

Today, there are ready-made (proprietary) solutions for monitoring IP(TS) streams, for example и , they have a fairly rich set of functions and usually large operators dealing with TV services have such solutions. This article describes a solution based on an open source project , designed for minimal control of IP(TS) streams by CC(continuity counter) counter and bitrate. A possible application is to control the loss of packets or the entire flow through a leased L2 channel (which cannot be monitored normally, for example, by reading loss counters in queues).
Very briefly about TSDuck
TSDuck is an open source (2-Clause BSD license) software (a set of console utilities and a library for developing custom utilities or plugins) for manipulating TS streams. As an input, it can work with IP (multicast/unicast), http, hls, dvb tuners, dektec dvb-asi demodulator, there is an internal TS-stream generator and reading from files. The output can be writing to a file, IP (multicast/unicast), hls, dektec dvb-asi and HiDes modulators, players (mplayer, vlc, xine) and drop. Various traffic processors can be included between input and output, for example, PID remapping, scrambling / descrambling, CC counter analysis, bitrate calculation, and other typical operations for TS streams.
In this article, IP streams (multicast) will be used as an input, the processors bitrate_monitor (from the name it is clear what it is) and continuity (analysis of CC counters) are used. You can easily replace IP multicast with another input type supported by TSDuck.
There are TSDuck for most current OS. For Debian there aren't any, but I managed to assemble it without any problems debian 8 and debian 10.
Next, the version TSDuck 3.19-1520 is used, and the OS is Linux (used to prepare the solution) debian 10, for real use - CentOS 7)
Preparing TSDuck and OS
Before monitoring real flows, you need to make sure that TSDuck works correctly and there are no drops at the network card or OS (socket) level. This is required in order not to guess later where the drops occurred - on the network or “inside the server”. You can check drops at the network card level with the ethtool -S ethX command, tuning is done by the same ethtool (usually, you need to increase the RX buffer (-G) and sometimes disable some offloads (-K)). As a general recommendation, it can be advised to use a separate port for receiving the analyzed traffic, if possible, this minimizes false positives associated with the fact that the drop happened exactly on the analyzer port due to the presence of other traffic. If this is not possible (a mini-computer/NUC with one port is used), then it is highly desirable to set up the prioritization of the analyzed traffic in relation to the rest on the device to which the analyzer is connected. Regarding virtual environments, here you need to be careful and be able to find packet drops starting from a physical port and ending with an application inside a virtual machine.
Generation and reception of a stream inside the host
As a first step in preparing TSDuck, we will generate and receive traffic within a single host using netns.
Preparing the environment:
ip netns add P #создаём netns P, в нём будет происходить анализ трафика
ip link add type veth #создаём veth-пару - veth0 оставляем в netns по умолчанию (в этот интерфейс будет генерироваться трафик)
ip link set dev veth1 netns P #veth1 - помещаем в netns P (на этом интерфейсе будет приём трафика)
ip netns exec P ifconfig veth1 192.0.2.1/30 up #поднимаем IP на veth1, не имеет значения какой именно
ip netns exec P ip ro add default via 192.0.2.2 #настраиваем маршрут по умолчанию внутри nents P
sysctl net.ipv6.conf.veth0.disable_ipv6=1 #отключаем IPv6 на veth0 - это делается для того, чтобы в счётчик TX не попадал посторонний мусор
ifconfig veth0 up #поднимаем интерфейс veth0
ip route add 239.0.0.1 dev veth0 #создаём маршрут, чтобы ОС направляла трафик к 239.0.0.1 в сторону veth0The environment is ready. We start the traffic analyzer:
ip netns exec P tsp --realtime -t
-I ip 239.0.0.1:1234
-P continuity
-P bitrate_monitor -p 1 -t 1
-O dropwhere "-p 1 -t 1" means that you need to calculate the bitrate every second and display information about the bitrate every second
We start the traffic generator with a speed of 10Mbps:
tsp -I craft
-P regulate -b 10000000
-O ip -p 7 -e --local-port 6000 239.0.0.1:1234where "-p 7 -e" means that you need to pack 7 TS packets into 1 IP packet and do it hard (-e), i.e. always wait 7 TS packets from the last processor before sending an IP packet.
The analyzer starts outputting the expected messages:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s
* 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s
* 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/sNow add some drops:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROPand messages like this appear:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets
* 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets which is expected. Disable packet loss (ip netns exec P iptables -F) and try to increase the generator bitrate to 100Mbps. The analyzer reports a bunch of CC errors and about 75 Mbps instead of 100. We are trying to figure out who is to blame - the generator does not have time or the problem is not in it, for this we start generating a fixed number of packets (700000 TS packets = 100000 IP packets):
# ifconfig veth0 | grep TX
TX packets 151825460 bytes 205725459268 (191.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
* count: PID 0 (0x0000): 700,000 packets
# ifconfig veth0 | grep TX
TX packets 151925460 bytes 205861259268 (191.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0As you can see, exactly 100000 IP packets were generated (151925460-151825460). So let's figure out what is happening with the analyzer, for this we check with the RX counter on veth1, it is strictly equal to the TX counter on veth0, then we look at what happens at the socket level:
# ip netns exec P cat /proc/net/udp
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops
133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355 Here you can see the number of drops = 24355. In TS packets, this is 170485 or 24.36% of 700000, so we see that those same 25% of the lost bitrate are drops in the udp socket. Drops in a UDP socket usually occur due to a lack of buffer, look at the default socket buffer size and the maximum socket buffer size:
# sysctl net.core.rmem_default
net.core.rmem_default = 212992
# sysctl net.core.rmem_max
net.core.rmem_max = 212992Thus, if applications do not explicitly request a buffer size, sockets are created with a buffer of 208 KB, but if they request more, they still will not receive what was requested. Since you can set the buffer size in tsp for the IP input (-buffer-size), we will not touch the default socket size, but only set the maximum socket buffer size and specify the buffer size explicitly through the tsp arguments:
sysctl net.core.rmem_max=8388608
ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O dropWith this tuning of the socket buffer, now the reported bitrate is about 100Mbps, there are no CC errors.
According to the CPU consumption of the tsp application itself. Relative to one core i5-4260U CPU @ 1.40GHz, 10Mbps flow analysis will require 3-4% CPU, 100Mbps - 25%, 200Mbps - 46%. When setting the % Packet Loss, the load on the CPU practically does not increase (but may decrease).
On more productive hardware, it was possible to generate and analyze streams of more than 1Gb / s without any problems.
Testing on real network cards
After testing on a veth pair, you need to take two hosts or two ports of one host, connect the ports to each other, start the generator on one, and the analyzer on the second. There were no surprises here, but in fact it all depends on the iron, the weaker, the more interesting it will be here.
Using the received data by the monitoring system (Zabbix)
tsp does not have any machine-readable API like SNMP or similar. CC messages must be aggregated for at least 1 second (with a high percentage of packet loss, there can be hundreds/thousands/tens of thousands per second, depending on the bitrate).
Thus, in order to save both information and draw graphs for CC errors and bitrate and make some kind of accidents, there may be the following options:
- Parse and aggregate (by CC) the output of tsp, i.e. convert it to the desired form.
- Finish tsp itself and/or processor plugins bitrate_monitor and continuity so that the result is given in a machine-readable form suitable for the monitoring system.
- Write your application on top of the tsduck library.
Obviously, option 1 is the easiest in terms of effort, especially considering that tsduck itself is written in a low-level (by modern standards) language (C ++)
A simple bash parser+aggregator prototype showed that on a 10Mbps stream and 50% packet loss (worst case), the bash process consumed 3-4 times more CPU than the tsp process itself. This scenario is unacceptable. Actually a piece of this prototype below
Noodles on the top
#!/usr/bin/env bash
missingPackets=0
ccErrorSeconds=0
regexMissPackets='^* (.+) - continuity:.*missing ([0-9]+) packets$'
missingPacketsTime=""
ip netns exec P tsp --realtime -t -I ip -b 8388608 "239.0.0.1:1234" -O drop -P bitrate_monitor -p 1 -t 1 -P continuity 2>&1 |
while read i
do
#line example:* 2019/12/28 23:41:14 - continuity: packet index: 6,078, PID: 0x0100, missing 5 packets
#line example 2: * 2019/12/28 23:55:11 - bitrate_monitor: 2019/12/28 23:55:11, TS bitrate: 4,272,864 bits/s
if [[ "$i" == *continuity:* ]]
then
if [[ "$i" =~ $regexMissPackets ]]
then
missingPacketsTimeNew="${BASH_REMATCH[1]}" #timestamp (seconds)
if [[ "$missingPacketsTime" != "$missingPacketsTimeNew" ]] #new second with CC error
then
((ccErrorSeconds += 1))
fi
missingPacketsTime=$missingPacketsTimeNew
packets=${BASH_REMATCH[2]} #TS missing packets
((missingPackets += packets))
fi
elif [[ "$i" == *bitrate_monitor:* ]]
then
: #...
fi
doneIn addition to being unacceptably slow, there are no normal threads in bash, bash jobs are separate processes and I had to write the value of missingPackets once a second on the side effect (when receiving bitrate messages that come every second). As a result, bash was left alone and it was decided to write a wrapper (parser + aggregator) in golang. The CPU consumption of similar golang code is 4-5 times less than the tsp process itself. The speedup of the wrapper due to the replacement of bash with golang turned out to be about 16 times and in general the result is acceptable (CPU overhead by 25% in the worst case). The golang source file is located .
Run wrapper
To start the wrapper, the simplest service template for systemd was made (). The wrapper itself is supposed to be compiled into a binary file (go build tsduck-stat.go) located in /opt/tsduck-stat/. It is assumed that you are using golang with support for monotonic clock (>=1.9).
To create a service instance, you need to run the systemctl enable tsduck-stat@239.0.0.1:1234 command, then start with systemctl start tsduck-stat@239.0.0.1:1234.
Discovery from Zabbix
In order for zabbix to be able to discover running services, it is done (discovery.sh), in the format required for Zabbix discovery, it is assumed that it is located in the same place - in /opt/tsduck-stat. To run discovery via zabbix-agent, you need to add to the zabbix-agent configuration directory to add the user parameter.
Zabbix template
(tsduck_stat_template.xml) contains the autodiscover rule, item prototypes, graphs, and triggers.
Brief checklist (well, what if someone decides to use it)
- Make sure that tsp does not drop packets under "ideal" conditions (generator and analyzer are connected directly), if there are drops, see paragraph 2 or the text of the article on this matter.
- Make tuning the maximum socket buffer (net.core.rmem_max=8388608).
- Compile tsduck-stat.go (go build tsduck-stat.go).
- Put the service template in /lib/systemd/system.
- Start services with systemctl, check that counters have started to appear (grep "" /dev/shm/tsduck-stat/*). The number of services by the number of multicast streams. Here you may need to create a route to the multicast group, perhaps disable rp_filter or create a route to the source ip.
- Run discovery.sh, make sure it generates json.
- Add zabbix agent config, restart zabbix agent.
- Upload the template to zabbix, apply it to the host that is being monitored and the zabbix-agent is installed, wait about 5 minutes, see if there are new items, graphs and triggers.
Experience the Power of Effective Results
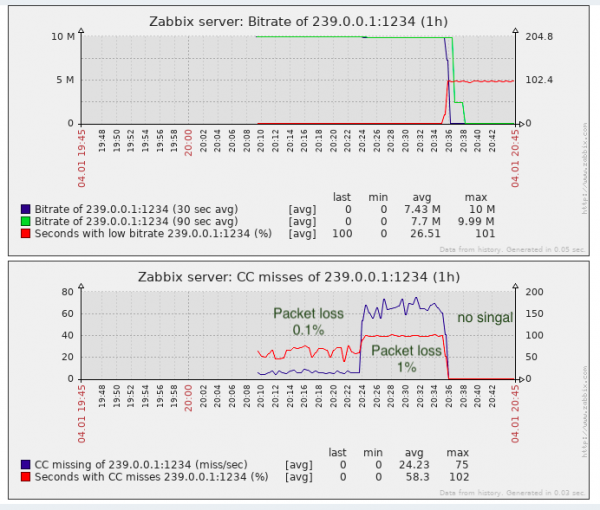
For the task of detecting packet loss, it is almost enough, at least it is better than no monitoring.
Indeed, CC “losses” can occur when merging video fragments (as far as I know, this is how inserts are made at local TV centers in the Russian Federation, i.e. without recalculating the CC counter), this must be remembered. Proprietary solutions partially circumvent this problem by detecting SCTE-35 labels (if added by the stream generator).
In terms of transport quality monitoring, there is a lack of jitter monitoring (IAT). TV equipment (be it modulators or end devices) has requirements for this parameter and it is not always possible to inflate the jitbuffer to infinity. And jitter can float when equipment with large buffers is used in transit and QoS is not configured or not well configured enough to transmit such realtime traffic.
Source: habr.com
