεί τη σειρά του ίχνους στοίβας. Μπορούμε να αποθηκεύσουμε ίχνη στοίβας μίας γραμμής κάθε 1 ms και, στη συνέχεια, να επισημάνουμε και να αποθηκεύσουμε ένα δείγμα 100 χιλιοστά του δευτερολέπτου πριν εμφανιστεί το ίχνος ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Εδώ είναι τα αποτελέσματα:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Υπάρχουν πολλά πράγματα εδώ, αλλά το κυριότερο είναι ότι βρίσκουμε το μοτίβο "cadvisor before ksoftirqd" που είδαμε νωρίτερα στο ICMP tracer. Τι σημαίνει?
Κάθε γραμμή είναι ένα ίχνος CPU σε μια συγκεκριμένη χρονική στιγμή. Κάθε κλήση προς τα κάτω στη στοίβα σε μια γραμμή χωρίζεται με ένα ερωτηματικό. Στη μέση των γραμμών βλέπουμε το syscall να ονομάζεται: read(): .... ;do_syscall_64;sys_read; .... Έτσι, το cadvisor ξοδεύει πολύ χρόνο στην κλήση συστήματος read()που σχετίζονται με λειτουργίες mem_cgroup_* (κορυφή στοίβας κλήσεων/τέλος γραμμής).
Δεν είναι βολικό να βλέπετε σε ένα ίχνος κλήσης τι ακριβώς διαβάζεται, οπότε ας τρέξουμε strace και ας δούμε τι κάνει το cadvisor και ας βρούμε κλήσεις συστήματος μεγαλύτερες από 100ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Όπως μπορείτε να περιμένετε, βλέπουμε αργές κλήσεις εδώ read(). Από τα περιεχόμενα των πράξεων ανάγνωσης και του περιβάλλοντος mem_cgroup είναι σαφές ότι αυτές οι προκλήσεις read() ανατρέξτε στο αρχείο memory.stat, το οποίο δείχνει τη χρήση μνήμης και τα όρια cgroup (τεχνολογία απομόνωσης πόρων Docker). Το εργαλείο cadvisor υποβάλλει ερώτημα σε αυτό το αρχείο για να λάβει πληροφορίες χρήσης πόρων για κοντέινερ. Ας ελέγξουμε αν ο πυρήνας ή ο cadvisor κάνει κάτι απροσδόκητο:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
πραγματικό 0m0.153s
χρήστης 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Τώρα μπορούμε να αναπαράγουμε το σφάλμα και να καταλάβουμε ότι ο πυρήνας Linux συναντά παθολογία.
Γιατί είναι τόσο αργή η λειτουργία ανάγνωσης;
Σε αυτό το στάδιο, είναι πολύ πιο εύκολο να βρείτε μηνύματα από άλλους χρήστες σχετικά με παρόμοια προβλήματα. Όπως αποδείχθηκε, στο cadvisor tracker αυτό το σφάλμα αναφέρθηκε ως , απλά κανείς δεν παρατήρησε ότι η καθυστέρηση αντανακλάται επίσης τυχαία στη στοίβα δικτύου. Πράγματι, παρατηρήθηκε ότι το cadvisor κατανάλωνε περισσότερο χρόνο CPU από το αναμενόμενο, αλλά αυτό δεν δόθηκε μεγάλη σημασία, καθώς οι διακομιστές μας έχουν πολλούς πόρους CPU, επομένως το πρόβλημα δεν μελετήθηκε προσεκτικά.
Το πρόβλημα είναι ότι οι cgroups λαμβάνουν υπόψη τη χρήση μνήμης εντός του χώρου ονομάτων (κοντέινερ). Όταν όλες οι διεργασίες σε αυτήν την cgroup εξέλθουν, το Docker απελευθερώνει την cgroup μνήμης. Ωστόσο, η "μνήμη" δεν είναι μόνο μνήμη διεργασιών. Αν και η ίδια η μνήμη διεργασίας δεν χρησιμοποιείται πλέον, φαίνεται ότι ο πυρήνας εξακολουθεί να εκχωρεί αποθηκευμένα περιεχόμενα, όπως οδοντοστοιχίες και inodes (κατάλογος και μεταδεδομένα αρχείου), τα οποία αποθηκεύονται στην κρυφή μνήμη cgroup της μνήμης. Από την περιγραφή του προβλήματος:
zombie cgroups: cgroups που δεν έχουν διεργασίες και έχουν διαγραφεί, αλλά εξακολουθούν να έχουν εκχωρημένη μνήμη (στην περίπτωσή μου, από την προσωρινή μνήμη dentry, αλλά μπορεί επίσης να εκχωρηθεί από την προσωρινή μνήμη σελίδων ή tmpfs).
Ο έλεγχος του πυρήνα όλων των σελίδων στη μνήμη cache κατά την απελευθέρωση μιας cgroup μπορεί να είναι πολύ αργός, επομένως επιλέγεται η lazy διαδικασία: περιμένετε έως ότου ζητηθούν ξανά αυτές οι σελίδες και, στη συνέχεια, διαγράψτε τελικά την cgroup όταν χρειάζεται πραγματικά η μνήμη. Μέχρι αυτό το σημείο, η cgroup εξακολουθεί να λαμβάνεται υπόψη κατά τη συλλογή στατιστικών στοιχείων.
Από την άποψη της απόδοσης, θυσίασαν τη μνήμη για την απόδοση: επιτάχυναν τον αρχικό καθαρισμό αφήνοντας πίσω τους κάποια αποθηκευμένη μνήμη. Είναι εντάξει. Όταν ο πυρήνας χρησιμοποιεί την τελευταία από την κρυφή μνήμη, η cgroup τελικά διαγράφεται, επομένως δεν μπορεί να ονομαστεί "διαρροή". Δυστυχώς, η συγκεκριμένη εφαρμογή του μηχανισμού αναζήτησης memory.stat σε αυτήν την έκδοση του πυρήνα (4.9), σε συνδυασμό με την τεράστια ποσότητα μνήμης στους διακομιστές μας, σημαίνει ότι χρειάζεται πολύ περισσότερος χρόνος για την επαναφορά των πιο πρόσφατων αποθηκευμένων δεδομένων στην κρυφή μνήμη και την εκκαθάριση των ζόμπι cgroup.
Αποδεικνύεται ότι ορισμένοι από τους κόμβους μας είχαν τόσα πολλά cgroup zombies που η ανάγνωση και η καθυστέρηση ξεπέρασαν το ένα δευτερόλεπτο.
Η λύση για το ζήτημα του cadvisor είναι η άμεση απελευθέρωση κρυφών μνήμων οδοντοστοιχιών/ινωδών σε όλο το σύστημα, πράγμα που εξαλείφει αμέσως την καθυστέρηση ανάγνωσης καθώς και την καθυστέρηση δικτύου στον κεντρικό υπολογιστή, καθώς η εκκαθάριση της προσωρινής μνήμης ενεργοποιεί τις αποθηκευμένες σελίδες ζόμπι cgroup και αυτές επίσης απελευθερώνονται. Αυτή δεν είναι λύση, αλλά επιβεβαιώνει την αιτία του προβλήματος.
Αποδείχθηκε ότι σε νεότερες εκδόσεις πυρήνα (4.19+) η απόδοση κλήσης βελτιώθηκε memory.stat, οπότε η μετάβαση σε αυτόν τον πυρήνα επιλύθηκε το πρόβλημα. Ταυτόχρονα, είχαμε εργαλεία για να ανιχνεύσουμε προβληματικούς κόμβους στα συμπλέγματα Kubernetes, να τους αποστραγγίσουμε με χάρη και να τους επανεκκινήσουμε. Χτενίσαμε όλα τα συμπλέγματα, βρήκαμε κόμβους με αρκετά υψηλή καθυστέρηση και τα επανεκκινήσαμε. Αυτό μας έδωσε χρόνο να ενημερώσουμε το λειτουργικό σύστημα στους υπόλοιπους διακομιστές.
Ανακεφαλαίωση
Επειδή αυτό το σφάλμα σταμάτησε την επεξεργασία ουράς RX NIC για εκατοντάδες χιλιοστά του δευτερολέπτου, προκάλεσε ταυτόχρονα υψηλό λανθάνοντα χρόνο σε σύντομες συνδέσεις και λανθάνουσα κατάσταση στη μέση σύνδεση, όπως μεταξύ αιτημάτων MySQL και πακέτων απόκρισης.
Η κατανόηση και η διατήρηση της απόδοσης των πιο θεμελιωδών συστημάτων, όπως το Kubernetes, είναι κρίσιμης σημασίας για την αξιοπιστία και την ταχύτητα όλων των υπηρεσιών που βασίζονται σε αυτά. Κάθε σύστημα που εκτελείτε επωφελείται από βελτιώσεις απόδοσης Kubernetes.
Πηγή: www.habr.com
