

The year was 2019. Our laboratory received a QUANTUM FIREBALL Plus KA drive with a capacity of 9.1 GB, which is not quite usual for our time. According to the owner of the drive, the failure happened back in 2004 due to the fault of a failed power supply, which took the hard drive and other PC components with it. Then there were trips to various services with attempts to repair the drive and restore data, which were unsuccessful. Somewhere they promised cheap, but they did not solve the problem, somewhere it was too expensive and the client did not want to restore the data, but in the end the disk went through many service centers. It was repeatedly lost, but due to the fact that the owner took care of recording information from various stickers on the drive in advance, he managed to ensure that his hard drive was returned from some service centers. The walks did not go unnoticed, there were multiple soldering marks on the original controller board, and there was also a visual lack of SMD elements (looking ahead, I’ll say that this is the least of the problems of this drive).

Rice. 1 HDD Quantum Fireball Plus KA 9,1GB
First of all, I had to work hard to find in the donor archive such an ancient twin brother of this drive with a working controller board. When this quest was completed, it became possible to carry out detailed diagnostic measures. After checking the motor windings for a short circuit and making sure that there is no short circuit, we install the board from the drive - donor to the drive - patient. We turn on the power and hear the normal sound of the shaft spinning up, passing the calibration test with loading the firmware, and after a few seconds the drive reports by registers that it is ready to respond to commands from the interface.
![]()
Rice. 2 DRD DSC indicators indicate readiness to accept commands.
We back up all copies of firmware modules. We check the integrity of the firmware modules. There are no problems with reading the modules, but the analysis of the reports shows that there are some oddities.
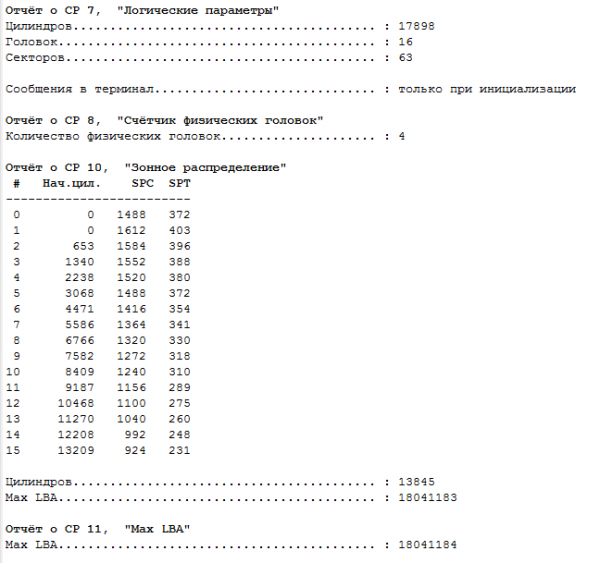
Rice. 3. Table of zones.
We pay attention to the zone distribution table, we notice that the number of cylinders is 13845.
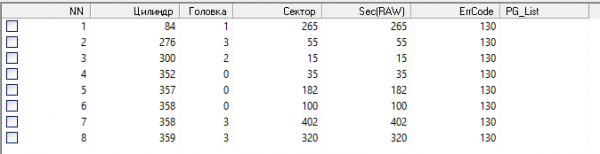
Rice. 4 P-list (primary list - a list of defects introduced during the production cycle).
We pay attention to too few defects and their localization. We look at the factory defects hiding log module (60h) and find that it is empty and does not contain a single entry. Based on this, we can assume that some of the previous service centers may have done some manipulations with the service area of the drive, and accidentally or intentionally a foreign module was written, or the list of defects in the original was cleaned up. To test this assumption, we create a task in the Data Extractor with the options "create a sector-by-sector copy" and "create a virtual translator" enabled.
Rice. 5 Task settings.
After creating a task, we look at the entries in the partition table in the zero sector (LBA 0)
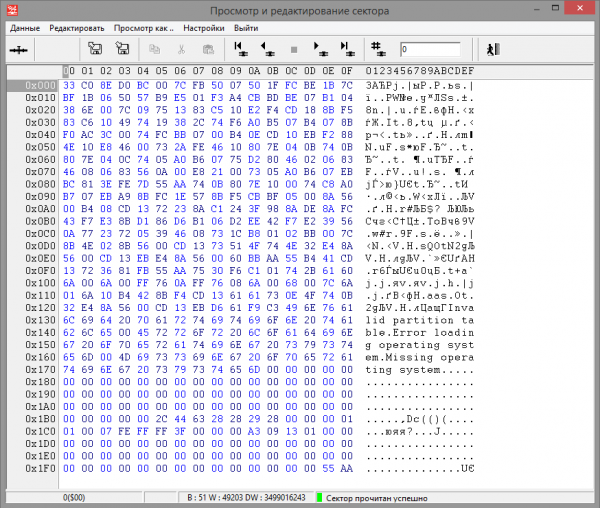
Rice. 6 Master boot record and partition table.
At offset 0x1BE, there is a single entry (16 bytes). The file system type on the partition is NTFS, the offset to the beginning is 0x3F (63) sectors, the partition size is 0x011309A3 (18) sectors.
Open LBA 63 in the sector editor.
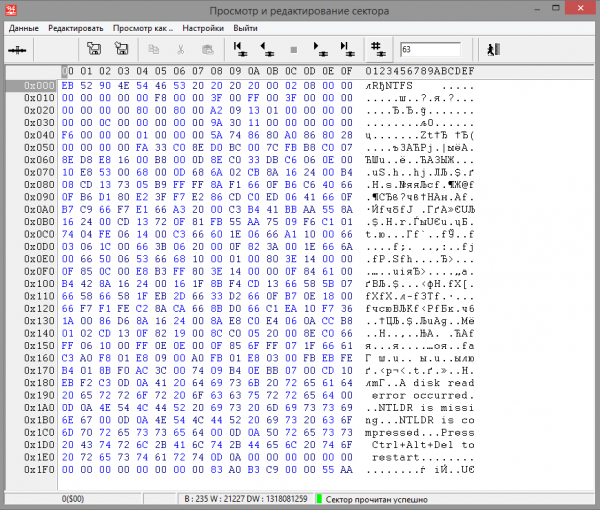
Rice. 7 NTFS boot sector
According to the information in the boot sector of the NTFS partition, we can say the following: the sector size accepted in the volume is 512 bytes (the word 0x0 (0) is written at offset 0200x512B), the number of sectors in the cluster is 8 (byte 0x0 is written at offset 0x08D), the cluster size is 512x8=4096 bytes, the first MFT record is located at offset 6 sectors from the beginning of the disk (at offset 291x519 quadword 0x30 0 00 00 00 00C 00 0 (00) the number of the first MFT cluster. The sector number is calculated by the formula: Cluster number * number of sectors in the cluster + offset to the beginning of the section 00 786* 432+786= 432 8 63).
We pass to the sector 6 291 519.
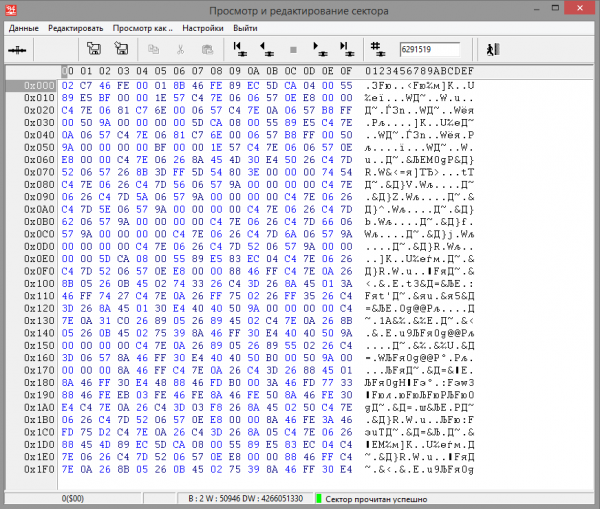
Fig. 8
But the data contained in this sector is completely different from the MFT record. Although this indicates a possible incorrect translation due to an incorrect defect list, it does not prove this fact. For further verification, let's read the disk 10 sectors in both directions relative to 000 sectors. And then we will search for regular expressions in the read.
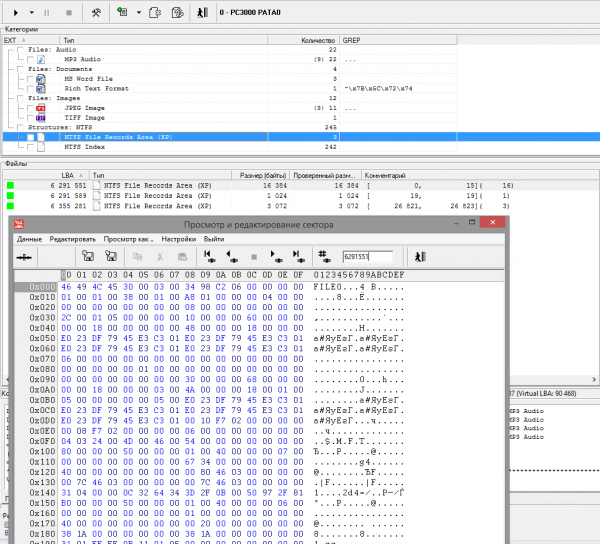
Rice. 9 First MFT entry
In sector 6 291 551 we find the first MFT entry. Its position differs from the calculated one by 32 sectors, and then a group of 16 entries continuously follows (from 0 to 15). Let's enter the position of the sector 6 291 519 into the table of shifts to move forward by 32 sectors.
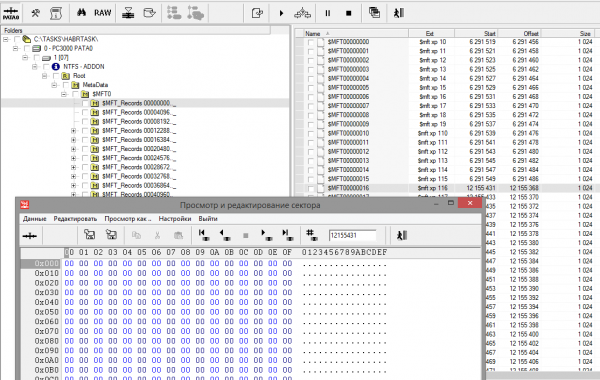
Fig. 10
The position of record No. 16 should be at offset 12 551 431, but there we find zeros, instead of the MFT record. We will conduct a similar search in the vicinity.
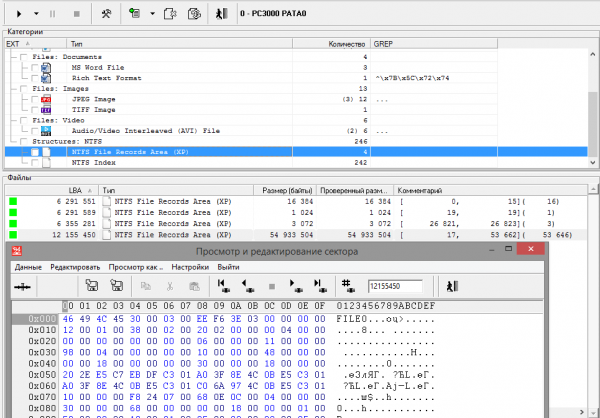
Rice. 11 MFT entry 0x00000011 (17)
A large fragment of the MFT is found, starting with record number 17, 53 records long) with a shift of 646 sectors. For position 17 12 155 we will put a shift of +431 sectors in the shift table.
Having determined the position of the MFT fragments in space, we can conclude that this does not look like a random failure and recording of MFT fragments at incorrect offsets. The version with the incorrect translator can be considered confirmed.
For further localization of shift points, we set the maximum possible shift. To do this, let's determine how far the end marker of the NTFS partition (copy of the boot sector) is shifted. In Figure 7, at offset 0x28, the quad word is the partition size value 0x00 00 00 00 01 13 09 A2 (18) sectors. Let's add the offset of the partition itself from the beginning of the disk to its length, we get the offset of the ending NTFS marker 024 866 18 + 024 = 866 63 18. As expected, the required copy of the boot sector was not there. When searching in the vicinity, it was found with an increasing shift of +024 sectors in relation to the last MFT fragment.
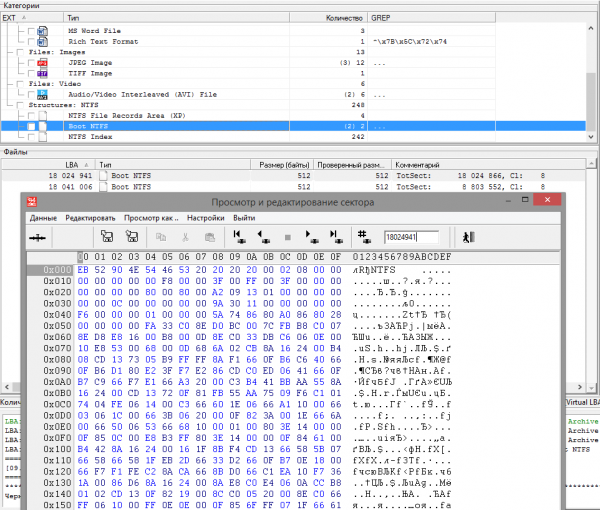
Rice. 12 Copy of NTFS boot sector
We ignore another copy of the boot sector at offset 18 041 006, since it is not related to our partition. Based on previous activities, it was found that within the section there are inclusions from 61 sectors that “surfaced” in the broadcast, which pushed the data apart.
We perform a full read of the drive, the result of which is 34 unread sectors. Unfortunately, it is impossible to reliably guarantee that all of them are defects removed from the P-list, but in further analysis it is desirable to take into account their position, since in some cases it will be possible to reliably determine shift points with an accuracy of a sector, and not to a file.
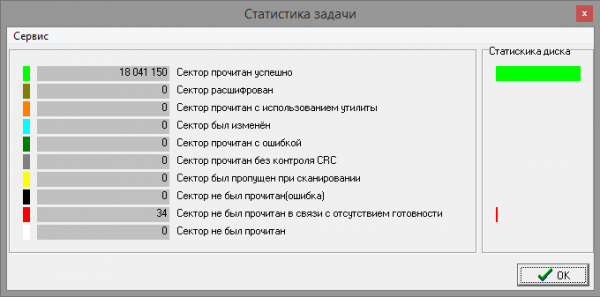
Rice. 13 Disk read statistics.
Our next task will be to establish the approximate places of the shifts (accurate to the file in which they occurred). To do this, we will scan all MFT records and build a chain of file locations (file fragments).
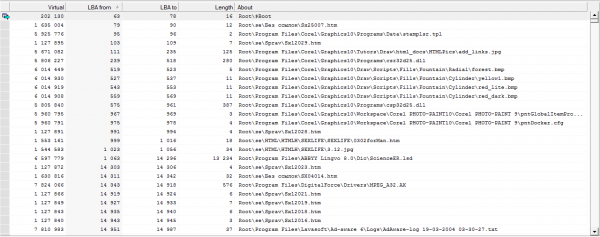
Rice. 14 Chains of location of files or their fragments.
Further, moving from file to file, we are looking for from what moment instead of the expected file header there will be other data, and the desired header will be found with a certain positive shift. And as the shift points are refined, we fill in the table. The result of its completion will be over 99% of the files without damage.
Rice. 15 List of user files (consent received from the client to publish this screenshot)
To establish point shifts in individual files, you can carry out additional work and, if you know the structure of the file, find inclusions of data that are not related to it. But in this task it was not economically feasible.
PS I would also like to address my colleagues who have had this disc in their hands before. Please be careful when working with device firmware and back up service data before changing anything, and also do not intentionally aggravate the problem if you failed to agree with the client on the work to be done.
Source: habr.com
