

On March 14, 2017, Arthur Khachuyan, CEO of Social Data Hub, spoke at the BBDO lecture hall. Artur spoke about intelligent monitoring, building behavioral models, recognizing photo and video content, as well as other tools and studies of the Social Data Hub that allow targeting an audience using social networks and Big Data technologies.

Artur Khachuyan (hereinafter - AH): - Hello! Hi all! My name is Artur Khachuyan, I manage the Social Data Hub company, and we are engaged in various interesting intellectual analysis of open data sources, information fields and doing all sorts of interesting research and so on.
And today, colleagues from the BBDO Group were asked to talk about modern technologies for analyzing big data, big and not so big data for advertising: how it is applied, to show some interesting examples. I hope you will ask questions along the way, because I can start to push and not reveal the essence and so on, so feel free.
Actually, the main directions, some “near-big” solutions have ever been used somewhere, they are all clear - this is audience targeting, analysis, conducting some kind of analysis and marketing research. But it is always interesting what additional data can be found, what additional meanings can be found after applying the analysis.
Why do we need technology for advertising?
Where do we start? The most understandable is advertising in social networks. Today I took it off in the morning: for some reason, Vkontakte thinks I should see this particular advertisement ... Is it good or bad - this is the second question. We see that I fall under the category of conscripts for sure:

The very first and interesting thing that can be taken as a technological solution ... The first thing I wanted to decide before we start is to define the terms: what is open data and what is big data? Because all people have their own understanding on this matter, and I do not want to impose my terms on anyone, but ... Just so that there are no discrepancies.
Personally, I think open data is all that I can reach without any login or password. This is an open profile on social networks, this is search results, these are open registries, etc. Big data, in my own understanding, I see this way: if this is a data plate, this is a billion lines, if this is some kind of file storage, this is somewhere petabytes of data. The rest in my terminology is not big data, but something close to it.
High-precision profiling and profile scoring
Let's go in order. The very first and most interesting thing that can come up from the analysis of open data sources is high-precision profiling and profile scoring. What is this? This is a story when, according to your account on a social network, you can predict not only who you are, not only your interests.
But now, by combining various sources, you can understand the average level of your salary, how much your apartment costs, where it is located. And all this data can be used literally from improvised means. For example, if you take your account on a social network, look, say, where you live, where you work; understand what section of the business the company you work for is in; take an upload of similar vacancies from HH and Superjob if you are an analyst, manager, etc.; see where you live (base, say, CYAN), understand how much it costs to rent a house in this place, how much it costs to buy a house in this place, predict approximately how much you earn. Further on your social networks, you can understand how much you travel, where you are, how loyal you are to the employer.
Accordingly, from such a huge number of metrics, we can do anything. We can introduce you the product that you are interested in. Imagine an online store? You go there - this online store catches your social network account and tells you: "Masha, you just broke up with a guy, here are some certain products for you." It's not the near future...
How is a person's location determined?
Answers to questions from the audience:
- Usually, 80% of all check-ins are considered to be the exact place of residence. But for people who don’t check in anywhere, there are several options: either check-in, or geolocation, or this is an analysis of posts and publications for the entire period of time when a person wrote anything ... And somewhere, something will pop up like “I want to buy a stroller near Akademicheskaya” or “I recently saw ugly graffiti on the wall here.” That is, almost 80% of people can be determined by their geolocation, their place of work and their place of residence according to data or metadata that can be collected from social networks.
Again, this is post analysis. In the simplest sense, this is an analysis of check-ins and geolocations in social networks that do not delete jpeg metadata (you can parse something from them). But for the rest of the people, these are usually text broadcasts: either a person “shines” his location when he writes about something, or he “shines” his phone, where you can find some of his advertising on Avito or his account on "Auto RU". Based on these data, you can combine (for example, "I'm selling a car near Mayakovskaya") and roughly assume this.
- Usually people post it on social media. We work only with open sources and here we are talking only about open sources. Usually they publish ads, that is, in sixty percent of cases, the most common story when people “shine” their current cell phone number is an ad for the sale of something. Either in some groups a person writes (“I sell this or that there), or goes somewhere.
Yes! They usually comment, like: “Answer me or throw a text message, call me at the number. This very often happens with people who sell something, buy something on social networks, communicate with someone ... Accordingly, by this number you can then link his profile on CYAN to him, if he has ever published something, or , again, on "Avito". These are just the most popular, top sources, it will continue to be - these are Avito, CYAN and so on.
- I mean online store. Next will be face recognition and profile matching technology (we'll talk about it). Purely theoretically, this can be applied to an offline store. And in general, my big dream is when street banners appear, when you walk past the camera, it “traces” your face. But this case will be banned by law, because it is a violation of privacy. I hope that sooner or later it will be.
- I have from personal experience. Very often, when a person writes something to you, you operate with some facts from his life, which you kind of should not know ... People in most cases get scared. But! Based on recent statistics, the number of closed accounts in social networks has decreased by 14%. The number of fakes is increasing, the number of open accounts is growing - people are moving more and more towards openness. I think that in 3-4 years they will stop reacting so sharply to the fact that someone knows information about them that he potentially should not know. But it's actually very easy to get it by looking at his wall.
What can be taken from open sources?
There is an approximate list of things that can be understood with a fairly high certainty from open sources. In fact, there are even more different metrics; it depends on the customer of such studies. There is some HR agency that is interested in whether you swear on social networks or somewhere in public space. Someone wonders whether you like Navalny's publications or, conversely, United Russia's publications, or some kind of pornographic content - such things happen quite often.
The main ones are family values, the approximate cost of an apartment, home, car search, and so on. According to this, people can be divided into social groups. These are users of the Moscow Tinder, who they are (according to their pictures found on their Facebook accounts); on the basis of their interests are divided into various social groups:

If we move closer to advertising, then we have already slowly moved away from standard advertising targeting, when you choose in the conditional VKontakte that you are interested in men aged 18 who subscribe to certain groups. I have the following picture, now I'll show you:

The bottom line is that most of the current services that are engaged in analysis, in principle, people who are engaged in the analysis of social networks, are engaged in the analysis of interests ... The first thing that comes to people's minds is about analyzing the top groups of their subscribers. It may work with someone, but personally I think that this is fundamentally wrong. Why?
Your likes are collected and analyzed
Take your phones now, look at your top groups - there will definitely be more than 50% of the groups that you have already forgotten about, this is some kind of content that is actually irrelevant to you. You don’t consume it at all, but nevertheless the system will stretch you according to them: that you are subscribed to recipes, to some popular groups. That is, you will violate the system that analyzes your profile, and your interests will not be justified.
Moving on... What's in there? We assume what other people are doing. In our opinion, the most adequate way to evaluate the interests of users is likes. For example, there is no like feed on Vkontakte, and people think that no one knows what they like. Yes, some of the likes are on Instagram, we see something on Facebook, but most of the content in certain groups does not broadcast it as a general feed, and people live and think that no one will know what they like.
And, having collected certain content of some kind that interests us, collecting these posts, collecting these likes, then checking this person using this database, we can determine with high accuracy who he is, what his fate is, what he is interested in. Define exactly in a certain social group and interact with it.
Buying a car changes behavior
I have such an example. I’ll make a reservation right away that my examples are near-advertising and near-marketing, because, you know, most cases are protected by NDA and so on. But still there will be a lot of interesting things. So, the story with these people: these are men who bought a car between 2010 and 2015. How their online social behavior has changed is marked in color. The percentage of girls in subscribers has changed, subscribed to "boy" publics, found a permanent sexual partner ...
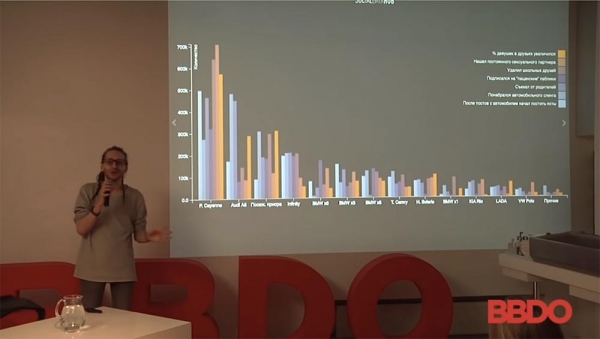
The whole thing is broken down by car brands and by the number of people. From here you can draw many interesting conclusions about the behavior of people, how it all works. I can say that the Porsche Cayenne and the planted Priora are practically the same in terms of the number of attracted audiences. The quality of this audience, their behavior is different, but the number is about the same. The conclusion from here can be drawn, closer to your market, whatever. You sell Audi - you make the slogan "Buy an Audi - get away from your parents!" and so on.
Yes, this is a funny example of the fact that the behavior of people based on the analysis of likes, based on which group they go to, what content they analyze - with almost 100% probability makes it clear who you are. Because if you do not have access to network traffic, do not read private messages, likes will always tell you who this person is - a pregnant woman, mother, military man, policeman. And for you, as a person who can advertise, this is a big hit on the target.
Answers to questions from the audience:
- Each column is the number of people in this car; how their behavior pattern has changed. Look here: people who bought a Porsche Cayenne - about 550 people (yellow), the percentage of girls in subscribers has increased.
- The sample is the users of social networks Vkontakte, Facebook, Instagram from 2010 to 2015. The only clarification: here are selected cars that can be identified with more than 80% accuracy in photographs using certain tools.
- For a certain period of time, his car (well, that is, not his, we already leave this to the test of social networks) ... For a certain period of time, a person was constantly photographed with a car, was with him, the publications were different, the photos were from different angles, and so on . There will be a picture next, which people are photographed with which cars and ... Yes, this is the second question - trust in social networking data.
- Since we raised it, unfortunately, the data of social networks is not always correct. People are not always inclined to publish their information. Personally, I conducted such a study: I compared the number of graduates of Moscow universities with the number of people registered in social networks. On average, 60% more people are registered in social networks - graduates of Moscow State University for a certain year in certain specialties, than they actually exist in principle. So yes - here, of course, there is a percentage of errors, and no one hides this. Here, we simply take as a basis those cars that can be identified with more than 80% probability.
List of sources for model training
Here is an approximate list of sources that can be used, which is used in order to determine with great certainty the social profile of a person, who he is.

From social networks we take a profile, from CYAN - the cost of an apartment is approximately, "Head-Hunter", "Superjob" - this is the average salary for this person. I hope there are no Head Hunter representatives here, because they believe that it is not very good to take this data from them. However, this is the average salary for certain regions for certain types of activities for vacancies.
"Avito", "Avto.ru": very often people, when they light up their phone, they definitely have it (in a large number of cases) at least something on "Avito", or on "Avto.ru", or on another several sites from which you can understand who they are. If a stroller or a car was sold on this phone ... Rosstat and the Unified State Register of Legal Entities are still more registers with which you can rank the employer company - according to some formula, according to a model that any person can set (you can roughly determine the money of this person etc.).
Tinder helps collect data about the situation of people
Plus, there is such an interesting thing (as an option, very funny in the study) - this, again, is the collection of data from the Moscow Tinder using bots for this Tinder. The distance to people was determined, and then their approximate location was determined.
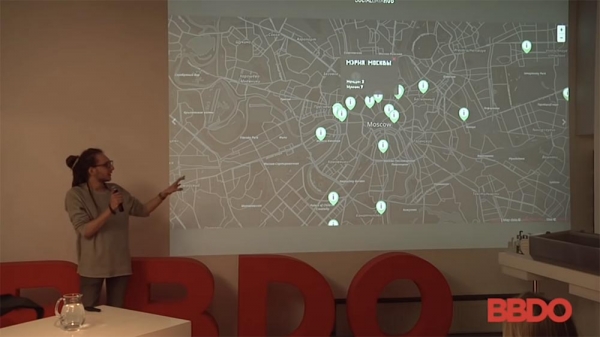
The purpose of this study was to determine the number of Tinder accounts on the territory of state institutions - in the Duma, the prosecutor's office, and so on. But you, as an advertiser, can imagine anything you like: it can be, for example, Starbucks or someone else ... That is, the number of people of the same Tinder who drink coffee from you, order something, are in stores. Regarding this geolocation: you can do this with any service.
Answer to a question from the audience:
- "Tinder"? You do not know? Tinder is a dating app where you look at photos (left-right) and this app shows you the distance to a person. If you get the distance to this person from three different points, you can approximately (+ 5-7 meters) determine the location. In this case, to determine on the territory of the prosecutor's office or the State Duma, it is not so difficult. But then again, it could be your store, it could be anything.
For example, we had such a case a long time ago (not a study) when we received from one of the mobile operators data on the density of the flow, data on the density of movement of cell points, and all this information was superimposed on the coordinates of billboards located on highways . And the task of the mobile operator is to determine approximately how many people pass by and potentially see this billboard advertising.
If there are billboard advertising experts here, you can say: it’s impossible to understand super-reliably - someone is driving, someone didn’t look, someone looked ... Nevertheless, this is an example of how 20 billion such polygons around Moscow, on which is the density of these people every hour along certain routes ... You can see what these people were passing by at any moment and roughly estimate the passenger flow.
Answer to a question from the audience:
- No one gives such data. We conducted such a study for one of the operators, this is an exclusively internal story, so, unfortunately, it is not presented in the form of pictures. But often large advertising agencies have no problem contacting the operator. At least in Moscow, there are many precedents when, for example, insurance companies turn to companies like GetTaxi, which provide depersonalized data about the age of the driver, how they drive (good - bad, reckless - no), in order to to predict policies and so on. Everyone is struggling with this, but at some internal level to give anonymous data - I think that no one has such a problem.
Image and Pattern Recognition
Go ahead. My favorite is image recognition. There will be a small piece about finding people by faces, but we basically do not take this part. We take exactly image recognition and determine what is in this image - the brand of the car, its color, and so on.

I have this funny example:

There was such a study on the search for tattoos in various social networks. Accordingly, the same can be applied to any brand, to any visual image, to almost any visual image. There are those that cannot be determined reliably enough (we do not take them).
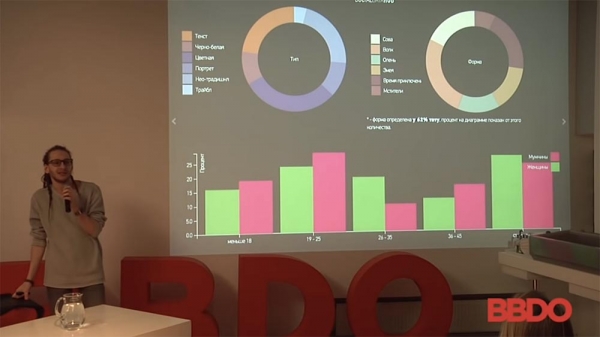
Here is my favorite. Car brands often apply for such a task, because their task, for example, is to find all the owners of some BMW X6, understand who they are, how they are related to each other, what they are interested in, and so on. This is to the question of what cars people are photographed with on social networks.

There was no filtering at all here: the subject is theirs, the car is not theirs; just such a breakdown of cars - age and so on. But visual pattern recognition is used quite often: this is the search for pregnant women, and the search for brand logos in some kind of mass media (who posts what).

My favorite case (which is used by various restaurants): what rolls are posted on a social network. A funny thing, but in fact it allows you to understand a lot of interesting things, firstly, about your own customers: who came to you and why they did it. Because it’s no secret that in sushi bars most people (I won’t say “girls”) take a picture to check in, take a picture of something, etc.
The brand can use it. The brand is interested in what kind of products it needs to beautifully photograph and upload, what kind of people came there. Such a thing can be done with almost anything, from food.
Video Pattern Recognition
Answer to a question from the audience:
- On video, no. We have it in test mode. We tried this technology, but it turns out that ... It recognizes the whole thing with video quite well, but we have not found an application for this anywhere. Bye. Except as an analysis of how much, what kind of video bloggers are talking somewhere ... There was such a study. How many of their faces meet, how often. But for brands, they have not yet figured out where to come up with it. Maybe someday it will come.
Again, this is food, it can be pregnant women, men (not pregnant), cars, anything.
As an option, there was such a New Year's study for one media outlet. Also far from advertising, but nonetheless. This is what food people post for the New Year:

It's also broken down by age. You can see such a correlation that young people mostly order food, adults mostly make the traditional table. A joke thing, but imagining it as a brand owner, you can evaluate a large number of things: who and how treats your products, what they write about it. Often, people do not always mention the brand itself in the text, and traditional analytical monitoring systems cannot always understand, find this mention of the brand solely because it is not mentioned in the text. Or it's misspelled in the text, no hash tags, or whatever.
Photos are visible. With a photograph, you can understand whether it is the central object of the frame, not the central object of the frame. Then you can see what this person wrote. But most often it is used as a search for a potential audience that drove certain cars and so on. And then we will do a lot of interesting things with these cars.
Bots are taught to imitate humans
There was also such an option for using people counting:

There is a variant of comparing people, when you need to find people from some photographs, understand their social profile, who they are. Again, back to the question that if we have a camera in an offline store, then this is a good enough way to understand who comes to you, who these people are, what they are interested in, what made them come to you.
Then the most interesting thing: if we collect their accounts on social networks, understand who these people are, what they are interested in, we can (as an option) make a bot similar to these people; this bot will start to live like these people and analyze what ads it sees on various social networks. This will allow you to accurately understand which brands are focused on this person. This is also a fairly common story when it is necessary not only to analyze who this person is and what his interests are, but also what kind of advertising your potential competitors or other interested people are targeting on him.

Analysis of connections in social networks

The next thing is interesting: it is an analysis of the relationships between people. Actually, the analysis of connections in the network itself, these network graphs - there is not a drop at all, nothing new, everyone knows this.

But the application to advertising tasks is the most interesting. This is a search for people who set trends, this is a search for people who distribute information according to certain criteria within this network. Let's say we are interested in the same owners of a certain BMW model. By bringing them all together, we can find those who hold public opinion in their hands. These are not necessarily automotive bloggers and so on. Usually these are simple comrades who sit in various publics, are interested in some kind of content and can, in a very short period of time, lure your brand or someone of interest to you into this area of responsibility, into the area of interest.
There is such an example here. We have some potential people, connections between people. Here orange are people, small dots are common groups, common friends.

If you collect all these connections between them, you can very clearly see that there are people who have a large number of common groups, mutual friends, they are there with each other ... And if we divide the same visualization into groups by interests, by content, which they distribute, how much they interact with each other ... Here you can see that the previous picture has become like this:

Here the groups are clearly distinguished by color. In this case, these are students of our master's program at the Higher School of Economics. Here you can see that purple / blue are those who love Transparency International, Open Russia, Khodorkovsky's publics. Bottom left - green, those who love United Russia.
You can see that the previous picture was like this (these are just connections between people), but it has become clearly demarcated. That is, all people are always connected with each other, they have the same interests, they are friends with each other. Some from above, others from below, there are still some comrades. And if each of these small subgraphs is visualized separately with different parameters and you can see the speed of content distribution (roughly speaking, who reposts what), you can find one or two people in each part who always hold public opinion in their hands, interacting with which, asking send a post of some kind or something else - you can get a response from all this interesting audience.
I have another such example. Also a graph: these are the employees of the BBDO Group, found in social networks as an example. It looks like uninteresting, big, green, connections between them ...

But I have a variant where groups are already built between them. Then, if anyone is interested, there is an interactive version - you can click and see.
Top right - those who love Putin. Here the purple ones are the designers; those who are fond of design, something so interesting and so on. Here, the white pieces are the management team (apparently, I understood it that way); these are people who, in general, are not connected in any way, but work in approximately the same positions. The rest is their common groups, connections and so on.
Brands do not need bloggers, but opinion leaders
We take these people and find - then the advertising agency, the advertising company decides for itself: it can give money to this person so that he somehow interacts with this content, something else, or direct their specific advertising campaign to them. It’s also used quite often, especially now, because all brands want to work with bloggers, they want their content to be promoted, and advertising agencies don’t really want to contact (well, it happens).
And the real way out of this situation is to find people who are not bloggers, not beauty bloggers, but for example, some real beings who interact with this brand, can write in some miserable public of their Mail.ru Answers, get a certain number of views. These people who are constantly interested in this person's content, they will spread the whole thing, and the brand will get its involvement.
The second option, how to use this technology now, is quite relevant - this is the search for bots, my favorite. This is a reputational risk for your competitors, and the ability to weed out irrelevant people from the advertising campaign, and anything (both deleting comments, and searching for connections between people). I have such an example, it also has a large interactive one - you can move it. These are the connections of people who wrote comments in the Lentach community.
Such an example is so that you understand how well and simply bots are visible; and you do not need to have any technical knowledge. So, Lentach released a post about the FBK investigation about Dmitry Medvedev, and certain people began to write comments. We gathered all the people who wrote comments - these people are green. Now I will move:

People are green (who wrote comments). They are here, they are here. The blue dots between them are their common groups, the yellow dots are their common followers, friends, and so on. This is where most of the people are connected. Because, whatever the theory of three, four, five handshakes, all people are interconnected in social networks. There are no people who are separated from each other. Even my socially phobic friends who use Vkontakte exclusively to watch videos are still subscribed to some publics that are the same as us.
Navalny also uses bots. Everyone has bots
The bulk of the people (here it is, here) are interconnected. But there is such a small group of comrades who are friends exclusively with each other. Here they are, little green ones, here are their mutual friends and groups. They even fell off separately here:

And by a happy coincidence, it was these people who wrote exactly under this post: “Navalny has no evidence,” and so on, they wrote the same comments. Of course, I don't jump to conclusions. But nevertheless, I had another post on Facebook, when there was a debate between Lebedev and Navalny, I analyzed the comments in the same way: it turned out that all the people who wrote “Lebedev is shit”, they did not go to social networks for the last four months, not subscribed to any of the publics, suddenly went to this particular post, wrote this particular comment and left. Conclusions, again, cannot be drawn from here, but someone from Navalny's team wrote a comment to me that they do not use bots. Well, okay!
Closer to advertising, closer to the brand. Everyone has bots now! We have them, our competitors have them, and someone else has them. They must be thrown out or left so that they live well; on the basis of such data (points to the previous slide) to perfect them so that they look like real people and only then use them. Although using bots is bad! However, it is a fairly common story...
In automatic mode, such a thing allows you to filter out from your analysis people who are irrelevant to the analysis, people who should not be included in the sample, should not be included in this study. Very often used. Again, not all car owners are truly car owners. Sometimes only people who potentially have a car are interesting, who sit in some groups, communicate with someone, they have a certain audience there.
Analysis of facts and opinions
The next one I have is also my favorite. This is an analysis of facts and opinions.

Mentioning your brand in various sources is now able to do everything. There is no secret in this. And everyone seems to be able to count the tone... Although I personally think that the tone metric itself is not very interesting, because when you come and tell the client, “Man, you have 37% neutral,” and he says that, “ Wow! Cool!" Therefore, it would be more interesting to move a little further: from assessing sentiment to assessing the opinions of what they say about your product.
And this is also a very interesting thing, because ... I personally think that there can be no neutral messages, because if a person writes something in a public space, this message is colored in any way. So I personally have never seen a neutral message mentioning a brand. Usually it's some kind of dirt.
If we take a large number of these messages (there may be millions, 10 million), we single out the main idea from each message, combine them, we can understand quite reliably what people say about this brand, what they think. "I don't like the packaging", "I don't like the consistency" and so on.
What do they think about Transaero, Chupa Chups and the President of the United States
I have a funny example: this is an infographic about what users of social networks would do with Transaero after its bankruptcy.

There are many interesting examples: burn, kill, deport to Europe, there were even 2% who wrote - "Send them to Syria for military action." Moving on from the funny thing, it could be almost any brand, from my favorite dog food to some cars. Who doesn't like packaging, who doesn't like real things - you can always work with it, you can always take it into account. There are a large number of examples when people almost changed the production of their products, because they wrote in social networks that lollipops are not round enough or they are not sweet enough.
There is another funny example. Guess what comments and about whom?

For some reason, now it is the analysis of opinions, the analysis of facts extracted from messages, that is not very used, not very widespread. Although this technology is not super secret, there is practically no know-how in this at all, because from the comments of people to extract the subject, predicate and group them - it does not take a genius of computational linguistics to do this. This is not so difficult to do. But I hope that in the next couple of years people will start using it, because ... It will be cool - this is such an automatic feedback! You always know what they say about you. Well, you understand that this is about the President of the United States.
Answer to a question from the audience:
- Yes, it's Facebook in English. They are here translated into Russian. Somewhere it was written.
Big Data and political technologies
In fact, I have many different interesting examples of politicians about Trump and about everyone else, but I decided not to bring them here. But there is one political example.
These are elections to the State Duma. When were you? Last year? Almost a year and a half ago.
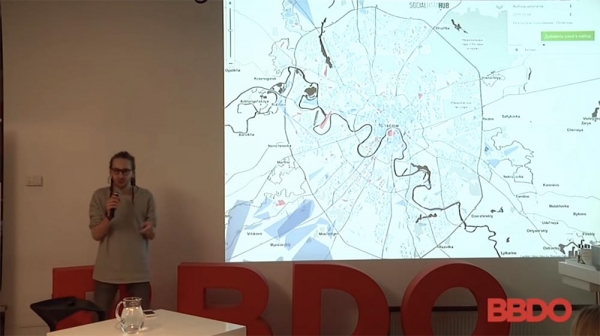
Here are people who managed to determine their exact location, up to a certain geopoint, in order to understand which electoral PEC they fall into. And then from these people only those who expressed their definite opinion are taken, for whom they will go to vote.
From the point of view of political technologies, this is not very correct, because the whole thing needs to be normalized for population density and so on. Nevertheless, the blues here are going to vote for you know who, the reds are going to vote for the opposition comrades, who, by the way, were not so many.
I personally think that Big Data will not reach political technologies very soon, but, as an option, the candidate is also a brand. And this is also, to some extent, an analysis of facts and opinions about your brand, and a rather interesting thing, because you can understand in real time who is doing what there. I know several cases from the BBC, when they monitored social networks in real time in some kind of broadcast: such and such a response, people write about it, ask such and such a question - and it's great! I think it will be applied very soon, because it is interesting for everyone.
Brand Position Modeling

Next I have the modeling of brand positions. A small, short piece about how various metrics (not likes of subscribers in social networks, but with the help of complex metrics, interest in content, time spent obtaining metrics) can be used to rank brands.

I have an example of a “farm” for a certain one. Here, small round circles are internal, bright - this is the amount of text content that the brand itself creates, a large round circle - this is the amount of photo and video content that the brand itself creates.
Proximity to the center shows how this content is interesting to the audience. There is a large model, there are a lot of all sorts of parameters: likes, reposts, response time, who shared there on average ... Here you can see: there is a wonderful Kagocel, which pumps a huge amount of money into creating its own content, and due to this they are quite close to the center. And there are comrades who also create their own content, but the audience is not interested in it. This is not a very adequate example, because all these accounts are practically dead.
Yegor Creed is loved more than Basta

Unfortunately, the rest ... from what to show ... Here, there are also Russian rappers, as an option, from real companies.
What's the plus? The fact that a company can put almost anything into such a model, starting from the average salary of subscribers who are in your brand; any model they like. Because each advertising agency calculates its own metrics differently, brands calculate their own metrics differently.
There is also one here - Basta, who generates a large amount of content, but at the same time is on the periphery, because this content, apparently, is not very interesting to the audience. Again, I'm not judging. But nevertheless, there is Yegor Creed, who, according to social networks, is generally almost the best performer of our time, and at the same time publishes only his personal photos. Nevertheless, he has a large number of subscribers: there are about a million of them. I don't remember the exact number; I remember that the percentage of engagement of these people is much higher than 85%, that is, for a million subscribers, he receives 850 thousand responses from these real people - this is real crazy. This is true.

Answers to questions from the audience:
How long did it take to build the rapper analysis model?
- Each has its own target audience, its own interests of these people, for each are calculated... All this is normalized by the distance to the center approximately, their radial position is not important (it is simply smeared here for beauty so that they do not run into each other). Only approximate proximity to the center is important. This is the model we are using. For example, I like the circle more, someone does it in the form of a semicircle.
- This model was compiled quickly, in two hours, three (yes, one person). Here, only metrics were inserted: what we multiply by what, add up, then it is somehow normalized. Depends on the model. There are people who are interested in the average salary (this is not a joke) of their subscribers. And for this you need to find their contacts, “Avito”, calculate all this, multiply it. It happens that this is considered for a long time, but specifically this (points to the previous slide) - there are very simple parameters here: subscribers, reposts, and so on. It was done for about two or three hours. Accordingly, this thing is then updated in real time, it can be used.
Now the most interesting. I have everything with examples, because it is not interesting to talk alone for a long time. And I hope that you will now ask questions, and we will move further, in fact, from topic to topic, because I have such examples of how technologies can be used and so on ...
Answers to questions from the audience:
- I had one and only personal case with one, if I may say so, “near the casino”, when the camera was set up there, faces were recognized and so on. The percentage of recognized people is definitely quite large - what we have, what our competitors have. But it's actually quite interesting. I see this as an interesting thing: you can understand who these people are and predict quite well why exactly they came here, what has changed in their lives so much that they decided to come to the casino. But about specific types of business... If you put such a thing in a pharmacy, then there is no point - you can’t predict why a person came to a pharmacy.
The global task here was to build a model in order to understand when a person would potentially want to be interested in your brand, in order to give him advertising not after he bought something (as is happening now), but to give him advertising “in the forecast” when it all happens. With such a "near casino" it was interesting; there turned out to be a rather interesting percentage of these people - why: someone suddenly received a promotion, someone else something - such interesting insights. But with some stores, with retail, with a store of some pills, it seems to me that it will not be very correct.
Is Big Data used offline?
- It was offline. You just need to understand exactly, approximately - this model will converge, it will not converge. Again, with sparkling water… I’m actually interested in everything, but I personally don’t understand how much, how the profiles of these people, their behavior can depend on when they want to buy bottled water. While this may be true, I don't know.
How many social media accounts are open?
- We specifically have 11 social networks - these are Vkontakte, Facebook, Twitter, Odnoklassniki, Instagram and some little things there (I can look at the list, such as Mail.ru and so on). “Vkontakte” we definitely have a copy of all these comrades. We have people on VKontakte - this is 430 million of all who have ever existed (of which about 200 million are constantly active); there are groups, there are connections between these people, and there is content that interests us (text), and part of the media, but very small ... Roughly speaking, we look at this picture: if there are faces, we save them, if there are memes, we save them we do not save, because even we would not have enough to save media content.
There is a Russian-language Facebook. Somewhere now, 60-80% are Odnoklassniki, in a couple of months we will probably get them all to the end. Russian Instagram. For all these social networks there are groups, people, connections between them and text.
- About 400 million people. There is a subtlety: there are people who do not have a city (they are potentially Russian / non-Russian); of which, on average, on social networks, here - on Vkontakte, 14% of closed accounts, on Facebook, I don’t know the exact figure.
- We also do not save media on Instagram - only if there are faces there. We do not save such (other) media content. Usually interesting: only text, connections between people; All. The most frequent research on Instagram is the usual research on the audience: who these people are, as well as, most importantly, the connection of these people with other social networks. Find the profile of this person in Vkontakte and Facebook in order to calculate his age and so on.
- There is no need to take all the rest yet - simply because there are no customers. Regarding the language: we have Russian, English, Spanish, but still it is used only for brands from Russia; well, or companies that lead them from Russia.
- We poll people every day in many, many, many threads: we collect data by collecting the web, and we update these indicators using Api. In 2-3 days, you can go through the entire Vkontakte by going through them; somewhere in a week you can go through the entire Facebook, understanding who has what has been updated there, what is not. And then we will reassemble these people separately: what exactly has changed, write down this whole story. In my memory, it's very rare that someone's old social media profile has been used for some real business task. This was the time when one politician applied, and his task was to understand what kind of people come to the headquarters, who these people were 6-8 months ago (whether they deleted their profile, but in fact for another candidate, ballots came spoil).
And a couple of times - personal stories, when someone's photos were published in the public domain. It was necessary to find connections, etc. Unfortunately, it is a pity, but we cannot testify in court, because our database is legally illiquid.
- MongoDB storage is my favorite.
Social networks are trying to fight data collection
- Usually, we only upload a list of these accounts to advertisers, and then they use the standard one ... That is, on social networks, on Vkontakte, you can specify a list of these people.
But Facebook uses purchased cookies. We don’t work with cookies ourselves, but there were several stories when the advertiser himself gave some people, we interacted with them - they have these networks, with teaser, not teaser advertising, these cookies. You can tie - no problem! But I don't really like these things because I don't think it's very reliable. It’s purely in my opinion, it’s like TNS, which “tracks” TVs - it’s not clear whether you watch this TV, don’t watch it, you wash the dishes while your TV is on ... And it’s the same here: I very often google something in Internet, but that doesn't mean I want to buy it.
- If you use some standard contextual advertising network: I had several stories when we unloaded these people for them, tried using their interfaces to bind them with "cookies" on their sites. But I don't really like that kind of stuff.
The formula for calculating the salary of an Internet user
- The general formula for the average salary: this is the region where a person lives, this is the category of business in which he works (that is, the company that is his employer), then his position in this company is taken, and the average salary in this position is pretended ... Average salary taken from Head Hunter and Superjob (and there are several other sources) for a given vacancy in a given region and for a given business context.
With "Avito" and "Avto.ru" additional parameters are usually taken if a person lit up the phone. With "Avito" you can see what kind of things a person sells - expensive, inexpensive, used, not used. With "Avto.ru" you can see if he has a car - he owns, does not own. This is somewhere less than 20% of people who accidentally dropped their phone somewhere, and their account can be tied up with this data.
How much does the data collection company operate?
- The amount of stored photos in petabytes is 6,4. I can’t say for sure the growth rate now, because in 2016 we started recording “periscopes” and started recording video a little bit.
I can't say exactly when it was zero. We moved from company to company - all these are such long stories. But I can say that VK, Facebook, Instagram and Twitter are all a matter (people, groups and connections between them) with text and content - this is actually not so much data, hardly even a petabyte plucked up. I think it's 700 gigabytes, probably 800.
Helping clients to identify the current niche, where to "dig"?
- When a client comes, we suggest such things to him, but we ourselves, like Google Trends, do not do such things.
- We had several near-sociological stories, with electoral, pre-election history - we analyzed it all. With brands and the assessment of opinions about brands, almost always everything converges. Here are the election-pre-election stories - no (with an assessment of which candidate should win). Who is wrong here - we, or those who believe in VTsIOM - I do not know.
- Usually we take these control results from the brand itself, they take it from their comrades who order research - telephone research, marketing research, and so on. Plus, this whole thing can be checked with elementary things: someone answered the mailing list, someone polled ... If it is a large brand (Coca-Cola, for example), they always have a million or two of their own internal reviews from customers - these are not only comments on social networks and some opinions; these are some internal systems, reviews and so on.
The law does not “know” what personal data is!
- We analyze exclusively open data sources, we never get into any dirty rubbish. Our model is based on the fact that we store all open data in some public data centers, rent it somewhere else, and analyze it at home, on the territory of offices, in our servers, and this does not go anywhere beyond the territory.
But our open data legislation is very vague.
We do not have a clear understanding of what is open data, what is personal data - there is this 152nd Federal Law, but still ... They think how? Now, if I have your name and your phone number in one database, your phone number and your e-mail in another database, and your e-mail and your car in the third one; All of this is like non-personal information. If all this is put together, it seems like by law it will become personal data.
We get around this in two ways. The first is that we put a server with software on the client, and then this data does not go beyond its territory, and then the client is responsible for the distribution of this personal data, not personal data, and so on. Or the second option: if this is some kind of story where you have to sue the social network or something else ...
We had such a study when we collected (there was a United Russia primaries) for LifeNews the accounts of these comrades and watched what kind of porn they liked. It was funny, but nonetheless. We sell it as our own, personal opinion, without legally disclosing in the documents what we analyzed - Unified State Register of Legal Entities, salary, social networks; we sell expert opinion, and then on the sidelines we explain to the person what we analyzed and how.
There were several stories, but they were connected with some public commercial projects. For example, we have a free non-commercial project for those who ride longboards (such boards are long): the task was to collect people's publications - when someone posts "I went to Gorky Park to ride." And now he should get on the map, and people around him can see that someone is next to him. VK butted heads with us on this topic for a very long time, because they did not like that we publish this information without people's permission. But then the matter did not reach the court, because we added to the rules within several large communities that the data can be used by third parties, agencies, companies, analyzes, etc. Of course, it was not particularly ethical, but nevertheless. - We just realized it just in time and started selling expert opinion to everyone.
Do you work with educational institutions?
- We cooperate with educational institutions, yes. We have a whole range: we have a master's program at the Higher School, we cooperate with other universities. We love universities!
- I have my contacts - you can write. And a link to the presentation, if anyone is interested - there are all these examples, you can move it.
- If you know the phone, mail - this is almost a XNUMX% option, no one will remove it. If there is no phone, this is usually a picture; if there is no picture, this is the year, place of residence, work. That is, by year, place of residence and work, almost everyone can always be identified quite subtly. But this, again, is a question about the task.
We have, say, a client who sells Internet TV. Here, someone bought a subscription to these “Game of Thrones” from them, and the task is to find these people on social networks from their CRM, and then find potential ones from their area of influence. I just mean that they have, say, a first name, a last name and an e-mail ... And then it is very difficult to do something. By e-mail'u you can find approximately in most cases people.
- According to the composition of friends, we usually “match” people with social networks, but this is not always correct. Not that it's not always right - it doesn't always work. Firstly, this requires a lot of labor, because this operation (by matching people) will have to be carried out first for each of the friends - to understand whether they switched from social networks or not. And then - for no one is an unknown fact that we have the same friends on Vkontakte, we have other friends on Facebook. Not at all, but at me, for example, so; and it is the same for most people.
How is the most complete data collected?
- Installing software to the client on his side. A server is set up for them, which takes only public data from us, and inside processes their personal data. An NDA is concluded with the client. This, of course, is not very correct that they pass it on to us, but the legal responsibility lies with the client - well, that is, installing software for him, or transferring anonymous data. But this was very rare, because - correct, incorrect anonymization - in most cases, the dependence between these people is lost.
Who buys facial recognition software?
- We are actually coming here because we have the main software that we sell - this is face search, relationship analysis - and we sell it to government agencies. And a year and a half ago, we decided that we would put all these stories into advertising, marketing, and the public market - this is how the Social Data Hub, a commercial legal entity, was formed. And here we are just now coming. We’ve been hanging out here for a year and a half, trying to explain to people that people shouldn’t be given uploads with a mention that they need to be given answers to questions, that they don’t need tonality and so on. So it's hard to say where...
- (Who do you mean?) To all the comrades who need to look for terrorists, pedophiles.
I can say right away (this will be the next question): no teachers, according to our data, were imprisoned for reposting. - In Vkontakte - 14%, on Facebook there is no closed profile as such (there is a closed list of friends and so on). And the most interesting thing is that I just wrote a message - now they will count and say.
Don't post anything you'd be embarrassed about!
- Do not post anything on social networks that you will be ashamed of - I personally am guided by this. Although I had many personal ones, because I swear on Facebook. Well, there was and was something to do ... Do not post anything for which you will be ashamed! If you are going to work somewhere in the Public Chamber later, yes, it is better not to comment. If you are not going to do this - by and large, no one cares. I can only assure you that no one reads your personal correspondence, and all this is forcing the whole story ...
Every week someone definitely comes to me and says: “Here, my friend’s photos were uploaded to the public by some anonymous person! Help!" By the way, never post anything to anonymous publics.
- I don’t know how other monitoring systems are – we will definitely take this into account that the mention of the brand was negative, God forgive me… But I can say that all sorts of near-state comrades are only interested in people who have more than 5 thousand audience, and their public opinion can be on someone then influence. In my practice, it has never happened that an HR agency that orders a profile assessment from us says: “Whoever likes Navalny, don’t take anyone to me!”
About the publication of the results. How many people are involved in research?
- Of the top 10 advertising companies, seven are now publishing. It’s hard to say: when we started it a year and a half ago… We have several people in each area – there are several people in banks, there are several people in HR, there are several people in advertisers. And now we are thinking about who it is more profitable to go to first, for whom we need to start making some kind of interfaces ...
- (about the number of people per segment of the market) No more than 25 people, because we did not rape anyone.
- In general, in principle, these technologies from the market are used, I think, by more than 50%. Who is in advertising campaigns, who is in some kind of internal analytics. I would say that 40 percent use it in internal analytics, 50-60% sell it for end brands. But it already depends on the advertising companies themselves. You see, someone reports simply for the money spent, twisted advertising, and someone writes, really how many people they brought, what kind of audience ... I would say so, but I could be wrong - I don’t really imagine how all these comrades work. I know only in quantitative data.

Some ads 🙂
Thank you for staying with us. Do you like our articles? Want to see more interesting content? Support us by placing an order or recommending to friends, , a unique analogue of entry-level servers, which was invented by us for you: (available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper in Equinix Tier IV data center in Amsterdam? Only here in the Netherlands! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - from $99! Read about
Source: habr.com
