

Transcription of the 2015 report by Alexey Lesovsky "Deep dive into PostgreSQL internal statistics"
Disclaimer from the author of the report: I note that this report is dated November 2015 - more than 4 years have passed and a lot of time has passed. Version 9.4 discussed in the report is no longer supported. Over the past 4 years, 5 new releases have been released in which a lot of innovations, improvements and changes regarding statistics have appeared, and some of the material is outdated and not relevant. As I reviewed, I tried to mark these places so as not to mislead you the reader. I did not rewrite these places, there are a lot of them, and as a result, a completely different report will turn out.
The PostgreSQL DBMS is a huge mechanism, and this mechanism consists of many subsystems, the coordinated work of which directly affects the performance of the DBMS. During operation, statistics and information about the operation of components are collected, which allows you to evaluate the effectiveness of PostgreSQL and take measures to improve performance. However, there is a lot of this information and it is presented in a rather simplified form. Processing this information and interpreting it is sometimes a completely non-trivial task, and the "zoo" of tools and utilities can easily confuse even an advanced DBA.


Good afternoon My name is Aleksey. As Ilya said, I will talk about PostgreSQL statistics.

PostgreSQL activity statistics. PostgreSQL has two statistics. Activity statistics, which will be discussed. And scheduler statistics about data distribution. I will talk specifically about PostgreSQL activity statistics, which allow us to judge performance and somehow improve it.
I will tell you how to effectively use statistics to solve a variety of problems that you have or may have.

What will not be in the report? In the report, I will not touch on the statistics of the scheduler, because. this is a separate topic for a separate report on how data is stored in the database and how the query planner gets an idea about the qualitative and quantitative characteristics of this data.
And there will be no tool reviews, I will not compare one product with another. There will be no advertising. Let's drop this.

I want to show you that using statistics is useful. It is necessary. Use it fearlessly. All we need is plain SQL and a basic knowledge of SQL.
And we'll talk about which statistics to choose to solve problems.

If we look at PostgreSQL and run a command on the operating system to view the processes, we will see a "black box". We will see some processes that do something, and by name we can roughly imagine what they are doing there, what they are doing. But, in fact, this is a black box, we cannot look inside.
We can look at the CPU load in top, we can see the memory utilization by some system utilities, but we will not be able to look inside PostgreSQL. For this we need other tools.
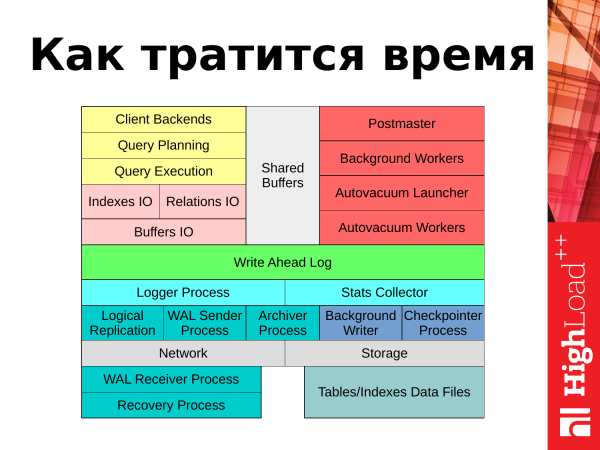
And continuing further, I will tell you where the time is spent. If we represent PostgreSQL in the form of such a scheme, then it will be possible to answer where the time is spent. These are two things: it is the processing of client requests from applications and the background tasks that PostgreSQL performs to keep it running.
If we start looking at the top left corner, we can see how client requests are processed. The request comes from the application and a client session is opened for further work. The request is passed to the scheduler. The planner builds a query plan. Sends it further for execution. There is some kind of block I / O data associated with tables and indexes. The necessary data is read from disks into memory in a special area called "shared buffers". The results of the query, if they are updates, deletes, are recorded in the transaction log in WAL. Some statistical information goes into the log or statistics collector. And the result of the request is given back to the client. After that, the client can repeat everything with a new request.
What do we have with background tasks and background processes? We have several processes that keep the database running and running normally. These processes will also be covered in the report: these are autovacuum, checkpointer, processes related to replication, background writer. I will touch on each of them as I report.

What are the problems with statistics?
- Lots of information. PostgreSQL 9.4 provides 109 metrics for viewing statistics data. However, if the database stores many tables, schemas, databases, then all these metrics will have to be multiplied by the corresponding number of tables, databases. That is, there is even more information. And it's very easy to drown in it.
- The next problem is that statistics are represented by counters. If we look at these statistics, we will see constantly increasing counters. And if a lot of time has passed since the statistics were reset, we will see billions of values. And they don't tell us anything.
- There is no history. If you have some kind of failure, something fell 15-30 minutes ago, you will not be able to use the statistics and see what happened 15-30 minutes ago. This is problem.
- The lack of a tool built into PostgreSQL is a problem. The kernel developers do not provide any utility. They don't have anything like that. They just give statistics in the database. Use it, make a request to it, whatever you want, then do it.
- Since there is no tool built into PostgreSQL, this causes another problem. Lots of third party tools. Every company that has more or less direct hands is trying to write its own program. And as a result, the community has a lot of tools that you can use to work with statistics. And in some tools there are some features, in other tools there are no other features, or there are some new features. And a situation arises that you need to use two, three, or four tools that overlap each other and have different functions. This is very unpleasant.

What follows from this? It is important to be able to take statistics directly so as not to depend on programs, or somehow improve these programs yourself: add some functions to get your benefit.
And you need basic knowledge of SQL. To get some data from statistics, you need to make SQL queries, i.e. you need to know how select, join are made.

Statistics tell us several things. They can be divided into categories.
- The first category is the events taking place in the database. This is when some event occurs in the database: a query, a table access, autovacuum, commits, then these are all events. The counters corresponding to these events are incremented. And we can track these events.
- The second category is the properties of objects such as tables, databases. They have properties. This is the size of the tables. We can track the growth of tables, the growth of indexes. We can see changes in dynamics.
- And the third category is the time spent on the event. Request is an event. It has its own specific measure of duration. Started here, ended here. We can track it. Either the time of reading a block from disk or writing. These things are also tracked.

Sources of statistics are presented as follows:
- In shared memory (shared buffers) there is a segment for placing static data there, there are also those counters that are constantly incremented when certain events occur, or some moments arise in the operation of the database.
- All these counters are not available to the user and are not even available to the administrator. These are low level things. To access them, PostgreSQL provides an interface in the form of SQL functions. We can make select selections using these functions and get some kind of metric (or set of metrics).
- However, it is not always convenient to use these functions, so functions are the basis for views (VIEWs). These are virtual tables that provide statistics on a specific subsystem, or on some set of events in the database.
- These built-in views (VIEWs) are the main user interface for working with statistics. They are available by default without any additional settings, you can immediately use them, watch, take information from there. And there are also contribs. Contribs are official. You can install the postgresql-contrib package (for example, postgresql94-contrib), load the necessary module in the configuration, specify parameters for it, restart PostgreSQL and you can use it. (Note. Depending on the distribution, in recent versions of contrib the package is part of the main package).
- And there are unofficial contrib. They are not supplied with the standard PostgreSQL distribution. They must either be compiled or installed as a library. Options can be very different, depending on what the developer of this unofficial contrib came up with.

This slide shows all those views (VIEWs) and some of those functions that are available in PostgreSQL 9.4. As we can see, there are a lot of them. And it's pretty easy to get confused if you're experiencing it for the first time.
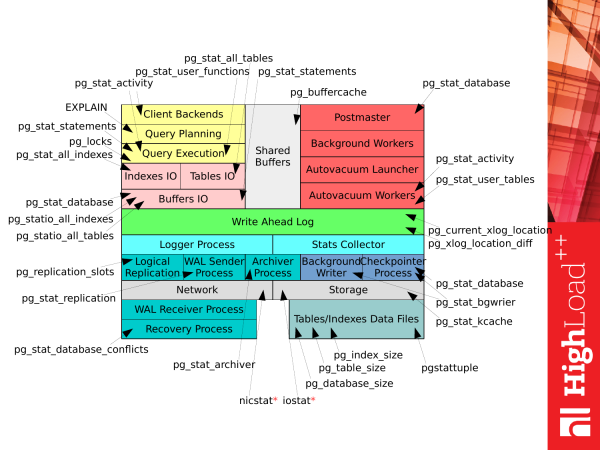
However, if we take the previous picture Как тратится время на PostgreSQL and compatible with this list, we get this picture. Each view (VIEWs), or each function, we can use for one purpose or another to obtain the appropriate statistics when we have PostgreSQL running. And we can already get some information about the operation of the subsystem.
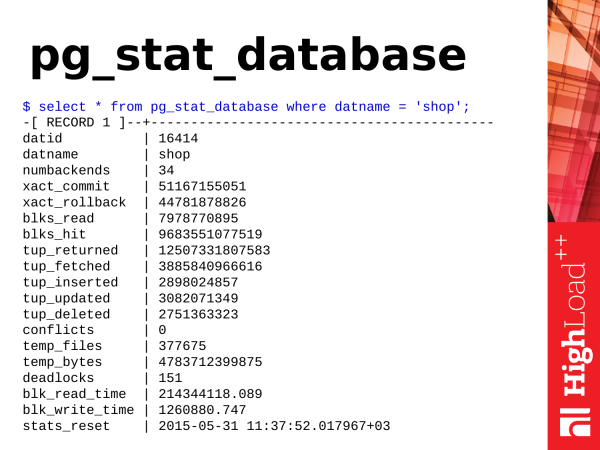
The first thing we'll look at is pg_stat_database. As we can see, this is a representation. It contains a lot of information. The most varied information. And it gives very useful knowledge of what we have going on in the database.
What can we take from there? Let's start with the simplest things.

select
sum(blks_hit)*100/sum(blks_hit+blks_read) as hit_ratio
from pg_stat_database;The first thing we can look at is the cache hit percentage. Cache hit percentage is a useful metric. It allows you to estimate how much data is taken from the shared buffers cache, and how much is read from disk.
It is clear that the more cache hit we have, the better. We evaluate this metric as a percentage. And, for example, if we have a percentage of these cache hits greater than 90%, then this is good. If it drops below 90%, then we don't have enough memory to keep the hot head of data in memory. And in order to use this data, PostgreSQL is forced to access the disk and this is slower than if the data were read from memory. And you need to think about increasing memory: either increase shared buffers, or increase iron memory (RAM).
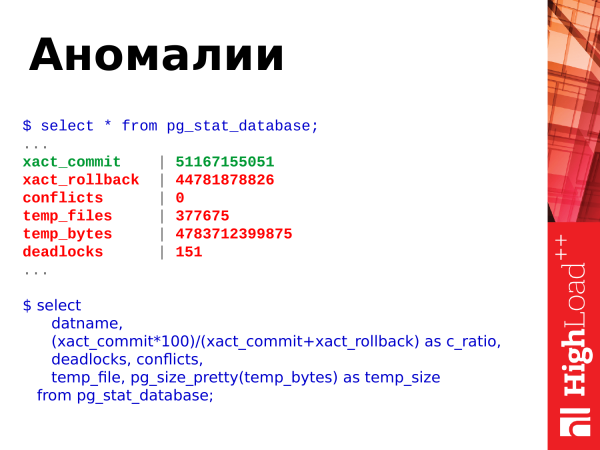
select
datname,
(xact_commit*100)/(xact_commit+xact_rollback) as c_ratio,
deadlocks, conflicts,
temp_file, pg_size_pretty(temp_bytes) as temp_size
from pg_stat_database;What else can be taken from this performance? You can see the anomalies occurring in the database. What is shown here? There are commits, rollbacks, creation of temporary files, their size, deadlocks and conflicts.
We can use this request. This SQL is pretty simple. And we can see this data for ourselves.
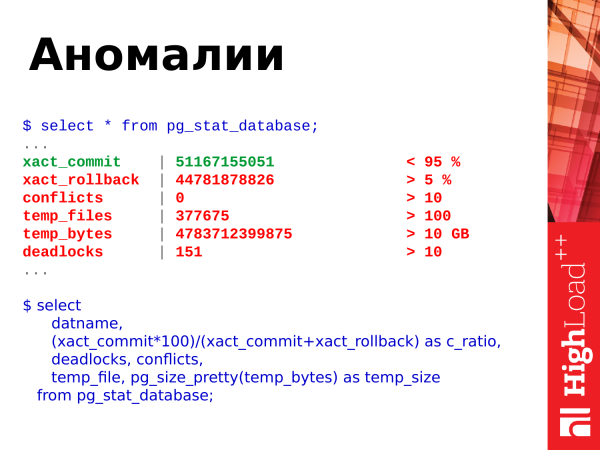
And here are the threshold values. We look at the ratio of commits and rollbacks. Commits is a successful confirmation of the transaction. Rollbacks is a rollback, i.e. the transaction did some work, strained the database, considered something, and then a failure occurred, and the results of the transaction are discarded. i.e. the number of rollbacks constantly increasing is bad. And you should somehow avoid them, and edit the code so that this does not happen.
Conflicts are related to replication. And they should be avoided too. If you have some queries that are executed on the replica and conflicts arise, then you need to analyze these conflicts and see what happens. Details can be found in the logs. And resolve conflicts so that application requests work without errors.
Deadlocks is also a bad situation. When requests compete for resources, one request accessed one resource and took the lock, the second request accessed the second resource and also took the lock, and then both requests accessed each other's resources and blocked waiting for the neighbor to release the lock. This is also a problematic situation. They need to be addressed at the level of rewriting applications and serializing access to resources. And if you see that your deadlocks are constantly increasing, you need to look at the details in the logs, analyze the situations that have arisen and see what the problem is.
Temporary files (temp_files) are also bad. When a user request does not have enough memory to accommodate the operational, temporary data, it creates a file on disk. And all the operations that he could perform in a temporary buffer in memory, he begins to perform already on the disk. It's slow. This increases the query execution time. And the client that sent a request to PostgreSQL will receive a response a little later. If all these operations are performed in memory, Postgres will respond much faster and the client will wait less.
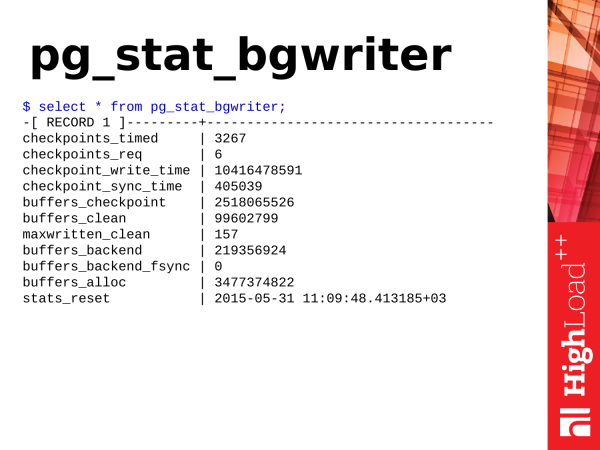
pg_stat_bgwriter - This view describes the operation of two PostgreSQL background subsystems: checkpointer и background writer.

To begin with, let's analyze the control points, the so-called. checkpoints. What are checkpoints? A checkpoint is a position in the transaction log indicating that all data changes committed in the log are successfully synchronized with the data on disk. The process, depending on the workload and settings, can be lengthy and mostly consists of synchronizing dirty pages in shared buffers with data files on disk. What is it for? If PostgreSQL was accessing the disk all the time and taking data from there, and writing data on each access, it would be slow. Therefore, PostgreSQL has a memory segment, the size of which depends on the parameters in the configuration. Postgres allocates operational data in this memory for further processing or querying. In the case of data change requests, they are changed. And we get two versions of the data. One is in memory, the other is on disk. And periodically you need to synchronize this data. We need what is changed in memory to be synchronized to disk. This requires a checkpoint.
Checkpoint goes through shared buffers, marks dirty pages that they are needed for checkpoint. Then it starts the second pass through shared buffers. And the pages that are marked for checkpoint, he already synchronizes them. Thus, the data is synchronized already with the disk.
There are two types of control points. One checkpoint is executed on timeout. This checkpoint is useful and good - checkpoint_timed. And there are checkpoints on demand - checkpoint required. Such a checkpoint occurs when we have a very large data record. We recorded a lot of transaction logs. And PostgreSQL believes that it needs to synchronize all this as quickly as possible, make a checkpoint and move on.
And if you looked at the statistics pg_stat_bgwriter and see what you have checkpoint_req is much larger than checkpoint_timed, then this is bad. Why bad? This means that PostgreSQL is under constant stress when it needs to write data to disk. Checkpoint by timeout is less stressful and is executed according to the internal schedule and, as it were, stretched over time. PostgreSQL has the ability to pause in work and not strain the disk subsystem. This is useful for PostgreSQL. And requests that are executed during checkpoint will not experience stress from the fact that the disk subsystem is busy.
And there are three parameters to adjust the checkpoint:
сheckpoint_segments.сheckpoint_timeout.сheckpoint_competion_target.
They allow you to control the operation of control points. But I won't dwell on them. Their influence is a separate issue.
Attention: Version 9.4 considered in the report is no longer relevant. In modern versions of PostgreSQL, the parameter checkpoint_segments replaced by parameters min_wal_size и max_wal_size.

The next subsystem is the background writer − background writer. What is he doing? It runs constantly in an endless loop. It scans pages into shared buffers and flushes the dirty pages it finds to disk. In this way, it helps the checkpointer to do less work during checkpointing.
What else is he needed for? It provides for the need for clean pages in shared buffers if they are suddenly required (in large quantities and immediately) to accommodate data. Suppose a situation arose when the request required clean pages and they are already in shared buffers. Postgres backend he just takes them and uses them, he doesn't have to clean anything himself. But if suddenly there are no such pages, the backend pauses and starts searching for pages to flush them to disk and take them for its own needs - which negatively affects the time of the currently executing request. If you see that you have a parameter maxwritten_clean large, this means that the background writer is not doing its job and you need to increase the parameters bgwriter_lru_maxpagesso that he can do more work in one cycle, clear more pages.
And another very useful indicator is buffers_backend_fsync. Backends don't do fsync because it's slow. They pass fsync up the IO stack checkpointer. The checkpointer has its own queue, it periodically processes fsync and synchronizes pages in memory with files on disk. If the checkpointer queue is large and full, then the backend is forced to do fsync itself and this slows down the backend, i.e. the client will receive a response later than it could. If you see that you have this value greater than zero, then this is already a problem and you need to pay attention to the settings of the background writer and also evaluate the performance of the disk subsystem.
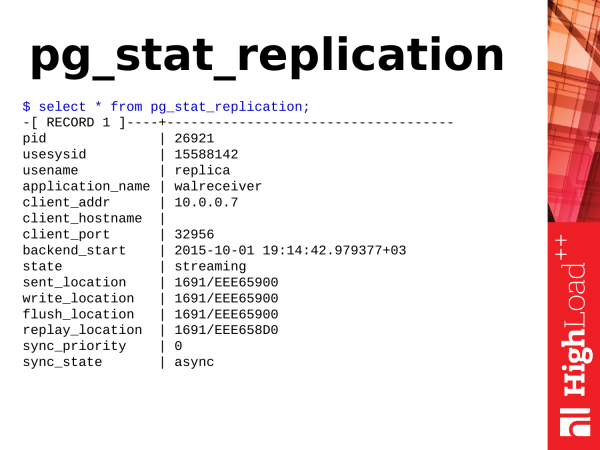
Attention: _The following text describes the statistical views associated with replication. Most of the view and function names have been renamed in Postgres 10. The essence of the renames was to replace xlog + wal и location + lsn in function/view names, etc. Particular example, function pg_xlog_location_diff() was renamed to pg_wal_lsn_diff()._
We have a lot here too. But we only need items related to location.
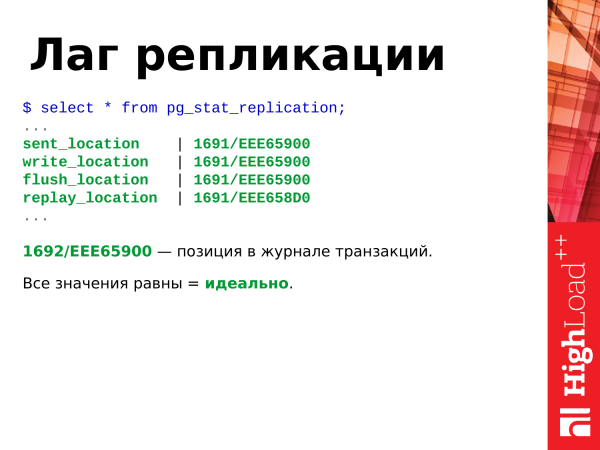
If we see that all values are equal, then this is ideal and the replica does not lag behind the master.
This hexadecimal position here is the position in the transaction log. It constantly increases if there is some activity in the database: inserts, deletes, etc.
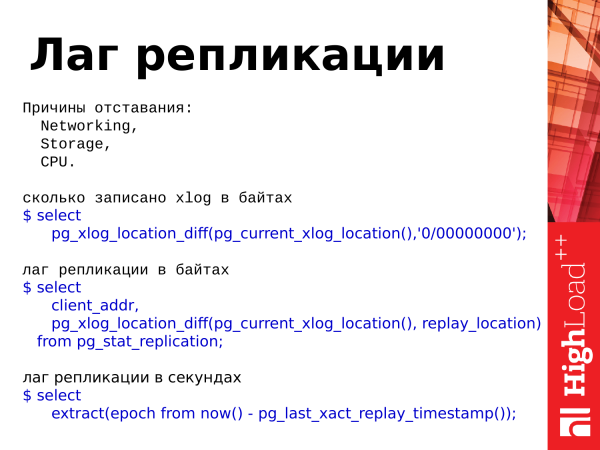
сколько записано xlog в байтах
$ select
pg_xlog_location_diff(pg_current_xlog_location(),'0/00000000');
лаг репликации в байтах
$ select
client_addr,
pg_xlog_location_diff(pg_current_xlog_location(), replay_location)
from pg_stat_replication;
лаг репликации в секундах
$ select
extract(epoch from now() - pg_last_xact_replay_timestamp());If these things are different, then there is some kind of lag. Lag is the lag of the replica from the master, i.e. the data differs between servers.
There are three reasons for the delay:
- It's the disk subsystem that can't handle file sync writes.
- These are possible network errors, or network overload, when the data does not have time to reach the replica and it cannot reproduce it.
- And the processor. The processor is a very rare case. And I've seen that two or three times, but that can happen too.
And here are three queries that allow us to use statistics. We can estimate how much is recorded in our transaction log. There is such a function pg_xlog_location_diff and we can estimate the replication lag in bytes and seconds. We also use the value from this view (VIEWs) for this.
Note: _Instead of pg_xlog_locationdiff() function, you can use the subtract operator and subtract one location from another. Comfortable.
With a lag, which is in seconds, there is one moment. If there is no activity on the master, the transaction was there about 15 minutes ago and there is no activity, and if we look at this lag on the replica, we will see a lag of 15 minutes. This is worth remembering. And it can lead to a stupor when you watched this lag.
pg_stat_all_tables is another useful view. It shows statistics on tables. When we have tables in the database, there is some activity with it, some actions, we can get this information from this view.

select
relname,
pg_size_pretty(pg_relation_size(relname::regclass)) as size,
seq_scan, seq_tup_read,
seq_scan / seq_tup_read as seq_tup_avg
from pg_stat_user_tables
where seq_tup_read > 0 order by 3,4 desc limit 5;The first thing we can look at is sequential table scans. The number itself after these passages is not necessarily bad and does not indicate that we need to do something already.
However, there is a second metric - seq_tup_read. This is the number of rows returned from the sequential scan. If the average number exceeds 1, 000, 10, 000, then this is already an indicator that you may need to build an index somewhere so that the accesses are by index, or it is possible to optimize queries that use such sequential scans so that this does not happen. was.
A simple example - let's say a request with a large OFFSET and LIMIT is worth it. For example, 100 rows in a table are scanned and after that 000 required rows are taken, and the previous scanned rows are discarded. This is also a bad case. And such requests need to be optimized. And here is such a simple SQL query on which you can see it and evaluate the received numbers.

select
relname,
pg_size_pretty(pg_total_relation_size(relname::regclass)) as
full_size,
pg_size_pretty(pg_relation_size(relname::regclass)) as
table_size,
pg_size_pretty(pg_total_relation_size(relname::regclass) -
pg_relation_size(relname::regclass)) as index_size
from pg_stat_user_tables
order by pg_total_relation_size(relname::regclass) desc limit 10;Table sizes can also be obtained using this table and using additional functions pg_total_relation_size(), pg_relation_size().
In general, there are metacommands dt и di, which you can use in PSQL and also see table and index sizes.
However, the use of functions helps us to look at the sizes of tables, even taking into account indexes, or without taking into account indexes, and already make some estimates based on the growth of the database, i.e. how it grows with us, with what intensity, and already draw some conclusions about sizing optimization.
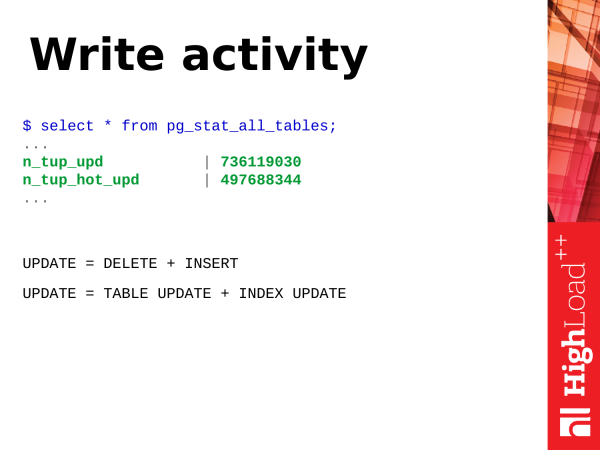
Write activity. What is a record? Let's look at the operation UPDATE – the operation of updating rows in the table. In fact, update is two operations (or even more). This is inserting a new row version and marking the old row version as obsolete. Later, autovacuum will come and clean out these obsolete versions of the lines, mark this place as available for reuse.
Also, update is not just about updating a table. It's still an index update. If you have a lot of indexes on the table, then with update, all indexes in which the fields updated in the query participate will also need to be updated. These indexes will also have obsolete row versions that will need to be cleaned up.

select
s.relname,
pg_size_pretty(pg_relation_size(relid)),
coalesce(n_tup_ins,0) + 2 * coalesce(n_tup_upd,0) -
coalesce(n_tup_hot_upd,0) + coalesce(n_tup_del,0) AS total_writes,
(coalesce(n_tup_hot_upd,0)::float * 100 / (case when n_tup_upd > 0
then n_tup_upd else 1 end)::float)::numeric(10,2) AS hot_rate,
(select v[1] FROM regexp_matches(reloptions::text,E'fillfactor=(\d+)') as
r(v) limit 1) AS fillfactor
from pg_stat_all_tables s
join pg_class c ON c.oid=relid
order by total_writes desc limit 50;And due to its design, UPDATE is a heavyweight operation. But they can be made easier. Eat hot updates. They appeared in PostgreSQL version 8.3. And what is this? This is a lightweight update that does not cause indexes to be rebuilt. That is, we updated the record, but only the record in the page (which belongs to the table) was updated, and the indexes still point to the same record in the page. There is a bit of such an interesting logic of work, when a vacuum comes, then it has these chains hot rebuilds and everything continues to work without updating the indexes, and everything happens with less waste of resources.
And when you have n_tup_hot_upd big, it's very good. This means that lightweight updates prevail and this is cheaper for us in terms of resources and everything is fine.

ALTER TABLE table_name SET (fillfactor = 70);How to increase volume hot updateov? We can use fillfactor. It determines the size of the reserved free space when filling a page in a table using INSERTs. When inserts go to the table, they completely fill the page, do not leave empty space in it. Then a new page is highlighted. The data is filled in again. And this is the default behavior, fillfactor = 100%.
We can set the fillfactor to 70%. That is, with inserts, a new page was allocated, but only 70% of the page was filled. And we have 30% left in reserve. When you need to do an update, it will most likely happen on the same page, and the new version of the row will fit on the same page. And hot_update will be done. This makes it easier to write on tables.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Autovacuum queue. Autovacuum is such a subsystem for which there are very few statistics in PostgreSQL. We can only see in the tables in pg_stat_activity how many vacuums we have at the moment. However, it is very difficult to understand how many tables in the queue he has on the go.
Note: _Since Postgres 10, the situation with tracking the vacuum vacuum has improved a lot - the pg_stat_progress view has appearedvacuum, which greatly simplifies the issue of autovacuum monitoring.
We can use this simplified query. And we can see when the vacuum should be made. But, how and when should the vacuum start? These are the old versions of the strings I talked about earlier. Update has occurred, the new version of the row has been inserted. An obsolete version of the string has appeared. Table pg_stat_user_tables there is such a parameter n_dead_tup. It shows the number of "dead" rows. And as soon as the number of dead rows has become more than a certain threshold, an autovacuum will come to the table.
And how is this threshold calculated? This is a very specific percentage of the total number of rows in the table. There is a parameter autovacuum_vacuum_scale_factor. It defines the percentage. Let's say 10% + there is an additional base threshold of 50 lines. And what happens? When we have more dead rows than "10% + 50" of all rows in the table, we put the table on autovacuum.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));However, there is one point. Basic thresholds for parameters av_base_thresh и av_scale_factor may be assigned individually. And, accordingly, the threshold will not be global, but individual for the table. Therefore, to calculate, there you need to use tricks and tricks. And if you are interested, you can look at the experience of our colleagues from Avito (the link on the slide is invalid and has been updated in the text).
They wrote for that takes into account these things. There is a footcloth on two sheets. But he considers correctly and quite effectively allows us to assess where we need a lot of vacuum for tables, where there is little.
What can we do about it? If we have a long queue and the autovacuum can’t cope, then we can increase the number of vacuum workers, or simply make the vacuum more aggressiveso that it triggers earlier, processes the table in small pieces. And thus the queue will decrease. - The main thing here is to monitor the load on the disks, because. The vacuum thing is not free, although with the advent of SSD / NVMe devices, the problem has become less noticeable.
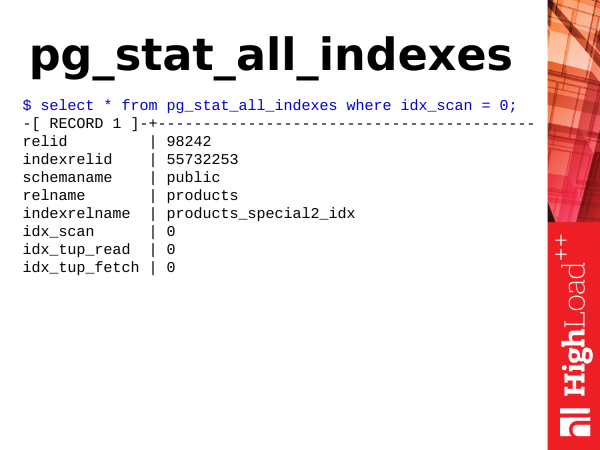
pg_stat_all_indexes is statistics on indexes. She is not big. And we can get information on the use of indexes from it. And for example, we can determine which indexes we have extra.
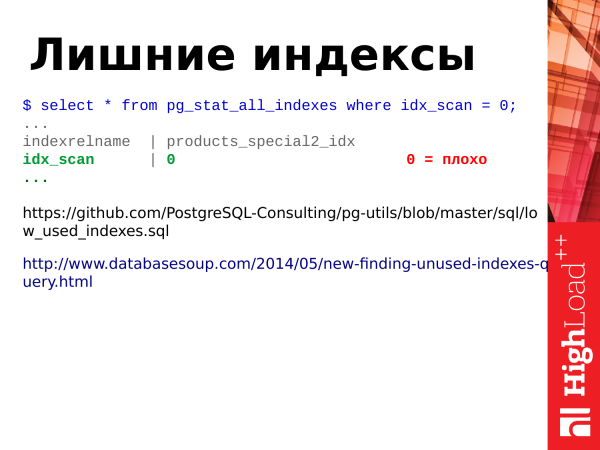
As I already said, update is not only updating tables, it is also updating indexes. Accordingly, if we have a lot of indexes on the table, then when updating the rows in the table, the indexes of the indexed fields also need to be updated, and if we have unused indexes for which there are no index scans, then they hang with us as ballast. And you need to get rid of them. For this we need a field idx_scan. We just look at the number of index scans. If the indexes have zero scans over a relatively long period of statistics storage (at least 2-3 weeks), then most likely these are bad indexes, we need to get rid of them.
Note: When searching for unused indexes in the case of streaming replication clusters, you need to check all nodes of the cluster, because statistics are not global, and if the index is not used on the master, then it can be used on replicas (if there is a load).
Two links:
These are more advanced query examples for how to look up unused indexes.
The second link is a rather interesting query. There is a very non-trivial logic in there. I recommend it for review.
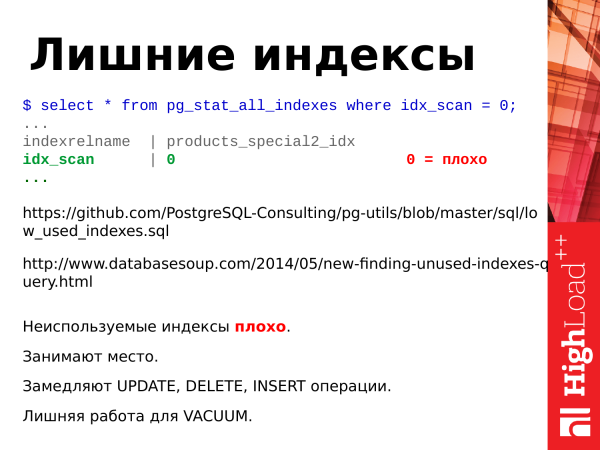
What else should be summed up by indexes?
Unused indexes are bad.
They take up space.
Slow down update operations.
Extra work for the vacuum.
If we remove unused indexes, then we will only make the database better.
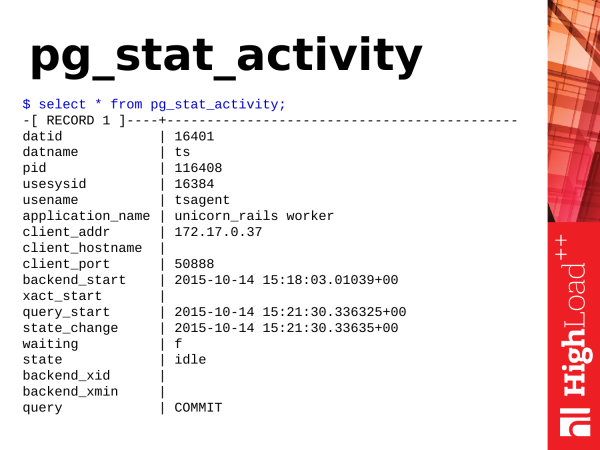
The next view is pg_stat_activity. This is an analogue of the utility ps, only in PostgreSQL. If ps'ohm you watch the processes in the operating system, then pg_stat_activity will show you the activity inside PostgreSQL.
What can we take from there?

select
count(*)*100/(select current_setting('max_connections')::int)
from pg_stat_activity;We can see the overall activity that is happening in the database. We can make a new deployment. Everything exploded there, new connections are not accepted, errors are pouring in the application.

select
client_addr, usename, datname, count(*)
from pg_stat_activity group by 1,2,3 order by 4 desc;We can run a query like this and see the total percentage of connections relative to the maximum connection limit and see who we have the most connections. And in this given case, we see that user cron_role opened 508 connections. And something happened to him. You need to deal with it and see. And it is quite possible that this is some kind of anomalous number of connections.
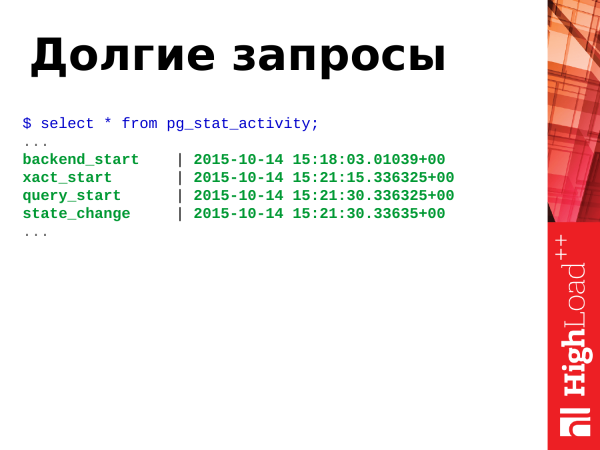
If we have an OLTP load, queries should be fast, very fast, and there shouldn't be long queries. However, if there are long requests, then in the short term there is nothing to worry about, but in the long run, long queries harm the database, they increase the bloat effect of tables when table fragmentation occurs. Both bloat and long queries need to be disposed of.

select
client_addr, usename, datname,
clock_timestamp() - xact_start as xact_age,
clock_timestamp() - query_start as query_age,
query
from pg_stat_activity order by xact_start, query_start;Please note: with such a request, we can define long requests and transactions. We use the function clock_timestamp() to determine the working time. Long requests that we found, we can remember them, execute them explain, look at plans and somehow optimize. We shoot the current long requests and live on.
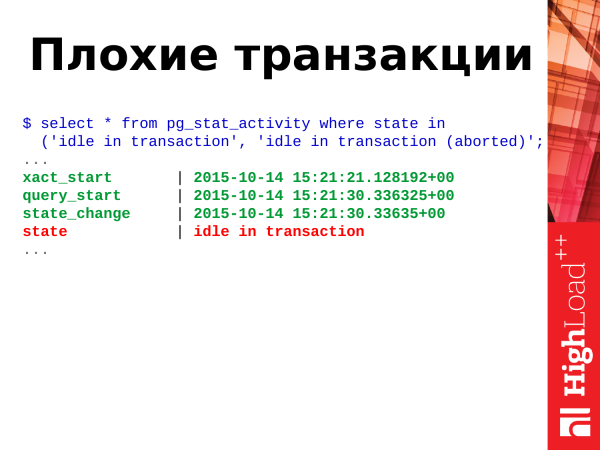
select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Bad transactions are idle in transaction and idle in transaction (aborted) transactions.
What does it mean? Transactions have multiple states. And one of these states can take at any time. There is a field to define states state in this view. And we use it to determine the state.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';And, as I said above, these two states idle in transaction and idle in transaction (aborted) are bad. What it is? This is when the application opened a transaction, did some actions and went about its business. The transaction remains open. It hangs, nothing happens in it, it takes a connection, locks on changed rows and potentially still increases the bloat of other tables, due to the architecture of the Postrges transactional engine. And such transactions should also be shot, because they are harmful in general, in any case.
If you see that you have more than 5-10-20 of them in your database, then you need to get worried and start doing something with them.
Here we also use for the calculation time clock_timestamp(). We shoot transactions, we optimize the application.
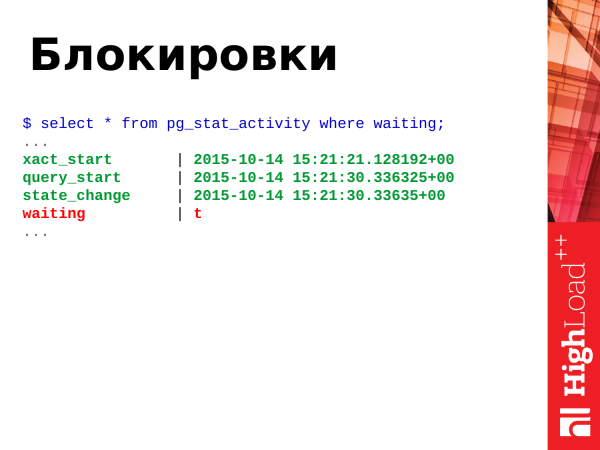
As I said above, locks are when two or more transactions compete for one or a group of resources. For this we have a field waiting with boolean value true or false.
True - this means that the process is waiting, something needs to be done. When a process is waiting, then the client that initiated the process is also waiting. The client in the browser sits and also waits.
Attention: _Starting from Postgres 9.6, the field waiting removed and replaced by two more informative fields wait_event_type и wait_event._
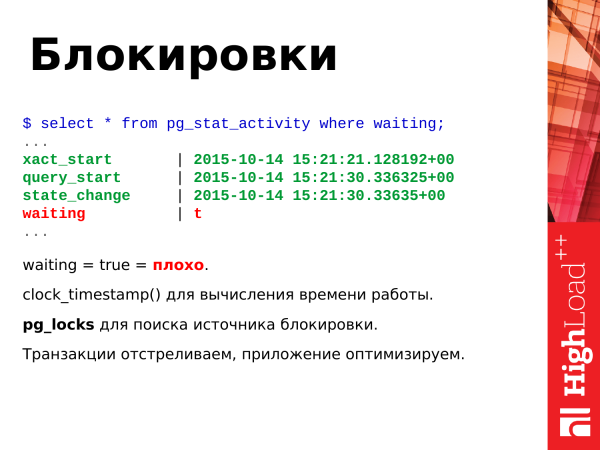
What to do? If you see true for a long time, then you should get rid of such requests. We just shoot such transactions. We write to developers what needs to be optimized somehow so that there is no race for resources. And then the developers optimize the application so that this does not happen.
And an extreme, but potentially not fatal case is occurrence of deadlocks. Two transactions have updated two resources, then they access them again, already to opposite resources. PostgreSQL in this case takes and shoots off the transaction itself so that the other one can continue working. This is a dead end situation and she does not understand herself. Therefore, PostgreSQL is forced to take extreme measures.

And here are two queries that allow you to track locks. We use the view pg_locks, which allows you to track heavy locks.
And the first link is the request text itself. It's pretty long.
And the second link is an article on locks. It is useful to read, it is very interesting.
So what do we see? We see two requests. Transaction with ALTER TABLE is a blocking transaction. It started, but did not end, and the application that posted this transaction is doing other things somewhere. And the second request is update. It waits for the alter table to finish before continuing its work.
This is how we can find out who locked up whom, who is holding whom, and we can deal with this further.
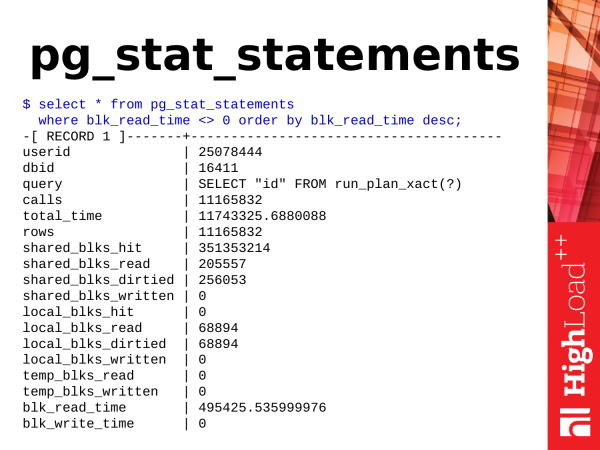
The next module is pg_stat_statements. Like I said, it's a module. To use it, you need to load its library in the configuration, restart PostgreSQL, install the module (with one command), and then we will have a new view.

Cреднее время запроса в милисекундах
$ select (sum(total_time) / sum(calls))::numeric(6,3)
from pg_stat_statements;
Самые активно пишущие (в shared_buffers) запросы
$ select query, shared_blks_dirtied
from pg_stat_statements
where shared_blks_dirtied > 0 order by 2 desc;What can we take from there? If we talk about simple things, we can take the average query execution time. Time is growing, which means that PostgreSQL is responding slowly and something needs to be done.
We can see the most active writing transactions in the database that change data in shared buffers. See who updates or deletes data there.
And we can just look at different statistics for these requests.

Мы pg_stat_statements used to build reports. We reset the statistics once a day. Let's accumulate it. Before resetting statistics next time, we build a report. Here is a link to the report. You can watch it.

What are we doing? We calculate the overall statistics for all queries. Then, for each query, we count its individual contribution to this overall statistic.
And what can we see? We can see the total execution time of all requests of a particular type against the background of all other requests. We can look at CPU and I/O usage in relation to the overall picture. And already to optimize these requests. We are building top queries based on this report and are already getting food for thought on what to optimize.

What do we have behind the scenes? There are still a few submissions that I did not consider, because time is limited.
There is pgstattuple is also an additional module from the standard contribs package. It allows you to evaluate bloat tables, so-called. table fragmentation. And if the fragmentation is large, you need to remove it, use different tools. And function pgstattuple works for a long time. And the more tables, the longer it will work.

The next contrib is pg_buffercache. It allows you to inspect shared buffers: how intensively and for which tables buffer pages are utilized. And it just allows you to look into shared buffers and evaluate what is happening there.
The next module is pgfincore. It allows you to perform low-level table operations through a system call mincore(), i.e. it allows you to load the table into shared buffers, or unload it. And it allows, among other things, to inspect the page cache of the operating system, that is, how much the table occupies in the page cache, in shared buffers, and simply allows you to evaluate the load on the table.
The next module is pg_stat_kcache. It also uses the system call getrusage(). And it executes it before and after the request is executed. And in the statistics obtained, it allows us to estimate how much our request spent on disk I / O, i.e., operations with the file system and looks at the processor usage. However, the module is young (khe-khe) and for its work it requires PostgreSQL 9.4 and pg_stat_statements, which I mentioned earlier.

The ability to use statistics is useful. You don't need third party software. You can look, see, do something, perform.
Using statistics is easy, it's plain SQL. You collected a request, compiled it, sent it, looked at it.
Statistics help answer questions. If you have questions, you turn to statistics - look, draw conclusions, analyze the results.
And experiment. Lots of requests, lots of data. You can always optimize some existing query. You can make your own version of the request that suits you better than the original and use it.

Links
Valid links that were found in the article, based on which, were in the report.
Author write more
(eng)
The Statistics Collector
System Administration Functions
Contrib modules
SQL utilities and sql code examples
Thank you for your attention!
Source: habr.com
