


Variti develops protection against bots and DDoS attacks, and also conducts stress and load testing. At the HighLoad++ 2018 conference, we talked about how to secure resources from various types of attacks. In short: isolate parts of the system, use cloud services and CDNs, and update regularly. But without specialized companies with protection, you still can’t cope 🙂
Before reading the text, you can read the short theses .
And if you do not like to read or just want to watch the video, the record of our report is below under the spoiler.
Video recording of the report

Many companies already know how to do load testing, but not everyone does stress testing. Some of our customers think that their site is invulnerable because they have a highload system and it protects well from attacks. We show that this is not entirely true.
Of course, before conducting tests, we obtain permission from the customer, with a signature and a seal, and with our help it is impossible to make a DDoS attack on anyone. Testing is carried out at the time chosen by the customer, when the attendance of his resource is minimal, and problems with access will not affect customers. In addition, since something can always go wrong during the testing process, we have constant contact with the customer. This allows not only to report on the results achieved, but also to change something during testing. At the end of testing, we always draw up a report in which we point out the identified shortcomings and give recommendations on how to eliminate the weaknesses of the site.
How it works
When testing, we emulate a botnet. Since we work with clients that are not located in our networks, in order for the test not to end in the first minute due to the activation of limits or protection, we load not from one IP, but from our own subnet. Plus, to create a significant load, we have our own fairly powerful test server.
Postulates
A lot doesn't mean good
The less load we can bring the resource to failure, the better. If you can make the site stop functioning at one request per second, or even one request per minute, that's great. Because according to the law of meanness, users or attackers will accidentally fall into this particular vulnerability.
Partial failure is better than complete
We always advise making systems heterogeneous. Moreover, it is worth separating them at the physical level, and not just by containerization. In the case of a physical separation, even if something fails on the site, it is likely that it will not stop working completely, and users will still have access to at least part of the functionality.
The right architecture is the foundation of sustainability
The fault tolerance of a resource and its ability to withstand attacks and loads should be laid down at the design stage, in fact, at the stage of drawing the first block diagrams in a notebook. Because if fatal errors creep in, it is possible to correct them in the future, but it is very difficult.
Not only the code should be good, but also the config
Many people think that a good development team guarantees service resilience. A good development team is indeed essential, but there also needs to be good operations, good DevOps. This means you need specialists who can configure it correctly. Linux and the network, correctly write NGINX configuration files, set limits, and so on. Otherwise, the resource will only work well in testing, but at some point in production, everything will break.
Differences between load and stress testing
Load testing allows you to identify the limits of the system functioning. Stress testing is aimed at finding weaknesses in the system and is used to break this system and see how it will behave in the process of failure of certain parts. At the same time, the nature of the load usually remains unknown to the customer until the start of stress testing.
Distinctive features of L7 attacks
We usually divide load types into L7 and L3&4 loads. L7 is the load at the application level, most often it is understood only as HTTP, but we mean any load at the TCP protocol level.
L7 attacks have certain distinguishing features. Firstly, they come directly to the application, that is, it is unlikely that they will be reflected by network means. Such attacks use logic, and due to this, they consume CPU, memory, disk, database, and other resources very efficiently and with little traffic.
HTTP Flood
In the case of any attack, the load is easier to create than to process, and in the case of L7 this is also true. It is not always easy to distinguish attack traffic from legitimate traffic, and most often this can be done by frequency, but if everything is planned correctly, then it is impossible to understand from the logs where the attack is and where the legitimate requests are.
As a first example, consider the HTTP Flood attack. The graph shows that such attacks are usually very powerful, in the example below, the peak number of requests exceeded 600 thousand per minute.
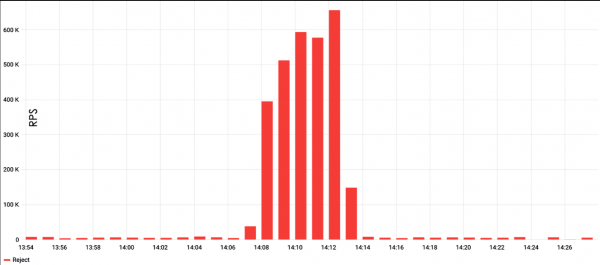
HTTP Flood is the easiest way to generate load. It usually takes some kind of load testing tool, such as ApacheBench, and sets a query and a target. With such a simple approach, there is a high probability of running into server caching, but it is easy to get around. For example, by adding random strings to the request, which will force the server to constantly return a fresh page.
Also, do not forget about the user-agent in the process of creating a load. Many user-agents of popular testing tools are filtered by system administrators, in which case the load may simply not reach the backend. You can significantly improve the result by inserting a more or less valid header from the browser into the request.
While HTTP Flood attacks are simple, they also have their drawbacks. First, it takes a lot of power to create a load. Secondly, such attacks are very easy to detect, especially if they come from the same address. As a result, requests immediately begin to be filtered either by system administrators or even at the provider level.
What to look for
To reduce the number of requests per second and at the same time not lose efficiency, you need to show a little imagination and explore the site. So, you can load not only the channel or the server, but also individual parts of the application, for example, databases or file systems. You can also look for places on the site that do big calculations: calculators, product selection pages, and so on. Finally, it often happens that the site has some kind of php script that generates a page of several hundred thousand lines. Such a script also heavily loads the server and can become a target for attack.
Where to look
When we scan a resource before testing, we first of all look, of course, at the site itself. We are looking for all kinds of input fields, heavy files - in general, everything that can create problems for the resource and slow it down. The commonplace development tools in Google Chrome and Firefox help here, showing the response time of the page.
We also scan subdomains. For example, there is a certain online store, abc.com, and it has a subdomain admin.abc.com. Most likely, this is an admin panel with authorization, but if you put a load on it, then it can create problems for the main resource.
The site may have a subdomain api.abc.com. Most likely, this is a resource for mobile applications. The application can be found in the App Store or Google Play, set up a special access point, dissect the API and register test accounts. The problem is that often people think that everything that is protected by authorization is not vulnerable to denial of service attacks. Allegedly, authorization is the best CAPTCHA, but it is not. Making 10-20 test accounts is easy, and by creating them, we get access to complex and overt functionality.
Naturally, we look at the history, at robots.txt and WebArchive, ViewDNS, looking for old versions of the resource. Sometimes it happens that the developers rolled out, say, mail2.yandex.net, but the old version, mail.yandex.net, remained. This mail.yandex.net is no longer supported, development resources are not allocated to it, but it continues to consume the database. Accordingly, with the help of the old version, you can effectively use the resources of the backend and everything that is behind the layout. Of course, this does not always happen, but we still encounter this quite often anyway.
Naturally, we prepare all request parameters, the cookie structure. You can, say, throw some value into the JSON array inside the cookie, create a large nesting and make the resource work for an unreasonably long time.
Search load
The first thing that comes to mind when exploring the site is to load the database, since almost everyone has a search, and unfortunately, almost everyone has it poorly protected. For some reason, developers do not pay enough attention to search. But there is one recommendation here - you should not make the same type of requests, because you may encounter caching, as is the case with HTTP flood.
Making random queries to the database is also not always efficient. It's much better to create a list of keywords that are relevant to the search. If we return to the example of an online store: let's say the site sells car tires and allows you to set the tire radius, type of car, and other parameters. Accordingly, combinations of relevant words will make the database work in much more complex conditions.
In addition, it is worth using pagination: it is much more difficult for the search to give the penultimate page of the search results than the first one. That is, with the help of pagination, you can diversify the load a little.
The example below shows the load in the search. It can be seen that from the very first second of the test at a speed of ten requests per second, the site lay down and did not respond.
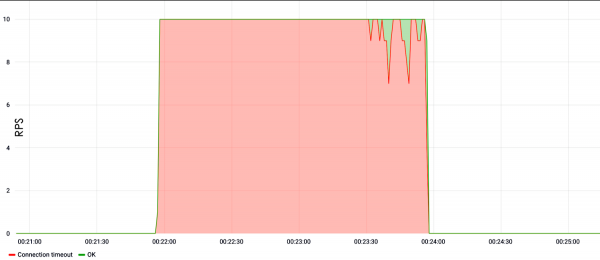
If there is no search?
If there is no search, then this does not mean that the site does not contain other vulnerable input fields. Authorization can be such a field. Now developers like to make complex hashes to protect the login database from a rainbow table attack. This is good, but such hashes consume a lot of CPU resources. A large flow of false authorizations leads to a processor failure, and as a result, the site stops working at the exit.
The presence on the site of all kinds of forms for comments and feedback is a reason to send very large texts there or simply create a massive flood. Sometimes sites accept attachments, including those in gzip format. In this case, we take a 1TB file, use gzip to compress it to a few bytes or kilobytes and send it to the site. Then it is unzipped and a very interesting effect is obtained.
Rest API
I would like to pay a little attention to such popular services today as the Rest API. Securing a Rest API is much more difficult than a regular website. For the Rest API, even banal methods of protection against password brute force and other illegitimate activity do not work.
The Rest API is very easy to break because it talks directly to the database. At the same time, the withdrawal of such a service entails quite serious consequences for the business. The fact is that the Rest API is usually tied not only to the main site, but also to a mobile application, some internal business resources. And if it all falls down, then the effect is much stronger than in the case of the failure of a simple site.
Heavy content load
If we are offered to test some ordinary single-page application, landing page, business card site that does not have complex functionality, we are looking for heavy content. For example, large pictures that the server gives, binary files, pdf documentation - we are trying to download all this. Such tests load the file system well and clog channels, and therefore are effective. That is, even if you do not put the server down, downloading a large file at low speeds, then you will simply clog the channel of the target server and then a denial of service will occur.
On the example of such a test, it can be seen that at a speed of 30 RPS, the site stopped responding, or issued 500 server errors.
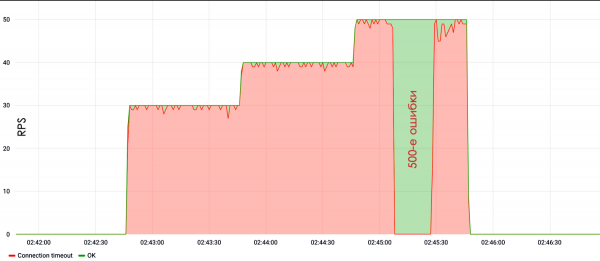
Do not forget about setting up servers. You can often find that a person bought a virtual machine, installed Apache there, configured everything by default, placed a php application, and below you can see the result.
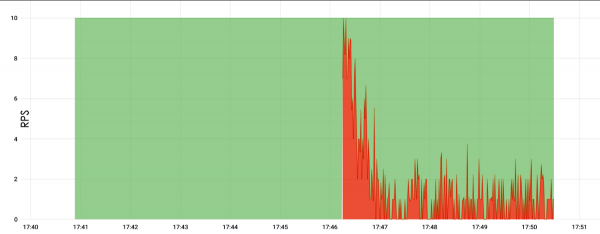
Here the load went to the root and was only 10 RPS. We waited 5 minutes and the server went down. To the end, however, it is not known why he fell, but there is an assumption that he simply ate too much memory, and therefore stopped responding.
wave based
In the last year or two, wave attacks have become quite popular. This is due to the fact that many organizations buy certain pieces of hardware for protection against DDoS, which require a certain amount of time to accumulate statistics to start filtering an attack. That is, they do not filter the attack in the first 30-40 seconds, because they accumulate data and learn. Accordingly, in these 30-40 seconds, so much can be launched on the site that the resource will lie for a long time until all requests are raked.
In the case of the attack below, there was an interval of 10 minutes, after which a new, modified portion of the attack arrived.
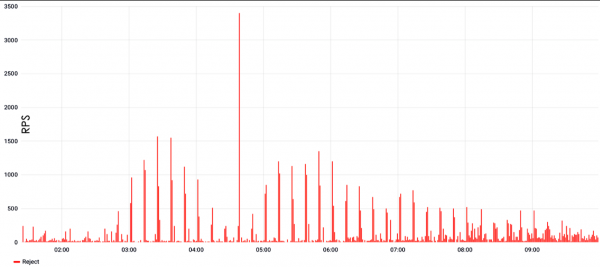
That is, the defense learned, launched the filtering, but a new, completely different portion of the attack arrived, and the defense began training again. In fact, filtering stops working, protection becomes ineffective, and the site is unavailable.
Wave attacks are characterized by very high values at the peak, it can reach one hundred thousand or a million requests per second, in the case of L7. If we talk about L3 & 4, then there can be hundreds of gigabits of traffic, or, accordingly, hundreds of mpps, if you count in packets.
The problem with such attacks is synchronization. Attacks come from a botnet, and a high degree of synchronization is required to create a very large one-time spike. And this coordination does not always work out: sometimes the output is some kind of parabolic peak, which looks rather pathetic.
Not HTTP Single
In addition to HTTP at the L7 level, we like to exploit other protocols. As a rule, a regular website, especially a regular hosting, has mail protocols and MySQL sticking out. Mail protocols are less stressed than databases, but they can also be loaded quite efficiently and result in an overloaded CPU on the server.
We have had real success with the 2016 SSH vulnerability. Now this vulnerability has been fixed for almost everyone, but this does not mean that you cannot submit a load to SSH. Can. It's just that a huge load of authorizations is served, SSH eats up almost the entire CPU on the server, and then the website develops from one or two requests per second. Accordingly, these one or two requests from the logs cannot be distinguished from the legitimate load.
Remain relevant and a lot of connections that we open in the servers. Previously, Apache sinned with this, now nginx actually sins with this, since it is often configured by default. The number of connections that nginx can keep open is limited, so we open this number of connections, nginx no longer accepts a new connection, and the site does not work at the exit.
Our test cluster has enough CPU to attack the SSL handshake. In principle, as practice shows, botnets also sometimes like to do this. On the one hand, it is clear that SSL is indispensable, because Google issuance, ranking, security. On the other hand, SSL unfortunately has a CPU problem.
L3&4
When we talk about an attack at L3&4 levels, we are usually talking about an attack at the channel level. Such a load is almost always distinguishable from a legitimate one, unless it is a SYN-flood attack. The problem with SYN flood attacks for defenses is the sheer volume. The maximum value of L3&4 was 1,5-2 Tbps. Such traffic is very difficult to process even for large companies, including Oracle and Google.
SYN and SYN-ACK are packets that are used when establishing a connection. Therefore, it is difficult to distinguish SYN-flood from a legitimate load: it is not clear whether this is a SYN that came to establish a connection, or part of a flood.
UDP flood
Usually attackers do not have the power that we have, so amplification can be used to organize attacks. That is, an attacker scans the Internet and finds either vulnerable or misconfigured servers, which, for example, in response to one SYN packet, respond with three SYN-ACKs. By spoofing the source address from the address of the target server, one packet can increase the power, say, three times, and redirect traffic to the victim.
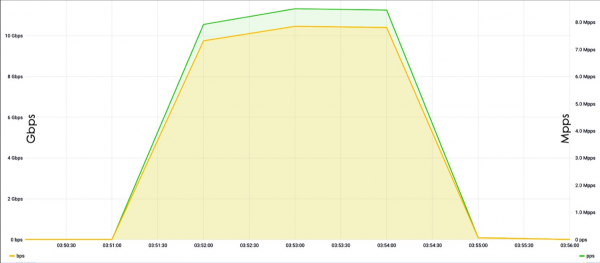
The problem with amplifications is that they are difficult to detect. From the latest examples, one can cite the sensational case with the vulnerable memcached. Plus, now there are a lot of IoT devices, IP cameras, which are also mostly configured by default, and by default they are configured incorrectly, so attackers use such devices most often to attack.
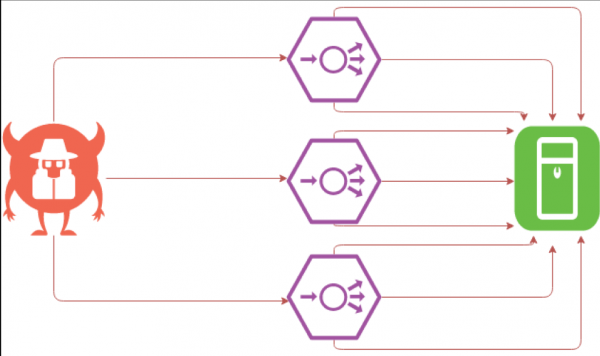
Difficult SYN-flood
SYN-flood is probably the most interesting type of attack from a developer's point of view. The problem is that often system administrators use IP blocking for protection. Moreover, blocking by IP affects not only system administrators who act according to scripts, but, unfortunately, some protection systems that are bought for a lot of money.
This method can turn into a disaster, because if the attackers replace IP addresses, the company will block its own subnet. When the firewall blocks its own cluster, external communications will be disrupted and the resource will fail.
Moreover, blocking your own network is easy. If the client's office has a WI-Fi network, or if the performance of resources is measured using various monitors, then we take the IP address of this monitoring system or office Wi-Fi client, and use it as a source. At the output, the resource seems to be available, but the target IP addresses are blocked. So, the Wi-Fi network of the HighLoad conference, where a new product of the company is presented, can be blocked - and this entails certain business and economic costs.
During testing, we cannot use amplification via memcached by some external resources, because there are agreements to feed traffic only to allowed IP addresses. Accordingly, we use amplification through SYN and SYN-ACK, when the system responds to sending one SYN with two or three SYN-ACKs, and the attack is multiplied two to three times at the output.
Tools
One of the main tools that we use to load at the L7 level is Yandex-tank. In particular, a phantom is used as a gun, plus there are several scripts for generating cartridges and for analyzing the results.
Tcpdump is used to analyze network traffic, and Nmap is used for server analysis. OpenSSL and a bit of custom magic with the DPDK library are used to generate load at the L3 and L4 levels. DPDK is an Intel library that allows you to work with the network interface without going through the stack. Linux, thereby increasing efficiency. Naturally, we use DPDK not only at L3 and L4, but also at L7, because it allows us to generate very high loads, up to several million requests per second from a single machine.
We also use certain traffic generators and special tools that we write for specific tests. If we recall the vulnerability under SSH, then it cannot be exploited with the above set. If we attack the mail protocol, then we take mail utilities or simply write scripts on them.
Conclusions
As a conclusion, I would like to say:
- In addition to the classic load testing, it is also necessary to conduct stress testing. We have a real-life example where a partner's subcontractor only performed load testing. It showed that the resource can withstand the standard load. But then an abnormal load appeared, site visitors began to use the resource a little differently, and at the exit the subcontractor lay down. Thus, it is worth looking for vulnerabilities even if you are already protected from DDoS attacks.
- It is necessary to isolate some parts of the system from others. If you have a search, you need to move it to separate machines, that is, not even to the docker. Because if the search or authorization fails, then at least something will continue to work. In the case of an online store, users will continue to find products in the catalog, go from the aggregator, buy if they are already authorized, or log in through OAuth2.
- Do not neglect all kinds of cloud services.
- Use a CDN not only to optimize network latency, but also as a means of protecting against channel exhaustion attacks and simply flooding into static.
- It is necessary to use specialized protection services. You cannot protect yourself against L3&4 attacks at the channel level, because you most likely simply do not have enough channel. You are also unlikely to fight off L7 attacks, since they can be very large. Plus, the search for small attacks is still the prerogative of special services, special algorithms.
- Update regularly. This applies not only to the kernel, but also to the SSH daemon, especially if you have them open to the outside. In principle, everything needs to be updated, because you are unlikely to be able to track certain vulnerabilities on your own.
Source: habr.com
