

Clouds are like a magic box - you ask what you need, and resources just appear out of nowhere. Virtual machines, databases, network - all this belongs only to you. There are other tenants of the cloud, but in your universe you are the sole ruler. You are sure that you will always get the required resources, you do not reckon with anyone and independently determine what the network will be like. How does this magic work, which makes the cloud allocate resources elastically and completely isolate tenants from each other?
The AWS cloud is a mega-super-complex system that has been evolving evolutionarily since 2006. Part of this development Vasily Pantyukhin - Amazon Web Services Architect. As an architect, he sees from the inside not only the end result, but also the complexities that AWS overcomes. The more understanding of how the system works, the more trust. Therefore, Vasily will share the secrets of AWS cloud services. Under the cut, the device of AWS physical servers, elastic database scalability, Amazon custom database and methods to improve the performance of virtual machines while reducing their price. Knowledge of Amazon's architectural approaches will help you make better use of AWS services and, perhaps, give you new ideas for building your own solutions.
About speaker: Vasily Pantyukhin () started as a Unix administrator in .ru companies, for 6 years he worked on the big hardware of Sun Microsystem, for 11 years he preached the data-centricity of the world at EMC. It naturally evolved into private clouds, and in 2017 moved into public ones. Now, with technical advice, he helps to live and develop in the AWS cloud.
Disclaimer: Everything below is Vasily's personal opinion and may not reflect the position of Amazon Web Services. The report on the basis of which the article was created is available on our YouTube channel.
Why am I talking about the Amazon device
My first car was with a "handle" - on a manual transmission. It was great because of the feeling that I can drive the car and completely control it. I also liked that I at least roughly understand the principle of its operation. Naturally, I imagined the device of the box rather primitively - something like a gearbox on a bicycle.

Everything was great, except for one thing - standing in traffic jams. You seem to be sitting and doing nothing, but constantly shifting gears, pressing the clutch, gas, brake - you really get tired of this. The problem of traffic jams was partially resolved when a car appeared on the machine in the family. Behind the wheel, there was time to think about something, listen to an audiobook.
Another mystery appeared in my life, because I didn’t understand how my car works at all. A modern car is a complex device. The car adapts simultaneously to dozens of different parameters: pressing the gas, brake, driving style, road quality. I don't understand how it works anymore.
When I started working on the Amazon cloud, it was a mystery to me too. Only this mystery is an order of magnitude higher, because there is one driver in the car, and there are millions of them in AWS. All users simultaneously steer, press the gas and brake. It's amazing that they go where they want - for me it's a miracle! The system automatically adapts, scales and elastically adjusts to each user so that it seems to him that he is alone in this Universe.
The magic dissipated a bit when I later came to work as an architect at Amazon. I saw what problems we face, how we solve them, how we develop services. With the growth of understanding of the system, there is more confidence in the service. So I want to share a picture of what's under the hood of the AWS cloud.
What shall we talk about
I chose a diversified approach - I selected 4 interesting services that are worth talking about.
Server Optimization. Ephemeral clouds with a physical appearance: physical data centers, where there are physical servers that buzz, heat up and flash lights.
Serverless functions (Lambda) is probably the most scalable service in the cloud.
Database scaling. I'll tell you about how we build our own scalable databases.
Network scaling. The last part, in which I will open the device of our network. This is a wonderful thing - each cloud user believes that he is alone in the cloud and does not see other tenants at all.
Note. This article will focus on server optimization and database scaling. Network scaling will be discussed in the next article. Where are the serverless functions? A separate transcript was published about them "". It talks about several different ways to scale, and analyzes in detail the Firecracker solution - a symbiosis of the best qualities of a virtual machine and containers.
Servers
The cloud is ephemeral. But this ephemeral nature still has a physical embodiment—servers. Initially, their architecture was classic. A standard x86 chipset, network cards, Linux, the Xen hypervisor on which the virtual machines were run.
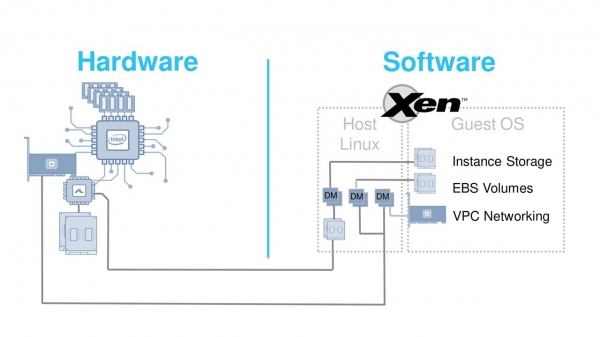
In 2012, this architecture coped well with its tasks. Xen is an excellent hypervisor, but with one major drawback. He has enough high overhead for device emulation. With new faster network cards or SSD drives, this overhead becomes too high. How to deal with this problem? Decided to work on two fronts at once - optimize both hardware and hypervisor. The task is very serious.
Hardware and hypervisor optimization
Doing it all at once won't work well. What is "good" was also initially unclear.
We decided to apply an evolutionary approach - we change one important element of the architecture and throw it into production.
We step on all the rakes, listen to complaints and suggestions. Then we change another component. So, in small increments, we radically change the entire architecture based on feedback from users and support.
Transformations began in 2013 with the most difficult - the network. IN С3 instances, a special Network Accelerator card was added to the standard network card. It was connected literally with a short loopback cable on the front panel. Ugly, but not visible in the cloud. But direct interaction with iron fundamentally improved jitter and network throughput.
Then we decided to improve access to EBS block data storage - Elastic Block Storage. It's a combination of network and storage. The difficulty is that if there were Network Accelerator cards on the market, then there was no way to simply buy Storage Accelerator hardware. So we turned to a startup Annapurna Labs, who developed special ASIC chips for us. They allowed remote EBS volumes to be mounted as NVMe devices.
In instances C4 we have solved two problems. First, we realized the groundwork for the future of the promising, but new at that time, NVMe technology. The second is that the CPU was significantly offloaded by transferring the processing of requests to EBS to a new card. It worked out well, which is why Annapurna Labs is now part of Amazon.
By November 2017, we realized that it was time to change the hypervisor itself.
The new hypervisor was developed on the basis of modified KVM kernel modules.
It made it possible to fundamentally reduce the overhead of device emulation and work directly with new ASICs. Instances С5 were the first virtual machines under the hood of which the new hypervisor works. We named him Nitro.
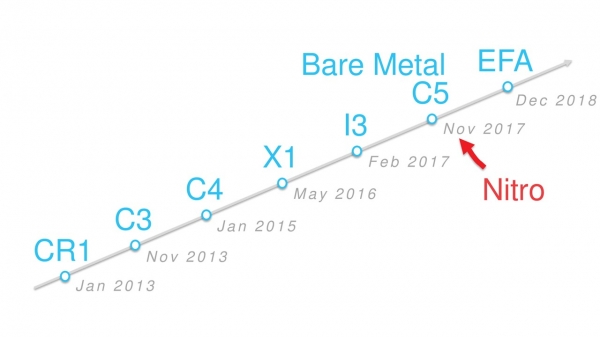 Evolution of instances on the timeline.
Evolution of instances on the timeline.
All new types of virtual machines that have appeared since November 2017 run on this hypervisor. Iron Bare Metal instances do not have a hypervisor, but they are also called Nitro, as they use specialized Nitro cards.
Over the next two years, the number of types of Nitro instances exceeded a couple of dozen: A1, C5, M5, T3 and others.

Instance types.
How modern Nitro machines work
They have three main components: the Nitro hypervisor (mentioned above), the security chip, and the Nitro cards.
security chip integrated directly into the motherboard. It controls many important functions, such as boot control of the host OS.
Nitro maps There are four types of them. All of them are developed by Annapurna Labs and are based on common ASICs. Part of their firmware is also common.
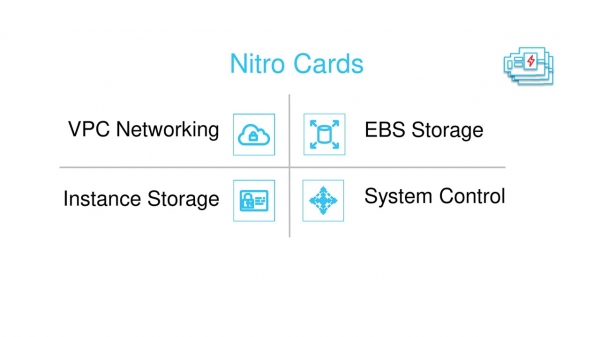
Four types of Nitro cards.
One of the cards is designed to work with networkMail order. It is she who is visible in virtual machines as a network card ENA - Elastic Network Adapter. It also encapsulates traffic when it is transmitted through a physical network (we will talk about this in the second part of the article), controls the Security Groups firewall, is responsible for routing and other network things.
Individual cards work with block storage EBS and disks that are built into the server. They appear to the guest virtual machine as NVMe adapters. They are also responsible for data encryption and disk monitoring.
The system of Nitro-cards, hypervisor and security chip is integrated into an SDN network or Software Defined Network. Responsible for managing this network (Control Plane) controller card.
Of course, we continue to develop new ASICs. For example, at the end of 2018, the Inferentia chip was released, which allows you to work more efficiently with machine learning tasks.

Chip Inferentia Machine Learning Processor.
Scalable database
The traditional database has a layered structure. If greatly simplified, then the following levels are distinguished.
- SQL — on it dispatchers of clients and requests work.
- Security transactions - everything is clear here, ACID and all that.
- caching, which is provided by buffer pools.
- Logging - provides work with redo-logs. In MySQL they are called Bin Logs, in PostgreSQL they are called Write Ahead Logs (WAL).
- Storage – direct recording to disk.
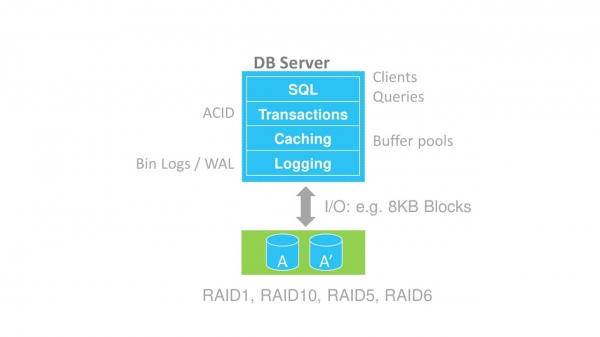
Layered database structure.
There are different ways to scale databases: sharding, Shared Nothing architecture, shared disks.
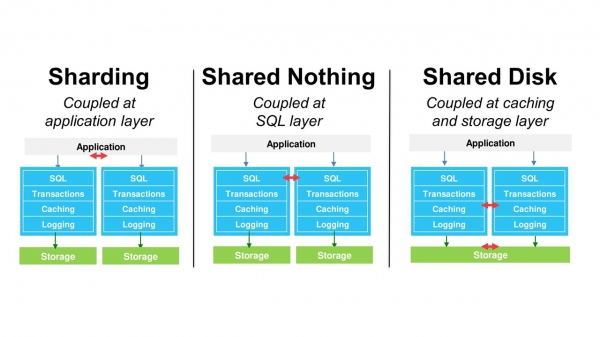
However, all of these methods retain the same monolithic database structure. This noticeably limits scaling. To solve this problem, we have developed our own DB − Amazon Aurora. It is compatible with MySQL and PostgreSQL.
Amazon Aurora
The main architectural idea is to split the storage and logging levels from the main database.
Looking ahead, I’ll say that we also made the caching level independent. The architecture ceases to be a monolith, and we get additional degrees of freedom in scaling individual blocks.
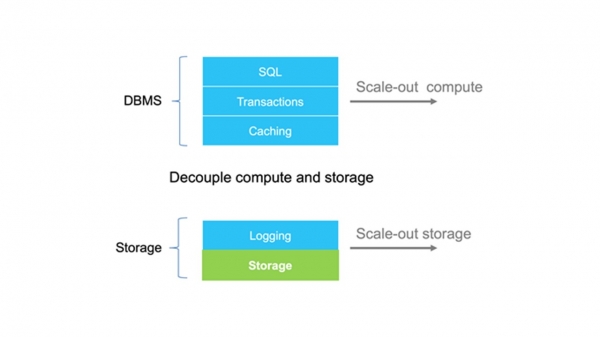
The logging and storage layers are separate from the database.
A traditional DBMS writes data to the storage system in the form of blocks. At Amazon Aurora, we created a smart storage that can speak the language redo-logs. Internally, the storage turns logs into data blocks, monitors their integrity and automatically backs up.
This approach allows you to implement such interesting things as cloning. It works fundamentally faster and more economical due to the fact that it does not require the creation of a complete copy of all data.
The storage layer is implemented as a distributed system. It consists of a very large number of physical servers. Each redo log is processed and saved at the same time six knots. This ensures data protection and load balancing.
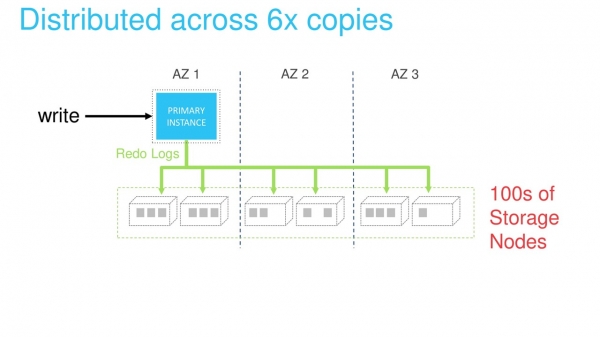
Read scaling can be achieved using appropriate replicas. Distributed storage eliminates the need for synchronization between the master DB Instance, through which we write data, and the rest of the replicas. Up-to-date data is guaranteed to be available to all replicas.
The only issue is caching old data on read replicas. But this problem is solved transfer of all redo logs to replicas over the internal network. If the log is in the cache, then it is marked as invalid and overwritten. If it is not in the cache, then it is simply discarded.
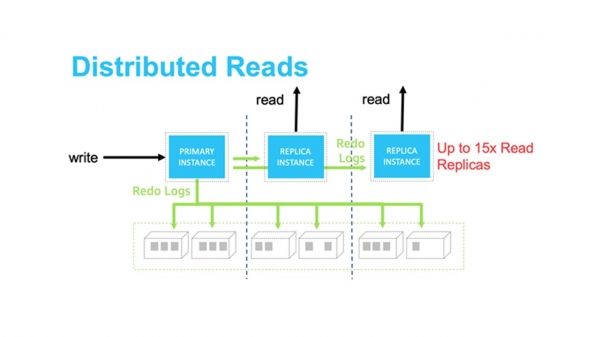
Dealt with storage.
How to scale DBMS levels
Here horizontal scaling is much more difficult to do. So let's go the beaten track classic vertical zoom.
Suppose we have an application that communicates with the DBMS through the master node.
With vertical scaling, we allocate a new node, which will have more processors and memory.
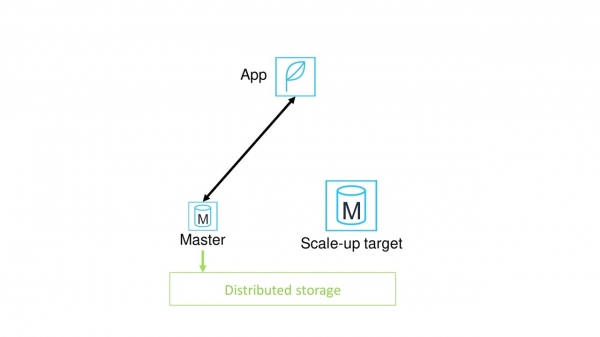
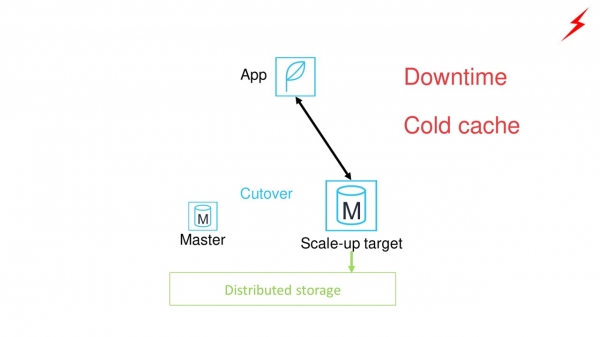
Next, we switch the application from the old master node to the new one. There are problems.
- This will require a noticeable downtime of the application.
- The new master node will have a cold cache. The performance of the database will be maximum only after the cache is warmed up.
How to improve the situation? Set up a proxy between the application and the master node.
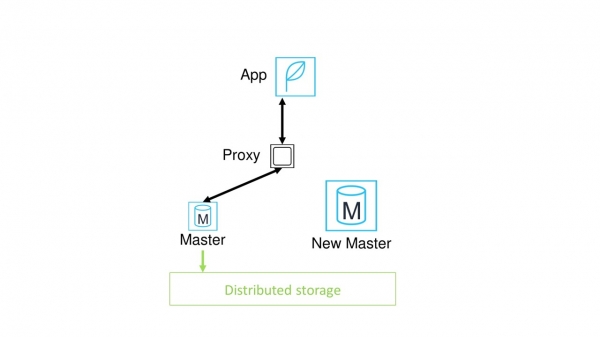
What will it give us? Now all applications do not need to be manually redirected to a new node. Switching can be done under a proxy and at the same time is fundamentally faster.
It seems that the problem is solved. But no, we still suffer from the need to warm up the cache. In addition, a new problem has appeared - now the proxy is a potential point of failure.
Final solution with Amazon Aurora serverless
How did we solve these problems?
left proxy. This is not some separate instance, but a whole distributed proxy fleet through which applications connect to the database. Any of the nodes in the event of failure can be replaced almost instantly.
Added a pool of warm nodes of various sizes. Therefore, if it is necessary to allocate a new node of a larger or smaller size, it is immediately available. You don't have to wait for it to load.
The whole scaling process is controlled by a special monitoring system. Monitoring constantly monitors the status of the current master node. If it detects, for example, that the load on the processor has reached a critical value, then it notifies the pool of warm instances about the need to allocate a new node.
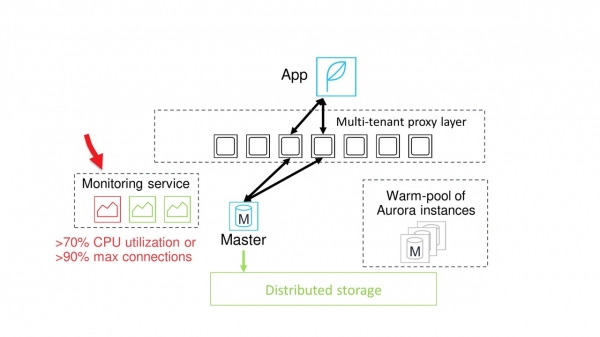
Distributed proxies, warm instances and monitoring.
The required power node is available. Buffer pools are copied to it, and the system begins to wait for a safe moment to switch.
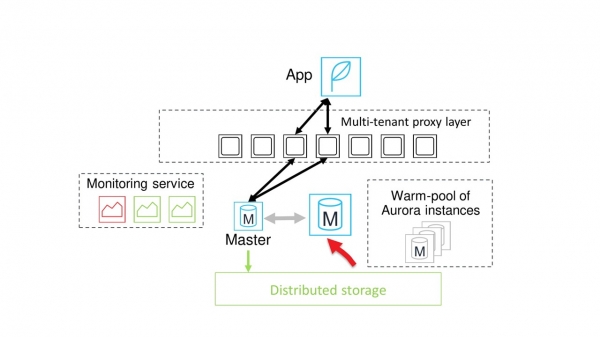
Usually the moment for switching comes quickly enough. Then the communication between the proxy and the old master node is suspended, all sessions are switched to the new node.
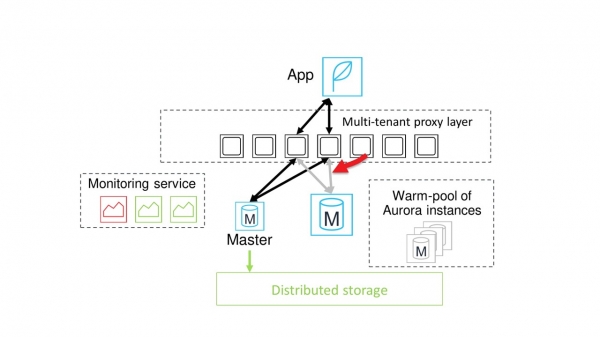
The database activity is resumed.
The graph shows that the suspension is really very short. On the blue graph is the load, and on the red steps are the scaling moments. Short-term dips in the blue chart are just that very short delay.
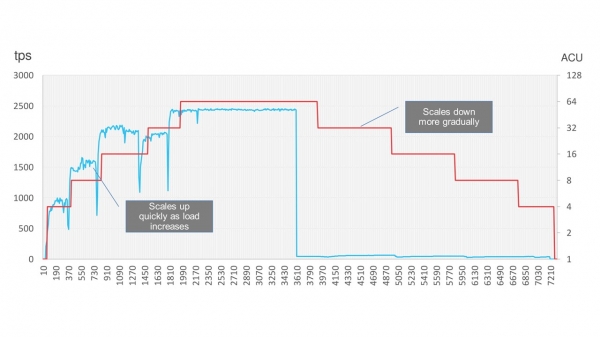
By the way, Amazon Aurora allows you to completely save money and turn off the database when it is not in use, for example, on weekends. After the load is stopped, the database gradually reduces its power and turns off for a while. When the load returns, it will slowly rise again.
In the next part of the story about the Amazon device, we will talk about network scaling. Subscribe and stay tuned so you don't miss the article.
For Vasily Pantyukhin will make a presentation "". What distributed system design patterns are used by Amazon developers, what are the reasons for service failures, what is Cell-based architecture, Constant Work, Shuffle Sharding - it will be interesting. Less than a month before the conference . October 24 final price increase.
Source: habr.com
