

In the beginning there was a technology and it was called BPF. We looked at her , Old Testament, article in this series. In 2013, through the efforts of Alexei Starovoitov and Daniel Borkman, it was developed and included in the core Linux An improved version optimized for modern 64-bit machines. This new technology was briefly called Internal BPF, then renamed Extended BPF, and now, several years later, everyone simply calls it BPF.
Basically, BPF allows arbitrary user-provided code to run in kernel space. Linux And the new architecture turned out to be so successful that we'd need another dozen articles to describe all its applications. (The only thing the developers failed to do, as you can see in the efficiency chart below, was create a decent logo.)
This article describes the structure of the BPF virtual machine, the kernel interfaces for working with BPF, development tools, as well as a short, very short, overview of the existing features, i.e. everything that we need in the future for a deeper study of the practical applications of BPF.
Summary of the article
First, we will look at the BPF architecture from a bird's eye view and outline the main components.
Already having an understanding of the architecture as a whole, we will describe the structure of the BPF virtual machine.
In this section, we'll take a closer look at the life cycle of BPF objects - programs and maps.
Having already some understanding of the system, we will finally look at how to create and manage objects from user space using a special system call − bpf(2).
Of course, you can write programs using a system call. But it's difficult. For a more realistic scenario, nuclear programmers developed a library libbpf. We will create a basic BPF application skeleton that we will use in the following examples.
Here we will learn how BPF programs can access kernel helper functions - a tool that, along with maps, fundamentally expands the capabilities of the new BPF compared to the classic one.
At this point, we will know enough to understand exactly how you can create programs that use maps. And even with one eye we will look into the great and mighty verifier.
A reference section on how to build the required utilities and a kernel for experimentation.
At the end of the article, those who read this far will find motivating words and a brief description of what will happen in the following articles. We will also list a number of links for self-study for those who do not have the desire or ability to wait for the continuation.
Introduction to BPF Architecture
Before starting to look at the BPF architecture, we will refer to for the last time (oops) , which was developed as a response to the emergence of RISC machines and solved the problem of efficient packet filtering. The architecture turned out to be so successful that, having been born in the dashing nineties in Berkeley UNIX, it was ported to most existing operating systems, survived into the crazy twenties and still finds new applications.
The new BPF was developed as a response to the ubiquity of 64-bit machines, cloud services, and the increased need for SDN creation tools (Ssoftware-ddefined networking). Developed by core network engineers as an improved replacement for the classic BPF, the new BPF found application in the difficult task of tracing just six months later. Linux systems, and now, six years after their appearance, we would need a whole new article just to list the different types of programs.
Funny pictures
At its core, BPF is a sandbox virtual machine that allows "arbitrary" code to run in kernel space without sacrificing security. BPF programs are created in user space, loaded into the kernel, and connected to some event source. An event can be, for example, the delivery of a packet to a network interface, the launch of some kernel function, and so on. In the case of a package, the BPF program will have access to the data and metadata of the package (for reading and, maybe, for writing, depending on the type of program), in the case of running a kernel function, the arguments of the function, including pointers to kernel memory, etc.
Let's look at this process in more detail. To begin with, let's talk about the first difference from the classic BPF, the programs for which were written in assembler. In the new version, the architecture was supplemented so that programs could be written in high-level languages, primarily, of course, in C. For this, a backend for llvm was developed, which allows generating bytecode for the BPF architecture.

The BPF architecture was designed, in part, to run efficiently on modern machines. In order for this to work in practice, the BPF bytecode, after being loaded into the kernel, is translated into native code using a component called the JIT compiler (Jmouth In Time). Further, if you remember, in the classic BPF, the program was loaded into the kernel and attached to the event source atomically - in the context of a single system call. In the new architecture, this happens in two stages - first, the code is loaded into the kernel using a system call bpf(2), and then, later, using other mechanisms, different depending on the type of program, the program is connected (attaches) to the event source.
Here the reader may have a question: what, so it was possible? How is the safety of executing such code guaranteed? Execution security is guaranteed to us by the stage of loading BPF programs called verifier (in English, this stage is called verifier and I will continue to use the English word):

Verifier is a static analyzer that ensures that the program does not break the normal course of the kernel. This, by the way, does not mean that the program cannot interfere with the operation of the system - BPF programs, depending on the type, can read and rewrite kernel memory areas, return values of functions, truncate, supplement, rewrite, and even forward network packets. The verifier guarantees that the kernel will not crash from running the BPF program and that a program that, according to the rules, is writeable, for example, the data of an outgoing packet, will not be able to overwrite the kernel memory outside the packet. We will look at the verifier in a little more detail in the corresponding section, after we get acquainted with all the other BPF components.
So what have we learned so far? The user writes a program in C, loads it into the kernel using a system call bpf(2), where it is checked by the verifier and translated into native bytecode. Then the same or another user connects the program to the event source and it starts to run. Separation of loading and connection is necessary for several reasons. Firstly, running a verifier is relatively expensive, and by downloading the same program several times, we waste computer time. Secondly, how exactly a program is connected depends on its type, and one “universal” interface developed a year ago may not be suitable for new types of programs. (Although now, when the architecture becomes more mature, there is an idea to unify this interface at the level libbpf.)
The attentive reader may notice that we are not finished with the pictures yet. Indeed, all of the above does not explain how BPF fundamentally changes the picture compared to the classic BPF. Two innovations that significantly expand the boundaries of applicability are the ability to use shared memory and kernel helper functions (kernel helpers). In BPF, shared memory is implemented using the so-called maps - shared data structures with a specific API. They got this name, probably, because the first type of map that appeared was a hash table. Then came arrays, local (per-CPU) hash tables and local arrays, search trees, maps containing pointers to BPF programs, and much more. We are now interested in the fact that BPF programs have the ability to save state between calls and share it with other programs and with user space.
maps is accessed from user processes using the system call bpf(2), and from BPF programs running in the kernel - using helper functions. Moreover, helpers exist not only for working with maps, but also for accessing other kernel features. For example, BPF programs can use helper functions to redirect packets to other interfaces, to generate perf subsystem events, to access kernel structures, and so on.

In total, BPF provides the ability to load arbitrary, i.e., verified by the verifier, user code into the kernel space. This code can save state between calls and communicate with user space, and has access to the kernel subsystems allowed for this type of program.
This is already similar to the capabilities provided by kernel modules, compared to which BPF has some advantages (of course, you can only compare similar applications, for example, system tracing - you cannot write an arbitrary driver on BPF). You can note a lower entry threshold (some utilities that use BPF do not require the user to have kernel programming skills, or programming skills in general), runtime security (raise your hand in the comments, those who did not break the system when writing or testing modules), atomicity - there is a downtime when reloading modules, and the BPF subsystem guarantees that no event will be missed (in fairness, this is not true for all types of BPF programs).
The presence of such capabilities makes BPF a universal tool for extending the core, which is confirmed in practice: more and more new types of programs are added to BPF, more and more large companies use BPF on 24x7 combat servers, more and more startups build their business on solutions, in based on BPF. BPF is used everywhere: in protection against DDoS attacks, creating SDN (for example, implementing networks for kubernetes), as the main tool for tracing systems and collecting statistics, in intrusion detection systems and sandbox systems, etc.
Let's finish the review part of the article here and look at the virtual machine and the BPF ecosystem in more detail.
Digression: Utilities
In order to be able to run the examples in the following sections, you may need a number of utilities, at least llvm/clang with bpf support and bpftool. In section you can read the instructions for building utilities, as well as your own kernel. This section is placed below so as not to disturb the harmony of our presentation.
Registers and instruction set of the BPF virtual machine
The BPF architecture and command system was developed taking into account the fact that programs will be written in C and, after being loaded into the kernel, translated into native code. Therefore, the number of registers and the set of instructions were chosen with an eye to the intersection, in the mathematical sense, of the capabilities of modern machines. In addition, various restrictions were imposed on programs, for example, until recently it was not possible to write loops and subroutines, and the number of instructions was limited to 4096 (now privileged programs can be loaded up to a million instructions).
BPF has eleven user-accessible 64-bit registers. r0 r10 and a program counter. Register r10 contains a frame pointer and is read-only. A 512-byte stack and an unlimited amount of shared memory in the form of maps are available to programs at runtime.
BPF programs are allowed to run a specific set of kernel helpers, depending on the type of program, and, more recently, normal functions. Each called function can take up to five arguments passed in registers r1 r5, and the return value is passed to r0. It is guaranteed that after returning from the function, the contents of the registers r6 r9 Will not change.
For efficient translation of programs, registers r0 r11 for all supported architectures are uniquely mapped to real registers, taking into account the ABI features of the current architecture. For example, for x86_64 registers r1 r5, used to pass function parameters, are displayed on rdi, rsi, rdx, rcx, r8, which are used to pass parameters to functions on x86_64. For example, the code on the left translates to the code on the right like this:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8Регистр r0 also used to return the result of program execution, and in the register r1 the program is passed a pointer to the context - depending on the type of program, this can be, for example, a structure (for XDP) or structure (for different network programs) or structure (for different types of tracing programs), etc.
So, we had a set of registers, kernel helpers, a stack, a pointer to the context and shared memory in the form of maps. Not that all this was categorically necessary on a trip, but ...
Let's continue the description and talk about the command system for working with these objects. All () BPF instructions have a fixed 64-bit size. If you look at one instruction on a 64-bit Big Endian machine, you will see
![]()
Here Code is the encoding of the instruction, Dst/Src are the source and destination encodings, respectively, Off - 16-bit signed indentation, and Imm is a 32-bit signed integer used in some commands (analogous to the constant K from cBPF). Encoding Code has one of two types:
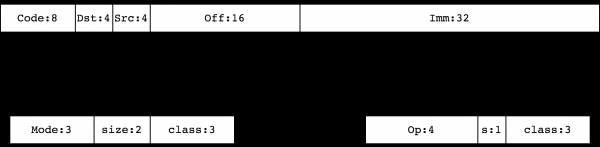
Instruction classes 0, 1, 2, 3 define instructions for working with memory. They , BPF_LD, BPF_LDX, BPF_ST, BPF_STX, respectively. Classes 4, 7 (BPF_ALU, BPF_ALU64) constitute a set of ALU instructions. Classes 5, 6 (BPF_JMP, BPF_JMP32) encapsulate jump instructions.
The further plan for studying the BPF command system is this: instead of meticulously listing all the instructions and their parameters, we will analyze a couple of examples in this section and from them it will become clear how the instructions actually work and how to manually disassemble any binary file for BPF. To consolidate the material further in the article, we will meet with individual instructions in sections about the Verifier, JIT compiler, translation of the classic BPF, as well as when studying maps, calling functions, etc.
When we talk about individual instructions, we will refer to kernel files. и , which define numeric BPF instruction codes. When studying the architecture and / or parsing binaries on your own, you can find semantics in the following sources, sorted in order of complexity: , , and, of course, in the source codes Linux — verifier, JIT, BPF interpreter.
Example: disassembling BPF in the mind
Let's look at an example in which we will compile a program readelf-example.c and look at the resulting binary. We will reveal the original content readelf-example.c below, after restoring its logic from binary codes:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hex dump of section '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................First column in output readelf is an indent and our program thus consists of four commands:
Code Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000Command codes are equal b7, 15, b7 и 95. Recall that the three least significant bits are the class of the instruction. In our case, the fourth bit of all instructions is empty, so the instruction classes are 7, 5, 7, 5, respectively. Class 7 is BPF_ALU64, and 5 is BPF_JMP. For both classes, the instruction format is the same (see above) and we can rewrite our program like this (at the same time we will rewrite the remaining columns in human form):
Op S Class Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0Operation b Class ALU64 - Is . It assigns a value to the destination register. If the bit is set s (source), then the value is taken from the source register, and if, as in our case, it is not set, then the value is taken from the field Imm. Thus, in the first and third instructions, we perform the operation r0 = Imm. Further, operation 1 of the JMP class is (jump if equal). In our case, since the bit S is zero, it compares the value of the source register with the field Imm. If the values match, then the transition occurs to PC + OffWhere PC, as usual, contains the address of the next instruction. Finally, operation 9 of the JMP class is . This instruction terminates the program by returning to the kernel r0. Let's add a new column to our table:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitWe can rewrite this in a more convenient form:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitIf we remember that in the register r1 the program is passed a pointer to the context from the kernel, and in the register r0 a value is returned to the kernel, then we can see that if the pointer to the context is null, then we return 1, and otherwise - 2. Check that we are right by looking at the source:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}Yes, this is a meaningless program, but it translates into just four simple instructions.
Exception example: 16-byte instruction
We mentioned earlier that some instructions take up more than 64 bits. This applies, for example, to instructions lddw (Code = 0x18 = | | ) - load a double word from the fields into the register Imm. The fact is that Imm has a size of 32, and a double word is 64 bits, so you cannot load a 64-bit immediate value into a register in one 64-bit instruction. To do this, two adjacent instructions are used to store the second part of the 64-bit value in the field Imm. Example:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex dump of section '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........There are only two instructions in a binary program:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitWe will meet again with instructions lddwwhen we talk about relocations and working with maps.
Example: disassembling BPF using standard tools
So, we have learned how to read BPF binary codes and are ready to parse any instruction, if necessary. However, it should be said that in practice it is more convenient and faster to disassemble programs using standard tools, for example:
$ llvm-objdump -d x64.o
Disassembly of section .text:
0000000000000000 <foo>:
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitLife cycle of BPF objects, bpffs file system
(Some of the details described in this subsection I first learned from Alexei Starovoitov in .)
BPF objects - programs and maps - are created from user space using commands BPF_PROG_LOAD и BPF_MAP_CREATE system call bpf(2), we will talk about exactly how this happens in the next section. At the same time, kernel data structures are created and for each of them refcount (reference count) is set to one, and a file descriptor pointing to the object is returned to the user. After closing the handle refcount object is decremented by one, and when it reaches zero, the object is destroyed.
If the program uses maps, then refcount of these maps is increased by one after the program is loaded, i.e. their file descriptors can be closed from a user process and still refcount will not become null:
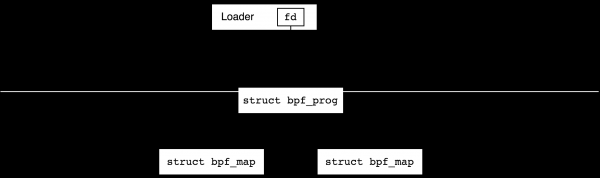
After the program has successfully loaded, we usually attach it to some kind of event generator. For example, we can put it on a network interface to process incoming packets or connect it to some tracepoint in the core. At this point, the link count will also increase by one and we can close the file descriptor in the loader.
What happens if we now exit the bootloader? It depends on the type of event generator (hook). All network hooks will exist after the loader completes, these are the so-called global hooks. And, for example, trace programs will be released after the process that created them terminates (and therefore are called local, from “local to the process”). Technically, local hooks always have a corresponding file descriptor in user space and therefore close when the process closes, while global hooks do not. In the following figure, I try to show with the help of red crosses how the termination of the loader program affects the lifetime of objects in the case of local and global hooks.
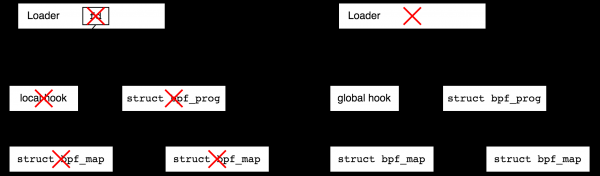
Why is there a division into local and global hooks? Running some types of network programs makes sense even without userspace, for example, imagine DDoS protection - the loader writes the rules and connects the BPF program to the network interface, after which the loader can go and kill itself. On the other hand, imagine a debug tracing program that you wrote on your knee in ten minutes - after its completion, you would like no garbage left in the system, and local hooks guarantee this.
On the other hand, imagine that you want to connect to a tracepoint in the kernel and collect statistics over many years. In this case, you would like to complete the user part and return to the statistics from time to time. This feature is provided by the bpf file system. This is a memory-only pseudo-file system that allows you to create files that refer to BPF objects and thereby increase refcount objects. After that, the loader can exit, and the objects it created will remain alive.
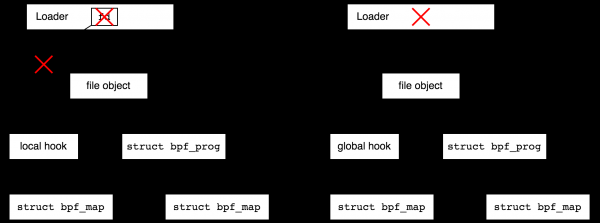
Creating files in bpffs that refer to BPF objects is called "pinning" ("pin", as in the following phrase: "process can pin a BPF program or map"). Creating file objects for BPF objects makes sense not only to extend the life of local objects, but also for the convenience of using global objects - going back to the example with the global DDoS protection program, we want to be able to come and look at the statistics from time to time.
The BPF file system is usually mounted on /sys/fs/bpf, but it can also be mounted locally, for example, like this:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointNames in the file system are created using the command BPF_OBJ_PIN BPF system call. As an illustration, let's take a program, compile it, download it, and paste it into bpffs. Our program doesn't do anything useful, we just include the code so you can reproduce the example:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";Let's compile this program and create a local copy of the file system bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointNow let's load our program using the utility bpftool and look at the accompanying system calls bpf(2) (some irrelevant lines removed from strace output):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0Here we have loaded the program with BPF_PROG_LOAD, received a file descriptor from the kernel 3 and with the command BPF_OBJ_PIN pinned this file descriptor as a file "bpf-mountpoint/test". Then the downloader bpftool finished, but our program remained in the kernel even though we didn't attach it to any network interface:
$ sudo bpftool prog | tail -3
783: xdp name test tag 5c8ba0cf164cb46c gpl
loaded_at 2020-05-05T13:27:08+0000 uid 0
xlated 24B jited 41B memlock 4096BWe can delete a file object with the usual unlink(2) and after that the corresponding program will be removed:
$ sudo rm ./bpf-mountpoint/test
$ sudo bpftool prog show id 783
Error: get by id (783): No such file or directoryRemoving objects
Speaking of deleting objects, it must be clarified that after we have disconnected the program from the hook (event generator), no new event will cause it to start, however, all current instances of the program will be completed in the normal order.
Some types of BPF programs allow you to change the program on the fly, i.e. provide sequence atomicity replace = detach old program, attach new program. In this case, all active instances of the old version of the program will finish their work, and new event handlers will be created already from the new program, and “atomicity” here means that not a single event will be missed.
Attaching Programs to Event Sources
In this article, we will not separately describe the connection of programs to event sources, since it makes sense to study this in the context of a particular type of program. Cm. below, in which we show how programs like XDP are connected.
Manipulating Objects with the bpf System Call
BPF Programs
All BPF objects are created and managed from user space using a system call bpf, which has the following prototype:
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);Here is the team cmd is one of the values of type , attr - a pointer to the parameters for a specific program and size — the size of the object according to the pointer, i.e. usually this sizeof(*attr). In kernel 5.8 system call bpf supports 34 different commands, and union bpf_attr occupies 200 lines. But we should not be afraid of this, as we will get acquainted with commands and parameters throughout several articles.
Let's start with the team BPF_PROG_LOAD, which creates BPF programs - takes the BPF instruction set and loads it into the kernel. At the time of loading, the verifier is launched, and then the JIT compiler, and, after successful execution, the file descriptor of the program is returned to the user. We saw what happens to him next in the previous section. .
Now we will write a custom program that will load a simple BPF program, but first we need to decide what kind of program we want to load - we will have to choose and within the framework of this type, write a program that will pass the test on the verifier. However, in order not to complicate the process, here is a ready-made solution: we will take a program like BPF_PROG_TYPE_XDP, which will return a value XDP_PASS (skip all packages). In BPF assembler, this looks very simple:
r0 = 2
exitAfter we have decided on that we will upload, we can tell how we will do it:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}Interesting events in the program begin with the definition of an array insns - our BPF program in native code. In this case, each instruction of the BPF program is packed into a structure . First element insns corresponds to the instructions r0 = 2second - exit.
Retreat. The kernel defines more convenient macros for writing machine codes, and using the kernel header file tools/include/linux/filter.h we could write
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};But since writing BPF programs in native code is only necessary for writing tests in the core and articles about BPF, the absence of these macros does not really complicate the life of the developer.
After defining the BPF program, we move on to loading it into the kernel. Our Minimalist Parameter Set attr includes the type of program, the set and number of instructions, the required license, and the name "woo", which we use to find our program on the system after it has loaded. The program, as promised, is loaded into the system using the system call bpf.
At the end of the program, we get into an infinite loop that simulates a payload. Without it, the program will be destroyed by the kernel when closing the file descriptor returned by the system call bpf, and we will not see it in the system.
Well, we are ready for testing. Build and run the program straceto check that everything is working as it should:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_V
ERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(Everything is fine, bpf(2) returned descriptor 3 to us and we went into an infinite loop with pause(). Let's try to find our program in the system. For this we will go to another terminal and use the utility bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)We see that the system has a loaded program woo whose global ID is 390, and what is currently in progress simple-prog there is an open file descriptor pointing to the program (and if simple-prog completes the job, then woo will disappear). As expected, the program woo occupies 16 bytes - two instructions - of binary codes in the BPF architecture, but in native form (x86_64) - this is already 40 bytes. Let's look at our program in its original form:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitno surprises. Now let's look at the code generated by the JIT compiler:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqnot very effective for exit(2), but in fairness, our program is too simple, and for non-trivial programs, the prologue and epilogue added by the JIT compiler are, of course, needed.
Maps
BPF programs can use structured memory areas that are available to both other BPF programs and user-space programs. These objects are called maps and in this section we will show how to manipulate them using the system call bpf.
Let's say right away that the possibilities of maps are not limited only to access to shared memory. There are special-purpose maps containing, for example, pointers to BPF programs or pointers to network interfaces, maps for working with perf events, etc. Here we will not talk about them, so as not to confuse the reader. Other than that, we're ignoring timing issues, as they're not important for our examples. A complete list of available map types can be found in , and in this section we will take as an example the historically first type, the hash table BPF_MAP_TYPE_HASH.
If you are creating a hash table in, say, C++, you would say unordered_map<int,long> woo, which in Russian means "I need a table woo of unlimited size, whose keys are of type int, and the values are the type long". In order to create a BPF hash table, we must do roughly the same thing, with the exception that we will have to specify the maximum size of the table, and instead of types of keys and values, we need to specify their sizes in bytes. To create maps, use the command BPF_MAP_CREATE system call bpf. Let's look at a more or less minimal program that creates a map. After the previous program that loads BPF programs, this one should look simple:
$ cat simple-map.c
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}Here we define a set of parameters attr, in which we say "I need a hash table with keys and values of size sizeof(int), in which I can put a maximum of four elements. When creating BPF maps, you can specify other parameters, for example, in the same way as in the example with the program, we specified the name of the object as "woo".
Compile and run the program:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(Here is the system call bpf(2) returned us the map descriptor number 3 and then the program, as expected, waits for further instructions in the system call pause(2).
Now let's send our program to background or open another terminal and look at our object using the utility bpftool (we can distinguish our map from others by its name):
$ sudo bpftool map
...
114: hash name woo flags 0x0
key 4B value 4B max_entries 4 memlock 4096B
...The number 114 is the global ID of our object. Any program on the system can use this ID to open an already existing map with the command BPF_MAP_GET_FD_BY_ID system call bpf.
Now we can play around with our hash table. Let's take a look at its contents:
$ sudo bpftool map dump id 114
Found 0 elementsEmpty. Let's put a value in it hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0Let's look at the table again:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
Found 1 elementHooray! We managed to add one element. Note that we have to work at the byte level for this, since bptftool does not know what type the values in the hash table are. (She can be given this knowledge using BTF, but that's beyond the point.)
How exactly does bpftool read and add elements? Let's take a look under the hood:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTWe first opened the map by its global ID using the command BPF_MAP_GET_FD_BY_ID и bpf(2) returned descriptor 3 to us. Next, using the command BPF_MAP_GET_NEXT_KEY we found the first key in the table by passing NULL as a pointer to the "previous" key. With the key, we can do BPF_MAP_LOOKUP_ELEM, which returns a value in a pointer value. The next step is we are trying to find the next element by passing a pointer to the current key, but our table contains only one element and the command BPF_MAP_GET_NEXT_KEY returns ENOENT.
Okay, let's change the value on key 1, let's say our business logic requires to write hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0As expected, it's very simple: the command BPF_MAP_GET_FD_BY_ID opens our map by ID, and the command BPF_MAP_UPDATE_ELEM overwrites the element.
So, after creating a hash table from one program, we can read and write its contents from another. Note that if we were able to do this from the command line, then it could be any other program on the system. In addition to the commands described above, to work with maps from user space, there are :
BPF_MAP_LOOKUP_ELEM: find value by keyBPF_MAP_UPDATE_ELEM: update/create valueBPF_MAP_DELETE_ELEM: delete keyBPF_MAP_GET_NEXT_KEY: find next (or first) keyBPF_MAP_GET_NEXT_ID: allows you to go through all existing maps, this is how it worksbpftool mapBPF_MAP_GET_FD_BY_ID: open an existing map by its global IDBPF_MAP_LOOKUP_AND_DELETE_ELEM: atomically update the object's value and return the old oneBPF_MAP_FREEZE: make the map immutable from userspace (this operation cannot be undone)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: bulk operations. For example,BPF_MAP_LOOKUP_AND_DELETE_BATCH- this is the only reliable way to read and reset all values from the map
Not all of these commands work for all types of maps, but in general, working with other types of maps from user space looks exactly the same as working with hash tables.
For order, let's complete our hash table experiments. Remember that we created a table that can contain up to four keys? Let's add a few more elements:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0So far so good:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Found 4 elementsLet's try adding another one:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Error: update failed: Argument list too longAs expected, we failed. Let's look at the error in more detail:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argument list too long)
Error: update failed: Argument list too long
+++ exited with 255 +++Everything is in order: as expected, the command BPF_MAP_UPDATE_ELEM tries to create a new, fifth, key, but falls from E2BIG.
So, we can create and load BPF programs, as well as create and manage maps from user space. Now it is logical to look at how we can use maps from the BPF programs themselves. We could talk about this in the language of hard-to-read programs in machine macro codes, but in fact, it's time to show how BPF programs are actually written and maintained - using libbpf.
(For readers who are unhappy with the lack of a low-level example: we will go into detail about programs that use maps and helper functions created with libbpf and tell you what happens at the level of instructions. For readers dissatisfied very much, we added at the appropriate place in the article.)
Writing BPF programs with libbpf
Writing BPF programs using machine code can be interesting only at first, and then satiety sets in. At this point, you need to turn your attention to llvm, which has a backend for generating code for the BPF architecture, as well as a library libbpf, which allows you to write a custom part of BPF applications and load the code of BPF programs generated with llvm/clang.
In fact, as we will see in this and subsequent articles, libbpf does quite a lot of work without it (or similar tools - iproute2, libbcc, libbpf-go, etc.) it is impossible to live. One of the killer features of the project libbpf is BPF CO-RE (Compile Once, Run Everywhere) - a project that allows you to write BPF programs that are portable from one kernel to another, with the ability to run on different APIs (for example, when the kernel structure changes from version to version). In order to be able to work with CO-RE, your kernel must be compiled with BTF support (we describe how to do this in the section . It is very easy to check whether your kernel is built with BTF or not - by the presence of the following file:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M Jul 29 15:30 /sys/kernel/btf/vmlinuxThis file contains information about all data types used in the kernel and is used in all of our examples using libbpf. We will talk about CO-RE in detail in the next article, but in this one, just build yourself a kernel with CONFIG_DEBUG_INFO_BTF.
Library libbpf lives directly in the directory tools/lib/bpf kernel and its development is carried out through the mailing list bpf@vger.kernel.org. However, for the needs of applications that live outside the kernel, a separate repository is maintained in which the core library is mirrored for read access more or less as is.
In this section, we will look at how you can create a project using libbpf, write some (more or less meaningless) test programs and analyze in detail how it all works. This will make it easier for us to explain in the following sections exactly how BPF programs interact with maps, kernel helpers, BTF, and so on.
Typically, projects that use libbpf add the github repository as a git submodule, we will do it too:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Initialized empty Git repository in /tmp/libbpf-example/.git/
$ git submodule add https://github.com/libbpf/libbpf.git
Cloning into '/tmp/libbpf-example/libbpf'...
remote: Enumerating objects: 200, done.
remote: Counting objects: 100% (200/200), done.
remote: Compressing objects: 100% (103/103), done.
remote: Total 3354 (delta 101), reused 118 (delta 79), pack-reused 3154
Receiving objects: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, done.
Resolving deltas: 100% (2176/2176), done.Going to libbpf very simple:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcOur next plan in this section is as follows: we will write a BPF program like BPF_PROG_TYPE_XDP, the same as in the previous example, but in C, compile it with clang, and write a helper program that will load it into the kernel. In the following sections, we will expand the capabilities of both the BPF program and the helper program.
Example: building a complete application with libbpf
First we use the file /sys/kernel/btf/vmlinux, which was mentioned above, and create its equivalent in the form of a header file:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hThis file will store all the data structures that are available in our kernel, for example, this is how the IPv4 header is defined in the kernel:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};Now we will write our BPF program in C language:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Although the program we have turned out to be very simple, we still need to pay attention to many details. First, the first header file we include is vmlinux.h, which we just generated with bpftool btf dump - now we do not need to install the kernel-headers package to find out what the kernel structures look like. The following header file comes to us from the library libbpf. Now we only need it to define the macro SEC, which sends the character to the appropriate section of the ELF object file. Our program is contained in the section xdp/simple, where before the slash we define the BPF program type - this is the convention used in libbpf, based on the section name, it will substitute the correct type on startup bpf(2). The BPF program itself on C - very simple and consists of one line return XDP_PASS. Finally, a separate section "license" contains the name of the license.
We can compile our program with llvm/clang, version >= 10.0.0 or better (see section ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oOf the interesting features: we specify the target architecture -target bpf and path to headers libbpfwhich we have recently installed. Also, don't forget about -O2, without this option, you may be in for some surprises later on. Let's look at our code, did we manage to write the program we wanted?
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: r0 = 2
1: exitYes, it worked! Now, we have a binary file with a program, and we want to create an application that will load it into the kernel. For this the library libbpf offers us two options - use a lower-level API or a higher-level API. We will go the second way, because we want to learn how to write, download and connect BPF programs with minimal effort for their subsequent study.
First, we need to generate the "skeleton" of our program from its binary using the same utility bpftool - the Swiss knife of the BPF world (which can also be taken literally, since Daniel Borkman - one of the creators and maintainers of BPF - is Swiss):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hIn file xdp-simple.skel.h contains the binary code of our program and functions for managing - loading, attaching, deleting our object. In our simple case, this looks like overkill, but it also works in the case when the object file contains many BPF programs and maps, and to load this giant ELF, we just need to generate a skeleton and call one or two functions from the user application, which we will now write.
As a matter of fact, our loader program is trivial:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}Here struct xdp_simple_bpf defined in file xdp-simple.skel.h and describes our object file:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};We can see traces of a low-level API here: the structure struct bpf_program *simple и struct bpf_link *simple. The first structure describes specifically our program, written in the section xdp/simple, and the second describes how the program connects to the event source.
Function xdp_simple_bpf__open_and_load, opens an ELF object, parses it, creates all structures and substructures (besides the program, ELF contains other sections - data, readonly data, debug information, license, etc.), and then loads it into the kernel via a system call bpf, which we can check by compiling and running the program:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4Let's now look at our program with bpftool. Let's find its ID:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)and dump (we use the abbreviated form of the command bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitSomething new! The program printed pieces of our C source file. This was done by the library libbpf, which found the debug section in the binary, compiled it into a BTF object, loaded it into the kernel using BPF_BTF_LOAD, and then indicated the resulting file descriptor when loading the program with the command BPG_PROG_LOAD.
Kernel Helpers
BPF programs can run "external" functions - kernel helpers. These helper functions allow BPF programs to access kernel structures, manage maps, and also communicate with the "real world" - create perf events, manage hardware (for example, forward packets), and so on.
Example: bpf_get_smp_processor_id
As part of the “learn by example” paradigm, consider one of the helper functions, bpf_get_smp_processor_id(), in file kernel/bpf/helpers.c. It returns the processor number on which the BPF program that called it is running. But we are not so interested in its semantics as the fact that its implementation takes one line:
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}BPF helper function definitions are similar to system call definitions. LinuxHere, for example, a function is defined that has no arguments. (A function that takes, say, three arguments is defined using a macro BPF_CALL_3. The maximum number of arguments is five.) However, this is only the first part of the definition. The second part is to define the type structure struct bpf_func_proto, which contains a description of the helper function, understandable by the verifier:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};Registering Helper Functions
In order for BPF programs of a certain type to use this function, they must register it, for example, for the type BPF_PROG_TYPE_XDP a function is defined in the kernel xdp_func_proto, which, given the helper function ID, determines whether the XDP supports this function or not. Our function is :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}New types of BPF programs are "defined" in a file with a macro BPF_PROG_TYPE. Defined is in quotation marks because it is a logical definition, and in terms of the C language, the definition of a whole set of concrete structures occurs elsewhere. In particular, in the file kernel/bpf/verifier.c all definitions from file bpf_types.h are used to create an array of structures bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = & _name ## _verifier_ops,
#include <linux/bpf_types.h>
#undef BPF_PROG_TYPE
};That is, for each type of BPF programs, a pointer to a data structure of type struct bpf_verifier_ops, which is initialized with the value _name ## _verifier_ops, i.e., xdp_verifier_ops for xdp. Structure xdp_verifier_ops in file net/core/filter.c in the following way:
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};Here we see our familiar function xdp_func_proto, which will run the verifier every time it encounters a challenge some functions inside a BPF program, see .
Let's look at how a hypothetical BPF program uses the function bpf_get_smp_processor_id. To do this, we rewrite the program from our previous section as follows:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Symbol bpf_get_smp_processor_id в <bpf/bpf_helper_defs.h> Library libbpf How
static u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;i.e, bpf_get_smp_processor_id is a function pointer whose value is 8, where 8 is the value BPF_FUNC_get_smp_processor_id type enum bpf_fun_id, which is defined for us in the file vmlinux.h (file bpf_helper_defs.h generated by a script in the kernel, so "magic" numbers are ok). This function takes no arguments and returns a value of type __u32. When we run it in our program, clang generates an instruction BPF_CALL "correct kind". Let's compile the program and look at the section xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <<= 32
3: 77 01 00 00 20 00 00 00 r1 >>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 <LBB0_2>:
7: 95 00 00 00 00 00 00 00 exitIn the first line we see the instruction call, parameter IMM which is equal to 8, and SRC_REG - zero. By the ABI convention used by the verifier, this is the helper function call number eight. After its launch, the logic is simple. Return value from register r0 copied to r1 and on lines 2,3 it is reduced to the type u32 - the upper 32 bits are set to zero. On lines 4,5,6,7 we return 2 (XDP_PASS) or 1 (XDP_DROP) depending on whether the helper function returned zero or non-zero from line 0.
Let's test ourselves: load the program and look at the output bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <<= 32
3: (77) r1 >>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitOkay, the verifier has found the correct kernel-helper.
Example: passing arguments and finally running the program!
All runlevel helper functions have a prototype
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)Parameters to helper functions are passed in registers r1 r5, and the value is returned in a register r0. There are no functions that take more than five arguments, and it is not planned to add their support in the future.
Let's take a look at the new kernel helper and how BPF passes parameters. Let's rewrite xdp-simple.bpf.c as follows (the rest of the lines are unchanged):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("running on CPU%un", bpf_get_smp_processor_id());
return XDP_PASS;
}Our program prints the number of the CPU it is running on. Let's compile it and look at the code:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 <simple>:
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitIn lines 0-7 we push the string running on CPU%un, and then on line 8 we run the familiar bpf_get_smp_processor_id. In lines 9-12 we prepare the helper arguments bpf_printk - registers r1, r2, r3. Why are there three and not two? Because bpf_printk around a real helper bpf_trace_printkThe to which you want to pass the size of the format string.
Let's now add a couple of lines to xdp-simple.cso that our program connects to the interface lo and it really kicked off!
$ cat xdp-simple.c
#include <linux/if_link.h>
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}Here we use the function bpf_set_link_xdp_fd, which connects BPF programs of type XDP to network interfaces. We have hardcoded the interface number lo, which is always 1. We run the function two times to first detach the old program if it was attached. Note that now we don't need to call pause or an infinite loop: our loader program will exit, but the BPF program will not be destroyed, since it is connected to the event source. After successful download and connection, the program will be launched for each network packet coming to lo.
Download the program and look at the interface lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669The program we downloaded has ID 669 and the same ID we see on the interface lo. We'll send a couple of packages to 127.0.0.1 (request + reply):
$ ping -c1 localhostand now look at the contents of the debug virtual file /sys/kernel/debug/tracing/trace_pipe, in which bpf_printk writes his messages:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0Two packages were seen on lo and processed on CPU0 - our first full-fledged meaningless BPF program worked!
It is worth noting that bpf_printk writes to the debug file for a reason: this is not the best helper for use in production, but our goal was to show something simple.
Accessing maps from BPF programs
Example: using a map from a BPF program
In the previous sections, we learned how to create and use user-space maps, and now let's look at the core part. Let's start, as usual, with an example. Let's rewrite our program xdp-simple.bpf.c in the following way:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";At the beginning of the program, we added a map definition woo: is an array of 8 elements that stores values like u64 (in C we would define an array like this u64 woo[8]). In a programme "xdp/simple" we get the number of the current processor into a variable key and then using the helper function bpf_map_lookup_element we get a pointer to the corresponding entry in the array, which we increase by one. Translated into Russian: we calculate the statistics on which CPU the incoming packets were processed on. Let's try to run the program:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleLet's check that she's hooked on lo and send some packets:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneNow let's look at the contents of the array:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]Almost all processes were processed on CPU7. It doesn’t matter to us, the main thing is that the program works and we understood how to access maps from BPF programs - using .
mystical pointer
So, we can access the map from the BPF program using calls like
val = bpf_map_lookup_elem(&woo, &key);where the helper function looks like
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)but we are passing a pointer &woo to an unnamed structure struct { ... }...
If we look at the assembler of the program, we will see that the value &woo not actually defined (line 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: file format elf64-bpf
Disassembly of section xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...and is contained in relocations:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relocation section '.relxdp/simple' at offset 0xe18 contains 1 entries:
Offset Info Type Symbol's Value Symbol's Name
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooBut if we look at the already loaded program, we see a pointer to the correct map (line 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:64]
...Thus, we can conclude that at the time of launching our loader program, the link to &woo has been replaced by a library libbpf. First, we'll look at the output strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5We see that libbpf created a map woo and then loaded our program simple. Let's take a closer look at how we load the program:
- call
xdp_simple_bpf__open_and_loadfrom filexdp-simple.skel.h - which causes
xdp_simple_bpf__loadfrom filexdp-simple.skel.h - which causes
bpf_object__load_skeletonfrom filelibbpf/src/libbpf.c - which causes
bpf_object__load_xattrin thelibbpf/src/libbpf.c
The last function, among other things, will call bpf_object__create_maps, which creates or opens existing maps, turning them into file descriptors. (This is where we see BPF_MAP_CREATE in the output strace.) Next, the function is called bpf_object__relocate and it is she who interests us, since we remember what we saw woo in the relocation table. Exploring it, we eventually get into the function bpf_program__relocate, which and :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;So we take our instruction
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 lland replace the source register in it with BPF_PSEUDO_MAP_FD, and the first IMM to the file descriptor of our map and, if it is equal, for example, 0xdeadbeef, then as a result we get the instruction
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llThis is how map information is passed to the specific loaded BPF program. In this case, the map can be created using BPF_MAP_CREATE, and opened by ID using BPF_MAP_GET_FD_BY_ID.
Total, when using libbpf the algorithm is as follows:
- at compile time, for references to maps, entries are created in the relocation table
libbpfopens the ELF object, finds all used maps and creates file descriptors for them- file descriptors are loaded into the kernel as part of the instruction
LD64
As you understand, this is not all, and we will have to look into the core. Fortunately, we have a clue - we have registered the value BPF_PSEUDO_MAP_FD into the source register and we can bury it, which will lead us to the holy of all saints - kernel/bpf/verifier.c, where a function with a characteristic name replaces the file descriptor with the address of a structure of type struct bpf_map:
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) {
...
f = fdget(insn[0].imm);
map = __bpf_map_get(f);
if (insn->src_reg == BPF_PSEUDO_MAP_FD) {
addr = (unsigned long)map;
}
insn[0].imm = (u32)addr;
insn[1].imm = addr >> 32;(full code can be found ). So we can complete our algorithm:
- during the loading of the program, the verifier checks the correct use of the map and prescribes the address of the corresponding structure
struct bpf_map
When loading the ELF binary with libbpf there is a lot more going on, but we will discuss it in other articles.
Loading programs and maps without libbpf
As promised, here is an example for readers who want to know how to create and load a program that uses maps without help. libbpf. This can be useful when you're working in an environment for which you can't build dependencies, or saving every bit, or writing a program like , which generates BPF binary code on the fly.
To make it easier to follow the logic, we will rewrite our example for this purpose xdp-simple. You can find the complete and slightly extended code of the program considered in this example in this .
The logic of our application is as follows:
- create map type
BPF_MAP_TYPE_ARRAYusing the commandBPF_MAP_CREATE, - create a program that uses this map,
- connect the program to the interface
lo,
which translates to human
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}Here map_create creates a map just like we did in the first syscall example bpf - "kernel, please make me a new map in the form of an array of 8 elements like __u64 and give me back the file descriptor":
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}The program is also easy to load:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns)/sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}The hard part prog_load is the definition of our BPF program as an array of structures struct bpf_insn insns[]. But since we're using the program we have in C, we can cheat a little:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2>
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 <LBB0_2>:
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitIn total, we need to write 14 instructions in the form of structures like struct bpf_insn (advice: take the dump from above, re-read the instructions section, open и and try to define struct bpf_insn insns[] on one's own):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* placeholder */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};An exercise for those who did not write it themselves - find map_fd.
There is one more undisclosed part in our program - xdp_attach. Unfortunately, programs like XDP cannot be connected using the system call bpfThe people who created BPF and XDP were from the online community. Linux, which means they used the one that was most familiar to them (but not for normal people) interface of interaction with the core: , see also . The easiest way to implement xdp_attach is copying the code from libbpf, namely, from the file , which we did, shortening it a bit:
Welcome to the world of netlink sockets
Open a netlink socket like NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlink error reporting not supported");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}We read from such a socket:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len < 0)
err(1, "recv");
if (len == 0)
break;
for (nh = (struct nlmsghdr *)buf; NLMSG_OK(nh, len);
nh = NLMSG_NEXT(nh, len)) {
if (nh->nlmsg_pid != nl_pid)
errx(1, "wrong pid");
if (nh->nlmsg_seq != seq)
errx(1, "INVSEQ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); too many code to copy...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}Finally, here is our function that opens a socket and sends a special message to it containing a file descriptor:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock < 0)
return sock;
memset(&req, 0, sizeof(req));
req.nh.nlmsg_len = NLMSG_LENGTH(sizeof(struct ifinfomsg));
req.nh.nlmsg_flags = NLM_F_REQUEST | NLM_F_ACK;
req.nh.nlmsg_type = RTM_SETLINK;
req.nh.nlmsg_pid = 0;
req.nh.nlmsg_seq = ++seq;
req.ifinfo.ifi_family = AF_UNSPEC;
req.ifinfo.ifi_index = ifindex;
/* started nested attribute for XDP */
nla = (struct nlattr *)(((char *)&req)
+ NLMSG_ALIGN(req.nh.nlmsg_len));
nla->nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}So, everything is ready for testing:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ exited with 0 +++Let's see if our program is connected to lo:
$ ip l show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160Let's send pings and look at the map:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
Found 8 elementsHurray, everything works. Note, by the way, that our map is again displayed as bytes. This is due to the fact that, in contrast to libbpf we didn't load type information (BTF). But we will talk more about this next time.
Development tools
In this section, we'll take a look at the minimal BPF developer toolkit.
Generally speaking, nothing special is needed to develop BPF programs - BPF runs on any decent distribution kernel, and programs are built using clang, which can be supplied from the package. However, due to the fact that BPF is under development, the core and tools are constantly changing, if you do not want to write BPF programs in the old fashioned ways from 2019, then you will have to build
llvm/clangpahole- its core
bpftool
(For reference: this section and all examples in the article were run on Debian 10.)
llvm/clang
BPF is friendly with LLVM, and although recently BPF programs can be compiled with gcc, all current development is done for LLVM. Therefore, the first thing we will do is build the current version clang from git:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... много времени спустя
$Now we can check if everything is assembled correctly:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM version 11.0.0git
Optimized build.
Default target: x86_64-unknown-linux-gnu
Host CPU: znver1
Registered Targets:
bpf - BPF (host endian)
bpfeb - BPF (big endian)
bpfel - BPF (little endian)
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64(Assembly instructions clang taken by me from .)
We will not install the newly built programs, but instead just add them to PATH, For example:
export PATH="`pwd`/bin:$PATH"(This can be added to .bashrc or in a separate file. Personally, I add things like this to ~/bin/activate-llvm.sh and when I need to do . activate-llvm.sh.)
pahole and btf
Utility pahole used when building the kernel to generate debug information in BTF format. We won't go into the details of the BTF technology in this article, other than the fact that it's convenient and we want to use it. Therefore, if you are going to build your kernel, first build pahole (without pahole you will not be able to build a kernel with the option CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeKernels for experimenting with BPF
When exploring the possibilities of BPF, I want to build my own core. This is generally not necessary, since you can build and load BPF programs on the distribution kernel, however, having your own kernel allows you to use the latest BPF features that will be in your distribution in months at best or, as is the case with some debugging tools, will not be covered at all in the foreseeable future. Also, its core makes it feel important to experiment with the code.
In order to build a kernel you need, firstly, the kernel itself, and secondly, a kernel configuration file. For experiments with BPF, we can use the usual core or one of the developer cores. Historically, BPF development has taken place within the network community. Linux and therefore all changes sooner or later go through David Miller, the network maintainer LinuxDepending on their nature—fixes or new features—network changes end up in one of two cores: or . Changes for BPF are distributed in the same way between и , which are then fired at net and net-next, respectively. For details see и . So choose a kernel based on your taste and the stability needs of the system you're testing on (*-next cores are the most unstable of those listed).
It is not within the scope of this article to talk about how to manage kernel configuration files - it is assumed that you either already know how to do this, or on one's own. However, the following instructions should be more or less enough to get you a working BPF-enabled system.
Download one of the above kernels:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextBuild a minimal working kernel config:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigEnable BPF options in file .config by choice (probably CONFIG_BPF will already be enabled since systemd uses it). Here is a list of options from the kernel used for this article:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF is not set
# CONFIG_BPFILTER is not set
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=yNext, we can easily build and install the modules and the kernel (by the way, you can build the kernel using the just built clangadding CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installand reboot with the new kernel (I use kexec from package kexec-tools):
v=5.8.0-rc6+ # если вы пересобираете текущее ядро, то можно делать v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
The most commonly used utility in the article will be the utility bpftool, supplied as part of the kernel LinuxIt is written and maintained by BPF developers for BPF developers and can be used to manage all types of BPF objects—load programs, create and modify maps, explore the BPF ecosystem, and more. Documentation in the form of source code for the man pages can be found or, already compiled, .
At the time of writing the article bpftool comes ready-made only for RHEL, Fedora and Ubuntu (see, for example, , which tells the unfinished story of the wrapping bpftool в Debian). But if you have already assembled your kernel, then assemble bpftool as easy as pie:
$ cd ${linux}/tools/bpf/bpftool
# ... пропишите пути к последнему clang, как рассказано выше
$ make -s
Auto-detecting system features:
... libbfd: [ on ]
... disassembler-four-args: [ on ]
... zlib: [ on ]
... libcap: [ on ]
... clang-bpf-co-re: [ on ]
Auto-detecting system features:
... libelf: [ on ]
... zlib: [ on ]
... bpf: [ on ]
$(here ${linux} is your kernel directory.) After executing these commands bpftool will be collected in the directory ${linux}/tools/bpf/bpftool and it can be written on the path (first of all, the user root) or just copy to /usr/local/sbin.
Collect bpftool best with the latter clang, assembled as described above, and check whether it was assembled correctly using, for example, the command
$ sudo bpftool feature probe kernel
Scanning system configuration...
bpf() syscall for unprivileged users is enabled
JIT compiler is enabled
JIT compiler hardening is disabled
JIT compiler kallsyms exports are enabled for root
...which will show which BPF features are enabled in your kernel.
By the way, the previous command can be run as
# bpftool f p kThis is done by analogy with the utilities from the package iproute2, where we can, for example, say ip a s eth0 instead ip addr show dev eth0.
Conclusion
BPF allows shoeing a flea to effectively measure and change the functionality of the kernel on the fly. The system turned out to be very successful, in the best tradition of UNIX: a simple mechanism that allows (re)programming the kernel allowed a huge number of people and organizations to experiment. And, although the experiments, as well as the development of the BPF infrastructure itself, are far from over, the system already has a stable ABI that allows you to build a reliable, and most importantly, effective business logic.
I would like to note that, in my opinion, the technology turned out to be so popular because, on the one hand, it can play (the architecture of a machine can be understood more or less in one evening), and on the other hand, to solve problems that could not be solved (beautifully) before its appearance. These two components together make people experiment and dream, which leads to the emergence of more and more innovative solutions.
This article, although not very short, is only an introduction to the world of BPF and does not describe "advanced" features and important parts of the architecture. The road ahead is something like this: the next article will be an overview of BPF program types (there are 5.8 types of programs supported in the 30 kernel), then we will finally look at how to write real BPF applications using kernel tracing programs as an example, then it will be time for a more in-depth course on BPF architecture, and then for examples of BPF networking and security applications.
Previous articles in this series
Links
- BPF documentation from cilium, or rather from Daniel Borkman, one of the creators and maintainers of BPF. This is one of the first serious descriptions, which differs from the rest in that Daniel knows exactly what he is writing about and there are no blunders there. In particular, this document describes how to work with BPF programs of the XDP and TC types using the well-known utility
ipfrom packageiproute2.- the original file with documentation for the classic, and then for extended BPF. A good read if you want to dig into assembly language and the technical details of the architecture.
. It is rarely updated, but aptly, as Alexei Starovoitov (author of eBPF) and Andrii Nakryiko - (mantainer) write there
libbpf).. Interesting twitter thread by Quentin Monnet with examples and secrets of using bpftool.
. A gigantic (and still maintained) list of links to BPF documentation by Quentin Monnet.
Source: habr.com
