

Hi Habr! Datasets for Big Data and machine learning are growing exponentially and we need to manage to process them. Our post about another innovative technology in the field of high performance computing (HPC, High Performance Computing), shown at the Kingston booth at . This is the use of Hi-End storage systems (SHD) in servers with graphics processing units (GPU) and GPUDirect Storage bus technology. Thanks to the direct exchange of data between the storage system and the GPU, bypassing the CPU, data loading into the GPU accelerators is an order of magnitude faster, so Big Data applications run at the maximum performance that the GPU provides. In turn, HPC system developers are interested in advances in storage with the highest I / O speed, such as those released by Kingston.

GPU performance outpaces data loading
Since CUDA, a GPU-based parallel computing hardware and software architecture for general-purpose application development, was created in 2007, the hardware capabilities of the GPUs themselves have grown tremendously. Today, GPUs are increasingly used in HPC applications such as Big Data, machine learning (ML, machine learning) and deep learning (DL, deep learning).
Note that despite the similarity of terms, the last two are algorithmically different tasks. ML trains a computer based on structured data, while DL trains a computer based on the response from a neural network. An example to help understand the differences is quite simple. Suppose that the computer must distinguish between photos of cats and dogs that are loaded from the storage system. For ML, you should submit a set of images with many tags, each of which defines one feature of the animal. For DL, it is enough to upload a much larger number of images, but with only one "this is a cat" or "this is a dog" tag. DL is very similar to how young children are taught - they are simply shown images of dogs and cats in books and in life (most often, without even explaining the detailed difference), and the child's brain itself begins to determine the type of animal after a certain critical number of pictures for comparison ( it is estimated that we are talking about only a hundred or two impressions for the entire period of early childhood). The DL algorithms are not yet so perfect: in order for the neural network to also successfully work on the definition of images, it is necessary to feed and process millions of images into the GPU.
Summary of the preface: HPC applications in Big Data, ML and DL can be built on the basis of the GPU, but there is a problem - the data sets are so large that the time spent loading data from the storage system to the GPU starts to reduce the overall performance of the application. In other words, fast GPUs are left underutilized due to slow I/O from other subsystems. The difference in I / O speed of the GPU and the bus to the CPU / storage system can be an order of magnitude.
How does GPUDirect Storage technology work?
The I/O process is controlled by the CPU, as is the process of loading data from storage to GPUs for further processing. From this arose a request for a technology that would provide direct access between the GPU and NVMe drives for fast interaction with each other. NVIDIA was the first to offer such a technology and called it GPUDirect Storage. In fact, this is a variation of their previously developed GPUDirect RDMA (Remote Direct Memory Address) technology.
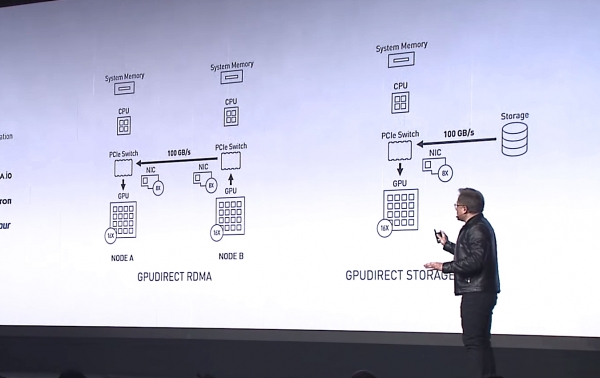
Jensen Huang, CEO of NVIDIA, unveils GPUDirect Storage as a variation of GPUDirect RDMA at SC-19. Source: NVIDIA
The difference between GPUDirect RDMA and GPUDirect Storage is in the devices between which the addressing is performed. GPUDirect RDMA technology is repurposed to move data directly between an ingress network interface card (NIC) and GPU memory, while GPUDirect Storage provides a direct data transfer path between local or remote storage such as NVMe or NVMe over Fabric (NVMe-oF) and GPU memory.
Both GPUDirect RDMA and GPUDirect Storage avoid unnecessary data transfers through the CPU memory buffer and allow the direct memory access (DMA) mechanism to move data from a network card or storage directly to or from the GPU memory - all without loading the central CPU. For GPUDirect Storage, the location of the storage does not matter: it can be an NVME disk inside a GPU unit, inside a rack, or networked as NVMe-oF.
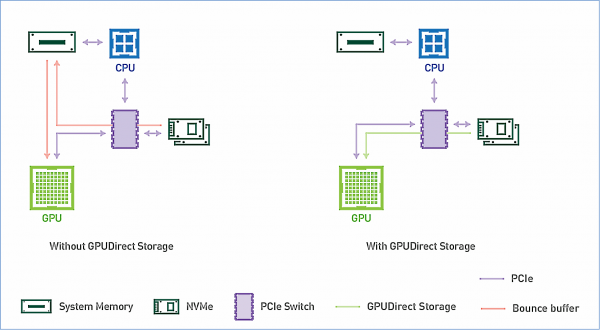
How GPUDirect Storage works. Source: NVIDIA
Hi-End storage systems on NVMe are in demand in the HPC application market
Realizing that with the advent of GPUDirect Storage, the interest of large customers will be turned to offer storage systems with I / O speeds corresponding to the throughput of the GPU, at the SC-19 exhibition, Kingston showed a demo of a system consisting of NVMe-based storage systems and a GPU unit, which analyzed thousands of satellite images per second. We already wrote about such a storage system based on 10 DC1000M U.2 NVMe drives .

Storage based on 10 DC1000M U.2 NVMe drives adequately complements the server with graphics accelerators. Source: Kingston
Such a storage system is implemented as a rack unit of 1U or more and can be scaled depending on the number of DC1000M U.2 NVMe drives, each with a capacity of 3.84-7.68 TB. The DC1000M is the first U.2 NVMe SSD in Kingston's data center line. It has a endurance rating (DWPD, Drive writes per day), which allows you to overwrite data at full capacity once a day during the guaranteed life of the drive.
In the test of fio v3.13 on the operating system Ubuntu 18.04.3 LTS, Linux kernel 5.0.0-31-generic, the demonstration sample of the storage system showed a read speed (Sustained Read) of 5.8 million IOPS with a sustainable throughput (Sustained Bandwidth) of 23.8 Gbps.
Ariel Perez, SSD business manager at Kingston, said: “We are ready to power the next generation of servers with U.2 NVMe SSD solutions to eliminate many of the data transfer bottlenecks that have traditionally been associated with storage. The combination of NVMe SSDs and our premium Server Premier DRAM makes Kingston one of the industry's most complete providers of end-to-end data processing solutions."
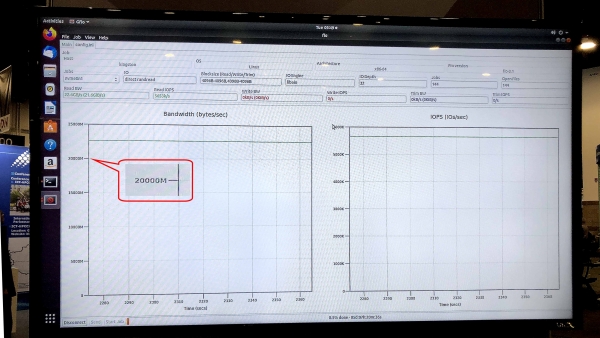
The gfio v3.13 test showed a throughput of 23.8 Gb / s for a demo storage system on DC1000M U.2 NVMe drives. Source: Kingston
What would a typical system for HPC applications with GPUDirect Storage technology or equivalent look like? This is an architecture with a physical division of functional blocks within a rack: one or two units for RAM, a few more for GPU and CPU computing nodes, and one or more units for storage.
With the announcement of GPUDirect Storage and the possible emergence of similar technologies from other GPU vendors, demand for storage systems designed for use in high performance computing is expanding for Kingston. The marker will be the speed of reading data from the storage system, comparable to the throughput of 40- or 100-Gbps network cards at the input to the computing unit with the GPU. Thus, ultra-fast storage systems, including external NVMe via Fabric, will go from exotic to mainstream for HPC applications. In addition to science and financial calculations, they will find application in many other practical areas, such as security systems at the level of the Safe City megalopolis or transport surveillance centers, where recognition and identification speeds of millions of HD images per second are required, ”marked the market niche of top storage
More information about Kingston products can be found at company.
Source: habr.com
