

In the fall of 2019, a long-awaited event took place in the Mail.ru Cloud iOS team. The main database for persistent storage of application state has become quite exotic for the mobile world (LMDB). Under the cut, your attention is invited to its detailed review in four parts. First, let's talk about the reasons for such a non-trivial and difficult choice. Then let's move on to the consideration of three whales at the heart of the LMDB architecture: memory-mapped files, B + tree, copy-on-write approach for implementing transactional and multiversioning. Finally, for dessert - the practical part. In it, we will look at how to design and implement a base schema with several tables, including an index one, on top of the low-level key-value API.
Content
3.1.
3.2.
3.3.
4.1.
4.2.
4.3.
1. Implementation motivation
Once a year, in 2015, we took care of taking a metric, how often the interface of our application lags. We didn't just do this. We have more and more complaints about the fact that sometimes the application stops responding to user actions: buttons are not pressed, lists do not scroll, etc. About the mechanics of measurements on AvitoTech, so here I give only the order of numbers.
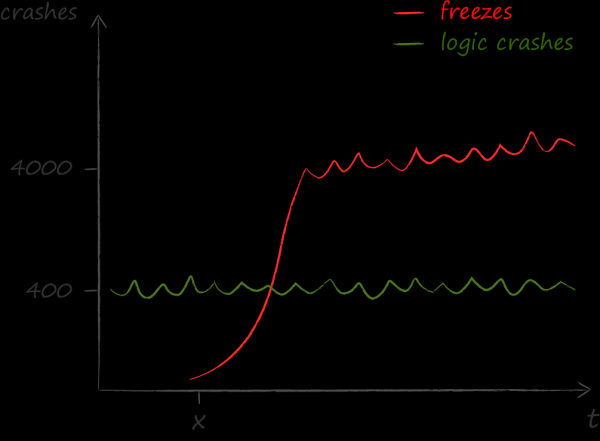
The measurement results became a cold shower for us. It turned out that the problems caused by freezes are much more than any other. If, before realizing this fact, the main technical indicator of quality was crash free, then after the focus on freeze free.
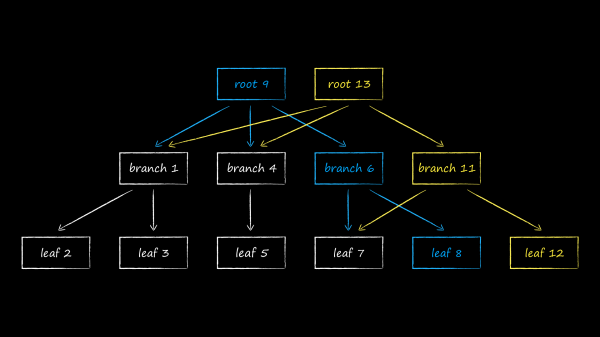
Having built and having spent и analysis of their causes, the main enemy became clear - heavy business logic executing in the main thread of the application. A natural reaction to this disgrace was a burning desire to shove it into work streams. For a systematic solution of this problem, we resorted to a multi-threaded architecture based on lightweight actors. I dedicated her adaptations for the iOS world in the collective twitter and . As part of the current story, I want to emphasize those aspects of the decision that influenced the choice of the database.
The actor model of system organization assumes that multithreading becomes its second essence. Model objects in it like to cross thread boundaries. And they do this not sometimes and in some places, but almost constantly and everywhere.
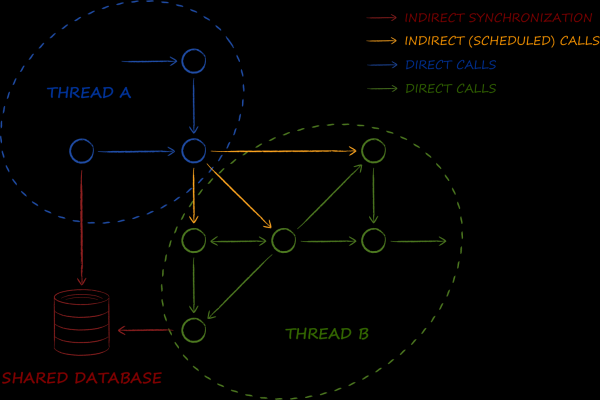
The database is one of the cornerstone components in the presented diagram. Its main task is to implement a macro pattern . If in the enterprise world it is used to organize data synchronization between services, then in the case of an actor architecture, data between threads. Thus, we needed such a database, working with which in a multi-threaded environment does not cause even minimal difficulties. In particular, this means that the objects derived from it must be at least thread-safe, and ideally not mutable at all. As you know, the latter can be used simultaneously from several threads without resorting to any kind of locks, which has a beneficial effect on performance.
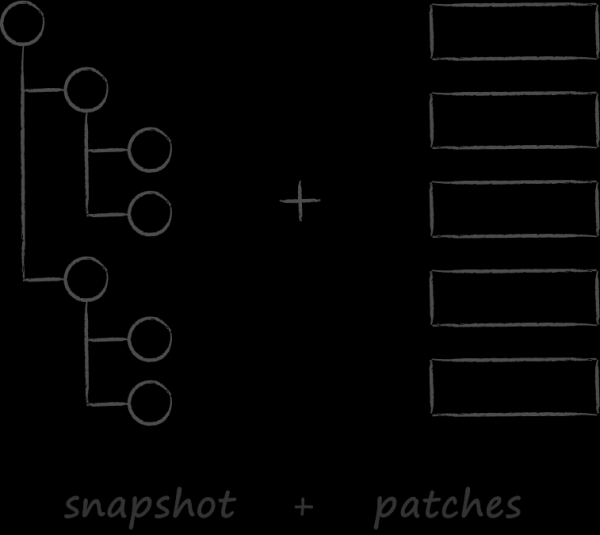 The second significant factor that influenced the choice of the database was our cloud API. It was inspired by the git approach to synchronization. Like him we aimed at , which looks more than appropriate for cloud clients. It was assumed that they would only once pump out the full state of the cloud, and then synchronization in the vast majority of cases would occur through rolling changes. Alas, this possibility is still only in the theoretical zone, and in practice, clients have not learned how to work with patches. There are a number of objective reasons for this, which, in order not to delay the introduction, we will leave out of the brackets. Now much more interesting are the instructive results of the lesson about what happens when the API said "A" and its consumer did not say "B".
The second significant factor that influenced the choice of the database was our cloud API. It was inspired by the git approach to synchronization. Like him we aimed at , which looks more than appropriate for cloud clients. It was assumed that they would only once pump out the full state of the cloud, and then synchronization in the vast majority of cases would occur through rolling changes. Alas, this possibility is still only in the theoretical zone, and in practice, clients have not learned how to work with patches. There are a number of objective reasons for this, which, in order not to delay the introduction, we will leave out of the brackets. Now much more interesting are the instructive results of the lesson about what happens when the API said "A" and its consumer did not say "B".
So, if you imagine git, which, when executing a pull command, instead of applying patches to a local snapshot, compares its full state with the full server one, then you will have a fairly accurate idea of \u500b\u1bhow synchronization occurs in cloud clients. It is easy to guess that for its implementation it is necessary to allocate two DOM trees in memory with meta-information about all server and local files. It turns out that if a user stores XNUMX thousand files in the cloud, then to synchronize it, it is necessary to recreate and destroy two trees with XNUMX million nodes. But each node is an aggregate containing a graph of subobjects. In this light, the profiling results were expected. It turned out that even without taking into account the merge algorithm, the very procedure of creating and then destroying a huge number of small objects costs a pretty penny. The situation is aggravated by the fact that the basic synchronization operation is included in a large number of user scripts. As a result, we fix the second important criterion in choosing a database - the ability to implement CRUD operations without dynamic allocation of objects.
Other requirements are more traditional, and their full list is as follows.
- Thread safety.
- Multiprocessing. Dictated by the desire to use the same database instance to synchronize state not only between threads, but also between the main application and iOS extensions.
- The ability to represent stored entities as non-mutable objects.
- Lack of dynamic allocations within CRUD operations.
- Transaction Support for Basic Properties Key words: atomicity, consistency, isolation and reliability.
- Speed on the most popular cases.
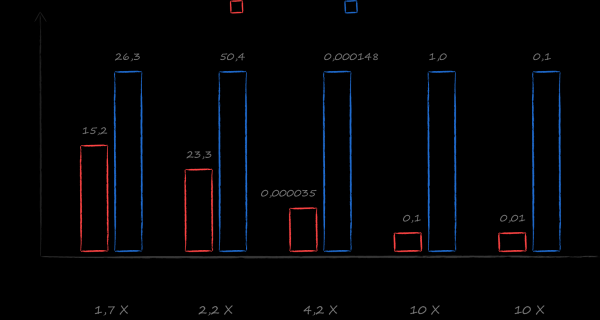
With this set of requirements, SQLite was and still is a good choice. However, as part of the study of alternatives, I came across a book . Under her leadership, a benchmark was written that compares the speed of work with different databases in real cloud scenarios. The result exceeded the wildest expectations. On the most popular cases - getting a cursor on a sorted list of all files and a sorted list of all files for a given directory - LMDB turned out to be 10 times faster than SQLite. The choice became obvious.
2. LMDB Positioning
LMDB is a library, very small (only 10K lines), which implements the lowest fundamental layer of databases - storage.
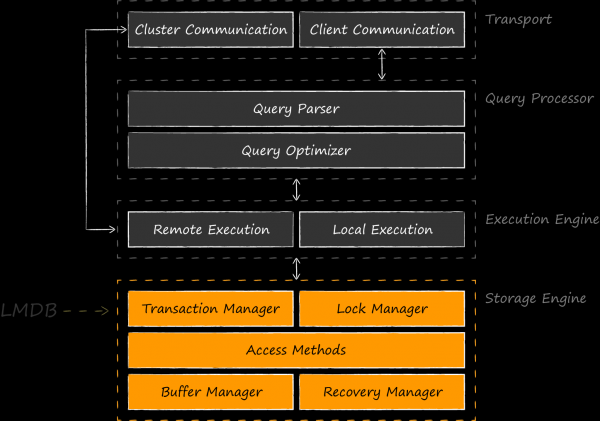
The above diagram shows that comparing LMDB with SQLite, which implements even higher levels, is generally not more correct than SQLite with Core Data. It would be more fair to cite the same storage engines as equal competitors - BerkeleyDB, LevelDB, Sophia, RocksDB, etc. There are even developments where LMDB acts as a storage engine component for SQLite. The first such experiment in 2012 author LMDB . turned out to be so intriguing that his initiative was picked up by OSS enthusiasts, and found its continuation in the face of . In January 2020 the author of this project is Den Shearer him to LinuxConfAu.
The main use of LMDB is as an engine for application databases. The library owes its appearance to the developers , who were strongly dissatisfied with BerkeleyDB as the basis of their project. Pushing away from the humble library , Howard Chu was able to create one of the most popular alternatives of our time. He devoted his very cool report to this story, as well as to the internal structure of LMDB . Leonid Yuriev (aka ) from Positive Technologies in his talk at Highload 2015 . In it, he talks about LMDB in the context of a similar task of implementing ReOpenLDAP, and LevelDB has already undergone comparative criticism. As a result of the implementation, Positive Technologies even got an actively developing fork with very tasty features, optimizations and .
LMDB is often used as an as is storage as well. For example, the Mozilla Firefox browser it for a number of needs, and, starting from version 9, Xcode its SQLite to store indexes.
The engine also caught on in the world of mobile development. Traces of its use can be in the iOS client for Telegram. LinkedIn went one step further and chose LMDB as the default storage for its homegrown data caching framework, Rocket Data, about which in an article in 2016.
LMDB is successfully fighting for a place in the sun in the niche left by BerkeleyDB after the transition under the control of Oracle. The library is loved for its speed and reliability, even in comparison with its own kind. As you know, there are no free lunches, and I would like to emphasize the trade-off that you will have to face when choosing between LMDB and SQLite. The diagram above clearly demonstrates how the increased speed is achieved. First, we do not pay for additional layers of abstraction on top of disk storage. Of course, in a good architecture, you still cannot do without them, and they will inevitably appear in the application code, but they will be much thinner. They will not have features that are not required by a specific application, for example, support for queries in the SQL language. Secondly, it becomes possible to optimally implement the mapping of application operations to requests to disk storage. If SQLite comes from the average needs of an average application, then you, as an application developer, are well aware of the main load scenarios. For a more productive solution, you will have to pay an increased price tag for both the development of the initial solution and its subsequent support.
3. Three whales LMDB
After looking at the LMDB from a bird's eye view, it's time to go deeper. The next three sections will be devoted to the analysis of the main whales on which the storage architecture rests:
- Memory-mapped files as a mechanism for working with disk and synchronizing internal data structures.
- B+-tree as an organization of the stored data structure.
- Copy-on-write as an approach to provide ACID transactional properties and multiversioning.
3.1. Whale #1. Memory-mapped files
Memory-mapped files are such an important architectural element that they even appear in the name of the repository. Issues of caching and synchronizing access to stored information are entirely at the mercy of the operating system. LMDB does not contain any caches within itself. This is a conscious decision by the author, since reading data directly from mapped files allows you to cut a lot of corners in the implementation of the engine. Below is a far from complete list of some of them.
- Maintaining the consistency of data in the storage when working with it from several processes becomes the responsibility of the operating system. In the next section, this mechanic is discussed in detail and with pictures.
- The absence of caches completely relieves LMDB of the overhead associated with dynamic allocations. Reading data in practice is setting the pointer to the correct address in virtual memory and nothing more. Sounds like fantasy, but in the repository source, all calloc calls are concentrated in the repository configuration function.
- The absence of caches also means the absence of locks associated with synchronization to access them. Readers, of which an arbitrary number can exist at the same time, do not encounter a single mutex on their way to the data. Due to this, the read speed has an ideal linear scalability in terms of the number of CPUs. In LMDB, only modifying operations are synchronized. There can only be one writer at a time.
- A minimum of caching and synchronization logic saves the code from an extremely complex type of errors associated with working in a multi-threaded environment. There were two interesting database studies at the Usenix OSDI 2014 conference: и . From them you can get information about both the unprecedented reliability of LMDB, and the almost flawless implementation of the ACID properties of transactions, which surpasses it in the same SQLite.
- The minimalism of LMDB allows the machine representation of its code to be completely placed in the L1 cache of the processor with the resulting speed characteristics.
Unfortunately, in iOS, memory-mapped files are not as rosy as we would like. To talk about the disadvantages associated with them more consciously, it is necessary to recall the general principles for implementing this mechanism in operating systems.
General information about memory-mapped files
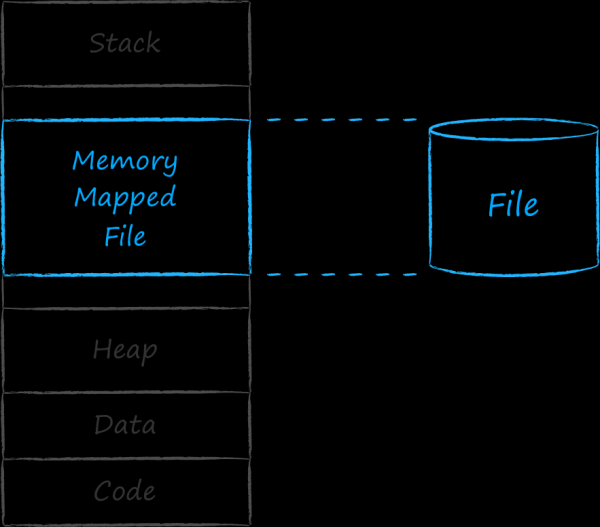 With each executable application, the operating system associates an entity called a process. Each process is allocated a contiguous range of addresses in which it places everything it needs to work. The lowest addresses contain sections with code and hardcoded data and resources. Next comes the upward-growing block of dynamic address space, well known to us as the heap. It contains the addresses of entities that appear during the program's operation. At the top is the area of memory used by the application stack. It either grows or shrinks, in other words, its size also has a dynamic nature. So that the stack and heap do not push and interfere with each other, they are separated at different ends of the address space. There is a hole between the two dynamic sections at the top and bottom. The addresses in this middle section are used by the operating system to associate with a process of various entities. In particular, it can map a certain continuous set of addresses to a file on disk. Such a file is called a memory-mapped file.
With each executable application, the operating system associates an entity called a process. Each process is allocated a contiguous range of addresses in which it places everything it needs to work. The lowest addresses contain sections with code and hardcoded data and resources. Next comes the upward-growing block of dynamic address space, well known to us as the heap. It contains the addresses of entities that appear during the program's operation. At the top is the area of memory used by the application stack. It either grows or shrinks, in other words, its size also has a dynamic nature. So that the stack and heap do not push and interfere with each other, they are separated at different ends of the address space. There is a hole between the two dynamic sections at the top and bottom. The addresses in this middle section are used by the operating system to associate with a process of various entities. In particular, it can map a certain continuous set of addresses to a file on disk. Such a file is called a memory-mapped file.
The address space allocated to a process is huge. Theoretically, the number of addresses is limited only by the size of the pointer, which is determined by the bitness of the system. If physical memory were assigned to it 1-in-1, then the first process would gobble up the entire RAM, and there would be no question of any multitasking.
However, we know from experience that modern operating systems can run as many processes as you want at the same time. This is possible due to the fact that they allocate a lot of memory to processes only on paper, but in reality they load into the main physical memory only that part that is in demand here and now. Therefore, the memory associated with the process is called virtual.
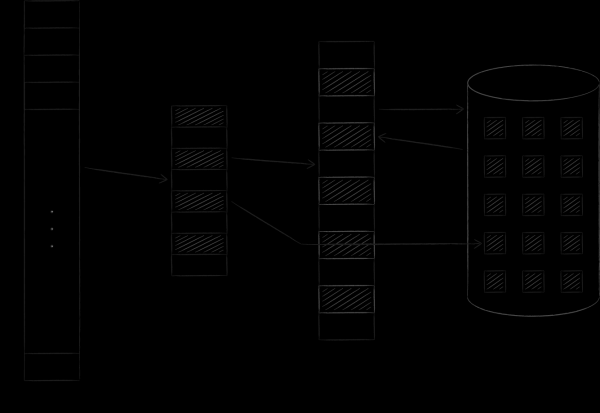
The operating system organizes virtual and physical memory into pages of a certain size. As soon as a certain page of virtual memory is in demand, the operating system loads it into physical memory and puts down a correspondence between them in a special table. If there are no free slots, then one of the previously loaded pages is copied to disk, and the requested one takes its place. This procedure, which we will return to shortly, is called swapping. The figure below illustrates the described process. On it, page A with address 0 was loaded and placed on the main memory page with address 4. This fact was reflected in the correspondence table in cell number 0.
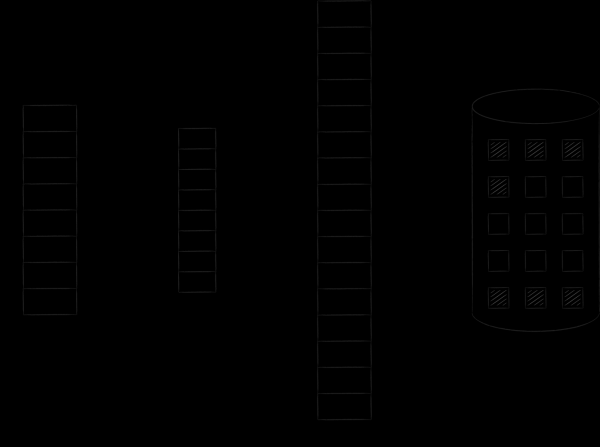
With memory-mapped files, the story is exactly the same. Logically, they are supposedly continuously and entirely placed in the virtual address space. However, they get into physical memory page by page and only on demand. Modification of such pages is synchronized with the file on disk. Thus, you can perform file I / O, simply working with bytes in memory - all changes will be automatically transferred by the operating system kernel to the original file.
The image below demonstrates how LMDB synchronizes its state when working with the database from different processes. By mapping the virtual memory of different processes onto the same file, we de facto oblige the operating system to transitively synchronize certain blocks of their address spaces with each other, which is where LMDB looks.
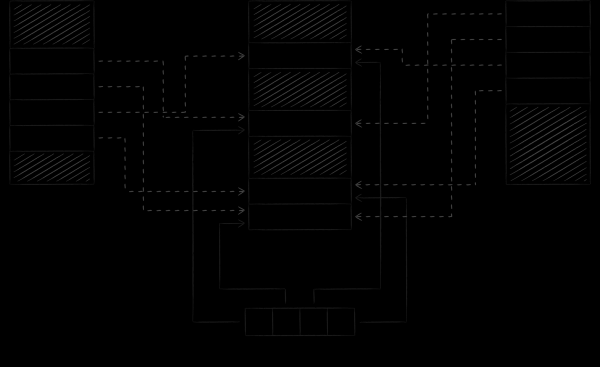
An important nuance is that LMDB modifies the data file by default through the write system call mechanism, and the file itself displays in read-only mode. This approach has two important implications.
The first consequence is common to all operating systems. Its essence is to add protection against inadvertent damage to the database by incorrect code. As you know, the executable instructions of a process are free to access data from anywhere in its address space. At the same time, as we just remembered, displaying a file in read-write mode means that any instruction can also modify it in addition. If she does this by mistake, trying, for example, to actually overwrite an array element at a non-existent index, then in this way she can accidentally change the file mapped to this address, which will lead to database corruption. If the file is displayed in read-only mode, then an attempt to change the address space corresponding to it will lead to the program crash with the signal SIGSEGV, and the file will remain intact.
The second consequence is already specific to iOS. Neither the author nor any other sources explicitly mention it, but without it, LMDB would be unsuitable for running on this mobile operating system. The next section is devoted to its consideration.
Specifics of memory-mapped files in iOS
In 2018, there was a wonderful report at WWDC . It tells that in iOS all pages located in physical memory belong to one of 3 types: dirty, compressed and clean.

Clean memory is a collection of pages that can be safely swapped out of physical memory. The data they contain can be reloaded from their original sources as needed. Read-only memory-mapped files fall into this category. iOS is not afraid to unload the pages mapped to a file from memory at any time, since they are guaranteed to be synchronized with the file on disk.
All modified pages get into dirty memory, no matter where they are originally located. In particular, memory-mapped files modified by writing to the virtual memory associated with them will also be classified in this way. Opening LMDB with flag MDB_WRITEMAP, after making changes to it, you can see for yourself.
As soon as an application starts to take up too much physical memory, iOS compresses its dirty pages. The collection of memory occupied by dirty and compressed pages is the so-called memory footprint of the application. When it reaches a certain threshold value, the OOM killer system daemon comes after the process and forcibly terminates it. This is the peculiarity of iOS compared to desktop operating systems. In contrast, lowering the memory footprint by swapping pages from physical memory to disk is not provided in iOS. One can only guess about the reasons. Perhaps the procedure for intensively moving pages to disk and back is too energy-consuming for mobile devices, or iOS saves the resource of rewriting cells on SSD disks, or maybe the designers were not satisfied with the overall performance of the system, where everything is constantly swapped. Be that as it may, the fact remains.
The good news, already mentioned earlier, is that LMDB does not use the mmap mechanism to update files by default. It follows that the rendered data is classified as clean memory by iOS and does not contribute to the memory footprint. This can be verified using the Xcode tool called VM Tracker. The screenshot below shows the virtual memory state of the iOS Cloud application during operation. At the start, 2 LMDB instances were initialized in it. The first was allowed to map its file to 1GiB of virtual memory, the second - 512MiB. Despite the fact that both storages occupy a certain amount of resident memory, neither of them contributes to the dirty size.
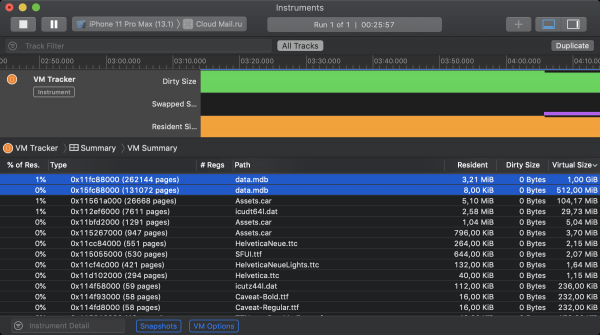
Now it's time for the bad news. Thanks to the swap mechanism in 64-bit desktop operating systems, each process can take up as much virtual address space as the free space on the hard disk allows for its potential swap. Replacing swap with compression in iOS drastically reduces the theoretical maximum. Now all living processes must fit into the main (read RAM) memory, and all those that do not fit are subject to forced termination. It is mentioned as in the above and . As a consequence, iOS severely limits the amount of memory available for allocation via mmap. Here you can look at the empirical limits on the amount of memory that could be allocated on different devices using this system call. On the most modern models of smartphones, iOS has become generous by 2 gigabytes, and on top versions of the iPad - by 4. In practice, of course, you have to focus on the youngest supported device models, where everything is very sad. Even worse, looking at the application's memory state in VM Tracker, you'll find that LMDB is far from the only one claiming memory-mapped memory. Good chunks are eaten away by system allocators, resource files, image frameworks, and other smaller predators.
Based on the results of experiments in the Cloud, we came to the following compromise values of memory allocated by LMDB: 384 megabytes for 32-bit devices and 768 for 64-bit ones. After this volume is used up, any modifying operations begin to complete with the code MDB_MAP_FULL. We observe such errors in our monitoring, but they are small enough to be neglected at this stage.
A non-obvious reason for excessive memory consumption by storage can be long-lived transactions. To understand how these two phenomena are related, it will help us to consider the remaining two LMDB whales.
3.2. Whale #2. B+-tree
To emulate tables on top of a key-value store, the following operations must be present in its API:
- Inserting a new element.
- Search for an element with a given key.
- Deleting an element.
- Iterate over key intervals in their sort order.
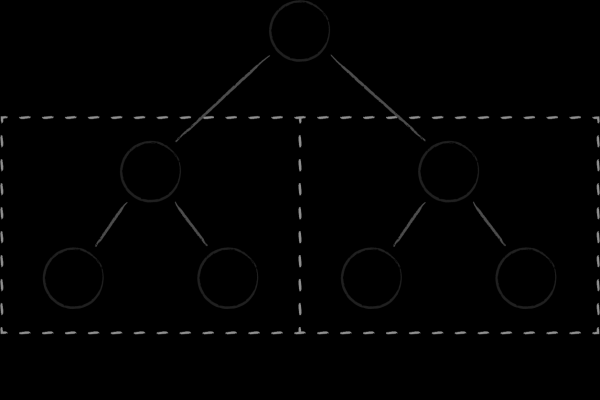 The simplest data structure that can easily implement all four operations is a binary search tree. Each of its nodes is a key that divides the entire subset of child keys into two subtrees. On the left are those that are smaller than the parent, and on the right - those that are larger. Obtaining an ordered set of keys is achieved through one of the classic tree traversals.
The simplest data structure that can easily implement all four operations is a binary search tree. Each of its nodes is a key that divides the entire subset of child keys into two subtrees. On the left are those that are smaller than the parent, and on the right - those that are larger. Obtaining an ordered set of keys is achieved through one of the classic tree traversals.
Binary trees have two fundamental drawbacks that prevent them from being effective as a disk data structure. First, the degree of their balance is unpredictable. There is a considerable risk of obtaining trees in which the height of different branches can vary greatly, which significantly worsens the algorithmic complexity of the search compared to what is expected. Secondly, the abundance of cross-links between nodes deprives binary trees of locality in memory. Close nodes (in terms of links between them) can be located on completely different pages in virtual memory. As a consequence, even a simple traversal of several neighboring nodes in a tree may require visiting a comparable number of pages. This is a problem even when we talk about the efficiency of binary trees as an in-memory data structure, since constantly rotating pages in the processor cache is not cheap. When it comes to frequently raising node-related pages from disk, things get really bad. .
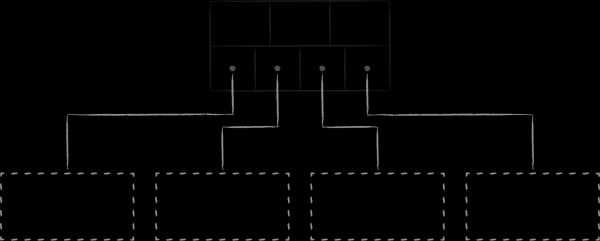 B-trees, being an evolution of binary trees, solve the problems identified in the previous paragraph. First, they are self-balancing. Secondly, each of their nodes splits the set of child keys not into 2, but into M ordered subsets, and the number M can be quite large, on the order of several hundred or even thousands.
B-trees, being an evolution of binary trees, solve the problems identified in the previous paragraph. First, they are self-balancing. Secondly, each of their nodes splits the set of child keys not into 2, but into M ordered subsets, and the number M can be quite large, on the order of several hundred or even thousands.
Thereby:
- Each node has a large number of already ordered keys and the trees are very low.
- The tree acquires the property of locality in memory, since keys that are close in value are naturally located next to each other on one or neighboring nodes.
- Reduces the number of transit nodes when descending the tree during a search operation.
- Reduces the number of target nodes read for range queries, since each of them already contains a large number of ordered keys.
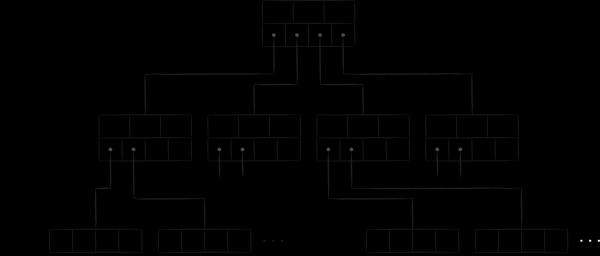
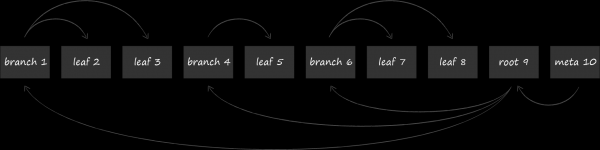
LMDB uses a variant of the B-tree called the B+ tree to store data. The diagram above shows the three types of nodes that it contains:
- At the top is the root. It materializes nothing more than the concept of a database within a repository. Within a single LMDB instance, you can create multiple databases that share the mapped virtual address space. Each of them starts from its own root.
- At the lowest level are the leaves (leaf). It is they and only they that contain the key-value pairs stored in the database. By the way, this is the peculiarity of B+-trees. If a normal B-tree stores the value-parts at the nodes of all levels, then the B+-variation is only at the lowest one. Having fixed this fact, in what follows we will call the subtype of the tree used in LMDB simply a B-tree.
- Between the root and the leaves, there are 0 or more technical levels with navigation (branch) nodes. Their task is to divide the sorted set of keys between the leaves.
Physically, nodes are blocks of memory of a predetermined length. Their size is a multiple of the size of the memory pages in the operating system, which we talked about above. The node structure is shown below. The header contains meta-information, the most obvious of which, for example, is the checksum. Next comes information about offsets, along which cells with data are located. The role of data can be either keys, if we are talking about navigation nodes, or entire key-value pairs in the case of leaves. You can read more about the structure of pages in the work .
Having dealt with the internal content of the page nodes, we will further represent the LMDB B-tree in a simplified way in the following form.
Pages with nodes are sequentially arranged on disk. Pages with a higher number are located towards the end of the file. The so-called meta page (meta page) contains information about offsets, which can be used to find the roots of all trees. When a file is opened, LMDB scans the file page by page from the end to the beginning in search of a valid meta page and finds existing databases through it.
Now, having an idea of the logical and physical structure of data organization, we can proceed to consider the third whale of LMDB. It is with its help that all storage modifications occur transactionally and in isolation from each other, giving the database as a whole also the multiversion property.
3.3. Whale #3. copy-on-write
Some B-tree operations involve making a whole series of changes to its nodes. One example is adding a new key to a node that has already reached its maximum capacity. In this case, it is necessary, firstly, to split the node into two, and secondly, to add a link to the new spun off child node in its parent. This procedure is potentially very dangerous. If for some reason (crash, power outage, etc.) only a part of the changes from the series happens, then the tree will remain in an inconsistent state.
One traditional solution to making a database fault-tolerant is to add an additional disk-based data structure, the transaction log, also known as the write-ahead log (WAL), next to the B-tree. It is a file, at the end of which, strictly before the modification of the B-tree itself, the intended operation is written. Thus, if data corruption is detected during self-diagnosis, the database consults the log to clean itself up.
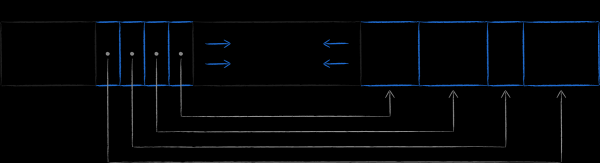
LMDB has chosen a different method as its fault tolerance mechanism, which is called copy-on-write. Its essence is that instead of updating the data on an existing page, it first copies it entirely and makes all modifications already in the copy.
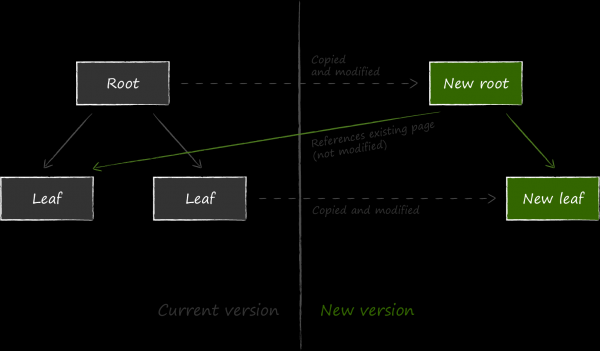
Further, in order for the updated data to be available, it is necessary to change the link to the node that has become up-to-date in the parent node in relation to it. Since it also needs to be modified for this, it is also pre-copied. The process continues recursively all the way to the root. The data on the meta page is the last to change.
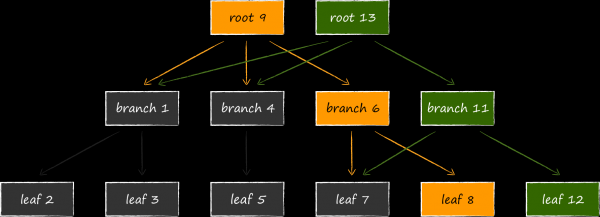
If the process suddenly crashes during the update procedure, then either a new meta page will not be created, or it will not be written to disk until the end, and its checksum will be incorrect. In either of these two cases, the new pages will be unreachable and the old ones will not be affected. This eliminates the need for LMDB to write ahead log to maintain data consistency. De facto, the structure of data storage on the disk, described above, simultaneously takes on its function. The absence of an explicit transaction log is one of the features of LMDB, which provides high data reading speed.
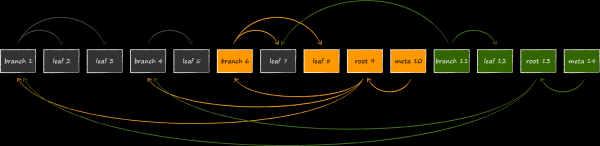
The resulting construct, called append-only B-tree, naturally provides transaction isolation and multiversioning. In LMDB, each open transaction has an up-to-date tree root associated with it. As long as the transaction is not completed, the pages of the tree associated with it will never be changed or reused for new versions of data. Thus, you can work for as long as you like exactly with the data set that was relevant at the time the transaction was opened, even if the storage continues to be actively updated at this time. This is the essence of multiversioning, making LMDB an ideal data source for our beloved UICollectionView. Having opened a transaction, you do not need to increase the memory footprint of the application, hastily pumping out the current data into some in-memory structure, being afraid to be left with nothing. This feature distinguishes LMDB from the same SQLite, which cannot boast of such total isolation. Having opened two transactions in the latter and deleting a certain record within one of them, the same record can no longer be obtained within the second remaining one.
The flip side of the coin is the potentially significantly higher consumption of virtual memory. The slide shows what the database structure will look like if it is modified at the same time with 3 open read transactions looking at different versions of the database. Since LMDB cannot reuse nodes that are reachable from the roots associated with the actual transactions, the storage has no choice but to allocate another fourth root in memory and once again clone the modified pages under it.
Here it will not be superfluous to recall the section on memory-mapped files. It seems that the additional consumption of virtual memory should not bother us much, since it does not contribute to the application's memory footprint. However, at the same time, it was noted that iOS is very stingy in allocating it, and we cannot provide a 1 terabyte LMDB region on a server or desktop from the master's shoulder and not think about this feature at all. When possible, you should try to keep the lifetime of transactions as short as possible.
4. Designing a data schema on top of the key-value API
Let's start parsing the API by looking at the basic abstractions provided by LMDB: environment and databases, keys and values, transactions and cursors.
A note about code listings
All functions in the LMDB public API return the result of their work in the form of an error code, but in all subsequent listings its check is omitted for the sake of conciseness. In practice, we used our own code to interact with the repository. C++ wrappers , in which errors materialize as C++ exceptions.
As the fastest way to connect LMDB to a project for iOS or macOS I offer my CocoaPod .
4.1. Basic abstractions
Environment
Structure MDB_env is is the repository of the internal state of the LMDB. Family of prefixed functions mdb_env allows you to configure some of its properties. In the simplest case, the initialization of the engine looks like this.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);In the Mail.ru Cloud application, we changed the default values for only two parameters.
The first one is the size of the virtual address space that the storage file is mapped to. Unfortunately, even on the same device, the specific value can vary significantly from run to run. To take into account this feature of iOS, we select the maximum amount of storage dynamically. Starting from a certain value, it successively halves until the function mdb_env_open will not return a result other than ENOMEM. In theory, there is an opposite way - first allocate a minimum of memory to the engine, and then, when errors are received MDB_MAP_FULL, increase it. However, it is much more thorny. The reason is that the procedure for remapping memory using the function mdb_env_set_map_size invalidates all entities (cursors, transactions, keys and values) received from the engine earlier. Accounting for such a turn of events in the code will lead to its significant complication. If, nevertheless, virtual memory is very dear to you, then this may be a reason to look at the fork that has gone far ahead. , where among the declared features there is “automatic on-the-fly database size adjustment”.
The second parameter, the default value of which did not suit us, regulates the mechanics of ensuring thread safety. Unfortunately, at least in iOS 10, there are problems with thread local storage support. For this reason, in the example above, the repository is opened with the flag MDB_NOTLS. In addition, it also required C++ wrapper to cut variables with and in this attribute.
Database
The database is a separate instance of the B-tree that we talked about above. Its opening occurs inside a transaction, which at first may seem a little strange.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);Indeed, a transaction in LMDB is a storage entity, not a specific database. This concept allows you to perform atomic operations on entities located in different databases. In theory, this opens up the possibility of modeling tables in the form of different databases, but at one time I went the other way, described in detail below.
Keys and values
Structure MDB_val models the concept of both a key and a value. The repository has no idea about their semantics. For her, something that is different is just an array of bytes of a given size. The maximum key size is 512 bytes.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;The store uses a comparator to sort the keys in ascending order. If you do not replace it with your own, then the default one will be used, which sorts them byte-by-byte in lexicographic order.
Transactions
The transaction device is described in detail in , so here I will repeat their main properties in a short line:
- Support for all basic properties : atomicity, consistency, isolation, and reliability. I can't help but note that in terms of durability, macOS There's a bug in iOS that's been fixed in MDBX. You can read more about it in their .
- The approach to multithreading is described by the "single writer / multiple readers" scheme. Writers block each other, but they don't block readers. Readers don't block writers or each other.
- Support for nested transactions.
- Multiversion support.
Multiversioning in LMDB is so good that I want to demonstrate it in action. The code below shows that each transaction works with exactly the version of the database that was relevant at the time of its opening, being completely isolated from all subsequent changes. Initializing the repository and adding a test record to it is of no interest, so these rituals are left under the spoiler.
Adding a test entry
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Открываем 2 транзакции, каждая из которых смотрит
// на версию базы данных с одной записью.
mdb_txn_begin(env, NULL, 0, &txn1); // read-write
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // read-only
// В рамках первой транзакции удаляем из базы данных существующую в ней запись.
mdb_del(txn1, dbi, &key, NULL);
// Фиксируем удаление.
mdb_txn_commit(txn1);
// Открываем третью транзакцию, которая смотрит на
// актуальную версию базы данных, где записи уже нет.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Убеждаемся, что запись по искомому ключу уже не существует.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Завершаем транзакцию.
mdb_txn_abort(txn3);
// Убеждаемся, что в рамках второй транзакции, открытой на момент
// существования записи в базе данных, её всё ещё можно найти по ключу.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Проверяем, что по ключу получен не абы какой мусор, а валидные данные.
assert(*(int *)val.mv_data == 997);
// Завершаем транзакцию, работающей хоть и с устаревшей, но консистентной базой данных.
mdb_txn_abort(txn2);Optionally, I recommend trying the same trick with SQLite and see what happens.
Multiversioning brings very nice benefits to the life of an iOS developer. Using this property, you can easily and naturally adjust the data source update rate for screen forms based on user experience considerations. For example, let's take such a feature of the Mail.ru Cloud application as autoloading content from the system media gallery. With a good connection, the client is able to add several photos per second to the server. If you update after each download UICollectionView with media content in the user's cloud, you can forget about 60 fps and smooth scrolling during this process. To prevent frequent screen updates, you need to somehow limit the rate of data change in the basis UICollectionViewDataSource.
If the database does not support multiversioning and allows you to work only with the current current state, then to create a time-stable data snapshot, you need to copy it either to some in-memory data structure or to a temporary table. Either of these approaches is very expensive. In the case of in-memory storage, we get both the memory costs caused by storing constructed objects and the time costs associated with redundant ORM transformations. As for the temporary table, this is an even more expensive pleasure, which makes sense only in non-trivial cases.
Multiversioning LMDB solves the problem of maintaining a stable data source in a very elegant way. It is enough just to open a transaction and voila - until we complete it, the data set is guaranteed to be fixed. The logic of its update rate is now entirely in the hands of the presentation layer, with no overhead of significant resources.
Cursors
Cursors provide a mechanism for orderly iteration over key-value pairs by traversing a B-tree. Without them, it would be impossible to effectively model the tables in the database, which we now turn to.
4.2. Table Modeling
The key ordering property allows you to construct a top-level abstraction such as a table on top of basic abstractions. Let's consider this process on the example of the main table of the cloud client, in which information about all files and folders of the user is cached.
Table Schema
One of the common scenarios for which the structure of a table with a folder tree should be sharpened is to select all elements located inside a given directory. A good data organization model for efficient queries of this kind is To implement it on top of key-value storage, it's necessary to sort file and folder keys so that they are grouped based on their parent directory. Furthermore, to display the directory contents in a user-friendly manner Windows view (first folders, then files, both sorted alphabetically), it is necessary to include the corresponding additional fields in the key.
The picture below shows how, based on the task, the representation of keys as an array of bytes may look like. First, the bytes with the parent directory identifier (red) are placed, then with the type (green), and already in the tail with the name (blue). Being sorted by the default LMDB comparator in lexicographic order, they are ordered in the required way. Sequentially traversing keys with the same red prefix gives us the values associated with them in the order in which they should be displayed in the user interface (right), without requiring any additional post-processing.

Serializing Keys and Values
There are many methods for serializing objects around the world. Since we had no other requirement other than speed, we chose the fastest possible one for ourselves - a memory dump occupied by an instance of the C language structure. So, the key of a directory element can be modeled by the following structure NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;To save NodeKey in storage need in object MDB_val position the pointer to the data at the address of the beginning of the structure, and calculate their size with the function sizeof.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}In the first chapter on database selection criteria, I mentioned minimizing dynamic allocations as part of CRUD operations as an important selection factor. Function Code serialize shows how, in the case of LMDB, they can be completely avoided when new records are inserted into the database. The incoming array of bytes from the server is first transformed into stack structures, and then they are trivially dumped into the storage. Given that there are also no dynamic allocations inside LMDB, you can get a fantastic situation by the standards of iOS - use only stack memory to work with data all the way from the network to the disk!
Ordering keys with a binary comparator
The key order relation is given by a special function called a comparator. Since the engine knows nothing about the semantics of the bytes they contain, the default comparator has no choice but to arrange the keys in lexicographic order, resorting to their byte-by-byte comparison. Using it to arrange structures is akin to shaving with a carving axe. However, in simple cases, I find this method acceptable. The alternative is described below, but here I will note a couple of rakes scattered along the way.
The first thing to keep in mind is the memory representation of primitive data types. So, on all Apple devices, integer variables are stored in the format . This means that the least significant byte will be on the left, and you won't be able to sort integers using their byte-by-byte comparison. For example, trying to do this with a set of numbers from 0 to 511 will result in the following result.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)To solve this problem, the integers must be stored in the key in a format suitable for the byte comparator. Functions from the family will help to carry out the necessary transformation. hton* (in particular htons for double-byte numbers from the example).
The format for representing strings in programming is, as you know, a whole . If the semantics of strings, as well as the encoding used to represent them in memory, suggests that there may be more than one byte per character, then it is better to immediately abandon the idea of using a default comparator.
The second thing to keep in mind is struct field compiler. Because of them, bytes with garbage values \uXNUMXb\uXNUMXbcan be formed in memory between fields, which, of course, breaks byte sorting. To eliminate garbage, you must either declare the fields in a strictly defined order, keeping the alignment rules in mind, or use the attribute in the structure declaration packed.
Key ordering by an external comparator
The key comparison logic may turn out to be too complex for a binary comparator. One of the many reasons is the presence of technical fields inside the structures. I will illustrate their occurrence on the example of a key already familiar to us for a directory element.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;For all its simplicity, in the vast majority of cases it consumes too much memory. The title buffer is 256 bytes, although on average file and folder names rarely exceed 20-30 characters.
One of the standard techniques for optimizing the size of a record is to "cut" it to fit the actual size. Its essence is that the contents of all variable-length fields are stored in a buffer at the end of the structure, and their lengths are stored in separate variables. In accordance with this approach, the key NodeKey is transformed in the following way.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Further, during serialization, not specified as the data size sizeof the entire structure, and the size of all fields is fixed length plus the size of the actually used part of the buffer.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}As a result of the refactoring, we got a significant savings in the space occupied by the keys. However, due to the technical field nameLength, the default binary comparator is no longer suitable for key comparison. If we do not replace it with our own, then the length of the name will be a more priority factor in sorting than the name itself.
LMDB allows each database to have its own key comparison function. This is done using the function mdb_set_compare strictly before opening. For obvious reasons, a database cannot be changed throughout its lifetime. At the input, the comparator receives two keys in binary format, and at the output it returns the result of the comparison: less than (-1), greater than (1) or equal (0). Pseudocode for NodeKey looks like that.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}As long as all keys in the database are of the same type, it is legal to unconditionally cast their byte representation to the type of the key's application structure. There is one nuance here, but it will be discussed a little lower in the “Reading Records” subsection.
Value Serialization
With the keys of stored records, LMDB works extremely intensively. They are compared with each other within the framework of any application operation, and the performance of the entire solution depends on the speed of the comparator. In an ideal world, the default binary comparator should be enough to compare keys, but if you really had to use your own, then the procedure for deserializing keys in it should be as fast as possible.
The database is not particularly interested in the Value-part of the record (value). Its conversion from a byte representation to an object occurs only when it is already required by the application code, for example, to display it on the screen. Since this happens relatively rarely, the requirements for the speed of this procedure are not so critical, and in its implementation we are much more free to focus on convenience. For example, to serialize metadata about files that have not yet been downloaded, we use NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};However, there are times when performance does matter. For example, when saving meta-information about the file structure of the user cloud, we use the same object memory dump. The highlight of the task of generating their serialized representation is the fact that the elements of a directory are modeled by a class hierarchy.
For its implementation in the C language, the specific fields of the heirs are taken out into separate structures, and their connection with the base one is specified through a field of the union type. The actual content of the union is specified via the type technical attribute.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Adding and updating records
The serialized key and value can be added to the store. For this, the function is used mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);At the configuration stage, the repository can be allowed or forbidden to store multiple records with the same key. If duplication of keys is prohibited, then when inserting a record, you can determine whether updating an already existing record is allowed or not. If fraying can only occur as a result of an error in the code, then you can insure against it by specifying the flag NOOVERWRITE.
Reading Records
The function for reading records in LMDB is mdb_get. If the key-value pair is represented by previously dumped structures, then this procedure looks like this.
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}The presented listing shows how serialization through a dump of structures allows you to get rid of dynamic allocations not only when writing, but when reading data. Derived from function mdb_get the pointer looks exactly at the virtual memory address where the database stores the byte representation of the object. In fact, we get a kind of ORM, almost free of charge providing a very high speed of reading data. With all the beauty of the approach, it is necessary to remember several features associated with it.
- For a readonly transaction, a pointer to a value structure is guaranteed to remain valid only until the transaction is closed. As noted earlier, the pages of the B-tree on which the object resides, thanks to the copy-on-write principle, remain unchanged as long as at least one transaction refers to them. At the same time, as soon as the last transaction associated with them is completed, the pages can be reused for new data. If it is necessary for objects to survive the transaction that created them, then they still have to be copied.
- For a readwrite transaction, the pointer to the resulting structure-value will be valid only until the first modifying procedure (writing or deleting data).
- Even though the structure
NodeValuenot full-fledged, but trimmed (see subsection "Ordering keys by an external comparator"), through the pointer, you can easily access its fields. The main thing is not to dereference it! - In no case can you modify the structure through the received pointer. All changes must be made only through the method
mdb_put. However, with all the desire to do this, it will not work, since the memory area where this structure is located is mapped in readonly mode. - Remap a file to the address space of a process in order to, for example, increase the maximum storage size using the function
mdb_env_set_map_sizecompletely invalidates all transactions and related entities in general and pointers to read objects in particular.
Finally, one more feature is so insidious that the disclosure of its essence does not fit into just one more point. In the chapter on the B-tree, I gave a diagram of the organization of its pages in memory. It follows from it that the address of the beginning of the buffer with serialized data can be absolutely arbitrary. Because of this, the pointer to them, obtained in the structure MDB_val and cast to a pointer to a structure is generally unaligned. At the same time, the architectures of some chips (in the case of iOS, this is armv7) require that the address of any data be a multiple of the size of a machine word, or, in other words, the bitness of the system (for armv7, this is 32 bits). In other words, an operation like *(int *foo)0x800002 on them is equated to escape and leads to execution with a verdict EXC_ARM_DA_ALIGN. There are two ways to avoid such a sad fate.
The first one is to copy the data into a known-aligned structure beforehand. For example, on a custom comparator, this will be reflected as follows.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}An alternative way is to notify the compiler in advance that structures with a key and value may not be aligned using an attribute aligned(1). On ARM the same effect can be and using the packed attribute. Considering that it also contributes to the optimization of the space occupied by the structure, this method seems to me preferable, although to increase the cost of data access operations.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Range Queries
To iterate over a group of records, LMDB provides a cursor abstraction. Let's look at how to work with it using the example of a table with user cloud metadata already familiar to us.
As part of displaying a list of files in a directory, you need to find all the keys with which its child files and folders are associated. In the previous subsections, we sorted the keys NodeKey so that they are first ordered by their parent directory ID. Thus, technically, the task of obtaining the contents of a folder is reduced to placing the cursor on the upper boundary of a group of keys with a given prefix, followed by iteration to the lower boundary.

You can find the upper bound "on the forehead" by sequential search. To do this, the cursor is placed at the beginning of the entire list of keys in the database and then incremented until the key with the parent directory identifier appears below it. This approach has 2 obvious drawbacks:
- The linear complexity of the search, although, as you know, in trees in general and in a B-tree in particular, it can be done in logarithmic time.
- In vain, all pages preceding the desired one are raised from the file to the main memory, which is extremely expensive.
Fortunately, the LMDB API provides an efficient way to initially position the cursor. To do this, you need to form such a key, the value of which will certainly be less than or equal to the key located on the upper bound of the interval. For example, in relation to the list in the figure above, we can make a key in which the field parentId will be equal to 2, and all the rest are filled with zeros. Such a partially filled key is fed to the input of the function mdb_cursor_get indicating operation MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);If the upper bound of the group of keys is found, then we iterate over it until either we meet or the key with another parentId, or the keys will not run out at all.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// processing...
} while (MDB_NOTFOUND != rc && // check end of table
IsTargetKey(key)); // check end of keys groupWhat is nice, as part of iteration using mdb_cursor_get, we get not only the key, but also the value. If, in order to fulfill the selection conditions, it is necessary to check, among other things, the fields from the value-part of the record, then they are quite accessible to themselves without additional gestures.
4.3. Modeling relationships between tables
To date, we have managed to consider all aspects of designing and working with a single-table database. We can say that a table is a set of sorted records consisting of key-value pairs of the same type. If you display a key as a rectangle and its associated value as a box, you get a visual diagram of the database.
![]()
However, in real life, it is rarely possible to get by with so little blood. Often in a database it is required, firstly, to have several tables, and secondly, to carry out selections in them in an order different from the primary key. This last section is devoted to the issues of their creation and interconnection.
Index tables
The cloud app has a "Gallery" section. It displays media content from the entire cloud, sorted by date. For the optimal implementation of such a selection, next to the main table, you need to create another one with a new type of keys. They will contain a field with the date the file was created, which will act as the primary sorting criterion. Because the new keys refer to the same data as the keys in the underlying table, they are called index keys. They are highlighted in orange in the picture below.
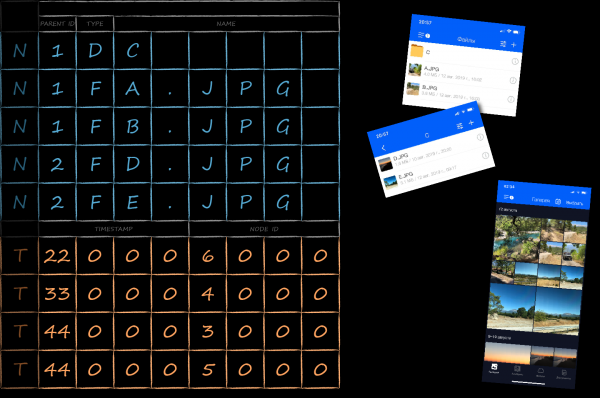
In order to separate the keys of different tables from each other within the same database, an additional technical field tableId has been added to all of them. By making it the highest priority for sorting, we will group the keys first by tables, and already inside the tables - according to our own rules.
The index key refers to the same data as the primary key. The straightforward implementation of this property by associating with it a copy of the value part of the primary key is suboptimal from several points of view at once:
- From a space occupied point of view, the metadata can be quite rich.
- From a performance point of view, since when updating the node metadata, you will have to overwrite two keys.
- From the point of view of code support, after all, if we forget to update the data for one of the keys, we will get a subtle bug of data inconsistency in the storage.
Next, we will consider how to eliminate these shortcomings.
Organization of relationships between tables
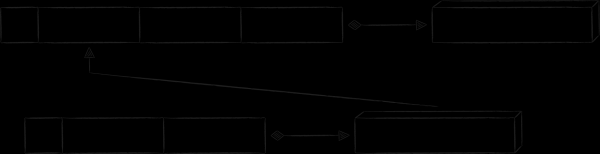
The pattern is well suited for linking an index table with the main one "key as value". As its name implies, the value part of the index record is a copy of the primary key value. This approach eliminates all the disadvantages listed above associated with storing a copy of the value-part of the primary record. The only fee is that to get the value by the index key, you need to make 2 queries to the database instead of one. Schematically, the resulting database schema is as follows.
Another pattern for organizing relationships between tables is "redundant key". Its essence is to add additional attributes to the key, which are needed not for sorting, but for recreating the associated key. There are real examples of its use in the Mail.ru Cloud application, however, in order to avoid deep diving into the context of specific iOS frameworks, I will give a fictitious, but but a more understandable example.
Cloud mobile clients have a page that displays all the files and folders that the user has shared with other people. Since there are relatively few such files, and there is a lot of specific information about publicity associated with them (to whom access is granted, with what rights, etc.), it will not be rational to burden it with the value-part of the entry in the main table. However, if you want to display such files offline, then you still need to store it somewhere. A natural solution is to create a separate table for it. In the diagram below, its key is prefixed with "P", and the "propname" placeholder can be replaced with the more specific value "public info".
All unique metadata, for the sake of which the new table was created, is moved to the value part of the record. At the same time, I don't want to duplicate the data about files and folders that are already stored in the main table. Instead, redundant data is added to the "P" key in the form of the "node ID" and "timestamp" fields. Thanks to them, you can construct an index key, by which you can get the primary key, by which, finally, you can get the metadata of the node.
Conclusion
We evaluate the results of LMDB implementation positively. After it, the number of application freezes decreased by 30%.
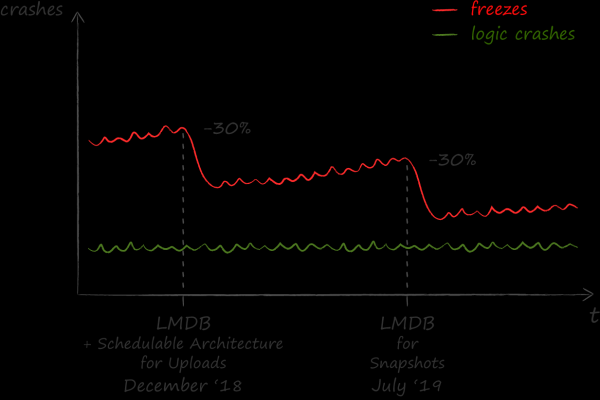
The results of this work have found resonance beyond the iOS team. Currently, one of the main sections in the "Files" app Android I also switched to using LMDB, with other parts on the way. The C language, in which the key-value store is implemented, was a good starting point for initially creating a cross-platform application framework around it in C++. A code generator was used to seamlessly connect the resulting C++ library with native Objective-C and Kotlin code. from Dropbox, but that's another story.
Source: habr.com
