


Since ClickHouse is a specialized system, it is important to take into account the peculiarities of its architecture when using it. In this report, Alexey will talk about examples of typical errors when using ClickHouse, which can lead to inefficient work. Using practical examples, we will show how the choice of one or another data processing scheme can change performance by orders of magnitude.
Hi all! My name is Alexey, I make ClickHouse.

Firstly, I hasten to please you right away, I will not tell you today what ClickHouse is. To be honest, I'm tired of it. I tell you every time what it is. And probably everyone already knows.

Instead, I will tell you what the possible rake is, i.e. how ClickHouse can be misused. In fact, you should not be afraid, because we are developing ClickHouse as a system that is simple, convenient, and works out of the box. Installed everything, no problem.
But still, it must be borne in mind that this system is specialized and you can easily stumble upon an unusual use case that will take this system out of its comfort zone.
So, what are the rakes? Basically I will talk about the obvious things. Everything is obvious to everyone, everyone understands everything and can be glad that they are so smart, and those who do not understand will learn something new.

The first simplest example, which, unfortunately, often occurs, is a large number of inserts with small batches, i.e. a large number of small inserts.
If we consider how ClickHouse performs an insert, then you can send at least a terabyte of data in one request. It's not a problem.
And let's see what the typical performance will be. For example, we have a table with Yandex.Metrics data. Hits. 105 some columns. 700 bytes uncompressed. And we will insert in a good way batches of one million lines.
We insert into the MergeTree table, half a million rows per second are obtained. Great. In a replicated table - it will be a little less, about 400 rows per second.
And if you turn on the quorum insert, you get a little less, but still decent performance, 250 times per second. Quorum Insertion is an undocumented feature in ClickHouse*.
* as of 2020, .

What happens if you do it wrong? We insert one row into the MergeTree table and we get 59 rows per second. This is 10 times slow. In ReplicatedMergeTree - 000 rows per second. And if the quorum turns on, then 6 lines per second are obtained. In my opinion, this is some kind of utter crap. How can you slow down like that? It even says on my T-shirt that ClickHouse should not slow down. But nevertheless it happens sometimes.

In fact, this is our shortcoming. We could have made it work just fine, but we didn't. And we didn't, because our script didn't need it. We already had batches. We just received batches at the entrance, and no problems. Plug it in and everything works fine. But, of course, all sorts of scenarios are possible. For example, when you have a bunch of servers on which data is generated. And they don't insert data as often, but they still get frequent inserts. And you need to somehow avoid this.
From a technical point of view, the bottom line is that when you do an insert in ClickHouse, the data does not get into any memtable. We don't even have a real MergeTree log structure, but just a MergeTree, because there is neither log nor memTable. We just immediately write the data to the file system, already decomposed into columns. And if you have 100 columns, then more than 200 files will need to be written to a separate directory. All this is very cumbersome.

And the question arises: “How to do it right?” If such a situation, you still need to somehow write data to ClickHouse.
Method 1. This is the easiest way. Use some kind of distributed queue. For example, Kafka. You just take data out of Kafka, we batch it once a second. And everything will be fine, you record, everything works fine.
The disadvantages are that Kafka is another cumbersome distributed system. I also understand if you already have Kafka in your company. It's good, it's convenient. But if it is not there, then you should think three times before dragging another distributed system into your project. And so it is worth considering alternatives.

Method 2. Here is such an old-school alternative and at the same time very simple. Do you have some kind of server that generates your logs. And it just writes your logs to a file. And once a second, for example, we rename this file, open a new one. And a separate script either by cron or some daemon takes the oldest file and writes it to ClickHouse. If you write logs once a second, then everything will be fine.
But the disadvantage of this method is that if your server on which the logs are generated has disappeared somewhere, then the data will also disappear.

Method 3. There is another interesting way, which is without temporary files at all. For example, you have some kind of advertising spinner or some other interesting daemon that generates data. And you can accumulate a bunch of data right in the RAM, in the buffer. And when a sufficient amount of time passes, you put this buffer aside, create a new one, and insert what has already accumulated into ClickHouse in a separate thread.
On the other hand, the data also disappears with kill -9. If your server goes down, you will lose this data. And another problem is that if you could not write to the database, then your data will accumulate in the RAM. And either the RAM runs out, or you just lose data.

Method 4. Another interesting way. Do you have any server process. And he can send data to ClickHouse at once, but do it in one connection. For example, I sent an http request with transfer-encoding: chunked with insert. And it generates chunks not too rarely, you can send each line, although there will be an overhead for framing this data.
However, in this case, the data will be sent to ClickHouse immediately. And ClickHouse itself will buffer them.
But there are also problems. Now you will lose data, including when your process is killed and if the ClickHouse process is killed, because it will be an incomplete insert. And in ClickHouse inserts are atomic up to some specified threshold in the size of rows. In principle, this is an interesting way. Also can be used.

Method 5. Here is another interesting way. This is some kind of community-developed server for data batching. I haven't looked at it myself, so I can't guarantee anything. However, there are no guarantees for ClickHouse itself. This is also open source, but on the other hand, you could get used to some quality standard that we try to provide. But for this thing - I don't know, go to GitHub, look at the code. Maybe they wrote something good.
*as of 2020, should also be added to consideration .

Method 6. Another way is to use Buffer tables. The advantage of this method is that it is very easy to start using. Create a Buffer table and insert into it.
But the disadvantage is that the problem is not completely solved. If at a rate of the MergeTree type you must group data by one batch per second, then at a rate in a buffer table, you need to group at least up to several thousand per second. If there are more than 10 per second, it will still be bad. And if you insert in batches, then you saw that a hundred thousand lines per second are obtained there. And this is already on fairly heavy data.
And also buffer tables do not have a log. And if something is wrong with your server, then the data will be lost.

And as a bonus, we recently had the opportunity to collect data from Kafka in ClickHouse. There is a table engine - Kafka. You are simply creating. And you can hang materialized views on it. In this case, he will take out the data from Kafka and insert it into the tables you need.
And what is especially pleasing about this opportunity is that we did not make it. This is a community feature. And when I say "community feature", I say it without any contempt. We read the code, did a review, it should work fine.
* as of 2020, there is similar support for .

What else can be inconvenient or unexpected when inserting data? If you make an insert values query and write some calculated expressions in values. For example, now() is also an evaluated expression. And in this case, ClickHouse is forced to launch the interpreter of these expressions for each line, and performance will drop by orders of magnitude. Better to avoid it.
* at the moment, the problem is completely solved, there is no more performance regression when using expressions in VALUES.
Another example where there may be some problems is when your data on one batch belongs to a bunch of partitions. By default, ClickHouse partitions by month. And if you insert a batch of a million rows, and there is data for several years, then you will have several dozen partitions there. And this is equivalent to the fact that there will be batches several tens of times smaller, because inside they are always first divided into partitions.
* recently in ClickHouse in experimental mode added support for the compact format of chunks and chunks in RAM with write-ahead log, which almost completely solves the problem.

Now consider the second kind of problem - data typing.
Data typing can be strict, and sometimes string. String - this is when you just took and declared that you have all fields of type string. It sucks. You don't have to do that.
Let's figure out how to do it right in cases where you want to say that we have some field, a string, and let ClickHouse figure it out on its own, but I won't take a steam bath. But it's still worth putting in some effort.

For example, we have an IP address. In one case, we saved it as a string. For example, 192.168.1.1. Otherwise, it will be a number of type UInt32*. 32 bits is enough for an IPv4 address.
First, oddly enough, the data will be compressed about the same. There will be a difference, sure, but not that big. So there are no special problems with disk I/O.
But there is a serious difference in CPU time and query execution time.
Let's count the number of unique IP addresses if they are stored as numbers. It turns out 137 million lines per second. If the same as lines, then 37 million lines per second. I don't know why this coincidence happened. I have done these requests myself. But nevertheless about 4 times slower.
And if you calculate the difference in disk space, then there is also a difference. And the difference is about one quarter, because there are quite a lot of unique IP addresses. And if there were lines with a small number of different values, then they would have been quietly compressed in the dictionary into approximately the same volume.
And the fourfold time difference is not lying on the road. Maybe you, of course, do not care, but when I see such a difference, I feel sad.

Let's consider different cases.
1. One case when you have few different unique values. In this case, we use a simple practice that you probably know and can use for any DBMS. This all makes sense not only for ClickHouse. Just write the numeric identifiers to the database. And you can convert to strings and back on the side of your application.
For example, you have a region. And you are trying to save it as a string. And it will be written there: Moscow and Moscow Region. And when I see that “Moscow” is written there, then this is still nothing, and when it is MO, it somehow becomes completely sad. That's how many bytes.
Instead, we simply write down the Ulnt32 number and 250. We have 250 in Yandex, but yours may be different. Just in case, I’ll say that ClickHouse has a built-in ability to work with a geobase. You simply write down a directory with regions, including a hierarchical one, i.e. there will be Moscow, Moscow Region, and everything you need. And you can convert at the request level.

The second option is about the same, but with support inside ClickHouse. It is an Enum data type. You simply write all the values you need inside the Enum. For example, the type of device and write there: desktop, mobile, tablet, TV. Only 4 options.
The disadvantage is that you need to periodically alter. Only one option has been added. We make alter table. In fact, alter table in ClickHouse is free. Especially free for Enum because the data on disk doesn't change. But nevertheless, alter acquires a lock * on the table and must wait until all selects are completed. And only after this alter will be executed, i.e., there are still some inconveniences.
* in recent versions of ClickHouse, ALTER is made completely non-blocking.

Another option quite unique for ClickHouse is the connection of external dictionaries. You can write numbers in ClickHouse, and keep your directories in any system convenient for you. For example, you can use: MySQL, Mongo, Postgres. You can even create your own microservice, which will send this data via http. And at the ClickHouse level, you write a function that will convert this data from numbers to strings.
This is a specialized but very efficient way to perform a join on an external table. And there are two options. In one option, this data will be fully cached, fully present in the RAM and updated at some intervals. And in another option, if this data does not fit into the RAM, then you can partially cache it.
Here is an example. There is Yandex.Direct. And there is an advertising company and banners. There are probably tens of millions of advertising companies. And roughly fit in the RAM. And there are billions of banners, they do not fit. And we are using a cached dictionary from MySQL.
The only problem is that the cached dictionary will work fine if the hit rate is close to 100%. If it is smaller, then when processing requests for each data pack, it will be necessary to actually take the missing keys and go to take data from MySQL. About ClickHouse, I can still guarantee that - yes, it doesn’t slow down, I won’t talk about other systems.
And as a bonus, dictionaries are a very easy way to update data in ClickHouse retroactively. That is, you had a report on advertising companies, the user simply changed the advertising company and in all the old data, in all reports, this data also changed. If you write rows directly to the table, then you will not be able to update them.

Another way when you don't know where to get the identifiers for your strings. you can just hash. And the easiest option is to take a 64-bit hash.
The only problem is that if the hash is 64-bit, then you will almost certainly have collisions. Because if there are a billion lines, then the probability is already becoming tangible.
And it would not be very good to hash the names of advertising companies like that. If the advertising campaigns of different companies get mixed up, then there will be something incomprehensible.
And there is a simple trick. True, it is also not very suitable for serious data, but if something is not very serious, then simply add another client identifier to the dictionary key. And then you will have collisions, but only within one client. And we use this method for the link map in Yandex.Metrica. We have urls there, we store hashes. And we know that there are conflicts, of course. But when a page is displayed, then the probability that it is on one page for one user that some urls stick together and this will be noticed, then this can be neglected.
As a bonus, for many operations, only hashes are enough and the strings themselves can not be stored anywhere.

Another example if the strings are short, such as website domains. They can be stored as is. Or, for example, the browser language ru is 2 bytes. Of course, I feel sorry for the bytes, but don't worry, 2 bytes are not a pity. Please keep it as is, don't worry.

Another case is when, on the contrary, there are a lot of strings and at the same time there are a lot of unique ones in them, and even the set is potentially unlimited. A typical example is search phrases or urls. Search phrases, including due to typos. Let's see how many unique search phrases per day. And it turns out that they are almost half of all events. And in this case, you might think that you need to normalize the data, count the identifiers, put them in a separate table. But you don't have to do that. Just keep these lines as is.
Better - do not invent anything, because if you store it separately, you will need to do a join. And this join is at best a random access to memory, if it still fits in memory. If it does not fit, then there will be problems in general.
And if the data is stored in place, then they are simply read in the right order from the file system and everything is fine.

If you have urls or some other complex long string, then you should think about the fact that you can calculate some squeeze in advance and write it in a separate column.
For urls, for example, you can store the domain separately. And if you really need a domain, then just use this column, and the urls will lie, and you will not even touch them.
Let's see what the difference is. ClickHouse has a specialized function that calculates the domain. It is very fast, we have optimized it. And, to be honest, it does not even comply with the RFC, but nevertheless it considers everything that we need.
And in one case, we will simply get the urls and calculate the domain. It turns out 166 milliseconds. And if you take a ready-made domain, then it turns out only 67 milliseconds, that is, almost three times faster. And faster, not because we need to do some calculations, but because we read less data.
For some reason, one request, which is slower, gets more speed in gigabytes per second. Because it reads more gigabytes. This is completely redundant data. The request seems to run faster, but takes longer to complete.
And if you look at the amount of data on the disk, it turns out that the URL is 126 megabytes, and the domain is only 5 megabytes. It turns out 25 times less. However, the query is still only 4 times faster. But that's because the data is hot. And if it were cold, it would probably be 25 times faster due to disk I / O.
By the way, if you evaluate how much the domain is less than the url, then it turns out to be about 4 times. But for some reason, the data on the disk takes 25 times less. Why? Due to compression. And the url is compressed, and the domain is compressed. But often the url contains a bunch of garbage.

And, of course, it's worth using the right data types that are specifically designed for the right values or that fit. If you are in IPv4 then store UInt32*. If IPv6, then FixedString(16), because an IPv6 address is 128 bits, i.e. store directly in binary format.
But what if you sometimes have IPv4 addresses and sometimes IPv6? Yes, you can keep both. One column for IPv4, another for IPv6. Of course, there is an option to map IPv4 to IPv6. This will also work, but if you often need an IPv4 address in your requests, then it would be nice to put it in a separate column.
* Now ClickHouse has separate IPv4, IPv6 data types that store data as efficiently as numbers, but represent them as conveniently as strings.

It is also important to note that it is worth preprocessing the data in advance. For example, some raw logs come to you. And, maybe, you should not put them into ClickHouse right away, although it is very tempting to do nothing and everything will work. But it is still worthwhile to carry out those calculations that are possible.
For example, browser version. In some neighboring department, which I don’t want to point the finger at, the browser version is stored there like this, that is, as a string: 12.3. And then, to make a report, they take this string and divide by an array, and then by the first element of the array. Naturally, everything slows down. I asked why they do this. They told me that they do not like premature optimization. And I don't like premature pessimism.
So in this case it would be more correct to divide into 4 columns. Don't be afraid here, because this is ClickHouse. ClickHouse is a column database. And the more neat little columns, the better. There will be 5 BrowserVersion, make 5 columns. This is fine.

Now consider what to do if you have a lot of very long strings, very long arrays. They do not need to be stored in ClickHouse at all. Instead, you can store only some identifier in ClickHouse. And these long lines shove them into some other system.
For example, one of our analytics services has some event parameters. And if a lot of parameters come to events, we simply save the first 512 that come across. Because 512 is not a pity.

And if you cannot decide on your data types, then you can also write data to ClickHouse, but to a temporary table of the Log type, which is special for temporary data. After that, you can analyze what kind of distribution of values you have there, what is generally there and make up the correct types.
* Now ClickHouse has a data type which allows you to efficiently store strings with less effort.

Now consider another interesting case. Sometimes things work in a strange way for people. I go and see this. And it immediately seems that this was done by some very experienced, smart admin who has extensive experience in setting up MySQL version 3.23.
Here we see a thousand tables, each of which contains the remainder of dividing it is not clear what by a thousand.
In principle, I respect other people's experience, including understanding what kind of suffering this experience can be gained.

And the reasons are more or less clear. These are old stereotypes that may have accumulated while working with other systems. For example, MyISAM tables do not have a clustered primary key. And this way of sharing data can be a desperate attempt to get the same functionality.
Another reason is that it is difficult to do any alter operations on large tables. Everything will be blocked. Although in modern versions of MySQL, this problem is no longer so serious.
Or, for example, microsharding, but more on that later.

In ClickHouse, you don’t need to do this, because, firstly, the primary key is clustered, the data is ordered by the primary key.
And sometimes people ask me: “How does the performance of range queries in ClickHouse change with the size of the table?”. I say it doesn't change at all. For example, you have a table with a billion rows and you are reading a range of one million rows. Everything is fine. If the table has a trillion rows and you are reading one million rows, then it will be almost the same.
And, secondly, any pieces like manual partitions are not required. If you go in and look at what's on the file system, you'll see that a table is a pretty serious thing. And there inside there is something like partitions. That is, ClickHouse does everything for you and you do not need to suffer.

Alter in ClickHouse is free if alter add/drop column.
And you shouldn't make small tables, because if you have 10 rows or 10 rows in your table, then it doesn't matter at all. ClickHouse is a system that optimizes throughput, not latency, so it makes no sense to process 000 lines.

It is correct to use one big table. Get rid of the old stereotypes, everything will be fine.
And as a bonus, in the latest version, we have the opportunity to make an arbitrary partitioning key in order to perform all sorts of maintenance operations on individual partitions.
For example, you need many small tables, for example, when there is a need to process some intermediate data, you receive chunks and you need to perform a transformation on them before writing to the final table. For this case, there is a wonderful table engine - StripeLog. It's like TinyLog, only better.
* Now ClickHouse has more .

Another anti-pattern is microsharding. For example, you need to shard data and you have 5 servers, and tomorrow there will be 6 servers. And you think how to rebalance this data. And instead, you are not splitting into 5 shards, but into 1 shards. And then you map each of these microshards to a separate server. And you will succeed on one server, for example, 000 ClickHouse, for example. Separate instance on separate ports or separate databases.

But in ClickHouse this is not very good. Because even one instance of ClickHouse tries to use all available server resources to process one request. That is, you have some kind of server and there, for example, 56 processor cores. You are running a query that takes one second and it will use 56 cores. And if you placed 200 ClickHouses on one server there, then it turns out that 10 threads will start. In general, everything will be very bad.
Another reason is that the distribution of work across these instances will be uneven. Some will finish earlier, some will finish later. If all this happened in one instance, then ClickHouse itself would have figured out how to correctly distribute the data among the streams.
And another reason is that you will have interprocessor communication over TCP. The data will have to be serialized, deserialized, and this is a huge number of microshards. It just won't work.

Another antipattern, although it can hardly be called an antipattern. This is a large amount of pre-aggregation.
In general, preaggregation is good. You had a billion rows, you aggregated it and it became 1 rows, and now the query is executed instantly. Everything is great. That's how you can do it. And for this, even ClickHouse has a special AggregatingMergeTree table type that does incremental aggregation as data is inserted.
But there are times when you think that we will aggregate data like this and aggregate data like this. And in some neighboring department, I don’t want to say which one either, they use SummingMergeTree tables for summing up by the primary key, and 20 columns are used as the primary key. Just in case, I changed the names of some columns for conspiracy, but that's about it.

And such problems arise. First, the amount of data you have is not reduced too much. For example, it is reduced by three times. Three times would be a good price to afford the unlimited analytics that comes with having non-aggregated data. If the data is aggregated, then you get only miserable statistics instead of analytics.
And what is especially good? That these people from the next department, go and ask sometimes to add one more column to the primary key. That is, we have aggregated the data like this, and now we want a little more. But there is no alter primary key in ClickHouse. Therefore, you have to write some scripts in C ++. And I don't like scripts, even if they're in C++.
And if you look at what ClickHouse was created for, then non-aggregated data is exactly the scenario for which it was born. If you are using ClickHouse for non-aggregated data, then you are doing everything right. If you are aggregating, then this is sometimes forgivable.
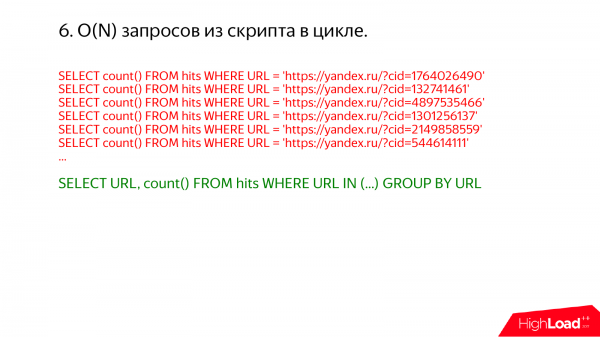
Another interesting case is requests in an infinite loop. I sometimes go to some production server and look at show processlist there. And every time I discover that something terrible is happening.
For example, here is this. It is immediately clear that it was possible to do everything in one request. Just write the url in and the list there.

Why are many such requests in an infinite loop bad? If the index is not used, then you will have many passes over the same data. But if an index is used, for example, you have a primary key on ru and you write url = something there. And you think that one url will be pointwise read from the table, everything will be fine. But really no. Because ClickHouse does everything in batches.
When he needs to read some range of data, he reads a little more, because the index in ClickHouse is sparse. This index does not allow you to find one individual row in the table, only some kind of range. And the data is compressed in blocks. In order to read one line, you need to take the whole block and uncompress it. And if you run a bunch of queries, you'll have a lot of intersections of those, and you'll have a lot of work done over and over again.

And as a bonus, you can see that in ClickHouse you should not be afraid to transfer even megabytes and even hundreds of megabytes to the IN section. I remember from our practice that if we pass a bunch of values \u100b\u10bin the IN section in MySQL, for example, we pass XNUMX megabytes of some numbers there, then MySQL eats up XNUMX gigabytes of memory and nothing else happens to it, everything works badly.
And the second thing is that in ClickHouse, if your queries use an index, then it is always no slower than a full scan, i.e. if you need to read almost the entire table, it will go sequentially and read the entire table. In general, he will figure it out.
However, there are some difficulties. For example, that IN with a subquery does not use the index. But this is our problem and we need to fix it. There is nothing fundamental here. Let's do it*.
And another interesting thing is that if you have a very long request and distributed request processing is going on, then this very long request will be sent to each server without compression. For example, 100 megabytes and 500 servers. And, accordingly, 50 gigabytes will be transferred over the network. It will be transferred and then everything will be successfully executed.
* already using; everything was fixed as promised.

And it's quite common if the requests come from the API. For example, you have made some kind of service. And if someone needs your service, then you opened the API and literally two days later you see that something incomprehensible is happening. Everything is overloaded and some terrible requests are coming in that should never have been.
And there is only one solution. If you have opened the API, then you will have to cut it. For example, to enter some quotas. There are no other reasonable options. Otherwise, they will immediately write a script and there will be problems.
And ClickHouse has a special feature - this is the calculation of quotas. Moreover, you can transfer your quota key. This is, for example, an internal user ID. And quotas will be calculated independently for each of them.

Now another interesting thing. This is manual replication.
I know many cases where, despite ClickHouse having built-in replication support, people replicate ClickHouse manually.
What is the principle? You have a data processing pipeline. And it works independently, for example, in different data centers. You write the same data in the same way to ClickHouse, as it were. True, practice shows that the data will still diverge due to some peculiarities in your code. I hope that in yours.
And periodically you still have to manually sync. For example, once a month admins do rsync.
In fact, it is much easier to use the built-in replication in ClickHouse. But there may be some contraindications, because for this you need to use ZooKeeper. I won’t say anything bad about ZooKeeper, in principle, the system works, but it happens that people don’t use it because of java-phobia, because ClickHouse is such a good system written in C ++ that you can use and everything will be fine . And ZooKeeper in java. And somehow you don’t even want to look, but then you can use manual replication.

ClickHouse is a practical system. It takes into account your needs. If you have manual replication, then you can create a Distributed table that looks at your manual replicas and does a failover between them. And there is even a special option that allows you to avoid flops, even if your lines are systematically divergent.

Further, there may be problems if you use primitive table engines. ClickHouse is such a constructor that has a bunch of different table engines. For all serious cases, as written in the documentation, use tables of the MergeTree family. And all the rest - this is so, for individual cases or for tests.
In a MergeTree table, you don't need to have any date and time. You can still use. If there is no date and time, write that default is 2000. It will work and will not require resources.
And in the new version of the server, you can even specify that you have custom partitioning without a partition key. It will be the same.

On the other hand, primitive table engines can be used. For example, fill in the data once and see, twist and delete. You can use Log.
Or storing small volumes for intermediate processing is StripeLog or TinyLog.
Memory can be used if there is a small amount of data and just twist something in the RAM.

ClickHouse doesn't like renormalized data very much.
Here is a typical example. This is a huge number of urls. You put them in the adjacent table. And then we decided to do JOIN with them, but this will not work, as a rule, because ClickHouse only supports Hash JOIN. If there is not enough RAM for a lot of data with which to connect, then JOIN will not work *.
If the data is of high cardinality, then don't worry, store it in a denormalized form, the URLs are directly inplace in the main table.
* and now ClickHouse has a merge join too, and it works in conditions where the intermediate data does not fit into the RAM. But this is ineffective and the recommendation remains valid.

A couple more examples, but I already doubt whether they are anti-patterns or not.
ClickHouse has one known drawback. He does not know how to update *. In a sense, this is even good. If you have some important data, for example, accounting, then no one will be able to send them, because there are no updates.
* support for update and delete in batch mode has long been added.
But there are some special ways that allow updates to appear in the background. For example, tables of type ReplaceMergeTree. They do updates during background merges. You can force this with optimize table. But don't do it too often, because it will completely overwrite the partition.
Distributed JOINs in ClickHouse - this is also poorly handled by the query planner.
Bad, but sometimes OK.
Using ClickHouse just to read data back with select*.
I would not recommend using ClickHouse for bulky calculations. But this is not entirely true, because we are already moving away from this recommendation. And we recently added the ability to apply machine learning models in ClickHouse - Catboost. And it worries me, because I think: “What a horror. This is how many cycles per byte it turns out! It is a pity to me to start up clock cycles on bytes.

But don't be afraid, install ClickHouse, everything will be fine. If anything, we have a community. By the way, the community is you. And if you have any problems, you can at least go to our chat, and I hope that you will be helped.
Questions
Thanks for the report! Where to complain about the ClickHouse crash?
You can complain to me personally right now.
I recently started using ClickHouse. Immediately dropped the cli interface.
What a score.
A little later, I dropped the server with a small select.
You have talent.
I opened a GitHub bug, but it was ignored.
We'll see.
Aleksey tricked me into attending the report, promising to tell me how you are squeezing the data inside.
Very simple.
This is what I realized yesterday. More specifics.
There are no terrible tricks. It's just block-by-block compression. The default is LZ4, you can enable ZSTD*. Blocks from 64 kilobytes to 1 megabyte.
* there is also support for specialized compression codecs that can be used in chain with other algorithms.
Are the blocks just raw data?
Not exactly raw. There are arrays. If you have a numeric column, then the numbers in a row are stacked in an array.
Clear.
Alexey, an example that was with uniqExact over IPs, i.e. the fact that uniqExact takes longer to count by strings than by numbers, and so on. What if we apply a feint with our ears and cast at the moment of proofreading? That is, you seem to have said that it does not differ much on the disk. If we read lines from the disk, cast, then will we have aggregates faster or not? Or are we still marginally gaining here? It seems to me that you tested it, but for some reason did not indicate it in the benchmark.
I think it will be slower than no cast. In this case, the IP address must be parsed from the string. Of course, in ClickHouse, IP address parsing is also optimized. We tried very hard, but in the same place you have the numbers written in ten thousandth form. Very uncomfortable. On the other hand, the uniqExact function will work slower on strings, not only because these are strings, but also because a different specialization of the algorithm is chosen. Strings are just handled differently.
And if we take a more primitive data type? For example, they wrote down the user id that we have in, wrote it down as a line, and then cast it, will it be more fun or not?
I doubt. I think it will be even sadder, because after all, parsing numbers is a serious problem. It seems to me that this colleague even had a report on how difficult it is to parse numbers in ten thousandth form, but maybe not.
Alexey, thank you very much for the report! And thank you very much for ClickHouse! I have a question about plans. Is there a feature in the plans for updating dictionaries incompletely?
i.e. partial reboot?
Yes Yes. Like the ability to set a MySQL field there, i.e. update after so that only this data is loaded if the dictionary is very large.
Very interesting feature. And, it seems to me, some person suggested it in our chat. Maybe it was even you.
I don't think so.
Great, now it turns out that two requests. And you can start doing it slowly. But I want to warn you right away that this feature is quite simple to implement. That is, in theory, you just need to write the version number into the table and then write: the version is less than such and such. And this means that, most likely, we will offer it to enthusiasts. Are you an enthusiast?
Yes, but unfortunately not in C++.
Can your colleagues write in C++?
I'll find someone.
Great*.
* the feature was added two months after the report - it was developed by the author of the question and submitted by his .
Thank you!
Hello! Thanks for the report! You mentioned that ClickHouse consumes all the resources available to it very well. And the speaker next to Luxoft talked about his decision for the Russian Post. He said that they really liked ClickHouse, but they didn't use it instead of their main competitor precisely because it ate the entire processor. And they couldn't fit it into their architecture, into their ZooKeeper with dockers. Is it possible to somehow restrict ClickHouse so that it does not consume everything that becomes available to it?
Yes, it is possible and very easy. If you want to consume fewer cores, then just write set max_threads = 1. And that's all, it will execute the request in one core. Moreover, you can specify different settings for different users. So no problem. And tell your colleagues from Luxoft that it's not good that they did not find this setting in the documentation.
Alexey, hello! I would like to ask this question. This is not the first time I hear that many people are starting to use ClickHouse as a repository for logs. At the report, you said not to do this, that is, you do not need to store long lines. What do you think about it?
First, logs are usually not long lines. There are, of course, exceptions. For example, some service written in java throws an exception, it is logged. And so in an endless loop, and running out of hard drive space. The solution is very simple. If the lines are very long, then cut them. What does long mean? Tens of kilobytes is bad *.
* in recent versions of ClickHouse, "adaptive index granularity" is enabled, which removes the problem of storing long strings for the most part.
Is a kilobyte normal?
Normally.
Hello! Thanks for the report! I already asked about this in the chat, but I don’t remember if I received an answer. Is there any plan to extend the WITH section in a CTE fashion?
Not yet. The WITH section is somewhat frivolous. It's like a little feature for us.
I understand. Thank you!
Thanks for the report! Very interesting! global question. Is it planned to do, perhaps in the form of some kind of stubs, modification of data deletion?
Necessarily. This is our first task in our queue. We are now actively thinking about how to do everything right. And you should start pressing the keyboard*.
* pressed the buttons on the keyboard and everything was done.
Will it somehow affect system performance or not? Will the insert be as fast as it is now?
Perhaps the deletes themselves, the updates themselves will be very heavy, but this will not affect the performance of selects and the performance of inserts in any way.
And one more small question. At the presentation, you talked about the primary key. Accordingly, we have partitioning, which is monthly by default, right? And when we set a date range that fits into a month, then we only read this partition, right?
Yes.
A question. If we cannot select any primary key, then is it right to do it exactly by the “Date” field so that in the background there is a smaller restructuring of this data so that they fit in a more orderly manner? If you don't have range queries and you can't even select any primary key, is it worth putting a date in the primary key?
Yes.
Maybe it makes sense to put in the primary key a field by which the data will be better compressed if they are sorted by this field. For example, user ID. User, for example, goes to the same site. In this case, put the user id and time. And then your data will be better compressed. As for the date, if you really do not have and never have range queries on dates, then you can not put the date in the primary key.
OK thank you very much!
Source: habr.com
