

Από καιρό σε καιρό, ένας προγραμματιστής έχει μια ανάγκη περάστε ένα σύνολο παραμέτρων ή ακόμα και μια ολόκληρη επιλογή στο αίτημα «στην είσοδο». Μερικές φορές συναντάτε πολύ περίεργες λύσεις σε αυτό το πρόβλημα.
Ας πάμε «από το αντίθετο» και ας δούμε τι δεν πρέπει να γίνει, γιατί και πώς μπορεί να γίνει καλύτερα.
Άμεση εισαγωγή τιμών στο σώμα αιτήματος
Συνήθως μοιάζει κάπως έτσι:
query = "SELECT * FROM tbl WHERE id = " + value… ή όπως αυτό:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Αυτή η μέθοδος έχει ειπωθεί, γραφτεί για και αρκετά:

Σχεδόν πάντα είναι - άμεση διαδρομή για ενέσεις SQL και ένα επιπλέον φορτίο στην επιχειρηματική λογική, που αναγκάζεται να «κολλήσει» τη σειρά του αιτήματός σας.
Αυτή η προσέγγιση μπορεί να δικαιολογηθεί μόνο εν μέρει εάν είναι απαραίτητο. χρήση κατάτμησης στις εκδόσεις PostgreSQL 10 και παρακάτω για να αποκτήσετε ένα πιο αποτελεσματικό σχέδιο. Σε αυτές τις εκδόσεις, η λίστα των ενοτήτων που θα σαρωθούν καθορίζεται χωρίς να λαμβάνονται υπόψη οι παράμετροι που έχουν περάσει, μόνο με βάση το σώμα του αιτήματος.
$n-επιχειρήματα
Χρήση παράμετροι - αυτό είναι καλό, σας επιτρέπει να το χρησιμοποιήσετε , μειώνοντας το φόρτο τόσο στην επιχειρηματική λογική (η συμβολοσειρά ερωτήματος δημιουργείται και μεταδίδεται μόνο μία φορά) όσο και στον διακομιστή βάσης δεδομένων (δεν απαιτείται εκ νέου ανάλυση και προγραμματισμός για κάθε περίπτωση ερωτήματος).
Μεταβλητός αριθμός ορισμάτων
Θα μας περιμένουν προβλήματα όταν θέλουμε να περάσουμε έναν άγνωστο αριθμό ορισμάτων:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Εάν αφήσουμε το αίτημα σε αυτή τη φόρμα, θα μας προστατεύσει από πιθανές ενέσεις, αλλά θα εξακολουθεί να οδηγεί στην ανάγκη να κολλήσουμε/αναλύσουμε το αίτημα για κάθε επιλογή από τον αριθμό των ορισμάτων. Είναι καλύτερο από το να το κάνεις κάθε φορά, αλλά μπορείς και χωρίς αυτό.
Αρκεί να περάσετε μόνο μία παράμετρο που περιέχει σειριακή αναπαράσταση ενός πίνακα:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Η μόνη διαφορά είναι ότι πρέπει να μετατρέψετε ρητά το όρισμα στον επιθυμητό τύπο πίνακα. Αυτό όμως δεν δημιουργεί κανένα πρόβλημα, αφού ήδη γνωρίζουμε εκ των προτέρων πού πάμε.
Μεταφορά δείγματος (μήτρας)
Συνήθως, αυτές είναι κάθε είδους επιλογές για τη μεταφορά συνόλων δεδομένων για εισαγωγή στη βάση δεδομένων "σε ένα αίτημα":
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Εκτός από τα προβλήματα που περιγράφονται παραπάνω με την "επαναεπικόλληση" του αιτήματος, αυτό μπορεί επίσης να μας οδηγήσει σε εκτός μνήμης και συντριβή διακομιστή. Ο λόγος είναι απλός: το PG διατηρεί πρόσθετη μνήμη για ορίσματα και ο αριθμός των εγγραφών σε ένα σύνολο περιορίζεται μόνο από τις εφαρμοσμένες επιθυμίες της επιχειρηματικής λογικής. Σε ιδιαίτερα κλινικές περιπτώσεις έπρεπε να δω "αριθμημένα" επιχειρήματα άνω των $9000 - Μην το κάνεις αυτό.
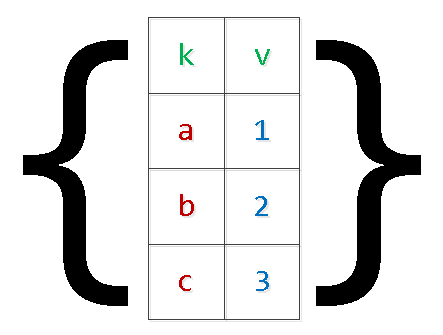
Ας ξαναγράψουμε το ερώτημα, χρησιμοποιώντας το ήδη εφαρμοσμένο σειριοποίηση "δύο επιπέδων".:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Ναι, σε περίπτωση "σύνθετων" τιμών μέσα σε έναν πίνακα, πρέπει να περικλείονται σε εισαγωγικά.
Είναι σαφές ότι με αυτόν τον τρόπο είναι δυνατή η «επέκταση» ενός δείγματος με αυθαίρετο αριθμό πεδίων.
φωλιά, φωλιά,…
Περιστασιακά, υπάρχουν επιλογές για να περάσετε αρκετούς "πίνακες στηλών" αντί για τον "πίνακα πινάκων" που ανέφερα. :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Με αυτήν τη μέθοδο, εάν κάνετε λάθος κατά τη δημιουργία λιστών τιμών για διαφορετικές στήλες, είναι πολύ εύκολο να λάβετε πλήρως απροσδόκητα αποτελέσματα, τα οποία εξαρτώνται επίσης από την έκδοση διακομιστή:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
Ξεκινώντας με την έκδοση 9.3, η PostgreSQL είχε πλήρεις λειτουργίες για εργασία με τον τύπο json. Επομένως, εάν ορίσετε παραμέτρους εισόδου στο πρόγραμμα περιήγησης, μπορείτε να τις δημιουργήσετε ακριβώς εκεί. αντικείμενο json για ερώτημα sql:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Για προηγούμενες εκδόσεις, μπορεί να χρησιμοποιηθεί η ίδια μέθοδος καθένα (hstore), αλλά το σωστό "δίπλωμα" με διαφυγή σύνθετων αντικειμένων στο hstore μπορεί να προκαλέσει προβλήματα.
json_populate_recordset
Εάν γνωρίζετε εκ των προτέρων ότι τα δεδομένα από τον πίνακα json "input" θα χρησιμοποιηθούν για τη συμπλήρωση κάποιου πίνακα, μπορείτε να εξοικονομήσετε πολλά για την "αποαναφορά" πεδίων και τη μετάδοση στους απαιτούμενους τύπους χρησιμοποιώντας τη συνάρτηση json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
Και αυτή η συνάρτηση απλώς θα «ξεδιπλώσει» τον διαβιβασμένο πίνακα αντικειμένων σε μια επιλογή, χωρίς να βασίζεται στη μορφή του πίνακα:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2ΠΡΟΣΩΡΙΝΟΣ ΤΡΑΠΕΖΙ
Αλλά εάν ο όγκος των δεδομένων στο μεταδιδόμενο δείγμα είναι πολύ μεγάλος, τότε η απόρριψή τους σε μία σειριακή παράμετρο είναι δύσκολη και μερικές φορές αδύνατη, καθώς απαιτεί εφάπαξ μεγάλες εκχωρήσεις μνήμης. Για παράδειγμα, πρέπει να συλλέξετε ένα μεγάλο πακέτο δεδομένων συμβάντων από ένα εξωτερικό σύστημα για μεγάλο χρονικό διάστημα και, στη συνέχεια, θέλετε να το επεξεργαστείτε μία φορά από την πλευρά του DB.
Σε αυτή την περίπτωση, η καλύτερη λύση θα ήταν η χρήση :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
Η μέθοδος είναι καλή ακριβώς για σπάνια μετάδοση μεγάλων όγκων δεδομένα.
Από την άποψη της περιγραφής της δομής των δεδομένων του, ένας προσωρινός πίνακας διαφέρει από έναν "κανονικό" πίνακα μόνο με έναν τρόπο: στον πίνακα συστήματος pg_class, ενώ στο pg_type, pg_depend, pg_attribute, pg_attrdef,… - τίποτα απολύτως.
Επομένως, σε συστήματα web με μεγάλο αριθμό βραχύβιων συνδέσεων, για καθένα από αυτά ένας τέτοιος πίνακας θα δημιουργεί νέες εγγραφές συστήματος κάθε φορά, οι οποίες διαγράφονται όταν η σύνδεση με τη βάση δεδομένων είναι κλειστή. Ως αποτέλεσμα, Η ανεξέλεγκτη χρήση του TEMP TABLE οδηγεί σε "φουσκώματα" των πινάκων στο pg_catalog και επιβραδύνοντας πολλές λειτουργίες που τα χρησιμοποιούν.
Φυσικά, αυτό μπορεί να καταπολεμηθεί με τη βοήθεια του περιοδική διέλευση ΚΕΝΟ ΠΛΗΡ σύμφωνα με τους πίνακες καταλόγου συστήματος.
Μεταβλητές συνεδρίας
Ας υποθέσουμε ότι η επεξεργασία των δεδομένων από την προηγούμενη περίπτωση είναι αρκετά περίπλοκη για ένα μόνο ερώτημα SQL, αλλά θέλετε να το κάνετε αρκετά συχνά. Δηλαδή, θέλουμε να χρησιμοποιήσουμε διαδικαστική επεξεργασία στο , αλλά η χρήση μεταφοράς δεδομένων μέσω προσωρινών πινάκων θα είναι πολύ ακριβή.
Επίσης, δεν θα μπορούμε να χρησιμοποιήσουμε $n παραμέτρους για να μεταβιβάσουμε σε ένα ανώνυμο μπλοκ. Οι μεταβλητές περιόδου λειτουργίας και η συνάρτηση θα μας βοηθήσουν να βγούμε από αυτήν την κατάσταση. τρέχουσα_ρύθμιση.
Πριν από την έκδοση 9.2, ήταν απαραίτητο να γίνει εκ των προτέρων ρύθμιση custom_variable_classes για τις μεταβλητές συνεδρίας "σας". Στις τρέχουσες εκδόσεις μπορείτε να γράψετε κάτι σαν αυτό:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Ενδέχεται να βρεθούν άλλες λύσεις σε άλλες υποστηριζόμενες διαδικαστικές γλώσσες.
Ξέρεις άλλους τρόπους; Κοινοποιήστε στα σχόλια!
Πηγή: www.habr.com
